Straight:普通にイスに座った状態 ◦ Seated Lean Non Dom - FACE DOWN:少し前屈みでイスに座った状態 ◦ Lie on Back:仰向けで寝た状態 ◦ Lie on Side - Non Dominant:非利き手側を下にして横向きで寝た状態 Seated Straight Seated Lean Non Dom - FACE DOWN Lie on Back Lie on Side - Non Dominant
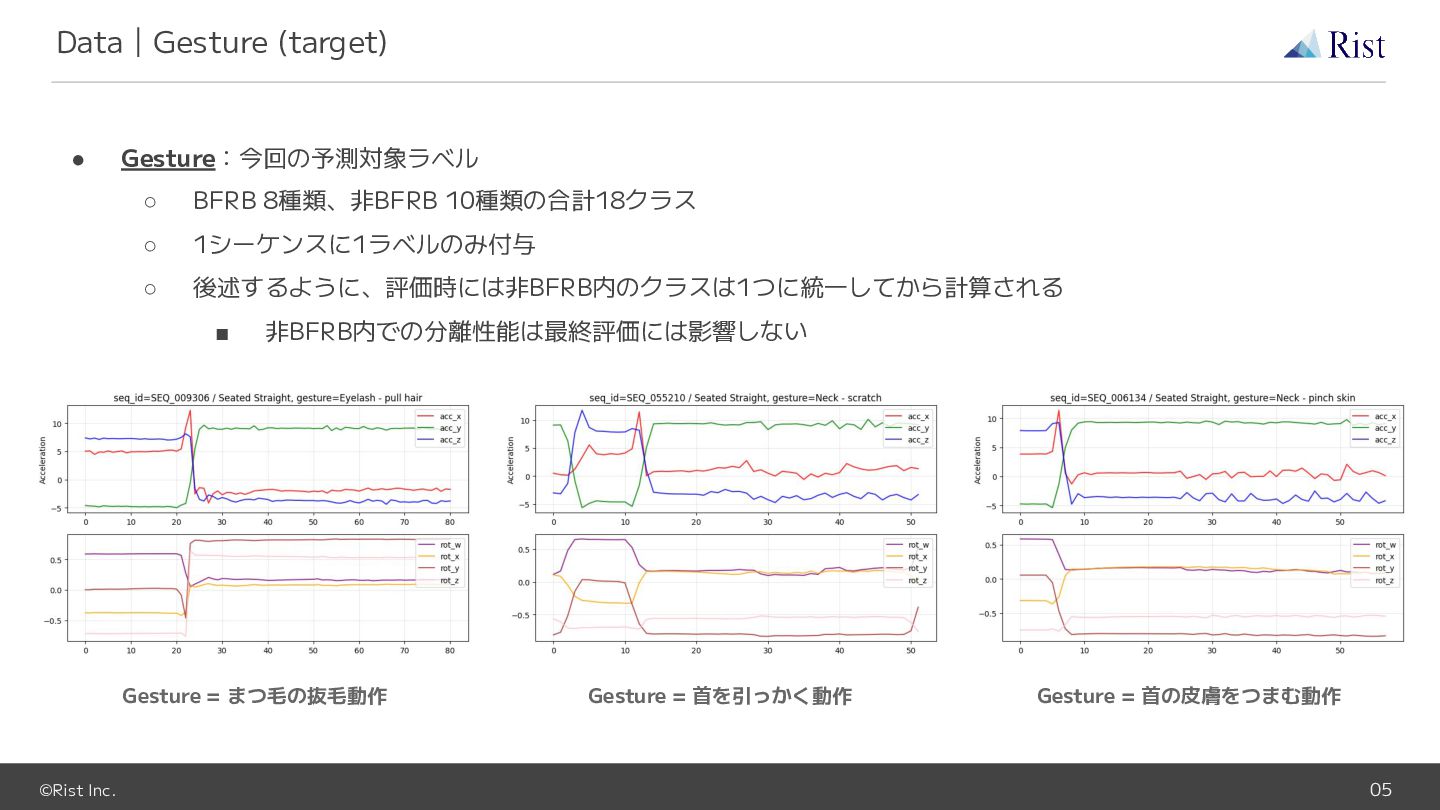
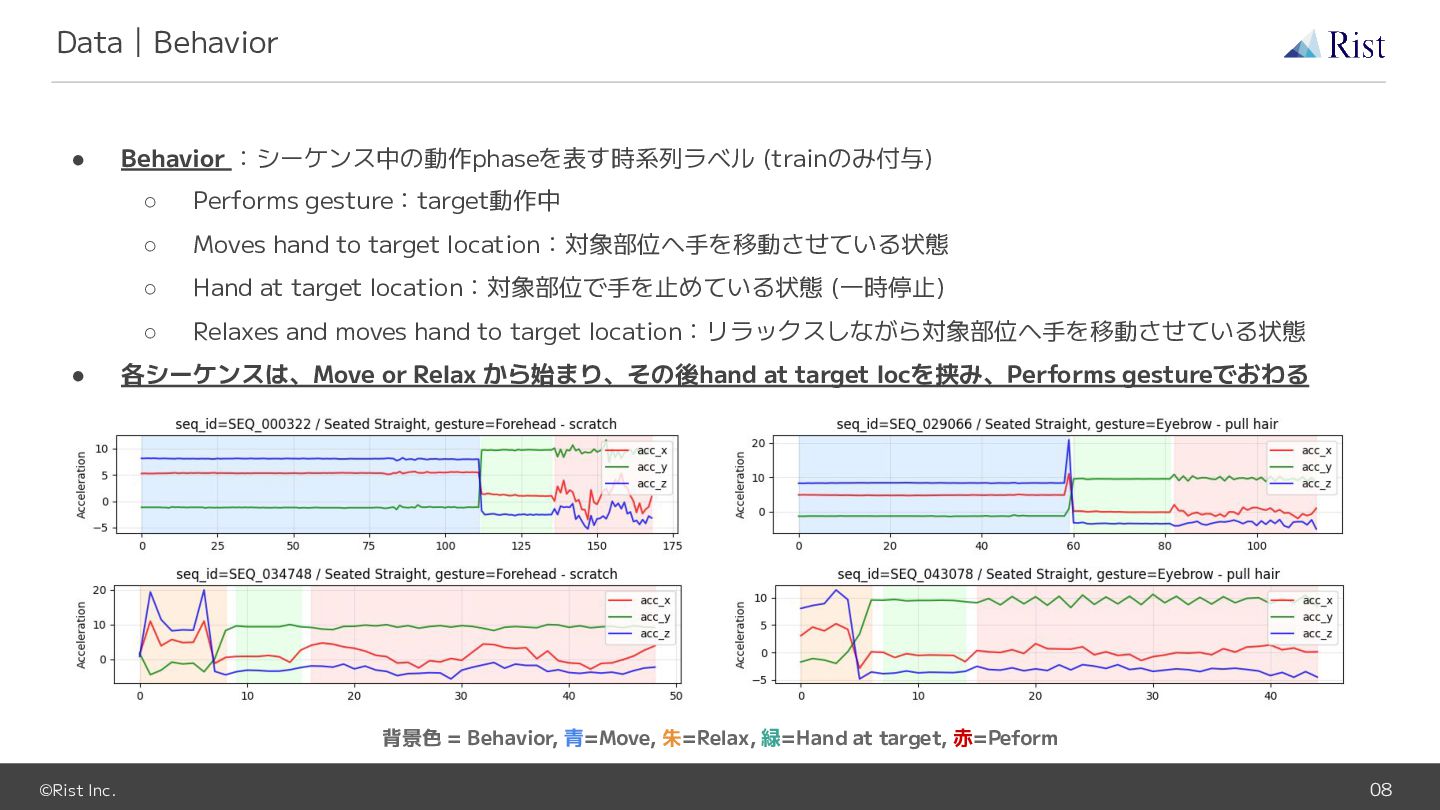
gesture:target動作中 ◦ Moves hand to target location:対象部位へ手を移動させている状態 ◦ Hand at target location:対象部位で手を止めている状態 (一時停止) ◦ Relaxes and moves hand to target location:リラックスしながら対象部位へ手を移動させている状態 • 各シーケンスは、Move or Relax から始まり、その後hand at target locを挟み、Performs gestureでおわる 背景色 = Behavior, 青=Move, 朱=Relax, 緑=Hand at target, 赤=Peform
◦ 新規予測の際、その被験者の過去の予測を参照して、まだ予測が少ないクラスへの割り当てが増えるように、 probability scoreに補正をかける(シーケンス数が貯まるほど補正が強くなるように調整) ◦ Public LBでは0.01の改善だったが、Private LBだと0.005の改善幅だった 出典:https://www.kaggle.com/competitions/cmi-detect-behavior-with-sensor-data/writeups/7th-place-solution
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
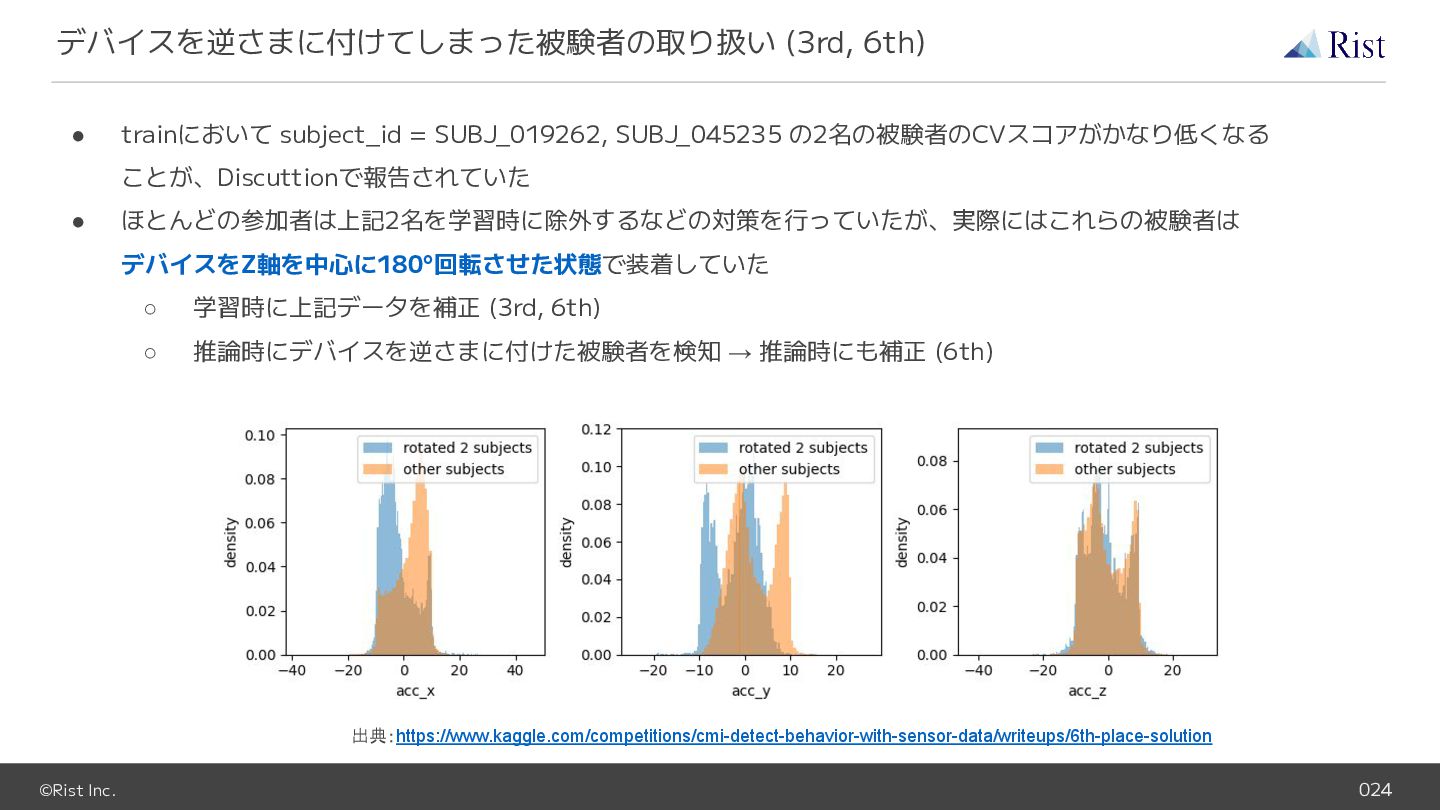{kind=link}
{kind=link}
{kind=link}
{kind=link}