本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
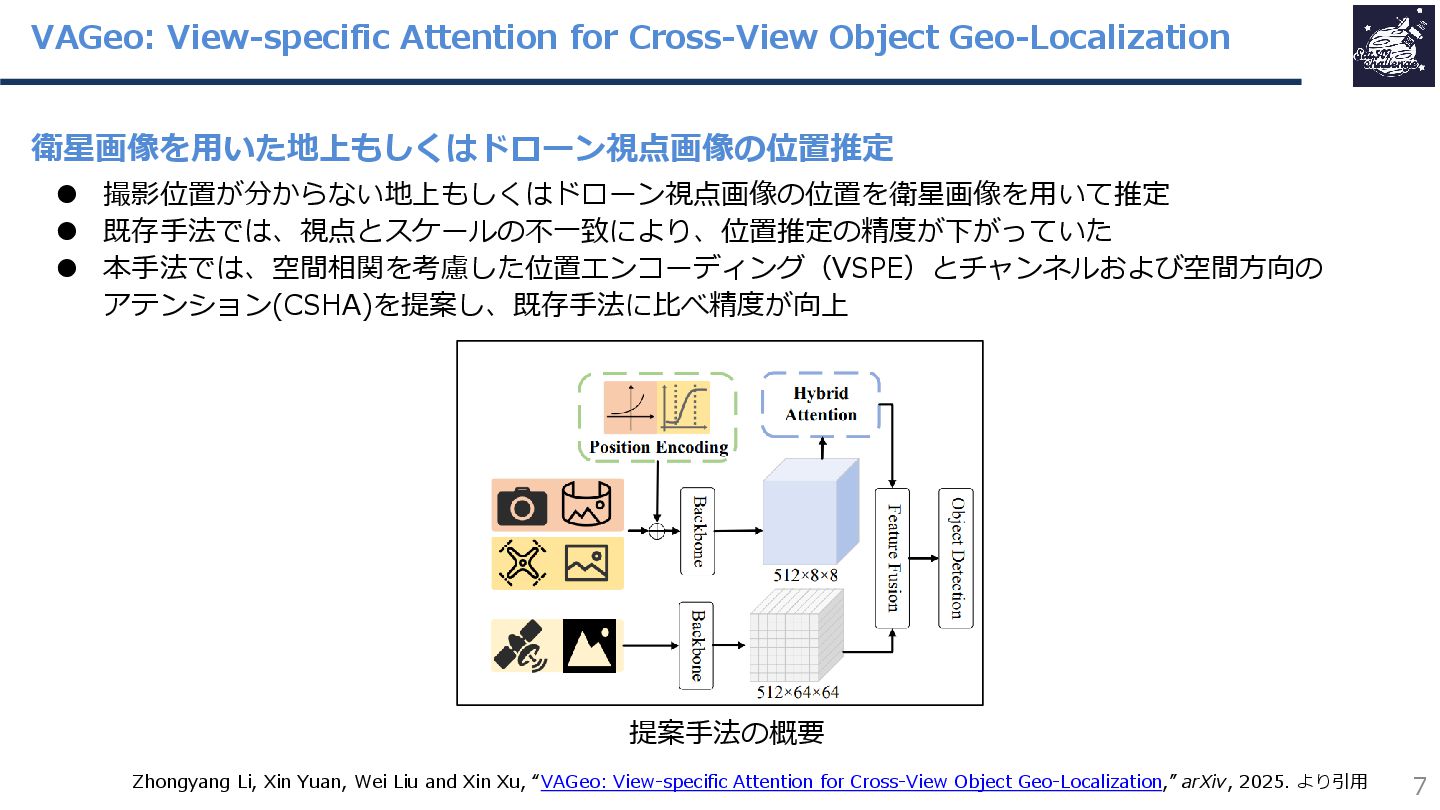
紹介する論文は、「VAGeo: View-specific Attention for Cross-View Object Geo-Localization」です。
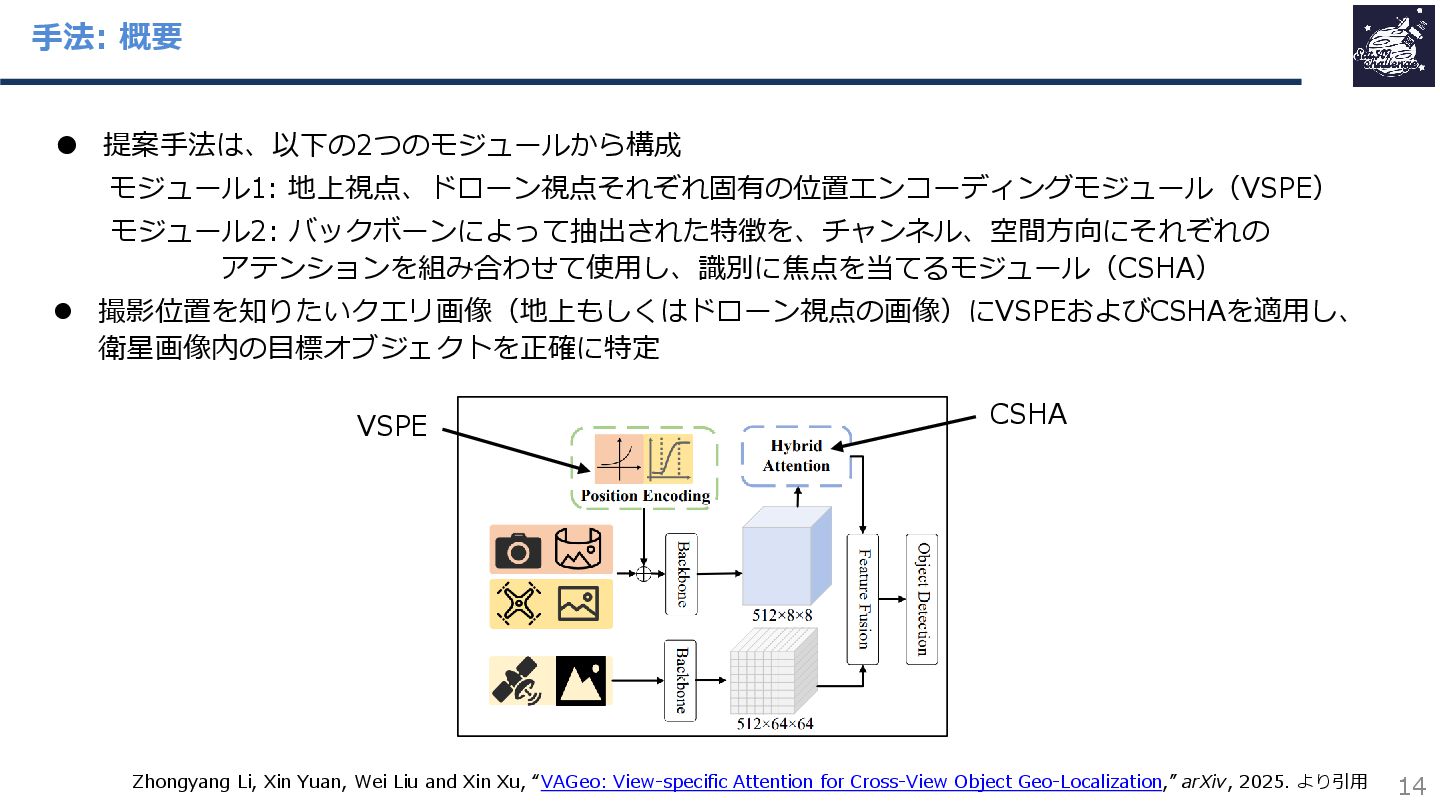
本研究では、位置情報が分からない地上やドローン視点の画像に映る物体の位置を、衛星画像を手がかりに推定する手法を提案しています。この研究では、地上・ドローン視点の画像と衛星画像では見え方が大きく異なるため、AIモデルがその違いを理解し、画像のどこに注目すればよいかを適切に学習できるよう工夫しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
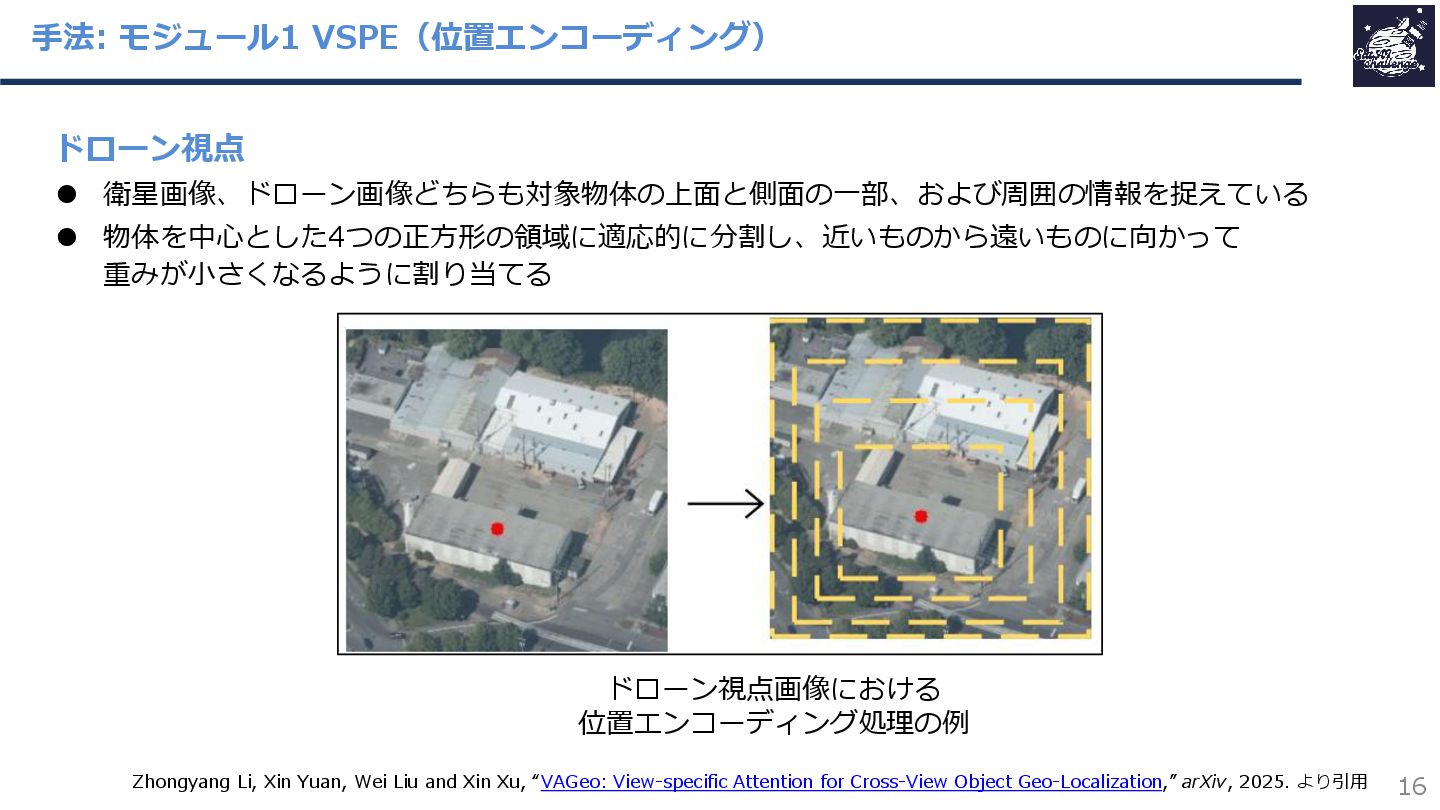{kind=link}
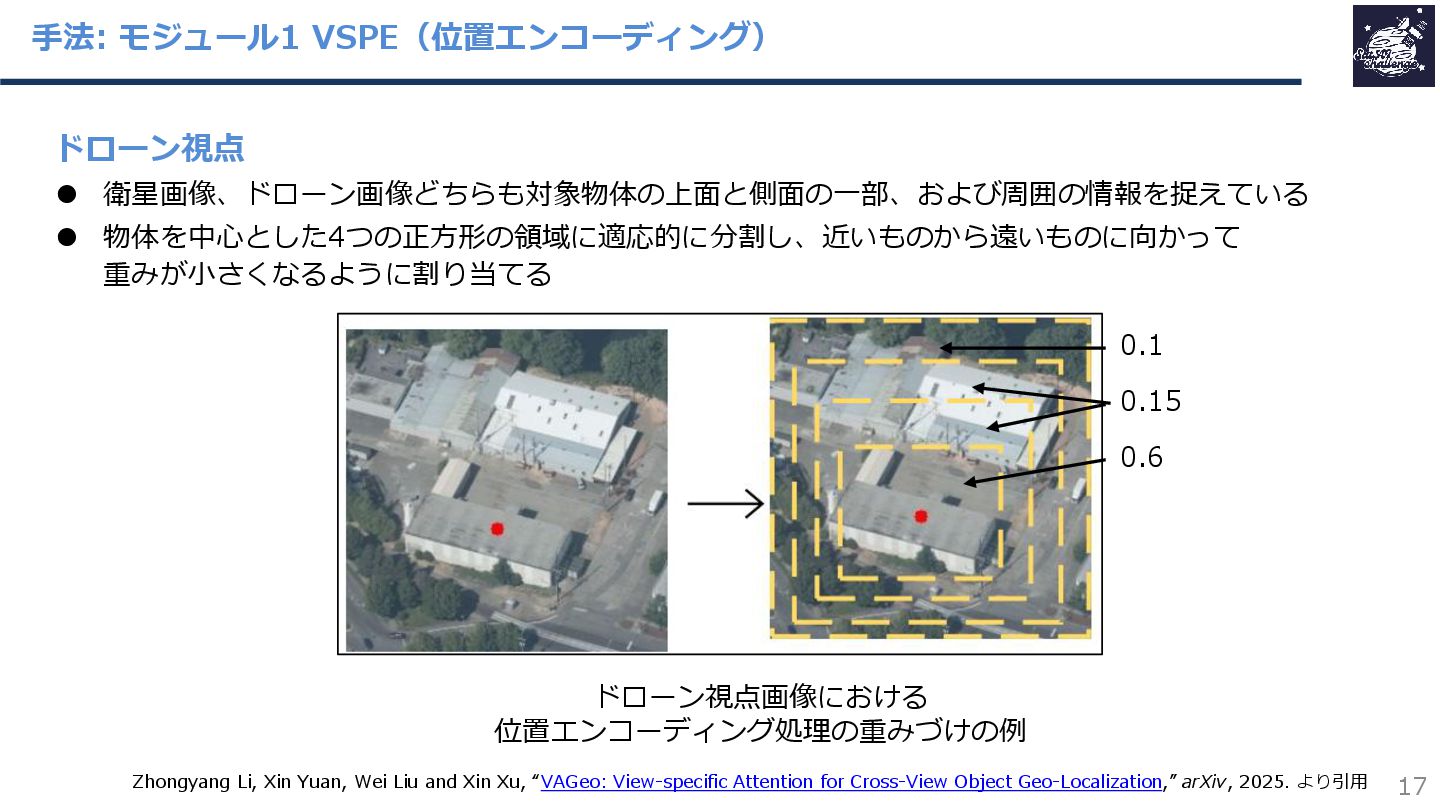{kind=link}
{kind=link}
{kind=link}
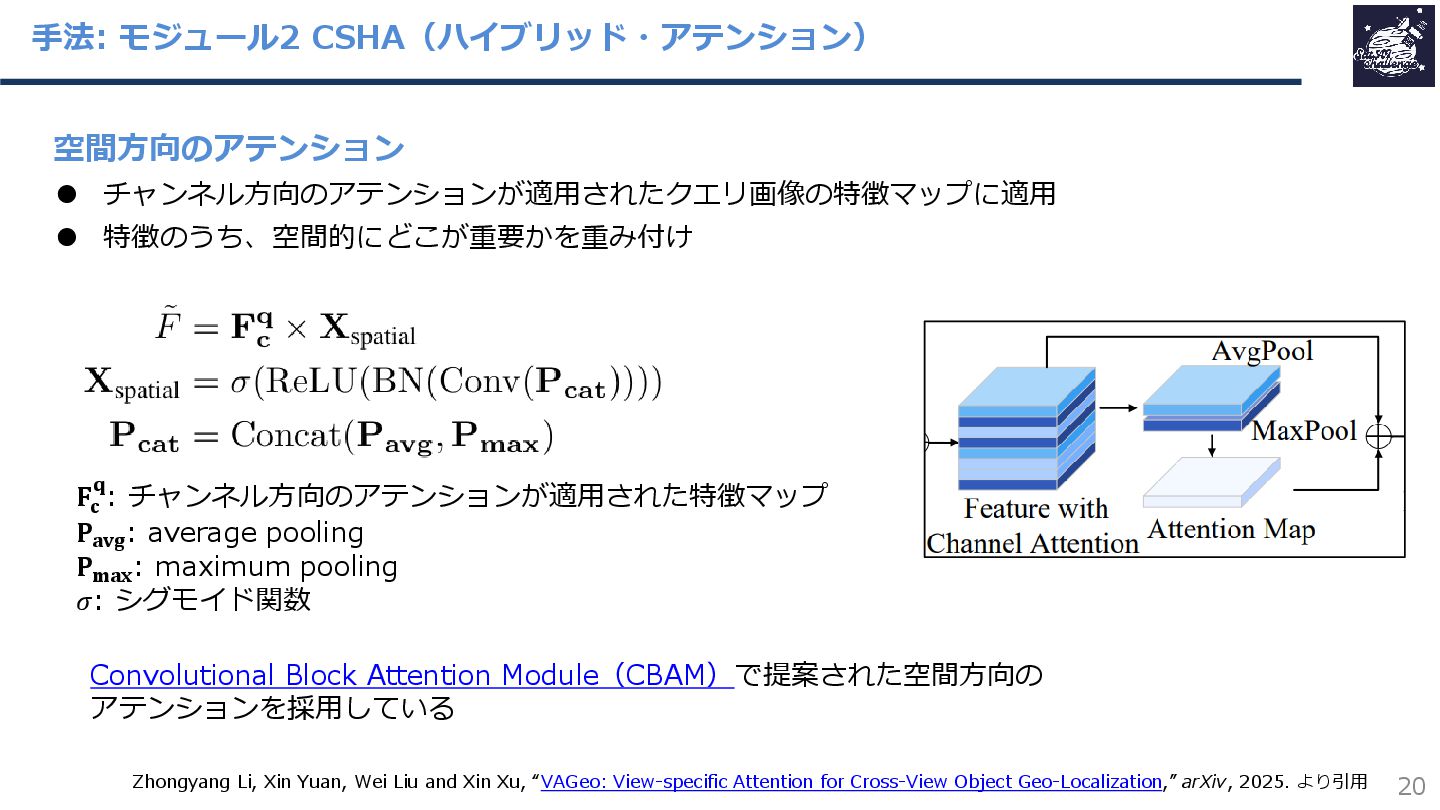{kind=link}
{kind=link}
{kind=link}
{kind=link}
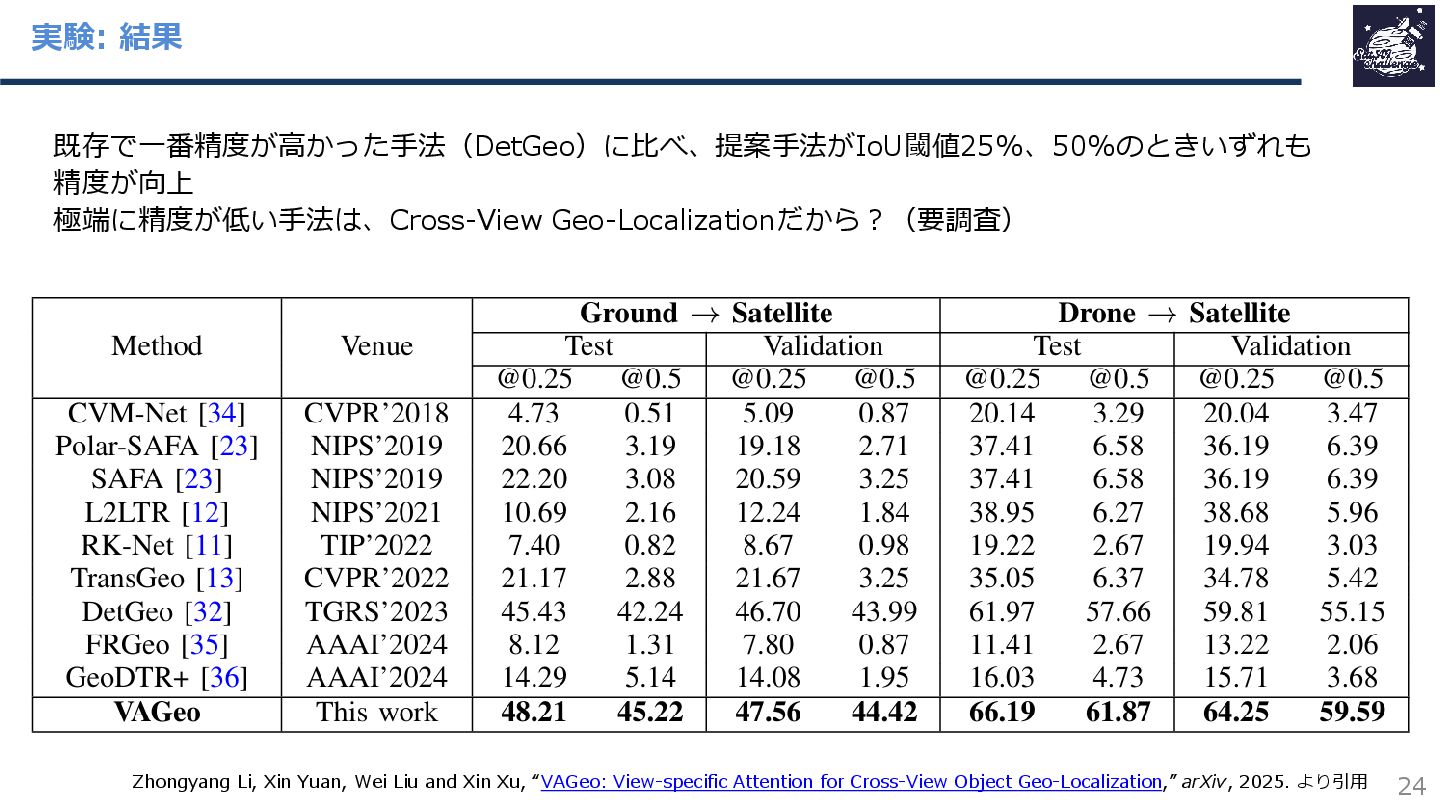{kind=link}
{kind=link}
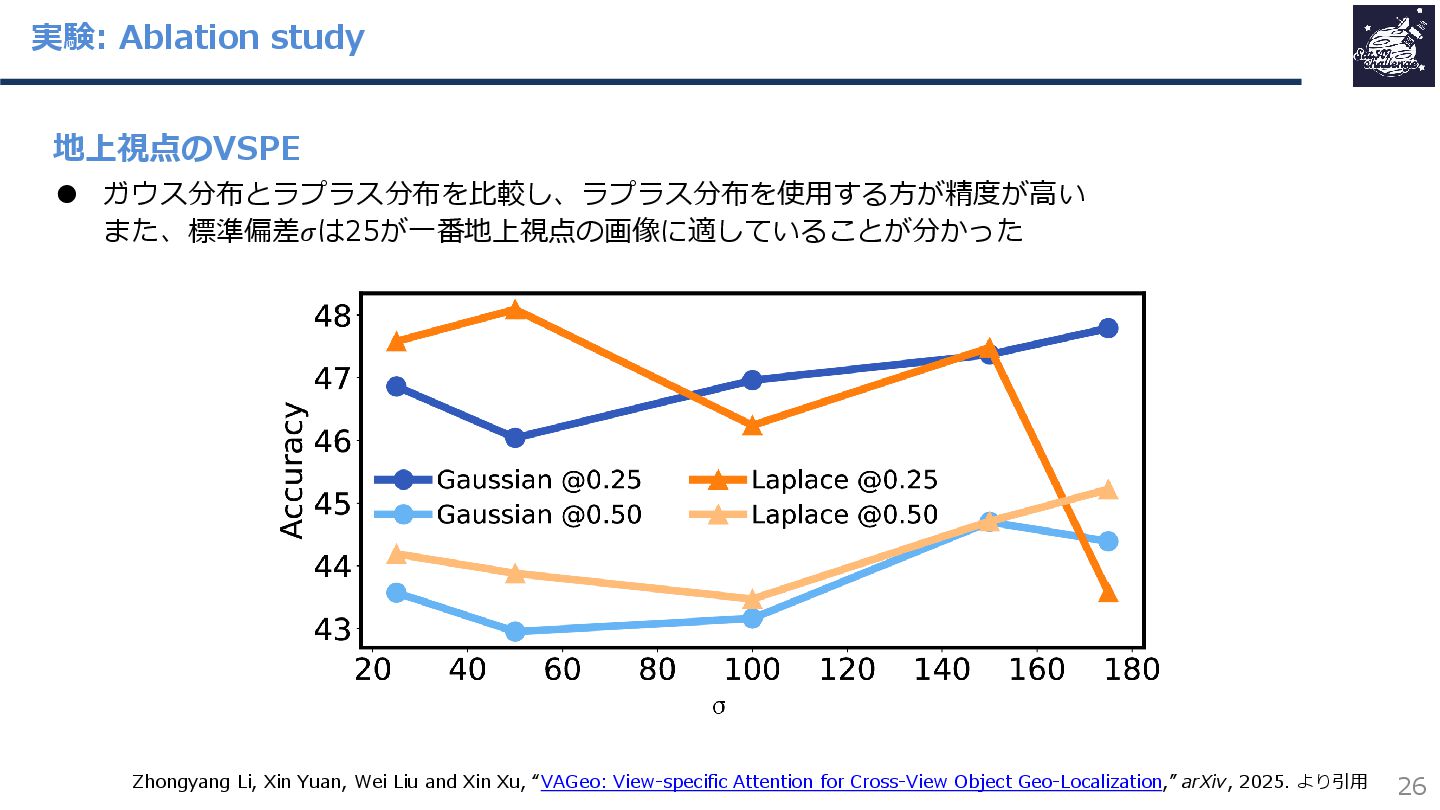{kind=link}
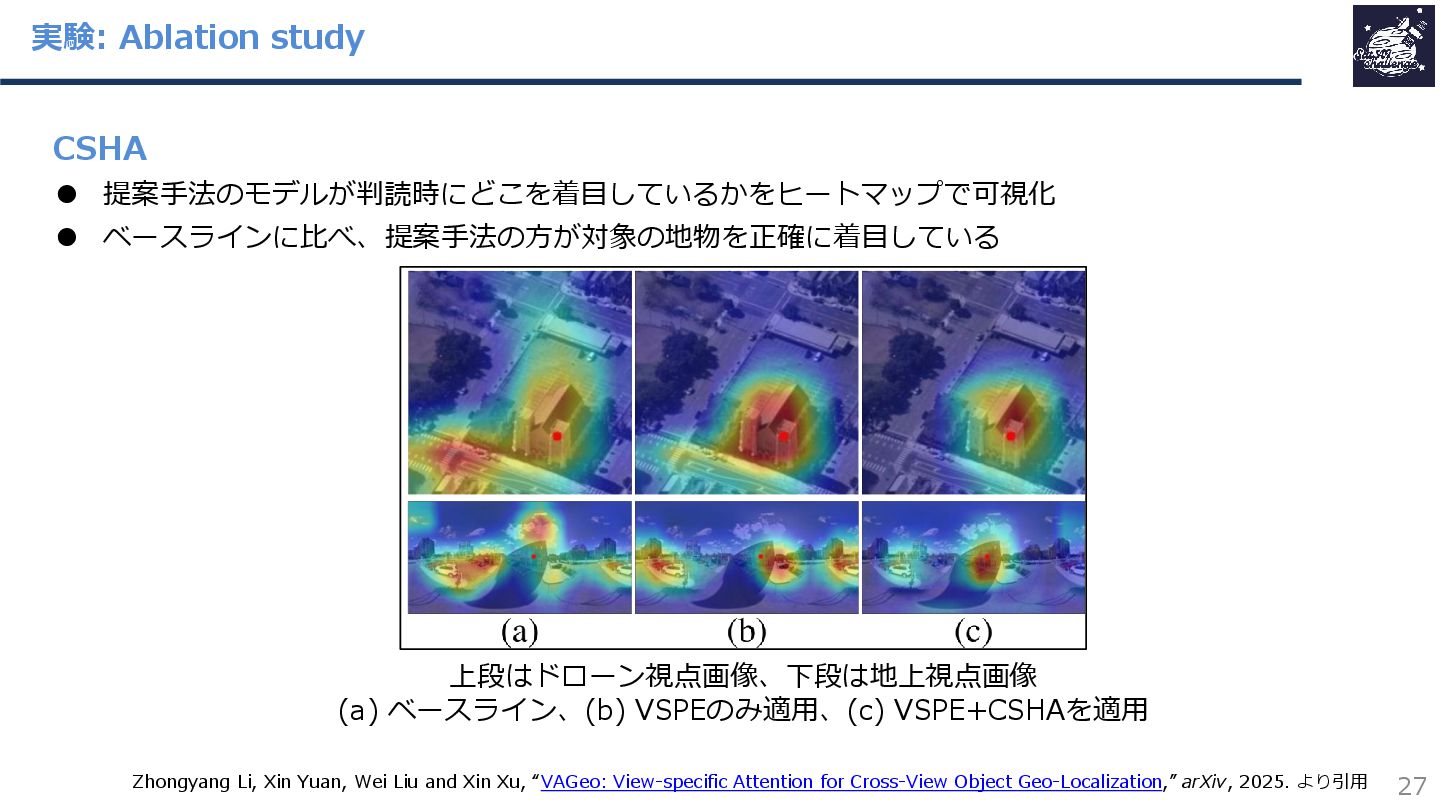{kind=link}
{kind=link}
{kind=link}