and is for informational purposes only. Customers who purchase Databricks services should make their purchase decisions relying solely upon services, features, and functions that are currently available. Unreleased features or functionality described in forward-looking statements are subject to change at Databricks discretion and may not be delivered as planned or at all Product safe harbor statement
— All rights reserved 4 About Serge ▪ Using Apache Spark since ~2015 ▪ At Databricks since 2019 ▪ Created Databricks Terraform Provider ▪ Author of Databricks SDKs ▪ Driving Databricks Labs ▪ Years in cybersecurity and payments before that
— All rights reserved • Consistent across all SDK • Exceptions are named after Databricks error codes • Inheritance is modelled after HTTP status codes 22 ERROR HIERARCHY Catch the right thing in the right place to recover properly
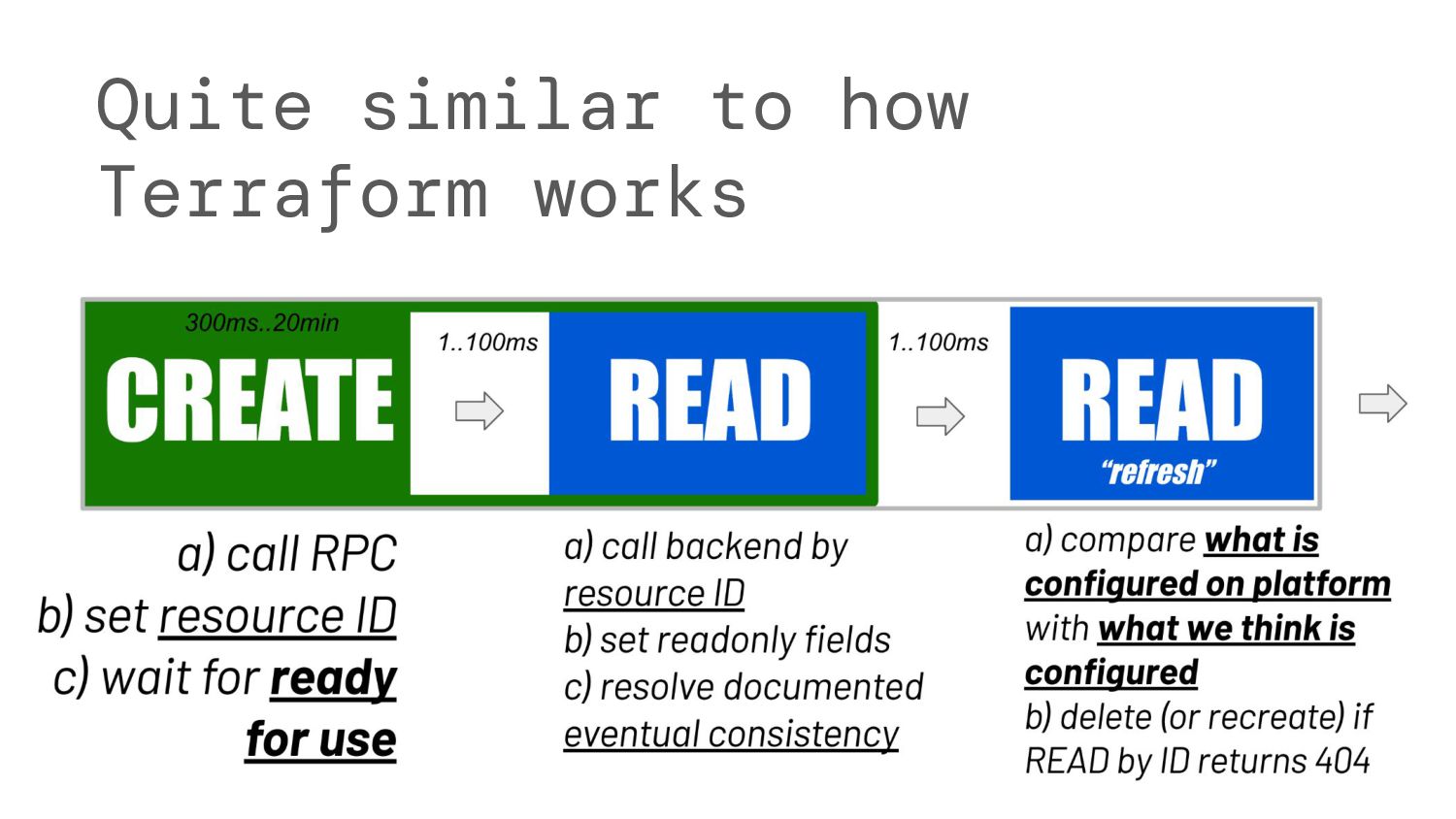
are not always successful @retried(on=[InternalError, ResourceConflict, DeadlineExceeded]) @rate_limited(max_requests=35, burst_period_seconds=60) def _delete_workspace_group(self, group_id: str, display_name: str) -> None: try: logger.info(f"Deleting the workspace-level group {display_name} with id {group_id}") self._ws.groups.delete(id=group_id) logger.info(f"Workspace-level group {display_name} with id {group_id} was deleted") return None # should be deleted now except NotFound: return None # it’s definitely deleted now EVENTUALLY CONSISTENT API 23
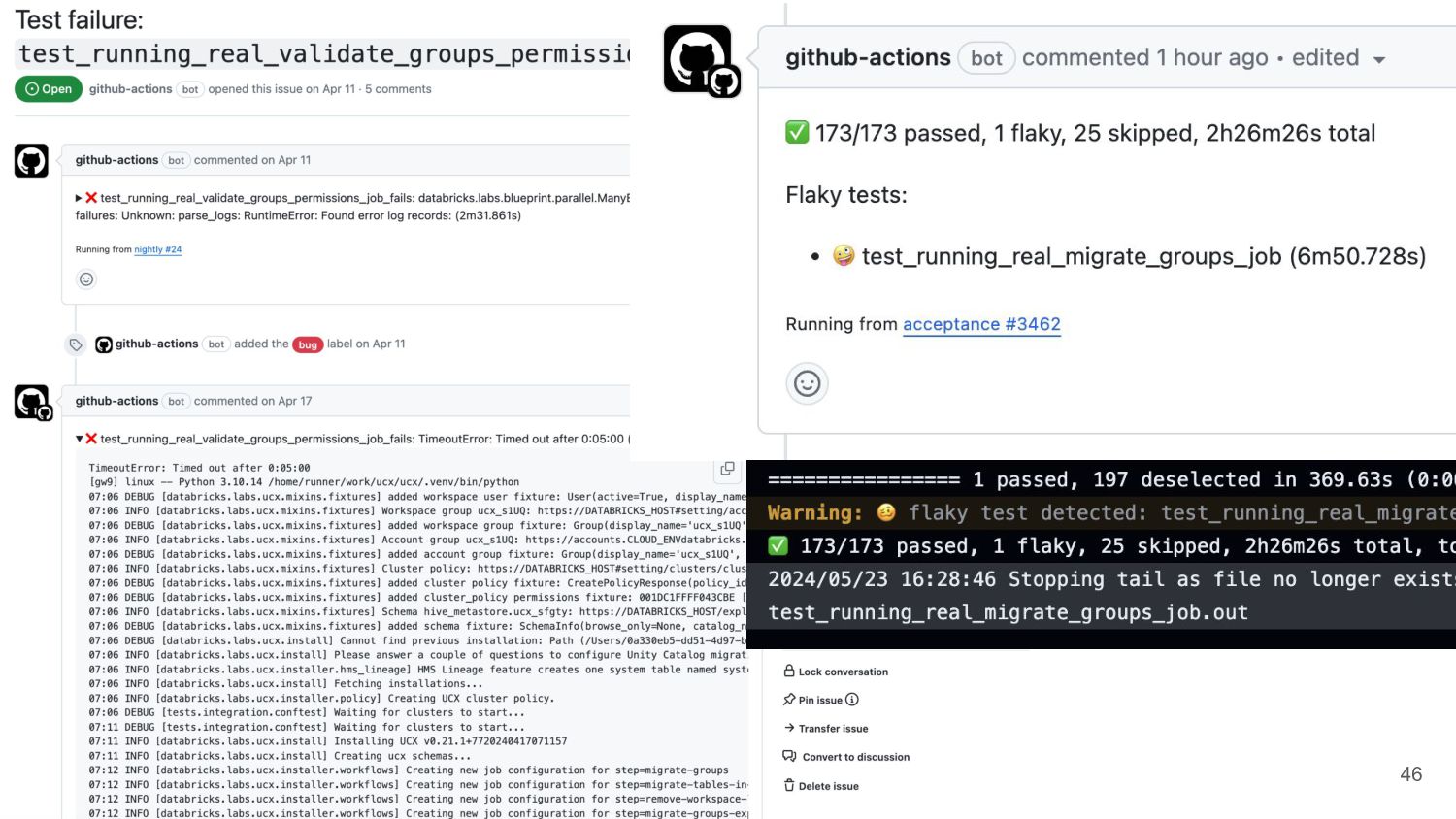
WORKFLOW By default, we only see the beginning and the end of standard output 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 128 1 2 3 … . .. .. 78368 Minute 1 1.5 hours Minute 5
RUFF? Even though RUFF is 10x+ faster than PyLint, it doesn't have a plugin system yet, nor does it have a feature parity with PyLint yet. Other projects use MyPy, Ruff, and PyLint together to achieve the most comprehensive code analysis. You can try using Ruff and just the checkers from this plugin in the same CI pipeline and pre-commit hook.
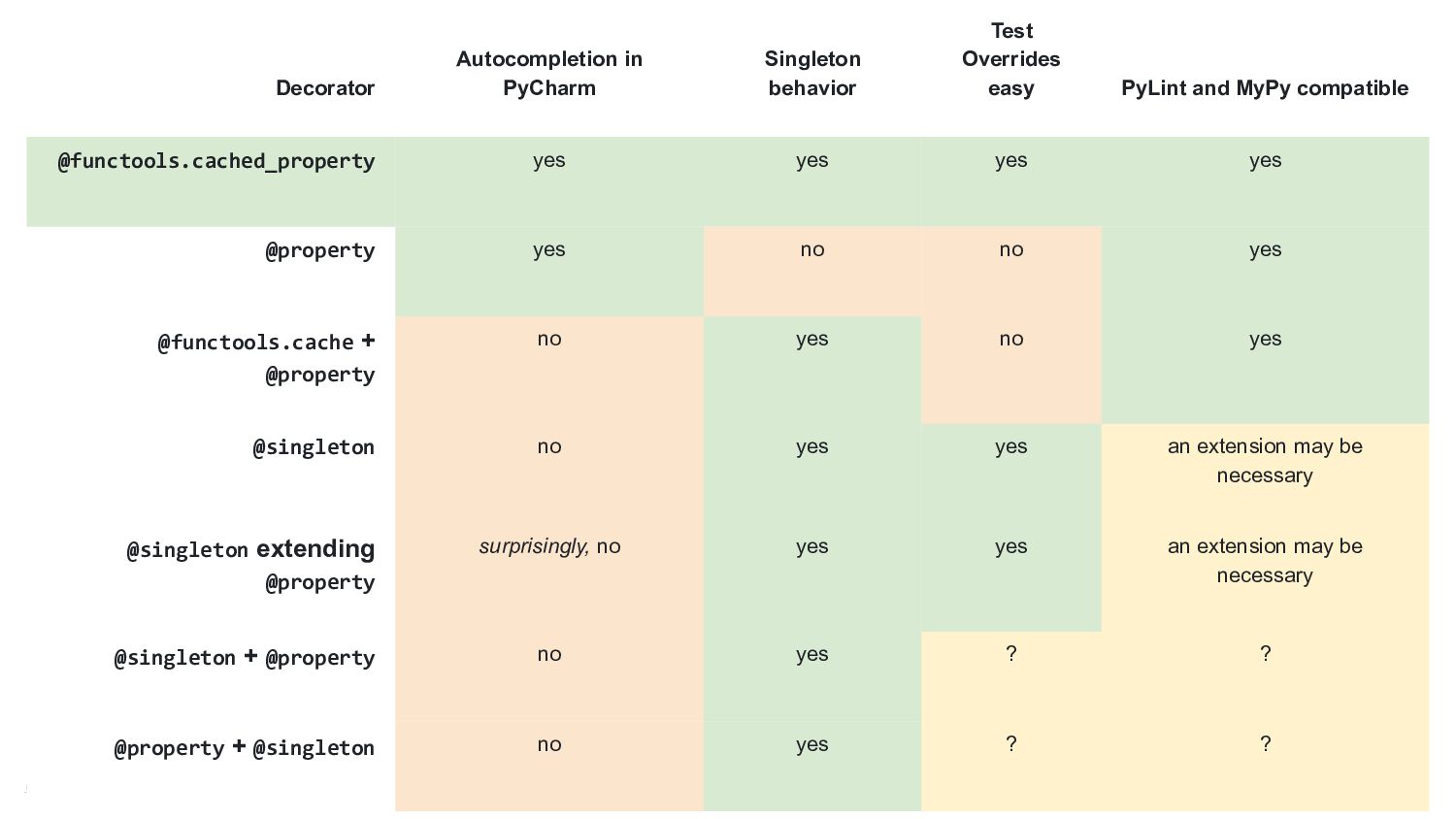
in PyCharm Singleton behavior Test Overrides easy PyLint and MyPy compatible @functools.cached_property yes yes yes yes @property yes no no yes @functools.cache + @property no yes no yes @singleton no yes yes an extension may be necessary @singleton extending @property surprisingly, no yes yes an extension may be necessary @singleton + @property no yes ? ? @property + @singleton no yes ? ?
works(): return True def fails(): raise NotFound("something is not right") tasks = [works, fails, works, fails, works, fails, works, fails] results, errors = Threads.gather("doing some work", tasks) assert [True, True, True, True] == results assert 4 == len(errors) 14:08:31 ERROR [d.l.blueprint.parallel][doing_some_work_0] doing some work task failed: something is not right: ... ... 14:08:31 ERROR [d.l.blueprint.parallel][doing_some_work_3] doing some work task failed: something is not right: ... 14:08:31 ERROR [d.l.blueprint.parallel] More than half 'doing some work' tasks failed: 50% results available (4/8). Took 0:00:00.001011 PARALLEL THINGS
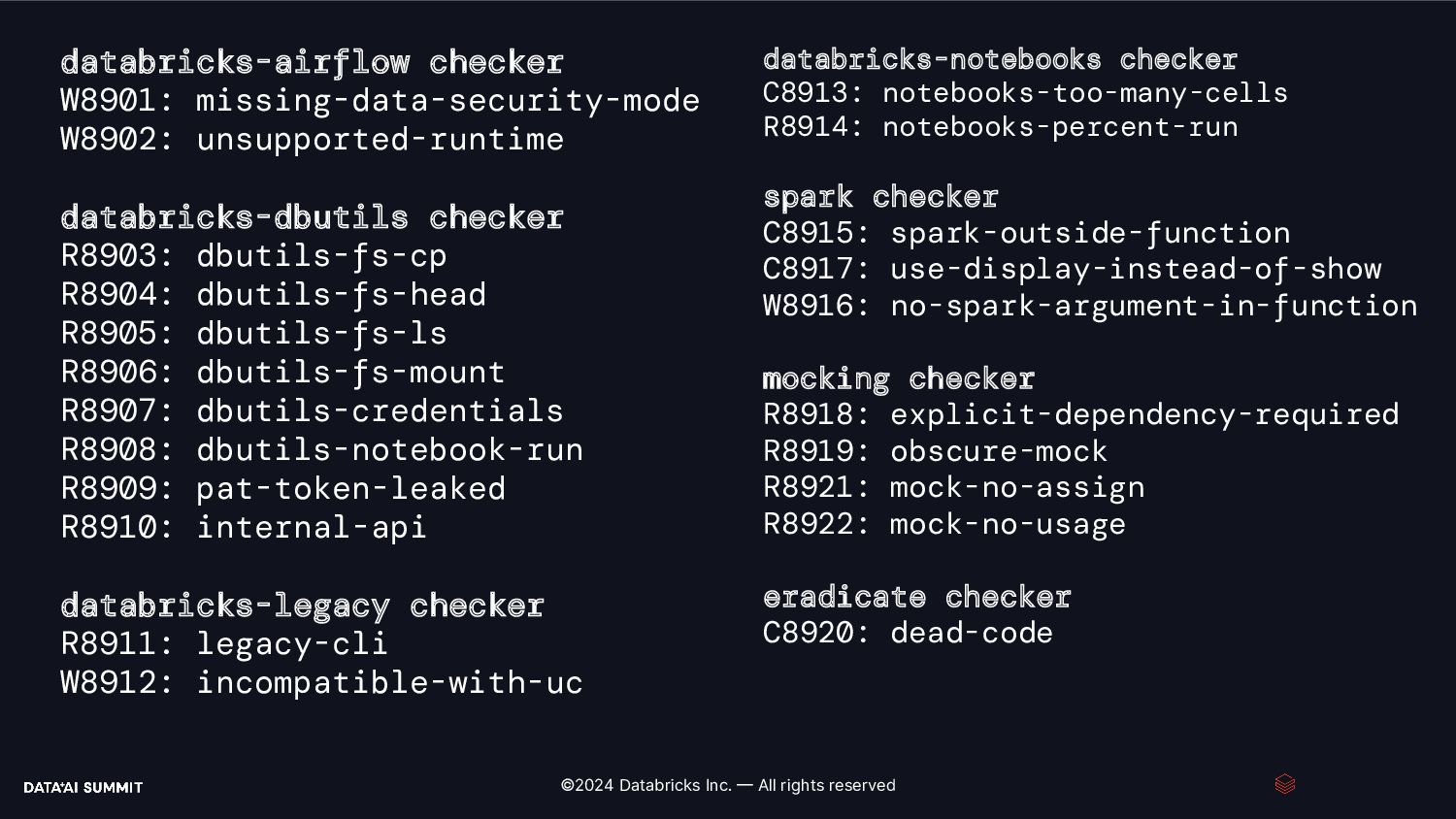
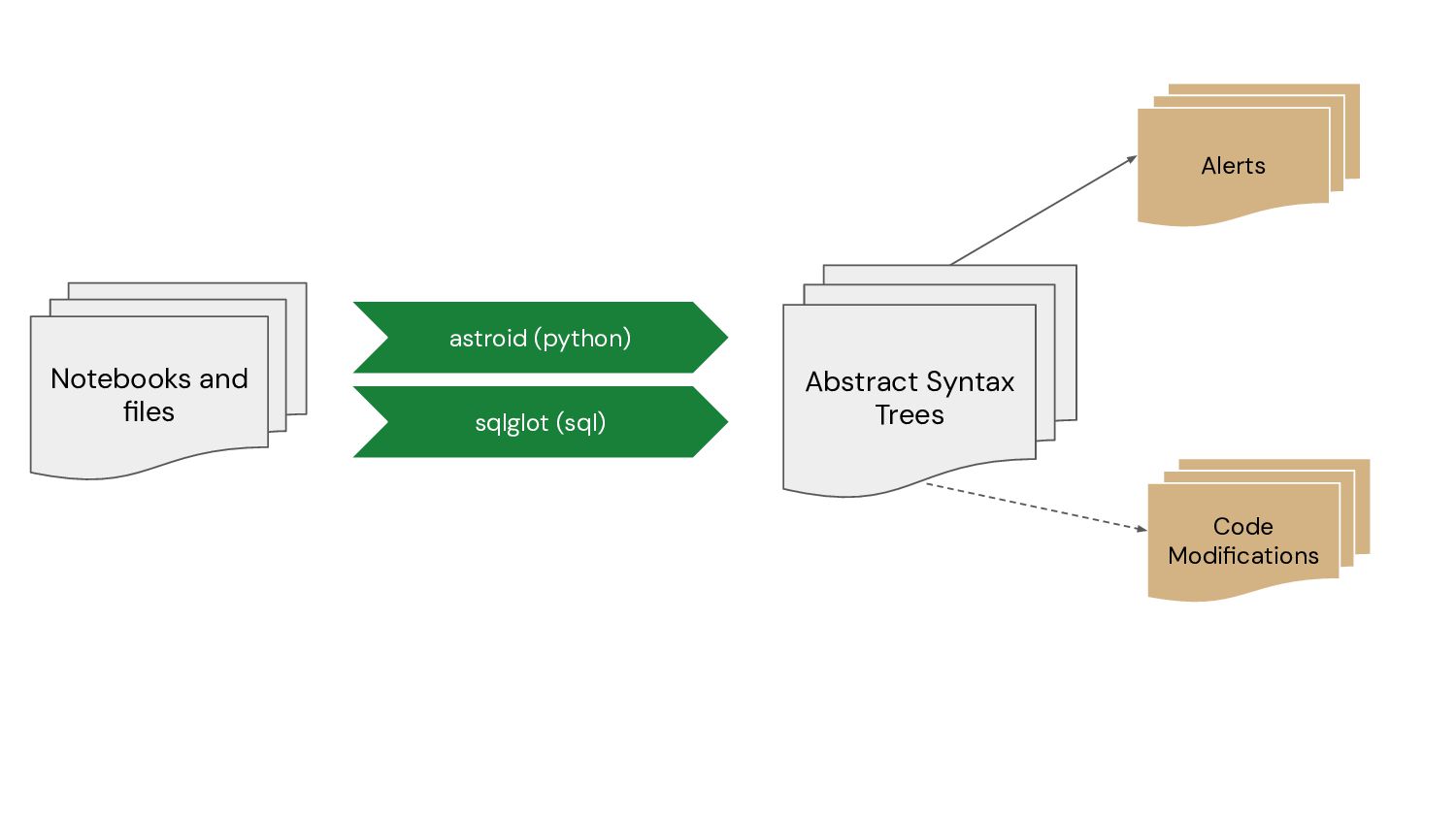
Shared Clusters dist/ioc-matching/10_discoverx_ioc_search.py:96:0: [legacy-context-in-shared-clusters] sc is not supported on UC Shared Clusters. Rewrite it using spark dist/ioc-matching/10_discoverx_ioc_search.py:97:0: [jvm-access-in-shared-clusters] Cannot access Spark Driver JVM on UC Shared Clusters dist/ioc-matching/10_discoverx_ioc_search.py:106:4: [table-migrate] Can't migrate 'saveAsTable' because its table name argument is not a constant dist/ioc-matching/10_discoverx_ioc_search.py:106:4: [table-migrate] The default format changed in Databricks Runtime 8.0, from Parquet to Delta dist/ioc-matching/10_discoverx_ioc_search.py:118:8: [table-migrate] Can't migrate table_name argument in 'spark.sql(sql_str)' because its value cannot be computed dist/campaign-effectiveness/_resources/00-setup.py:66:2: [table-migrate] Can't migrate table_name argument in 'spark.sql(f'DROP DATABASE IF EXISTS {dbName} CASCADE')' because its value cannot be computed dist/campaign-effectiveness/_resources/00-setup.py:70:0: [table-migrate] Can't migrate table_name argument in 'spark.sql(f"create database if not exists {dbName} LOCATION '{cloud_storage_path}/tables' ")' because its value cannot be computed dist/campaign-effectiveness/01a_Identifying Campaign Effectiveness For Forecasting Foot Traffic: ETL.py:40:87: [dbfs-usage] Deprecated file system path: dbfs:/databricks-datasets/identifying-campaign-effectiveness/subway_foot_traffic/foot_traffic.csv dist/campaign-effectiveness/01a_Identifying Campaign Effectiveness For Forecasting Foot Traffic: ETL.py:64:13: [direct-filesystem-access] The use of direct filesystem references is deprecated: dbfs:/databricks-datasets/identifying-campaign-effectiveness/subway_foot_traffic/foot_traffic.csv
valuable feedback on this session. • Please take a moment to rate and share your thoughts about it. • You can conveniently provide your feedback and rating through the Mobile App. Tells us what you think What to do next? • Visit the Learning Hub Experience at Moscone West, 2nd Floor! • Take complimentary certification at the event; come by the Certified Lounge • Visit our Databricks Learning website for more training, courses and workshops! databricks.com/learn Get trained and certified • Discover more related sessions in the mobile app! • Visit the Demo Booth: Experience innovation firsthand! • More Activities: Engage and connect further at the Databricks Zone! Databricks Events App
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@retried(on=[NotFound, Unknown, InvalidParameterValue], timeout=timedelta(minutes=20)) def test_running_real_assessment_job ( ws, new_installation, make_ucx_group,](https://files.speakerdeck.com/presentations/47d4c63936d24991863f8405895056e8/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![63 dist/ioc-matching/10_discoverx_ioc_search.py:96:0: [jvm-access-in-shared-clusters] Cannot access Spark Driver JVM on UC](https://files.speakerdeck.com/presentations/47d4c63936d24991863f8405895056e8/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}