Kubernetes祭り #1 登壇資料
https://3-shake.connpass.com/event/389755/
近年、LLMの開発現場では、学習からデプロイ、運用までを支える基盤として Kubernetes の活用が進んでいます。本セッションでは、学習基盤を構築する際の分散学習やジョブスケジューリングの考慮点を解説し、LLMの運用課題に対応する「LLMOps」のプラクティスもご紹介します。学習基盤の設計に取り組む方、Kubernetes と AI 運用の概要を把握したい方向けの入門的な内容です。
{kind=link}
{kind=link}
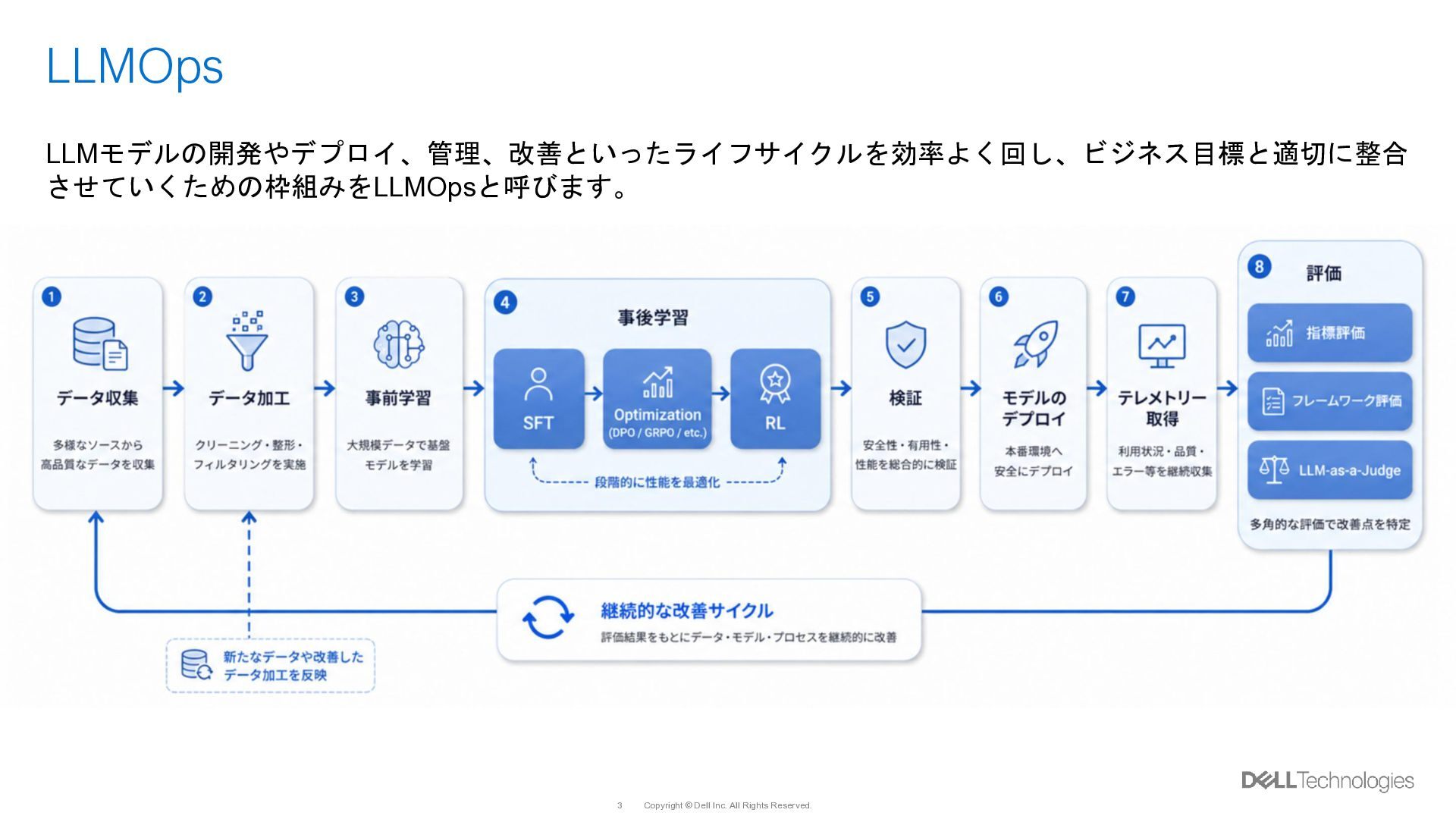{kind=link}
{kind=link}
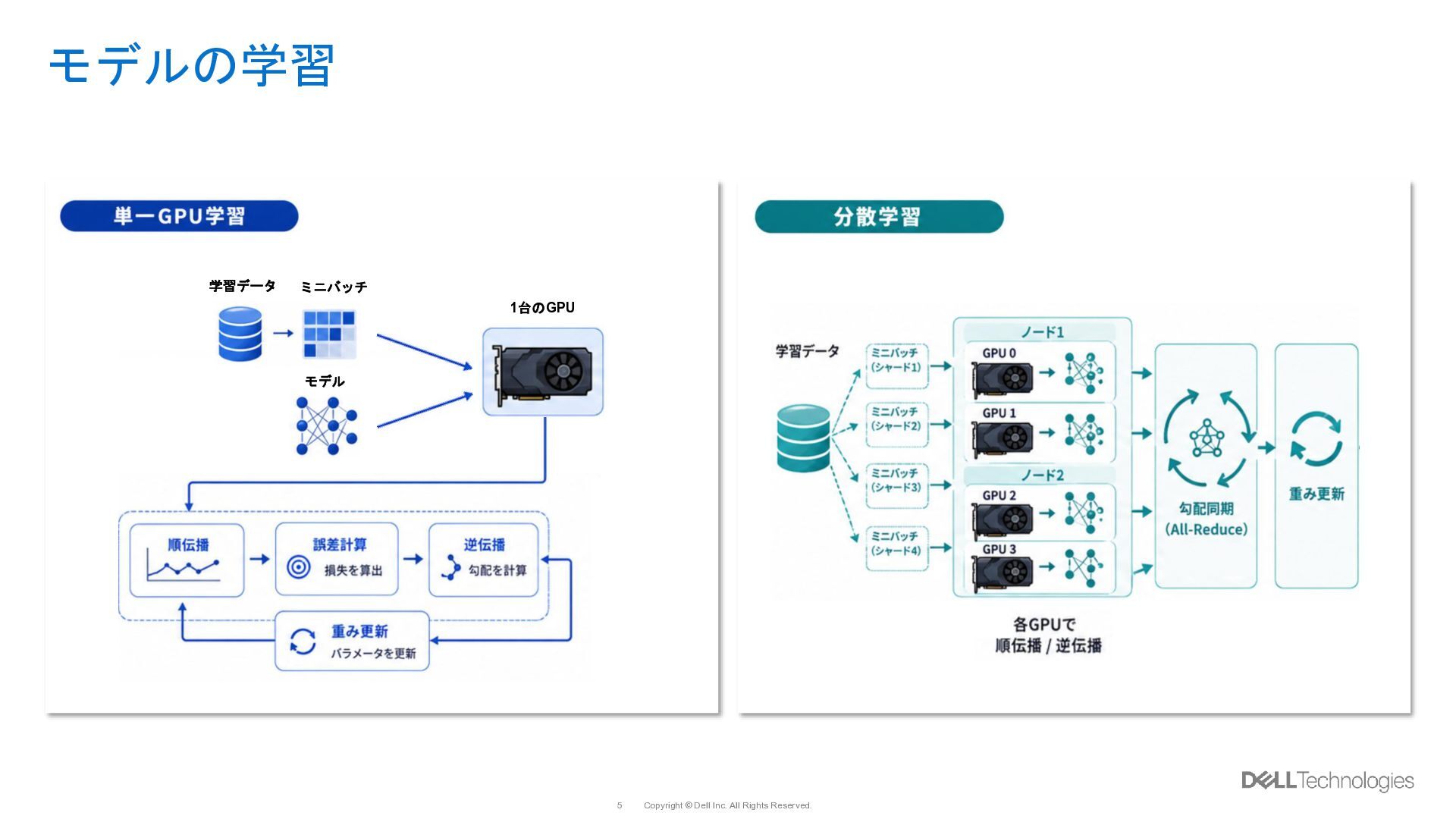{kind=link}
{kind=link}
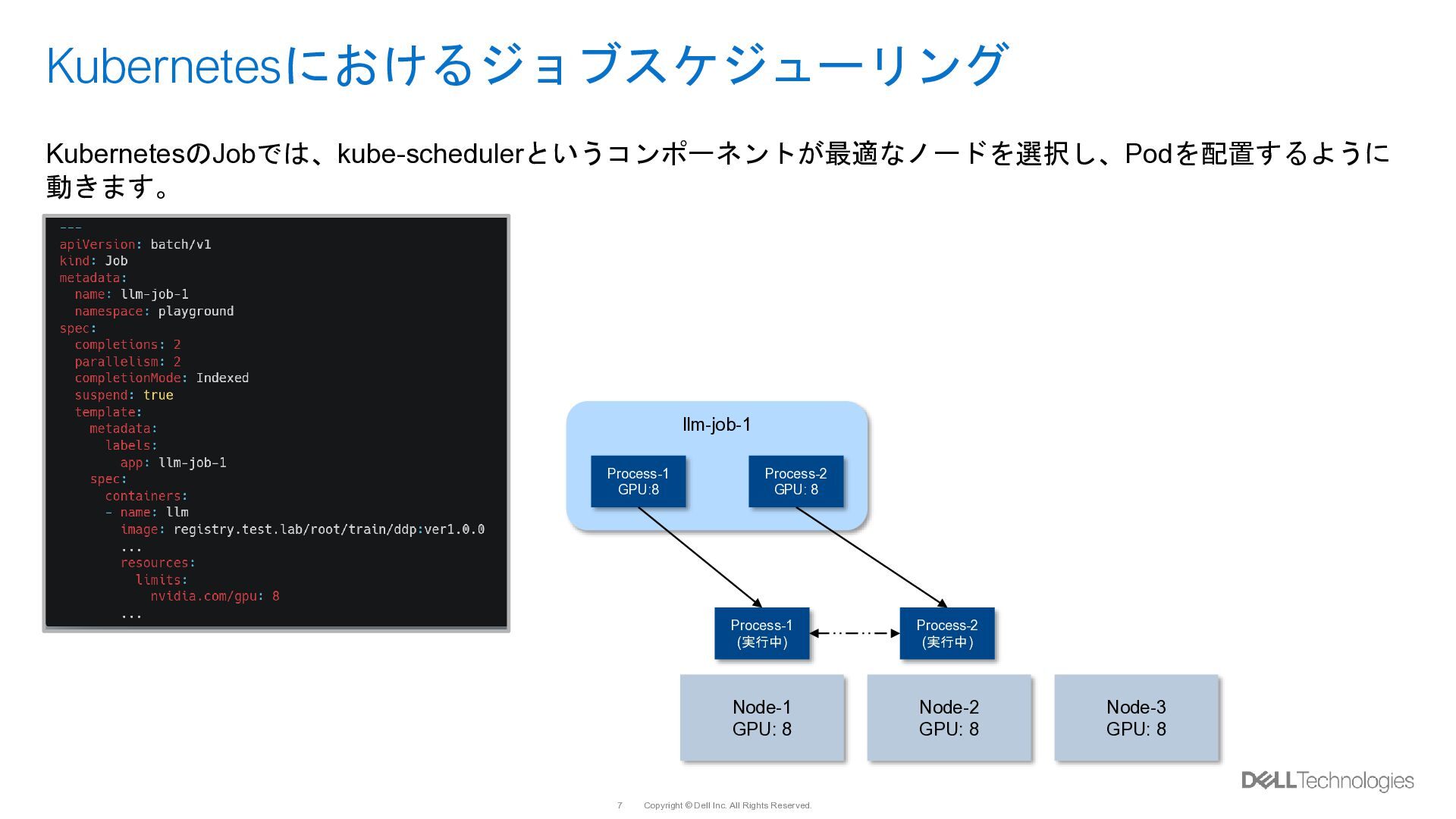{kind=link}
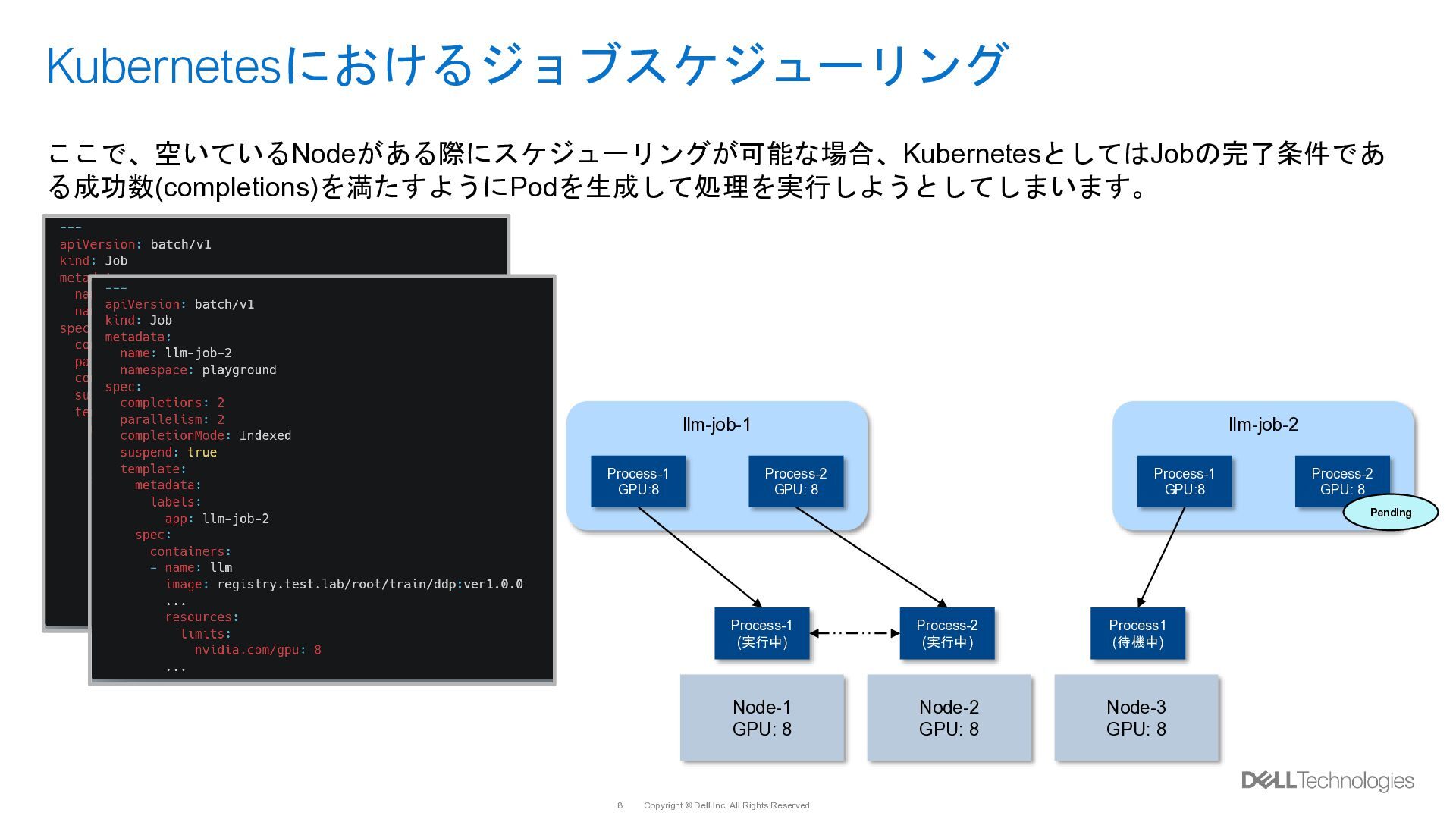{kind=link}
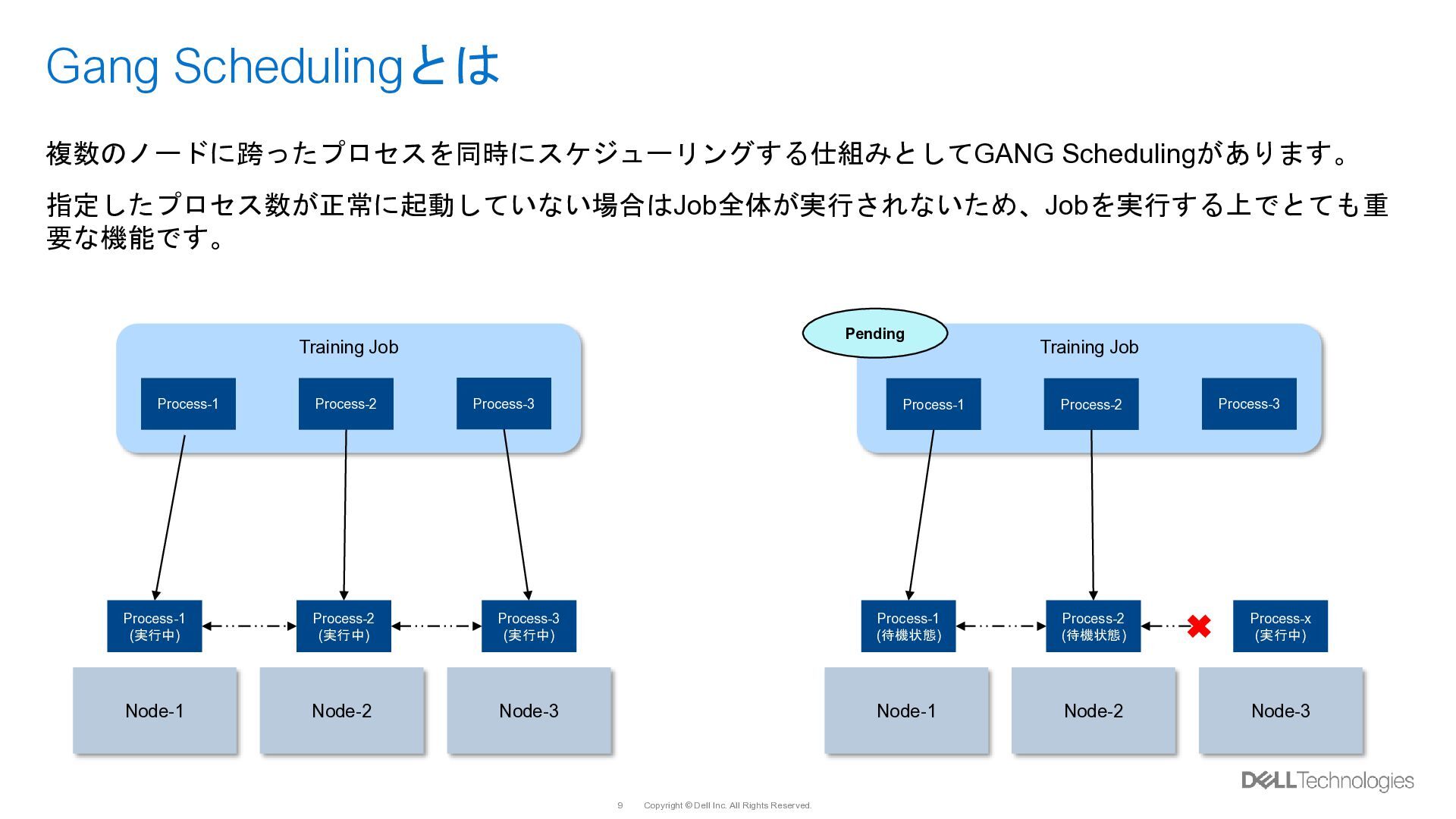{kind=link}
{kind=link}
{kind=link}
{kind=link}
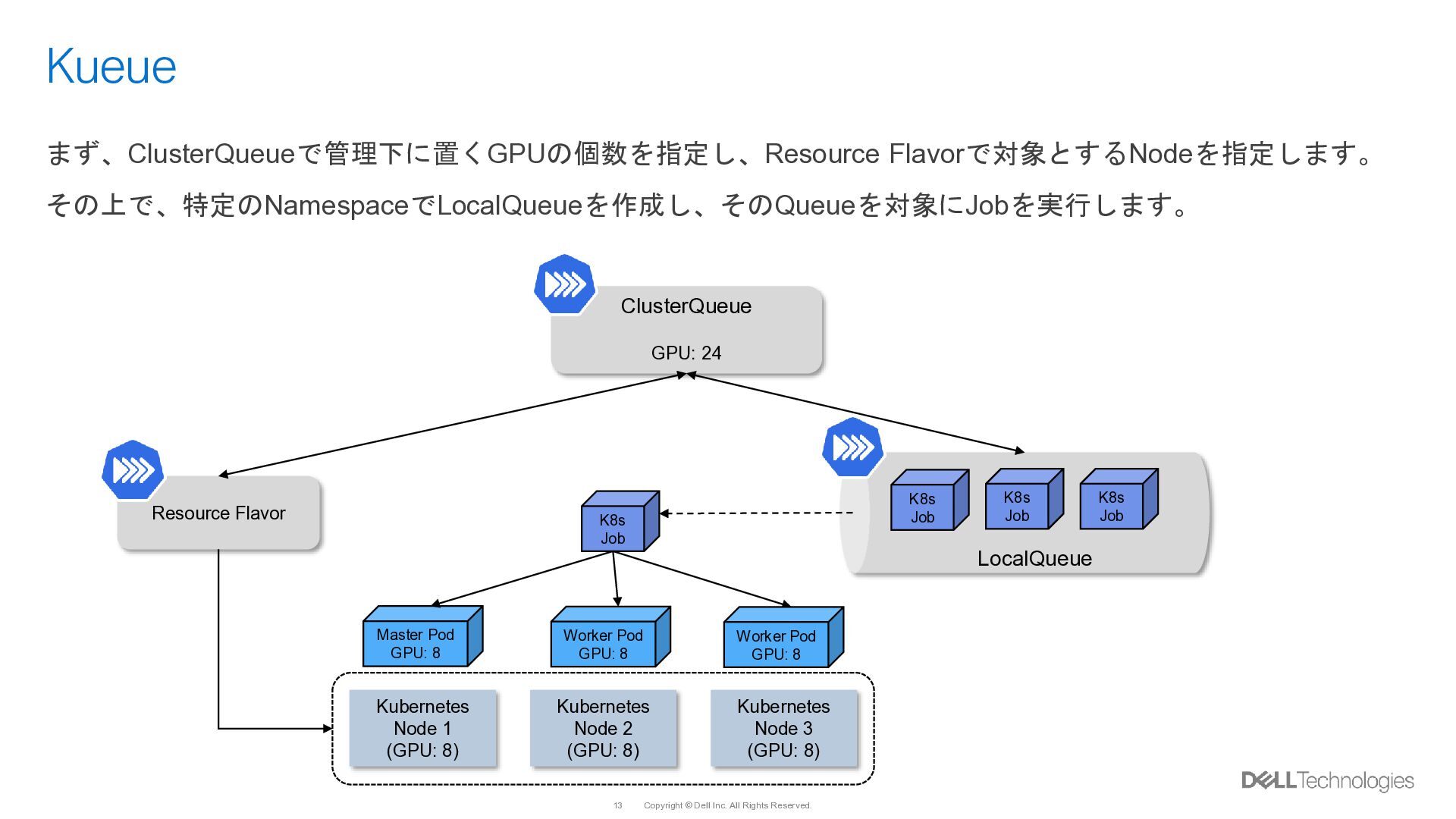{kind=link}
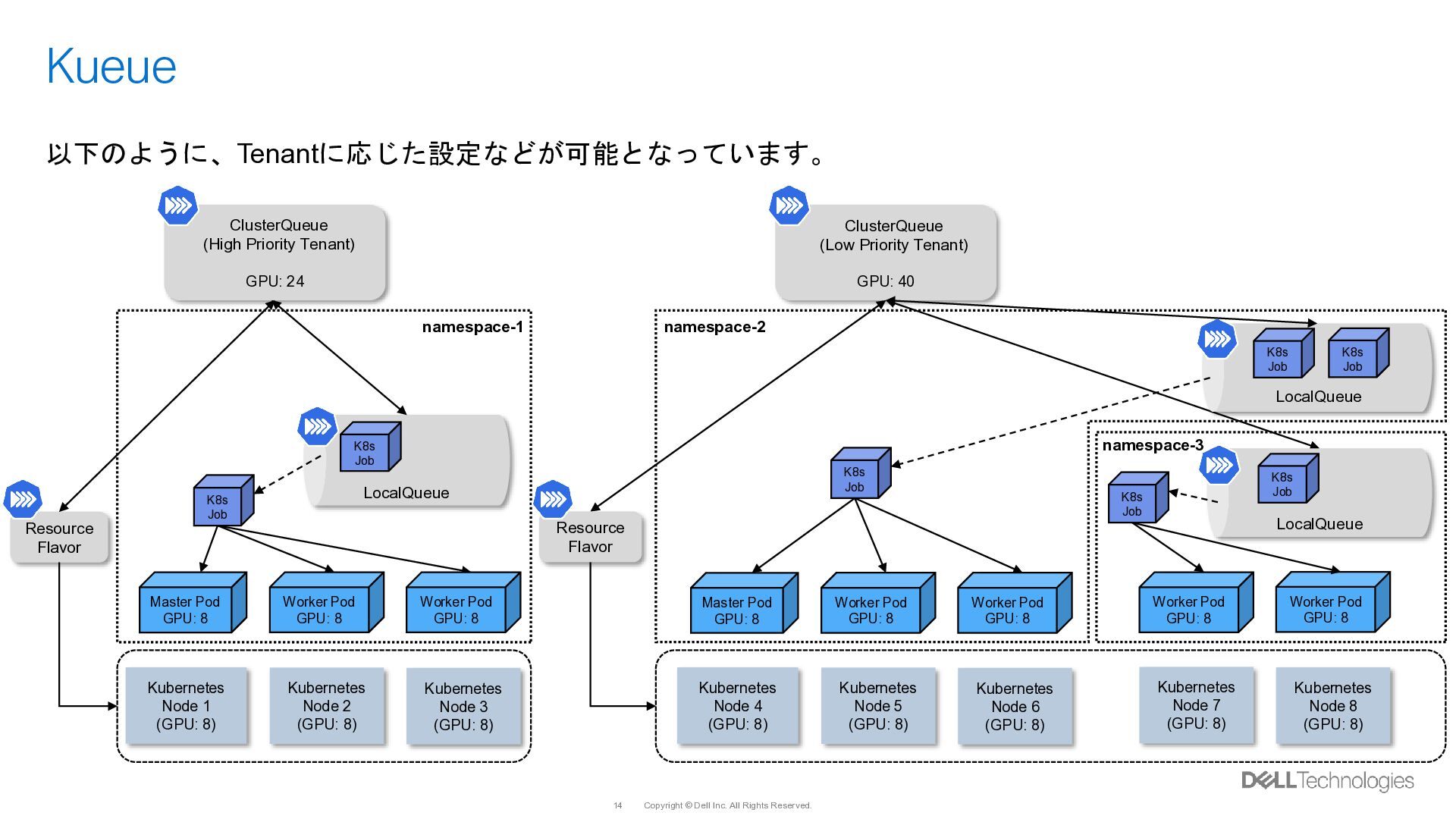{kind=link}
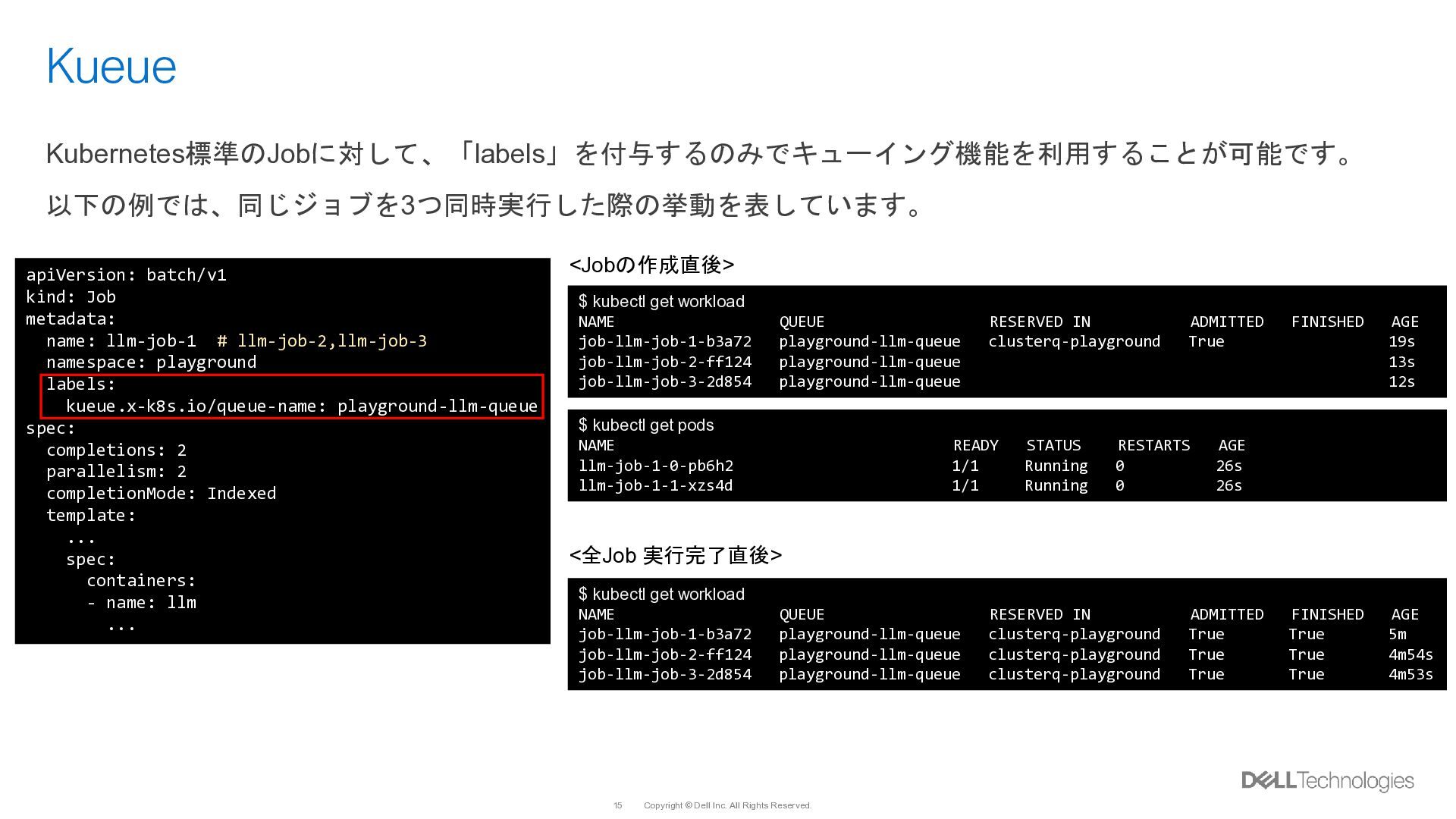{kind=link}
{kind=link}
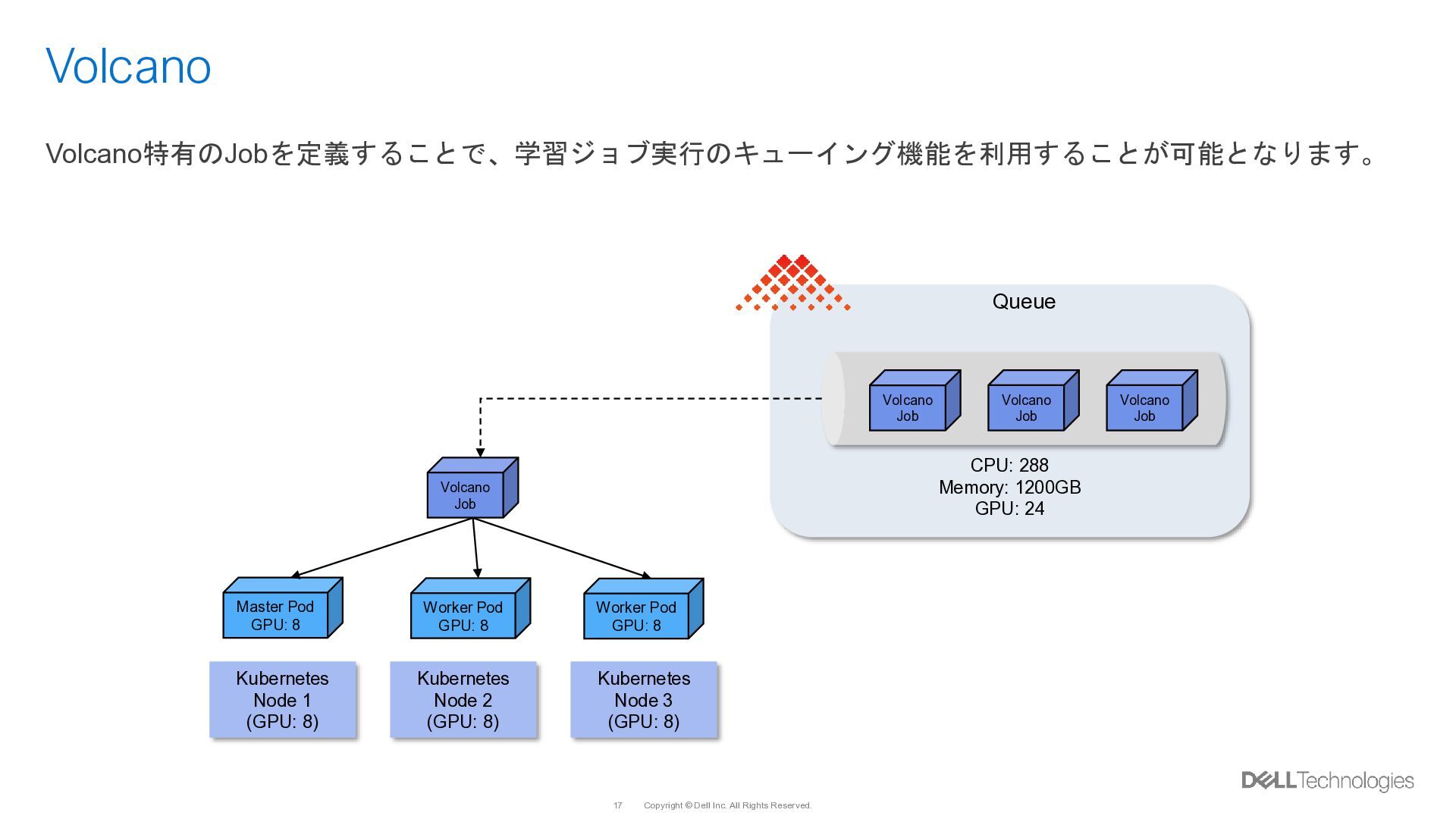{kind=link}
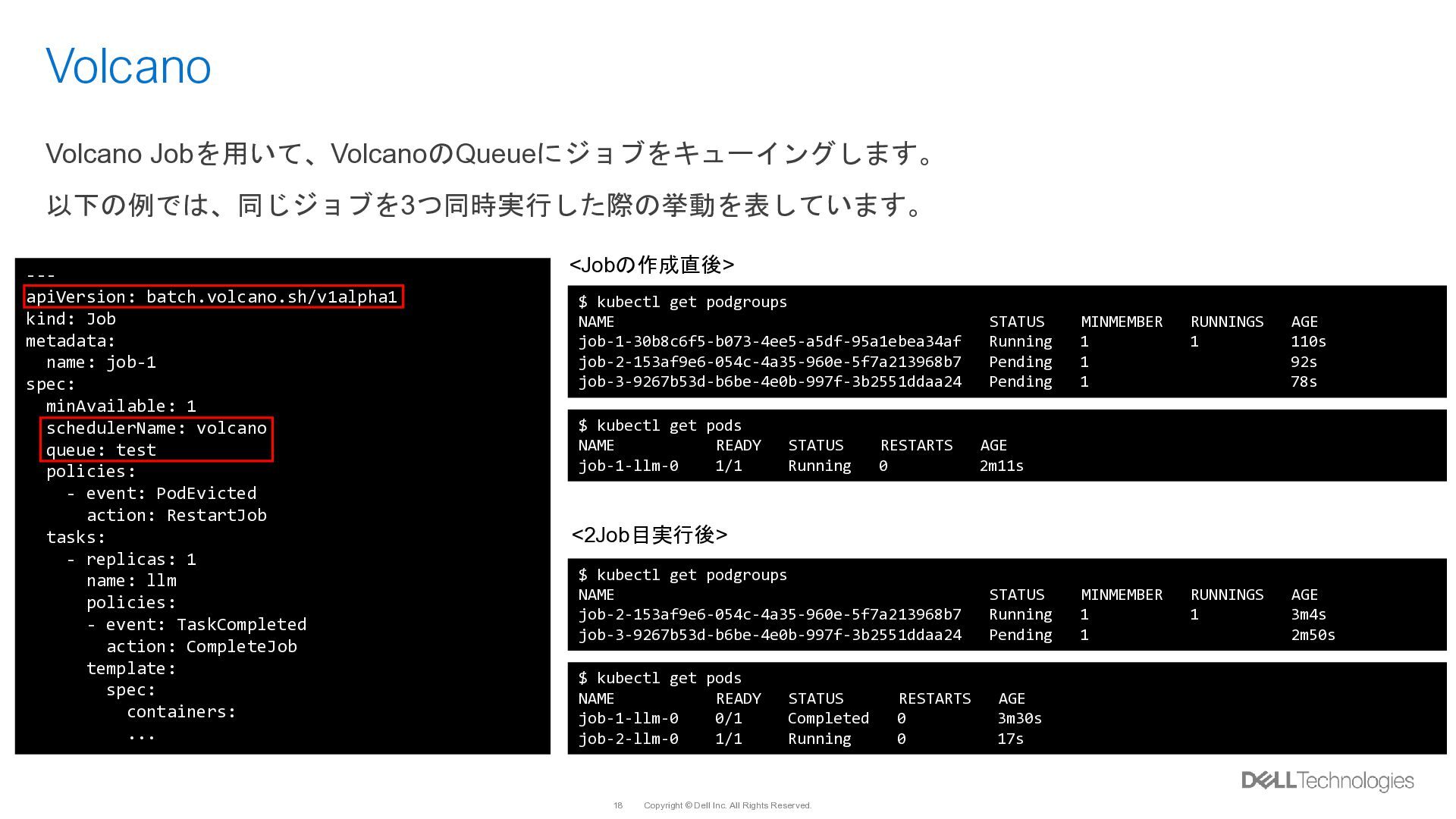{kind=link}
{kind=link}
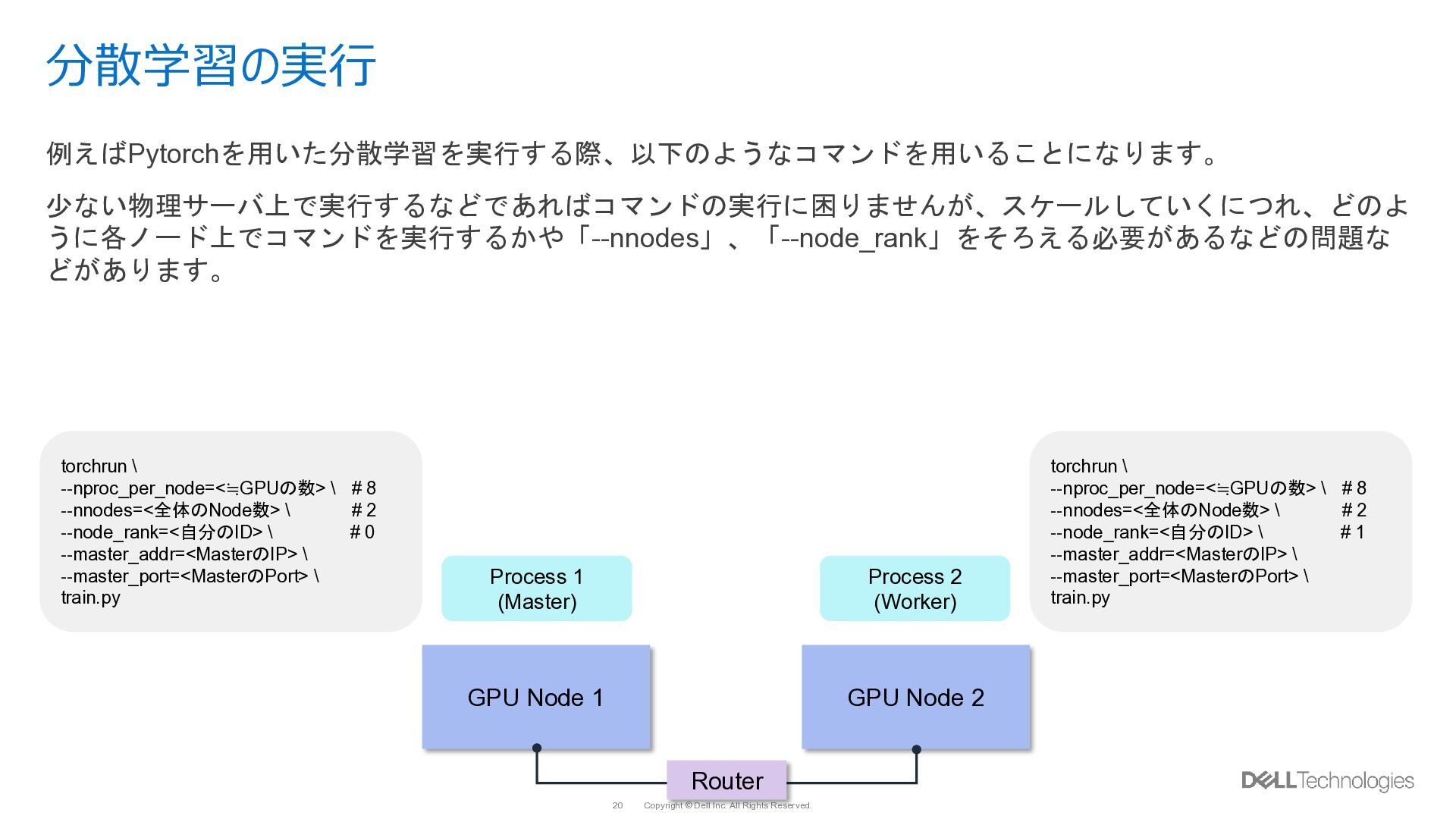{kind=link}
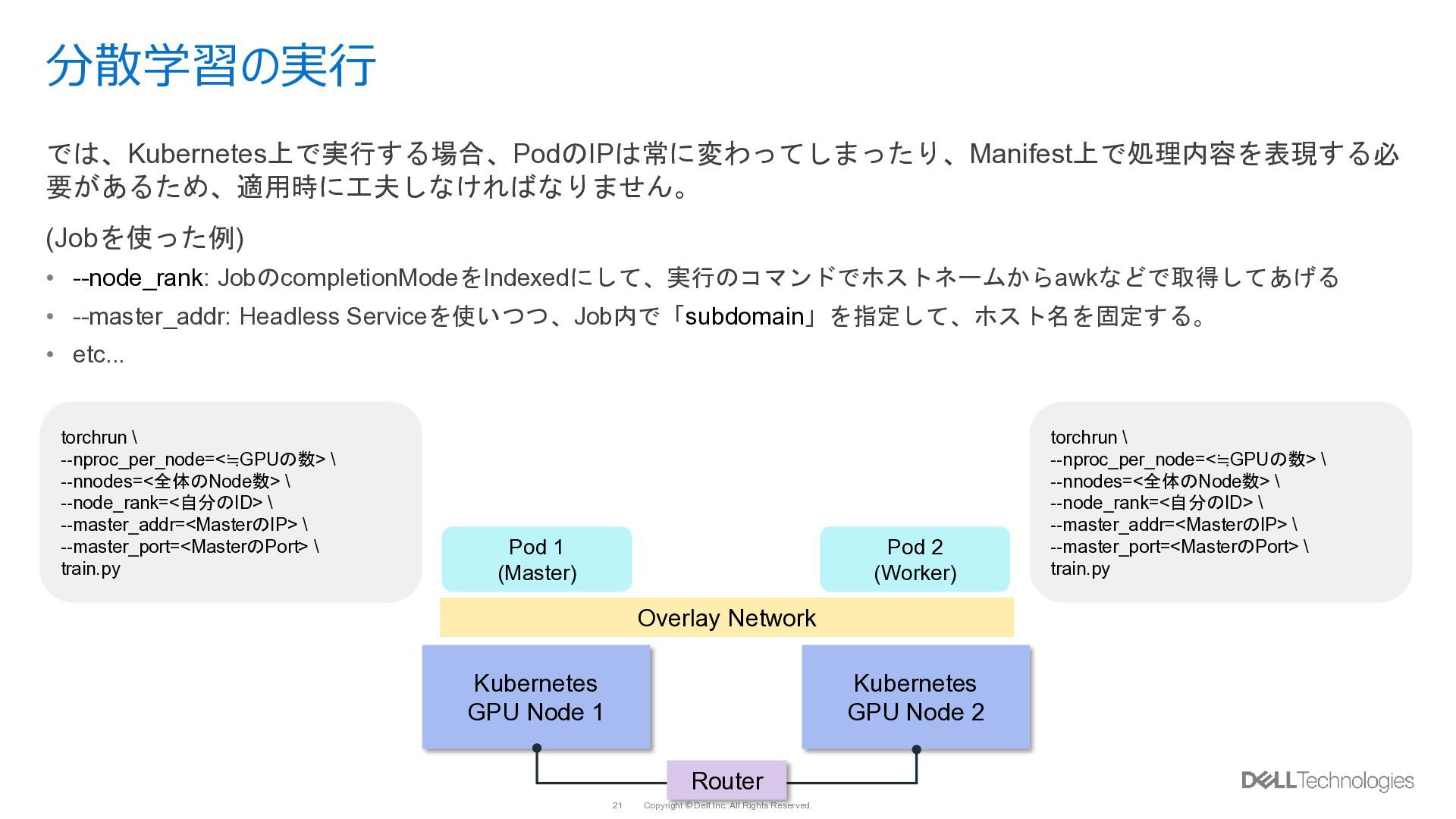{kind=link}
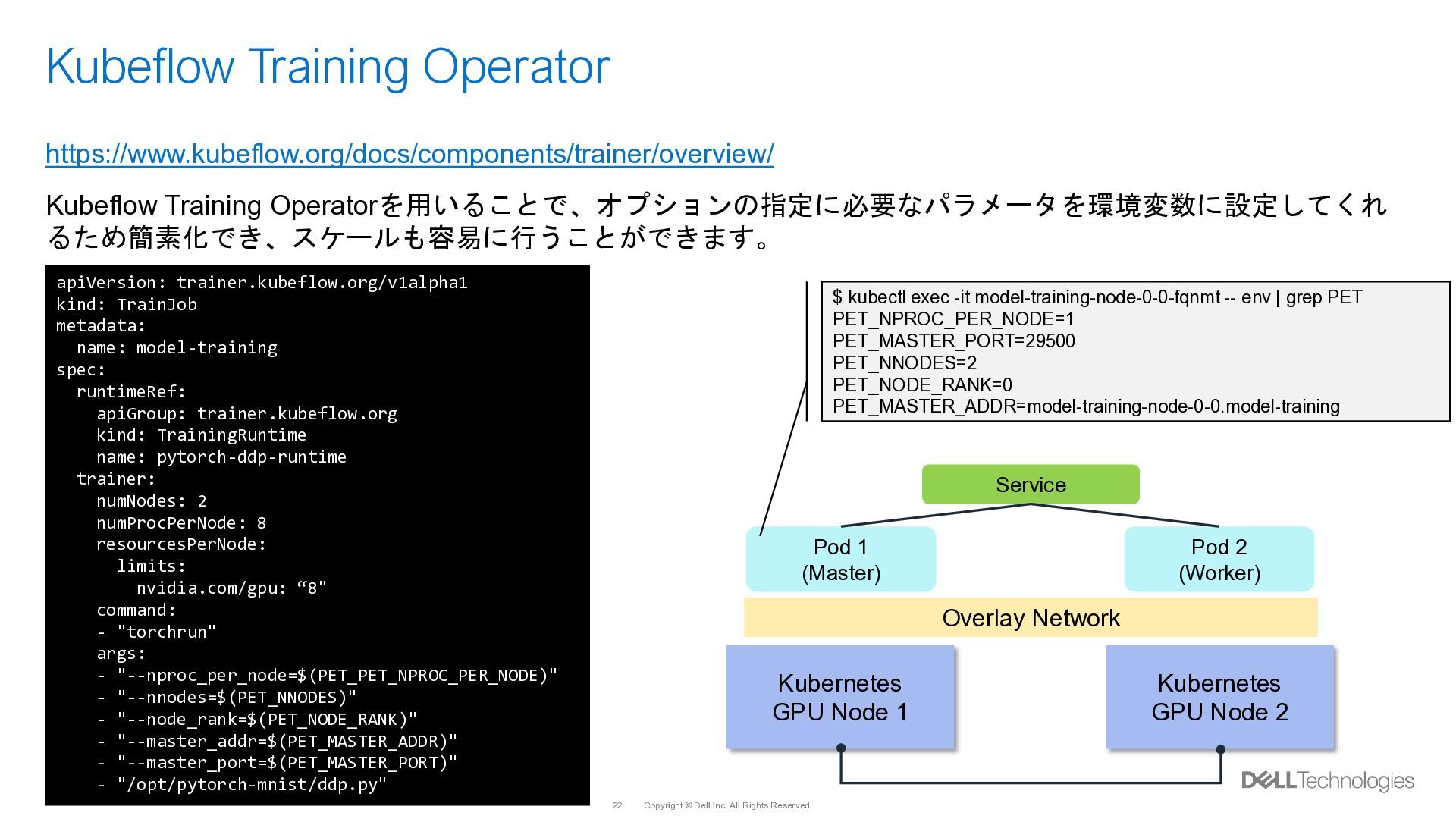{kind=link}
{kind=link}
{kind=link}
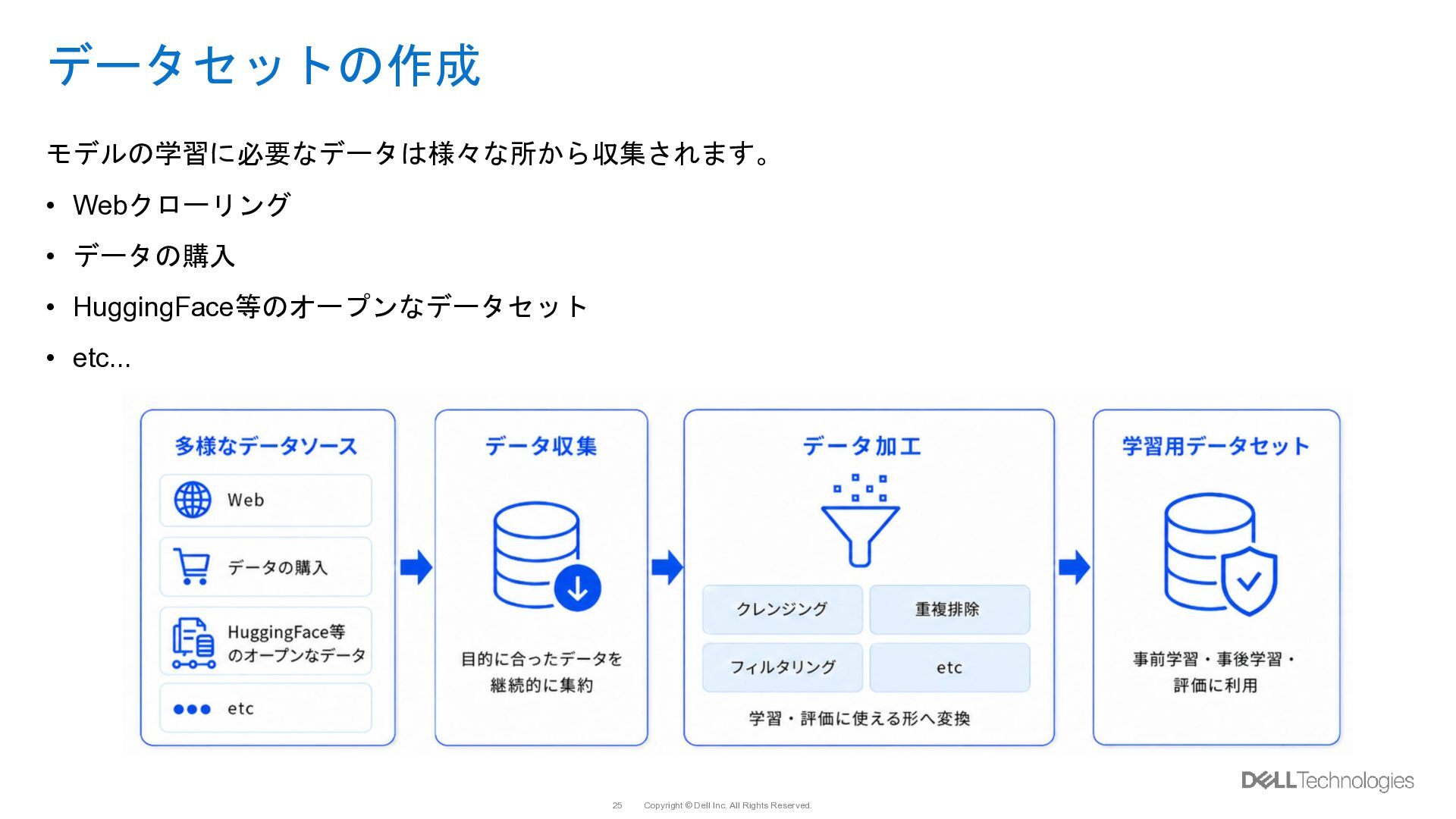{kind=link}
{kind=link}
{kind=link}
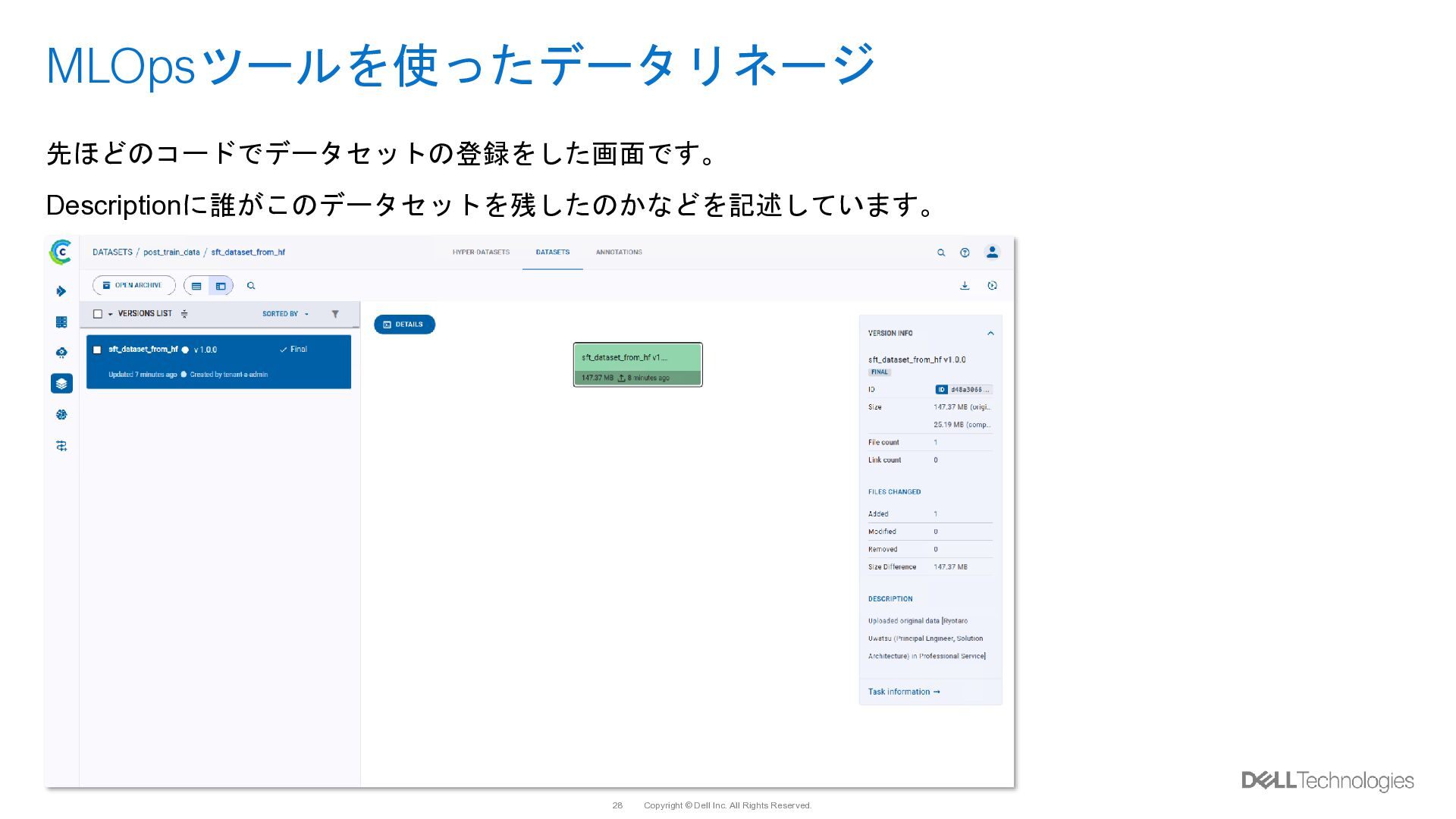{kind=link}
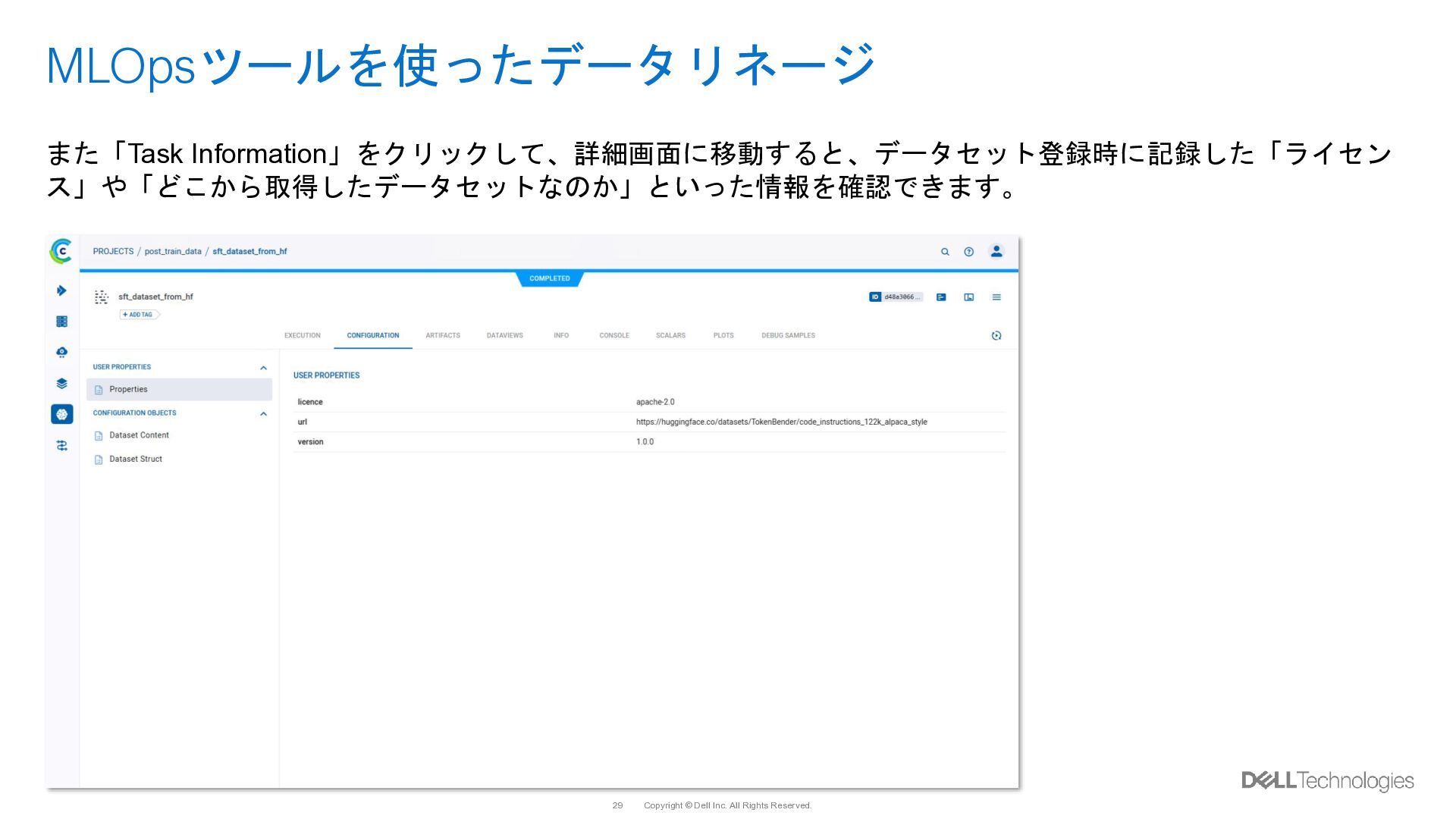{kind=link}
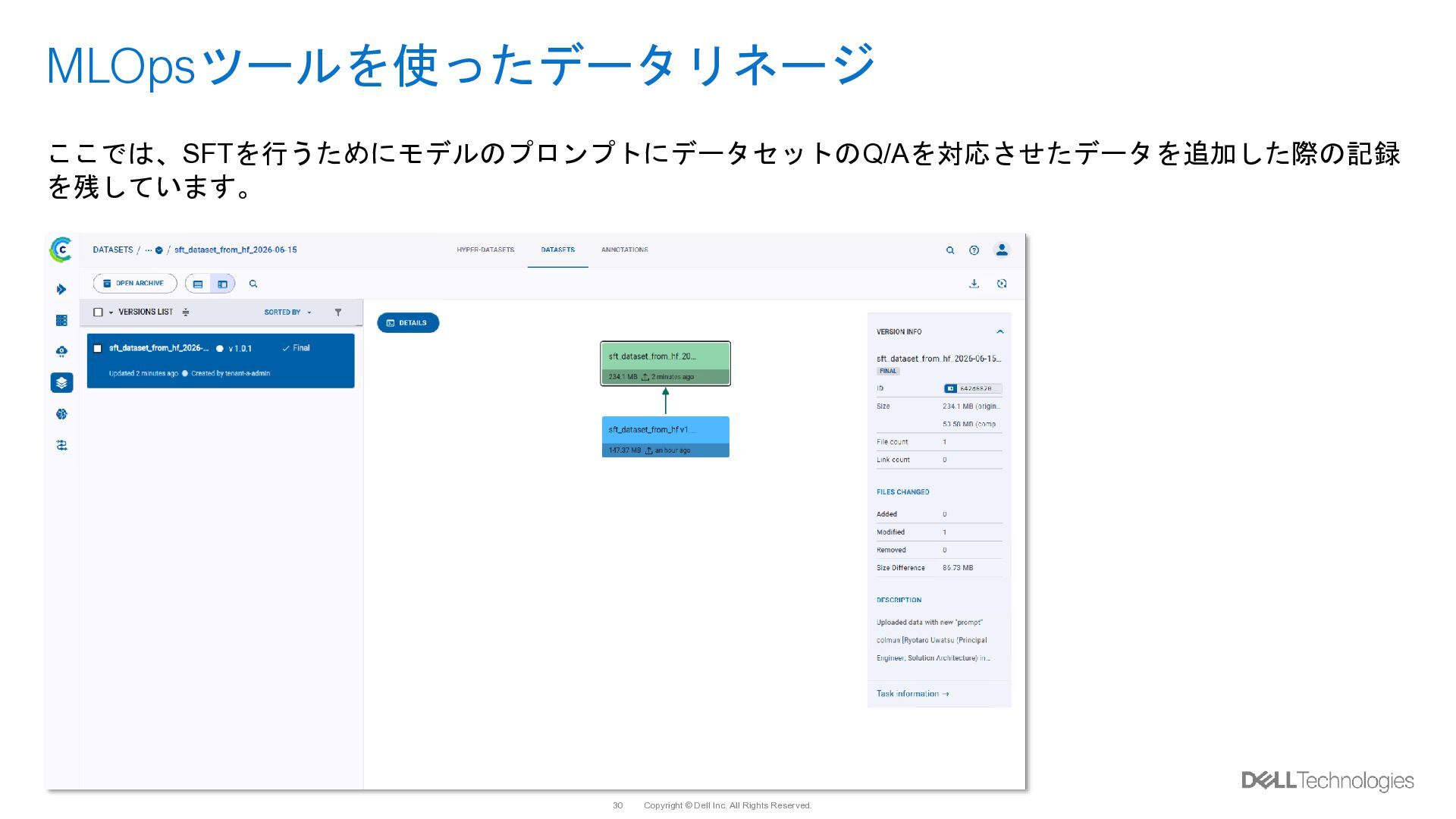{kind=link}
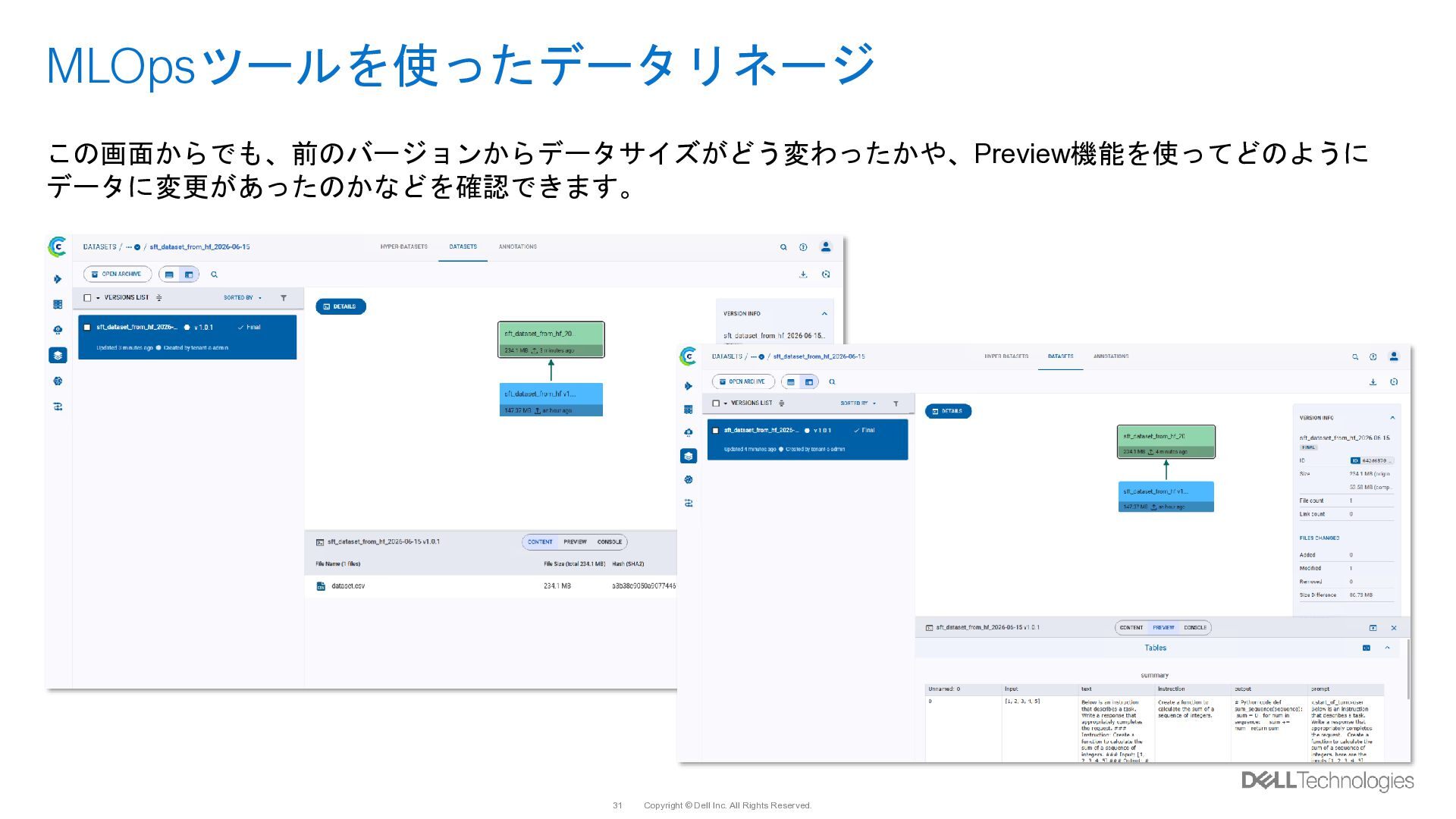{kind=link}
{kind=link}
{kind=link}