Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Perceiver: General Perception with Iterative [輪...
Search
shibutani
June 22, 2022
Research
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Perceiver: General Perception with Iterative [輪講発表資料]
Perceiver: General Perception with Iterativeに関する輪講発表資料
shibutani
June 22, 2022
More Decks by shibutani
See All by shibutani
越境するAIのために、境界を取り払う - AI 時代の開発体験向上に向けたリポジトリ統合の取り組み -
shibukazu
1
640
メッセージキュー型の非同期処理から Temporal 移行へ
shibukazu
4
5.7k
はじめてのOSS開発からみえたGo言語の強み
shibukazu
4
1.5k
全自動コードレビューの夢 〜実際に活用されるAIコードレビューの実現に向けて〜
shibukazu
11
5.6k
Hybrid Autoregressive Transducer [輪講発表資料]
shibukazu
0
410
Other Decks in Research
See All in Research
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
890
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
400
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
570
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
typst の使い方:言語学を研究する学生のために
gitomochang
0
520
「AIとWhyを深堀る」をAIと深堀る
iflection
0
530
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
420
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
170
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
260
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
230
LLM Compute Infrastructure Overview
karakurist
2
1.5k
Featured
See All Featured
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Odyssey Design
rkendrick25
PRO
2
730
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Un-Boring Meetings
codingconduct
0
350
Agile that works and the tools we love
rasmusluckow
331
22k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Code Review Best Practice
trishagee
74
20k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Faster Mobile Websites
deanohume
310
32k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
420
Transcript
Perceiver: General Perception with Iterative Attention [Jaegle, Gimeno+ 2020] 京都大学
音声メディア研究室 M1 渋谷和樹 1
これまではモダリティに依存したアーキテクチャが主流 ⇒アーキテクチャがモダリティにロックインされる Transformerはモダリティに依存しない Transformerの計算量は入力インデックスの二乗に比例 任意の入力長に対応できるTransformerベースのアーキテクチャが必要 ⇒Perceiverの登場 Introduction 2
Perceiver 3
Transformerベースのモダリティ非依存アーキテクチャ CrossAttentionによってTransformerの計算量を削減 画像・音声・点群において優れた性能 Perceiver 4
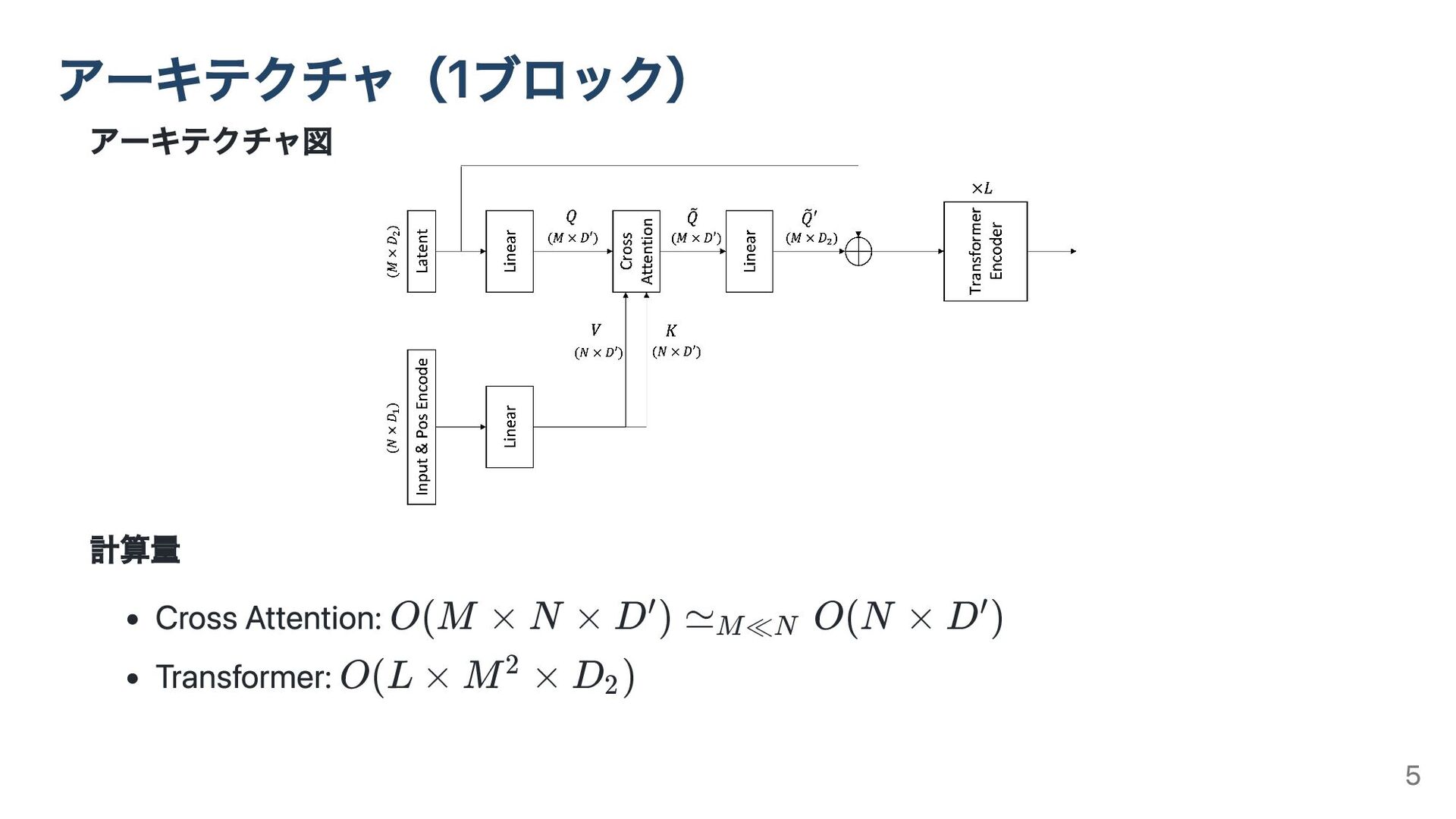
アーキテクチャ図 計算量 Cross Attention: Transformer: アーキテクチャ(1ブロック) O(M × N ×
D ) ≃ ′ M≪N O(N × D ) ′ O(L × M × 2 D ) 2 5
Attentionは入力系列の順序に依存しない Transformerと同様の位置エンコーディングを利用 p = i,2k sin(f πx
) k d p = i,2k+1 cos(f πx ) k d : ハイパーパラメータ : 次元 における位置( ) Transformerと異なり、加算ではなく入力へ連結する 位置エンコーディング f k x d d −1 ∼ 1 6
結果(Image) 7
実験設定 データセット: ImageNet ピクセルレベルの並び替えあり・並び替えなしで実験 評価指標: 予測ラベルの正解率 アーキテクチャ: (CrossAttention + TransformerEncoder
* 6) * 8 入力ベクトル: 50176x3 潜在ベクトル: 512x1024 結果(Image) 8
比較モデル ResNet-50: レイヤー数50のCNNベースモデル ViT-B-16: Transformerベースモデル 入力の処理に16x16の畳み込みを利用 Transformer: 64x64にダウンサンプリングした上で入力 結果(Image -
並び替えなしの場合) 9
結果 モダリティの仮定をせずにベースラインと互角の性能を発揮 ベースラインに位置エンコーディングを入力しても性能は向上しなかった 結果(Image - 並び替えなしの場合) 10
設定 各画像内のピクセルを同一の規則に従って並び替える 帰納バイアスの利用を防ぐ 並び替え前に位置エンコーディングを行う 位置エンコーディングからピクセル同士の関連は学習可能 Learned pos: 位置エンコーディングを学習する inputRF: 入力レイヤーにおける受容野の大きさ
結果(Image - 並び替えありの場合) 11
結果 モダリティを仮定しないTransformerやPerceiverでは性能が悪化しなかった ViTは性能が劣化しづらかった ViTで採用されている畳み込みフィルターはResNet50より大きいから? 最終的にTransformerでパッチ間の関係を見ていることも関係してそう? 結果(Image - 並び替えありの場合) 12
結果(Audio and Video) 13
実験設定 データセット: AudioSet Audio, Video, Audio&Videoで実験 評価指標: meanAveragePrecision アーキテクチャ: (CrossAttention+TransformerEncoder*8)*2
入力ベクトル 生音声: 480x128 メルスペクトログラム: 4800x1 動画: 12544x128 潜在ベクトル: サイズ記載なし 結果(Audio and Video) 14
結果 いずれの入力パターンでもほとんどの比較手法と同等以上の性能 CNN-14に関してはbalancingおよびmixupなどの前処理を除くと性能が下回った Attention AV-fusionとの違いは今後の調査課題 結果(Audio and Video) 15
結果(Point clouds) 16
実験設定 データセット: ModelNet40 評価指標: 予測ラベルの正解率 アーキテクチャ: (CrossAttention+TransformerEncoder*6)*2 入力ベクトル: サイズ記載なし(おそらく単純にflatten?) 潜在ベクトル:
サイズ記載なし 結果(Point cloulds) 17
結果 PointNet++以外の手法より優れていた PointNet++ではドメイン知識に基づいたデータ拡張や特徴量エンジニアリングを行って いるため比較対象としては不適? 結果(Point cloulds) 18
まとめ 19
TransformerベースのPerceiverを提案 Cross-Attentionの利用により、Transformerの計算量を削減 画像・音声・点群いずれにおいても極めて高い性能を発揮 モダリティ特有のデータ拡張や位置エンコーディングへの依存を減らすのが今後の課題 まとめ 20
![Perceiver: General Perception with Iterative Attention [Jaegle, Gimeno+ 2020] 京都大学](https://files.speakerdeck.com/presentations/6999486a794049c3878f67271d8470a6/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}