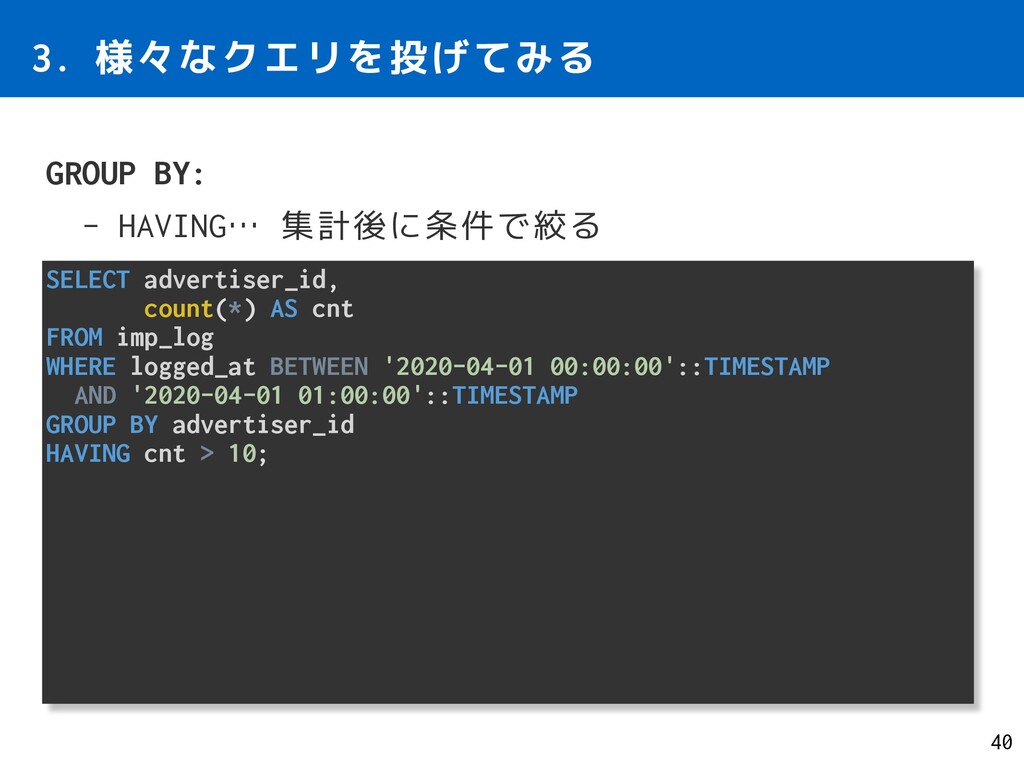
count(*) AS cnt FROM imp_log WHERE logged_at BETWEEN '2020-04-01 00:00:00'::TIMESTAMP AND '2020-04-01 01:00:00'::TIMESTAMP GROUP BY advertiser_id HAVING cnt > 10;
( SELECT * FROM imp_log WHERE imp.logged_at >= '2020-04-01 00:00:00' AND imp.logged_at < '2020-04-01 01:00:00' ) imp LEFT JOIN ( SELECT * FROM click_log WHERE click.logged_at >= '2020-04-01 00:00:00' AND click.logged_at < '2020-04-01 01:00:00' ) click ON imp.transaction_id = click.transaction_id;
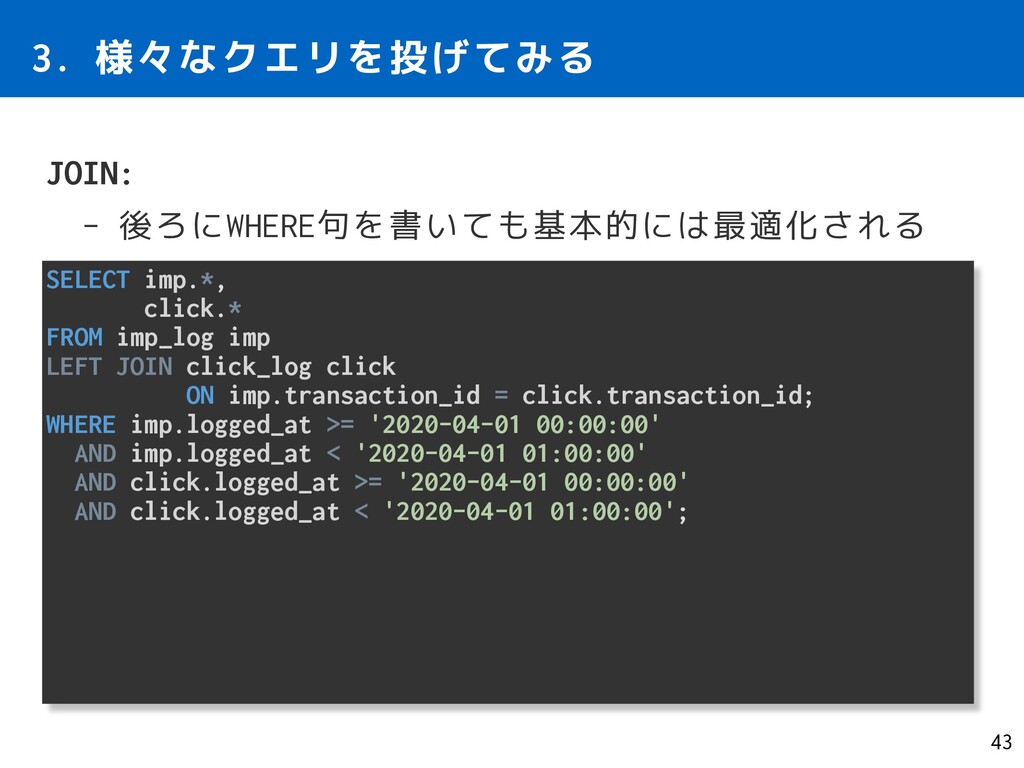
imp_log imp LEFT JOIN click_log click ON imp.transaction_id = click.transaction_id; WHERE imp.logged_at >= '2020-04-01 00:00:00' AND imp.logged_at < '2020-04-01 01:00:00' AND click.logged_at >= '2020-04-01 00:00:00' AND click.logged_at < '2020-04-01 01:00:00';
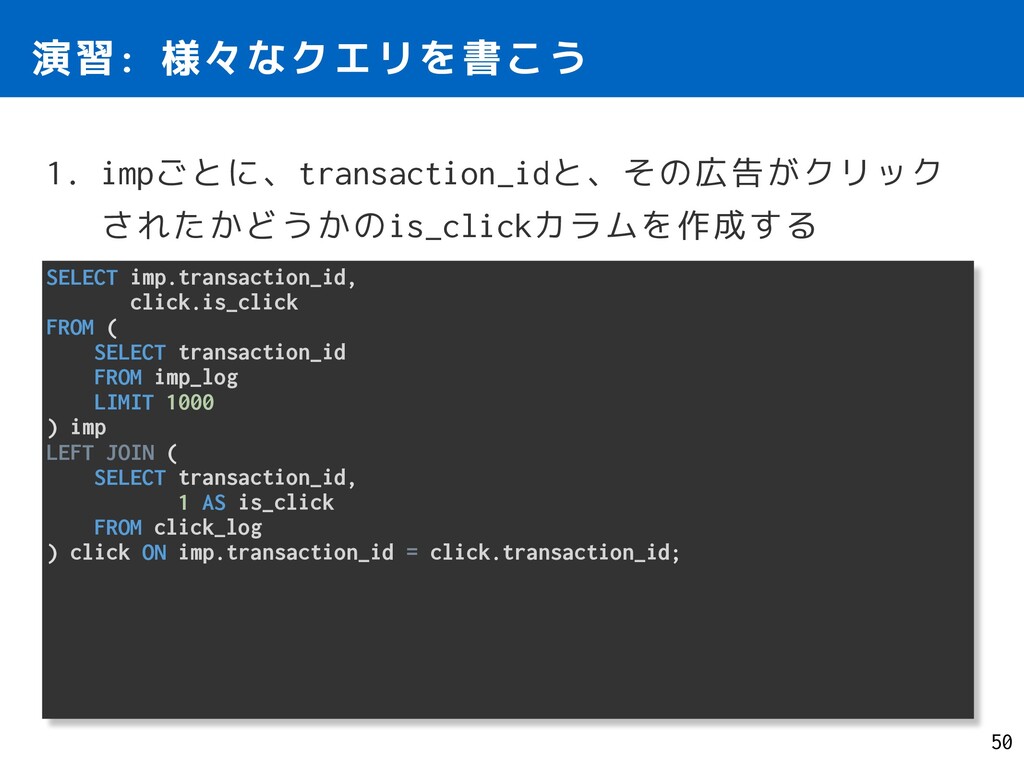
( SELECT transaction_id FROM imp_log LIMIT 1000 ) imp LEFT JOIN ( SELECT transaction_id, 1 AS is_click FROM click_log ) click ON imp.transaction_id = click.transaction_id;
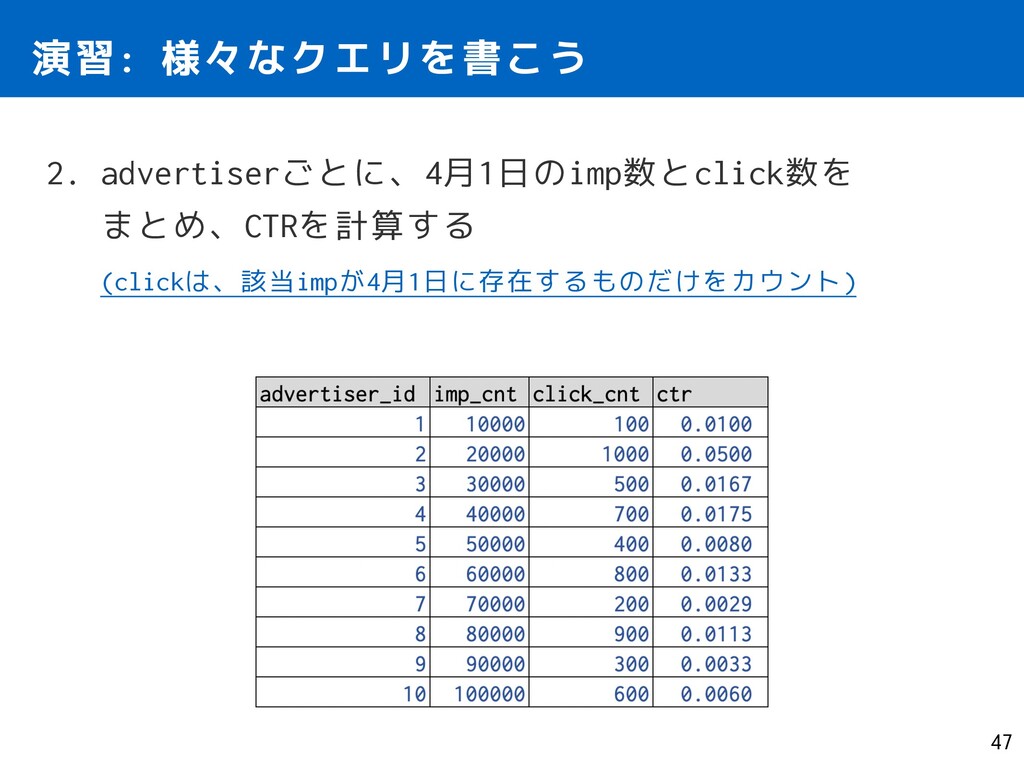
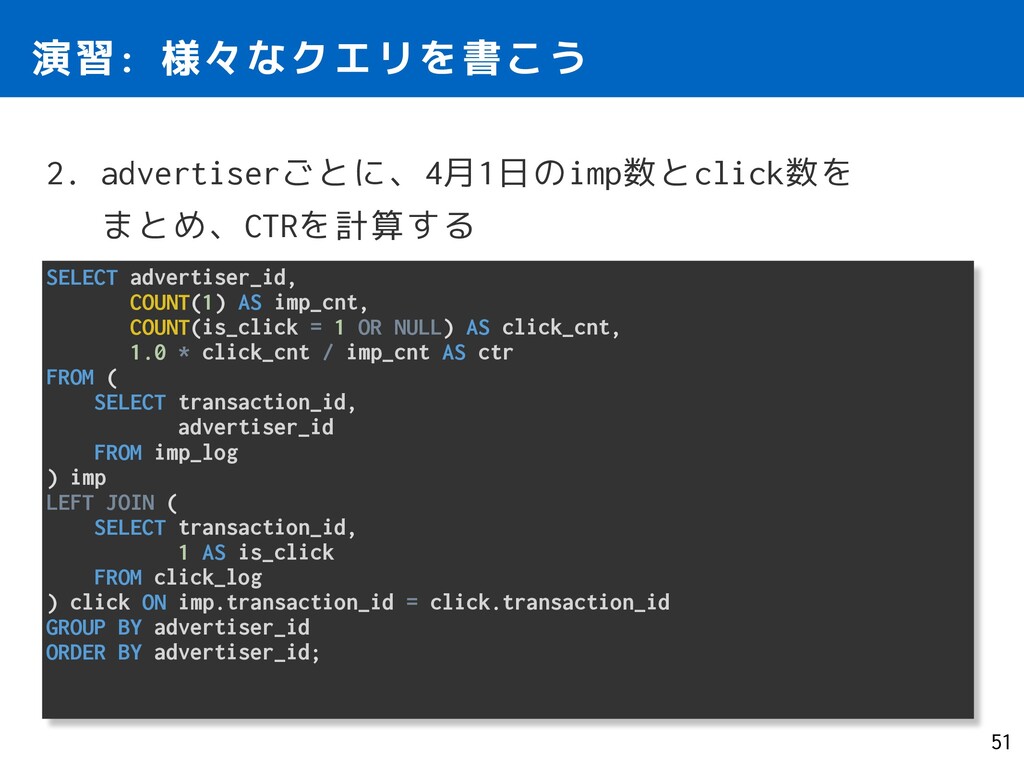
1 OR NULL) AS click_cnt, 1.0 * click_cnt / imp_cnt AS ctr FROM ( SELECT transaction_id, advertiser_id FROM imp_log ) imp LEFT JOIN ( SELECT transaction_id, 1 AS is_click FROM click_log ) click ON imp.transaction_id = click.transaction_id GROUP BY advertiser_id ORDER BY advertiser_id; 演習: 様々なクエリを書こう 51
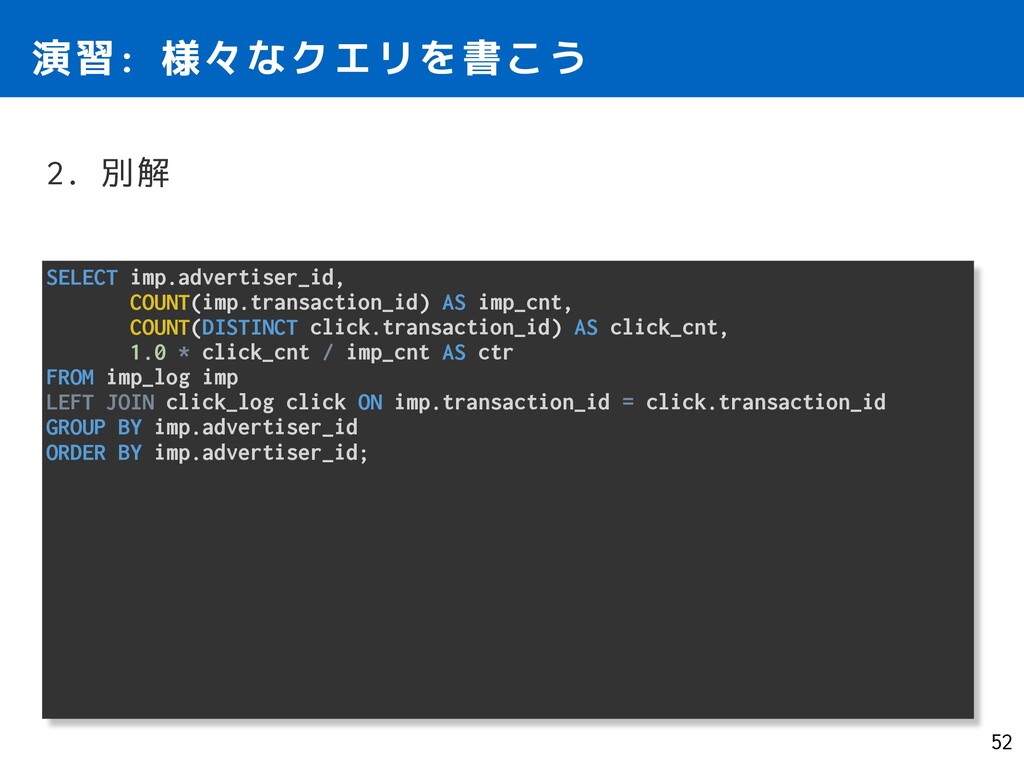
click_cnt, 1.0 * click_cnt / imp_cnt AS ctr FROM imp_log imp LEFT JOIN click_log click ON imp.transaction_id = click.transaction_id GROUP BY imp.advertiser_id ORDER BY imp.advertiser_id; 演習: 様々なクエリを書こう 52
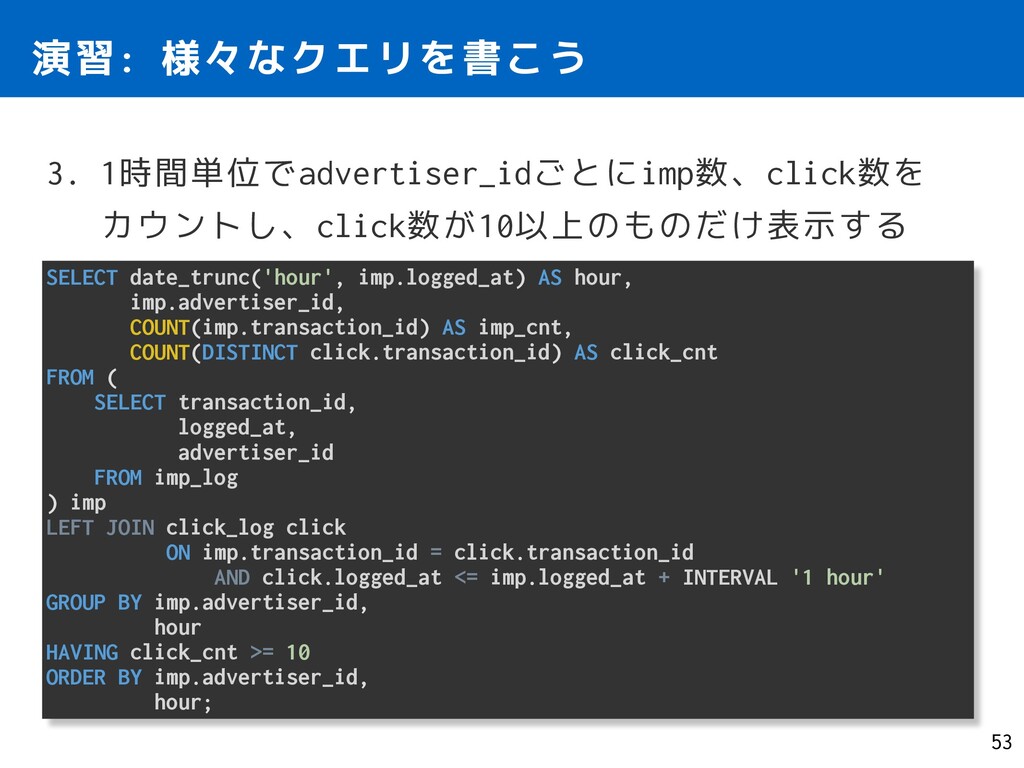
hour, imp.advertiser_id, COUNT(imp.transaction_id) AS imp_cnt, COUNT(DISTINCT click.transaction_id) AS click_cnt FROM ( SELECT transaction_id, logged_at, advertiser_id FROM imp_log ) imp LEFT JOIN click_log click ON imp.transaction_id = click.transaction_id AND click.logged_at <= imp.logged_at + INTERVAL '1 hour' GROUP BY imp.advertiser_id, hour HAVING click_cnt >= 10 ORDER BY imp.advertiser_id, hour;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}