Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MySQLやSSDとかの話 その後
Search
Takanori Sejima
December 16, 2016
Technology
26
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MySQLやSSDとかの話 その後
後日談です。
Takanori Sejima
December 16, 2016
More Decks by Takanori Sejima
See All by Takanori Sejima
(きっとたぶん)人材育成や教育のような何かの話
sejima
0
980
互換性のある(らしい)DBへの移行など考えるにあたってたいへんざっくり
sejima
1
3.8k
NAND Flash から InnoDB にかけての話(仮)
sejima
0
27
InnoDBのすゝめ(仮)
sejima
0
29
さいきんのMySQLに関する取り組み(仮)
sejima
0
26
sysloadや監視などの話(仮)
sejima
0
23
さいきんの InnoDB Adaptive Flushing (仮)
sejima
0
27
TIME_WAITに関する話
sejima
0
37
binary log と 2PC と Group Commit
sejima
0
21
Other Decks in Technology
See All in Technology
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
公式ドキュメントの歩き方etc
coco_se
1
120
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
160
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3.3k
Network Firewallやっていき!
news_it_enj
0
170
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
410
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
390
CIで使うClaude
iwatatomoya
0
290
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
230
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.6k
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
360
カードゲーム作りが教えてくれた プロダクトオーナーシップ
moritamasami
0
110
Featured
See All Featured
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
For a Future-Friendly Web
brad_frost
183
10k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
The untapped power of vector embeddings
frankvandijk
2
1.8k
How to build a perfect <img>
jonoalderson
1
5.8k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Navigating Weather and Climate Data
rabernat
0
360
Transcript
Copyright © GREE, Inc. All Rights Reserved. MySQLやSSDとかの話 その後 Takanori
Sejima
Copyright © GREE, Inc. All Rights Reserved. 自己紹介 • わりとMySQLのひと
• 3.23.58 から使ってる • むかしは Resource Monitoring も力入れてやってた • ganglia & rrdcached の(たぶん)ヘビーユーザ • 6年くらい前から使い始めた • gmond は素のまま使ってる • gmetad は欲しい機能がなかったので patch 書いた • webfrontend はほぼ書き直した • あとはひたすら python module 書いた • ganglia じゃなくても良かったんだけど、とにかく rrdcached を使いたかった • というわけで、自分は Monitoring を大事にする • 一時期は Flare という OSS の bugfix などもやってた
Copyright © GREE, Inc. All Rights Reserved. • 古いサーバを、新しくてスペックの良いサーバに置き換えていく際、いろい ろ工夫して集約していっているのですが
• 実際にいろいろ使ってきて見えてきたことや、今後について考えることも増 えてきたので • 今日はそんなお話をしようと思います • 今回はあまりMySQLの話はありません • わたしはいろいろ変なこと考えてますが • 引き続き、細かいところは優秀な若手の実働部隊が頑張ってくれてます 本日のお話
Copyright © GREE, Inc. All Rights Reserved. • まだ読まれたことのない方は •
後日、あわせて読んでいただけると、よりわかりやすいかと思います • 過去の資料 • MySQLやSSDとかの話 前編 • MySQLやSSDとかの話 後編 本日のお話の補足資料
Copyright © GREE, Inc. All Rights Reserved. まずはおさらい
Copyright © GREE, Inc. All Rights Reserved. • GREEのサービスは歴史が古い •
むかしから動いてるMySQLのサーバは、かなり sharding されていた • 2000年代、GREEは SAS HDD 146GB 15krpm * 4本使ったRAID10の前提で、 データベースを設計してるところが多かった • 15krpm だと それくらいの容量の製品しかなかった • そういうストレージでも動くように、データベースのサイズは 100-200GB以下のものが 多かった • わたしが入社した2010年のころは、よくサービスささっていて、各エンジニ アが協力して改善してた • アプリケーションレイヤーでがんばってもらったり、力の限り sharding したり かつてのGREEのサーバ
Copyright © GREE, Inc. All Rights Reserved. • HDD前提の設計だと、サーバの台数が増えまくる。電力効率も良くない •
HDD前提のDBだと、HDDがボトルネックになって、CPU使い切れないケースが多い • HDDを基準に sharding していくと、一台のサーバでさばく qpsはどうしても低くなって、 CPU使用率はあまり上げられない • むかしは積めるDRAMの量も少なかったし、メモリの帯域はそれほど多くなかった • そもそもHDDがそれなりに電力を食う • SAS 15krpm だと一本で 10W 以上かな? • 結果、ラック単位で見たときに消費電力効率が良くない • HDDの占める消費電力がそこそこ大きかった時代 • そんな中、 SSD の価格は下がり続けており • SSD の進化にあわせてサーバの構成を見直すことで、ランニングコストを 削減し、サービスの競争力を維持しようと試みた サービスとしては改善したんだけど
Copyright © GREE, Inc. All Rights Reserved. そして着手した
Copyright © GREE, Inc. All Rights Reserved. • Fusion-IO 流行し始めたころ、調達できたのは
ioDrive MLC 320GB • ほとんどのDBは、HDDでも動くように sharding など工夫していたから、 320GB という少ない容量は使いドコロが難しかったので • 長考して長考して長考して • ioDrive の、桁違いに低い latency に着目して • ストレージというより「ちょっと遅いメモリ」と考えて • MySQL の buffer pool を減らし、大量の connection 張れるように、 大量のqueryを受けられるように、メモリの割り当て方を変更した • 詳しくはこちら まずはそこそこの容量の ioDrive
Copyright © GREE, Inc. All Rights Reserved. • 新しいハードウェアに対する心理的障壁として、「特性がわからない」「どん な壊れ方をするかわからない」というものがある
• ioDrive を、ある程度まとまった台数酷使したことによって、どんなふうに 故障するのかが、つかめてきた • ioDrive 導入以前より、 NAND Flash への心理的障壁はだいぶ取り除 かれてきたので、そろそろ次のステージに行ってもいいころ • そうこうしていたら ハードウェアは壊れるまで使ってナンボ
Copyright © GREE, Inc. All Rights Reserved. • 時は流れ、NAND Flash
の価格が下がり、大容量化が進んでいった • 800GB以上のエンタープライズ仕様のSSDが普通に買えるようになった • これは使いたい • 当時、容量大きいSSD使ってる他社事例それほど多くは聞かなかったので、使ってやり たい • いまは珍しく無いと思いますけど • 他社が活用できてないものを活用することによって、サービスの競争力を向上させる • SSD は random I/O 性能が高いし、15krpm の SAS HDD でRAID 組むより消費電力少ないので • ラック単位で考えたとき、よりCPUに電力を回せるようになる NAND Flash の価格が下がってきた
Copyright © GREE, Inc. All Rights Reserved. だがしかし
Copyright © GREE, Inc. All Rights Reserved. • SSDにリプレースしなくても動かせるDBが大量にあった •
100-200GB程度しかないDBでは、800GBのSSDは無用の長物ではな かろうか? GREEは力の限り sharding していた
Copyright © GREE, Inc. All Rights Reserved. そこで考えた
Copyright © GREE, Inc. All Rights Reserved. • DBが100-200GB程度しかないなら、サービス無停止で master
統合す ればいいってことで、サービス無停止で master 統合する方法を考えた • DBが巨大になるとバックアップとるのに時間かかるようになるし、管理が 大変になるので、大きく運用を変えない範疇で、バックアップの取り方を変 更することにした DB統合するしバックアップの取り方も変える
Copyright © GREE, Inc. All Rights Reserved. • HDDのころは、masterとslaveは146GBのHDD*4でRAID10だった が、
バックアップファイルを取得するためのslaveはHDD*6とかHDD*8 とかで、データベース用の領域と、バックアップファイルを書き出すための 領域を確保できるようにしてた • 具体的には、 mysqld 止めて datadir を tar ball で固めてた • つまり、masterのサーバとバックアップファイルを取るためのサーバは、 ストレージの容量が等しくなかった かつてのバックアップの取り方
Copyright © GREE, Inc. All Rights Reserved. • バックアップサーバとmasterで同じ容量のSSD使うと、バックアップを取 ることができない
• DBで800GB使いきっちゃうと、 tar ball とれない • 数TBの大容量 PCI-e SSD をバックアップサーバ用に使う? • それはリッチすぎるコストパフォーマンスが悪い • HDDだとI/Oの性能が追いつかない • DBを統合するということは、それだけ更新が増えるということでもある • SSDをRAIDコントローラで束ねる? • そうするとRAIDコントローラがボトルネックになるケースも出てくる • かつては、RAIDコントローラ経由だと SMARTがとれないという課題もあった 一番容量のでかいSATA SSDを使いたい
Copyright © GREE, Inc. All Rights Reserved. • HDDもSSDも、ブロックデバイスは、一つのI/Oコントローラに対して read
と write を同時に発行すると遅い • read only ないし write only のときに最大のスループットがでる • RAIDで束ねたHDD上で tar ball 取得するの、データベースが大きくな るに連れて、無視できない遅さになってきていた • SSDに移行したとしても、このままだといつか遅くなって困るんじゃない? 大容量のSSDを使う前から、課題意識はあった
Copyright © GREE, Inc. All Rights Reserved. • master/slave/バックアップサーバをぜんぶ 800GB
のSSDにする • バックアップサーバは ssh 経由で、同じラックにある SATA HDDの RAID6なストレージサーバに tar ball を書き出す • $ tar cvf - ${datadir} | pigz | ssh ${storage_server} “cat - >backup.tar.gz” • SSDなので tar するときの read は速い • pigzでCPUのcoreぜんぶ使いきって圧縮するので、帯域制限にもなるし、 通信量もへる。まぁ、ラックをまたがないので、全力で転送しても困らない • HDDは sequential write only になるので、書き込むのは充分速い • 運用や監視も、既存の方法と比べて大きくは変えなくて良い 方法を変える、許容できる範囲内で
Copyright © GREE, Inc. All Rights Reserved. • データが巨大になると、DB再構築するのに時間がかかるようになる •
今までN+1の構成だったところはN+2にする • slaveは一台多めにしておく。一台故障したら、もう一台故障する前にじっくり再構築 • ストレージサーバは RAID6 にする。 SATA HDD の故障率を考慮して • ストレージサーバはTB単位のデータを持っているため、電源などが故障したときのダメー ジがでかいので、二台構成にする。 • バックアップサーバから書き出す先は現行系のストレージサーバにして、待機系は cron で rsync してコピーする • ストレージサーバは SATA HDD にしたから大容量にできたので、ストレージサーバ1台 に対して、書き込むバックアップサーバは複数台にする。それならば、ストレージサーバを 2台構成にしてもコスト的にペイする • 最終的に、トータルで台数減ればそれでいい 破綻しないよう、考えながら集約する
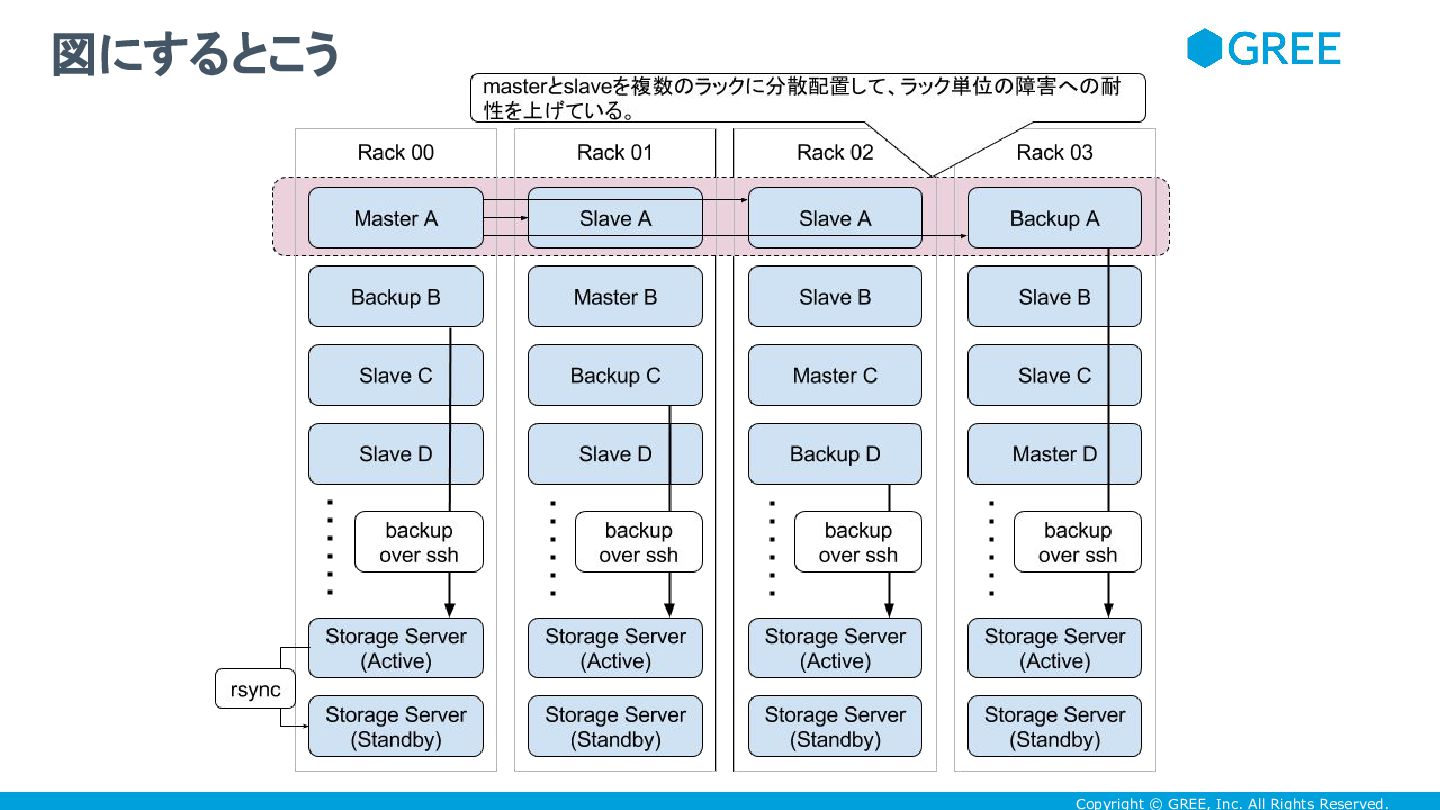
Copyright © GREE, Inc. All Rights Reserved. 図にするとこう
Copyright © GREE, Inc. All Rights Reserved. • Google の
Warehouse-Scale Computer ほど大きい粒度ではなく、4 本以上のラックを一つの単位として考える • replication の traffic は、これらのラックに閉じ込めてしまう。 • RAID5がパリティを複数のディスクに分散させるように、masterやバック アップ用のサーバを複数のラックに分散させる • 万が一、ラックごと落ちたとしても、影響を受ける master の数を限定的にできる • master -> slave 間の replication の traffic が、ラックごとに偏りにくくなる • アプリケーションサーバ <-> slave の traffic が多かったとしても、ラックごとに偏りに くくなる • バックアップサーバを分散配置することで、ストレージサーバのディスク使用量を、ラック ごとに偏らせないようにする 複数のラックをグルーピングし、RAID5の様に扱う
Copyright © GREE, Inc. All Rights Reserved. • 現状のHWの特性や、今後のHWを想定している •
サーバのNICの帯域が増えても、これらのラックの集合の中でその性能が活かせる • 弊社の場合、KVSの replication の traffic が大変多いのだが、 KVSやMySQLの replication の traffic を特定のラックに集約できると、運用上楽になる • pigz でバックアップファイルを圧縮するので、 DBの集約度が上がってDBのサイズが増 えても、CPUのコアが増えれば、バックアップの取得時間を稼ぐことができる • SSDの消費電力の少なさを活かして、一ラックあたりの集積度を上げていける • SSDは消費電力が少なく熱にも強いから、そのぶん CPU で TurboBoost 使って、熱 出しつつ性能を引き出す方向で行ける • TurboBoost 使うことで、NICの帯域が増えても、CPUがパケットさばけるようにする • 現状はSATAのHDDをバックアップ用のストレージに割り当てているけど、 SSD のバイ ト単価が十分下がっていけば、別に SSD でもかまわない このラックの使い方には、いろいろな思惑がある
Copyright © GREE, Inc. All Rights Reserved. おさらい ここまで
Copyright © GREE, Inc. All Rights Reserved. ここからが 最近の話
Copyright © GREE, Inc. All Rights Reserved. • エンタープライズ仕様のSATA SSD
でも、1TB超の製品が出てきた • 3D NAND が実用化してきているので、容量は来年以降もまだまだ増え ていく • わたし的には、まだまだ集約していけると思う。少なくともバックアップサー バは • 仮に master/slave が 800GB 以下のままでも、 バックアップサーバであれば、 mysqld を複数プロセス相乗りしてもそれほど困らないので • バックアップサーバだけ、800GBより大きい SSD 積んだっていい • 例えば、バックアップサーバに 1.6TB くらいの SSD を積んで、 mysqld を2プロセス 起動して、 800GB の SSD つんだ master 二台と replication しても良い SSDの進化はめざましい
Copyright © GREE, Inc. All Rights Reserved. が
Copyright © GREE, Inc. All Rights Reserved. • ssh 経由で、同じラックにある
SATA HDDの RAID6なストレージサーバ に tar ball を書き出す方法、うまくいったんだけど • SSD は書き込み寿命という概念があるので、 DB のフルバックアップを定期的に SSD へ書き込むのはあまりうれしくないが、バックアップの書き込み先が HDD なら、定期的 にフルバックアップ書き込んでも、別に困らない • SATA HDD は 24時間365日フル稼働させると設計的にきびしい製品もあるが、 daily のバックアップ保存先として使うなら、 24時間フル稼働するわけではない • 書き込み寿命の概念があるけど高速な SSD は、お客様向けのサービスに使って、書き 込み寿命の概念がないけど安価な HDD は、バックアップの保存先に使う • そんな具合に上手く行ったんだけど • ストレージサーバの HDD の容量を増やして集約率を上げていくなら、見 なおして良いポイントが幾つかあるなと、実稼働させていくうちに見えてき た サーバの構成を見なおしてもいいころ
Copyright © GREE, Inc. All Rights Reserved. • ストレージサーバのCPUはスカスカなので、CPU 1socket
に対して、もっ と大容量のストレージが扱える • バックアップサーバから書き込むとき、ストレージサーバは sshd くらいしか CPU 使わな いのだが、 sshd 1プロセスで複数のコア使えなくても、複数のバックアップサーバから書 き込んでいるので、結果的にストレージサーバのコアは複数使いこなせている • バックアップサーバが pigz で圧縮したものをストレージサーバに書き込んでいるので、 ssh で暗号化するデータもストレージに書き込むデータも、圧縮済みで最小化できてい る。 • そのため、ストレージサーバの CPU 負荷は低かった。 • その結果、ストレージサーバで増やしたいリソースは次のような印象 • NICの帯域 >= ストレージの容量 >>> (越えられない壁) >>> disk の書き込み負 荷 >>> CPU 使用率 ひとつひとつ、サーバ上のリソースを見直していく
Copyright © GREE, Inc. All Rights Reserved. • GbE 経由では
120MB/sec 程度でしか書き込めないが、いまどきの HDD とRAIDコントローラだと、RAID6 でも 120MB/sec なんて余裕す ぎる(HDDの本数によるでしょうが) • RAIDコントローラをもっと酷使するためには、 GbE では全く足りないので 、10GbE 以上の帯域を用意するしかない • NIC の帯域が太くなると、 tar ball 書き出す時間を短縮できるので、 DB のサイズが大きくなっても運用上さしつかえないし、ストレージサーバのス トレージの容量を増やしてもいい 少なくとも 10GbE
Copyright © GREE, Inc. All Rights Reserved. • 巨大すぎる RAID
は、リビルドにかかる時間が長くなる • リビルドの時間が、 HDD 一本あたりの容量と本数に比例するなら、わたしは容量を犠 牲にしようと思う • HDD の本数が増えて消費電力増えたとしても、性能面などでのメリットがあればいい • ラック単位で考えたとき、電力面でバランスが取れていればそれでいい • 可能であれば、1台のサーバにRAIDコントローラを複数積みたい • 一つのRAIDコントローラにぶら下がってる HDD の本数が減れば、リビルドの時間はそ れだけ減らせる。なので複数積んで、管理する HDD を分散させる。 • どうせ複数のバックアップサーバから書き出すので、 RAIDコントローラごとにボリューム分か れていても困らない • バックグラウンドでリビルド走ってるときも、リビルド走ってない方のコントローラは、性能に影 響しないだろうし RAIDはあまり大容量すぎても意味が無い
Copyright © GREE, Inc. All Rights Reserved. • ある程度まとまった本数の HDD
を積めるならば、 RAID6 より RAID60 にして書き込み性能を改善させる • HDD の特性として、円盤の外周と内周で性能差が出るケースはあるだろうから、性能に はある程度余裕をもたせておいたほうがいい。 • 実際にファイルを書き出したり削除したりすると、必ずしも局所的なアクセスになるとは限らな いだろうし • NIC の帯域に対してある程度余裕を持たせておいて、あくまでも「ボトル ネックは NIC の帯域」となるようにしておいたほうが、運用がシンプルに なって良い • NIC に合わせて設計するときに難しい点は、 NIC の帯域が1.5倍くらいのペースで増 えるのではなく、 GbE から 10GbE など、いきなり倍以上になってしまうところ。 RAID6 より RAID6+0
Copyright © GREE, Inc. All Rights Reserved. • いくらバックアップファイルを保存するストレージサーバとはいえ、一台に集 約してしまったら、(直接サービスに影響がでないとしても)故障などの障害
発生時、復旧のための運用上のコストは、かなりきびしいものになる • 複数のラックに分散配置して、万が一のときでも、復旧作業の作業コスト が、許容できる範囲に収まったほうが良い • 消費電力高いパーツを大量に積んだサーバを、一つのラックに集中して配 置してしまうと、突入電力の面でも懸念が残る 程よい大きさのストレージを、分散配置するのがよい
Copyright © GREE, Inc. All Rights Reserved. • ストレージサーバに 10GbE
を積んでも、ストレージサーバにバックアップ 書きだすサーバが同じラック内にいるだけなら、バックアップのためのトラ フィックは、上流のコアスイッチを経由しない • 仮に、 GbE を積んだ10台のバックアップサーバと、 10GbE のストレー ジサーバが全力で通信して 10Gbps 目一杯使うとしても、その通信が ラック内で完結しているなら、ネットワーク機器の設備投資は、局所的なも ので済ませられる • そのようなバックアップサーバとストレージサーバのセットが複数のラックに 分散配置できていれば、大容量のバックアップを高速に取得できる • もし、オンプレミス環境からクラウドストレージにバックアップを書き出すとし たら、このようにネットワークの帯域を使うことは、コスト面で難しいだろう トラフィックがラックの中で完結するメリット
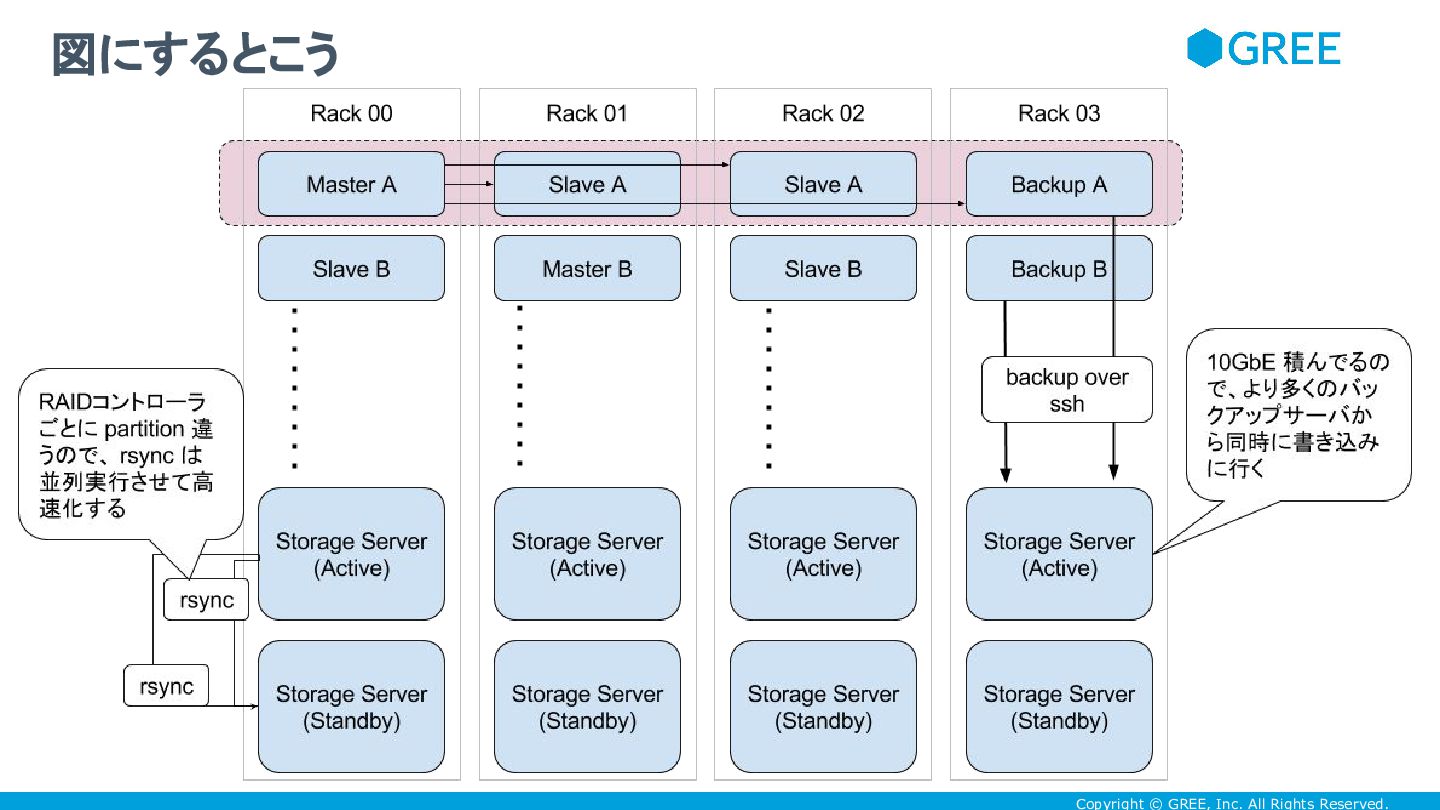
Copyright © GREE, Inc. All Rights Reserved. 図にするとこう
Copyright © GREE, Inc. All Rights Reserved. • ストレージサーバ1台に毎日書き出したいバックアップの総量は、何TBな のか?それを何時間で書き込みたいのか?
• 時間的に GbE の帯域で足りるのか?足りないなら、 10GbE の帯域に 見合うだけの書き込み性能を、RAIDコントローラは持っているのか? • バックアップは何日分保存しておきたいのか?それだけの容量を保存する とき、 RAID のリビルドはどれくらいかかるのか?ストレージサーバの再 構築にかかる時間はどれくらいか? • RAID のリビルドにかかる時間を短縮したいなら、RAIDコントローラはいく つ積むべきなのか? • 最終的に、電力や設置スペースなども踏まえて、 HDD で RAID を組む コストメリットはあるのか? 一つ一つ、積み上げて見積もる
Copyright © GREE, Inc. All Rights Reserved. • リビルドにかかる時間などは看過できないけど、実運用に収まる規模であ れば、未だに
RAID はコストパフォーマンス悪くない仕組み • ある程度の規模になると、分散ファイルシステムなどを検討しなければなら ないだろうけど。障害発生時の復旧コストや、ネットワーク機器への設備投 資など考えると、 RAID を使ったストレージサーバや、同一ラック内からそ のストレージサーバに Ethernet 経由でバックアップを書き出すというの は、現時点では充分選択肢になりうる • 保存するデータの規模や用途、障害復旧の方法、運用コスト等考慮し、自 分たちにとって適切な方法を選んでいくのがよい。 • その一つとして、 RAID はまだ選択肢になりうると思う 要素技術としてみたときの RAID
Copyright © GREE, Inc. All Rights Reserved. • 1TB超のエンタープライズ向け SATA
SSD、 10GbE 、そういったものに 対して • 2Uくらいのストレージ特化型サーバがあれば、 RAID で 3.5inch SATA HDD を束ねて、ある程度コストパフォーマンスのいいバックアップシステ ムが設計できる • 例えば、 HPE Apollo 4200 のような2Uのサーバ使うとか • Hadoop 以外でも、ストレージ特化型のサーバって意外と使い道あると思 います。容量100TBとかなくてもいいんです。HDDたくさん積めれば、使 い道はあるんです。 SSD 積んだサーバの、補助記憶装置的に捉えれば いいんです。 現時点でのハードウェアを見渡すと
Copyright © GREE, Inc. All Rights Reserved. このへんまでは 取り組んでる
Copyright © GREE, Inc. All Rights Reserved. で
Copyright © GREE, Inc. All Rights Reserved. • その一方、パブリッククラウドも活用してるし気にしてます。 •
仮想化というレイヤーを挟まないことによって、 MySQL からハードウェアまでの間を構 成する要素が減るので、何かあったときに調査しやすいのですが • パブリッククラウドのメリットも当然有るので、そのへんはいろいろ比較しながら勉強させ てもらってます。 • 余談ですが、パブリッククラウドでも、 Linux の kernel や TCP に関することについて は、やはりチューニングすべきポイントがあって、そういった意味では、オンプレミス環境 でもパブリッククラウドでも役に立つ知識や経験があります。 • TCP や Linux の kernel に関する知識は、インフラエンジニアである限り、当分役に立 つもんだと思います。 パブリッククラウドをチラチラみつつ
Copyright © GREE, Inc. All Rights Reserved. わりと真面目に 比較している ところは
Copyright © GREE, Inc. All Rights Reserved. • (月並みですが)Googleはすごいと思ってます。何がすごいかというと消 費電力効率です。彼らのデータセンターのPUEはハンパないです
• Googleに限らないですが、パブリッククラウド事業者は、日本以外の、一 つのラックに電力を大量に供給できて、一つのラックにサーバをたくさん詰 める地域でもサービスしてたりします。 • そうすると、日本より空間効率良くなって集約度が上がっていくわけで、日 本よりインスタンス費用が安くなっていきます。 • 極論すると、アメリカ西海岸の方が、パブリッククラウドのインスタンス安い なら、アメリカ西海岸でサービス開発してる人、コスト面で超有利じゃん?と 思うわけです • インスタンスの安い地域と比べて、日本の中でどうやってコストを最適化し ていくか?という課題が常にあると思っています 消費電力効率と空間効率をいかに最適化するか
Copyright © GREE, Inc. All Rights Reserved. • 日本では、スパコンを設置するためのデータセンターを設置する場合、場 所選びが大変なのではないか?と思います。
• 一方、土地が広い国は、データセンターいくつも作ってスパコンたくさん開 発できる余地があるんじゃないでしょうか? • スパコンはとても電力使うので、消費電力の多いデータセンターをいくつも 設置できるということは、電力効率が良いデータセンターのためのノウハウ が、その地域に蓄積されていくということになるのかもしれません。 • TOP500の国々を見ていると、そんな気がしてきます。 これは非常に個人的な推測なんですが
Copyright © GREE, Inc. All Rights Reserved. • 日本はGreen500で健闘してますが、いかにして電力効率を最適化して いくかっていうのが、日本の土地のことを考えると、方向性としては正しい
んじゃないかなという気がします。 • 消費電力多いけどclockの高いCPU使いたいなら、パブリッククラウドで、 電気たくさん使える地域でインスタンス立てる方が、今後、どんどんコスト パフォーマンス良くなっていくんじゃないかという気がします。 • そんな中、日本のデータセンターにあるサーバを使いたいなら、いかにして 電力効率を最適化し、ランニングコストを削減していくかが、重要なポイント ではないかなと考えています。 スパコンの世界を眺めて思うのは
Copyright © GREE, Inc. All Rights Reserved. そう思いながら サーバいじってて 気がついた
Copyright © GREE, Inc. All Rights Reserved. そうだ
Copyright © GREE, Inc. All Rights Reserved. CPUのCoreを disable に
しよう
Copyright © GREE, Inc. All Rights Reserved. • GREEのサービスはCPUが4Coreくらいの時代から続いてるので、CPUの Coreが10とか20とかなくても、どうにかなるケースが多い。
• DBはCPUよりもSSDとメモリ。もしCPU使用率高いなら、最適化を試みればいい。 • しかし、ワーストケースとして「すべてのCoreがぶん回されたときの消費電 力」を想定して、ラックに積むサーバの台数を決めなければならない • そうであるならば、BIOSから使うCoreの数を制限して、CPUの消費電力 の上限を設けてしまえばいい • Core数の少ない Low-Core-Count のCPUであれば、使うCoreが少な いと、 TurboBoost でより高いClockに引き上げることも可能になる • MySQL5.6以前であれば、SQL_Thread がシングルスレッドなので、シングルスレッド 性能高いほうが Replication では有利になる MySQLを最適化してくと、そこまでCPU使わない
Copyright © GREE, Inc. All Rights Reserved. MySQL最適化して 使うCoreの数を制限して 消費電力を削減し
お客様に還元する
Copyright © GREE, Inc. All Rights Reserved. • 1Uではなく、 2U4nodeなどの高集約型のサーバをDBに使う
• master/slaveは複数のラックに分散する設計にできているので、最悪、サーバごと落ち て4node全滅したとしても、影響範囲は限定的にできる。 • BIOSからCPUのCore数を制限して、消費電力を引き下げつつ、 TurboBoostでより高い clock を、より高いシングルスレッド性能を狙う • 1nodeあたり1U未満のサーバであれば、 一ラックあたり46Uしかなくて も、 1ラックあたり 48node くらいを狙える気がしている • ざっくり考えて、1UでDB一台130Wくらいだったけど、110Wくらいを狙えるのでは • 低電圧版のCPU1個で50-60W程度 • DDR4のメモリ1枚が9-10W程度で(クアッドチャネルということでそれが4枚) • SATAのSSDとNICがそれぞれ5-6Wずつ • ファンや残りのパーツで 10Wくらい余裕みて • 電源の力率をざっくり 0.9くらいで考えると • このままだとサーバ1台で 130Wくらいだが、Core を disable してそれを削る。 今後、検討したいこと
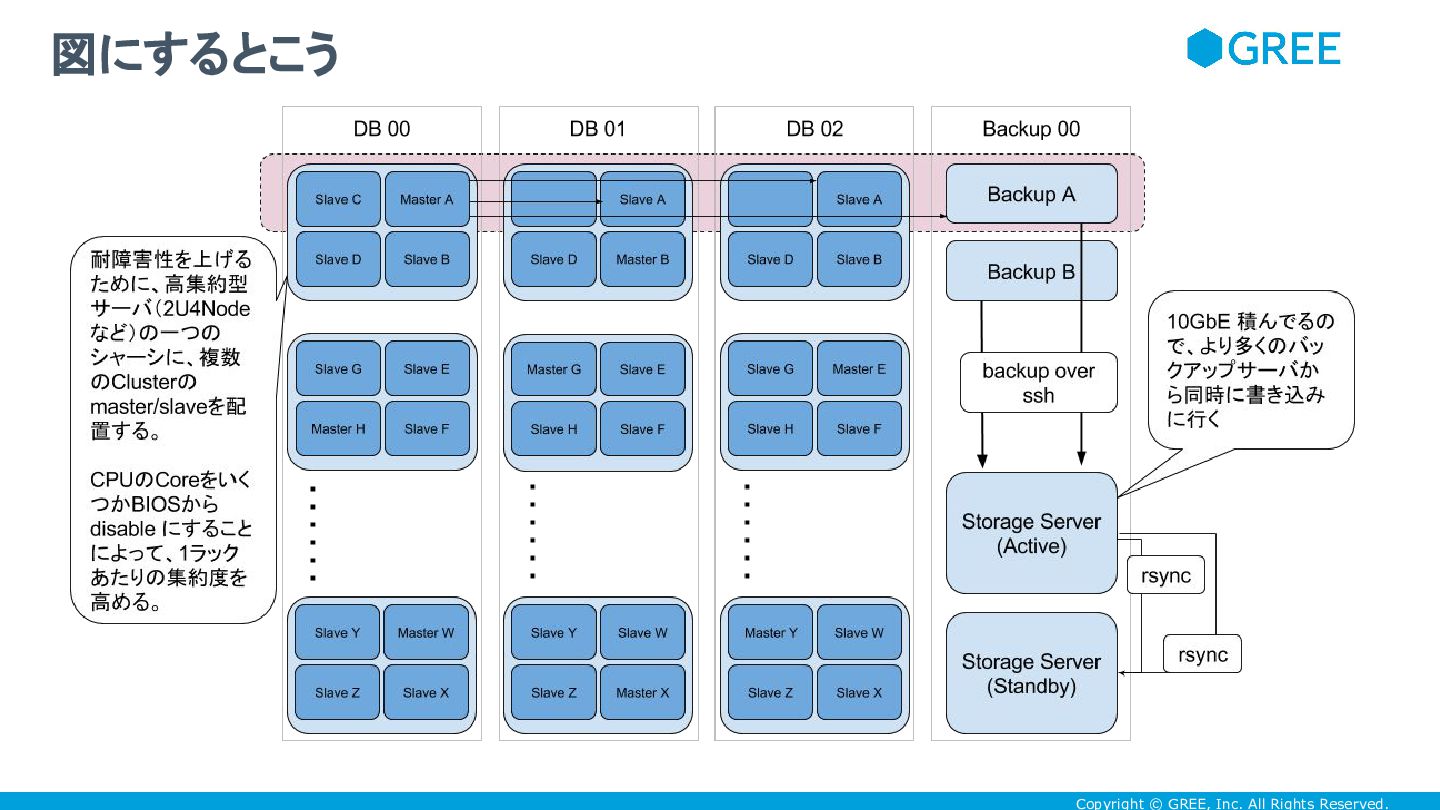
Copyright © GREE, Inc. All Rights Reserved. 図にするとこう
Copyright © GREE, Inc. All Rights Reserved. こんな感じで
Copyright © GREE, Inc. All Rights Reserved. 48portのswtich、 1ラック分のサーバで ポート使い切ってやろう
Copyright © GREE, Inc. All Rights Reserved. • 10GbEのストレージサーバを組んだことで、バックアップサーバ用のラック は実績が上がってきた。
• Webアプリケーションサーバ専用ラックとDBサーバ専用ラックを、それらと 切り離して、上手く組んで行ければいいかなと思っている • アプリケーションサーバとDBサーバで専用ラックを別々に組めると、アプリケーション サーバとDBサーバの台数比率を自由にコントロールできるので、柔軟に台数構成を考え られる。 • アプリケーションサーバはCoreたくさんあったほうが集約率上がるので、 Core を Disable にすることはあまり考えてないが、DBはCoreを Disable にすることで、1ラックあたりの集約度を上げていければいいかな と思ってる • 最大で、 1ラック48port 使い切れる範囲内まで disable にするということで バックアップ用HDDは他のラックに確保できたので
Copyright © GREE, Inc. All Rights Reserved. 現時点では、 ある程度までは 電力効率を
改善できそうだ
Copyright © GREE, Inc. All Rights Reserved. • おそらくきっと、サーバにも 40Gbps
のネットワークインターフェースが普 及してくる時代になってくるだろうから • 参考: EthernetやCPUなどの話 • 40GbE などが普及する時代になってくると、これらのバランスがまた崩れ てしまう • いまは仮想化しないで localhost 上のSSDを使ってる。ネットワーク経由で disk にア クセスしないで済ませられているので、データセンター内のトラフィックを絞れている。将 来、広帯域のネットワークが充分安価になれば、 localhost 上のSSDを使わない方が、 最終的にランニングコスト下げられるのかもしれない。 • おそらく2020年代には、別の選択肢を考えなければならない • なので、次はどうしようかと、個人的にいろいろ考えてるところです 次の、2020年代には
Copyright © GREE, Inc. All Rights Reserved. おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}