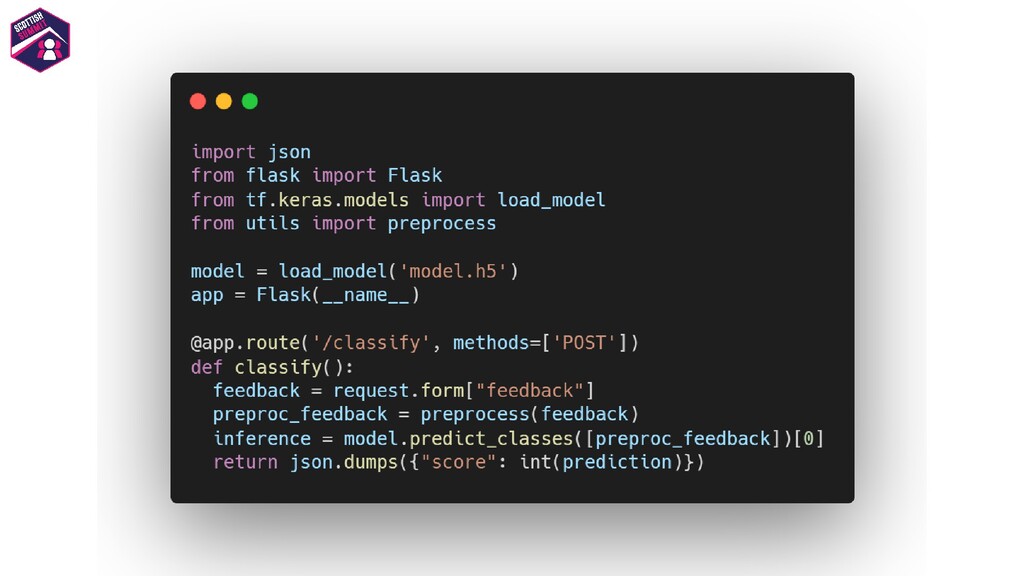
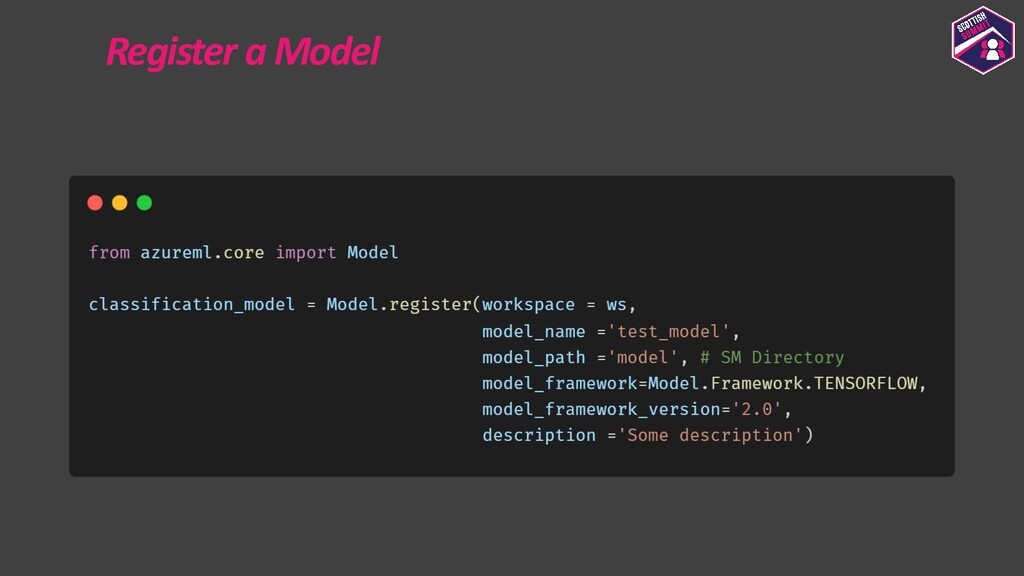
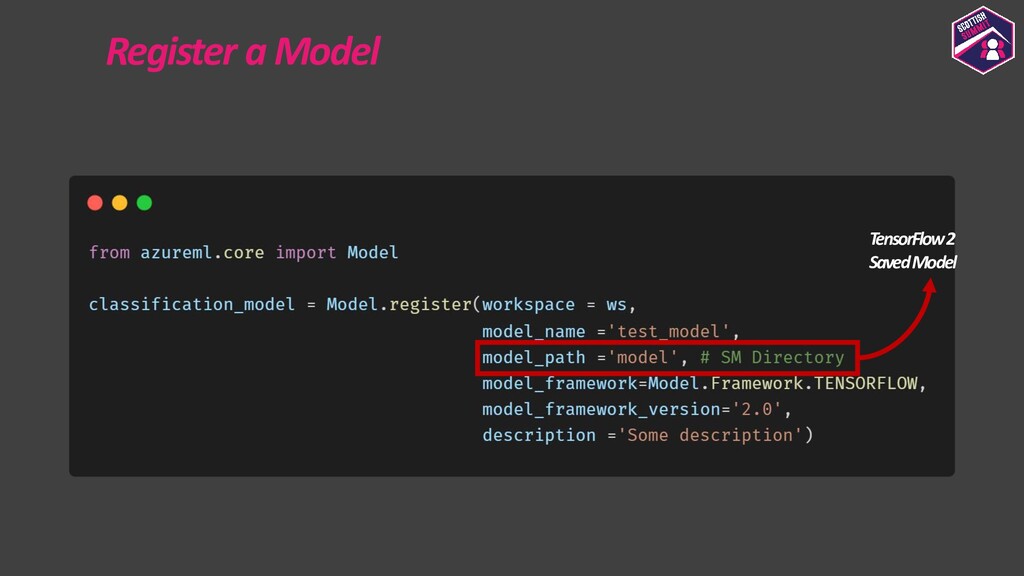
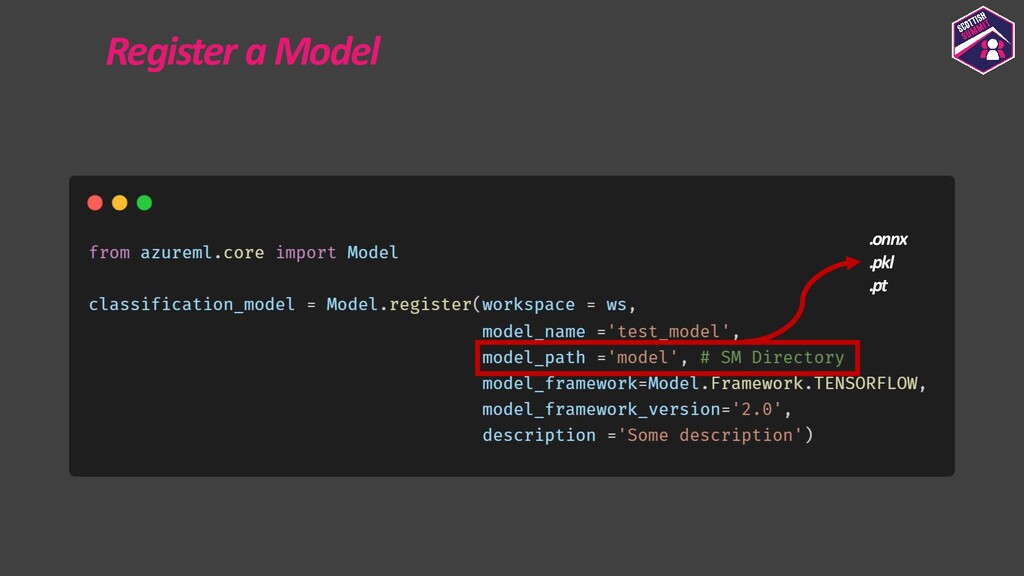
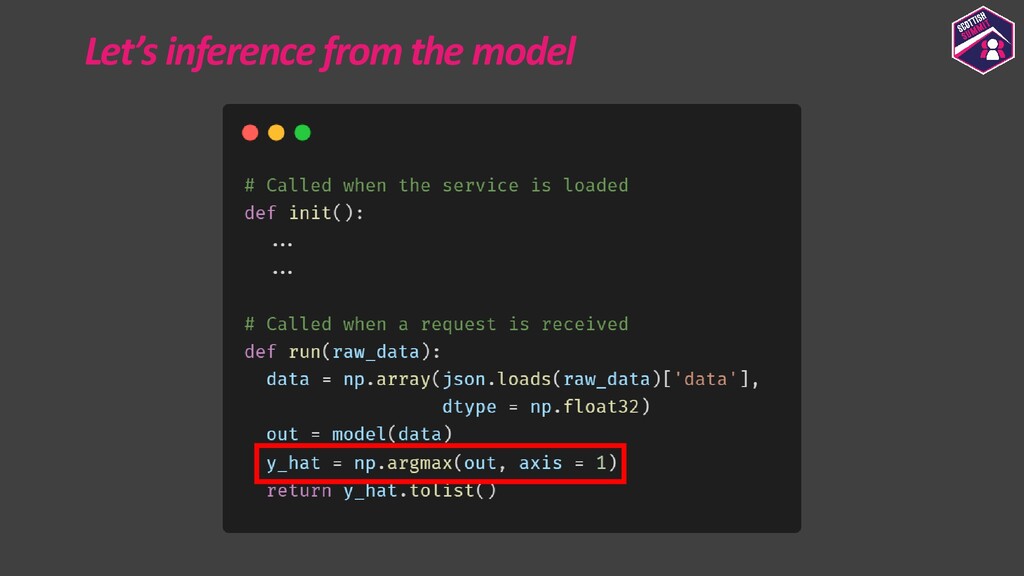
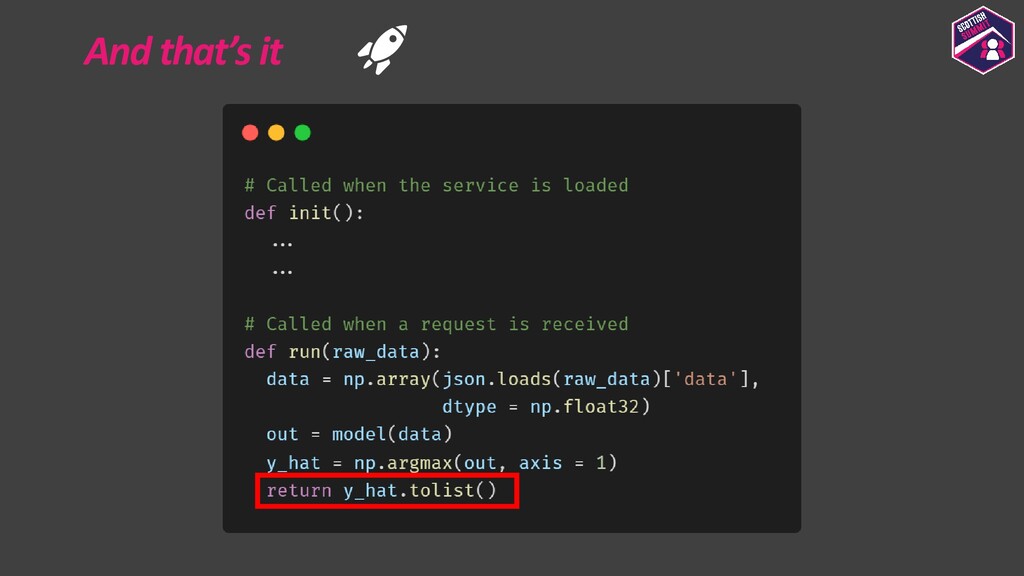
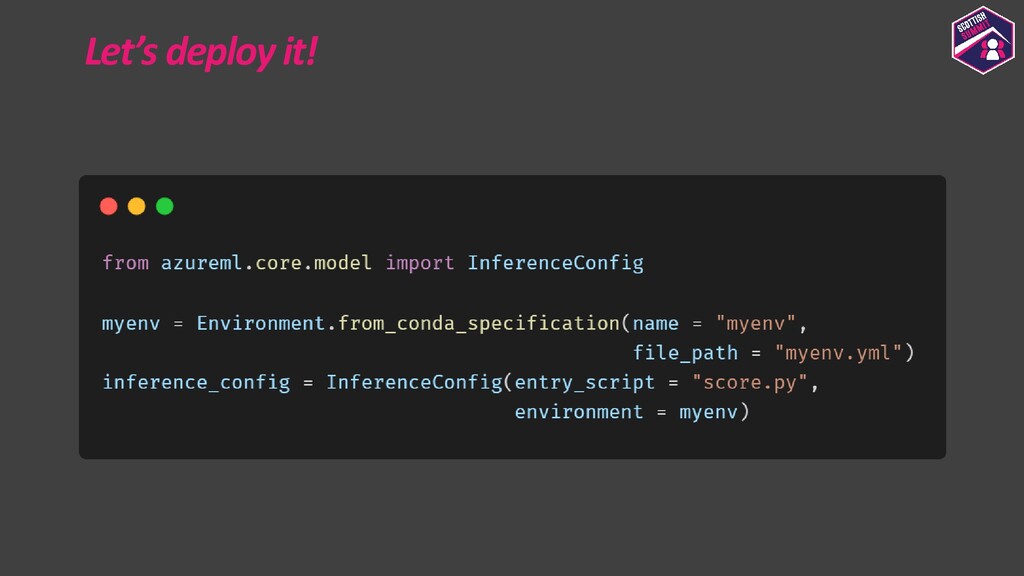
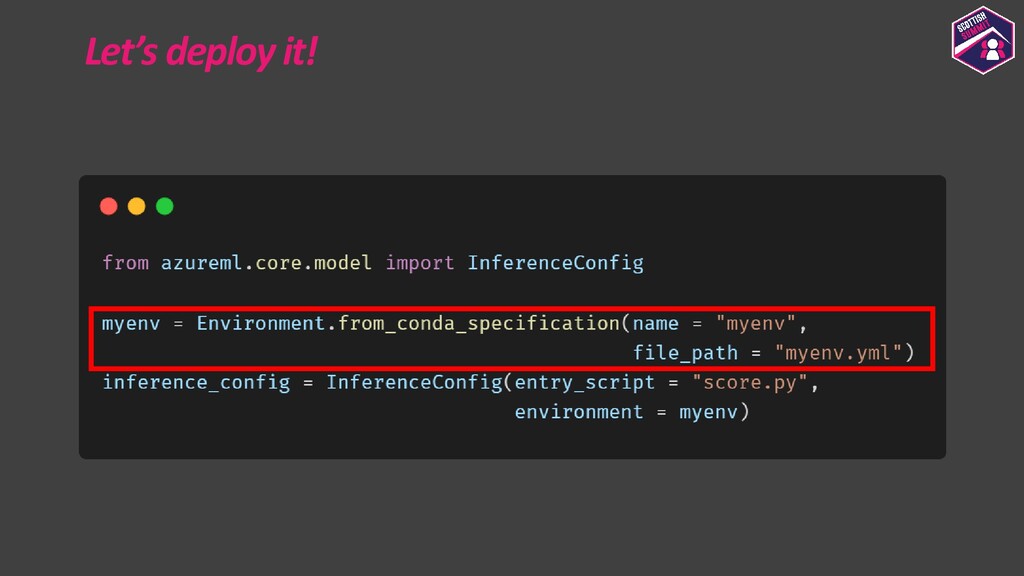
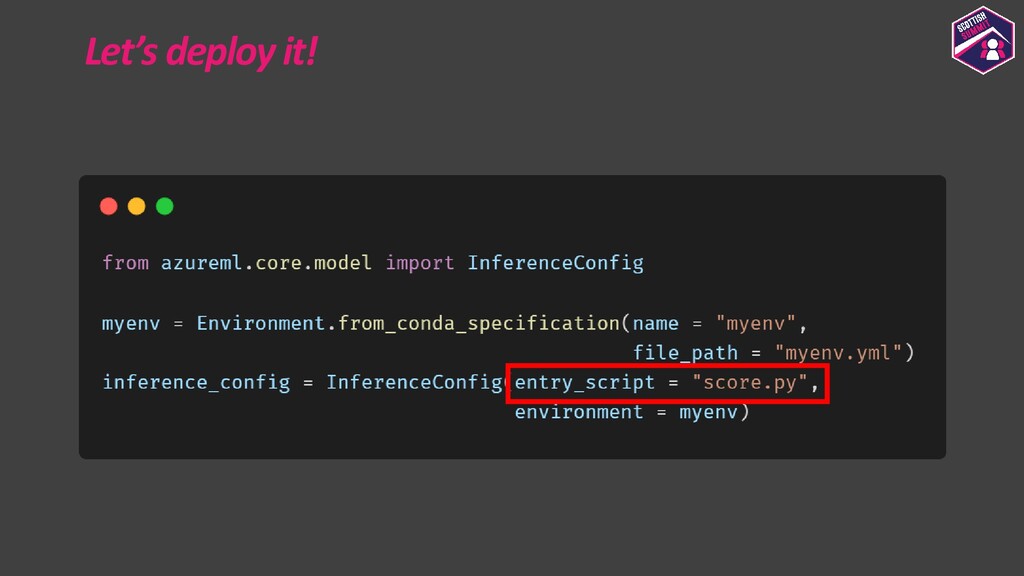
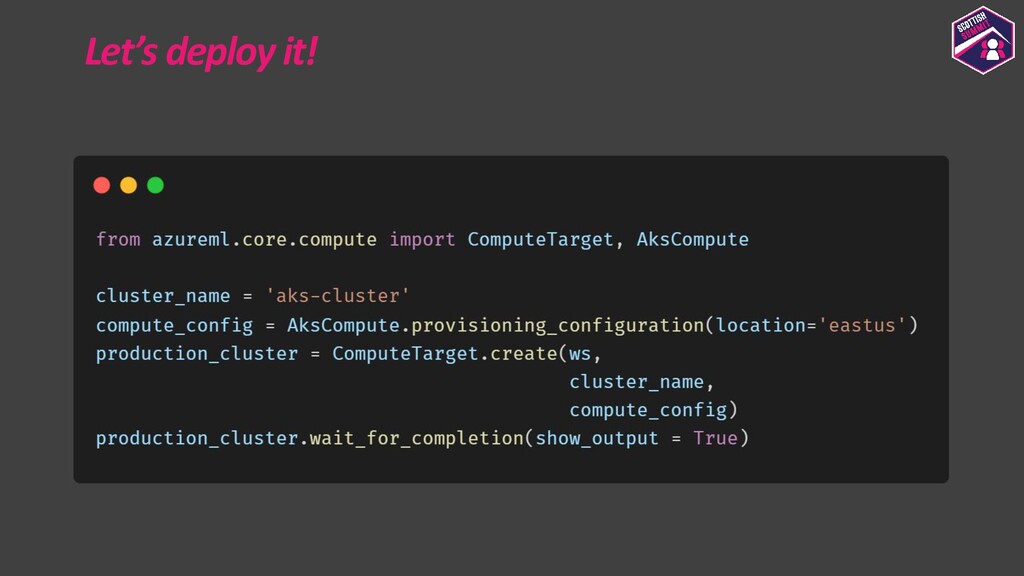
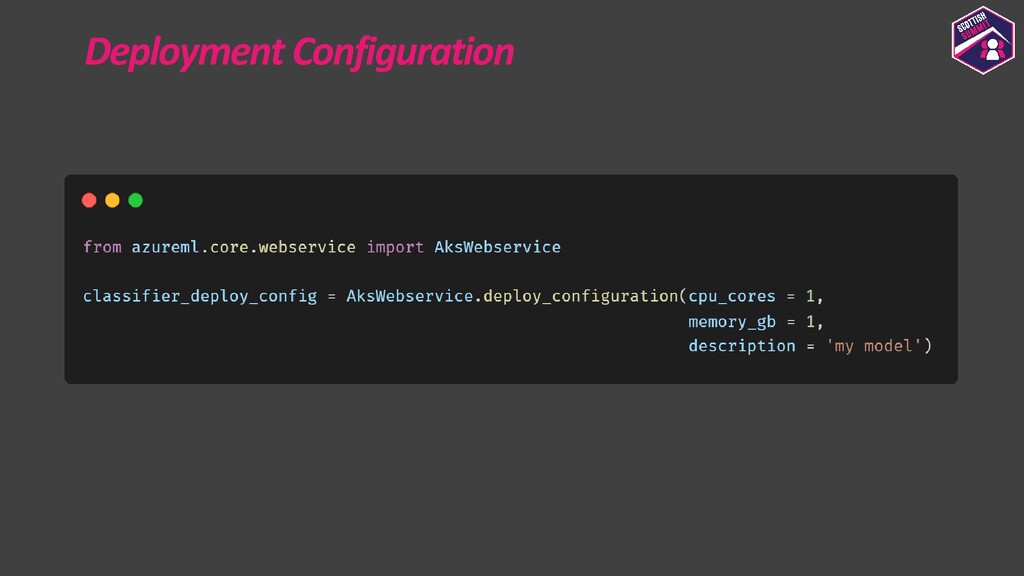
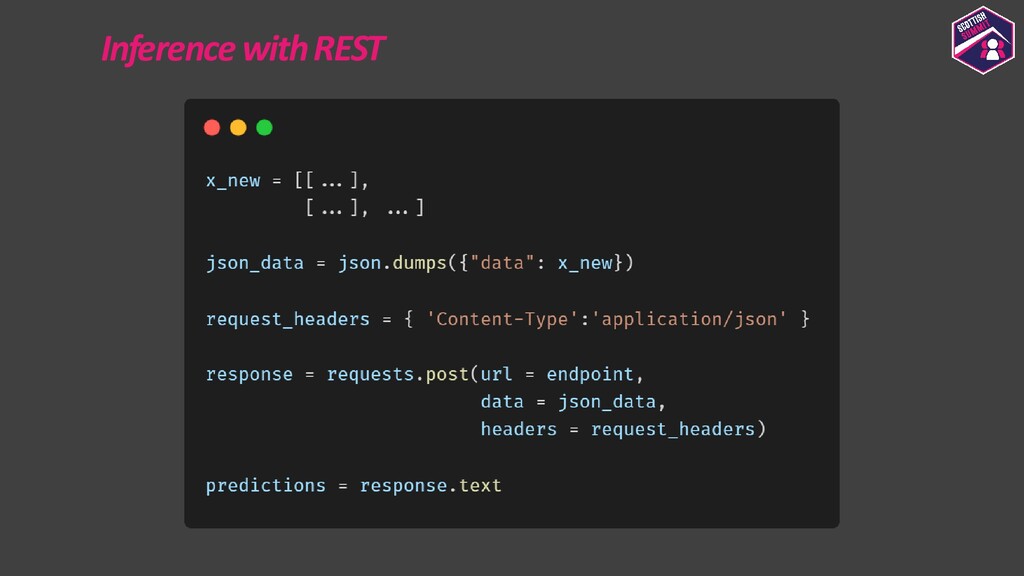
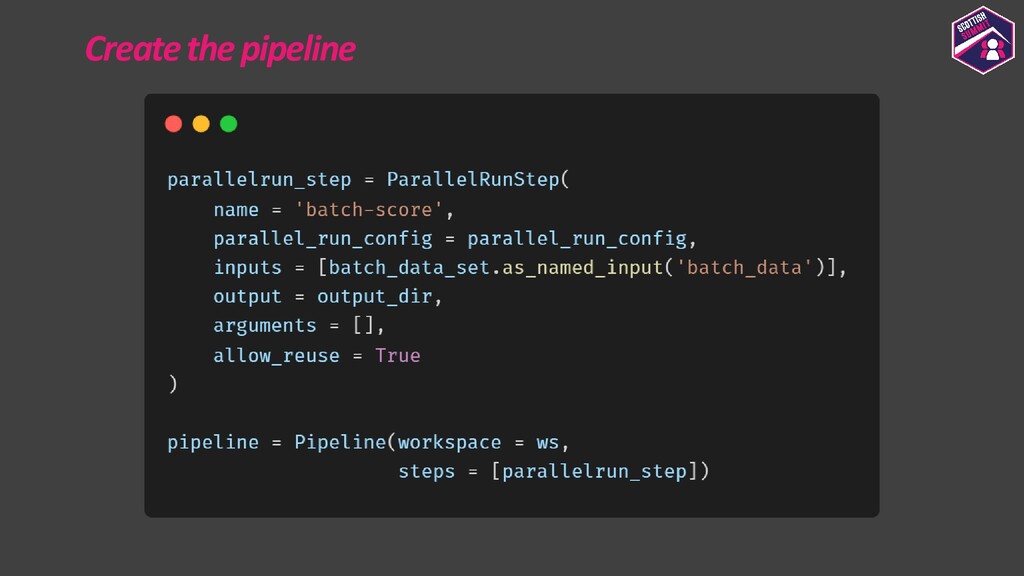
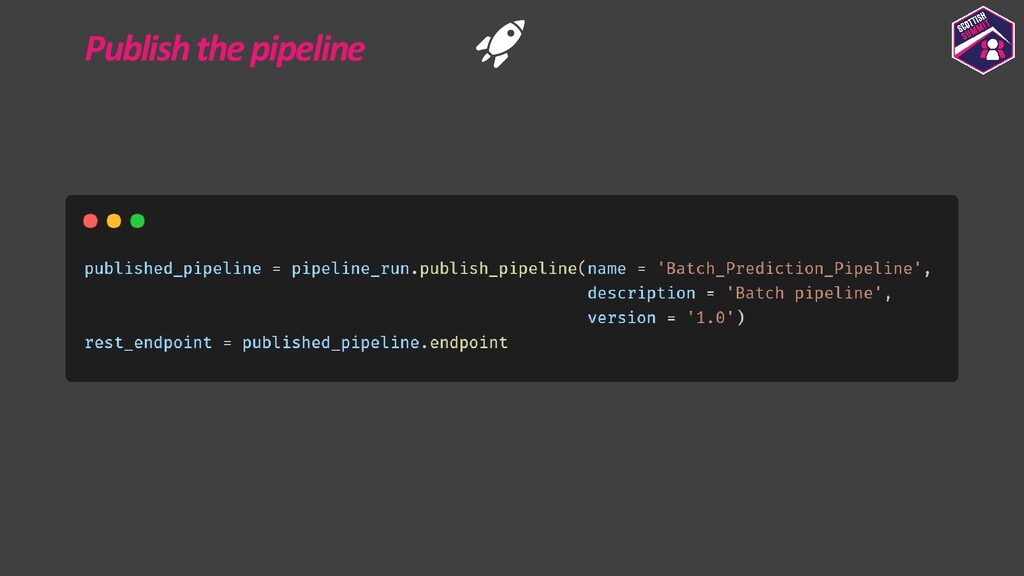
Deploying models is a pretty important aspect to consider while building end-to-end ML applications. I first plan to show how the models could be registered with Azure ML so as to make them accessible and allow them to be loaded for deployment. I then plan to show how configurations could be built for deploying the models with Azure ML. Azure ML allows us to easily deploy models to receive low latency real-time inferences which are required for a lot of applications, so I would majorly focus on this and also show how one could consume these models. I would further show how to also build batch inference pipelines. If time persists I would also show demos for the same.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
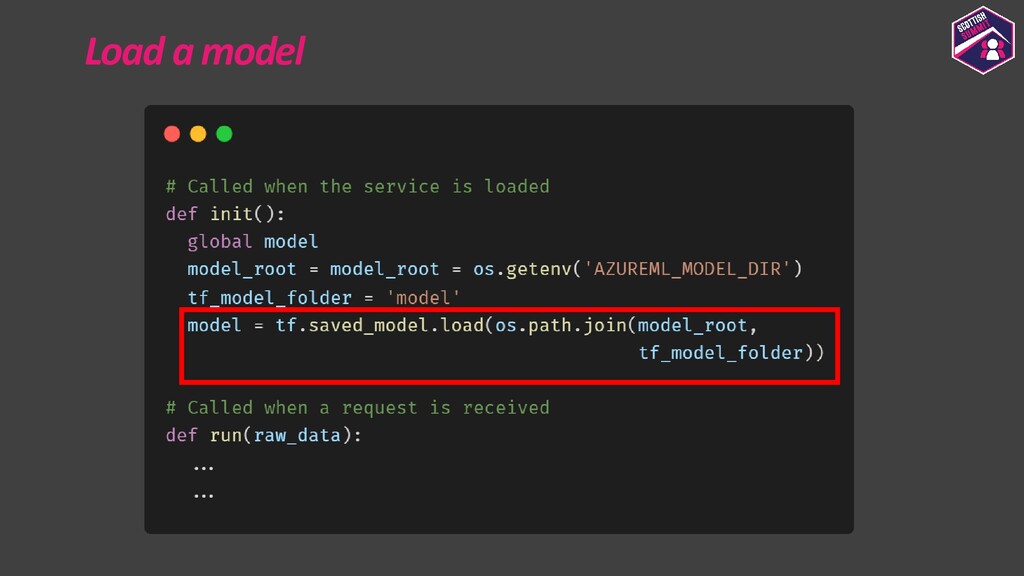
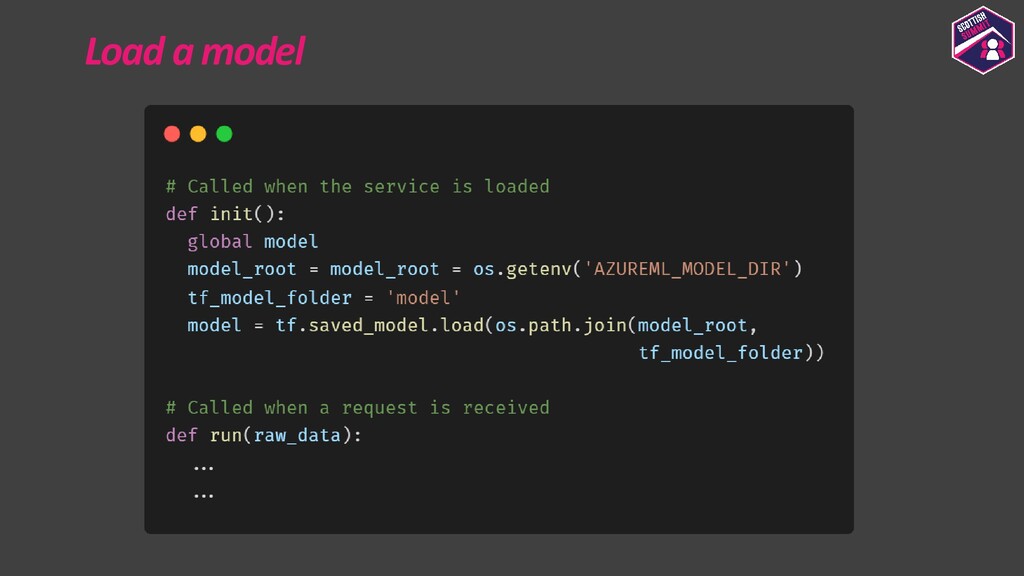{kind=link}
{kind=link}
{kind=link}
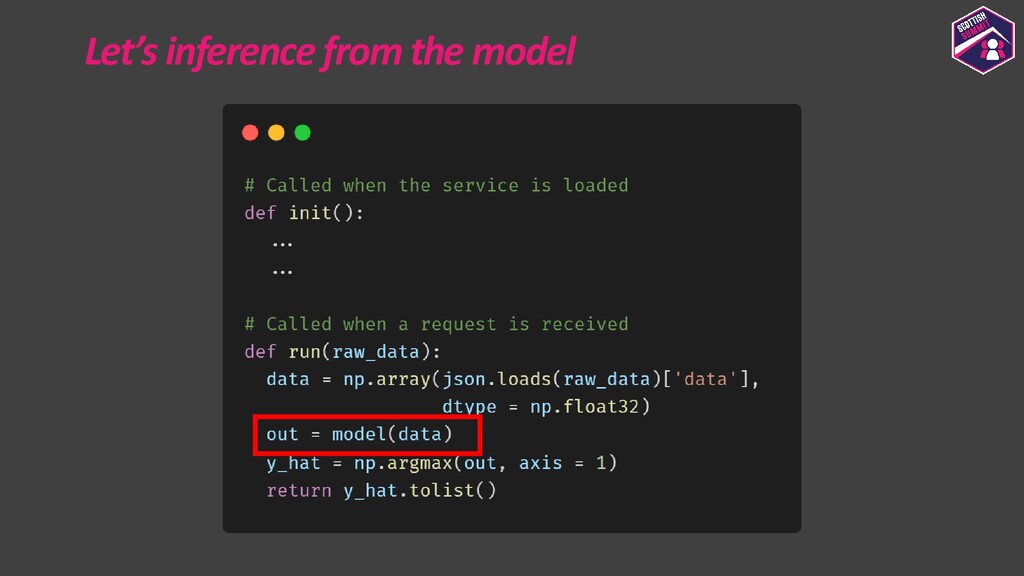
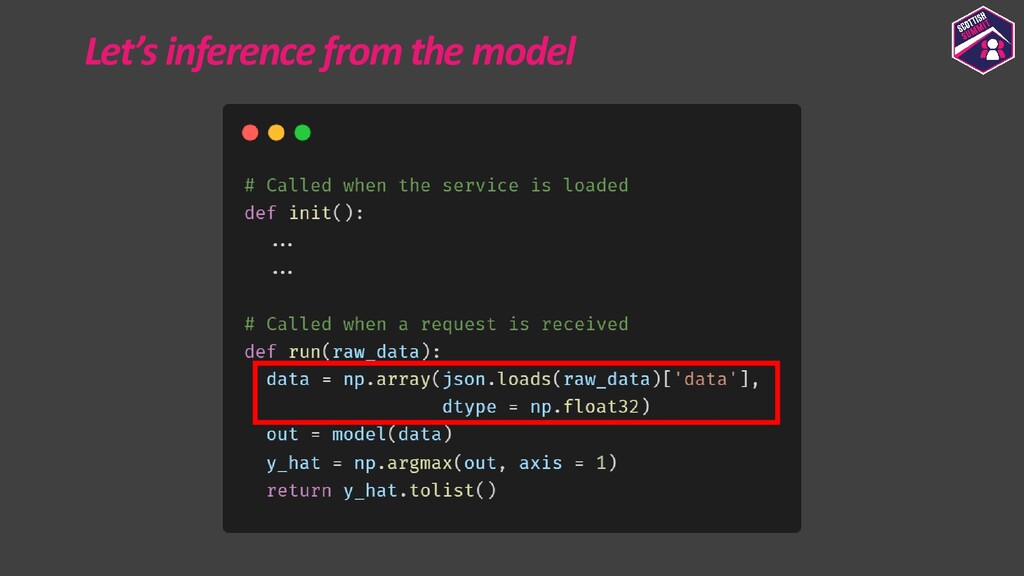{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}