User Question Search [101]: Name: TrekExtreme Hiking Shoes Price: 135.99 Brand: Raptor Elite Type: Footwear Description: The Trek Extreme hiking shoes by Raptor Elite are built to ensure any trail. … Large Language Model For great hiking shoes, consider the TrekExtreme Hiking Shoes1 or the Trailblaze Steel-Blue Hiking Shoes2
a mountain trale? User Question Large Language Model Mountain trail shoe Search [101]: Name: TrekExtreme Hiking Shoes Price: 135.99 Brand: Raptor Elite Type: Footwear Description: The Trek Extreme hiking shoes by Raptor Elite are built to ensure any trail. … Large Language Model For great hiking shoes, consider the TrekExtreme Hiking Shoes1 or the Trailblaze Steel-Blue Hiking Shoes2
User Question Search PerksPlus.pdf#page=2: Some of the lessons covered under PerksPlus include: · Skiing and snowboarding lessons · Scuba diving lessons · Surfing lessons · Horseback riding lessons These lessons provide employees with the opportunity to try new things, challenge themselves, and improve their physical skills.…. Large Language Model Yes, your company perks cover underwater activities such as scuba diving lessons1
need a way to vectorize & search target columns. PostgreSQL + pgvector Cosmos MongoDB Eventhouse in Microsoft Fabric Azure SQL + vector search (upcoming) Documents (Unstructured data) PDFs, docx, pptx, md, html, images You need an ingestion process for extracting, splitting, vectorizing, and storing document chunks. Azure AI Search + Integrated Vectorization Document Intelligence or
of floating-point numbers. ”dog” → [0.017198, -0.007493, -0.057982,…] Different models output different embeddings, with varying lengths. Model Encodes MTEB Avg. Vector length word2vec words 300 Sbert (Sentence-Transformers) text (up to ~400 words) 768 OpenAI text-embedding-ada-002 text (up to 8191 tokens) 61.0% 1536 OpenAI text-embedding-3-small text (up to 8191 tokens) 62.3% 512, 1536 OpenAI text-embedding-3-large text (up to 8191 tokens) 64.6% 256, 1024, 3072 Azure Computer Vision image or text 1024 Demo: vector_embeddings.ipynb (aka.ms/aitour/vectors)
similarity between inputs. The most common distance measurement is cosine similarity. def cosine_sim(a, b): return dot(a, b) / (mag(a) * mag(b)) For ada-002, cosine similarity values range from 0.7-1 Demo: vector_embeddings.ipynb (aka.ms/aitour/vectors)
data where it is: native vector search capabilities Built into: Azure Cosmos DB MongoDB vCore Azure PostgreSQL services Eventhouse in Microsoft Fabric Azure SQL server (upcoming) Azure AI Search Best relevance: highest quality of results out of the box Automatically index data from Azure data sources: SQL DB, Cosmos DB, Blob Storage, ADLSv2, and more
k_nearest_neighbors=5, fields="embedding")]) • ANN = Approximate Nearest Neighbors • Fast vector search at scale • Uses HNSW, a graph method with excellent performance-recall profile • Fine control over index parameters ANN search r = search_client.search( None, top=5, vector_queries=[ ( vector=search_vector, k_nearest_neighbors=5, fields="embedding", exhaustive=True)]) • KNN = K Nearest Neighbors • Per-query or built into schema • Useful to create recall baselines • Scenarios with highly selective filters • e.g., dense multi-tenant apps Exhaustive KNN search Demo: azure_ai_search.ipynb (aka.ms/aitour/azure-search)
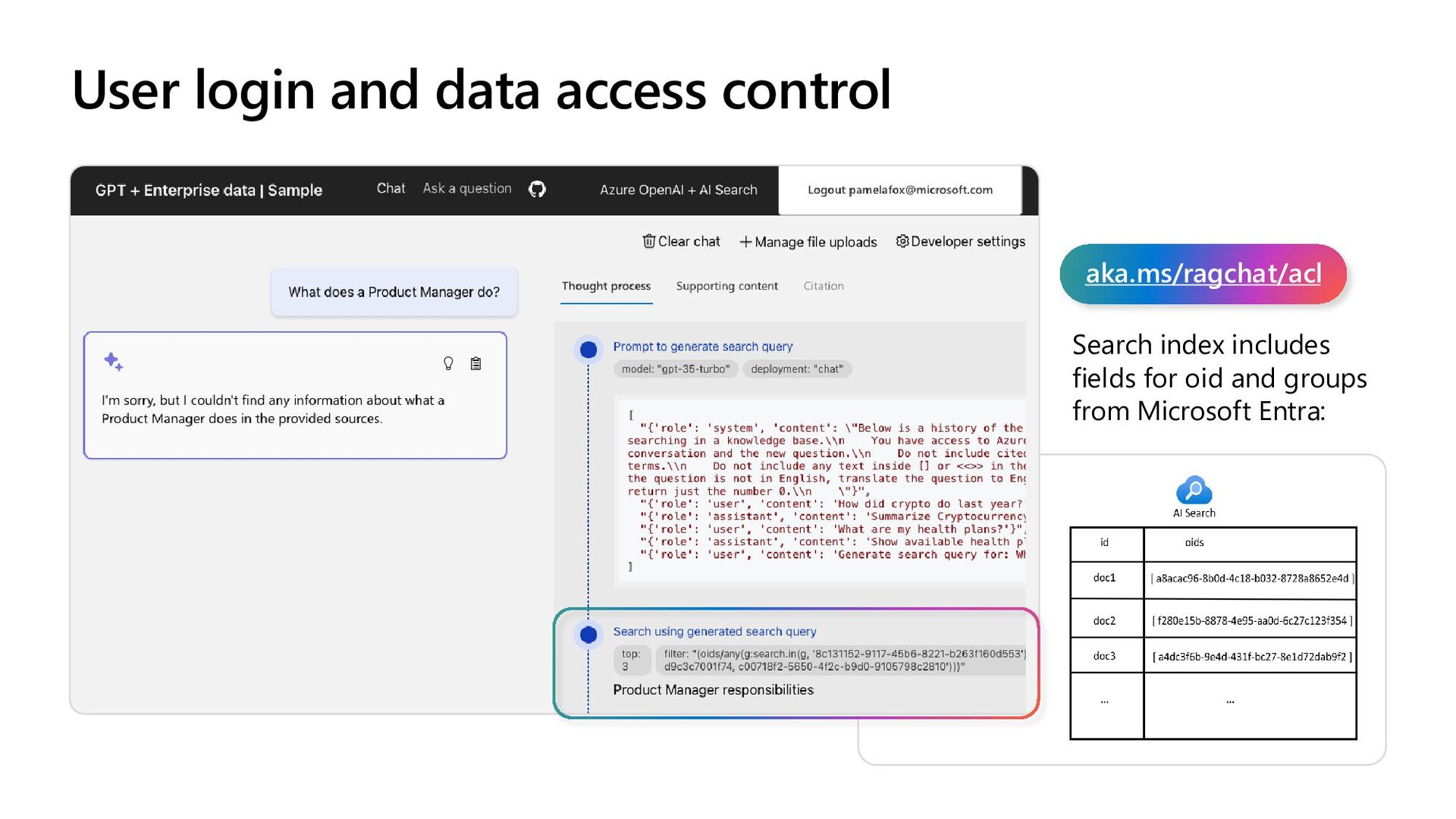
to date ranges, categories, geographic distances, access control groups, etc. • Rich filter expressions • Pre-/post-filtering • Pre-filter: great for selective filters, no recall disruption • Post-filter: better for low-selectivity filters, but watch for empty results https://learn.microsoft.com/azure/search/vector-search-filters r = search_client.search( None, top=5, vector_queries=[VectorizedQuery( vector=query_vector, k_nearest_neighbors=5, fields="embedding")], vector_filter_mode=VectorFilterMode.PRE_FILTER, filter= "tag eq 'perks' and created gt 2023-11-15T00:00:00Z") Multi-vector scenarios • Multiple vector fields per document • Multi-vector queries • Can mix and match as needed r = search_client.search( None, top=5, vector_queries=[ VectorizedQuery( vector=query1, fields="body_vector", k_nearest_neighbors=5), VectorizedQuery( vector=query2, fields="title_vector", k_nearest_neighbors=5) ])
(RRF) 1 Scuba Diving in Bahamas 1 Scuba Diving in the Carribean 2 Water skiing in Seychelles 1 Scuba Diving in the Carribean 2 Scuba Diving in Bahamas 3 Water skiing in Seychelles 1 Scuba Diving in Bahamas 2 Scuba Diving in the Carribean Question: "What underwater activities can I do in the Bahamas?" Vector results Keyword results
helps company employees questions about the employee handbook. Answer ONLY with the facts listed in the list of sources below. If there isn't enough information below, say you don't know. Each source has a name followed by colon and the actual information, include the source name for each fact you use.Use square brackets to reference the source, for example [info1.txt].""" USER_MESSAGE = user_question + "\nSources: " + sources # Now we can use the matches to generate a response response = openai_client.chat.completions.create( model=os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"), temperature=0.3, messages=[ {"role": "system", "content": SYSTEM_MESSAGE}, {"role": "user", "content": USER_MESSAGE}, ]) answer = response.choices[0].message.content Demo: rag.ipynb (aka.ms/aitour/rag)
limited context windows (4K – 128K) 2 When an LLM receives too much information, it can get easily distracted by irrelevant details. Accuracy 50 55 60 65 70 75 5 10 15 20 25 30 Number of documents in input context Source: Lost in the Middle: How Language Models Use Long Contexts, Liu et al. arXiv:2307.03172
Number of tokens Retrieval Configuration Recall@50 512 input tokens per vector 42.4 1024 input tokens per vector 37.5 4096 input tokens per vector 36.4 8191 input tokens per vector 34.9 Chunk boundary strategy Chunk boundary strategy Recall@50 512 tokens, break at token boundary 40.9 512 tokens, preserve sentence boundaries 42.4 512 tokens with 10% overlapping chunks 43.1 512 tokens with 25% overlapping chunks 43.9 A token is the unit of measurement for an LLM's input/output. ~1 token/word for English, higher ratios for other languages. A chunking algorithm should also consider tables, and generally avoid splitting tables when possible. Source: aka.ms/ragrelevance aka.ms/genai-cjk Source: aka.ms/ragrelevance
can be highly customized to meet the domain needs: Azure Blob Storage Upload documents An online version of each document is necessary for clickable citations. Azure Document Intelligence Extract data from documents Supports PDF, HTML, docx, pptx, xlsx, images, plus can OCR when needed. Local parsers also available for PDF, HTML, JSON, txt. Python Split data into chunks Split text based on sentence boundaries and token lengths. Langchain splitters could also be used here. Azure OpenAI Vectorize chunks Compute embeddings using OpenAI embedding model of your choosing. Azure AI Search Indexing ・Document index ・Chunk index ・Both
Are they correct? (relative to the knowledge base) Are they formatted in the desired manner? Do the perks cover underwater activities? Yes, according to the information provided in the PerksPlus.pdf document, underwater activities such as scuba diving are covered under the program. Yes, underwater activities are included as part of the PerksPlus program. Some of the underwater activities covered under PerksPlus include scuba diving lessons [PerksPlus.pdf#page=3]. Yes, the perks provided by the PerksPlus Health and Wellness Reimbursement Program cover a wide range of fitness activities, including underwater activities such as scuba diving. The program aims to support employees' physical health and overall well-being, so it includes various lessons and experiences that promote health and wellness. Scuba diving lessons are specifically mentioned as one of the activities covered under PerksPlus. Therefore, if an employee wishes to pursue scuba diving as a fitness-related activity, they can expense it through the PerksPlus program.
Search engine (ie. Azure AI Search) ・ Search query cleaning ・ Search options (hybrid, vector, reranker) ・ Additional search options ・ Data chunk size and overlap ・ Number of results returned ・ System prompt ・ Language ・ Message history ・ Model (ie. GPT 3.5) ・ Temperature (0-1) ・ Max tokens
Evaluate language models Shifting space, many metrics, consider your task. chat.lmsys.org/?leaderboard Evaluate the full RAG stack for quality and safety AI Studio or promptflow-evals for GPT-based evaluations and metrics→ At Build: BRK107: aka.ms/ragchat/eval Demo: rag.ipynb (aka.ms/aitour/rageval)
RAG apps for… Public government data Internal HR documents, company meetings, presentations Customer support requests and call transcripts Technical documentation and issue trackers Product manuals Customer Story: PwC scales GenAI for enterprise with Microsoft Azure AI
more into quality evaluation details and why Azure AI Search will make your application generate better results aka.ms/ragrelevance Deploy a RAG chat application for your organization’s data aka.ms/azai/python Explore Azure AI Studio for a complete RAG development experience aka.ms/AzureAIStudio 1 2 3 4 aka.ms/aitour/rag/mx Get the slides:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}