Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Making Deployments Easy with TF Serving | TF Ev...
Search
Rishit Dagli
May 11, 2021
Programming
200
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Making Deployments Easy with TF Serving | TF Everywhere India
My talk at TensorFlow Everywhere India
Rishit Dagli
May 11, 2021
More Decks by Rishit Dagli
See All by Rishit Dagli
Fantastic Models and Where to Find Them
rishitdagli
0
99
Plant AI: Project Showcase
rishitdagli
0
170
Deploying an ML Model as an API | Postman Student Summit
rishitdagli
0
120
APIs 101 with Postman
rishitdagli
0
140
Deploying Models to production with Azure ML | Scottish Summit
rishitdagli
1
110
Computer Vision with TensorFlow, Getting Started
rishitdagli
0
340
Teaching Your Models to Play Fair | Global AI Student Conf
rishitdagli
1
210
Deploying Models to Production with TF Serving
rishitdagli
1
240
Superpower Your Android apps with ML: Android 11 | Devfest 2020
rishitdagli
1
100
Other Decks in Programming
See All in Programming
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
310
symfony/aiとlaravel/boost
77web
0
120
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.4k
共通化で考えるべきは、実装より公開する型だった
codeegg
0
210
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
180
act1-costs.pdf
sumedhbala
0
210
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
310
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
140
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
480
自作OSでスライド発表する
uyuki234
1
3.8k
Featured
See All Featured
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
4 Signs Your Business is Dying
shpigford
187
22k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
Claude Code のすすめ
schroneko
67
230k
The Cult of Friendly URLs
andyhume
79
6.9k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Balancing Empowerment & Direction
lara
6
1.2k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Optimizing for Happiness
mojombo
378
71k
It's Worth the Effort
3n
188
29k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Transcript
Making Deployments Easy with TF Serving Rishit Dagli High School
TEDx, TED-Ed Speaker rishit_dagli Rishit-dagli
“Most models don’t get deployed.”
of models don’t get deployed. 90%
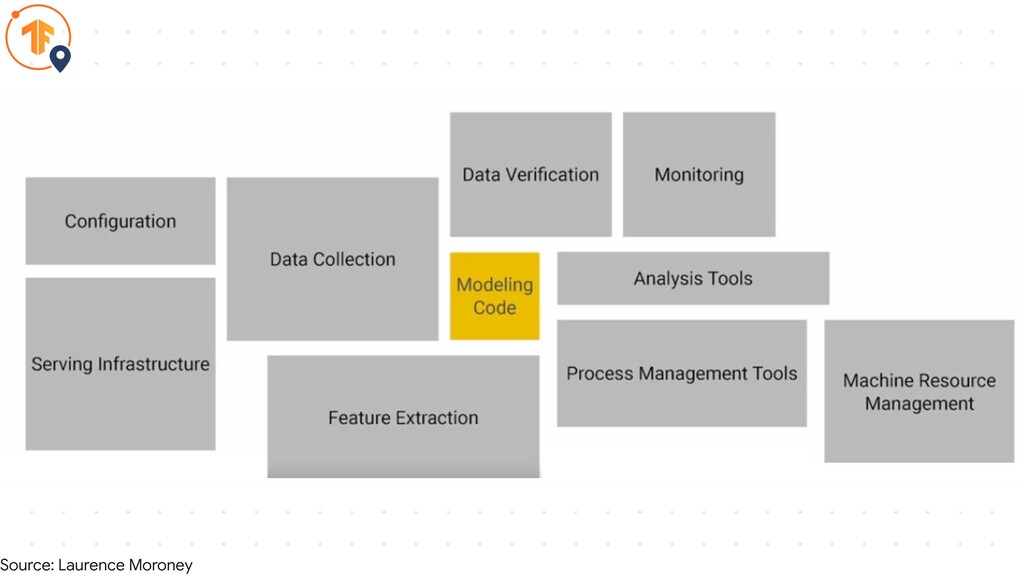
Source: Laurence Moroney
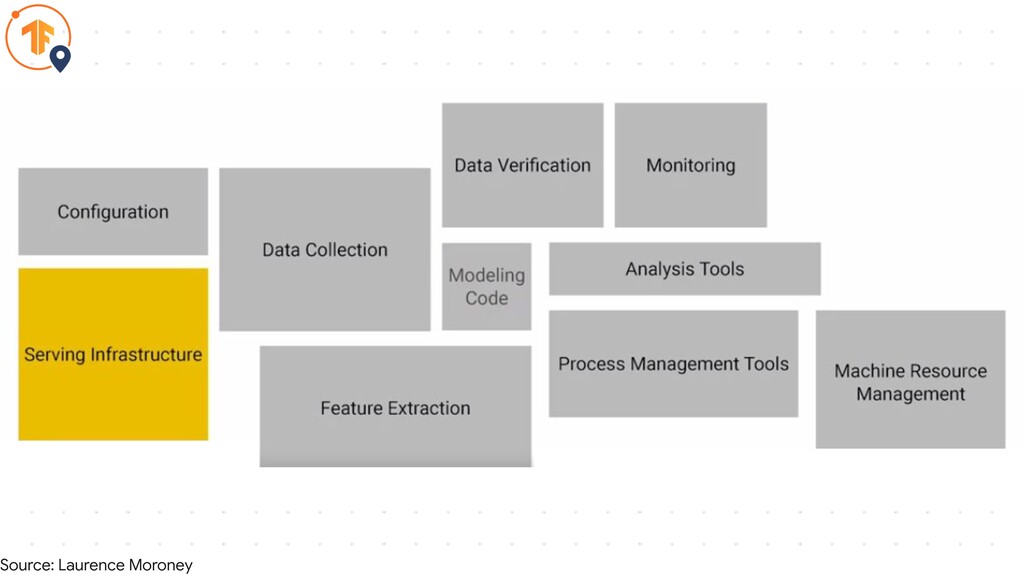
Source: Laurence Moroney
• High School Student • TEDx and Ted-Ed Speaker •
♡ Hackathons and competitions • ♡ Research • My coordinates - www.rishit.tech $whoami rishit_dagli Rishit-dagli
• Devs who have worked on Deep Learning Models (Keras)
• Devs looking for ways to put their model into production ready manner Ideal Audience
Why care about ML deployments? Source: memegenerator.net
None
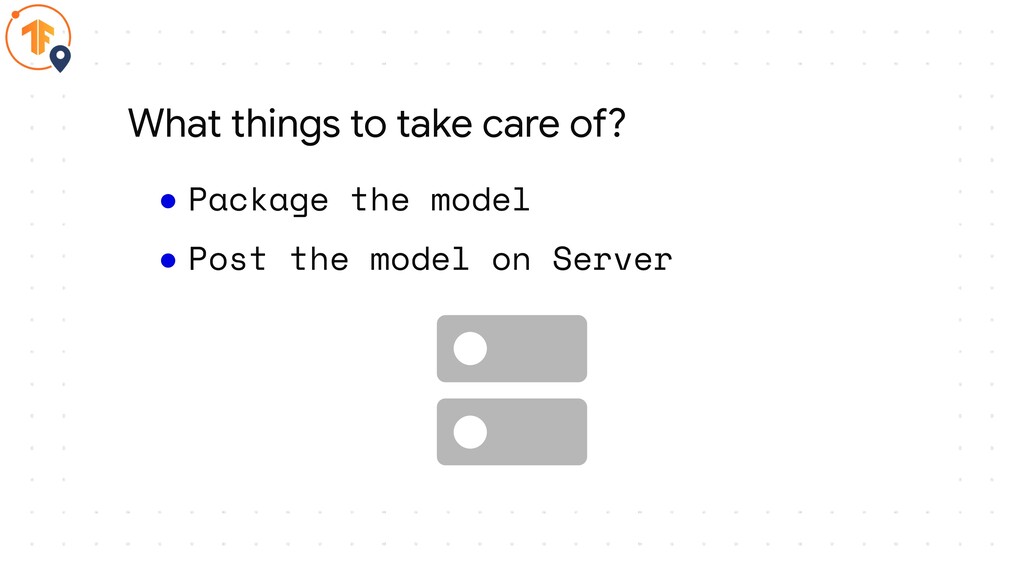
• Package the model What things to take care of?
• Package the model • Post the model on Server
What things to take care of?
• Package the model • Post the model on Server
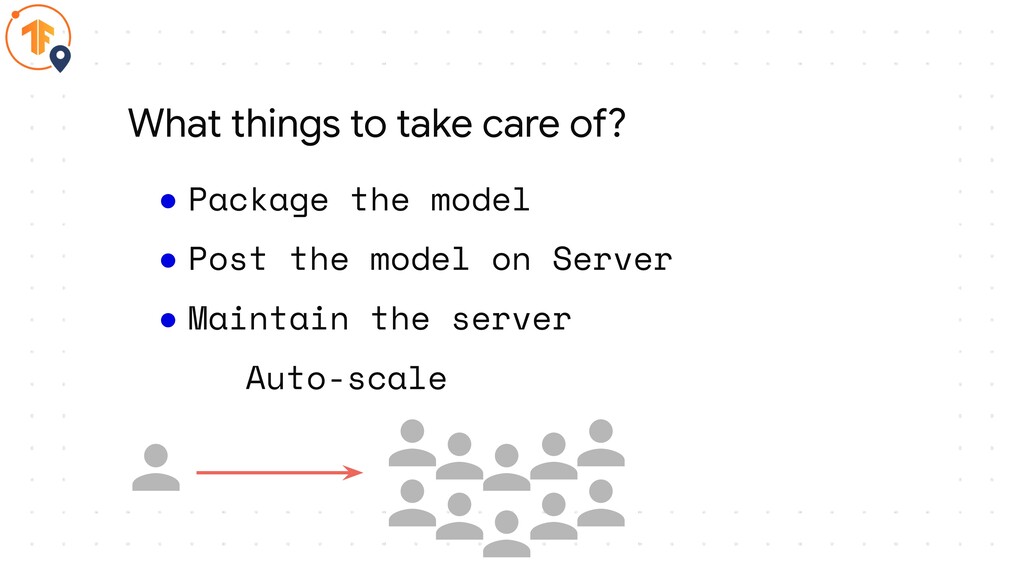
• Maintain the server What things to take care of?
• Package the model • Post the model on Server
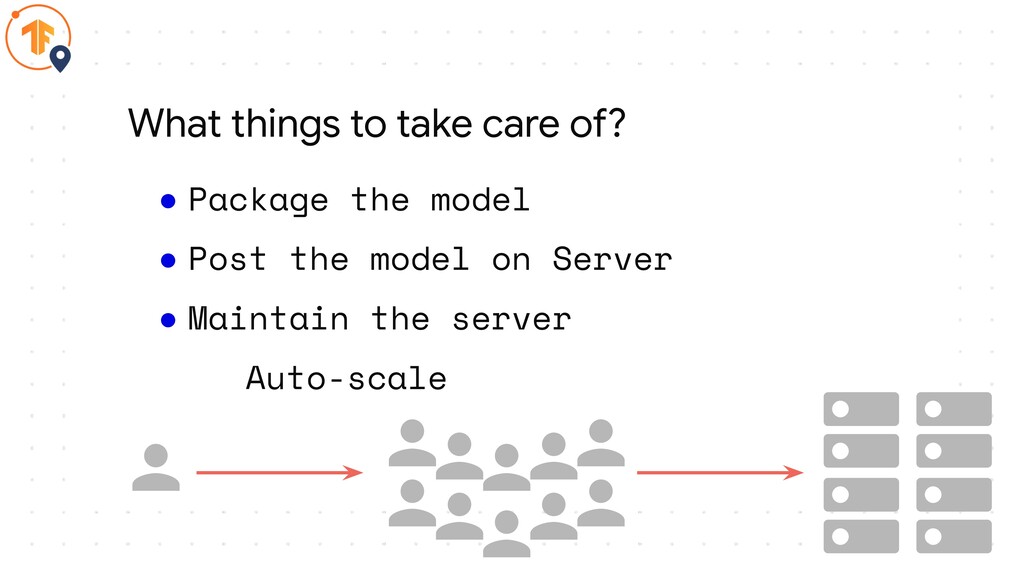
• Maintain the server Auto-scale What things to take care of?
• Package the model • Post the model on Server
• Maintain the server Auto-scale What things to take care of?
• Package the model • Post the model on Server
• Maintain the server Auto-scale Global availability What things to take care of?
• Package the model • Post the model on Server
• Maintain the server Auto-scale Global availability Latency What things to take care of?
• Package the model • Post the model on Server
• Maintain the server • API What things to take care of?
• Package the model • Post the model on Server
• Maintain the server • API • Model Versioning What things to take care of?
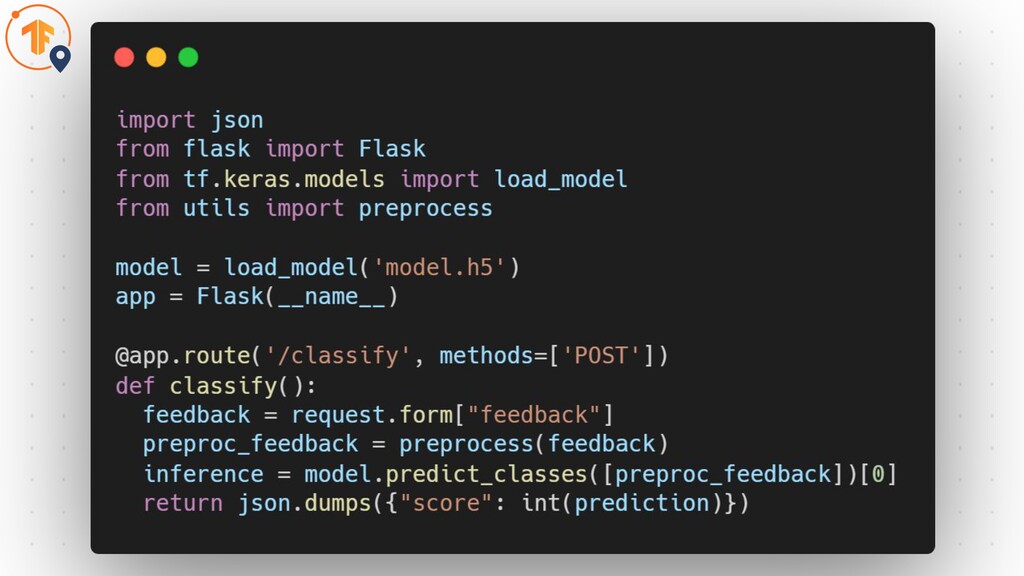
Simple Deployments Why are they inefficient?
None
Simple Deployments Why are they inefficient? • No consistent API
• No model versioning • No mini-batching • Inefficient for large models Source: Hannes Hapke
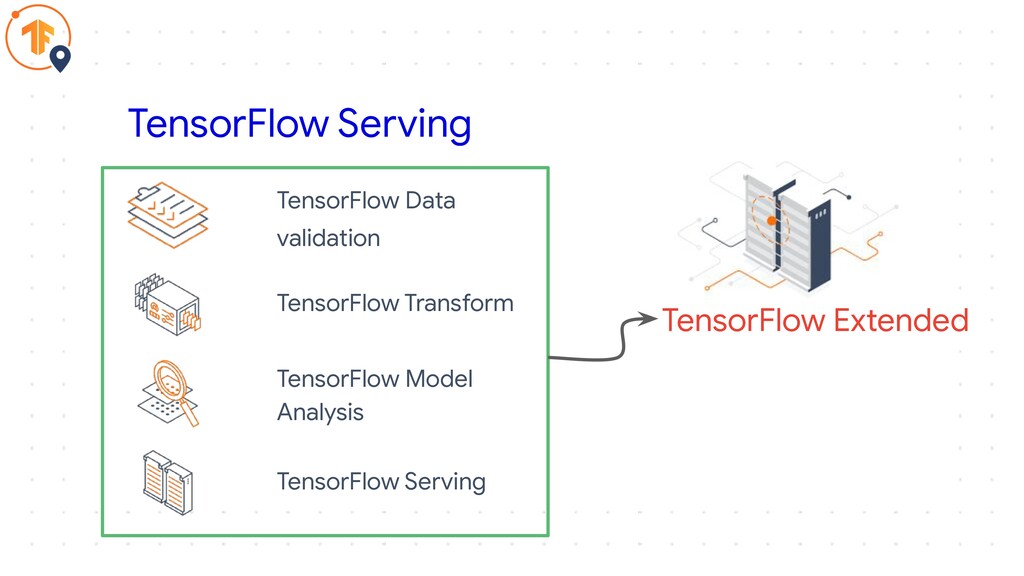
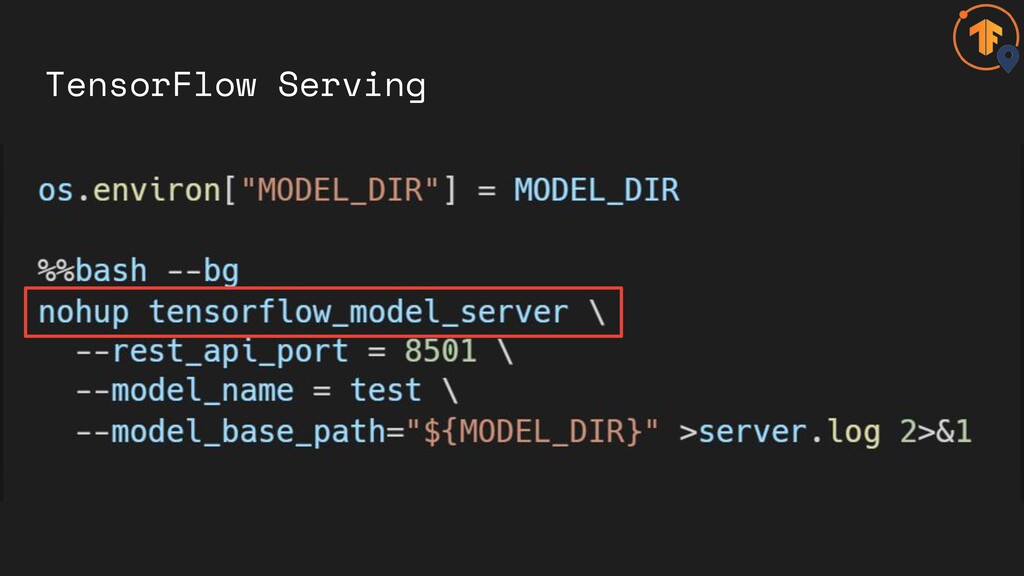
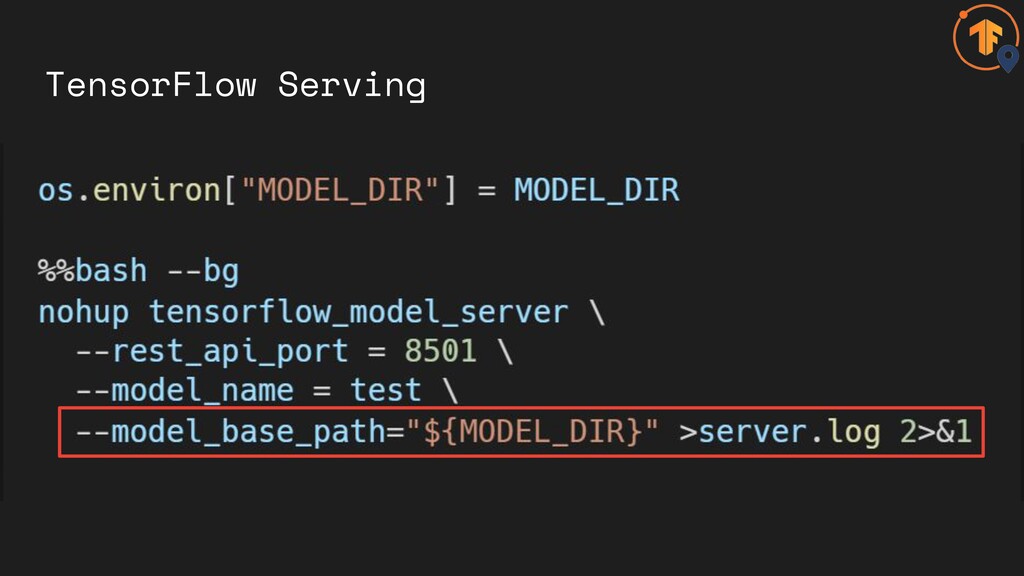
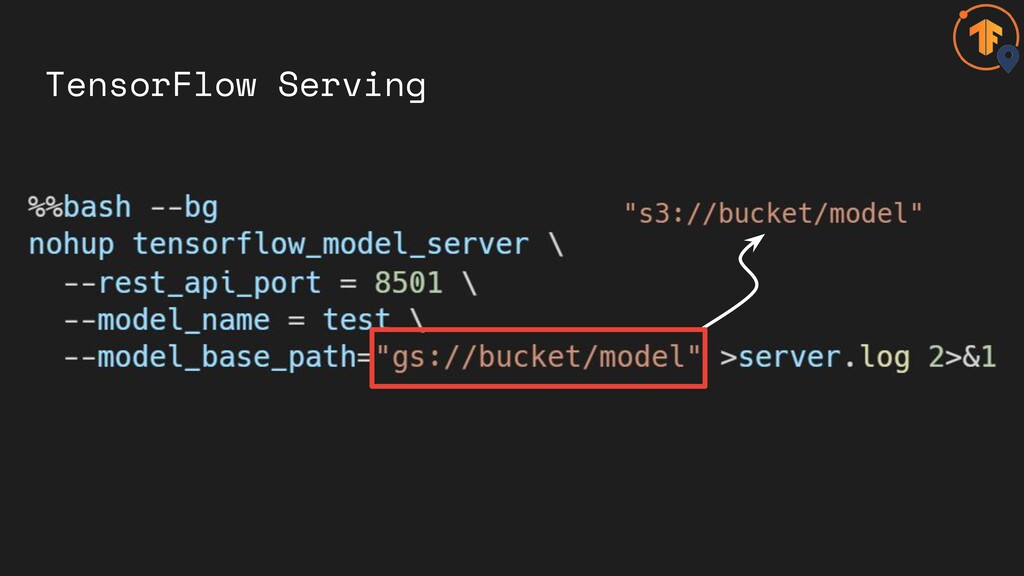
TensorFlow Serving
TensorFlow Serving TensorFlow Data validation TensorFlow Transform TensorFlow Model Analysis
TensorFlow Serving TensorFlow Extended
• Part of TensorFlow Extended TensorFlow Serving
• Part of TensorFlow Extended • Used Internally at Google
TensorFlow Serving
• Part of TensorFlow Extended • Used Internally at Google
• Makes deployment a lot easier TensorFlow Serving
The Process
• The SavedModel format • Graph definitions as protocol buffer
Export Model
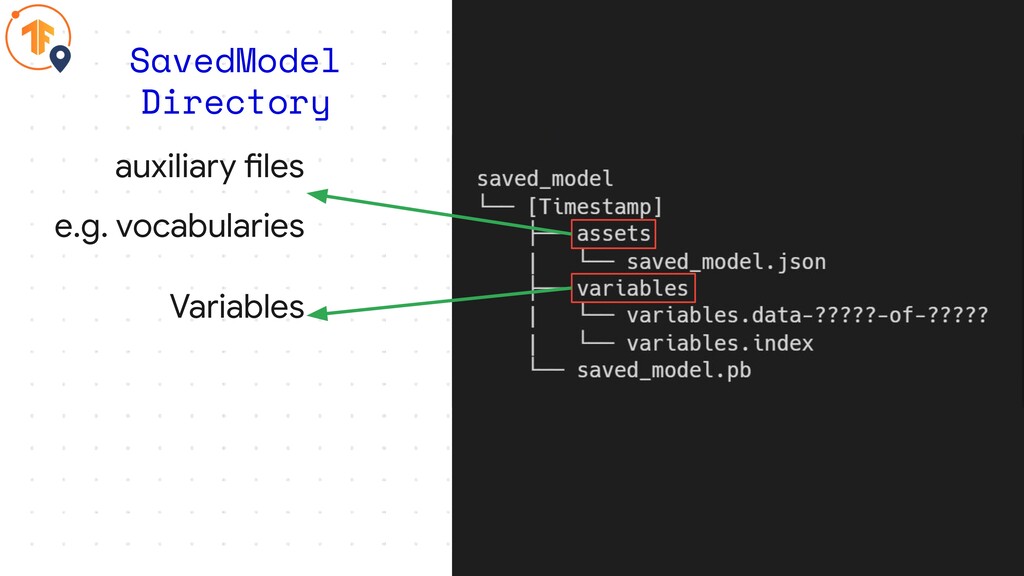
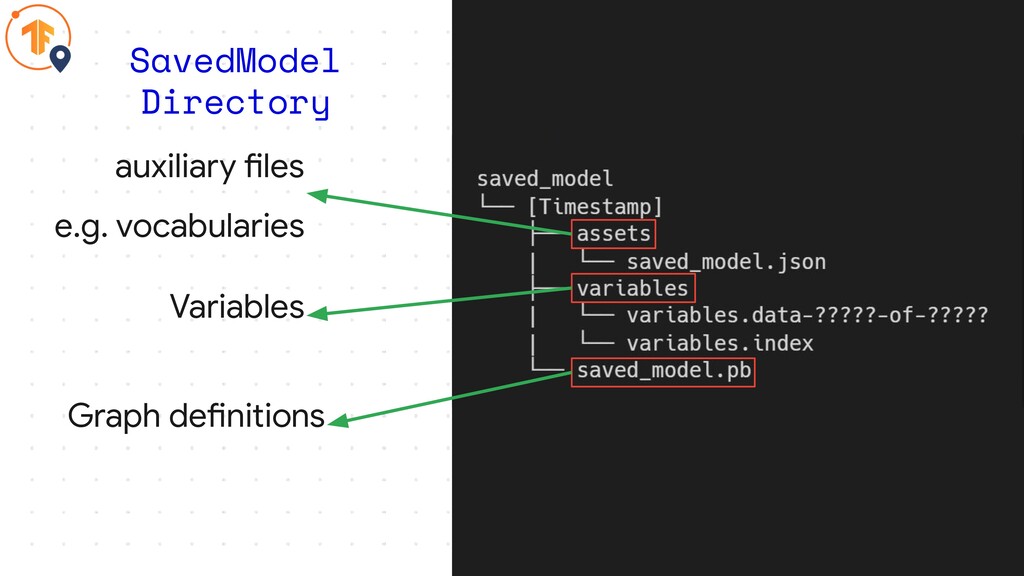
SavedModel Directory
auxiliary files e.g. vocabularies SavedModel Directory
auxiliary files e.g. vocabularies SavedModel Directory Variables
auxiliary files e.g. vocabularies SavedModel Directory Variables Graph definitions
TensorFlow Serving
TensorFlow Serving
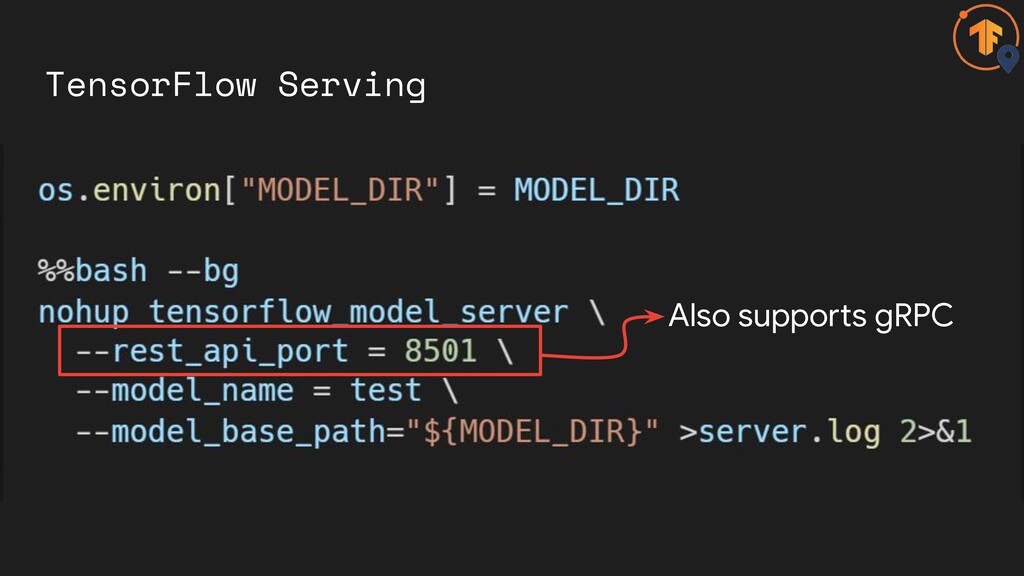
TensorFlow Serving Also supports gRPC
TensorFlow Serving
TensorFlow Serving
TensorFlow Serving
TensorFlow Serving
Inference
• Consistent APIs • Supports simultaneously gRPC: 8500 REST: 8501
• No lists but lists of lists Inference
• No lists but lists of lists Inference
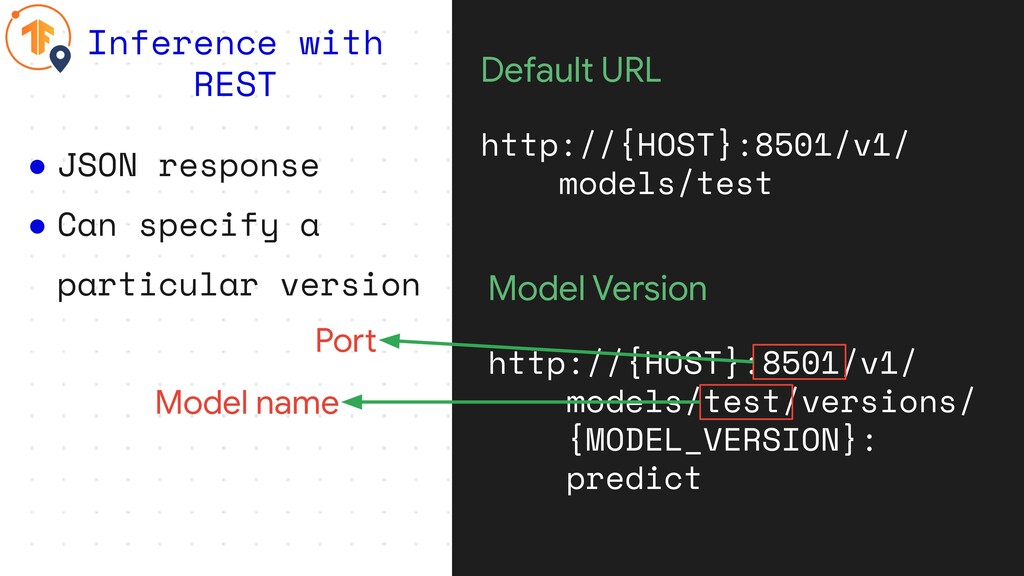
• JSON response • Can specify a particular version Inference
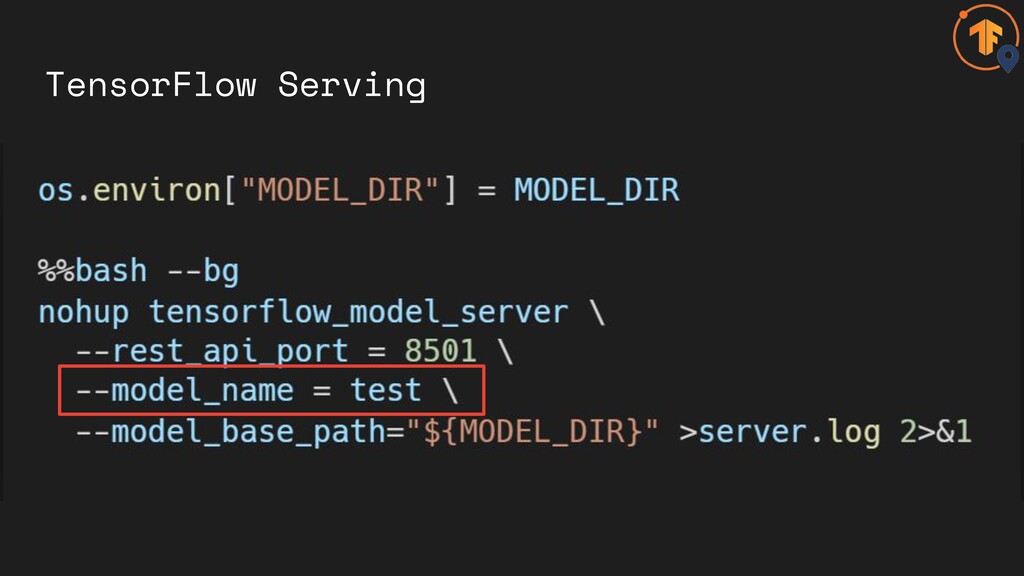
with REST Default URL http://{HOST}:8501/v1/ models/test Model Version http://{HOST}:8501/v1/ models/test/versions/ {MODEL_VERSION}: predict
• JSON response • Can specify a particular version Inference
with REST Default URL http://{HOST}:8501/v1/ models/test Model Version http://{HOST}:8501/v1/ models/test/versions/ {MODEL_VERSION}: predict Port Model name
Inference with REST
• Better connections • Data converted to protocol buffer •
Request types have designated type • Payload converted to base64 • Use gRPC stubs Inference with gRPC
Model Meta Information
• You have an API to get meta info •
Useful for model tracking in telementry systems • Provides model input/ outputs, signatures Model Meta Information
Model Meta Information http://{HOST}:8501/ v1/models/{MODEL_NAME} /versions/{MODEL_VERSION} /metadata
Batch Inferences
• Use hardware efficiently • Save costs and compute resources
• Take multiple requests process them together • Super cool😎 for large models Batch inferences
• max_batch_size • batch_timeout_micros • num_batch_threads • max_enqueued_batches • file_system_poll_wait
_seconds • tensorflow_session _paralellism • tensorflow_intra_op _parallelism Batch Inference Highly customizable
• Load configuration file on startup • Change parameters according
to use cases Batch Inference
Also take a look at...
• Kubeflow deployments • Data pre-processing on server🚅 • AI
Platform Predictions • Deployment on edge devices • Federated learning Also take a look at...
bit.ly/tf-everywhere-ind Demos!
bit.ly/serving-deck Slides
Thank You rishit_dagli Rishit-dagli
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}