U D Y S E S S I O N Why Open Dataspaces 設計思想とアーキテクチャパラダイム Leveraging distributed data management for inter-organization and global interoperability April 2026 KEY WORDS: dataspaces, data mesh, ontology, semantic layer, usage control, Agentic AI, DDD
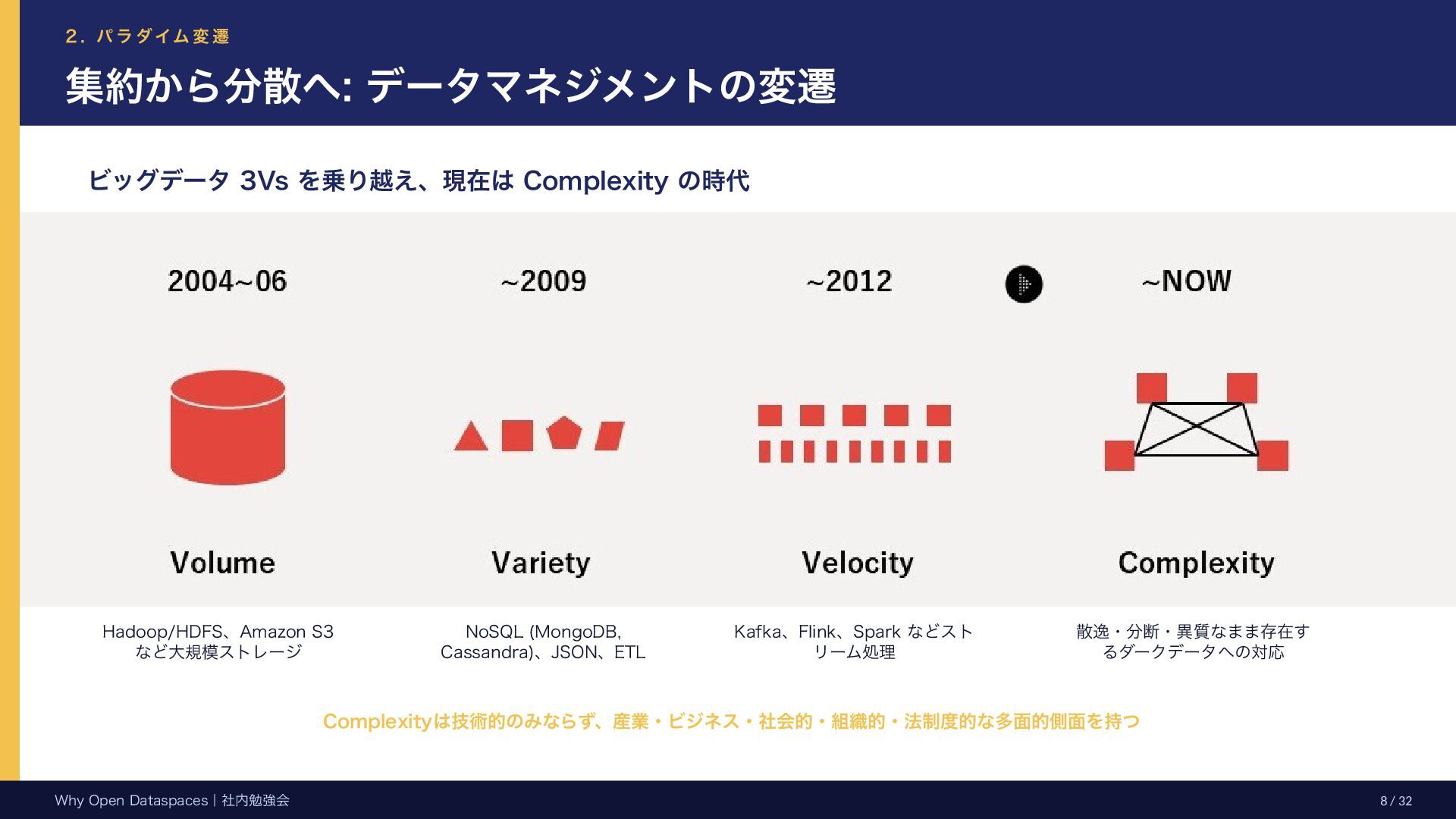
Governance Complexity 組織内の部門間連携を暗黙の前提とするため、組織境界を越えると課題が顕在化 W h e r e t o g e t 所在と同一性の問題 例: OEM契約先の製造実績はどこで取得可能か? 「6AX-10K Industrial Robot」と「Robot 10kg Standard Model」は同一機体か? W h a t t o m e a n 意味の問題 例: 広報チームの Alice は本当に広報部門所属か? 「高度」は標高なのか対地高度なのか? W h o a n d H o w t o u s e 利用条件の問題 例: アクセス者 (Agentic AI) はどの会社の運用か? このストリーミングデータは単位時間あたりいく らか? BI以外の二次利用は? スケーリングに伴う Governance Complexity の問題 — 組織・国境を横断するとガバナンスコストは爆発する Why Open Dataspaces|社内勉強会 12 / 32
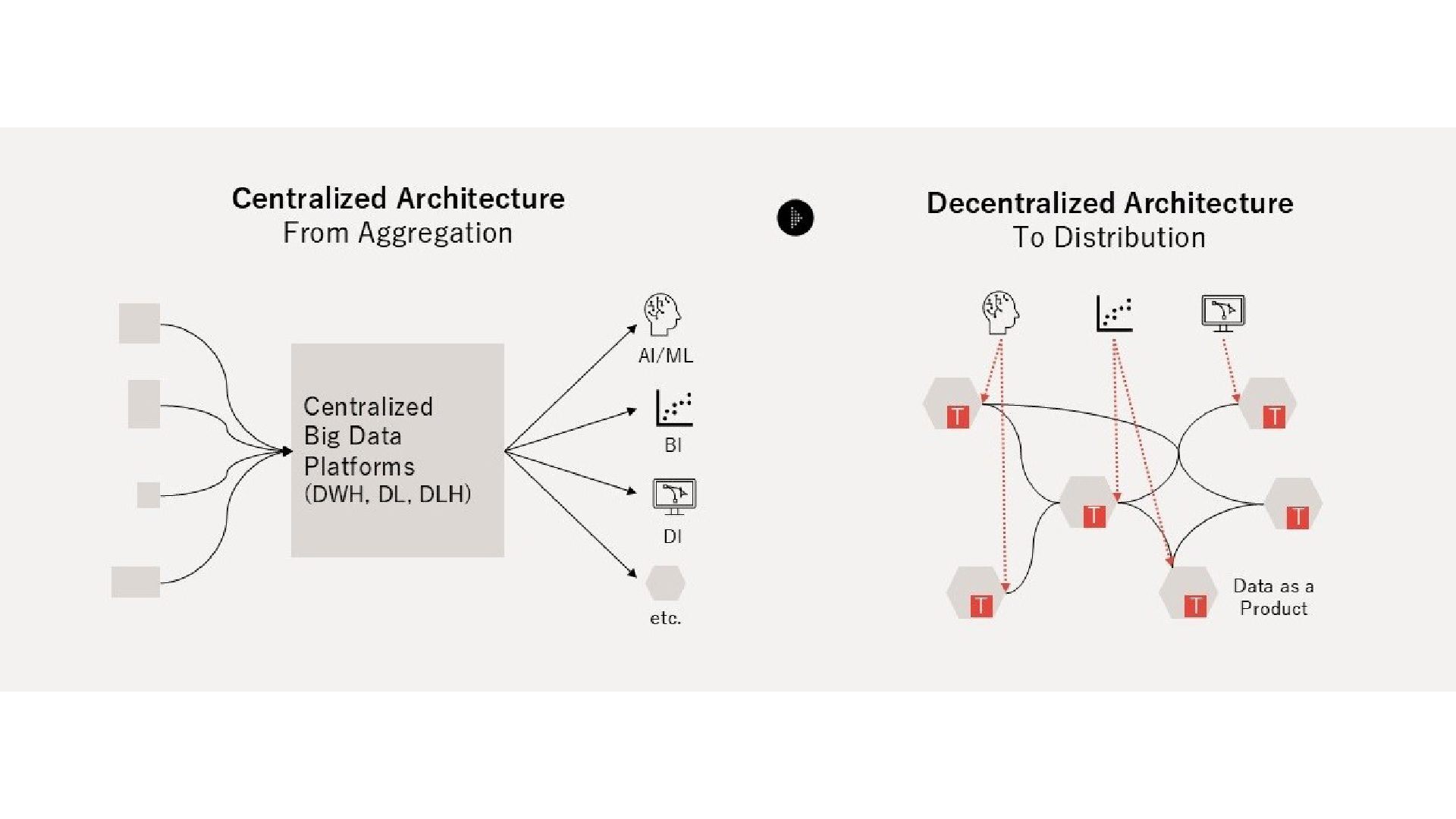
l D a t a s p a c e s 米国での「データスペース」誕生の背景 2005年、UC Berkeley の Franklin ら DBMS を補完する「新たな抽象化」として提唱 原 著 論 文 Franklin, Halevy, Maier (2005) “From databases to dataspaces: a new abstraction for information management” 扱う対象 = HCoD Heterogeneous Collection of the Data 組織に分断された異質なデータコレクション データスペースの特徴 参加者 (participant) と関係 (relationships) で定義される 参加者は RDB / XML / 文書DB / ウェブサービス 等のデータソース 構造化・半構造・非構造データいずれも参加可能 2以上の参加者のいかなる関係性もモデリング可能 ネスト構造・重複構造でも存在しうる アクセスルールは異なる性質のスペース間で共有 中央集権的 Push and Ingest と明確に異なるアプローチ。個々のソースの上に「空間 (spaces)」を定立 Why Open Dataspaces|社内勉強会 13 / 32
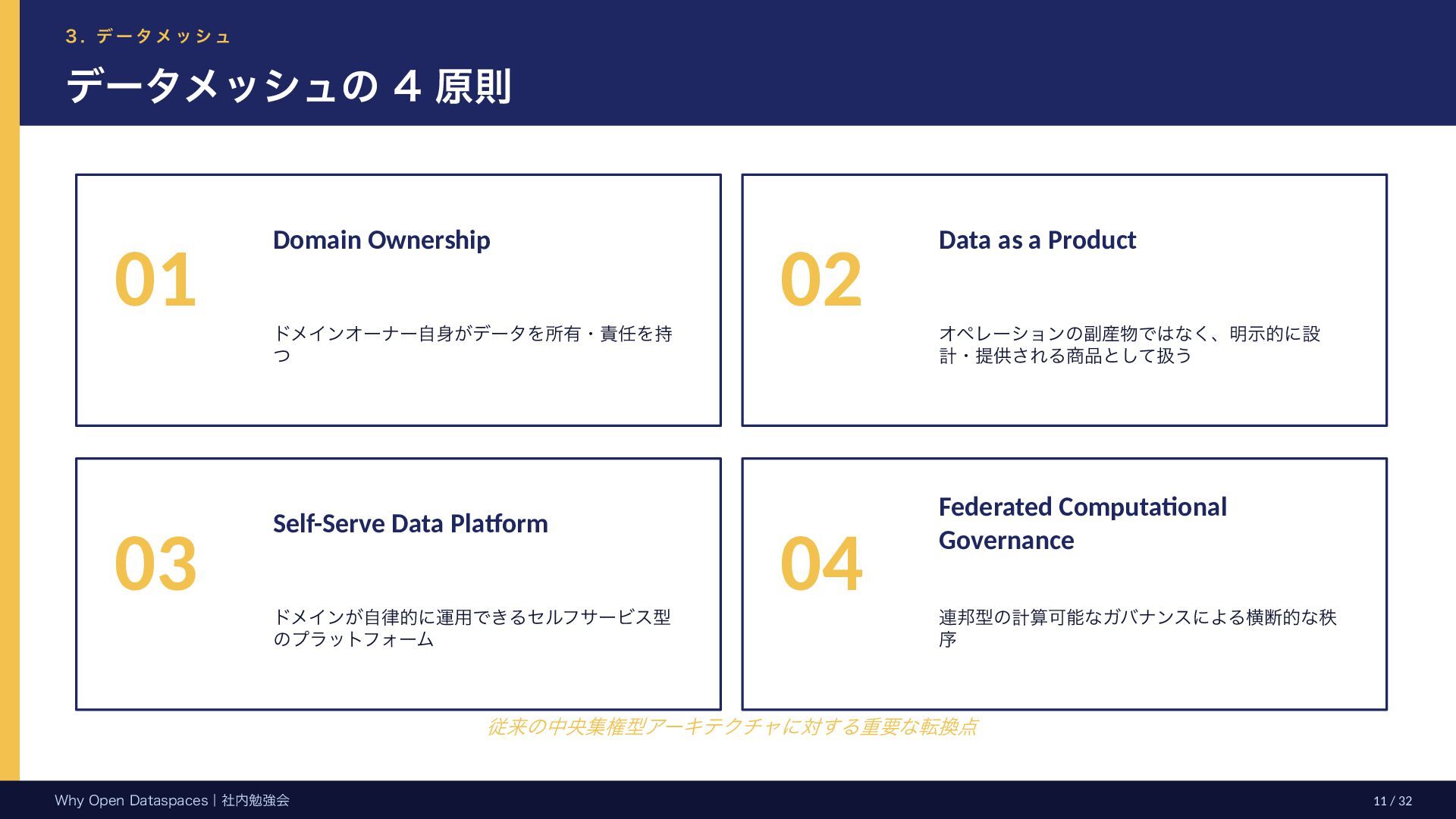
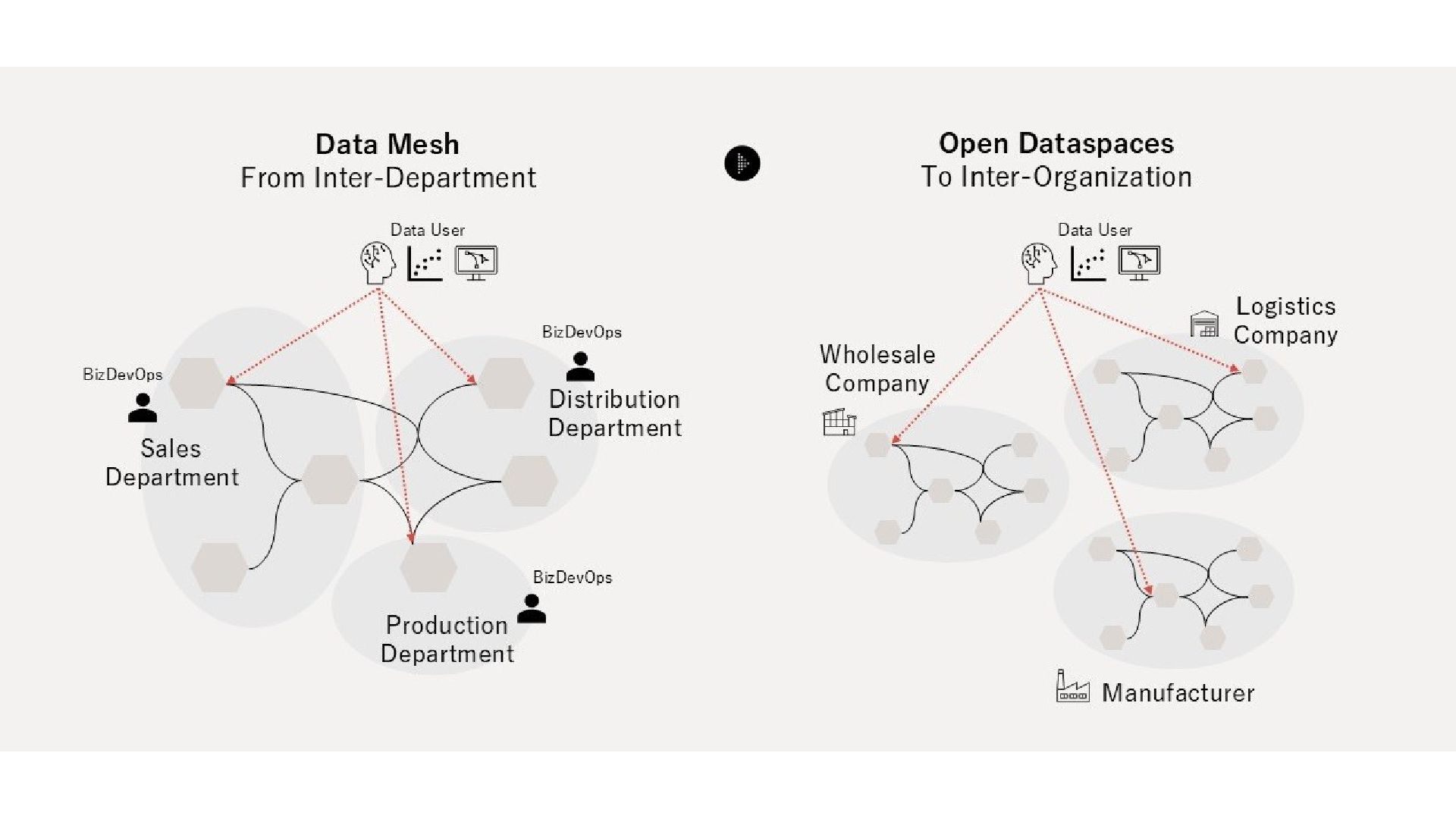
l D a t a s p a c e s Open Dataspaces の理論的な源流 2つの源流を継承し、組織・国境横断の Governance Complexity に応える Classical Dataspaces (2005, 米国) HCoD に対する抽象化概念。DBMS の補完として「空間」を定立 Data Mesh (2019, Dehghani) Serving and Pull のパラダイム。DDDベース・4原則による分散 Open Dataspaces 部門間 → 組織間 → 国境間のデータマネジメント DFFT (Data Free Flow with Trust, 2019 G20大阪) の理念を技術的に具体化 Inter-Department → Inter-Organization 継承: Serving and Pull 型 + Domain-Driven Design + 4原則 Why Open Dataspaces|社内勉強会 14 / 32
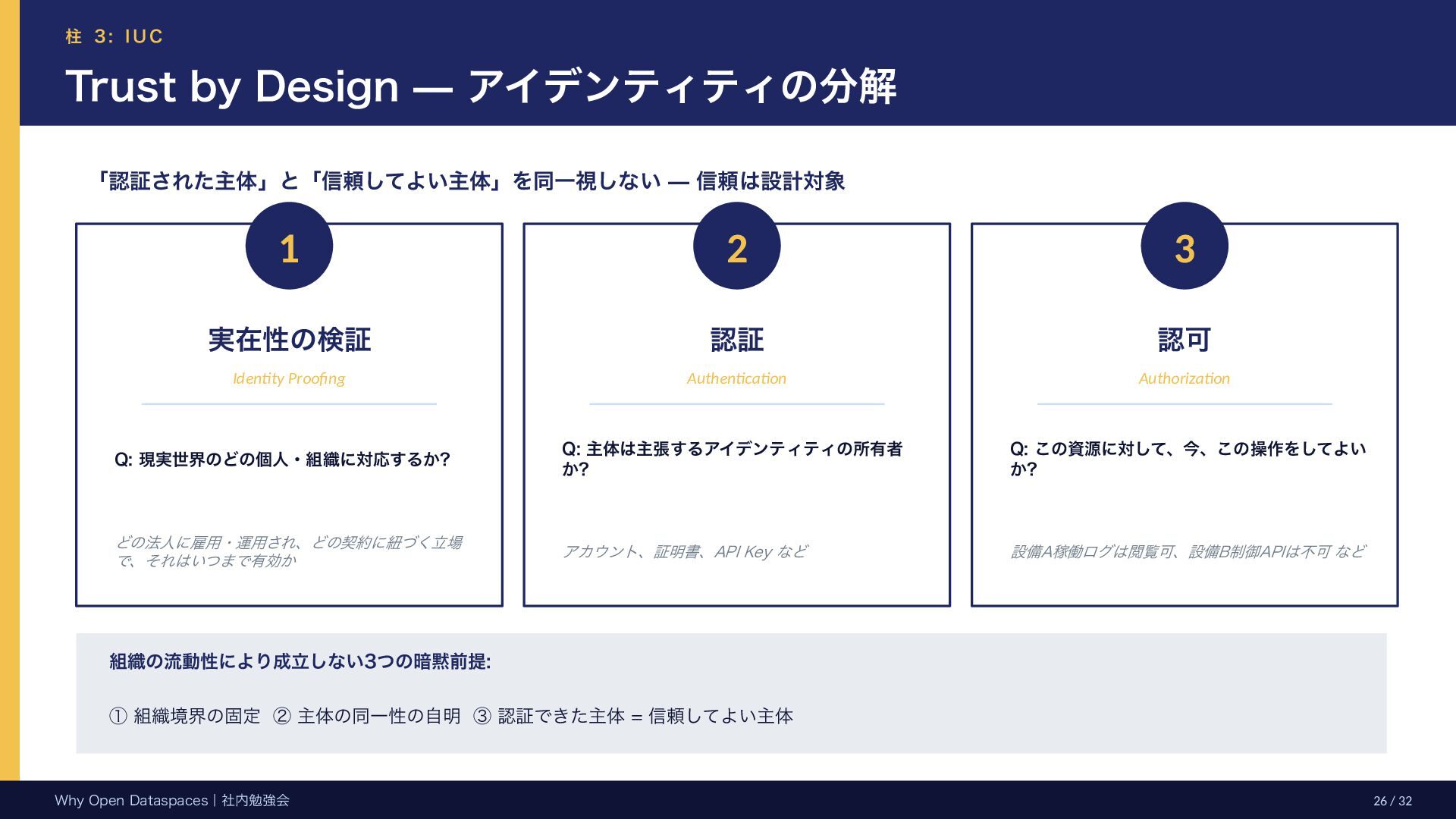
s p a c e s 3 つの柱 — 秩序と緩やかな規律 組織横断 × Agentic AIを前提に、3つの柱で透過的な SSOT と価値還元メカニズムを実現 W h e r e t o g e t DAD Data Addressability & Discoverability データの「存在」と「同一性」を保証し、関係性 を提供する緩やかな検索機構 W h a t t o m e a n OSI Ontology and Semantic Interoperability データモデルから情報モデルを分離し、推測では なく知識でデータを扱う W h o & H o w t o u s e IUC Identity and Usage Control Trust by Design の思想で、認証・認可・利用条 件を柔軟に設計 プロトコルは疎結合・後方互換を設計段階でビルトイン。Minimal Yet Viable な段階導入を重視 Why Open Dataspaces|社内勉強会 15 / 32
s p a c e s 設計指針 — 3 つの根幹原則 01 ベンダーロックインの回避 マルチクラウド・クラウドレス動作を前提とし、特定企業のサービス・商品に依存しないベンダーフリー設計 02 制度的ロックインの回避 特定法域の制度的・規制的要件を技術仕様から明示的に分離。グローバル適応可能な設計とローカライゼーション 03 プロダクトライクでサービス志向の設計 解くべき課題はマーケットにある。Make Money, Save Money に資するか。PMF を目指したアジャイル検証 注: ここでいう「Open」はデータをインターネット公開することではなく、3つのロックインからの開放を意味する Why Open Dataspaces|社内勉強会 16 / 32
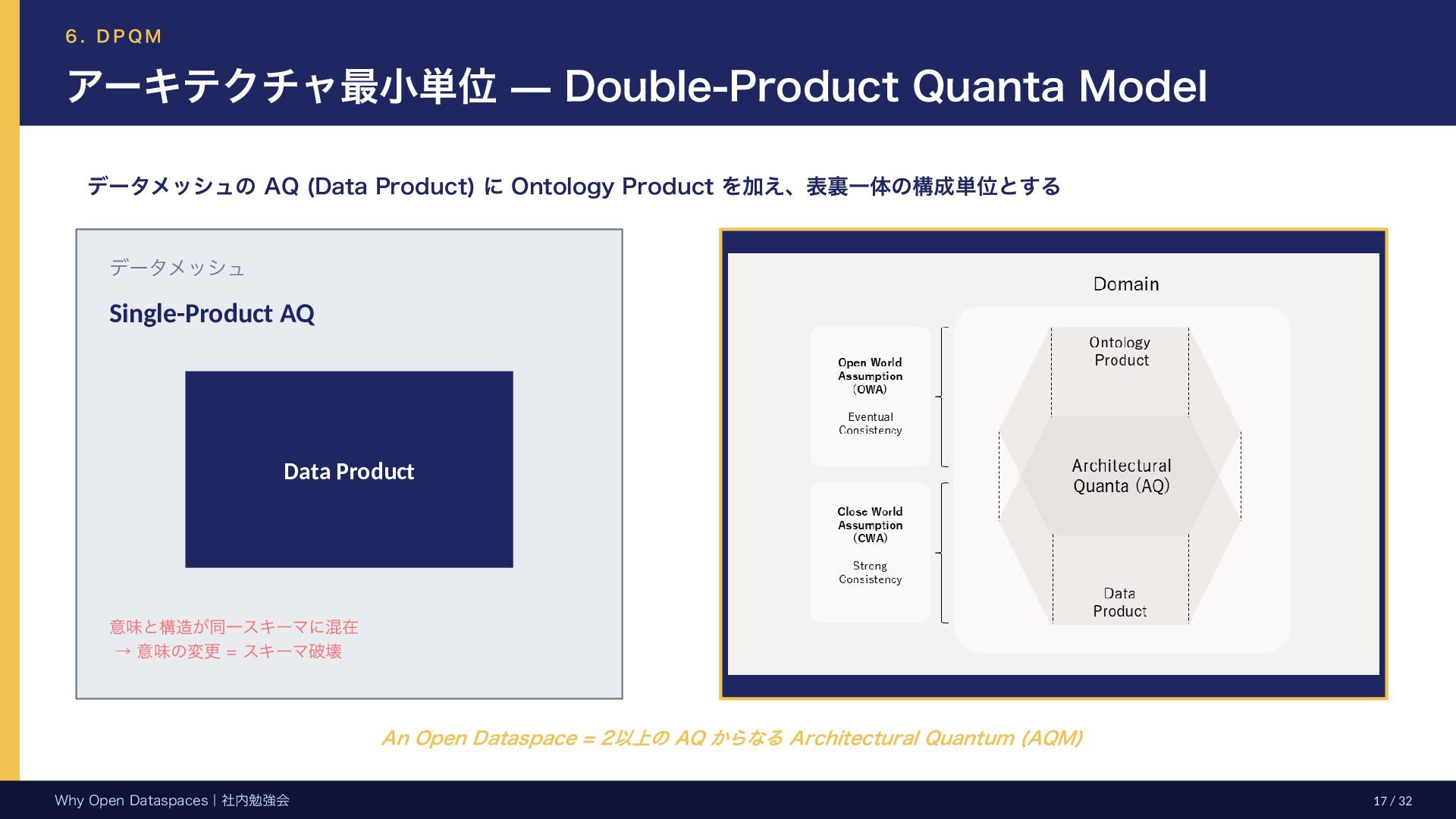
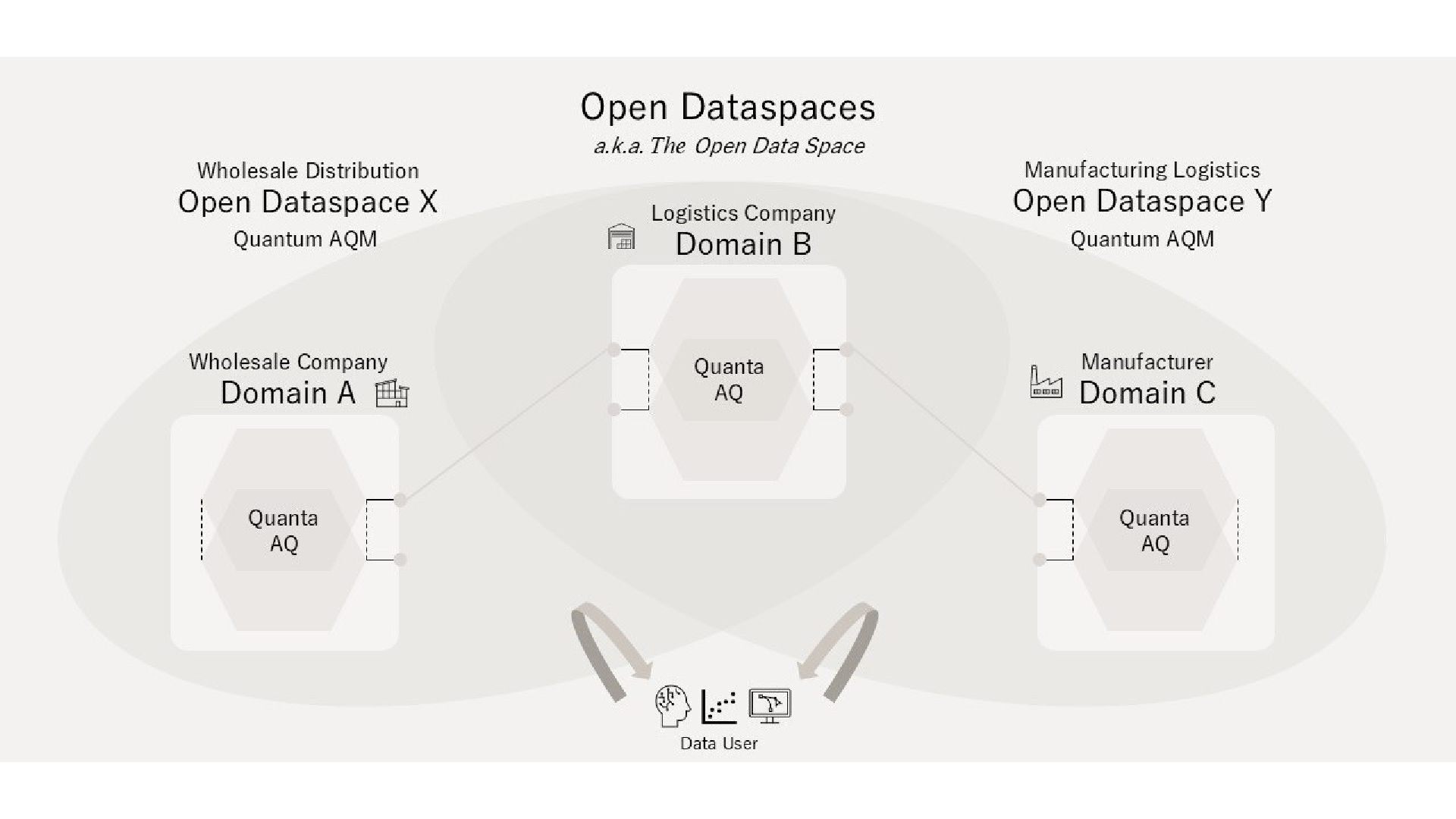
Model データメッシュの AQ (Data Product) に Ontology Product を加え、表裏一体の構成単位とする データメッシュ Single-Product AQ Data Product 意味と構造が同一スキーマに混在 → 意味の変更 = スキーマ破壊 An Open Dataspace = 2以上の AQ からなる Architectural Quantum (AQM) Why Open Dataspaces|社内勉強会 17 / 32
完全な答えを返す検索機構ではなく、関係性を提供する緩やかな検索機構 S T E P 1 Ontology Query 任意のキーワードに対して Best Effort Result (= データカタログ) を提示 ✓ 意味のグラフを返す ✓ 完全性は保証しない ✓ OWA に親和 S T E P 2 Data Query Best Effort Result のグラフをベースに、紐づく Data Endpoint へアクセス ✓ 完全性が要求される領域 ✓ 選択的 CWA / Data Trust ✓ SLOに基づく品質アセスメント 動的ビューワーとしてのデータカタログ: CKAN型の静的リポジトリではなく、クエリ依存で都度 Best Effort Result として生成される Why Open Dataspaces|社内勉強会 24 / 32
Dataspaces には存在しなかった後付け概念 Usage Control = “the specification and enforcement of restrictions regulating what must(not) happen to data” (Steinbuss et al. 2021) ① 権利義務関係の非対称性 一度アクセス許可した相手に対し、用途・条件を制御する術が なければ、資源を無配慮に提供し続けることになる ② 価格決定権の非対称性 補正なき市場原理では、価格決定権は実質的にデータ利用者が 握ることになり、市場の失敗を招く可能性 利用制御の技術的手段の多様性 — 単一プロトコルで硬直化させない Contract Negotiation データ契約による交換・交渉 ブロックチェーン秘密計算 BI/DI領域 (例: カーボンフットプリント) Data Clean Room AI領域での差分プライバシー学習 Machine Unlearning 先端研究中の忘却技術 市場からの要件由来ではなく、制度要件由来の技術的手段を強制することは、適合コストを強いることになる Why Open Dataspaces|社内勉強会 28 / 32
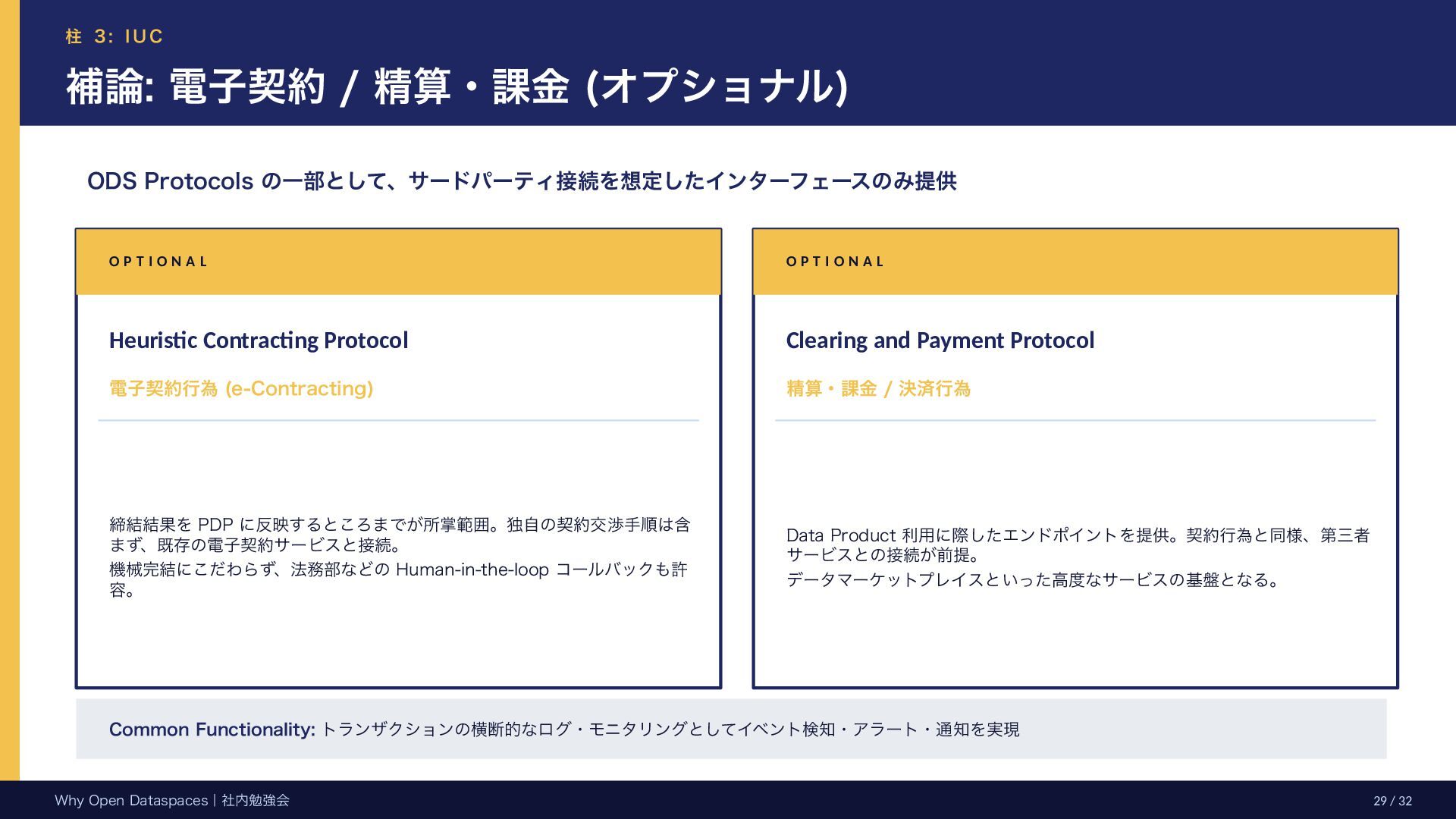
(オプショナル) ODS Protocols の一部として、サードパーティ接続を想定したインターフェースのみ提供 O P T I O N A L Heuristic Contracting Protocol 電子契約行為 (e-Contracting) 締結結果を PDP に反映するところまでが所掌範囲。独自の契約交渉手順は含 まず、既存の電子契約サービスと接続。 機械完結にこだわらず、法務部などの Human-in-the-loop コールバックも許 容。 O P T I O N A L Clearing and Payment Protocol 精算・課金 / 決済行為 Data Product 利用に際したエンドポイントを提供。契約行為と同様、第三者 サービスとの接続が前提。 データマーケットプレイスといった高度なサービスの基盤となる。 Common Functionality: トランザクションの横断的なログ・モニタリングとしてイベント検知・アラート・通知を実現 Why Open Dataspaces|社内勉強会 29 / 32
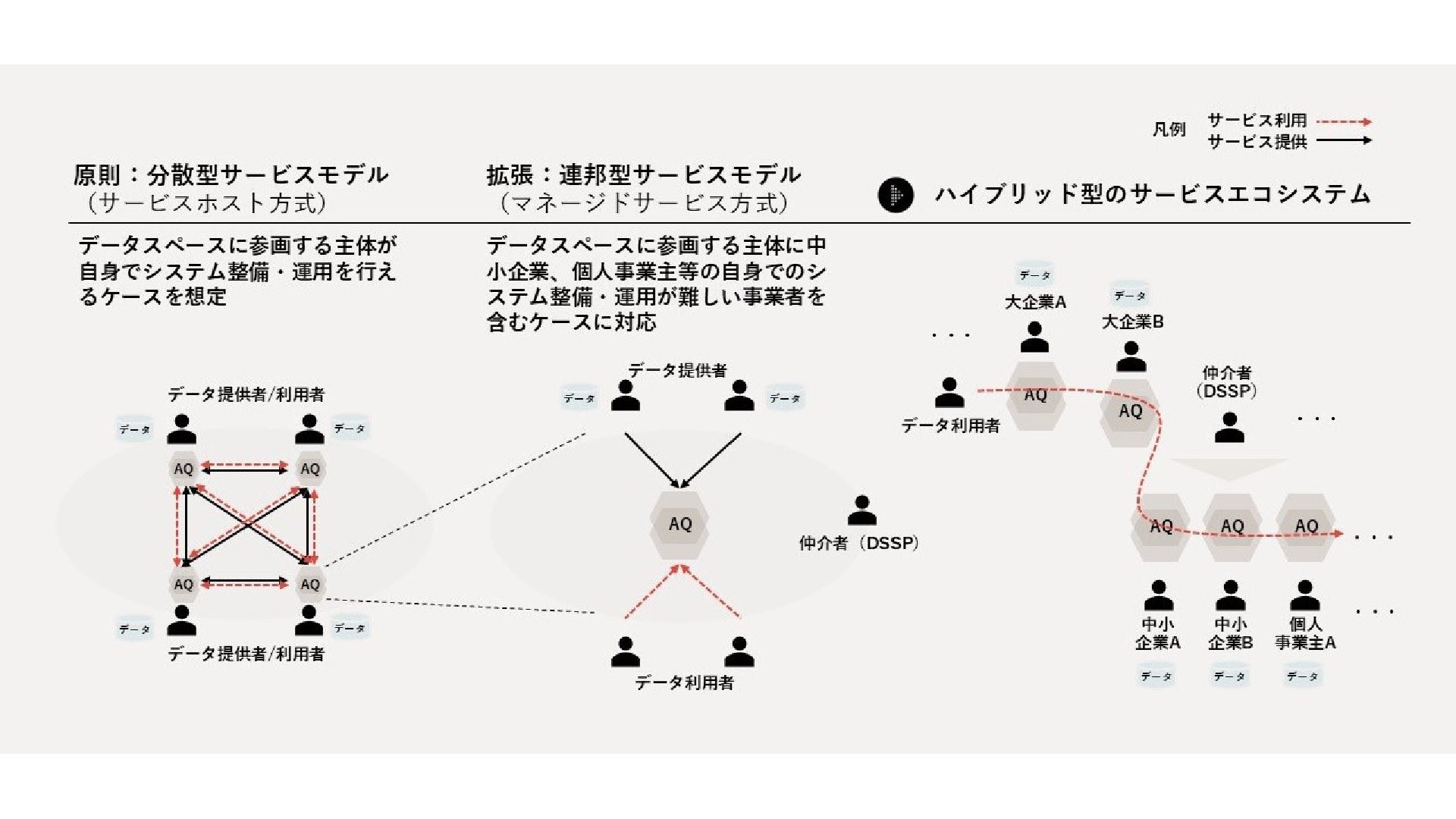
/ 連邦型 / HSM D i s t r i b u t e d 分散型サービスモデル ドメインオーナー自身が Self-Serve Data Platform を構築し、DPQM に基づいて Data Product / Ontology Product を提供 デジタル財源のある大企業向け F e d e r a t e d 連邦型サービスモデル ソフトウェアスタックを DSSP (Dataspace Service Provider) が代理提供。ドメイン オーナーはProduct提供に責任を持つ 中小企業やリソース制約下でも導入可能 H S M Hybrid Service Model 分散型 × 連邦型の混成。ドメインオーナー自 身と DSSP 仲介の両経路でオンボード 実例: 車載蓄電池CFP (OEM+Tier1+Tier2) DSSP (Dataspace Service Provider) = Classical Dataspaces 由来。仲介者 (Intermediaries) として Open Dataspaces の裾野を拡大する重要プレイヤー Why Open Dataspaces|社内勉強会 30 / 32
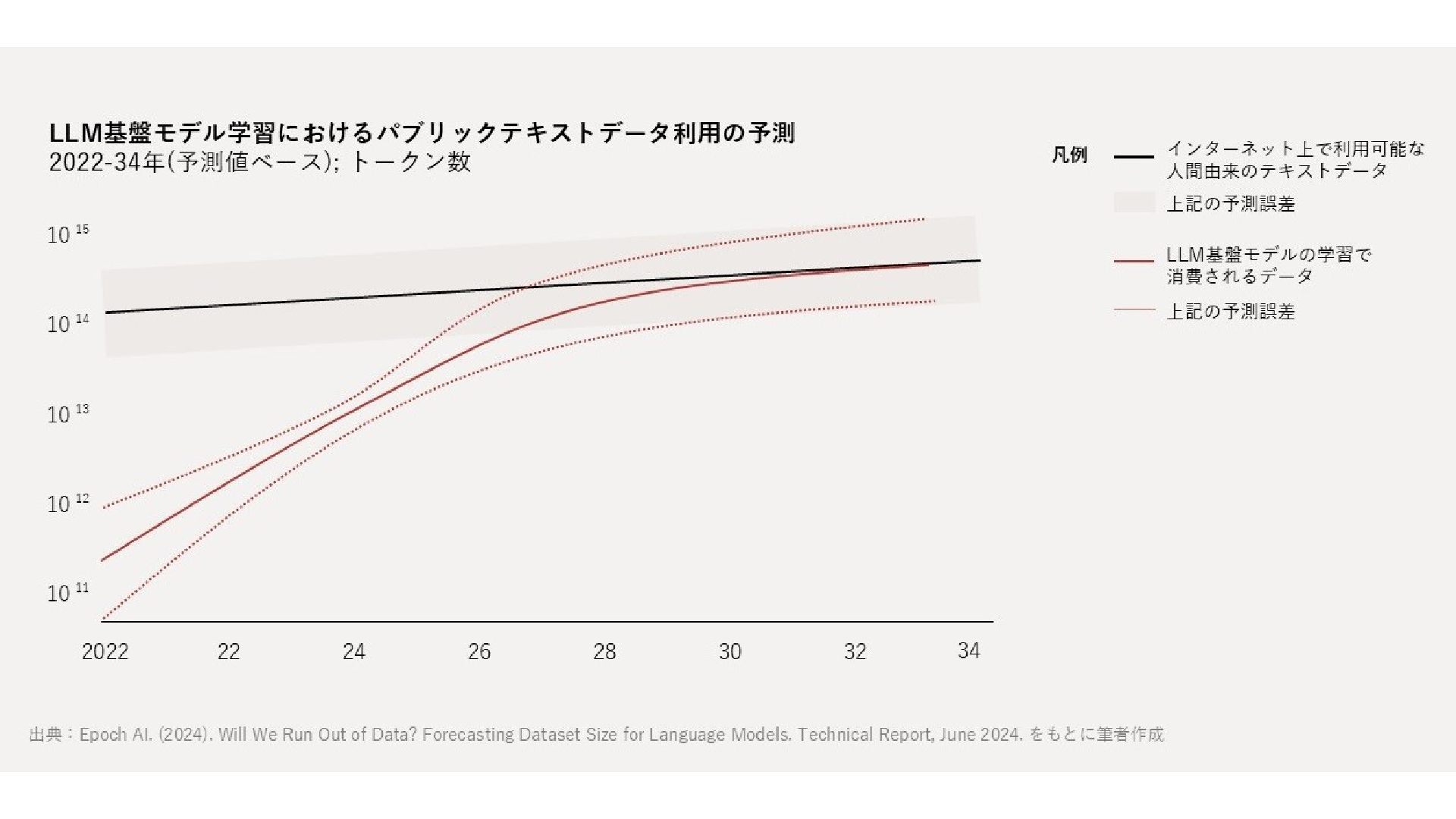
参考文献・さらなる学習リソース 主要参考文献 • Franklin, Halevy, Maier (2005) “From databases to dataspaces” • Halevy, Franklin, Maier (2006) “Principles of Dataspace Systems” • Dehghani Z. (2019) “How to Move Beyond a Monolithic Data Lake…” • Dehghani Z. (2022) Data Mesh (O’Reilly) • Otto B. et al. (2016) Industrial Data Space Whitepaper (Fraunhofer) • Steinbuss S. et al. (2021) Usage Control in IDS • Epoch AI (2024) “Will We Run Out of Data?” • NEDO (2025) Data Spaces Market Size Study • METI / IPA (2025) Ouranos Ecosystem Dataspaces RAM Whitepaper 次に読むべきドキュメント ODS-RAM Reference Architecture Model — 具体的な設計物 ODS Protocols 各プロトコル技術仕様 (Trust / Usage / Contracting 等) ODS Middleware 参照実装 OSS ソースコード Contact: IPA デジタルアーキテクチャ・デザインセンター [email protected] “伽藍とバザールの理念を胸に、全世界のOSSコミュニティの力を信じて前進させる” — 津田通隆 Why Open Dataspaces|社内勉強会 32 / 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}