Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Hybrid Autoregressive Transducer [輪講発表資料]
Search
shibutani
June 22, 2022
Research
410
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Hybrid Autoregressive Transducer [輪講発表資料]
Hybrid Autoregressive Transducer に関する輪講発表資料です。
shibutani
June 22, 2022
More Decks by shibutani
See All by shibutani
越境するAIのために、境界を取り払う - AI 時代の開発体験向上に向けたリポジトリ統合の取り組み -
shibukazu
1
640
メッセージキュー型の非同期処理から Temporal 移行へ
shibukazu
4
5.7k
はじめてのOSS開発からみえたGo言語の強み
shibukazu
4
1.5k
全自動コードレビューの夢 〜実際に活用されるAIコードレビューの実現に向けて〜
shibukazu
11
5.6k
Perceiver: General Perception with Iterative [輪講発表資料]
shibukazu
0
140
Other Decks in Research
See All in Research
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
280
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
全国町字単位空き家率推定データver1.0データ仕様
microbaseinc
0
140
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
230
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
290
Cross-Media Human-Information Interaction
signer
PRO
0
130
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
180
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
660
IA for theory
gpeyre
0
270
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.5k
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Building the Perfect Custom Keyboard
takai
2
820
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
550
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
340
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Believing is Seeing
oripsolob
1
170
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Transcript
Hybrid Autoregressive Transducer (HAT) [Variani, Rybach+ 2020] 京都大学 音声メディア研究室 M1
渋谷和樹 1
E2E音声認識 E2Eモデルはシンプルで学習しやすい パラレルデータの収集が難しいため、外部言語モデルを組み合わせたい 外部言語モデルの活用 ShallowFusion y = ∗ argmax
logP(y∣x) + logP (y) y ( LM ) E2Eモデル自体にも言語モデルが含まれてしまう(暗黙の言語モデル) 暗黙の言語モデルによる評価スコアを取り除いて推論を行いたい ⇒Transducerアーキテクチャの利用 Introduction 2
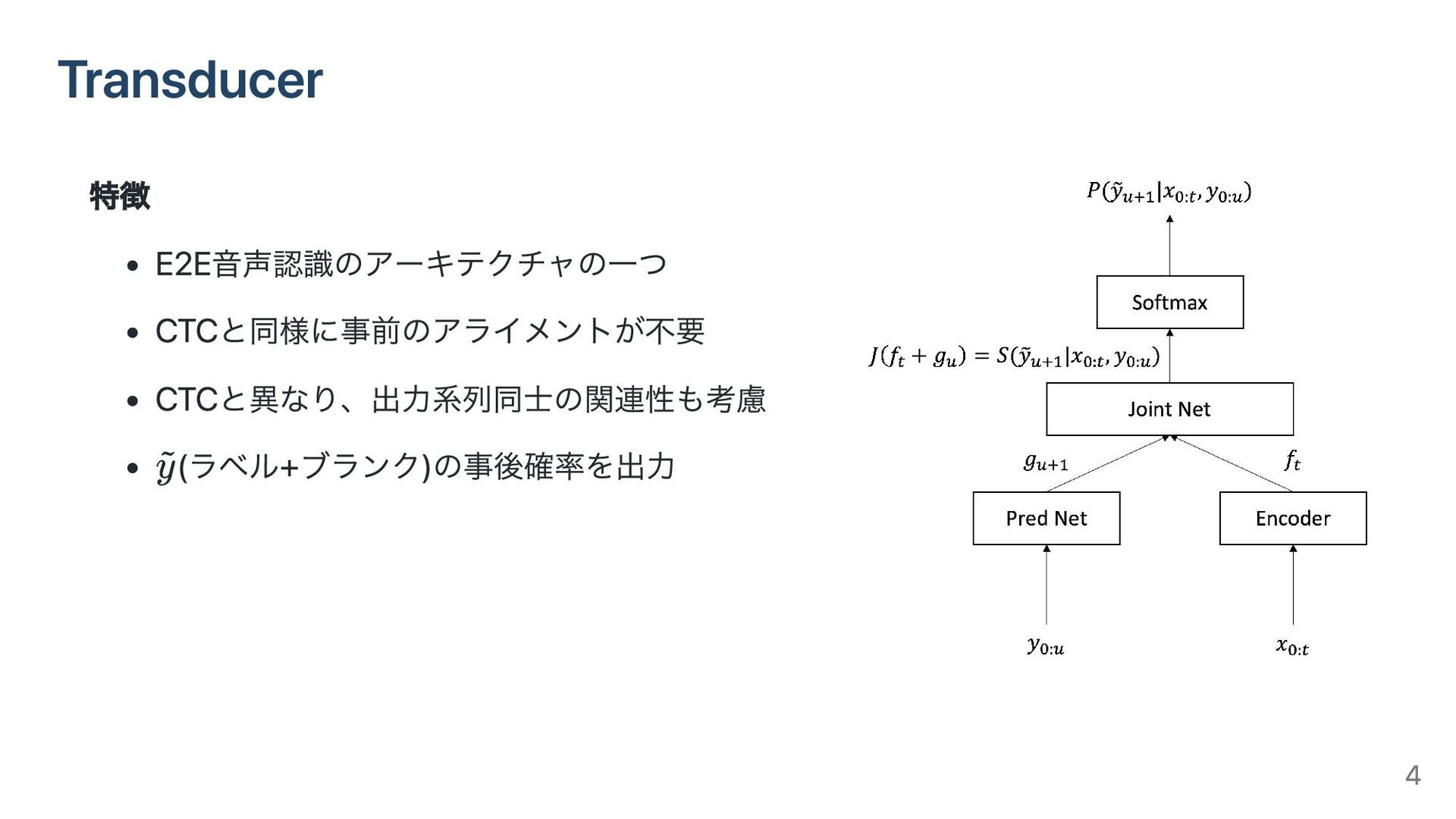
Transducer 3
Transducer 特徴 E2E音声認識のアーキテクチャの一つ CTCと同様に事前のアライメントが不要 CTCと異なり、出力系列同士の関連性も考慮 (ラベル+ブランク)の事後確率を出力 y ~ 4
Transducer 内部言語モデル Transducerではエンコーダーに依存しない出力 ラベルの事後確率(言語モデル確率) を計算できる から内部言語モデルスコアを計算する P(y∣y ) 0:u
logP (Y ) = ILM logP(y ∣y ) ∑ u=0 U−1 u+1 0:u 5
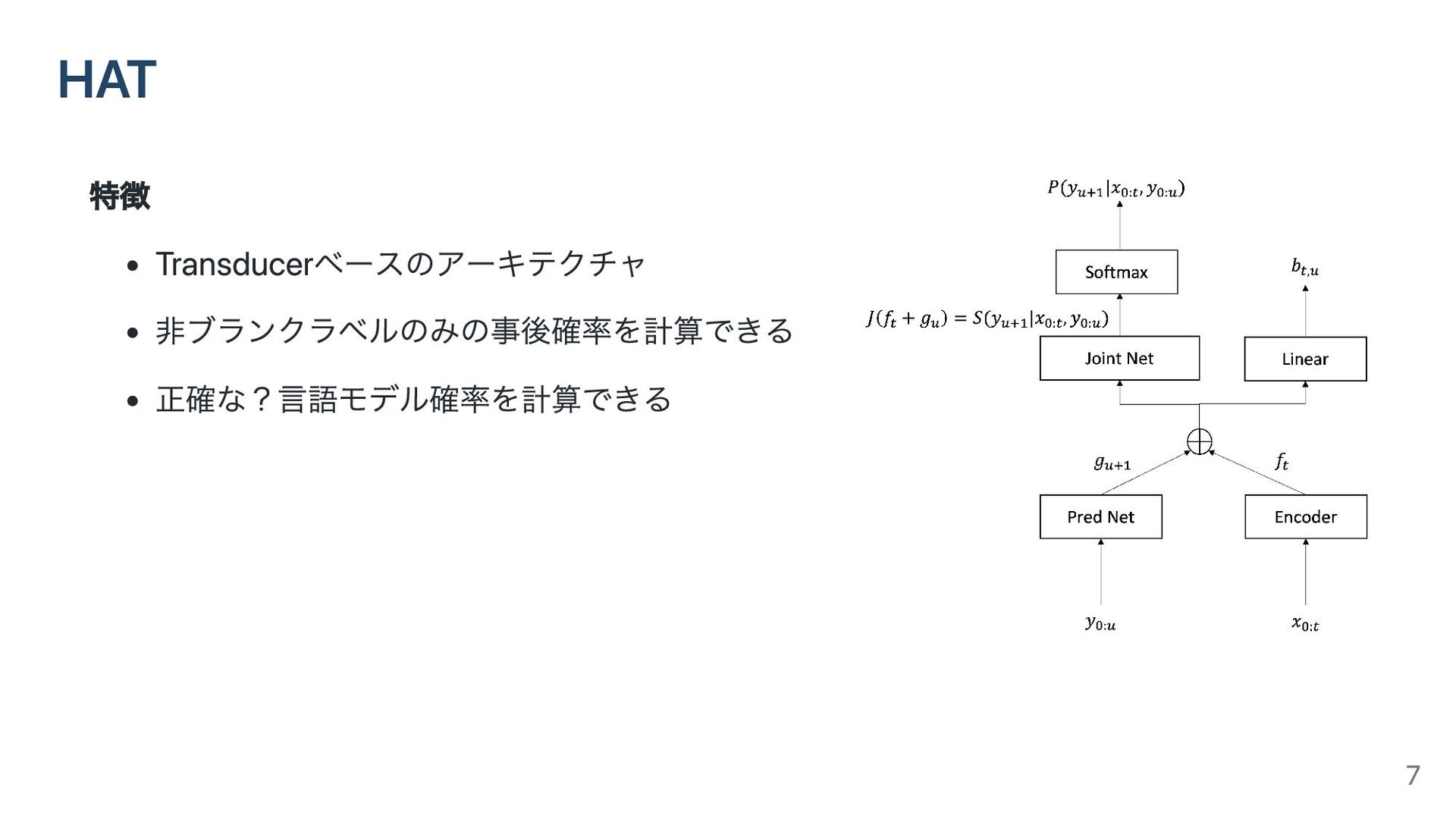
HAT 6
HAT 特徴 Transducerベースのアーキテクチャ 非ブランクラベルのみの事後確率を計算できる 正確な?言語モデル確率を計算できる 7
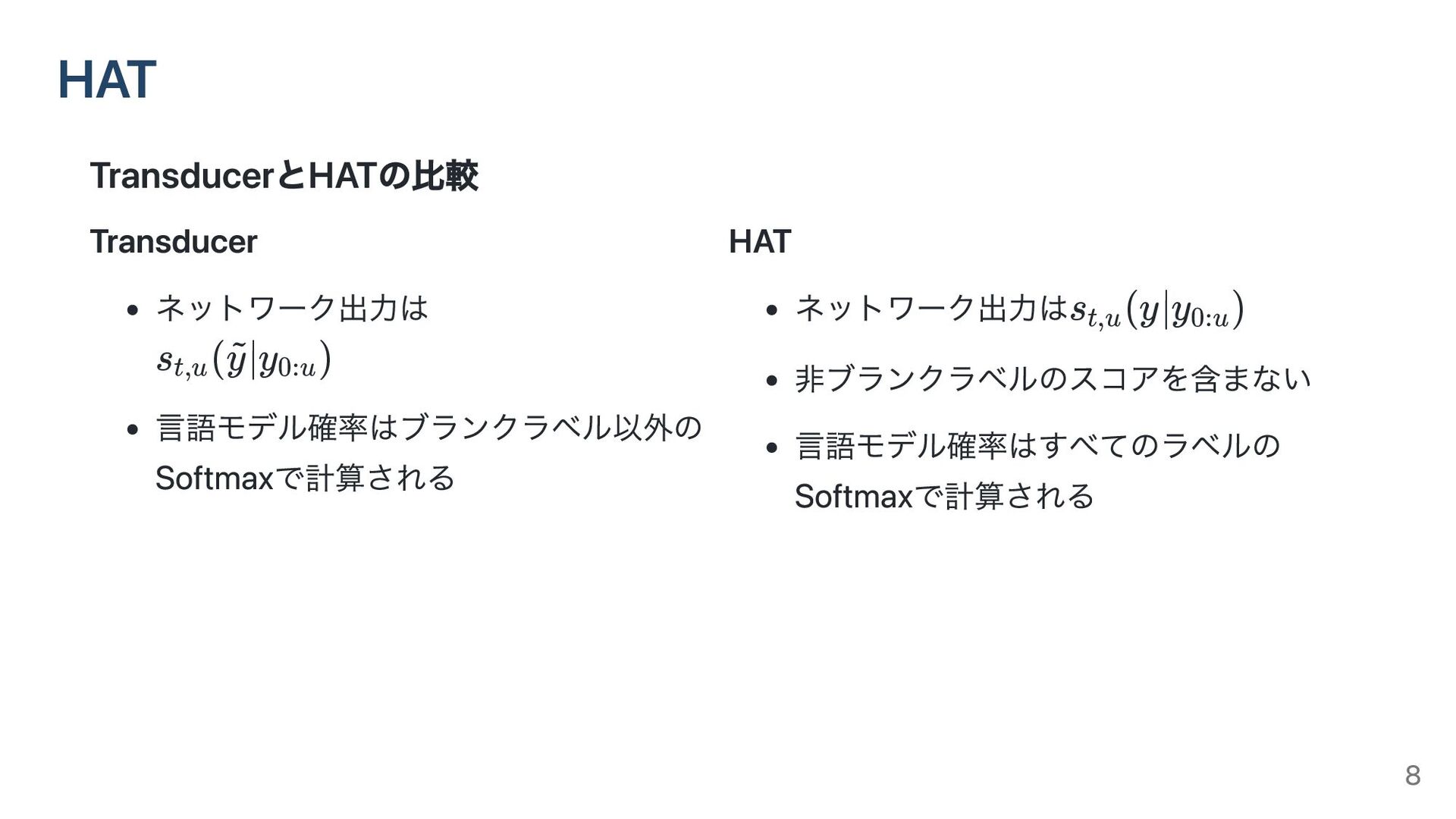
TransducerとHATの比較 HAT Transducer ネットワーク出力は 言語モデル確率はブランクラベル以外の Softmaxで計算される s (
∣y ) t,u y ~ 0:u HAT ネットワーク出力は 非ブランクラベルのスコアを含まない 言語モデル確率はすべてのラベルの Softmaxで計算される s (y∣y ) t,u 0:u 8
結果 9
実験設定 データセット: Google VoiceSearch Traffic 評価指標: WER アーキテクチャ: Encoder: 5layer,
2048cells/layerのLSTM Pred Net: 2layer, 256cells/layerのLSTM Joint Net: 1layerの線形層 入力: 対数メルスペクトログラム 結果 10
学習 強制アライメントを行い、教師ラベル(文章)の音素列を得る 各モデルは42種類の音素の事後確率を予測 各モデル単体で学習を行う(学習時は外部言語モデルを利用しない) 推論 各モデルを音響モデルとして使用 WFSTとして発音辞書・外部言語モデルを組み合わせてデコーディング 結果 11
各手法のデコード方法 Cross-Entropy CTC, RNN-T HAT 結果 = y ~∗
argmax λ log P(x ∣ ) + y ~ 1 (∏ t=1 T t y ~ t ) logP (B( )) LM y ~ = y ~∗ argmax λ logP ( ∣x) + y ~ 1 ′ y ~ logP (B( )) + LM y ~ λ v( ) 2 y ~ = y ~∗ argmax λ logP( ∣x) + y ~ 1 y ~ logP (B( )) − LM y ~ λ logP (B( )) 2 ILM y ~ 12
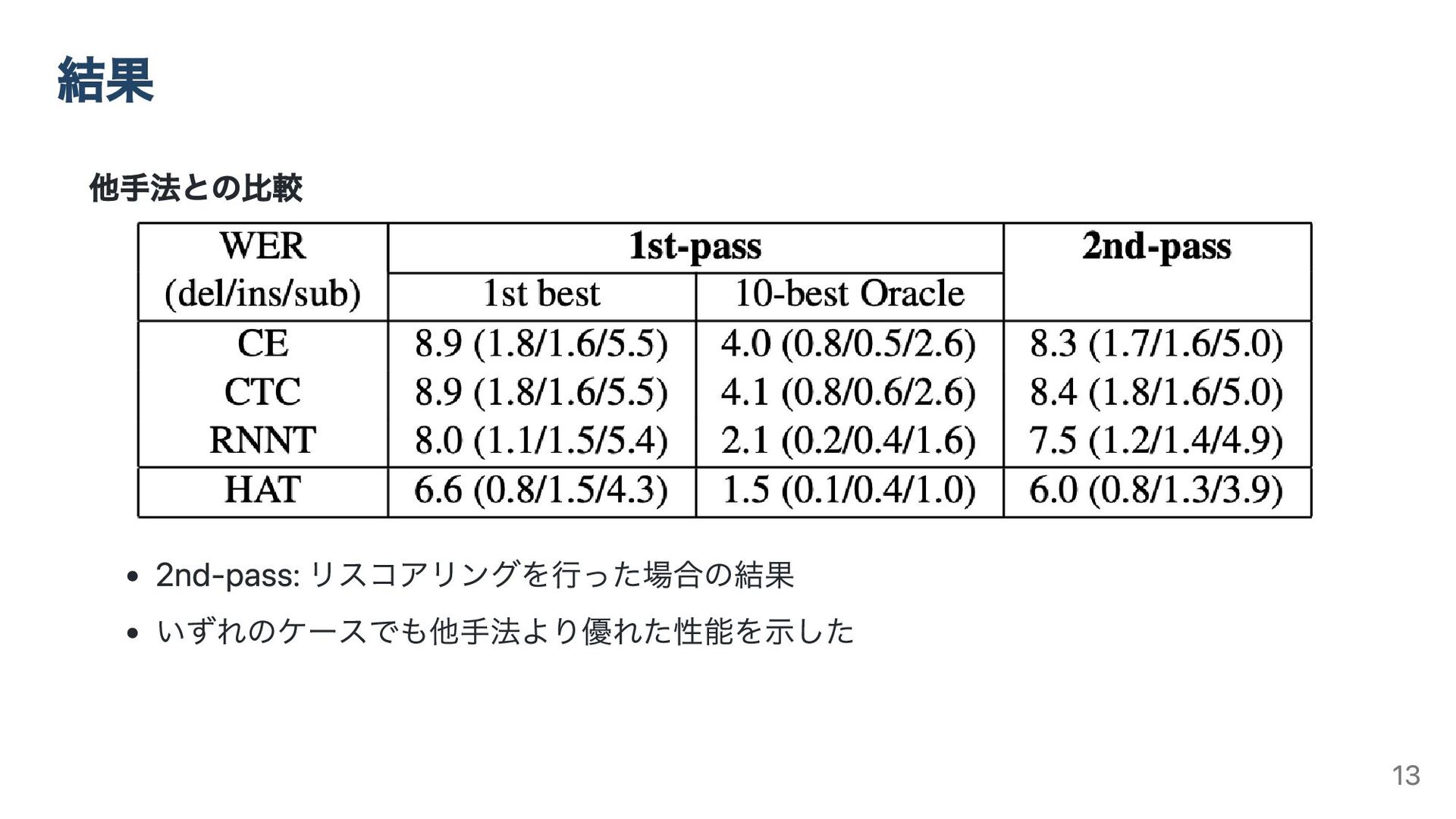
他手法との比較 2nd-pass: リスコアリングを行った場合の結果 いずれのケースでも他手法より優れた性能を示した 結果 13
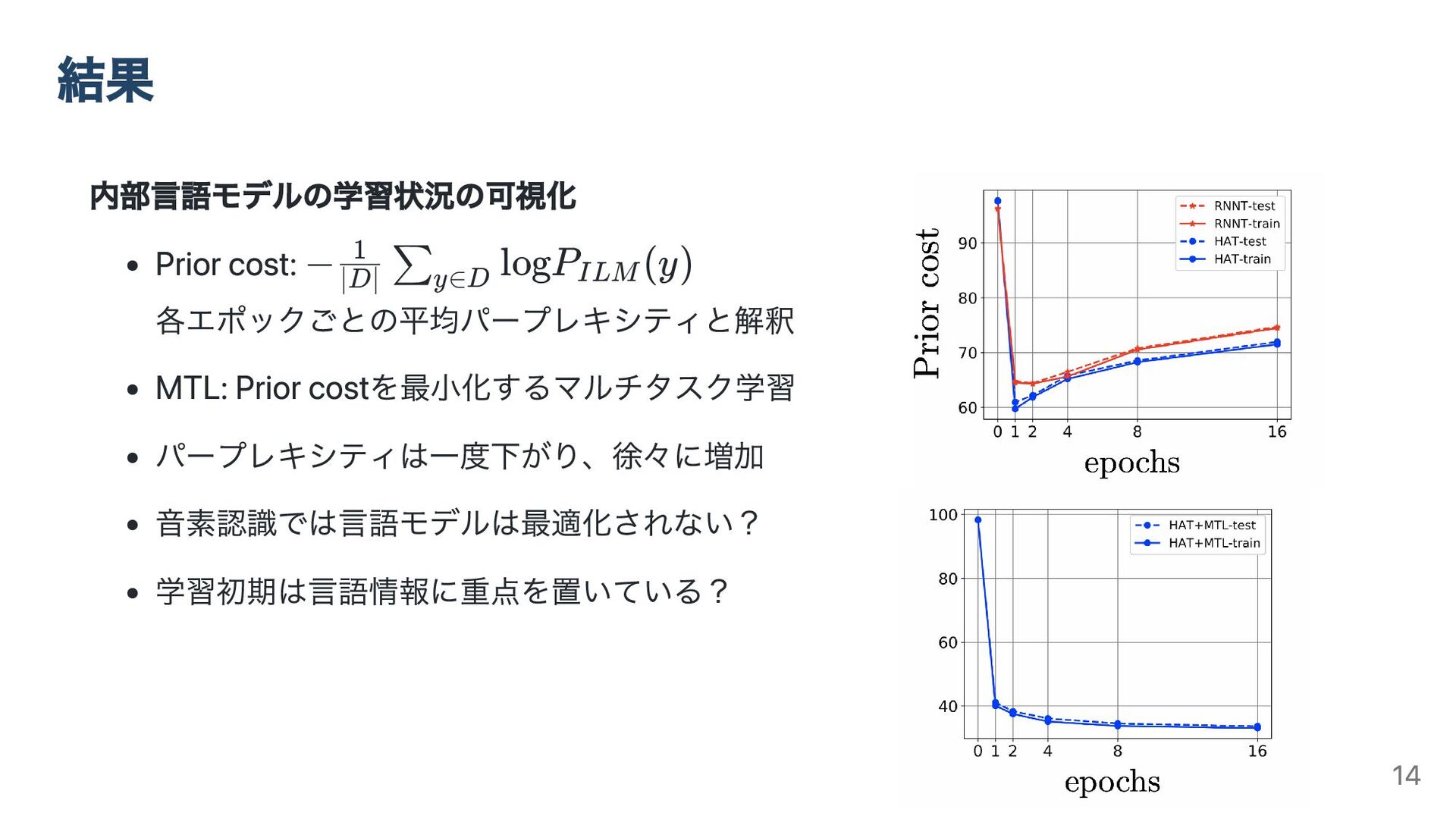
結果 内部言語モデルの学習状況の可視化 Prior cost: 各エポックごとの平均パープレキシティと解釈 MTL: Prior costを最小化するマルチタスク学習 パープレキシティは一度下がり、徐々に増加 音素認識では言語モデルは最適化されない?
学習初期は言語情報に重点を置いている? − logP (y) ∣D∣ 1 ∑ y∈D ILM 14
結果 内部言語モデルの寄与率とWER HAT 付近で最も良い性能 ただのShallowFusionではなく、内部言語 モデルの影響を取り除くことが重要 HAT+MTL Prior costを最小化しているが性能はあまり 向上していない
よい内部言語モデルを構築することは重要 ではないということ? λ = 2 1 15
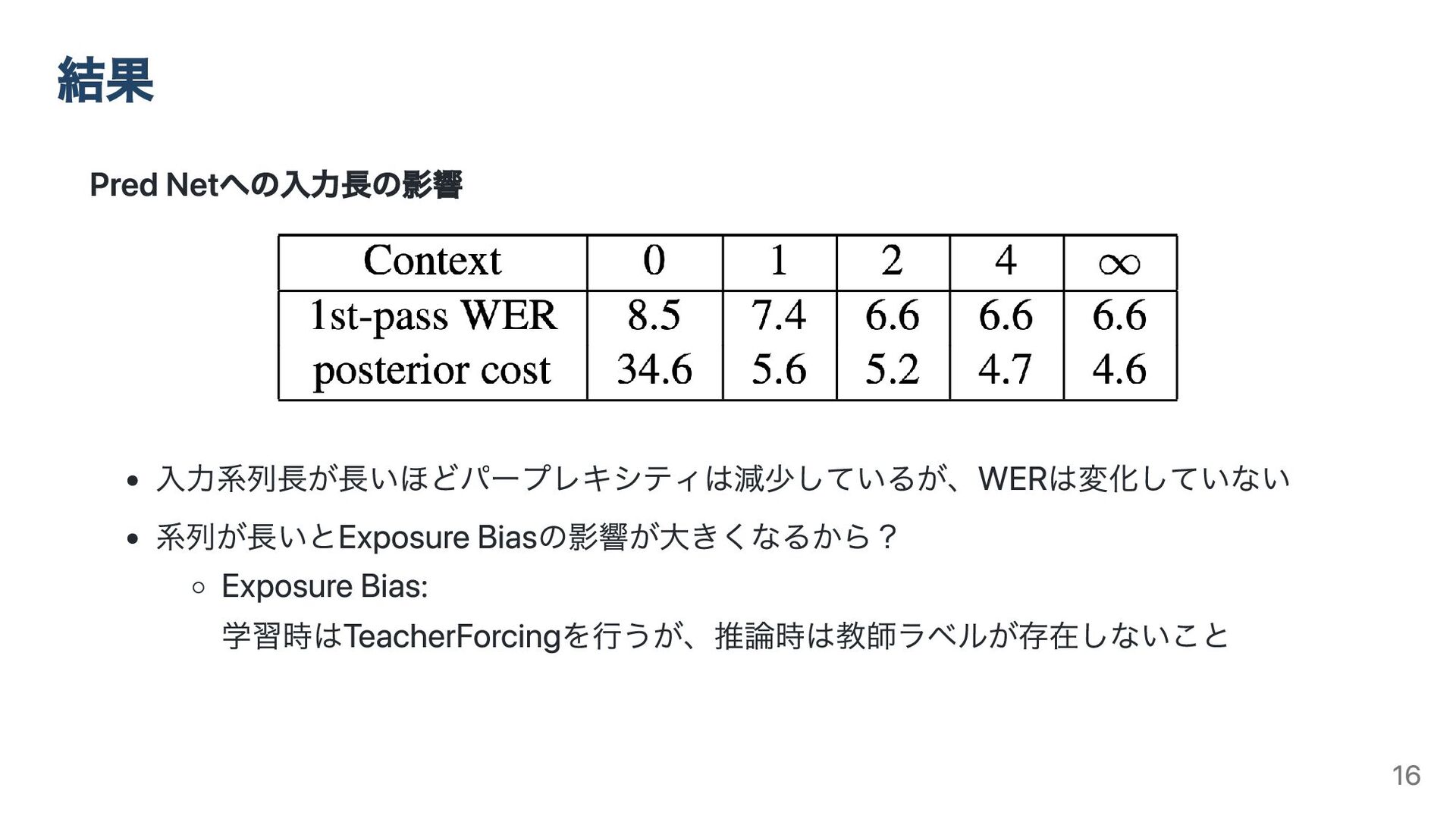
Pred Netへの入力長の影響 入力系列長が長いほどパープレキシティは減少しているが、WERは変化していない 系列が長いとExposure Biasの影響が大きくなるから? Exposure Bias: 学習時はTeacherForcingを行うが、推論時は教師ラベルが存在しないこと 結果 16
まとめ 17
E2Eモデルを音響モデルとして利用するためのアプローチであるHATを提案 内部言語モデルのパープレキシティを評価できるようになった →外部言語モデルの必要性の判断基準となる まとめ 18
![Hybrid Autoregressive Transducer (HAT) [Variani, Rybach+ 2020] 京都大学 音声メディア研究室 M1](https://files.speakerdeck.com/presentations/ad2ac754eb5548a68b16e3b6c306ec2b/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}