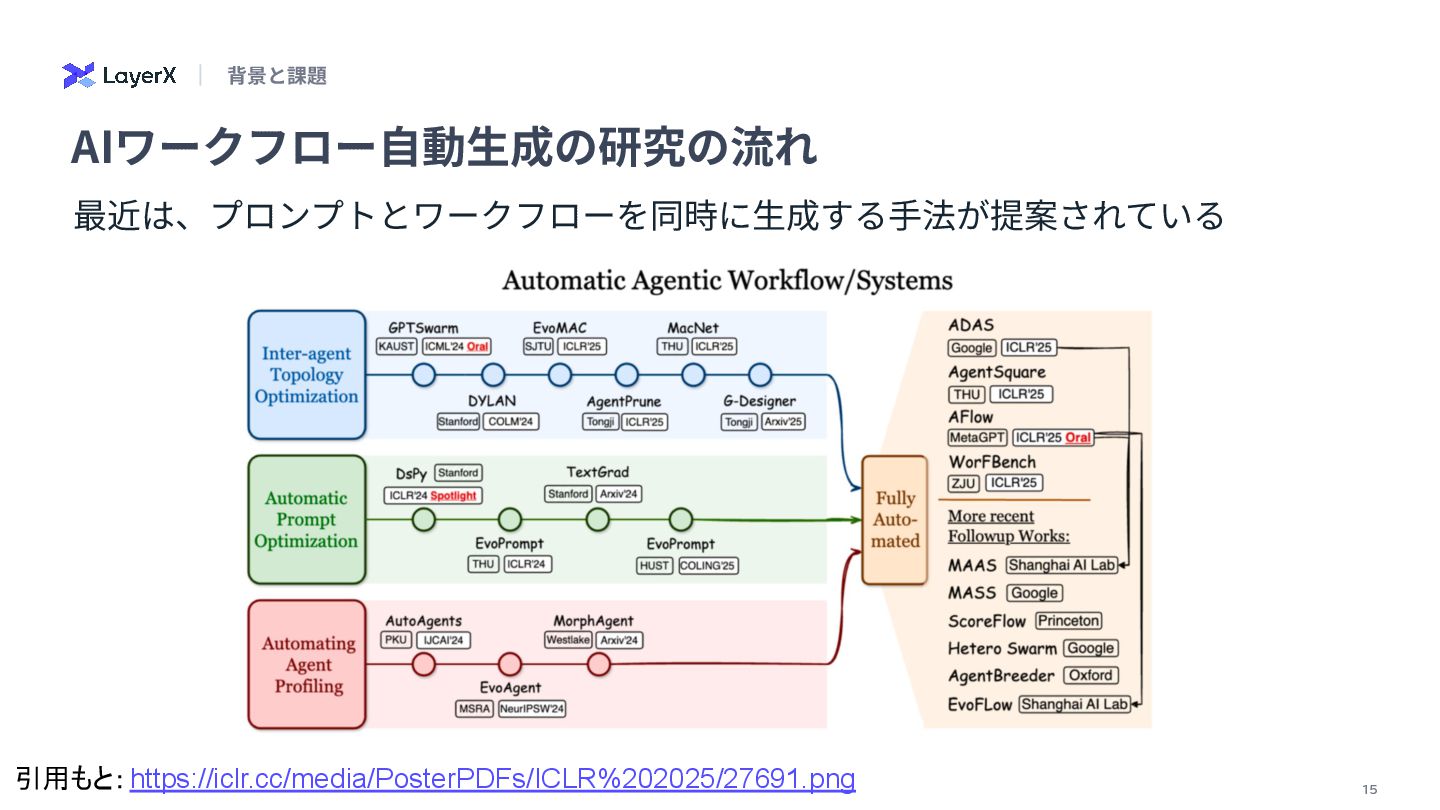
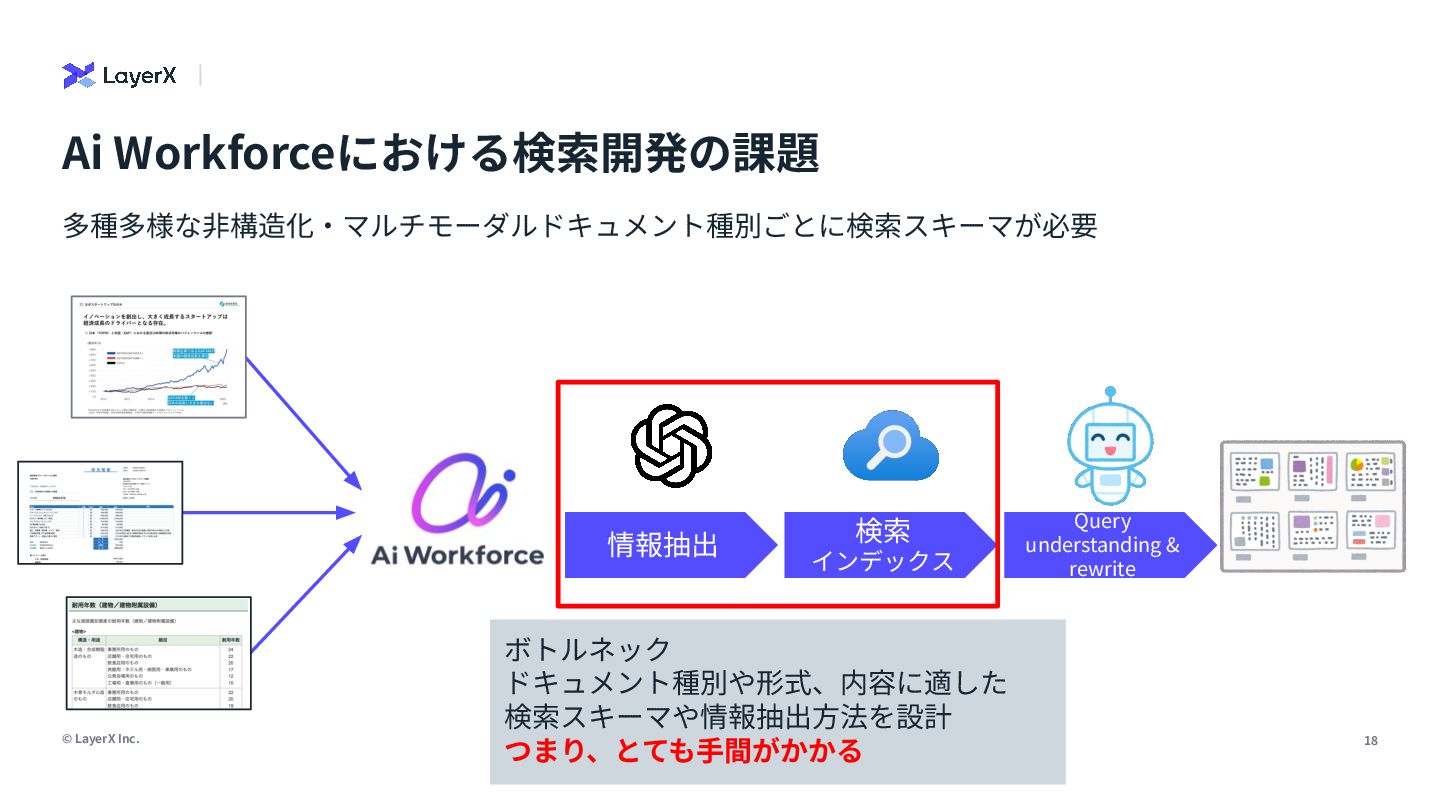
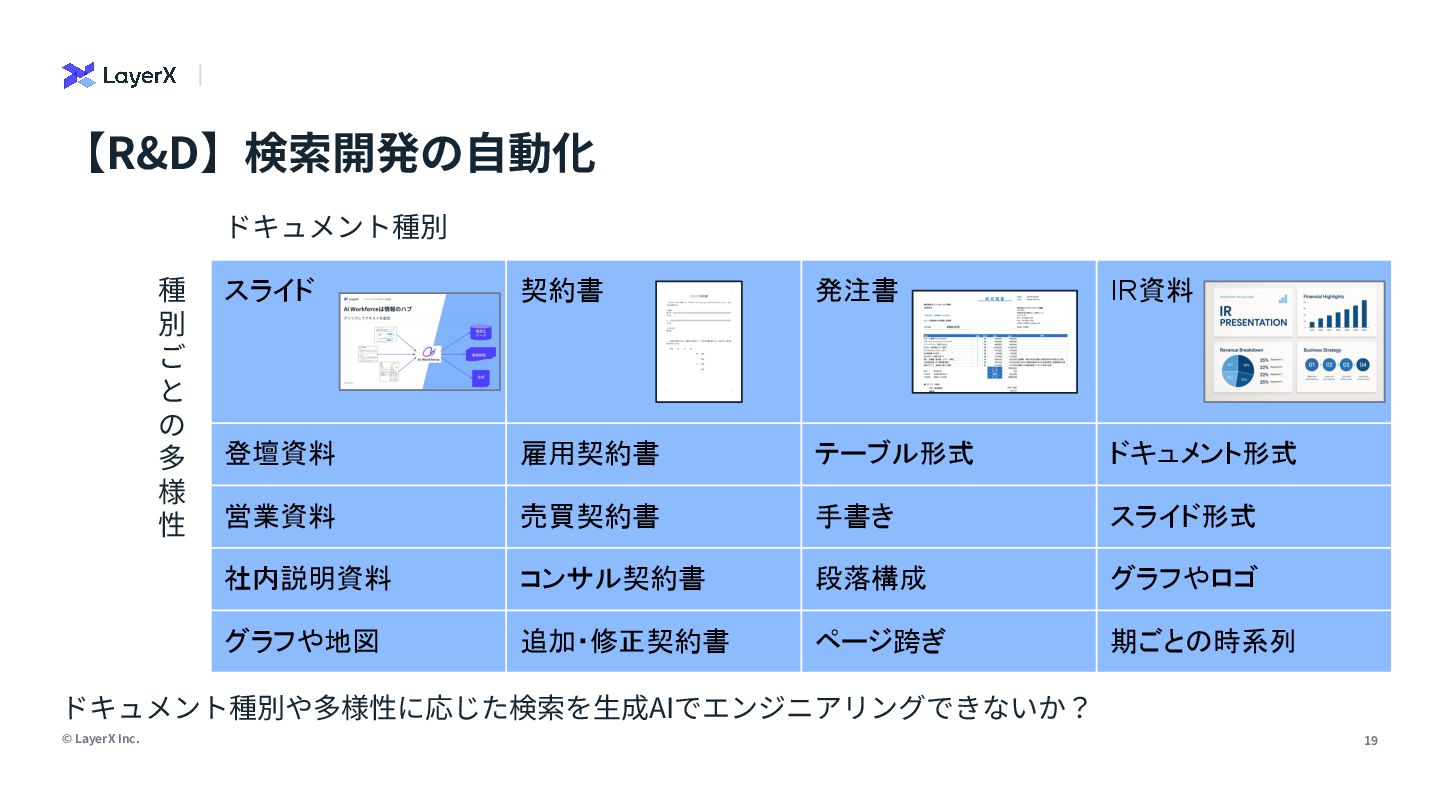
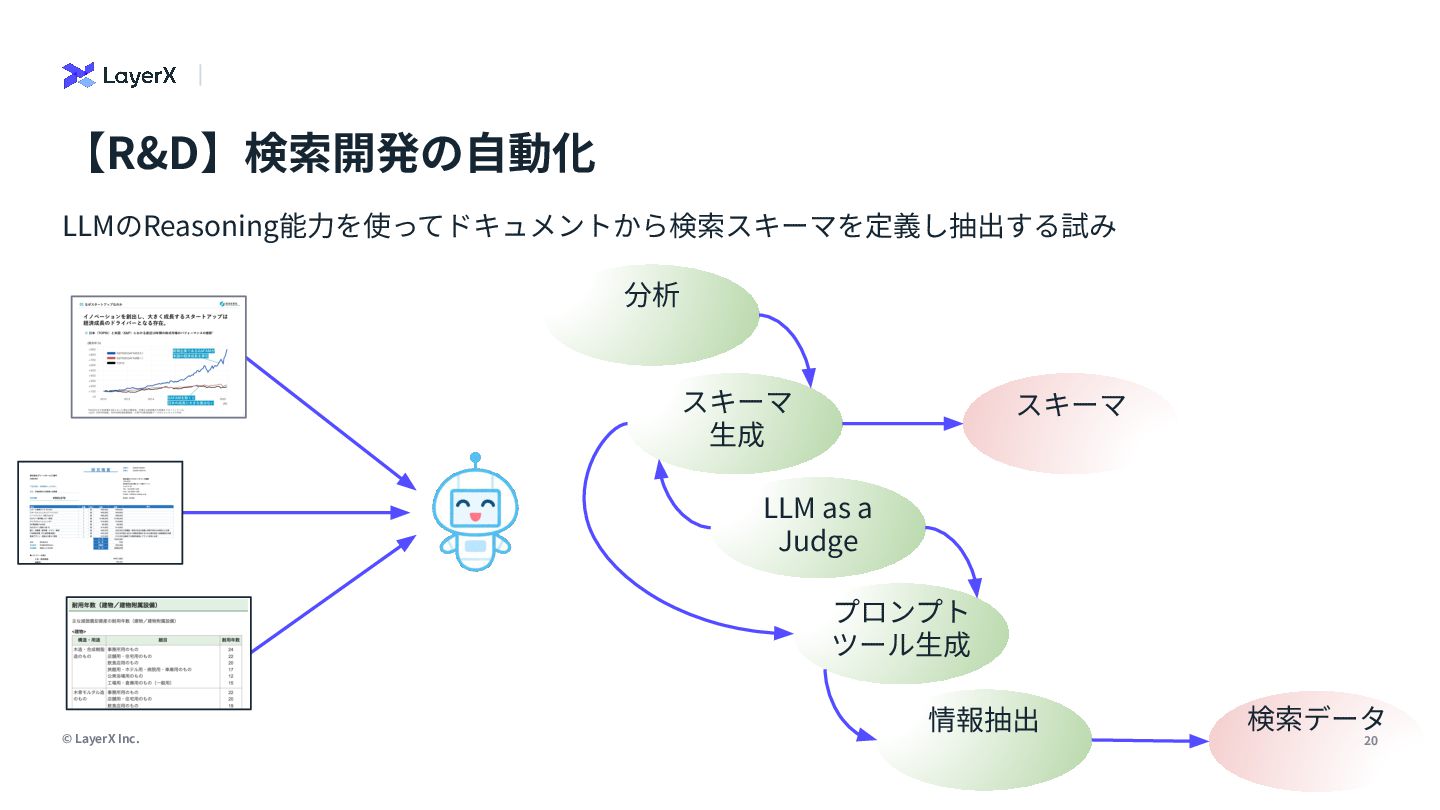
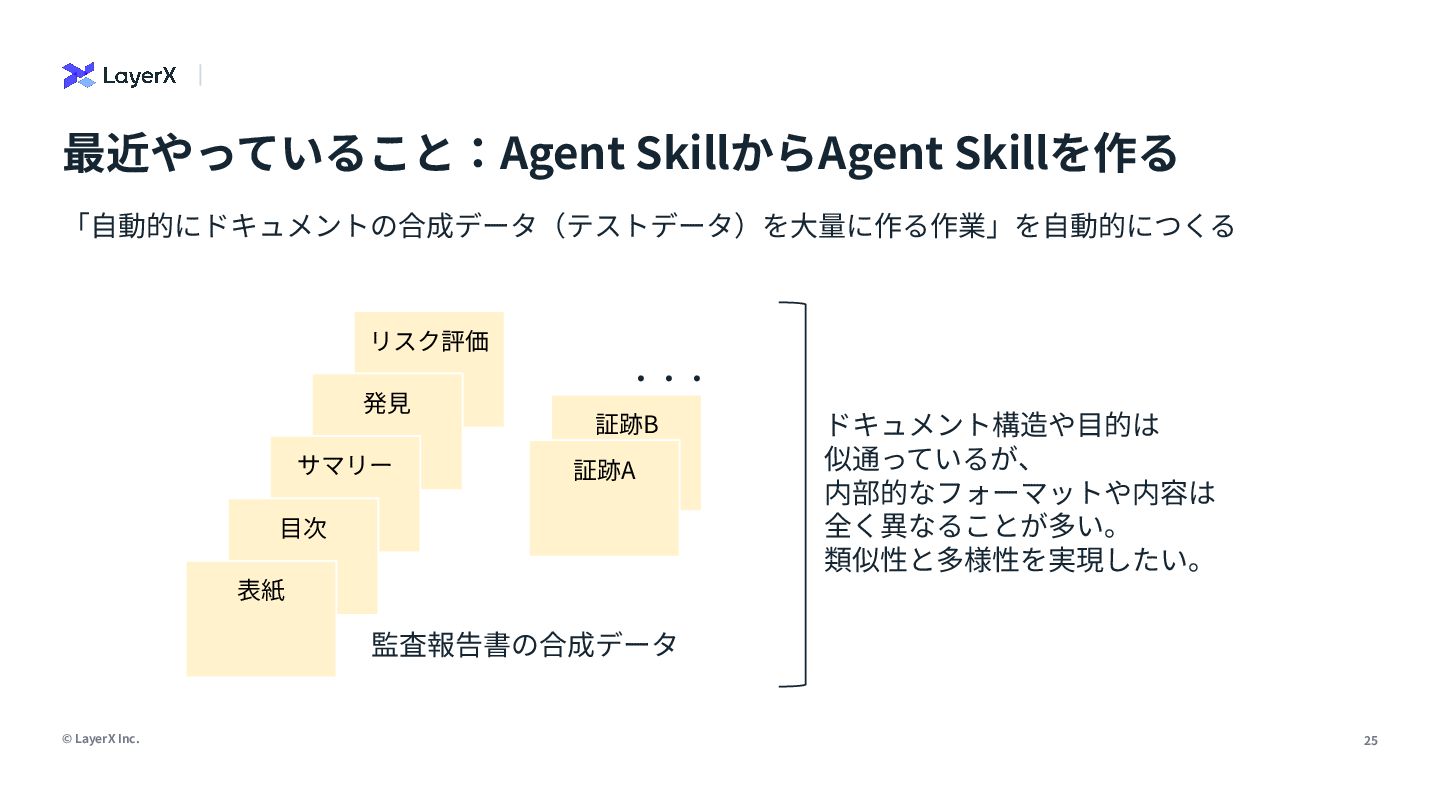
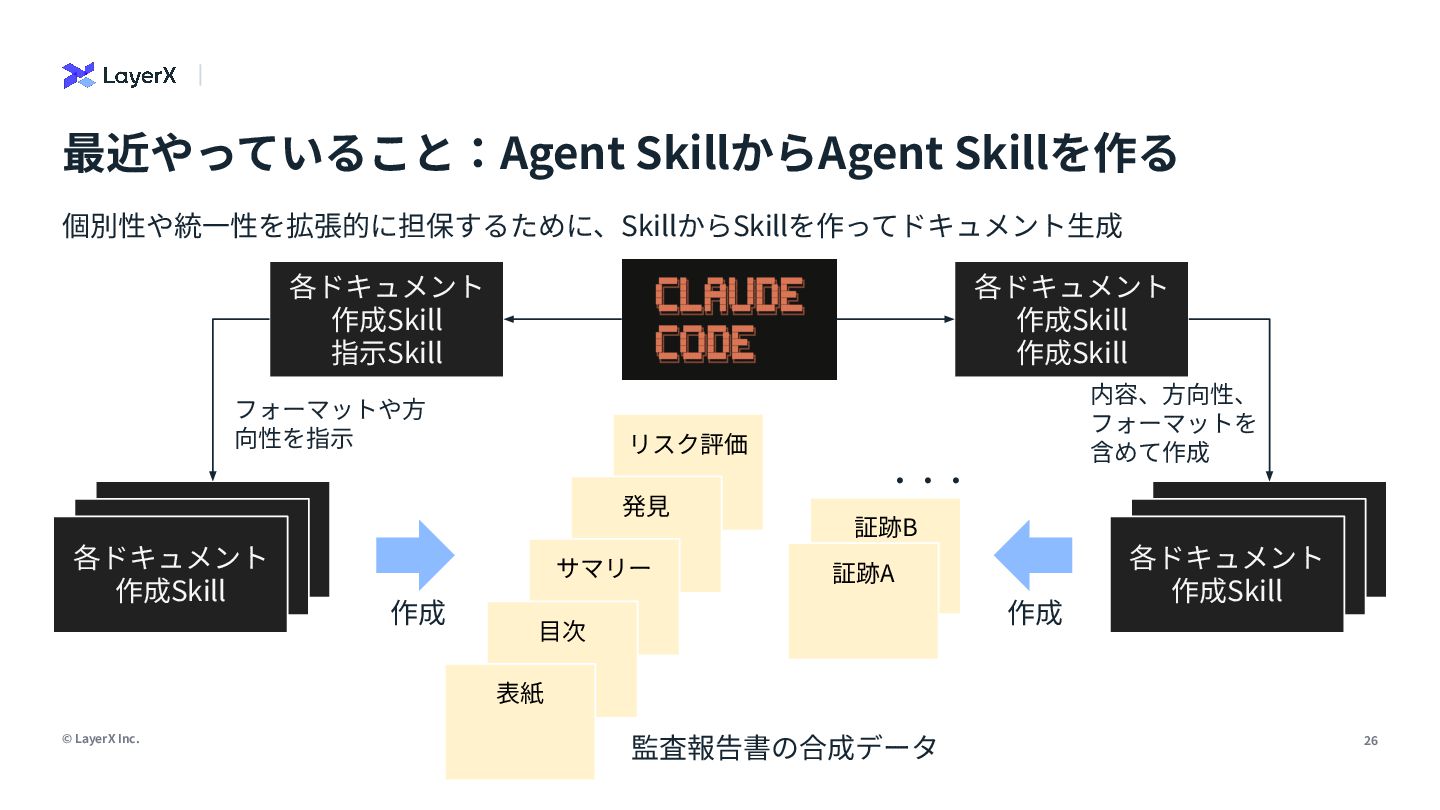
analyzing the content of documents that may include both text and visual elements (scanned pages, slide images, charts, tables, captions, labels and figure legends). </role> <instructions> Your task: extract all textual content that belongs to the search field "numeric_and_figure_text" from the provided PDF page text and the provided page image. The output must be a single string (one line) representing the value of this search field for the page(s). Follow these rules precisely: 1) What to extract: any text that is part of or comes from tables, charts, figures or their annotations, including… LLMのReasoning能⼒を使ってドキュメントから検索スキーマを定義し抽出する試み 【R&D】検索開発の⾃動化 分析 スキーマ ⽣成 LLM as a Judge プロンプト ツール⽣成 情報抽出 page_semantic:ページ‧スライド単位のテキスト埋め込み figure_and_numeric:図やグラフ、地図、テーブルのテキストや数値 diagram_structure:図表やダイアグラムの構造や形状、レイアウト
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}