Modeling data fast, slow and back-in-time: Change-aware dimensional data modeling in the modern data stack
Event: Postgres Ibiza 2024
Date: 9 September 2024
Location: Palacio de Congresos de Ibiza, Santa Eulària des Riu, Ibiza, Spain
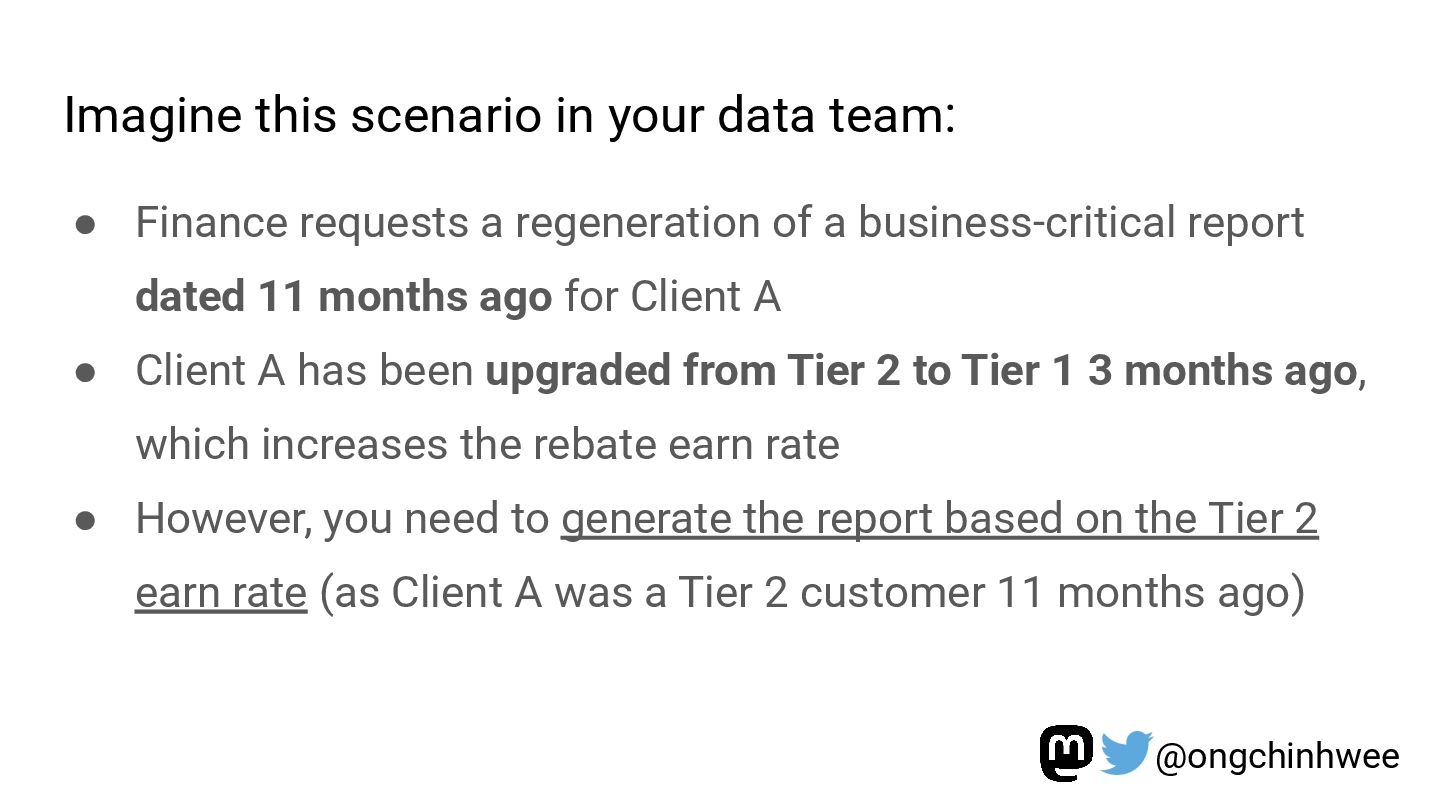
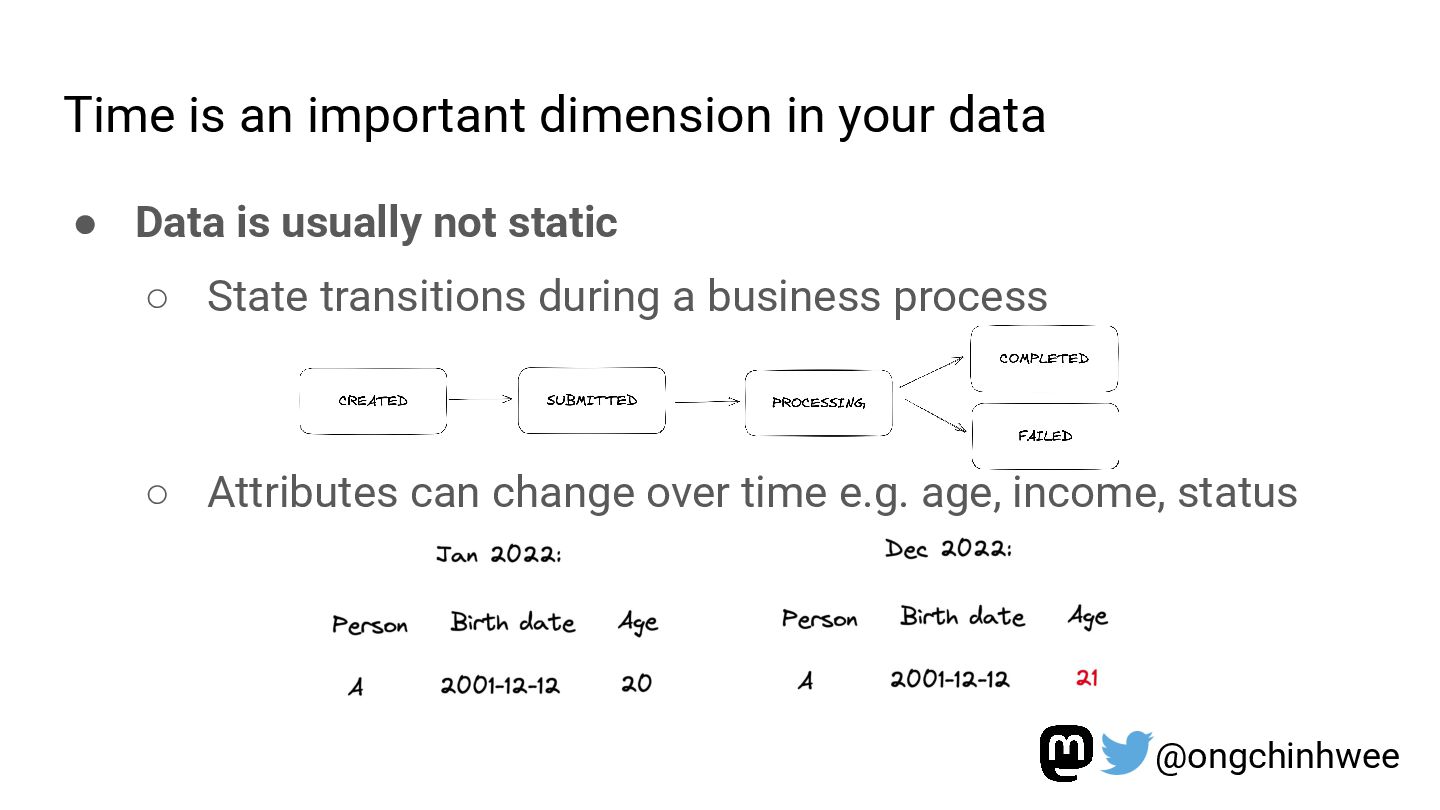
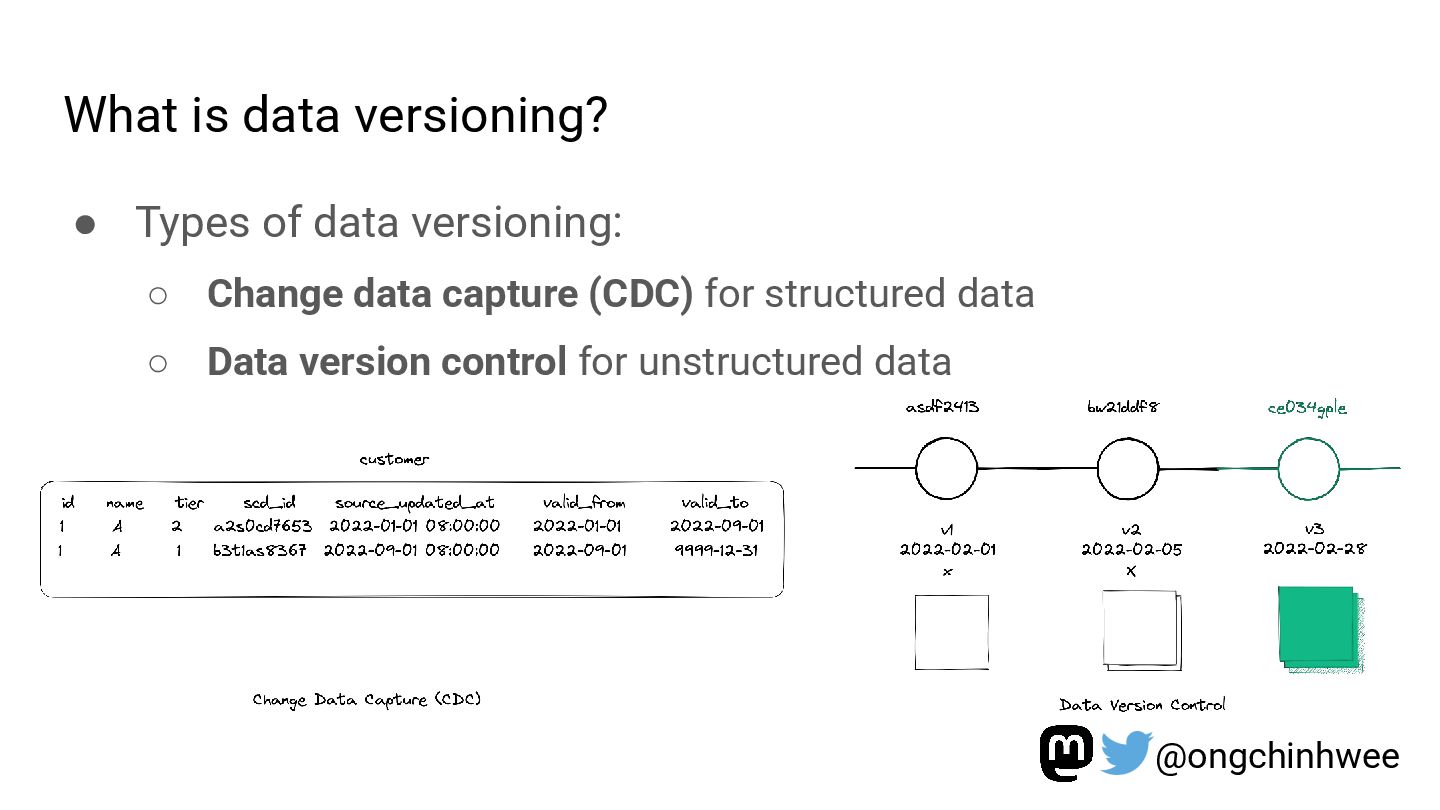
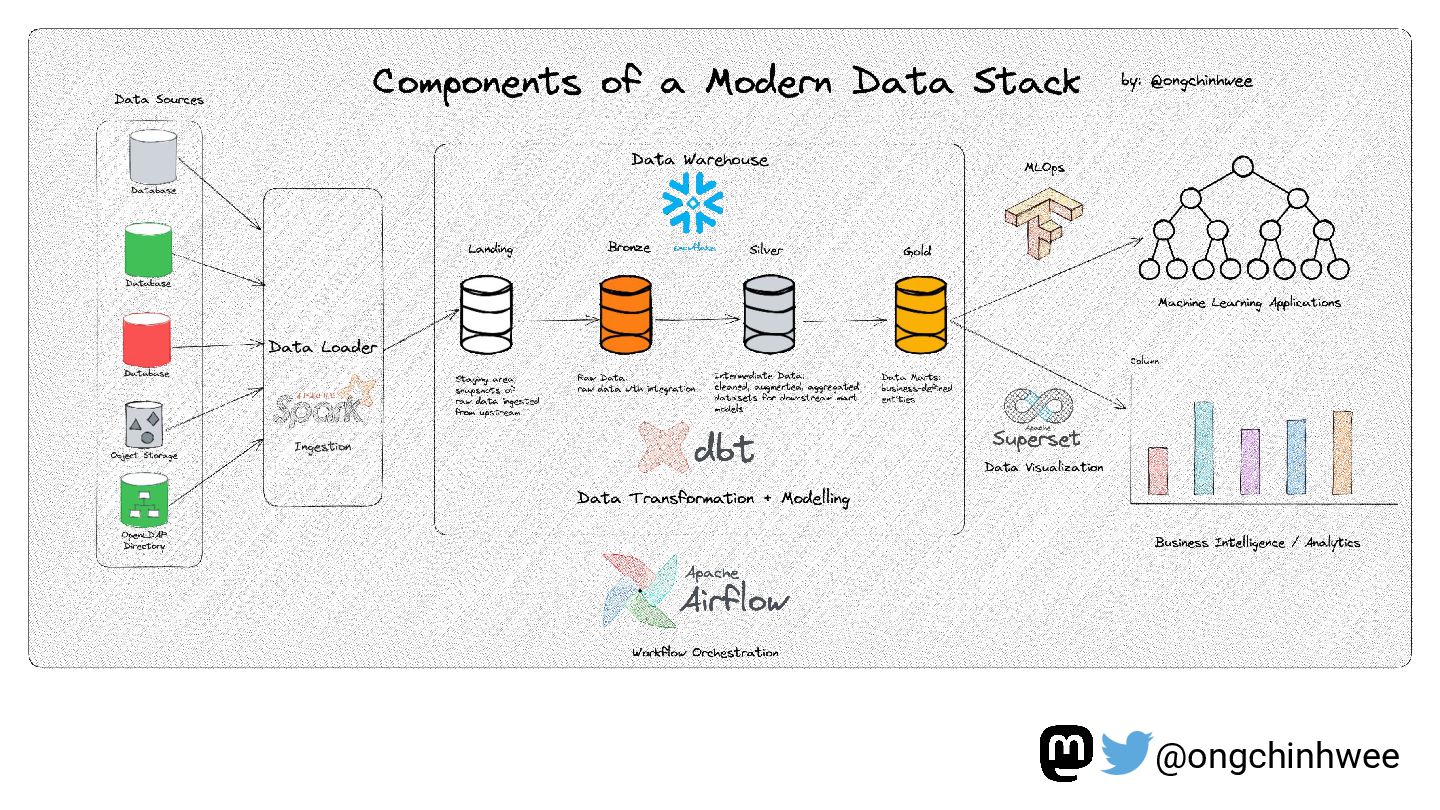
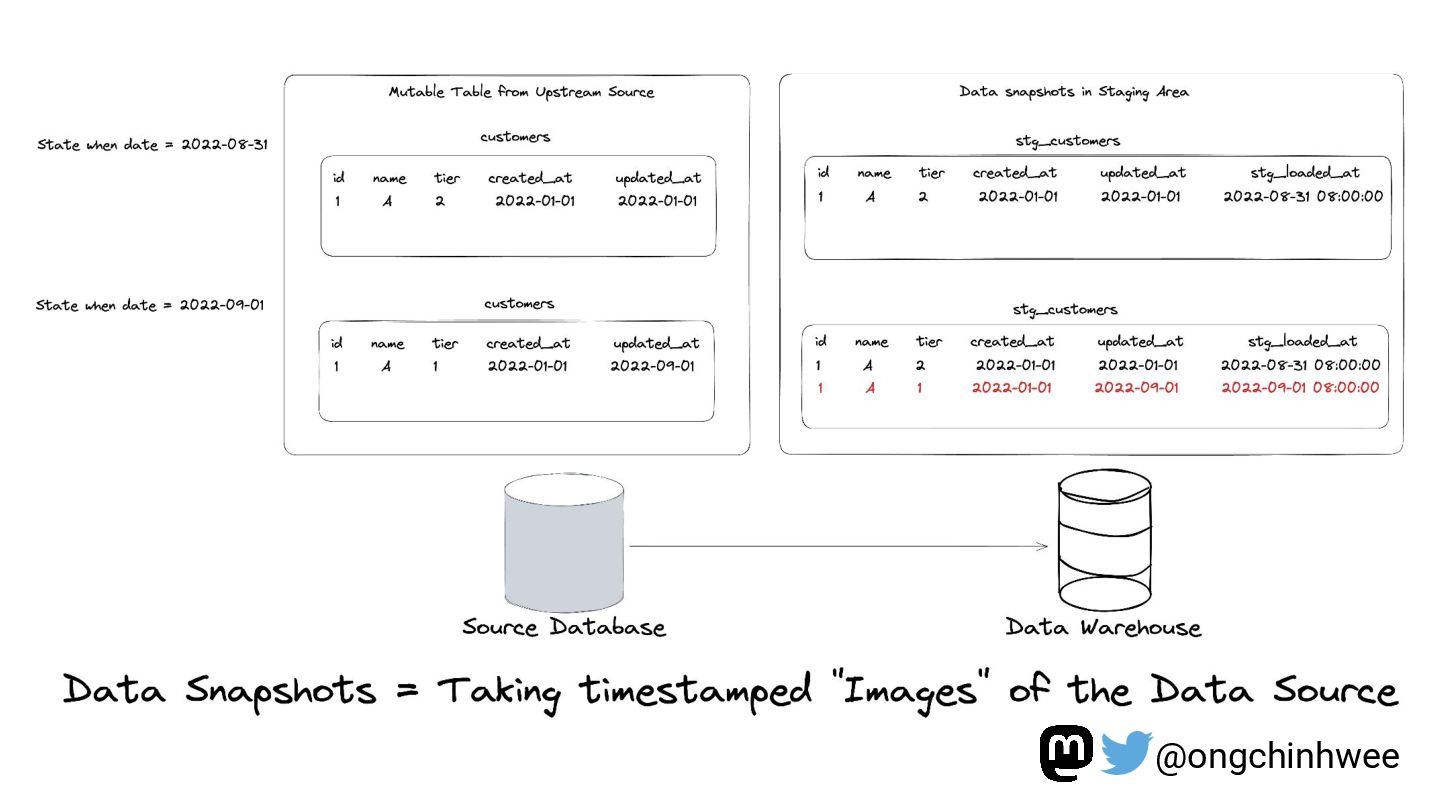
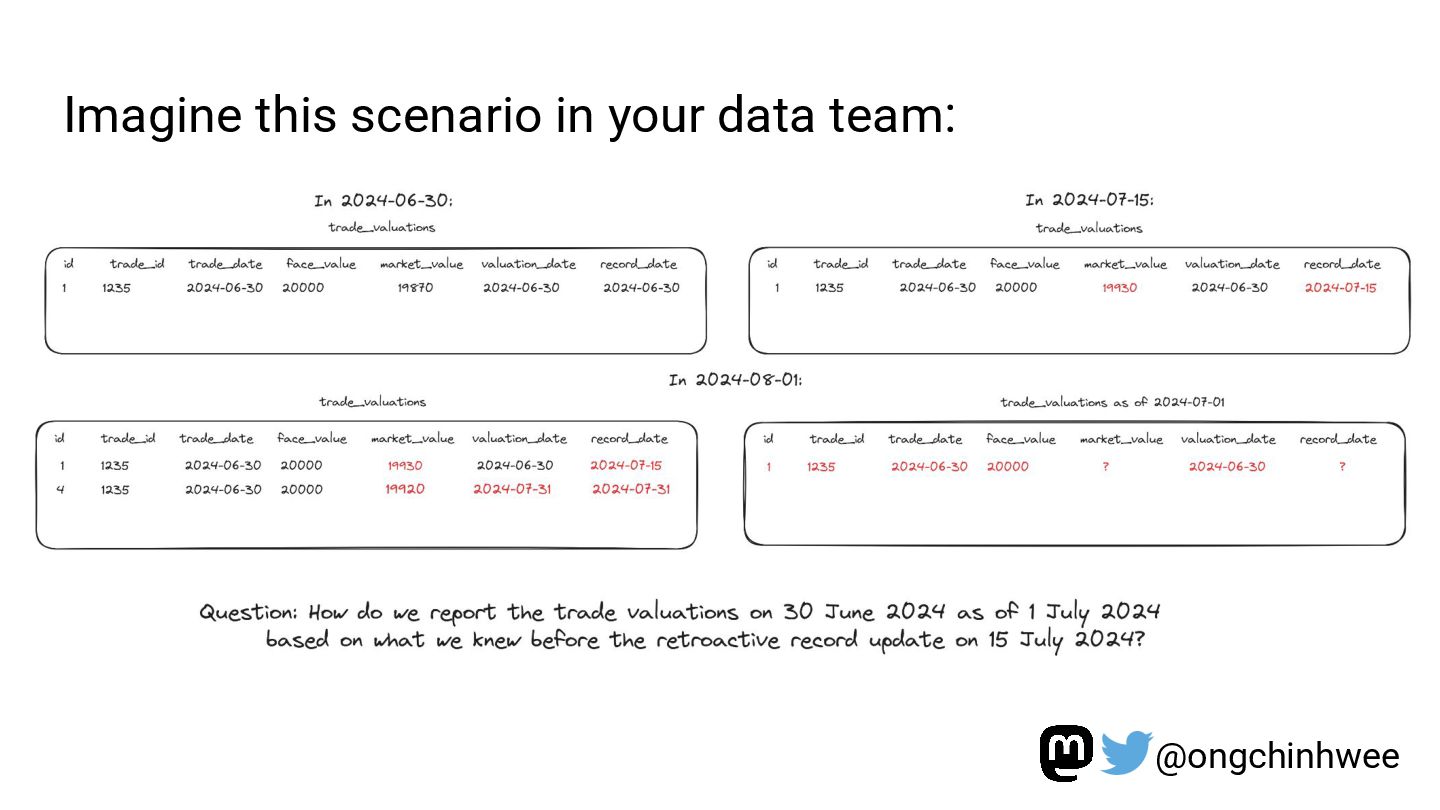
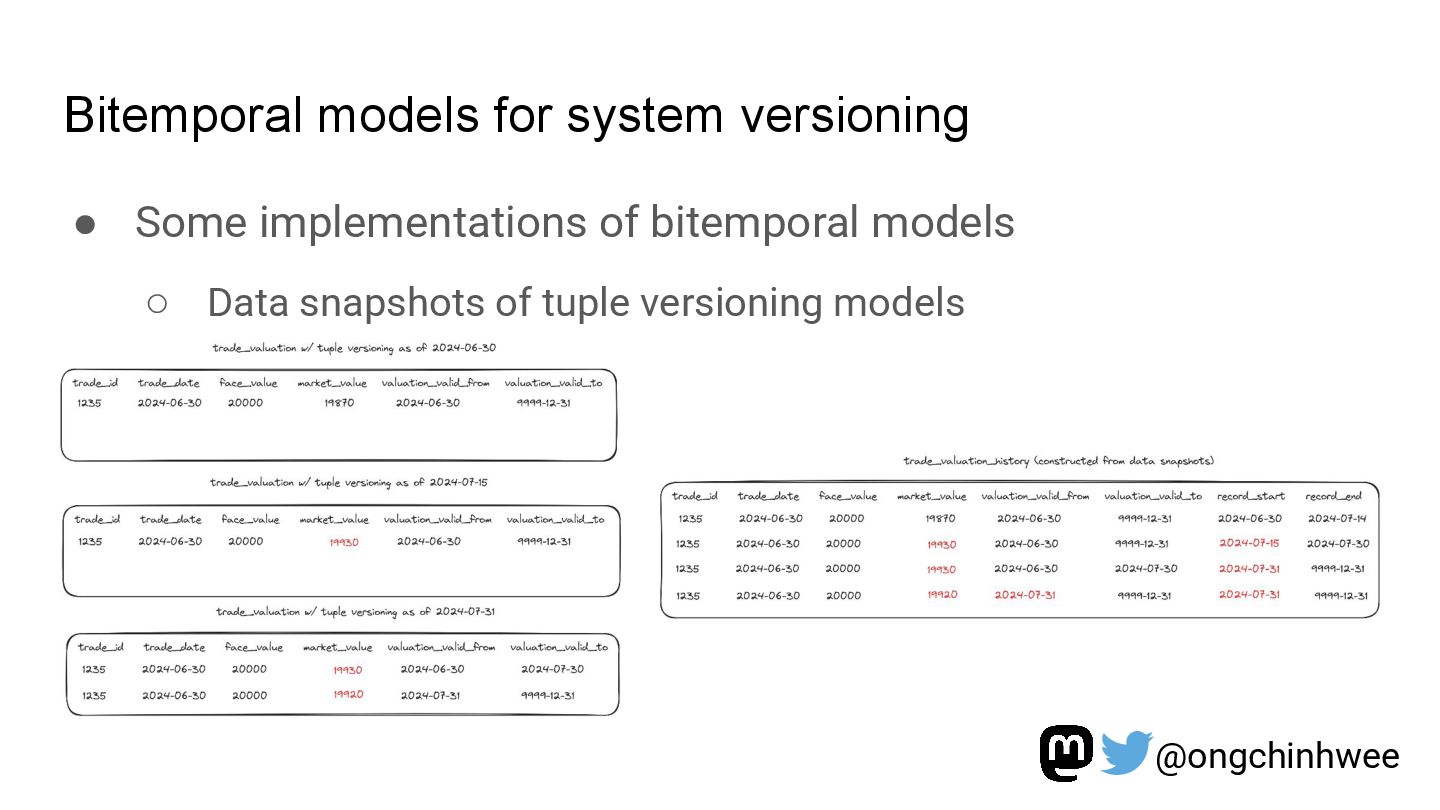
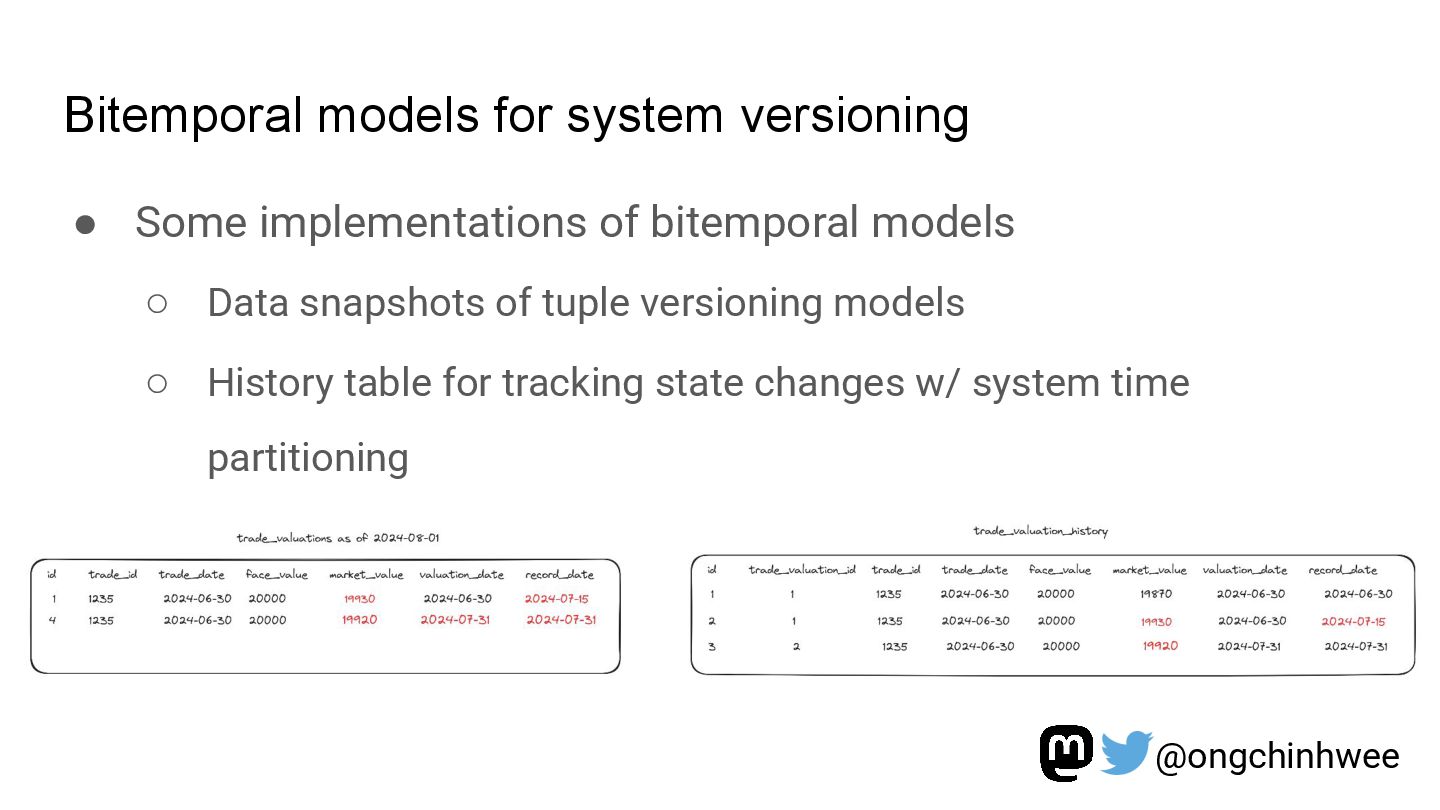
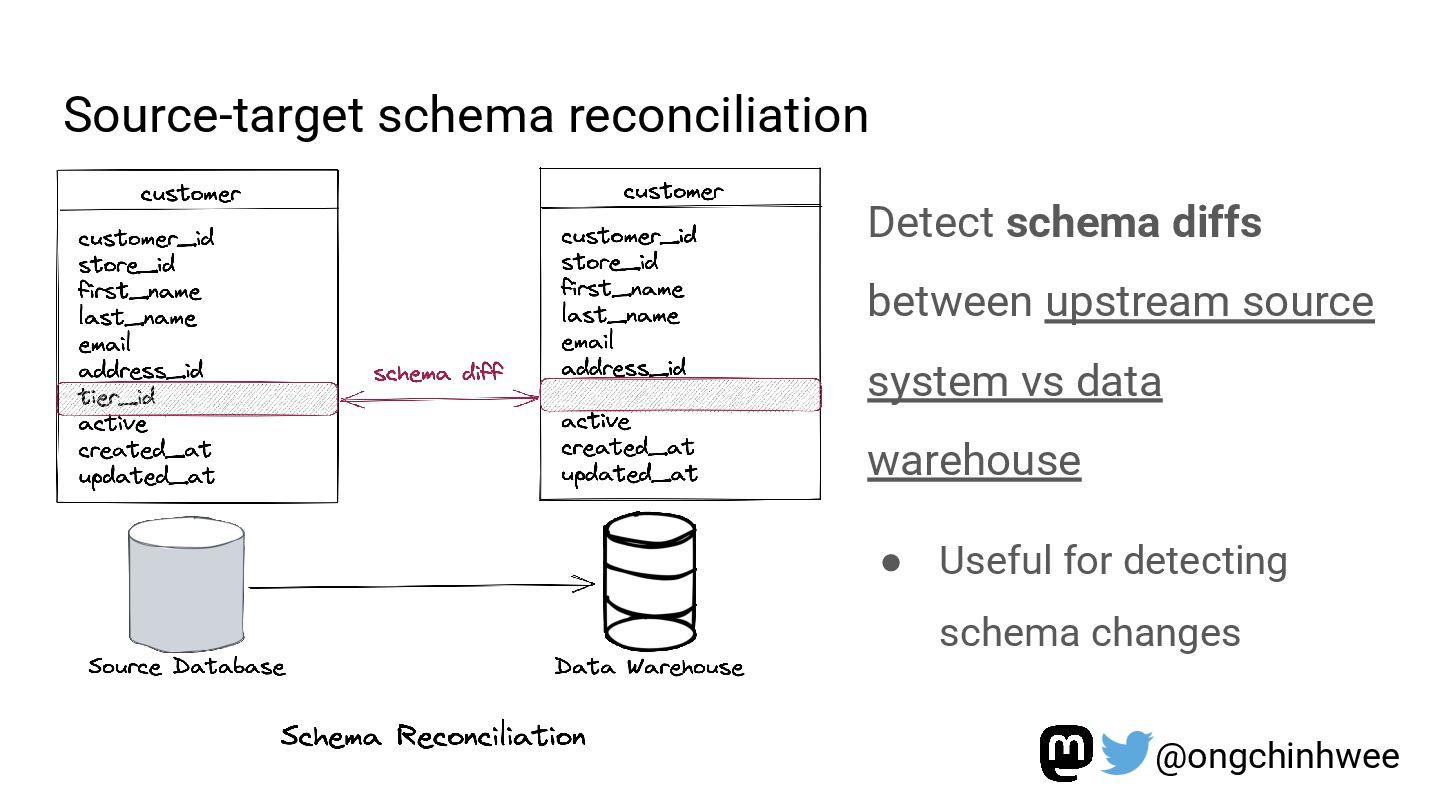
Modeling data with versioning enables data teams to track and reproduce history for fast- and slow-changing data over time. In the era of read-optimized cloud data warehouses and ELT (Extract-Load-Transform) workflows, there is still value in integrating dimensional data modeling practices with modern functional approaches in the modern data stack to design efficient and reproducible data models for analytics reporting use cases that require accurate reporting of point-in-time historical dimensions. In this talk, I will be exploring how we can design history-preserving data models and reproducible data transformation workflows by adopting “change-aware” dimensional modeling practices in the modern data stack.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reach out to me! : ongchinhwee : [email protected] : @ongchinhwee](https://files.speakerdeck.com/presentations/3a27e02b1ec046faaaeb60c4ec0005ca/slide_73.jpg){kind=link}