Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
画像生成AIについて
Search
shibuiwilliam
February 09, 2026
Technology
78
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
画像生成AIについて
画像生成AIについて、Deep researchとNano banana、Claude Code PPTX Skillsを組み合わせて自動生成した資料。
資料作成をほぼ自動化できた。
shibuiwilliam
February 09, 2026
More Decks by shibuiwilliam
See All by shibuiwilliam
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
440
From Prompt Engineering to Loop Engineering
shibuiwilliam
1
370
OntologyとLLMOps
shibuiwilliam
3
86
Rule repository
shibuiwilliam
3
65
LLM時代の検索アーキテクチャと技術的意思決定
shibuiwilliam
5
2.5k
Why Open Dataspacesのまとめ
shibuiwilliam
2
100
マルチモーダル非構造データとの闘い
shibuiwilliam
2
680
飽くなき自動生成への挑戦
shibuiwilliam
1
94
AIエージェントのメモリについて
shibuiwilliam
2
800
Other Decks in Technology
See All in Technology
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
160
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
810
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
26
11k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
620
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.3k
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
0
130
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
150
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
490
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
530
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
490
Featured
See All Featured
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Unsuck your backbone
ammeep
672
58k
The agentic SEO stack - context over prompts
schlessera
0
850
Tell your own story through comics
letsgokoyo
1
1k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
340
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
So, you think you're a good person
axbom
PRO
2
2.1k
Practical Orchestrator
shlominoach
191
11k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
550
Transcript
画像生成AIの最前線 拡散モデルからDriftingモデルまで Diffusion Models / Flow Matching / DiT /
Drifting Models 2026/02/10 Shibui Yusuke, with Claude Code PPTX Skills
目次 01 拡散モデルの基礎 Forward / Reverse Diffusion 02 U-Netと潜在拡散モデル LDM
/ Stable Diffusion 03 フローモデルとフロー・マッチング Normalizing Flows / Rectified Flow 04 Diffusion Transformer (DiT) U-NetからTransformerへ 05 MM-DiTとSD3 Multi-Modal Diffusion Transformer 06 Driftingモデル 1ステップ生成の新パラダイム 07 まとめと展望 生成AIの未来
01 拡散モデルの基礎 Diffusion Models 現在の画像生成AIの基盤技術
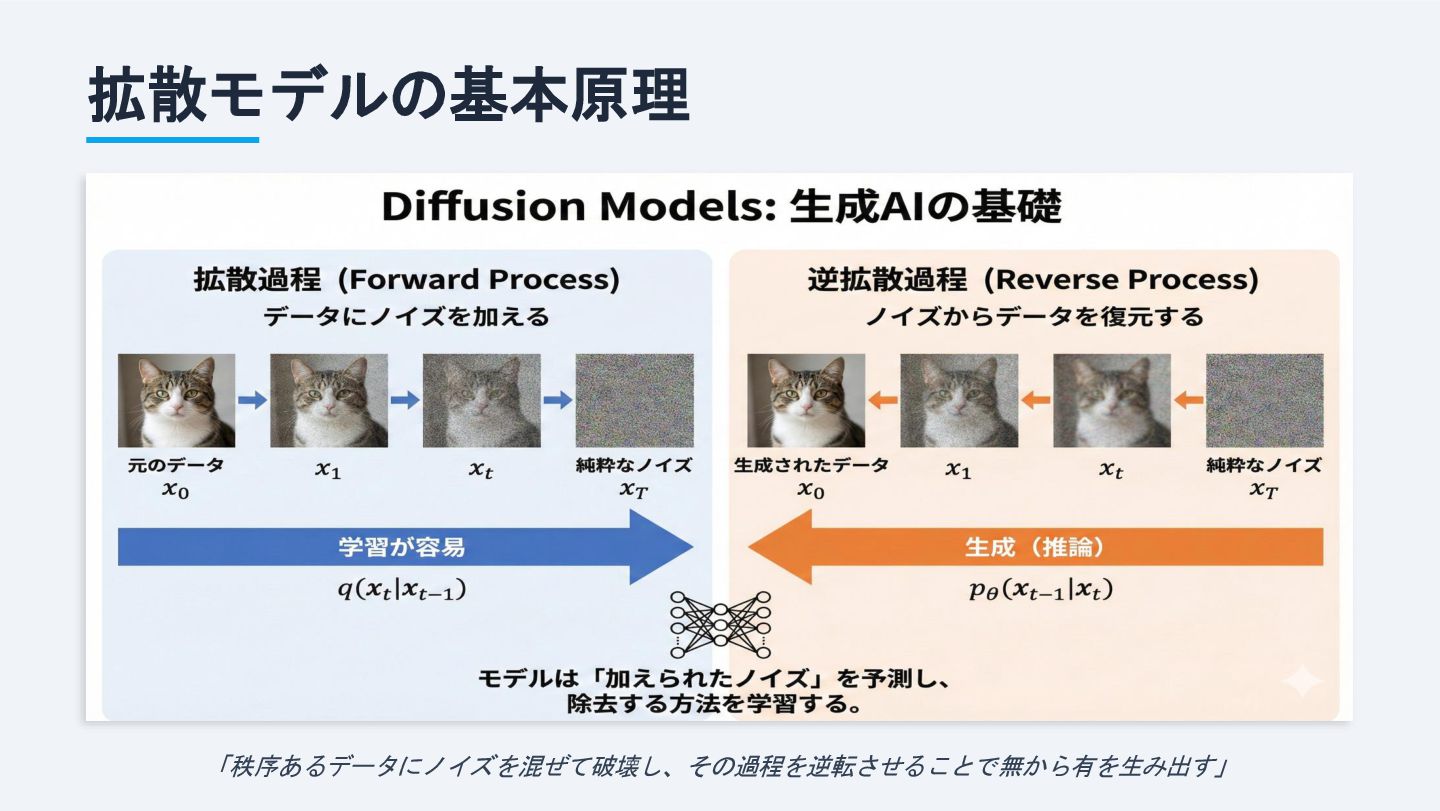
拡散モデルの基本原理 「秩序あるデータにノイズを混ぜて破壊し、その過程を逆転させることで無から有を生み出す」
順方向と逆方向のプロセス 順方向プロセス(拡散) Forward Diffusion Process • 画像に微量のガウスノイズを段階的に 追加 • 最終的に元の情報は完全に失われる
• ホワイトノイズ(純粋なランダム)へ • 数学的に定義(学習不要) 逆方向プロセス(生成) Reverse Diffusion Process • ノイズからデータを段階的に復元 • NNが「除去すべきノイズ」を予測 • スコアベースモデルとも呼ばれる • 学習の本質はここにある
DDPM:数学的フレームワーク ノイズの付加(Forward) 時刻 t における画像 x_t は前時刻 の画像にノイズを加えて定義 q(x_t |
x_{t-1}) = N(x_t; √(1-β_t)x_{t-1}, β_t I) β_t:ノイズ量のスケジュール 損失関数(学習目的) モデルは「含まれるノイズ量」を予測 L = E[ || ε - ε_θ(x_t, t) ||² ] ε:実際のノイズ ε_θ:モデルの予測ノイズ Denoising Diffusion Probabilistic Models (DDPM) 2020年にHo et al.により提案。ガウスノイズの付加・除去を確率過程として定式化し、高品質な画像生成 を実現。非平衡熱力学の概念を応用した画期的なモデルであり、現在のStable DiffusionやDALL-Eの基礎と なった。
02 U-Netと潜在拡散モデル Latent Diffusion Models 高効率な画像生成への進化
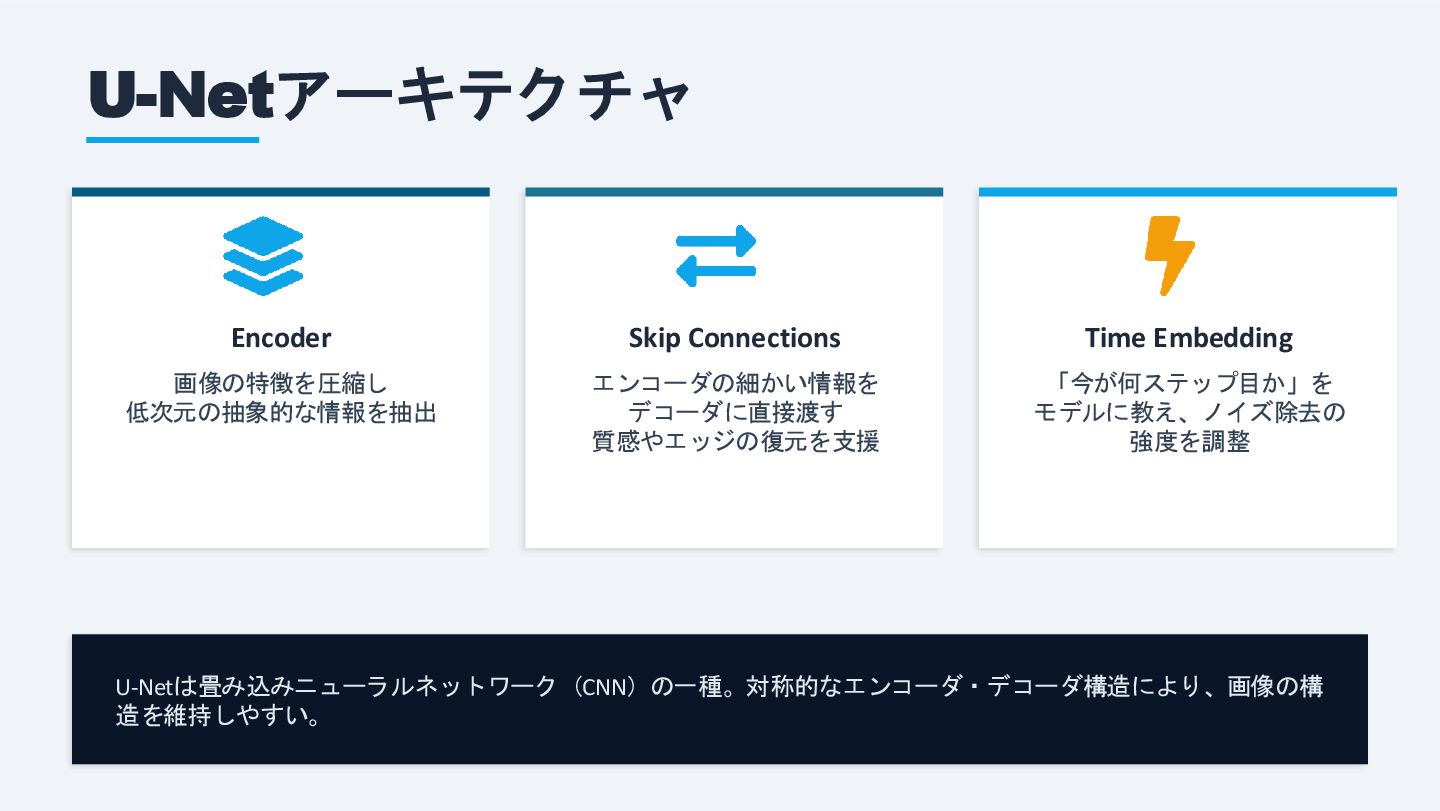
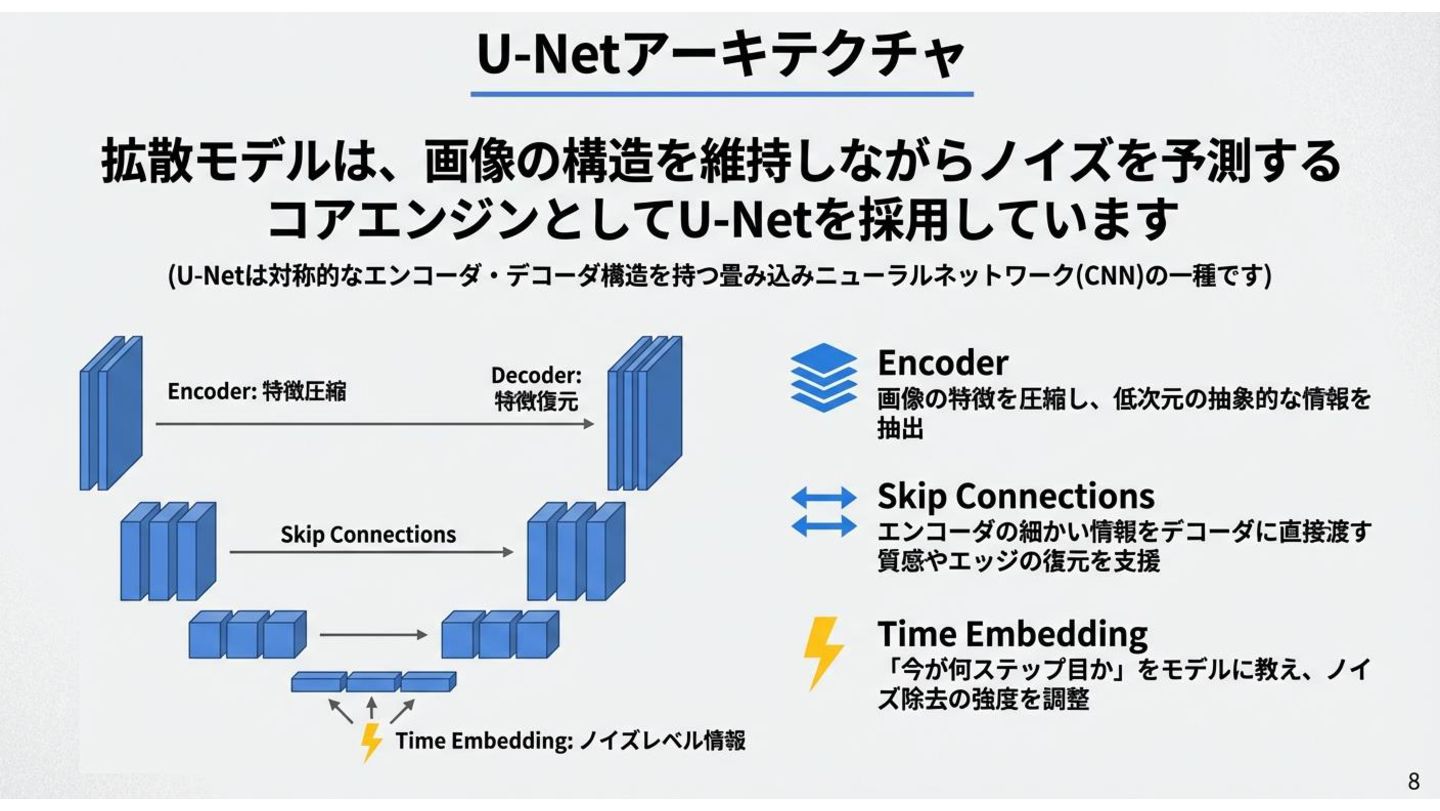
U-Netアーキテクチャ Encoder 画像の特徴を圧縮し 低次元の抽象的な情報を抽出 Skip Connections エンコーダの細かい情報を デコーダに直接渡す 質感やエッジの復元を支援 Time
Embedding 「今が何ステップ目か」を モデルに教え、ノイズ除去の 強度を調整 U-Netは畳み込みニューラルネットワーク(CNN)の一種。対称的なエンコーダ・デコーダ構造により、画像の構 造を維持しやすい。
None
潜在拡散モデル(LDM) 元画像 (512×512) VAE Encoder 潜在空間 (64×64) 拡散プロセス VAE Decoder
生成画像 (512×512) 計算量の大幅削減 潜在空間で処理することで、ピクセ ル空間の1/64の計算量 家庭用PCで実行可能 Stable Diffusionの登場により、個人 でも高品質な画像生成が可能に 高品質を維持 VAEにより画像の本質的な情報を保 持しつつ圧縮
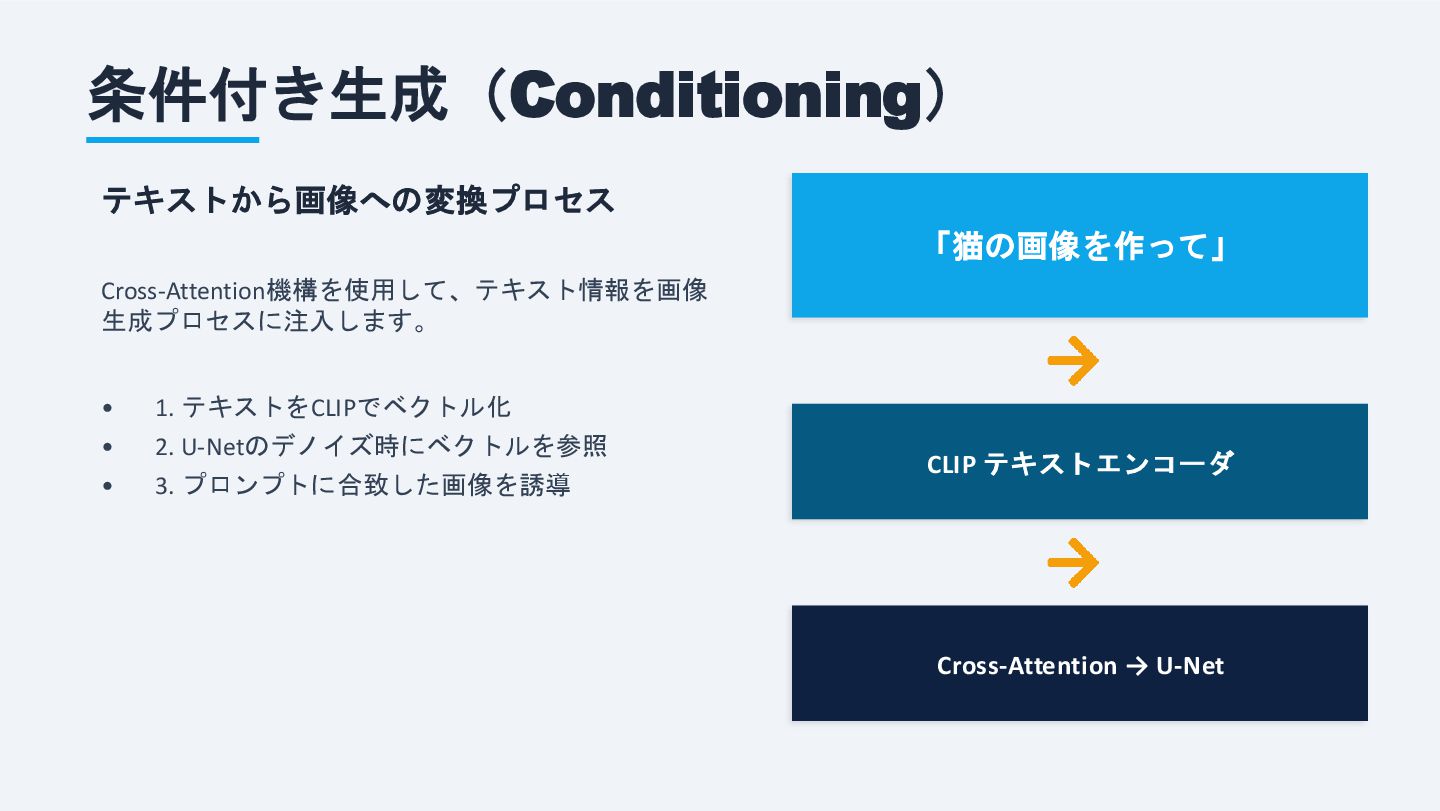
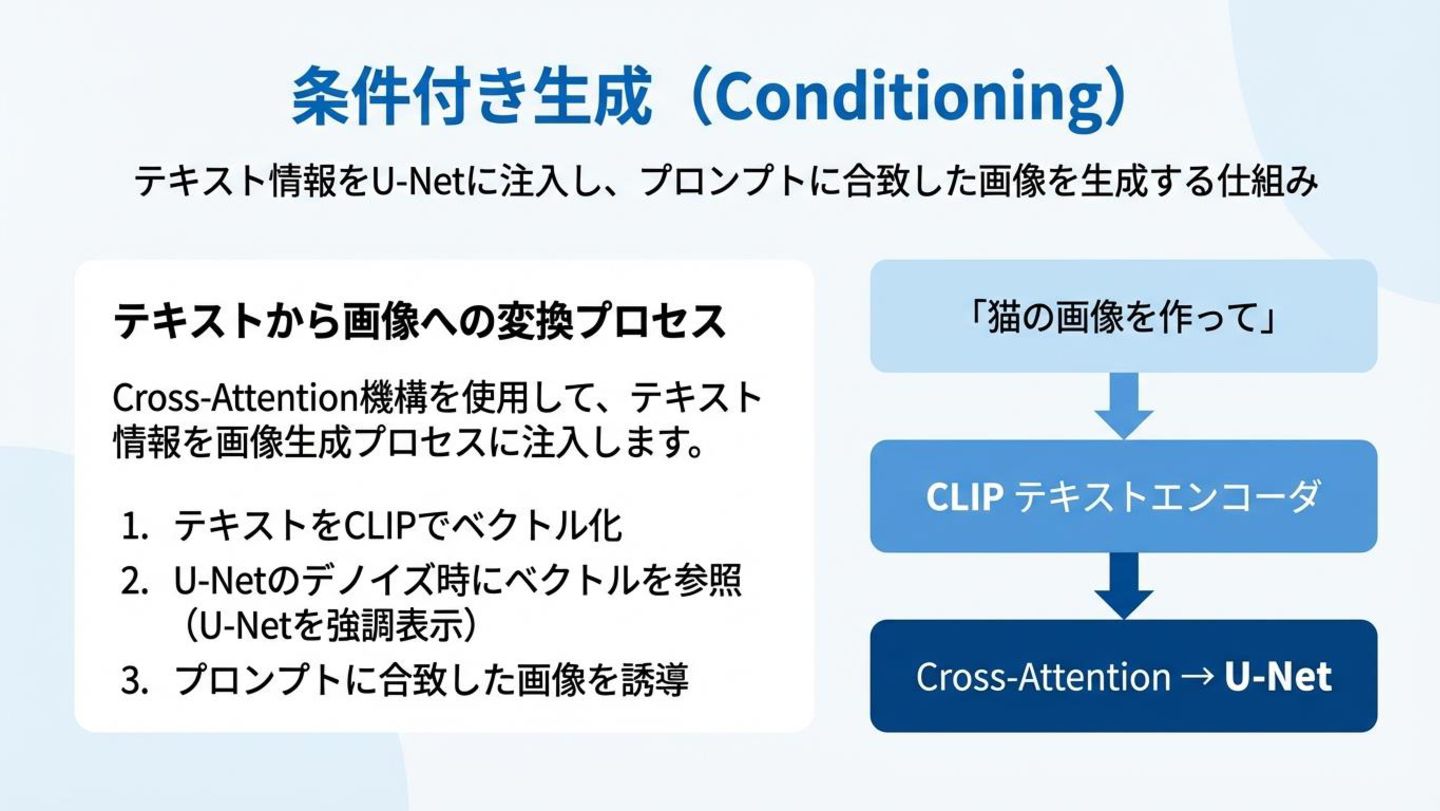
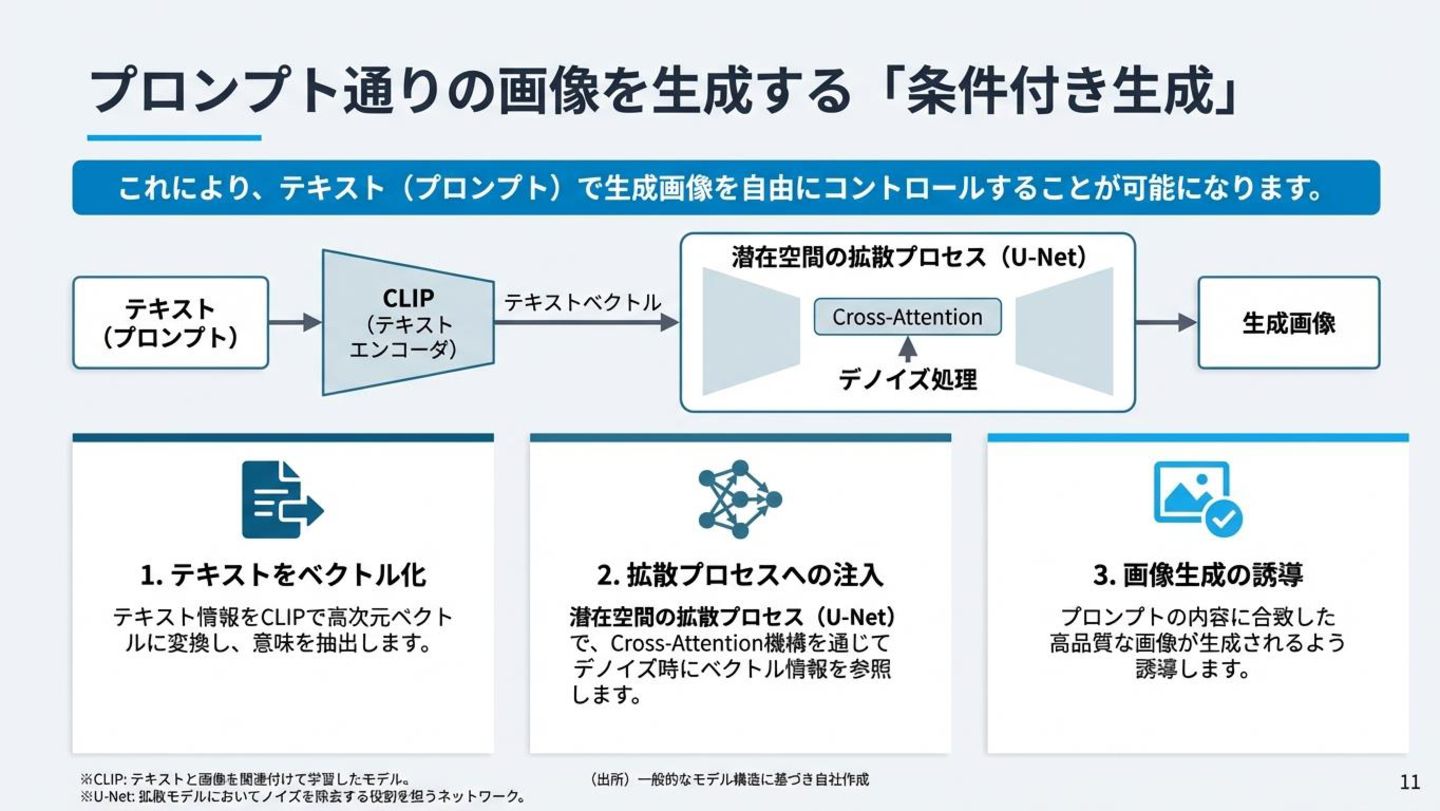
条件付き生成(Conditioning) テキストから画像への変換プロセス Cross-Attention機構を使用して、テキスト情報を画像 生成プロセスに注入します。 • 1. テキストをCLIPでベクトル化 • 2. U-Netのデノイズ時にベクトルを参照
• 3. プロンプトに合致した画像を誘導 「猫の画像を作って」 CLIP テキストエンコーダ Cross-Attention → U-Net
None
拡散モデルの課題と解決策 課題:生成速度が遅い 1枚の画像を生成するのに何十回もデノイズを繰り返す必要があり、GANなどの1ステップモデルに比べて計算 コストが高い。 サンプラー改良 DDIM等の手法で 10〜20ステップでの 生成が可能に 蒸留(Distillation) 多段階の推論を
1段階に凝縮 (例: SDXL Turbo) フロー・マッチング 拡散プロセスを 直線化して効率的 な生成を実現
03 フローモデルと フロー・マッチング Flow-based Models & Flow Matching 直線的な生成経路への革新
フローモデルの仕組み 「粘土細工を少しずつ変形させて形を作る」イメージ 正規化フロー(Normalizing Flows) • 可逆な変換関数を何度も適用 z₀ → f₁ →
f₂ → ... → fₖ → x • z₀: 単純なノイズ • x: 生成されたデータ • 1対1の対応関係を維持 • 逆変換も可能 メリット • 対数尤度を正確に計算可能 • 理論上は1ステップで生成可能 デメリット • 各層が「可逆」である制約が厳しい • モデル設計が難しく、メモリ消費大
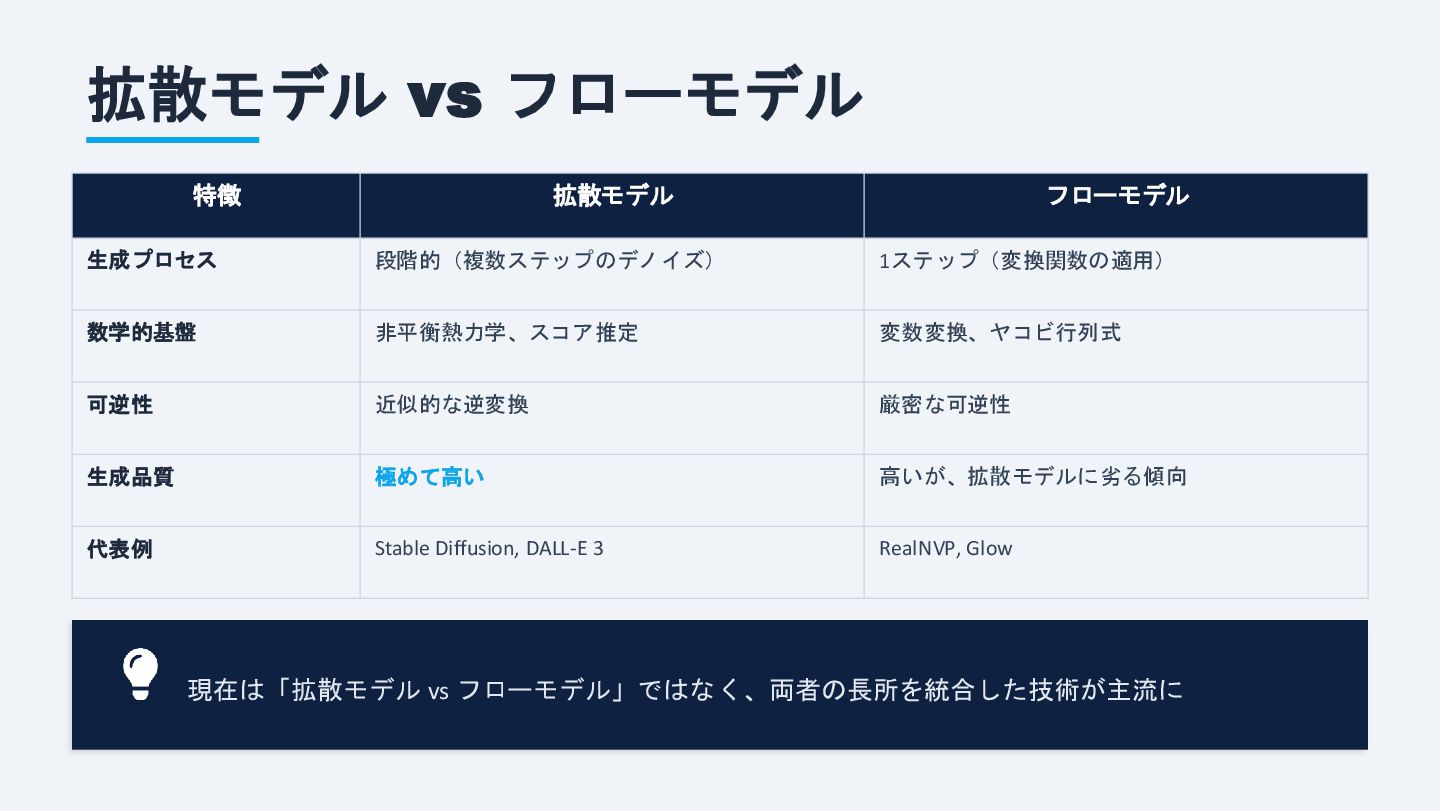
拡散モデル vs フローモデル 特徴 拡散モデル フローモデル 生成プロセス 段階的(複数ステップのデノイズ) 1ステップ(変換関数の適用) 数学的基盤
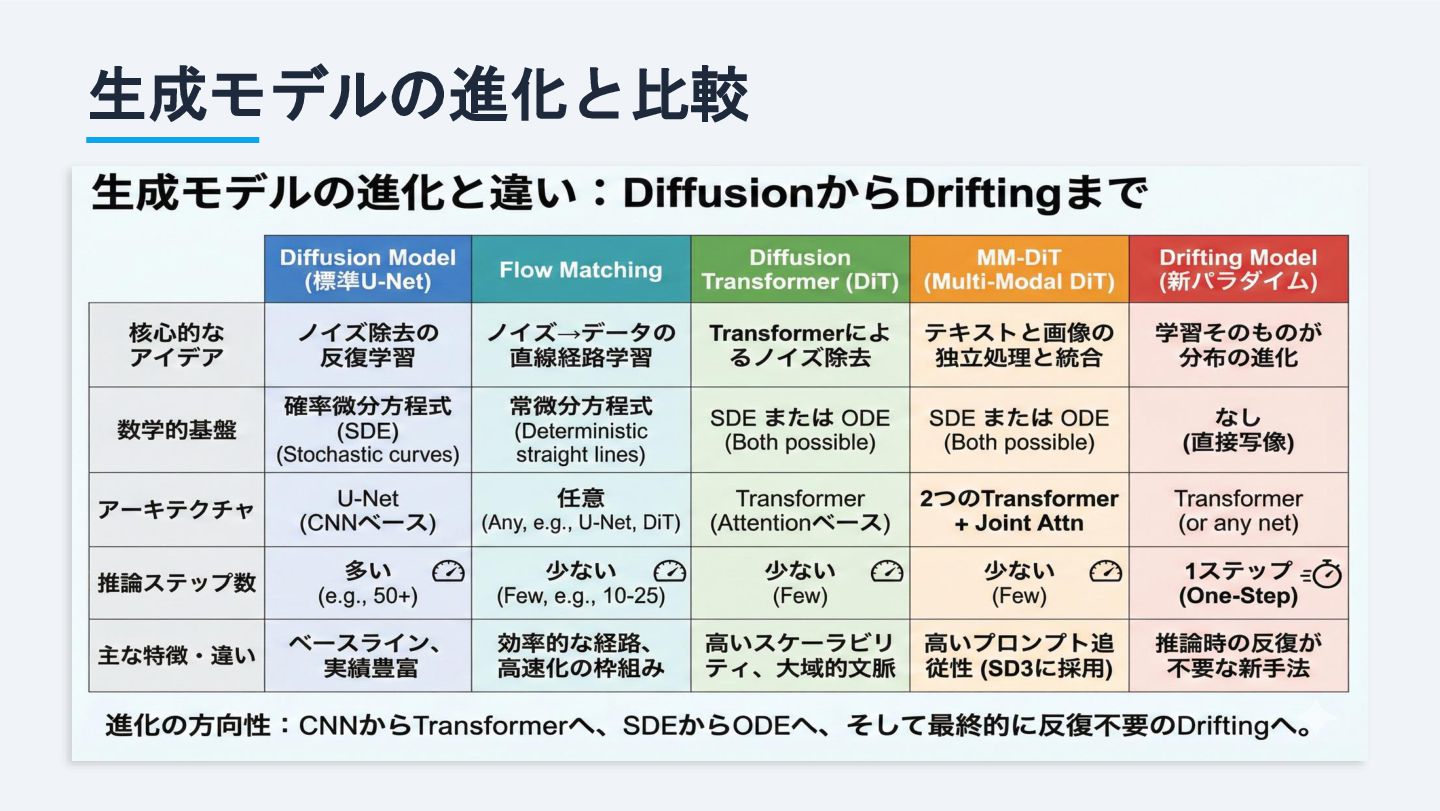
非平衡熱力学、スコア推定 変数変換、ヤコビ行列式 可逆性 近似的な逆変換 厳密な可逆性 生成品質 極めて高い 高いが、拡散モデルに劣る傾向 代表例 Stable Diffusion, DALL-E 3 RealNVP, Glow 現在は「拡散モデル vs フローモデル」ではなく、両者の長所を統合した技術が主流に
フロー・マッチングの核心 ベクトル場の学習 フロー・マッチングは「速度(ベクトル場)」を学 習します。 • 1. 確率経路を p_t と定義 •
2. ベクトル場 v_t がガイドマップ • 3. NNが速度ベクトルを直接予測 Rectified Flow(整流フロー): x_t = (1-t)x₀ + t·x₁ 理想速度 = x₁ - x₀ (定数!) 1〜4 ステップで高品質生成 拡散モデル 曲がった軌道 → 多くのステップ → 誤差が蓄積 フロー・マッチング 直線的な経路 → 少ないステップ → 高精度 損失関数: L = E[ || v_θ(x_t, t) - (x₁ - x₀) ||² ]
None
拡散 vs フロー・マッチング 特徴 拡散モデル フロー・マッチング 軌道の形状 確率的・曲進的 決定論的・直線的 数学的基盤
確率微分方程式 (SDE) 常微分方程式 (ODE) 学習対象 スコア(対数密度の勾配) ベクトル場(移動速度) 生成速度 多くのステップが必要 1〜4ステップで可能 精度 高いが、サンプリング誤差が出やすい 直線的で誤差が蓄積しにくい
None
04 Diffusion Transformer DiT U-NetからTransformerへの革新
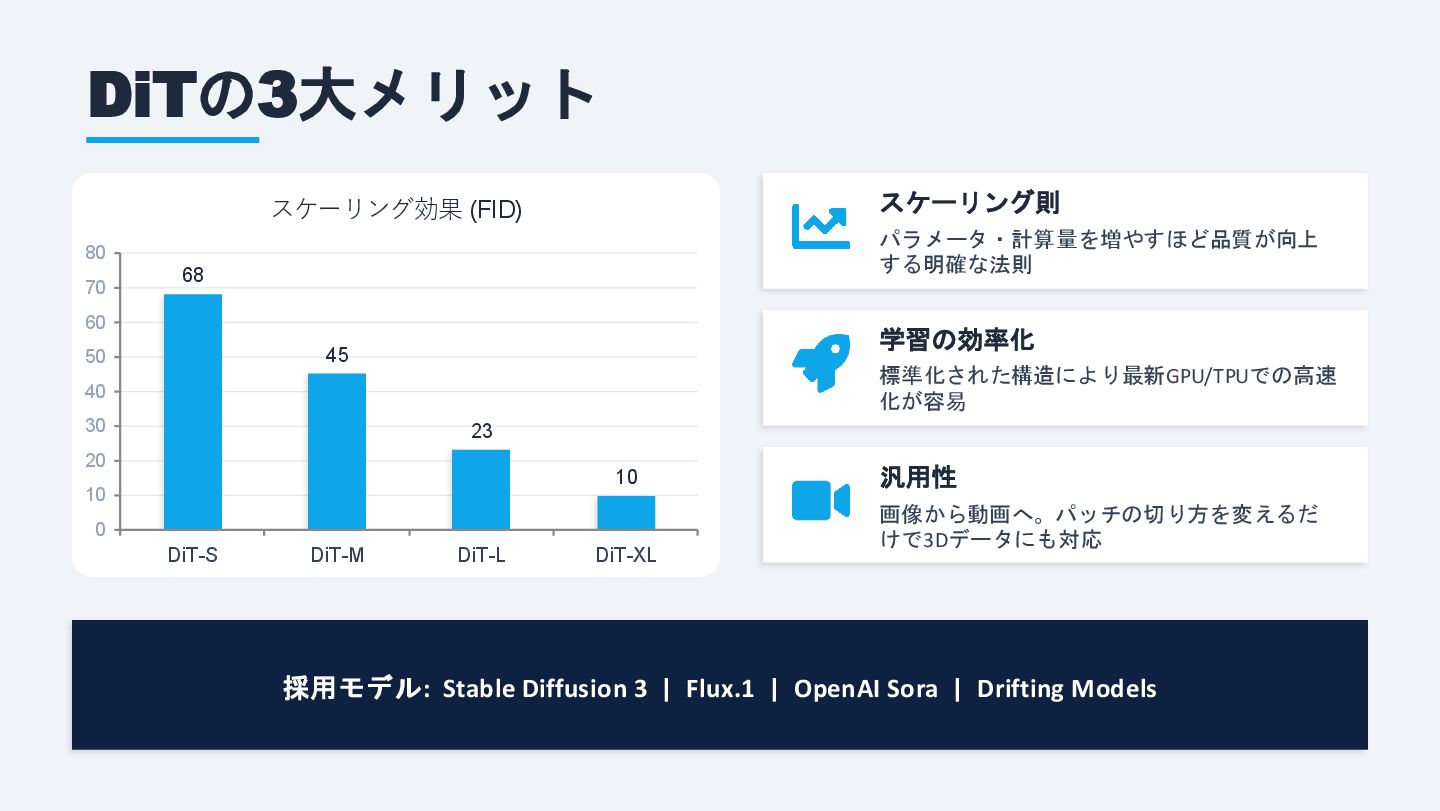
なぜU-NetからTransformerへ? U-Netの限界 • スケーラビリティの限界 → モデルを大きくしても性能向上が不明確 • 長距離依存関係が苦手 → CNNベースのため画像の遠い部分の関係性を捉
えにくい DiTの強み • スケーリング則が明確 → 大きくすればするほど高品質 • Self-Attentionで全体を把握 → 長距離依存関係を自然に学習 DiTのパイプライン 画像 → パッチ化 → Transformerブロック(Self-Attention + AdaLN) → 条件付け(時刻t, テキスト) → 出力
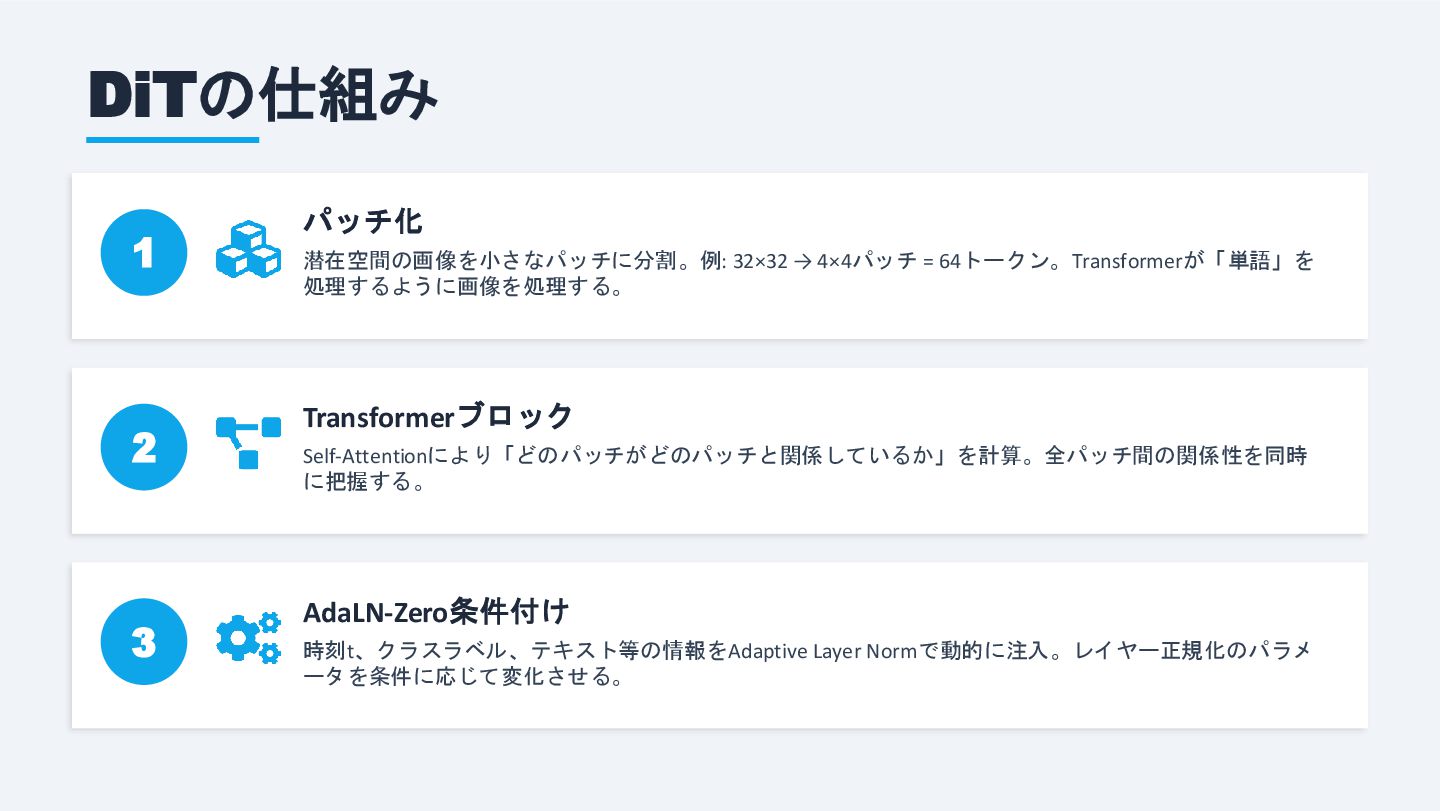
DiTの仕組み 1 パッチ化 潜在空間の画像を小さなパッチに分割。例: 32×32 → 4×4パッチ = 64トークン。Transformerが「単語」を 処理するように画像を処理する。
2 Transformerブロック Self-Attentionにより「どのパッチがどのパッチと関係しているか」を計算。全パッチ間の関係性を同時 に把握する。 3 AdaLN-Zero条件付け 時刻t、クラスラベル、テキスト等の情報をAdaptive Layer Normで動的に注入。レイヤー正規化のパラメ ータを条件に応じて変化させる。
DiTの3大メリット 68 45 23 10 0 10 20 30 40
50 60 70 80 DiT-S DiT-M DiT-L DiT-XL スケーリング効果 (FID) スケーリング則 パラメータ・計算量を増やすほど品質が向上 する明確な法則 学習の効率化 標準化された構造により最新GPU/TPUでの高速 化が容易 汎用性 画像から動画へ。パッチの切り方を変えるだ けで3Dデータにも対応 採用モデル: Stable Diffusion 3 | Flux.1 | OpenAI Sora | Drifting Models
05 MM-DiTとSD3 Multi-Modal Diffusion Transformer テキストと画像の相互理解を深める最新構造
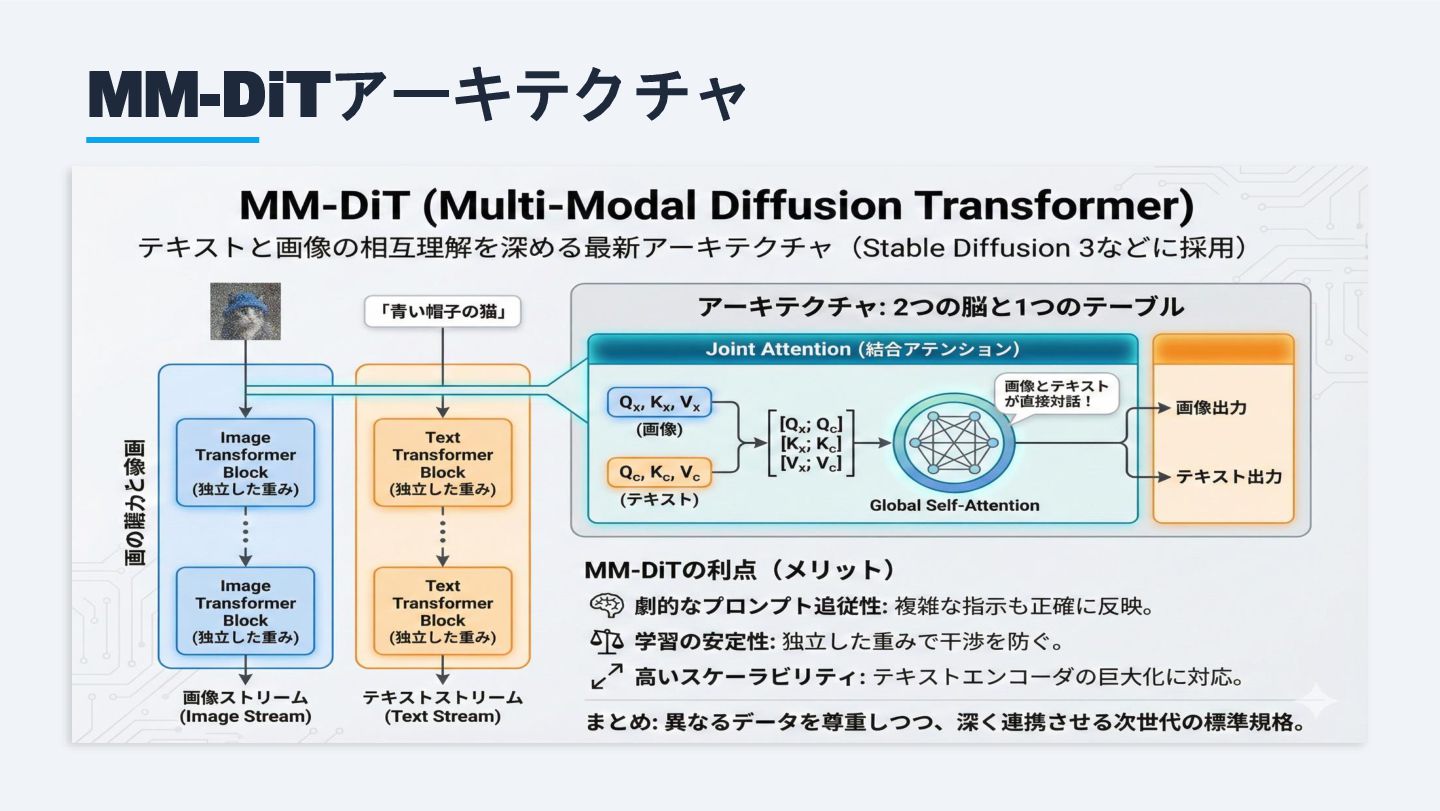
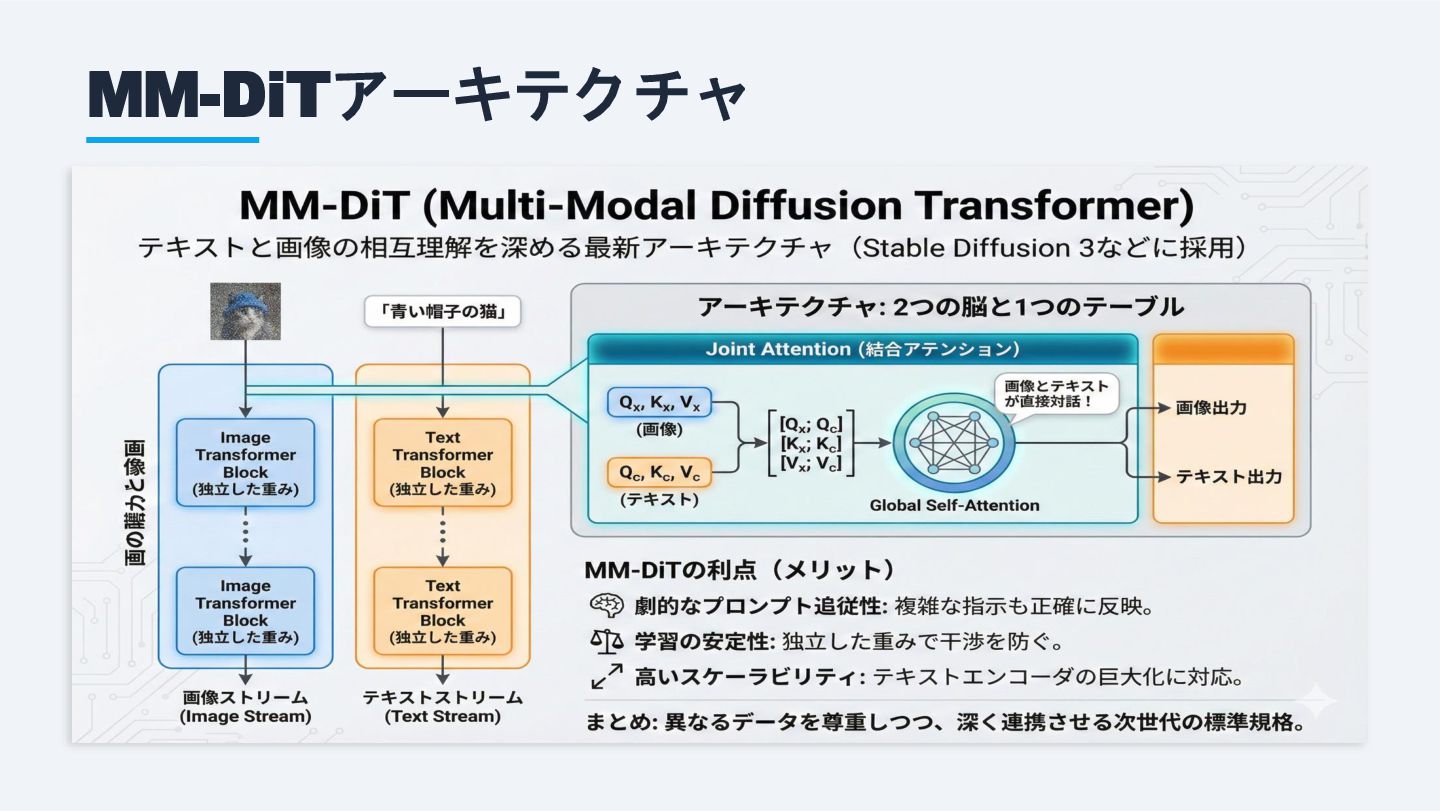
MM-DiTアーキテクチャ
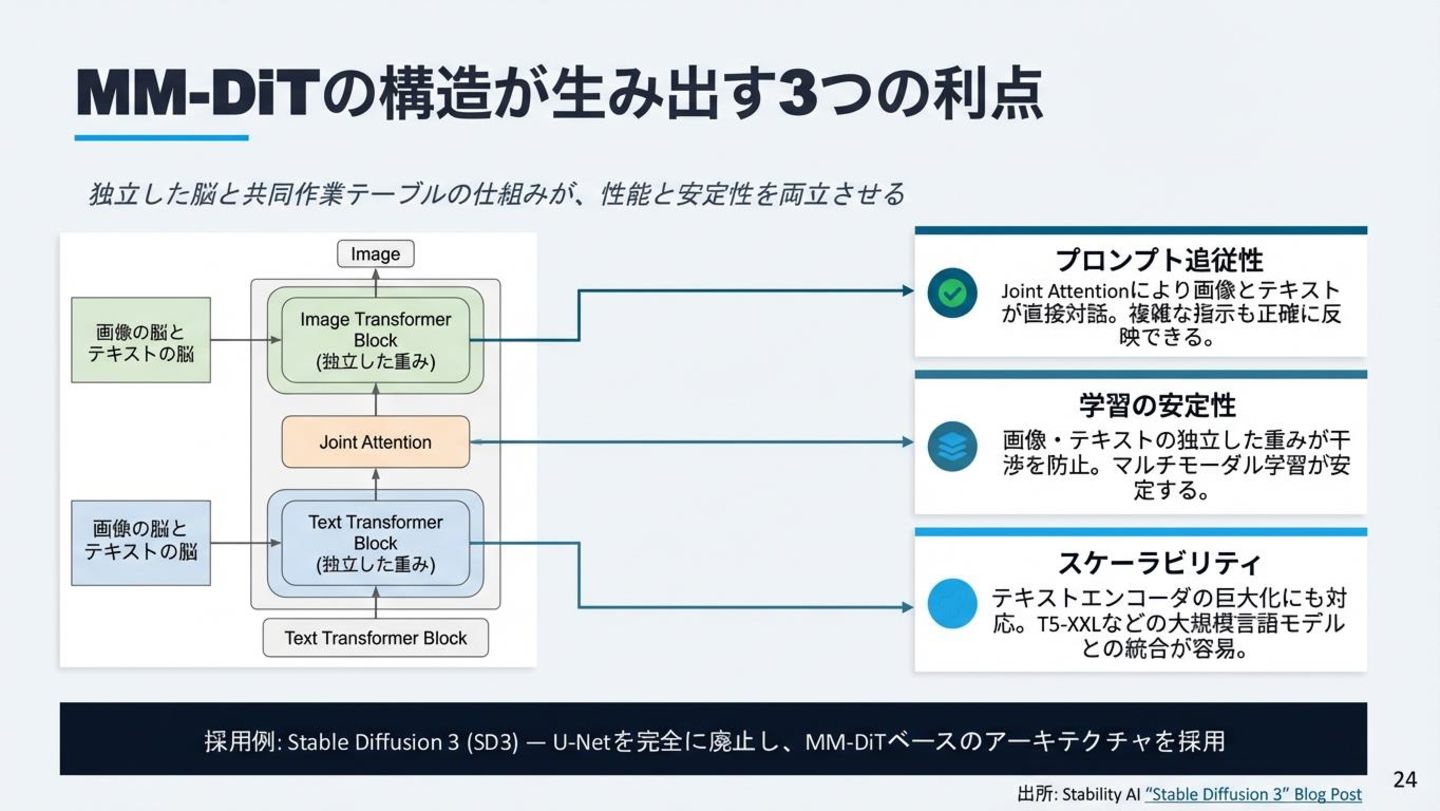
MM-DiTの3大利点 「2つの脳と1つのテーブル」:画像とテキストを独立処理し、Joint Attentionで統合 プロンプト追従性 Joint Attentionにより画像とテキスト が直接対話。複雑な指示も正確に反 映できる。 学習の安定性 画像・テキストの独立した重みが干
渉を防止。マルチモーダル学習が安 定する。 スケーラビリティ テキストエンコーダの巨大化にも対 応。T5-XXLなどの大規模言語モデル との統合が容易。 採用例: Stable Diffusion 3 (SD3) — U-Netを完全に廃止し、MM-DiTベースのアーキテクチャを採用
None
06 Driftingモデル Generative Modeling via Drifting 1ステップ生成の新パラダイム — Kaiming He
(MIT)
None
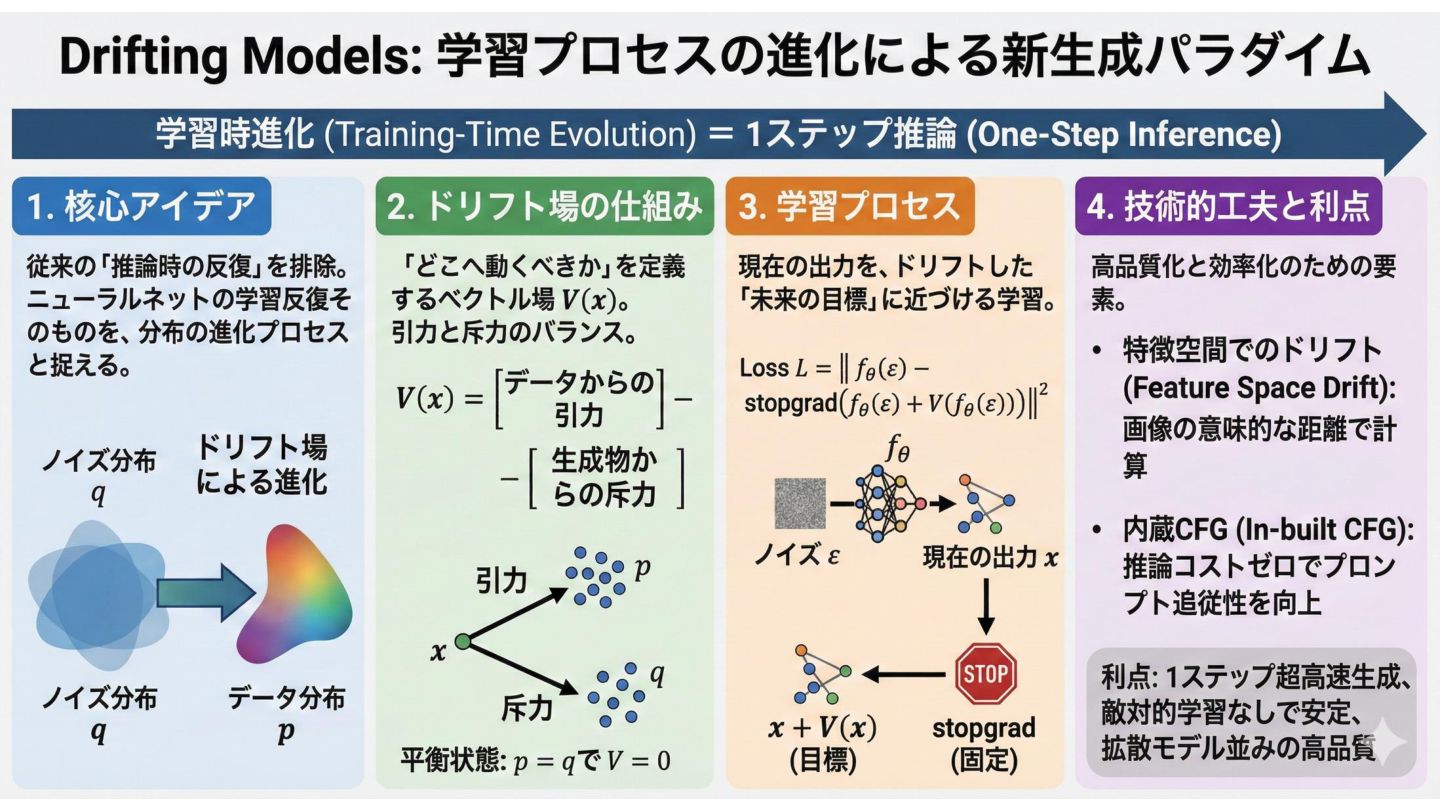
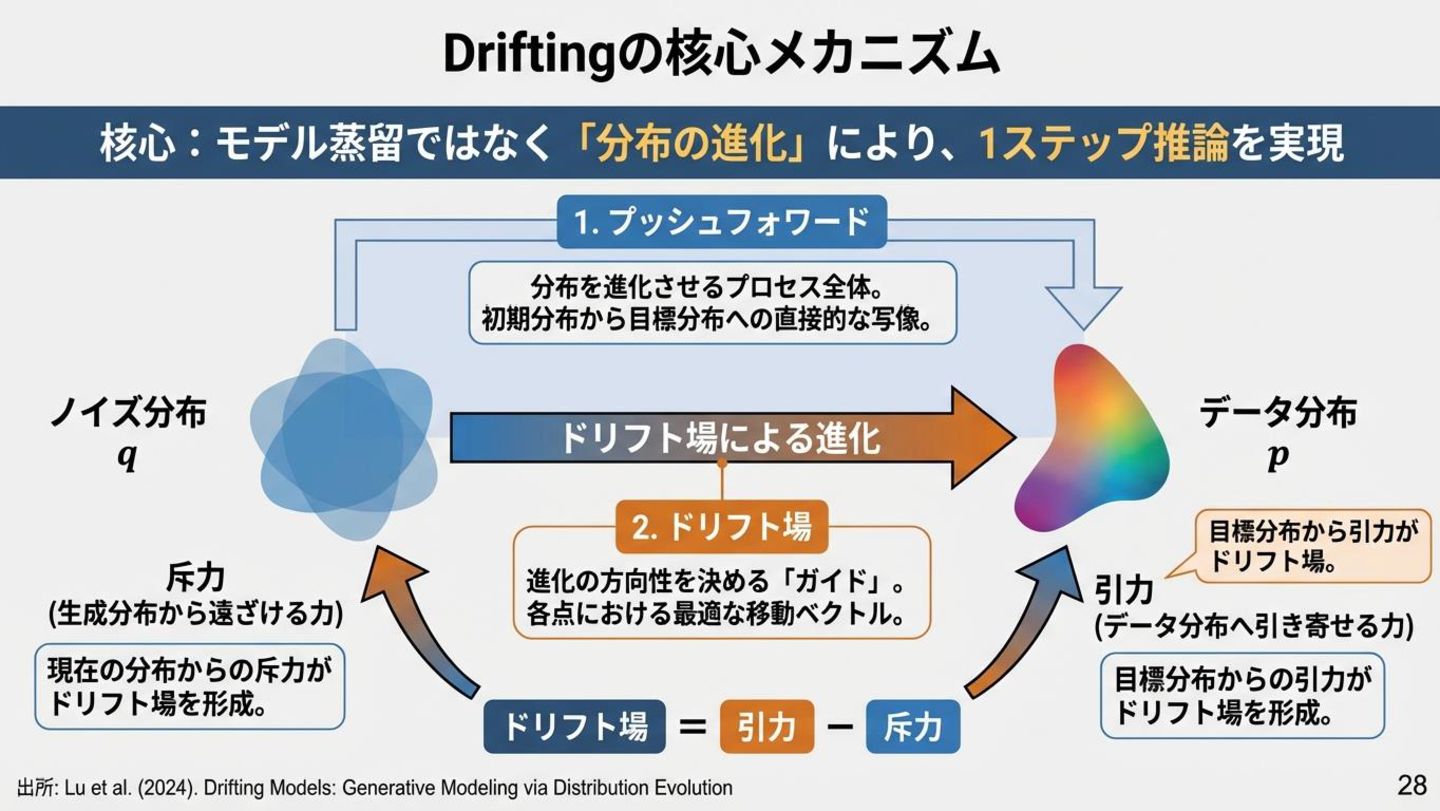
Driftingの核心メカニズム 核心:「推論を高速化するためにモデルを蒸留する」のではなく、「最初から1ステップで終わ るように分布を進化させる」 プッシュフォワード NNの出力分布 q_θ を「漂流」さ せてデータ分布に適合。学習のイ テレーション =
分布の進化。 ドリフト場 生成分布をデータ分布に近づける 「ガイド」ベクトル場 V。p = q で V = 0(平衡状態)になる設計 。 引力と斥力 データからの「引力」+ 生成分布 からの「斥力」でバランスを維持 。モード崩壊を防止。
None
None
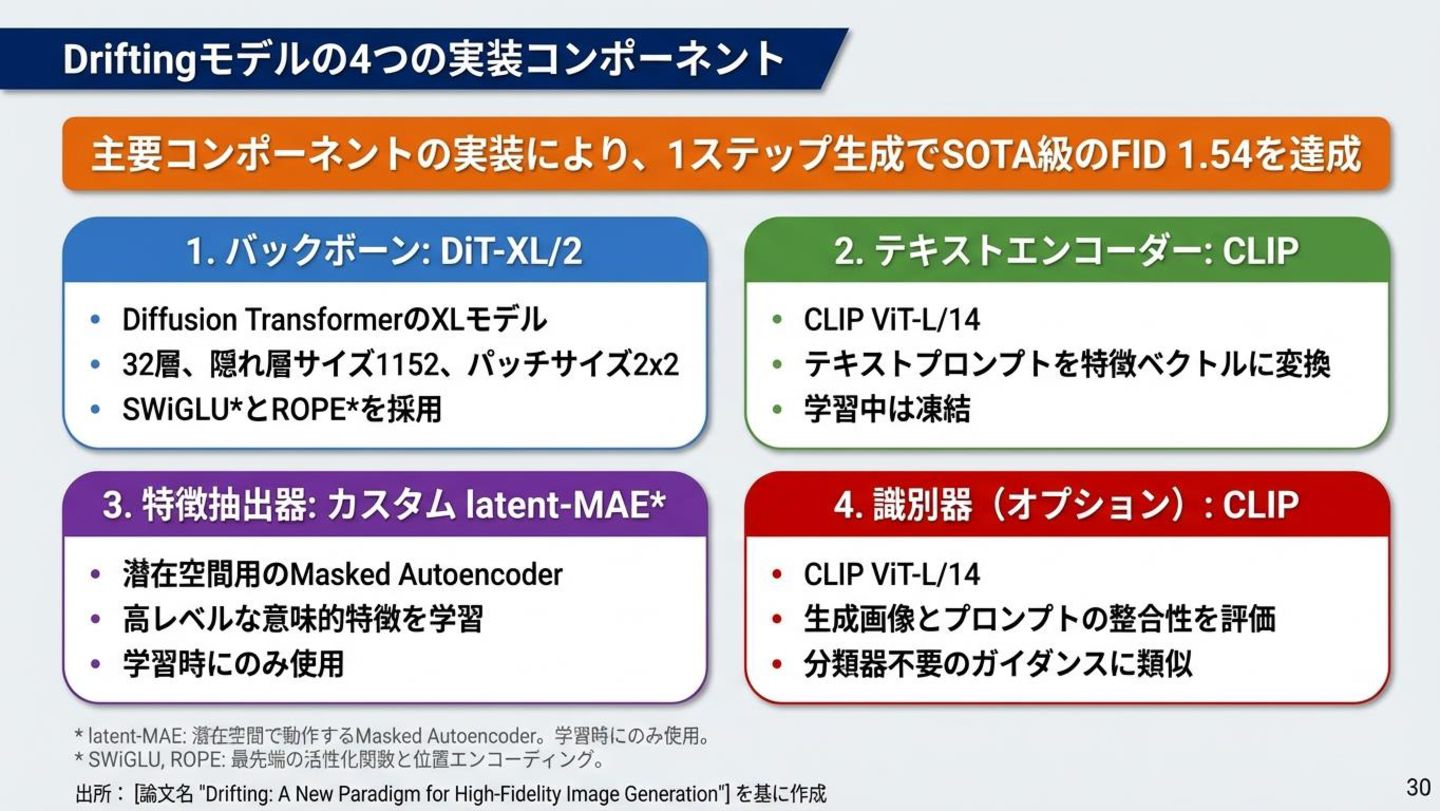
Driftingの実装 Tokenizer SD互換のVAEを使用 潜在空間(64×64)で生成 アーキテクチャ DiT類似構造 SwiGLU / ROPE /
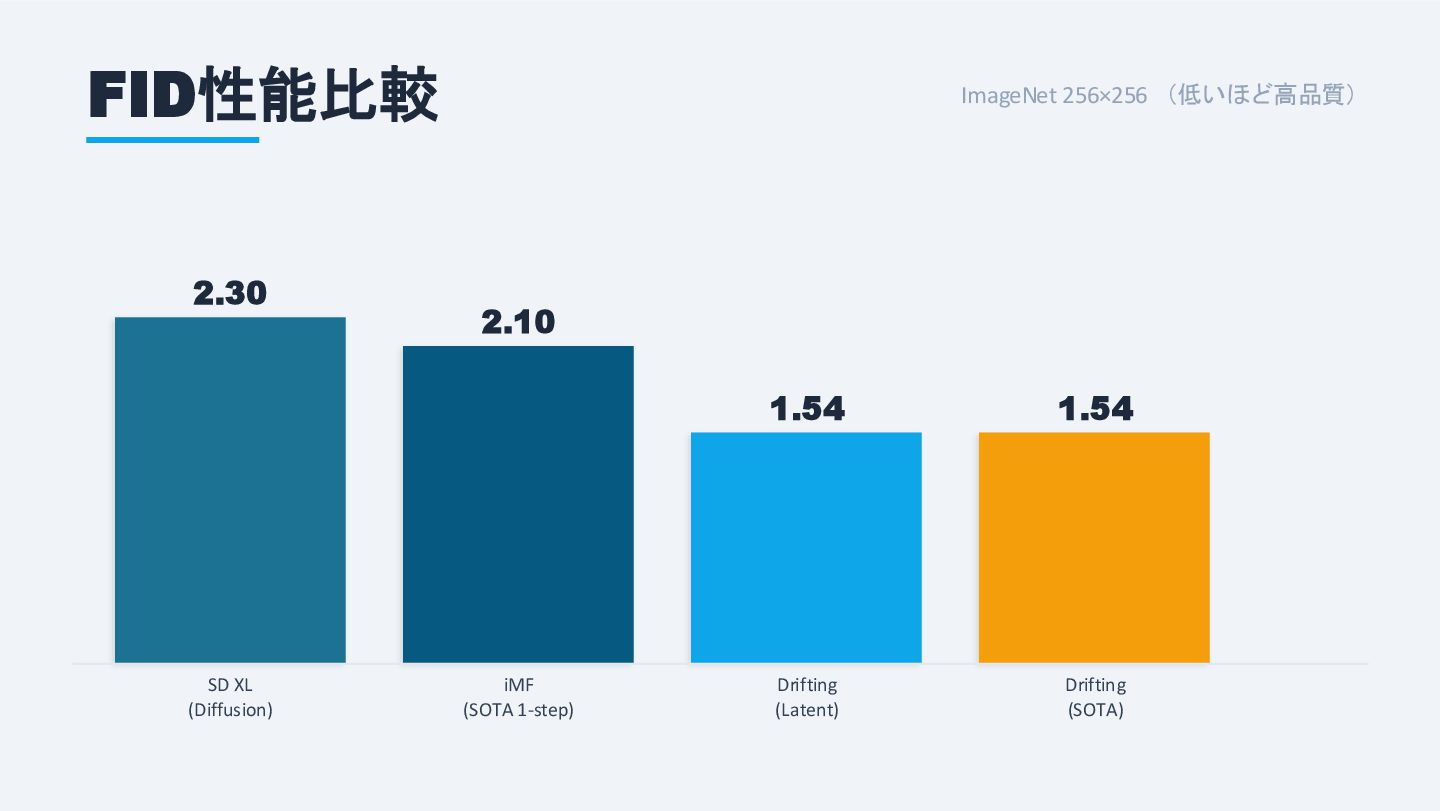
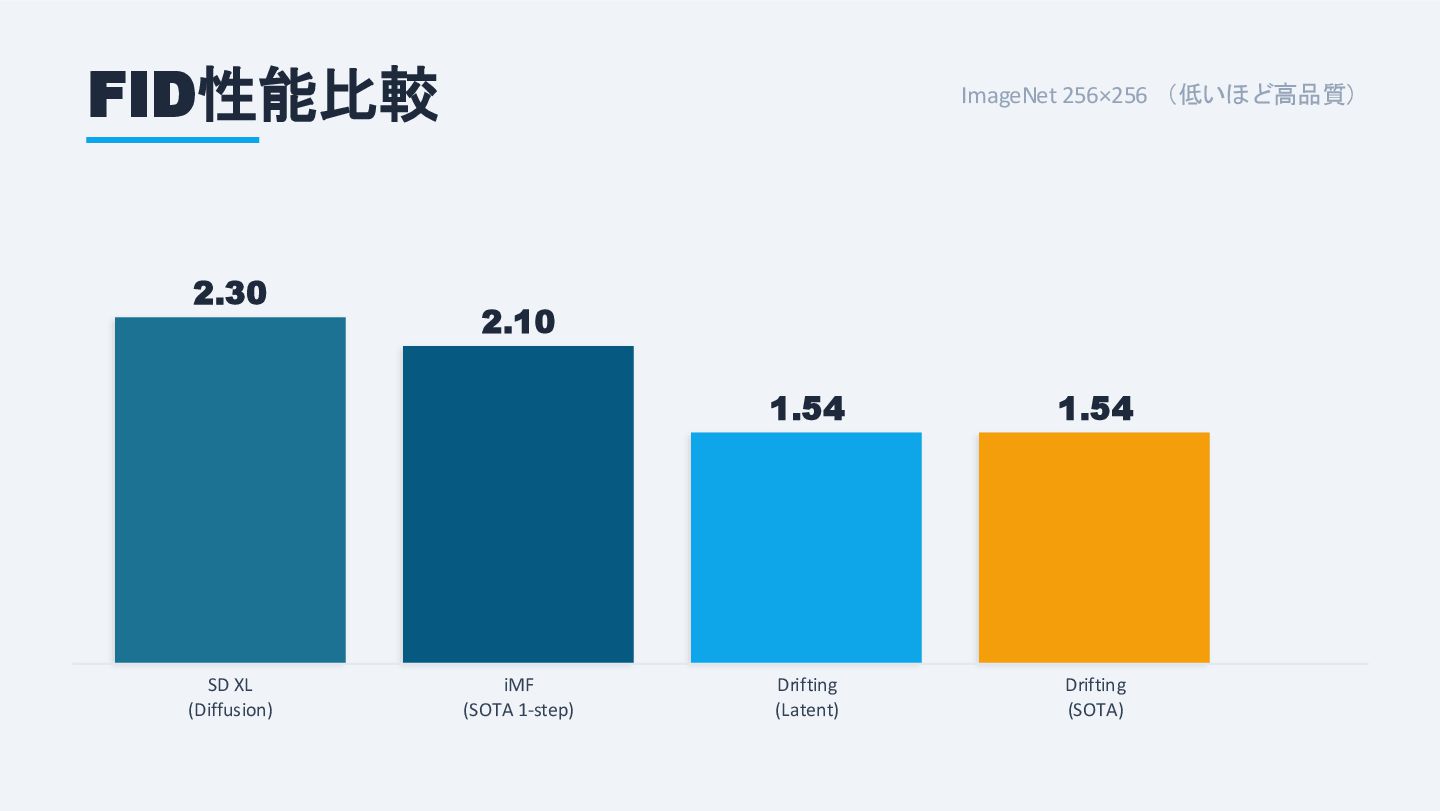
RMSNorm QK-Norm採用 特徴抽出器 カスタムlatent-MAE (ResNetベース) 学習時のみ使用 CFG統合 学習時にCFGを組み込み 推論時も1ステップ維持 スケールをランダムサンプリング ImageNet 256×256: 1ステップ生成で FID 1.54 を達成
None
生成モデルの進化と比較
FID性能比較 ImageNet 256×256 (低いほど高品質) 2.30 SD XL (Diffusion) 2.10 iMF
(SOTA 1-step) 1.54 Drifting (Latent) 1.54 Drifting (SOTA)
07 まとめと展望 Summary & Future Outlook 生成AIの未来を展望する
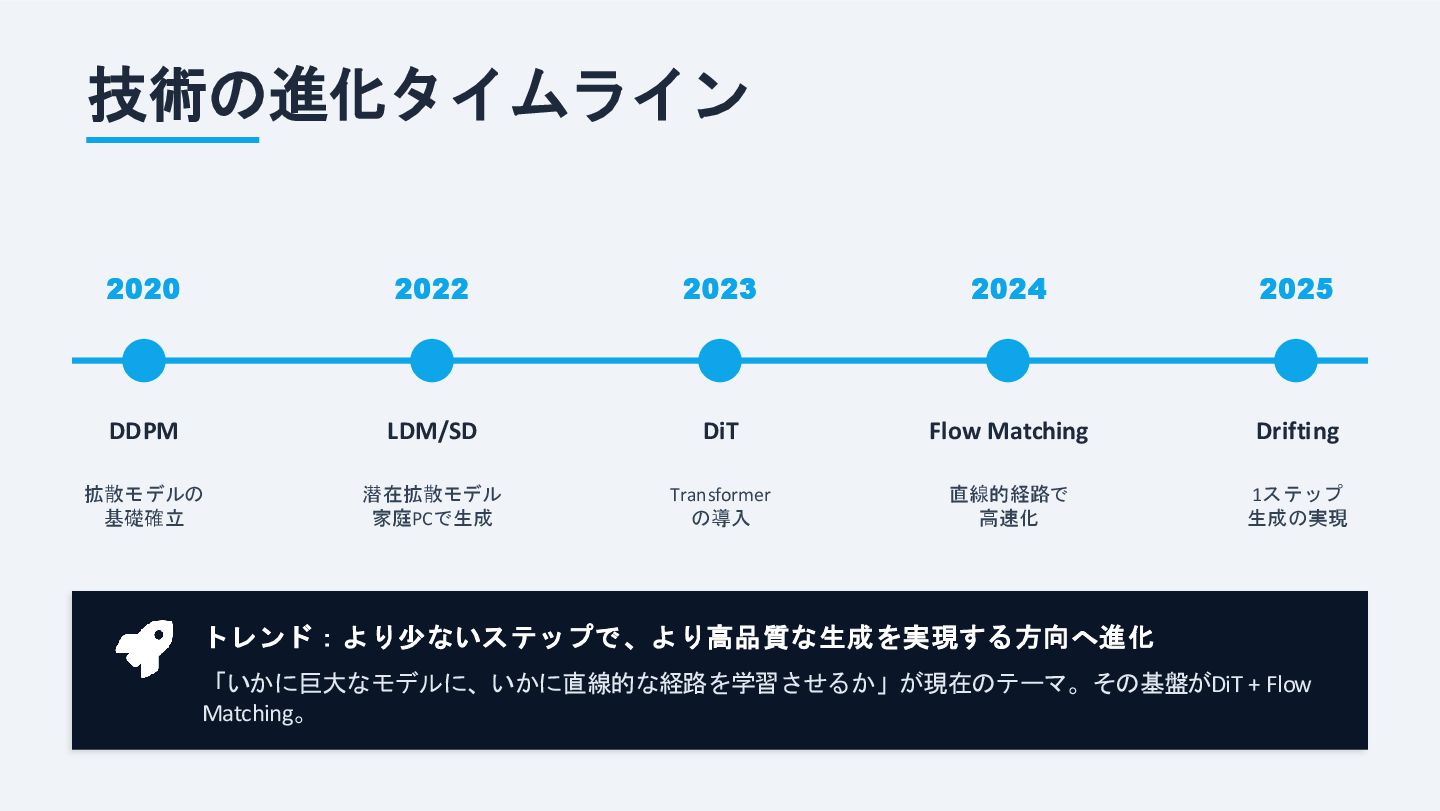
技術の進化タイムライン 2020 DDPM 拡散モデルの 基礎確立 2022 LDM/SD 潜在拡散モデル 家庭PCで生成 2023
DiT Transformer の導入 2024 Flow Matching 直線的経路で 高速化 2025 Drifting 1ステップ 生成の実現 トレンド:より少ないステップで、より高品質な生成を実現する方向へ進化 「いかに巨大なモデルに、いかに直線的な経路を学習させるか」が現在のテーマ。その基盤がDiT + Flow Matching。
キーポイント 拡散モデルは「ノイズ追加→除去」のシンプルな原理で高品質な生成を実現 潜在拡散モデル(LDM)が計算量を大幅削減し、一般利用を可能にした フロー・マッチングの「直線化」により、生成ステップ数が劇的に減少 DiT(Diffusion Transformer)がスケーリング則をもたらし、品質向上の道を開いた MM-DiTがテキストと画像の深い統合を実現し、プロンプト追従性が向上 Driftingモデルが1ステップ生成で最高水準のFID 1.54を達成 —
新パラダイム
ありがとうございました 生成AIの進化は加速し続けています。 拡散モデル → フロー・マッチング → DiT → Drifting 次の突破口はどこから?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}