Your Data is Late Again! Handling Late-Arriving Data in the Modern Data Stack
Event: MDS Fest 3.0
Date: 9 May 2025
Location: Online
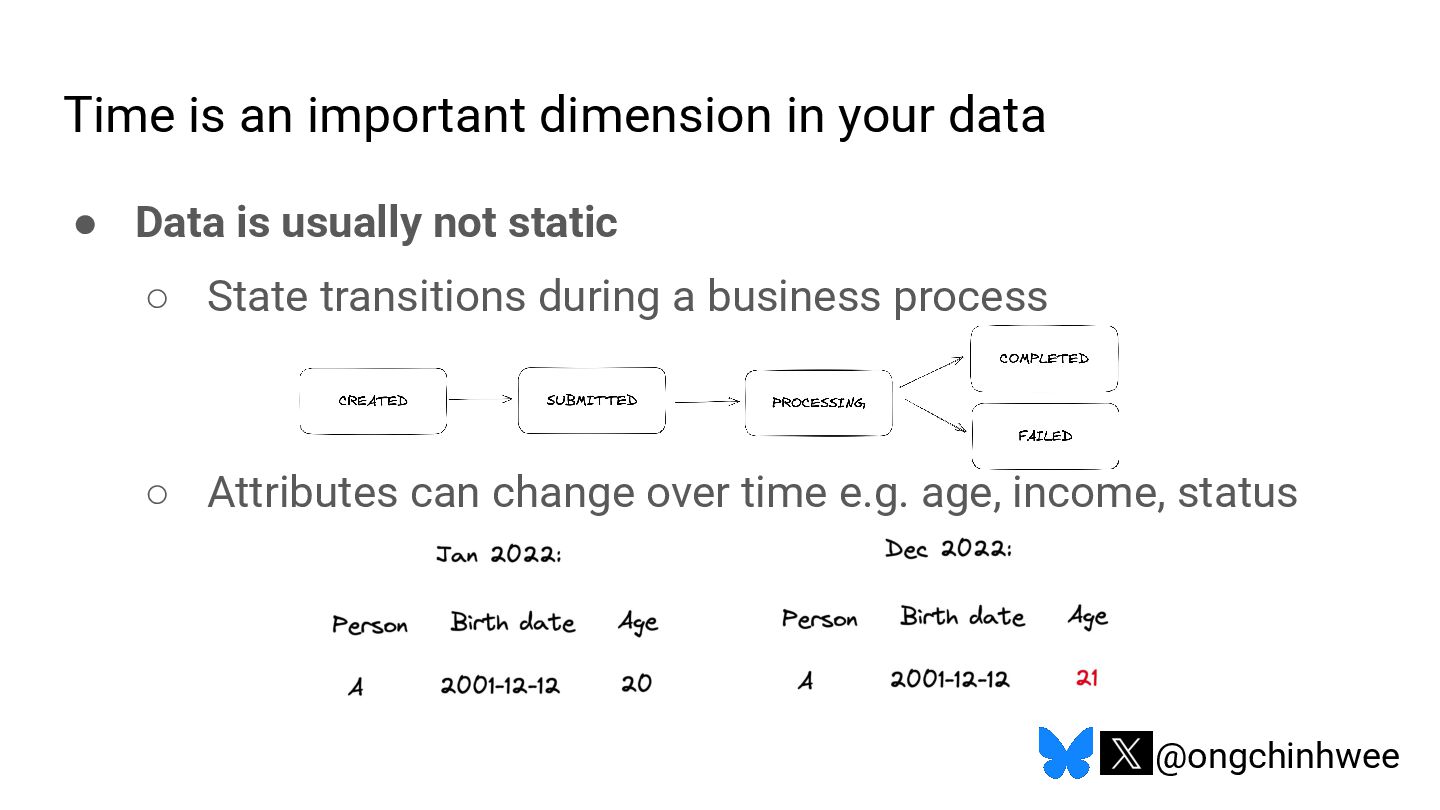
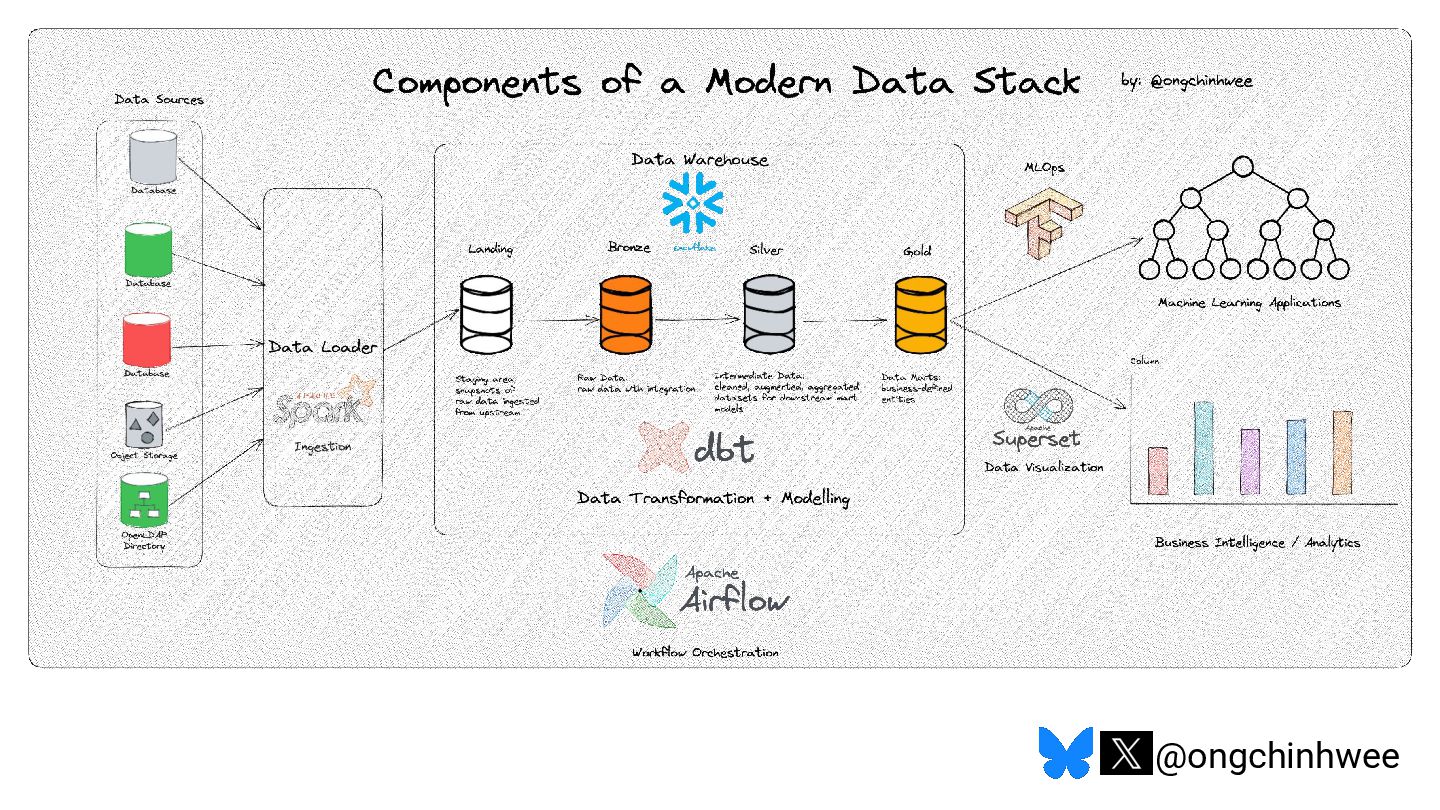
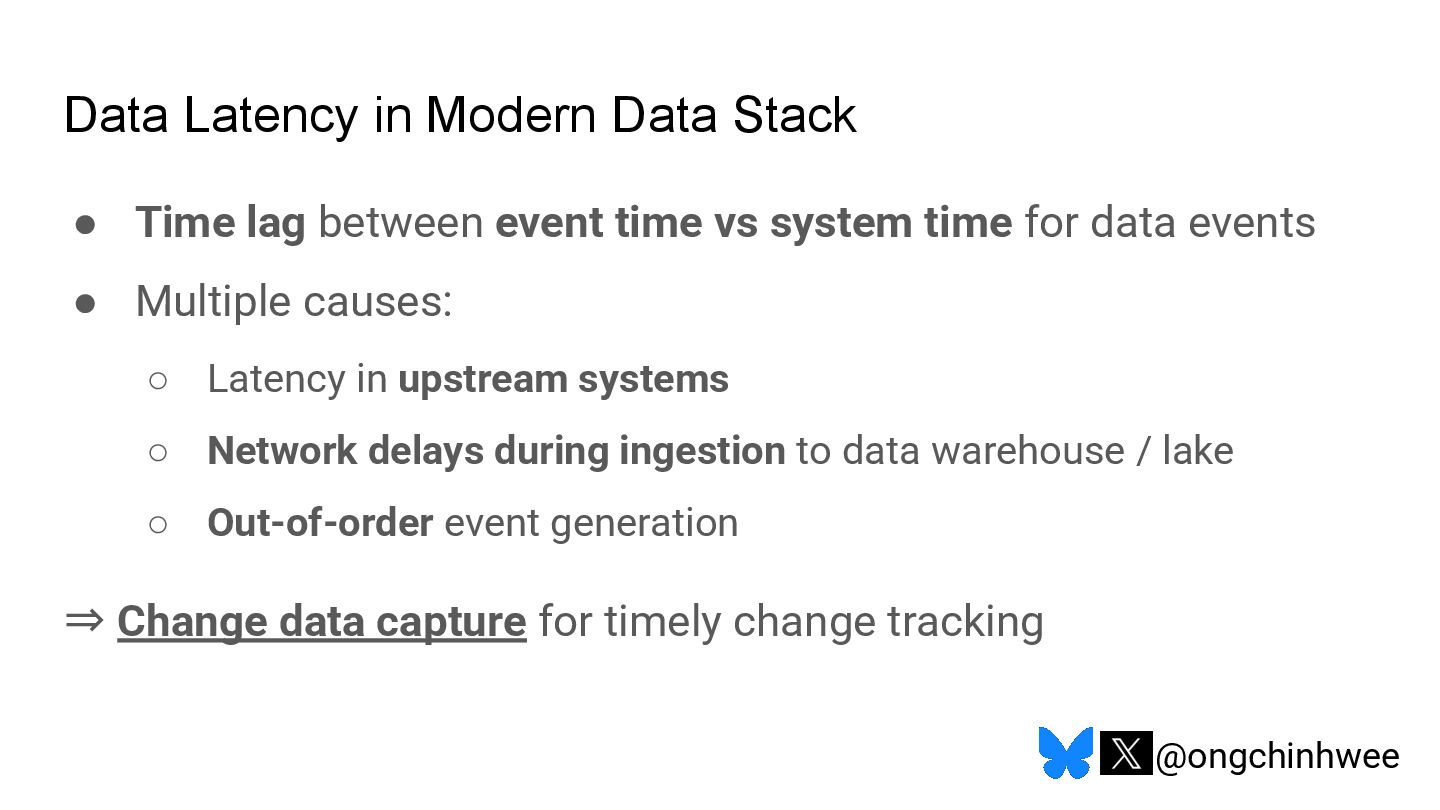
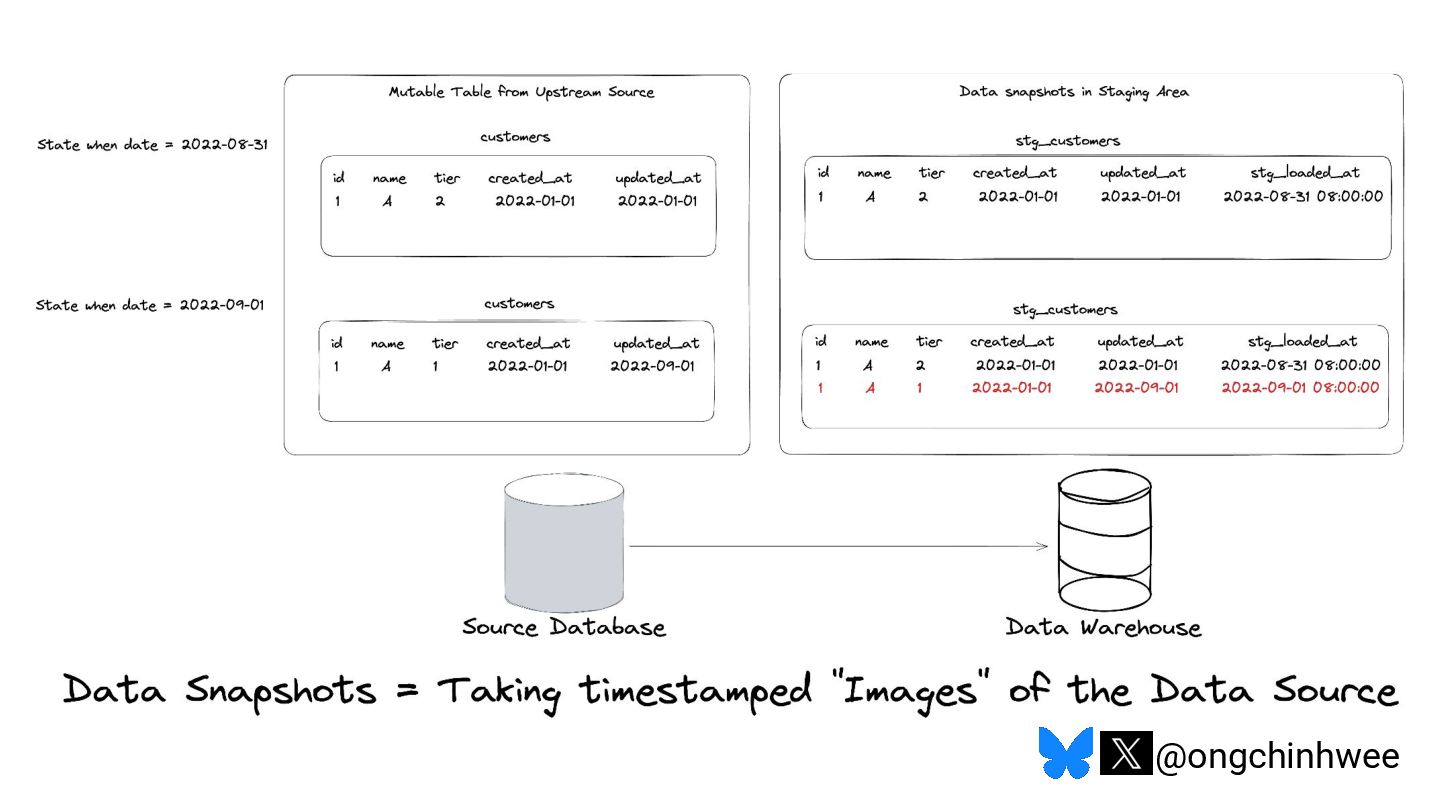
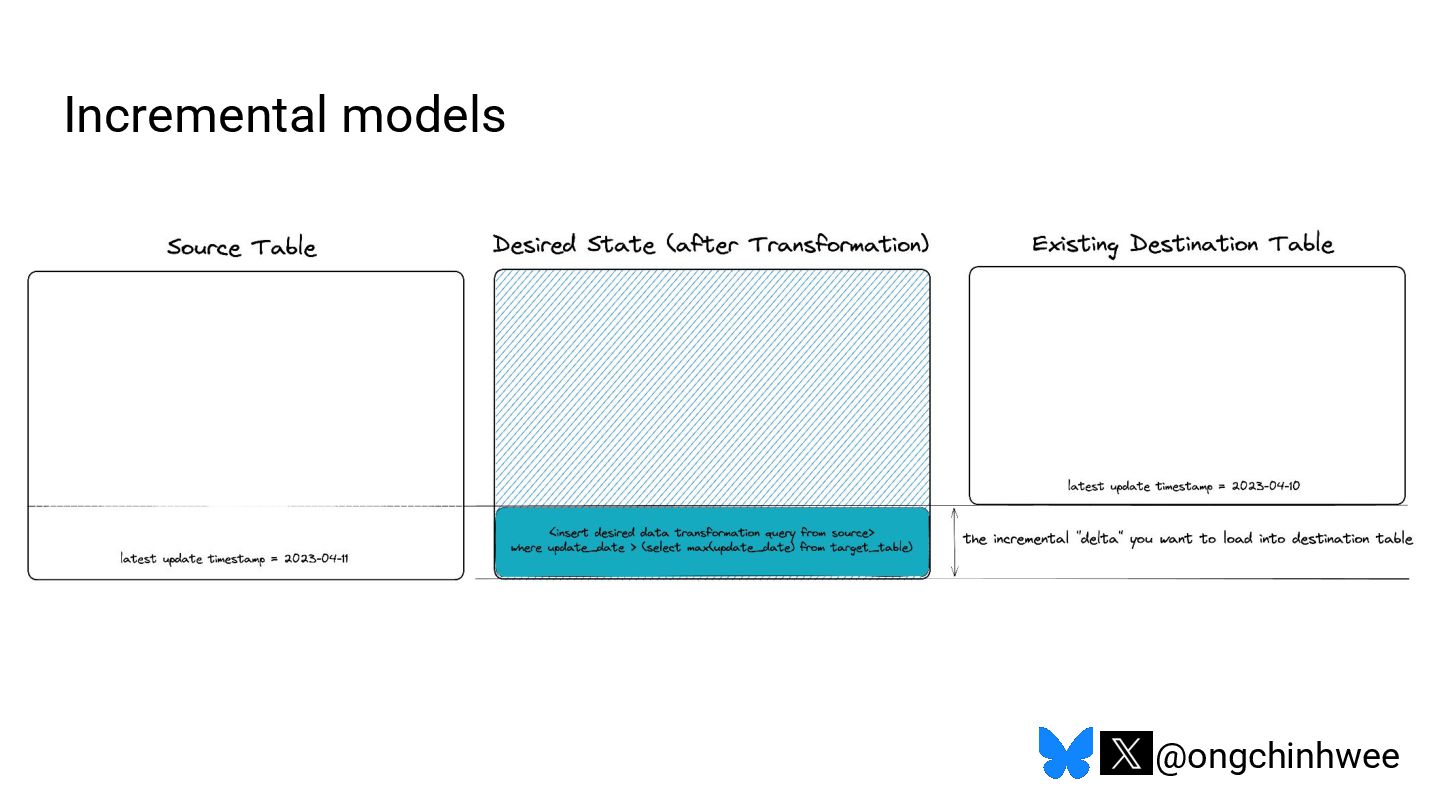
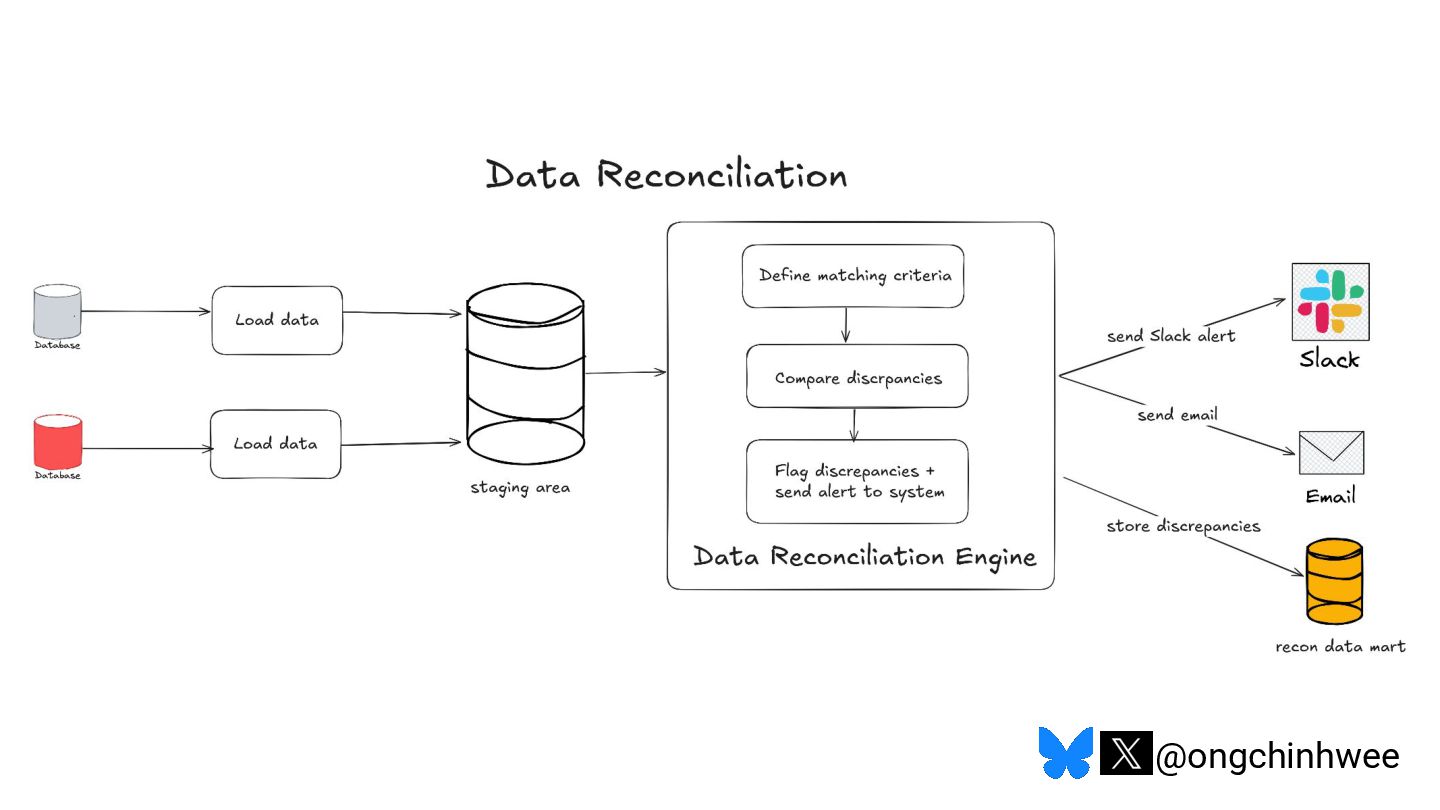
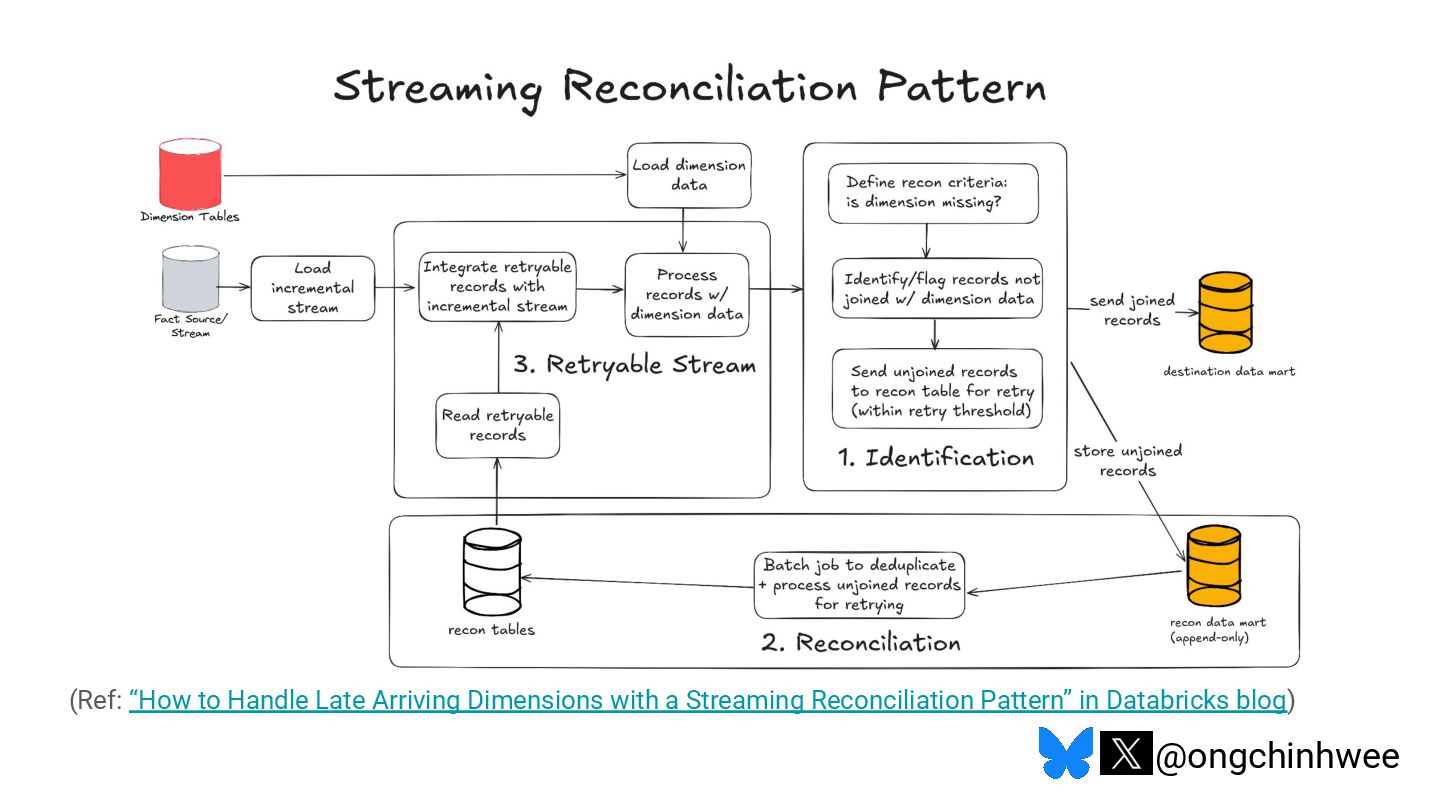
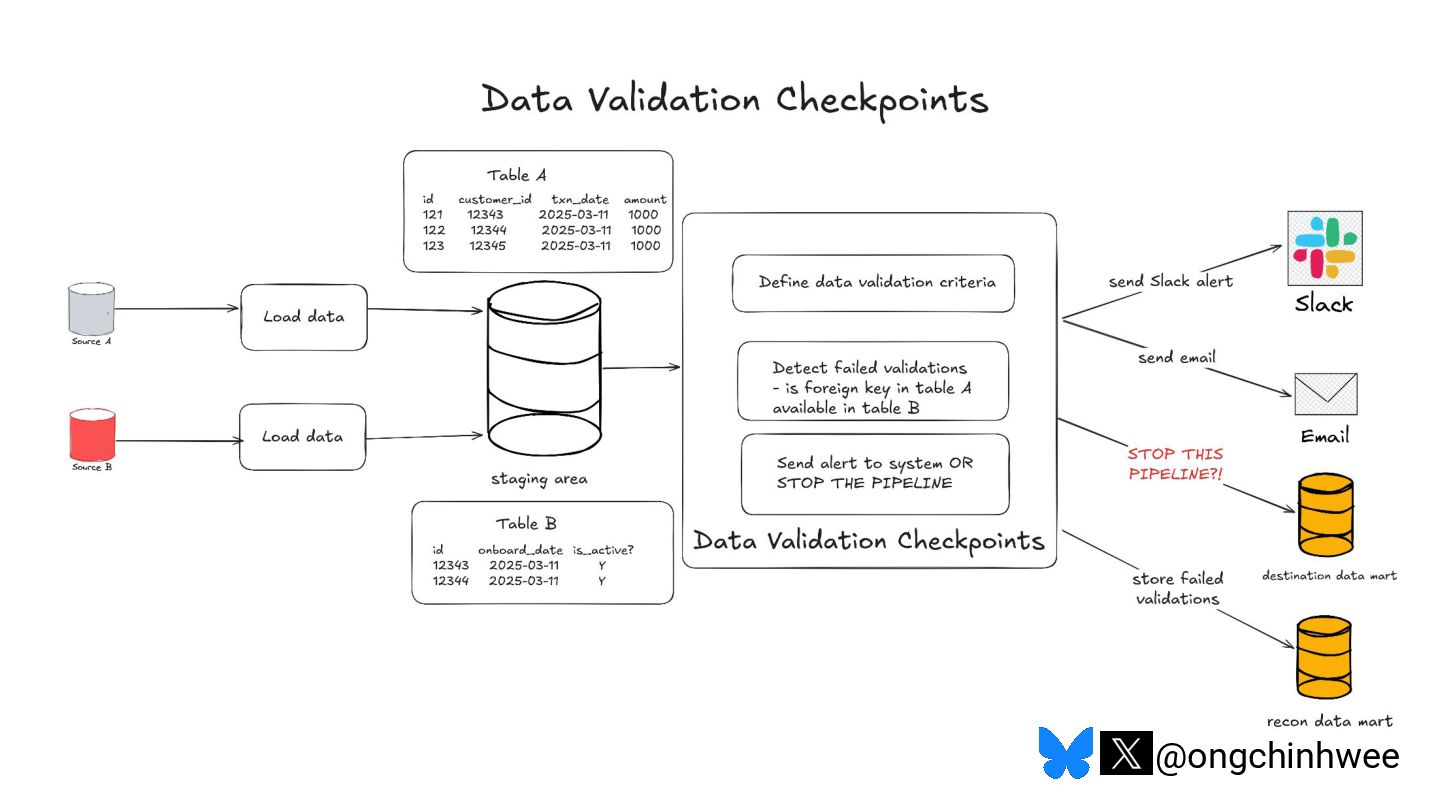
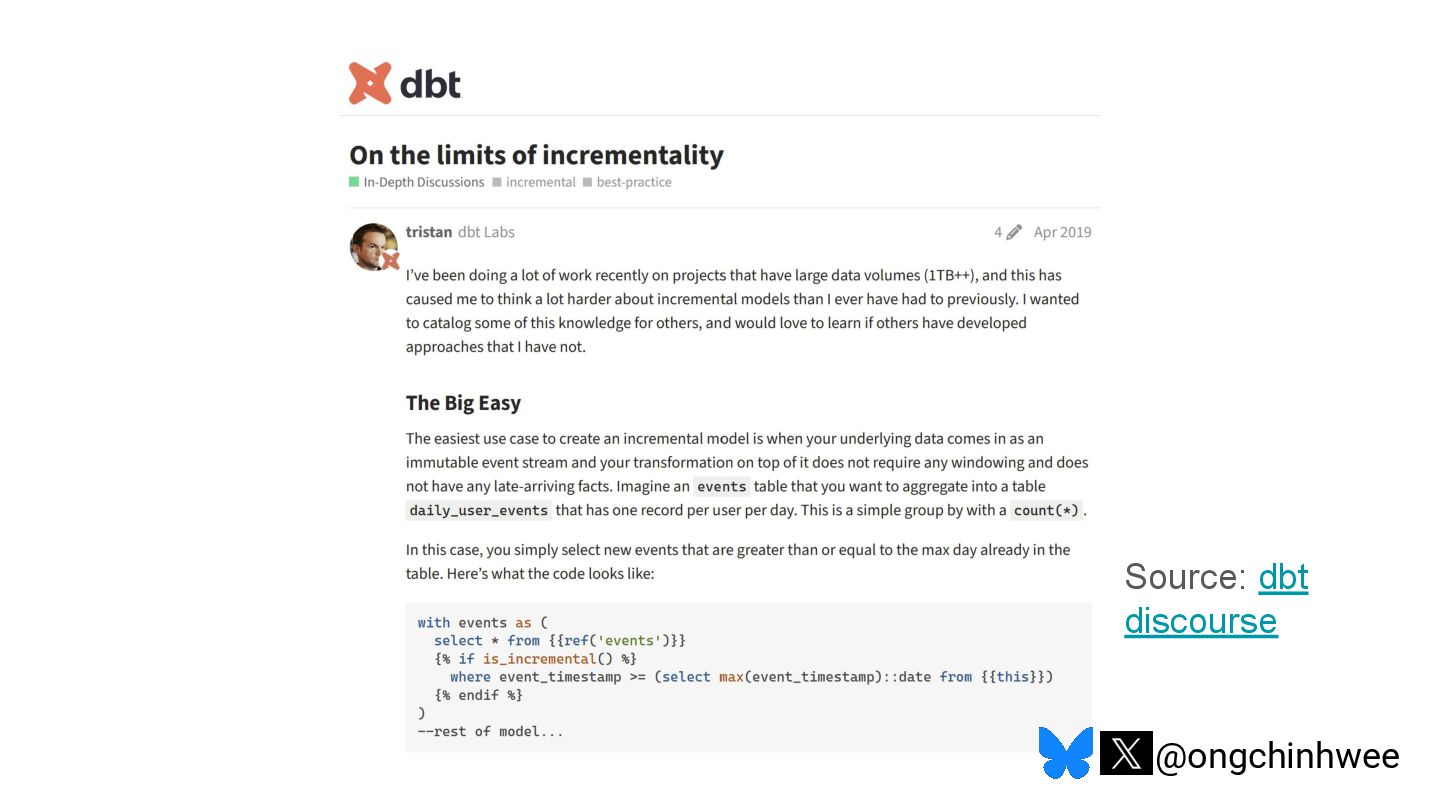
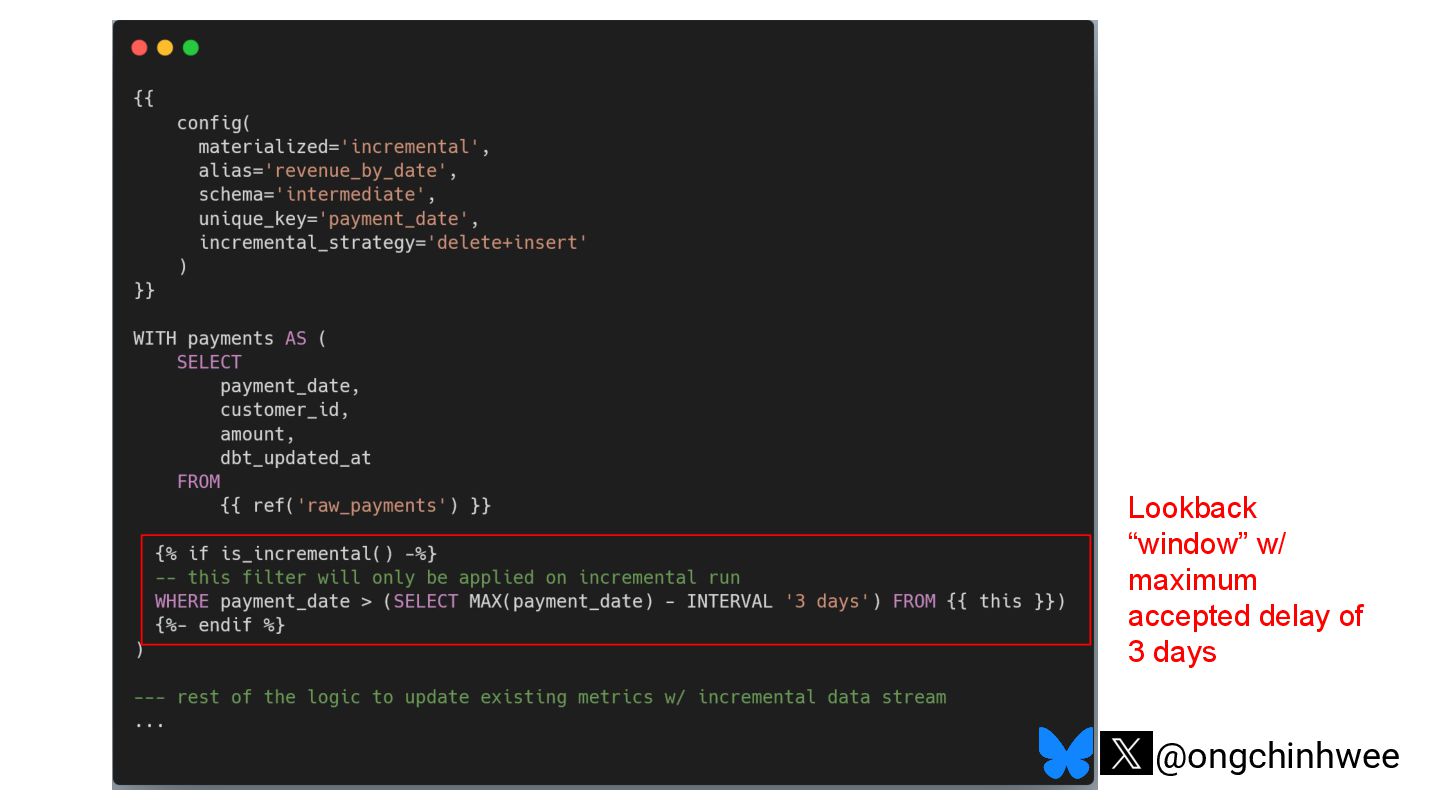
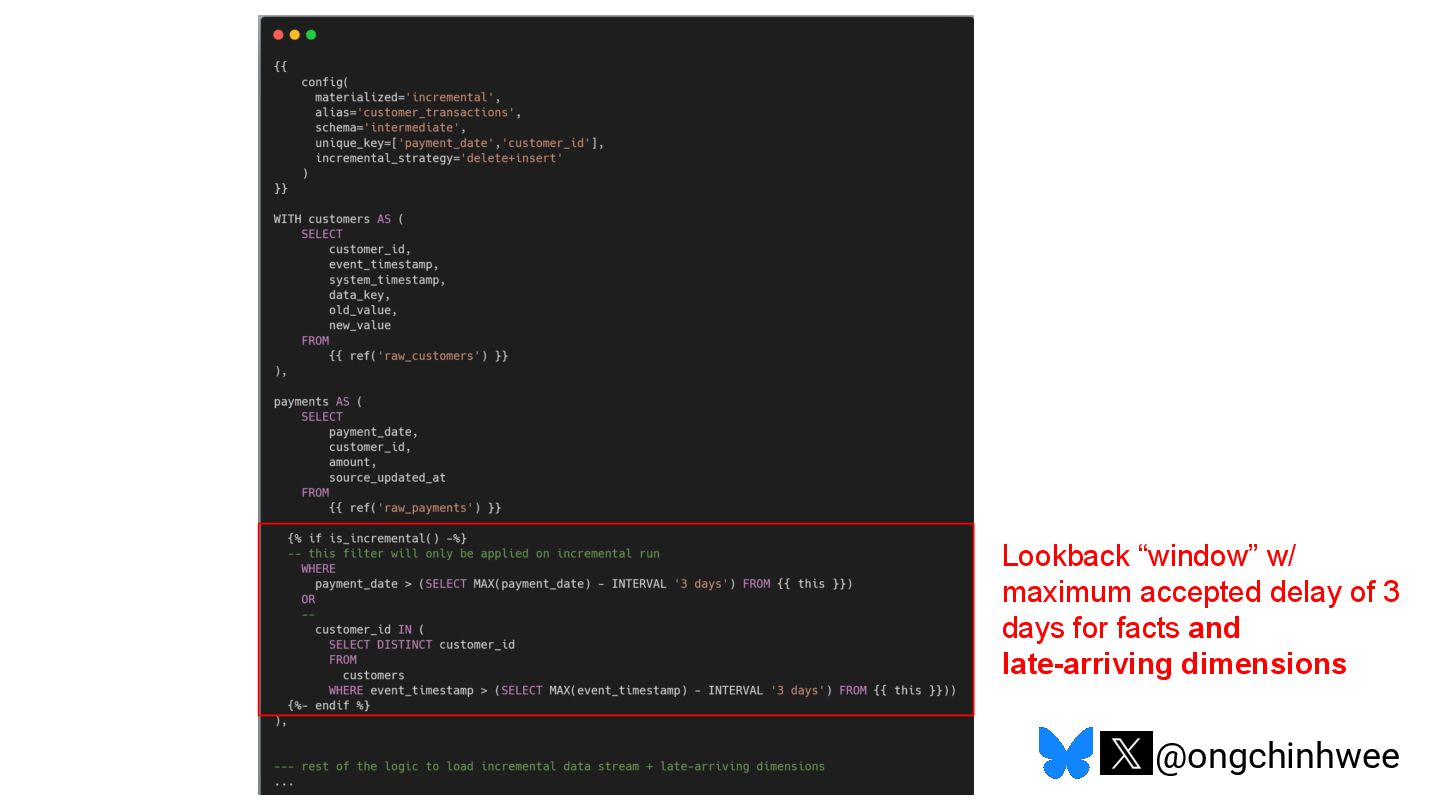
When we say we are processing the "latest" data in the data warehouse, which timestamp are we referring to? Late-arriving data can happen in data warehouses due to operational and technical reasons that may require data corrections, posing challenges in ensuring accurate reporting of point-in-time historical dimensions in the data warehouse. In this talk, I will be exploring approaches on how we can design data systems and history-preserving data models that can handle late-arriving data in the modern data stack.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}