Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
snlp2025_prevent_llm_spikes
Search
Sho Takase
August 27, 2025
Research
520
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
snlp2025_prevent_llm_spikes
Sho Takase
August 27, 2025
More Decks by Sho Takase
See All by Sho Takase
snlp2024_multiheadMoE
takase
0
730
snlp2023_beyond_neural_scaling_laws
takase
0
460
snlp2023_rogue_scores
takase
0
450
[SNLP2022] ABC: Attention with Bounded-memory Control
takase
0
450
SNLP2020_mixtext
takase
0
370
SNLP2020_sandwich
takase
0
370
ニューラル言語モデルの 研究動向(NL研招待講演資料)
takase
12
5.3k
Other Decks in Research
See All in Research
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
200
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
590
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
670
EIRによる不正端末のブロッキング 5G時代におけるデバイス識別と不正対策の進化
stellarcraft
0
100
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
260
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
180
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.5k
2025年度秋葉原ウォーカブルプロジェクト調査報告 「アキバらしいウォーカブル」とは何か
izumiyama_lab
1
130
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
240
AIで最適化を解けるか?
mickey_kubo
0
140
Featured
See All Featured
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Being A Developer After 40
akosma
91
590k
Making Projects Easy
brettharned
120
6.7k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
580
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Building an army of robots
kneath
306
46k
Building the Perfect Custom Keyboard
takai
2
820
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Transcript
Spike No More: Stabilizing the Pre-training of Large Language Models
Sho Takase, Shun Kiyono, Sosuke Kobayashi, Jun Suzuki 読む⼈︓⾼瀬翔(サイバーエージェント) 2025/8/31 1
この論⽂を選んだワケ • 初期化の話がしたかったので… • ニューラルネットの学習に初期化の影響は⼤きい – 初期化によって勾配消失 / 爆発を防ぐ •
Xavier 初期化 [Glorot+ 10] • 1000層超え Transformer [Wang+ 22] • Maximal Update Parametrization(μP)[Yang+ 21] • 初期化の背景にある気持ちは伝わってないことが多い – 例︓Xavier 初期化は順伝播 / 逆伝播で各層の分散を 1 にしたい • Xavier 初期化は FFN で議論 → 構造次第で適した初期化も変化 • 構造にあわせて分散を 1 にする初期化を考える必要がある – ReLU⽤の初期化(He初期化 [He+ 15]) • 初期化の気持ちを知って学習周りの議論の⾒通しを良くしたい 2
事前学習は必ず成功させたい • ⼤規模⾔語モデルの事前学習は⾮常にコストが⾼い – 例︓Llama3 8B の学習は 130万 H100 GPU時間
• 現在の AWS EC2 だとだいたい 240万ドル – 何度も学習を⾏うことが不可能 • (⼀回きりの)本番の学習で下記を満たして欲しい – 学習に成功する • 途中で Loss が発散しない – なるべく性能の良いモデルを得る 3
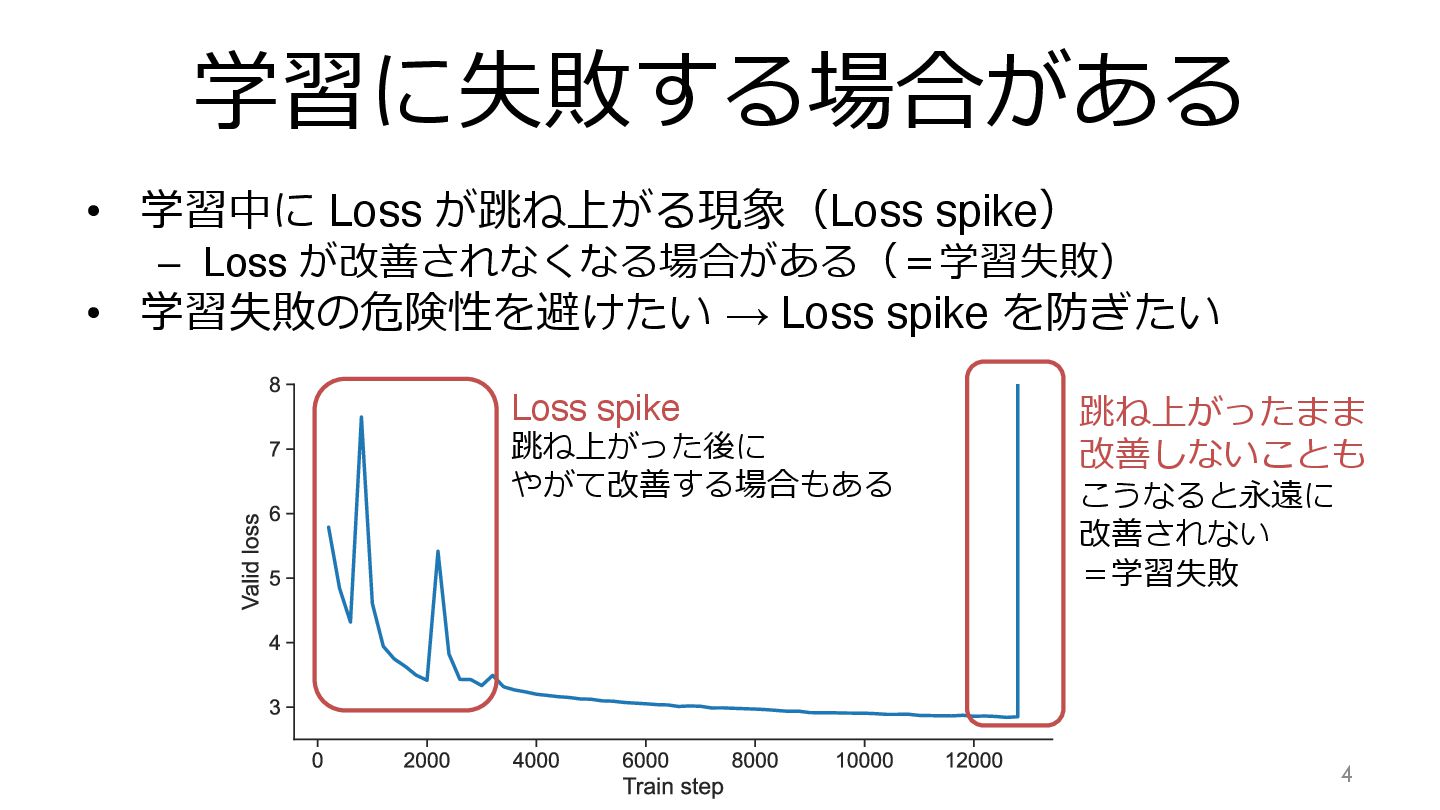
学習に失敗する場合がある • 学習中に Loss が跳ね上がる現象(Loss spike) – Loss が改善されなくなる場合がある(=学習失敗) •
学習失敗の危険性を避けたい → Loss spike を防ぎたい 4 Loss spike 跳ね上がった後に やがて改善する場合もある 跳ね上がったまま 改善しないことも こうなると永遠に 改善されない =学習失敗
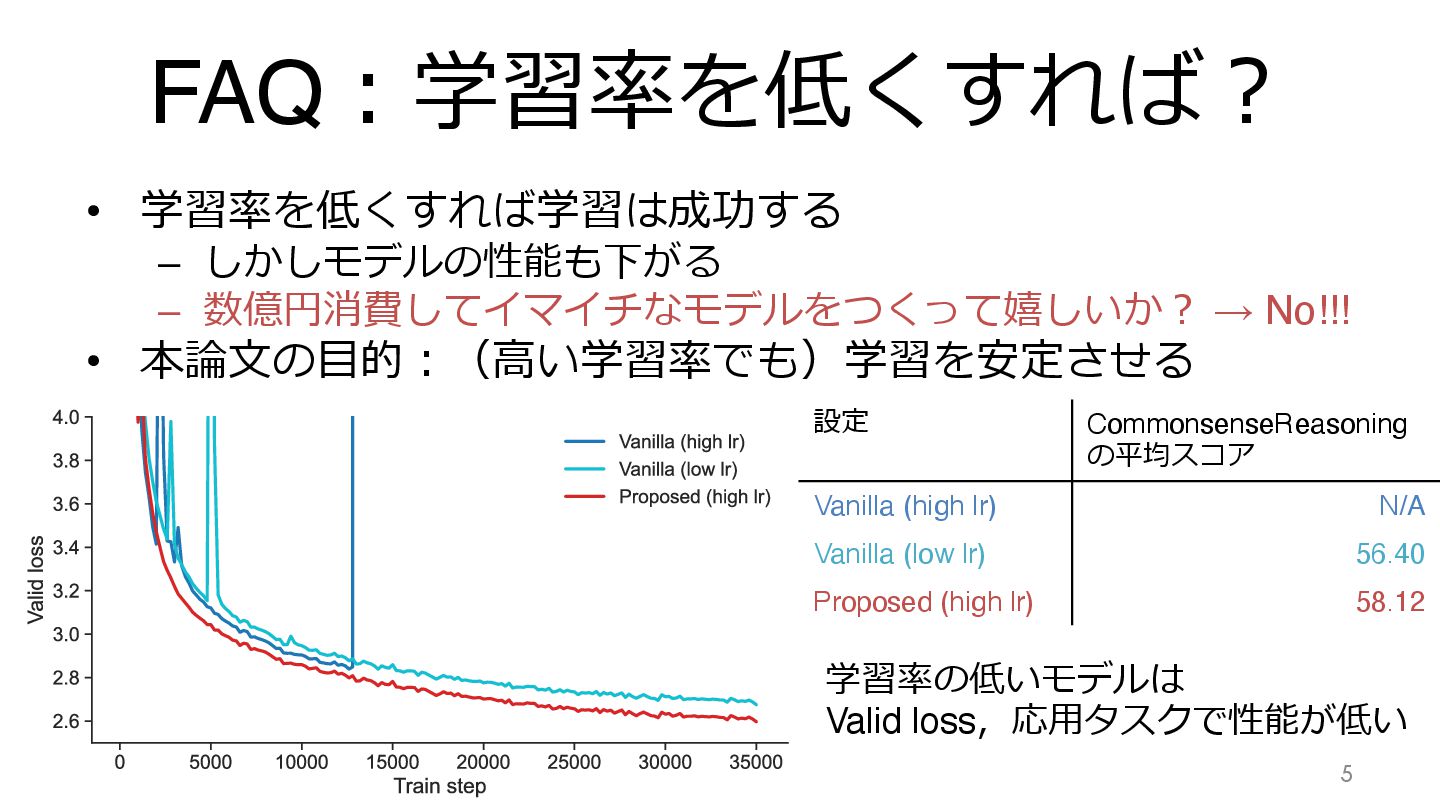
FAQ︓学習率を低くすれば︖ • 学習率を低くすれば学習は成功する – しかしモデルの性能も下がる – 数億円消費してイマイチなモデルをつくって嬉しいか︖ → No!!! •
本論⽂の⽬的︓(⾼い学習率でも)学習を安定させる 5 設定 CommonsenseReasoning の平均スコア Vanilla (high lr) N/A Vanilla (low lr) 56.40 Proposed (high lr) 58.12 学習率の低いモデルは Valid loss,応⽤タスクで性能が低い
本論⽂の貢献 • Transformer の学習が安定する条件を⽰す – 各層の勾配のノルムの上界を提⽰ – 上界を抑えてモデルが⼤きく変化することを防ぐ – 経験値依存よりは安⼼して学習が可能な状態に
• 既存の経験的な知⾒との関わりも整理 – 既存⼿法が上⼿くいく / 本当は上⼿くいかない理由を整理 6
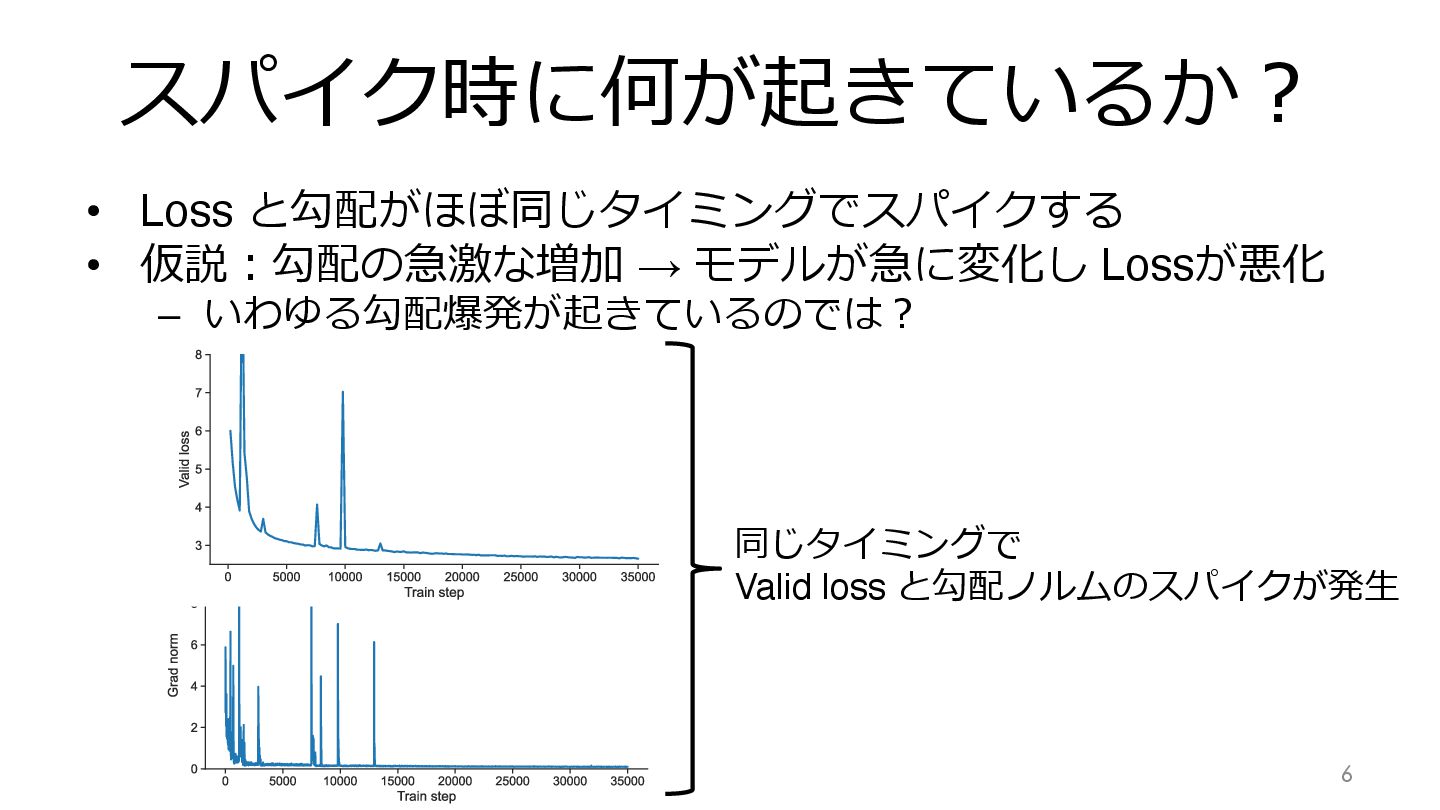
スパイク時に何が起きているか︖ • Loss と勾配がほぼ同じタイミングでスパイクする • 仮説︓勾配の急激な増加 → モデルが急に変化し Lossが悪化 –
いわゆる勾配爆発が起きているのでは︖ 7 同じタイミングで Valid loss と勾配ノルムのスパイクが発⽣
LLM に使われる Transformer の性質 • LLM では Pre-LN Transformer が使われる
• Pre-LN Transformer は低層側で勾配が増加する → 低層での勾配の増加を抑制すれば良いのでは︖ 8 Layer Norm Attention FFN Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention × N × N Attention Layer Norm Layer Norm Attention Layer Norm Layer Norm FFN Attention Layer Norm × N × N FFN Layer Norm Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention × N × N (a) Post-LN (b) Pre-LN (c) Post-LN with B2T connection m n m m n N Attention Layer Norm Layer Norm Attention Layer Norm Layer Norm FFN Attention Layer Norm × N × N FFN Layer Norm Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention × N × N (b) Pre-LN (c) Post-LN with B2T connection オリジナル︓Post-LN Residual 接続後に LN (勾配消失する構造) LLM での構造︓Pre-LN Attention / FFN 直前に LN Pre-LN Transformer の 学習初期の各層の勾配ノルム 低層にいくにつれ値が増加
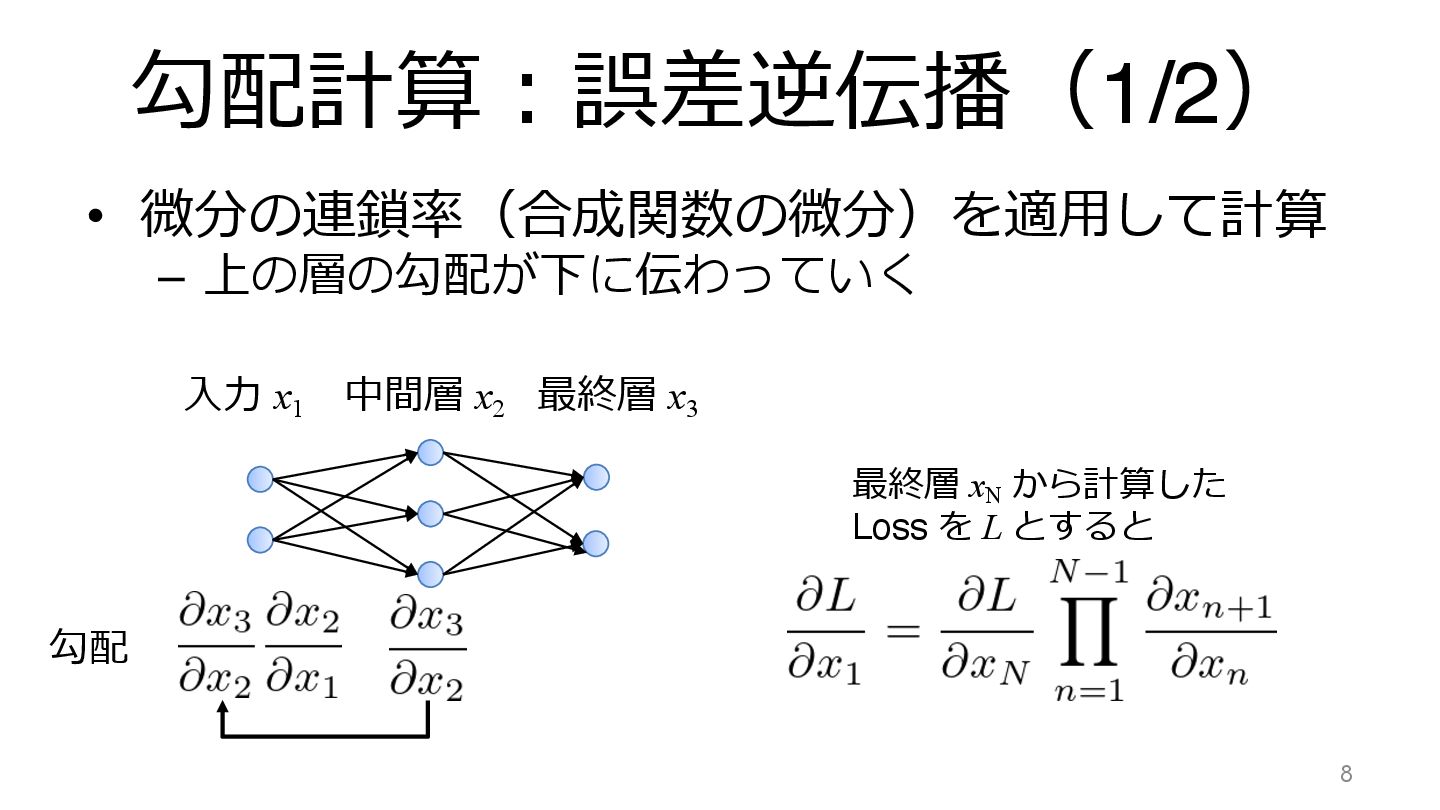
勾配計算︓誤差逆伝播(1/2) • 微分の連鎖率(合成関数の微分)を適⽤して計算 – 上の層の勾配が下に伝わっていく 9 最終層 x3 中間層 x2
⼊⼒ x1 勾配 最終層 xN から計算した Loss を L とすると
勾配計算︓誤差逆伝播(2/2) • ノルムについて考えると • 各層の勾配のノルムの積が出てくる=各層のノルムが – 1より⼩さい︓勾配消失の可能性あり – 1より⼤きい︓勾配爆発の可能性あり •
初期化時の勾配消失 / 爆発の傾向から学習挙動を考える – 初期化で学習挙動を考える(制御する)のは伝統的な(︖)研究 • 例︓Xavier 初期化 [Glorot+ 10],He 初期化 [He+ 15],μP [Yang+ 21] 10
Transformer の構造を⾒ると… • Transformer の各層は⼊⼒を x とした際 • 直感︓ショートカットが上層の勾配を維持 –
なので勾配のノルムは低層ほど増加する – 特にFFN,Attn部分での勾配増加が⼤きいと勾配爆発 • FFN,Attn部分の勾配のノルムの上界を抑えて対処する 11 ショートカット
勾配のノルムの上界を抑える • FFNとAttn部分の勾配のノルムの上界は – 詳細な証明・議論や C の値については論⽂参照 • 既存の初期化では σx,
x’ が⼩さすぎることが問題 – LNへの⼊⼒(=Embedding とショートカット項)の標準偏差 • 勾配のノルムを抑えるために満たすべき 2つの条件 – Embedding の標準偏差を 1 で初期化 – 各層のパラメータは⼩さい標準偏差で初期化 12 FFN部分 Attn部分 LNへの⼊⼒ベクトルの標準偏差 FFN,Attnのパラメータの標準偏差
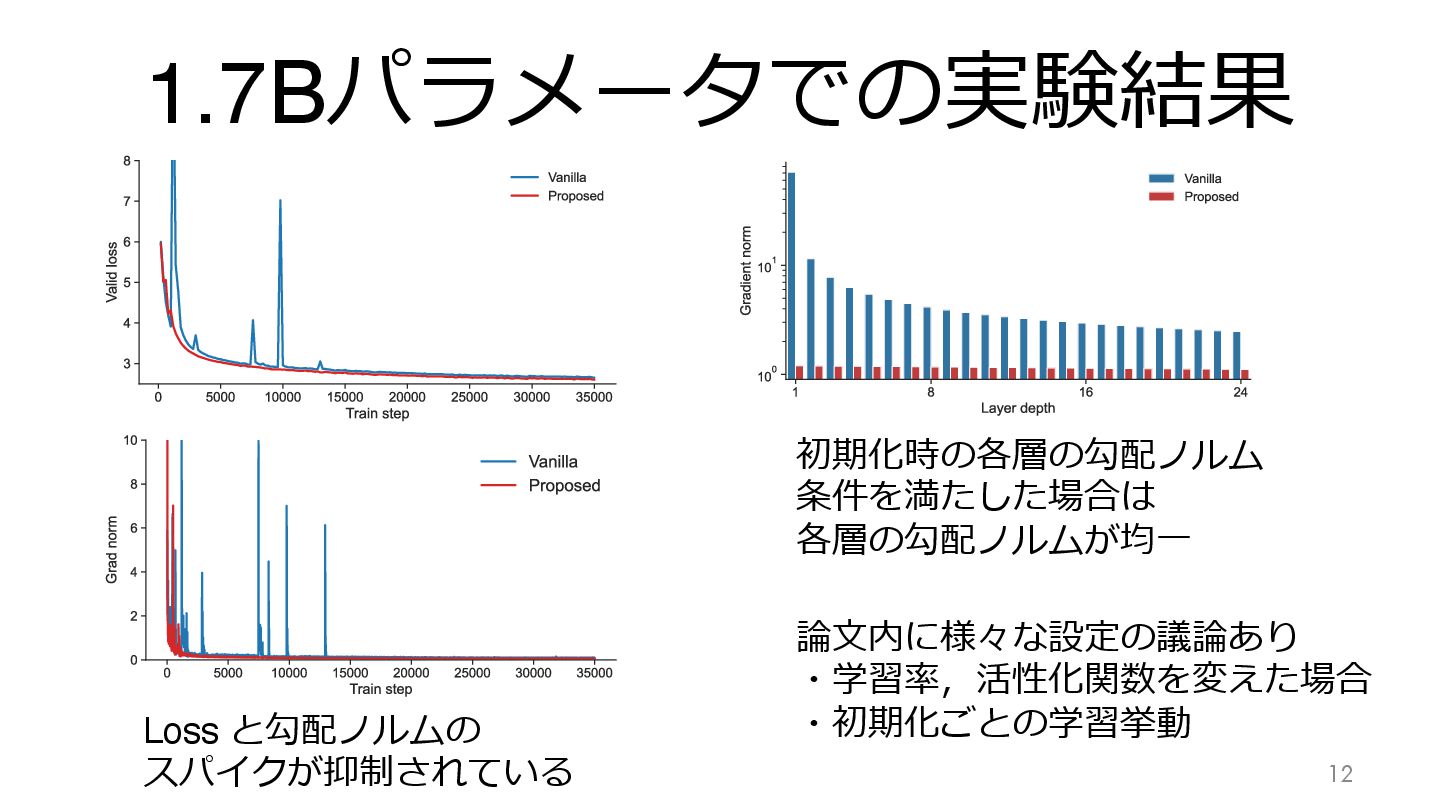
1.7Bパラメータでの実験結果 13 Loss と勾配ノルムの スパイクが抑制されている 初期化時の各層の勾配ノルム 条件を満たした場合は 各層の勾配ノルムが均⼀ 論⽂内に様々な設定の議論あり ・学習率,活性化関数を変えた場合
・初期化ごとの学習挙動
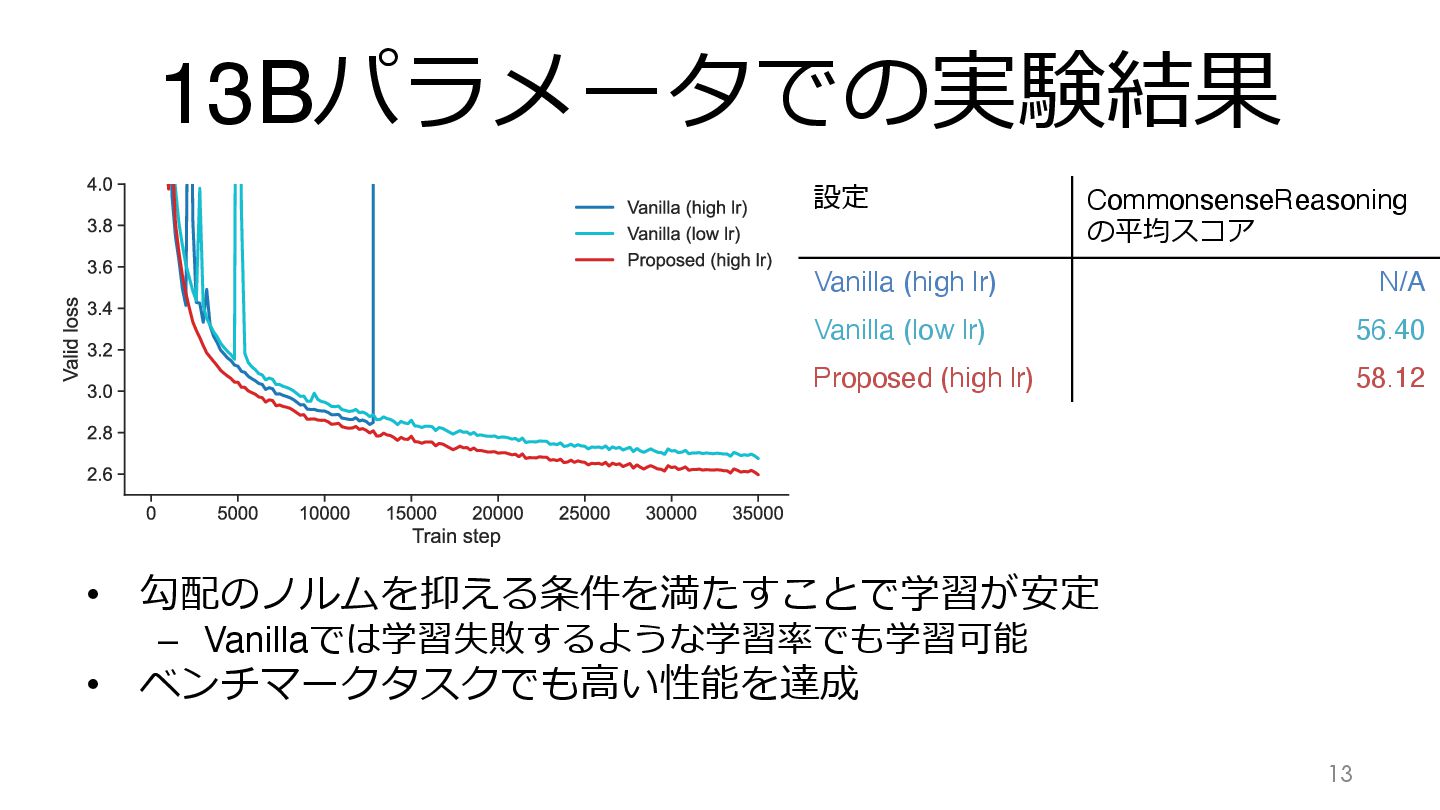
13Bパラメータでの実験結果 • 勾配のノルムを抑える条件を満たすことで学習が安定 – Vanillaでは学習失敗するような学習率でも学習可能 • ベンチマークタスクでも⾼い性能を達成 14 設定 CommonsenseReasoning
の平均スコア Vanilla (high lr) N/A Vanilla (low lr) 56.40 Proposed (high lr) 58.12
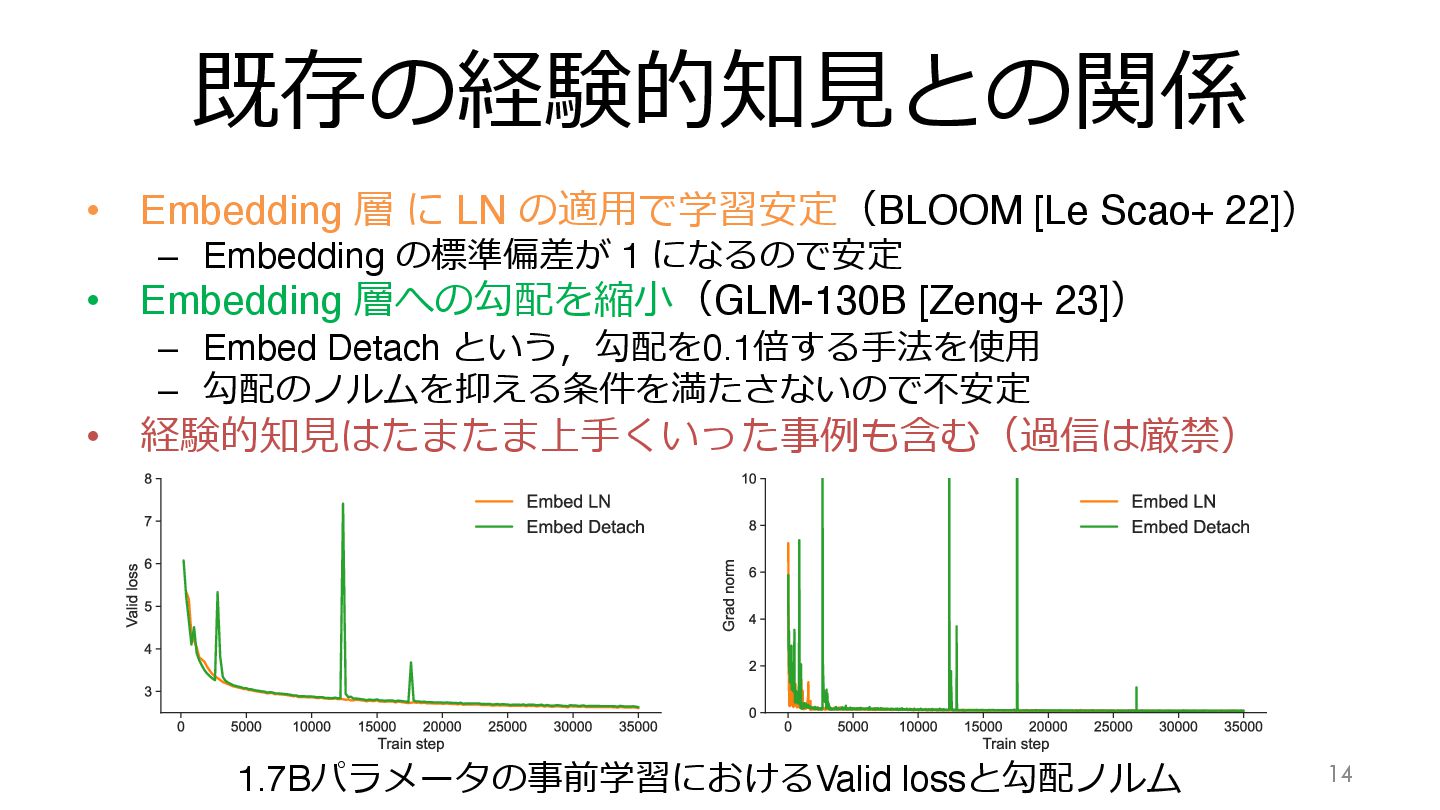
既存の経験的知⾒との関係 • Embedding 層 に LN の適⽤で学習安定(BLOOM [Le Scao+ 22])
– Embedding の標準偏差が 1 になるので安定 • Embedding 層への勾配を縮⼩(GLM-130B [Zeng+ 23]) – Embed Detach という,勾配を0.1倍する⼿法を使⽤ – 勾配のノルムを抑える条件を満たさないので不安定 • 経験的知⾒はたまたま上⼿くいった事例も含む(過信は厳禁) 15 1.7Bパラメータの事前学習におけるValid lossと勾配ノルム
[Nishida+ 24] との整合性 • [Nishida+ 24] の主張︓パラメータに対する勾配を⼩さくする – パラメータに対する勾配の⼤きさがスパイクの原因と仮定 •
学習時の勾配の挙動の観測から – パラメータのスケールを調整する項を導⼊ • 学習パラメータとして導⼊ • 学習設定が勾配のノルムをより強く抑えている • 再掲︓勾配のノルムを抑えるために満たすべき 2つの条件 – Embedding の標準偏差を 1 で初期化 – 各層のパラメータは⼩さい標準偏差で初期化 • [Nishida+ 24] の初期化は LLM でよく使われる初期化より⼤幅に⼩さい • 勾配のノルムの上界が強く抑えられる=より学習が安定 16
系列⻑と学習の安定性 • 系列⻑が短いほど事前学習が安定 – 経験的には系列⻑を徐々に⻑くすることで⻑い系列も安定して学習可能 [Li+ 22] – これを本研究での議論から説明可能 •
Embedding が⼩さい場合,系列⻑が⻑いほど σx, x’ が⼩さくなる – 学習初期のアテンションは⼀様分布に近い – 系列⻑が⻑いほどアテンション層の出⼒の分散が⼩さくなる → Residual 結合でショートカット項の分散が⼤きくならない • Embedding の標準偏差を 1 で初期化することで⻑い系列⻑でも安定 17 FFN部分 Attn部分 LNへの⼊⼒ベクトルの標準偏差 FFN,Attnのパラメータの標準偏差 FFN とAttn部分の 勾配のノルムの 上界は
その他の関連研究 • 初期化を考慮する – Maximal Update Parametrization(μP)と⼀連の論⽂ [Yang+ 21] •
単純化した議論なので Transformer に直接適⽤は本来は不可 • 初期化 + Transformer の構造もいじる系 – Residual 接続において係数を設ける [Wang+ 22] • ⼀昔前に出た,Transformer 1000層積みました論⽂ – Transformer から LN を削除する [Zhang+ 19, Huang+ 20] – 構造をいじると取り回しが悪くなるので今回は考慮せず • 学習コード,transformers,vLLM に独⾃実装をするか︖ • 構築したモデルが使われる可能性を狭める⾏為だと思うので… 18
学習の安定化研究のまとめ • ⼤規模⾔語モデルの事前学習は⾼コスト – 学習に失敗はしたくない – 低品質なモデルになることも防ぎたい → ⾼い学習率でも安定して学習できるようにしたい •
問題︓学習中に Loss spike が発⽣する – 場合によっては発散して学習が失敗する • 本研究の貢献︓勾配を分析し,上界を抑える条件を提⽰ – 条件を満たすことで Loss と勾配のノルムのスパイクを抑制 – 学習が安定 + ⾼い学習率で学習可能 → 性能も向上 19
おまけ︓初期化とタスク選好 • An Analysis for Reasoning Bias of Language Models
with Small Initialization [Yao+ 25] – ICML 2025 Spotlight Poster – ⾔語モデルは初期化のスケールが⼩さいほど Reasoning タスクに強いことを発⾒ • 実際は初期化のスケールが⼤きいと Reasoning タスクが 学習できない(汎化性能が低い)ことを報告 • ……と⾔ってるが本当か︖ – 汎化性能は Reasoning タスクだけ測っているように ⾒えるのはさておき 20
Transformer 構造での性質の違い • LLM では Pre-LN Transformer が使われる • An
Analysis for … では Post-LN Transformer が使われている – Appendix A の記述を信じる限りはそう – Post-LNは勾配消失が発⽣することが知られている • 特に初期化のスケールが⼤きいほど影響がある • 初期化のスケールが⼤きい場合に汎化性能が低い原因は勾配消失では︖ – 少なくとも論⽂内の「LLMへの知⾒にもなる」は偽だと思う… • LLM で使われる構造で議論していないので • 主流の Transformer がオリジナルの論⽂と全然違うことも問題 21 Layer Norm Attention FFN Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention × N × N Attention Layer Norm Layer Norm Attention Layer Norm Layer Norm FFN Attention Layer Norm × N × N FFN Layer Norm Layer Norm (a) Post-LN (b) Pre-LN m n m m n N Attention Layer Norm Layer Norm Attention Layer Norm Layer Norm FFN Attention Layer Norm × N × N FFN Layer Norm Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention FFN Layer Norm Layer Norm Attention × N × N (b) Pre-LN (c) Post-LN with B2T connection オリジナル︓Post-LN Residual 接続後に LN (勾配消失する構造) LLM での構造︓Pre-LN Attention / FFN 直前に LN この論⽂で議論されている構造
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存の経験的知⾒との関係 • Embedding 層 に LN の適⽤で学習安定(BLOOM [Le Scao+ 22])](https://files.speakerdeck.com/presentations/9f1da1c460bb46169a0b25a69019e436/slide_14.jpg){kind=link}
![[Nishida+ 24] との整合性 • [Nishida+ 24] の主張︓パラメータに対する勾配を⼩さくする – パラメータに対する勾配の⼤きさがスパイクの原因と仮定 •](https://files.speakerdeck.com/presentations/9f1da1c460bb46169a0b25a69019e436/slide_15.jpg){kind=link}
![系列⻑と学習の安定性 • 系列⻑が短いほど事前学習が安定 – 経験的には系列⻑を徐々に⻑くすることで⻑い系列も安定して学習可能 [Li+ 22] – これを本研究での議論から説明可能 •](https://files.speakerdeck.com/presentations/9f1da1c460bb46169a0b25a69019e436/slide_16.jpg){kind=link}
![その他の関連研究 • 初期化を考慮する – Maximal Update Parametrization(μP)と⼀連の論⽂ [Yang+ 21] •](https://files.speakerdeck.com/presentations/9f1da1c460bb46169a0b25a69019e436/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}