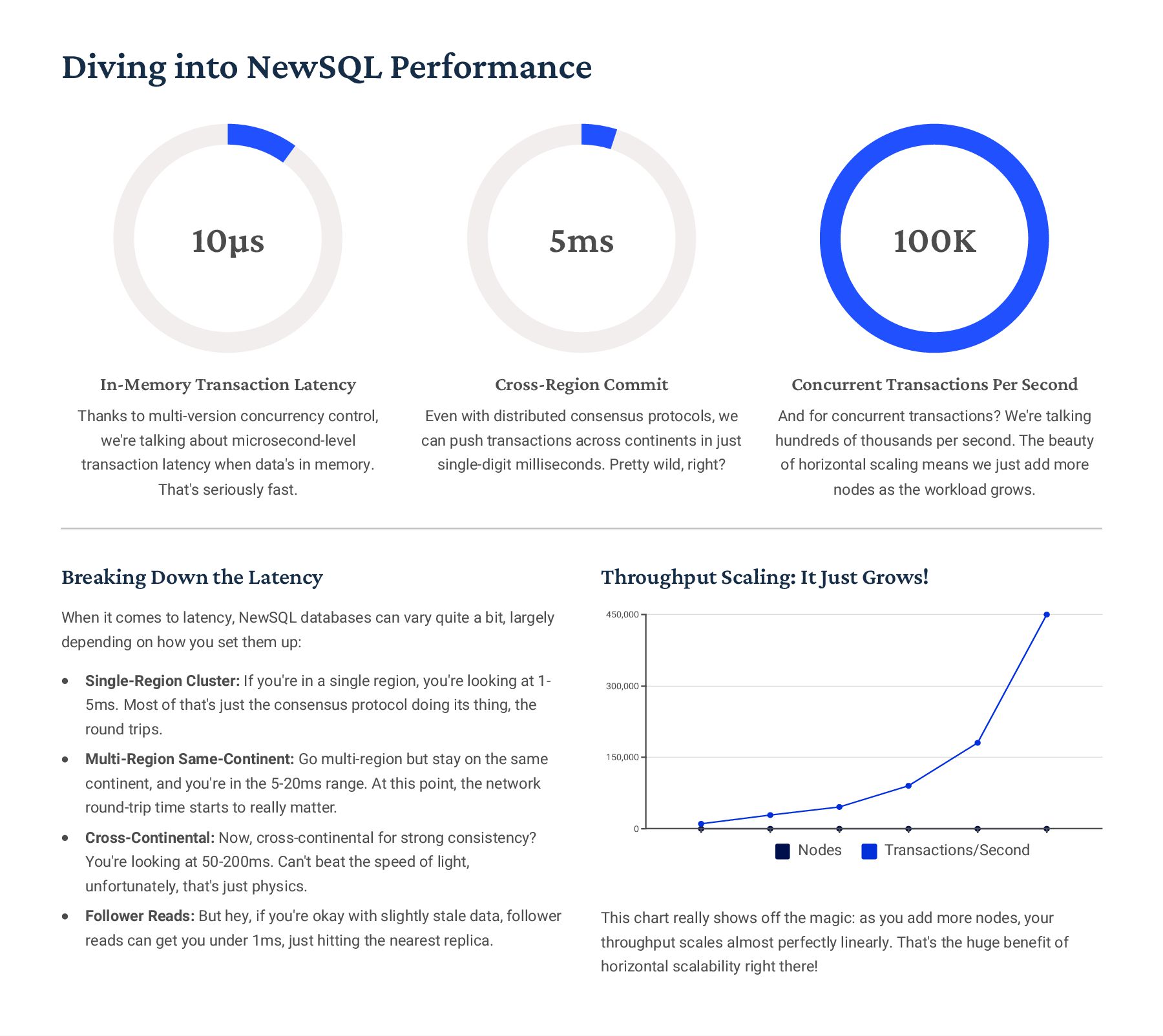
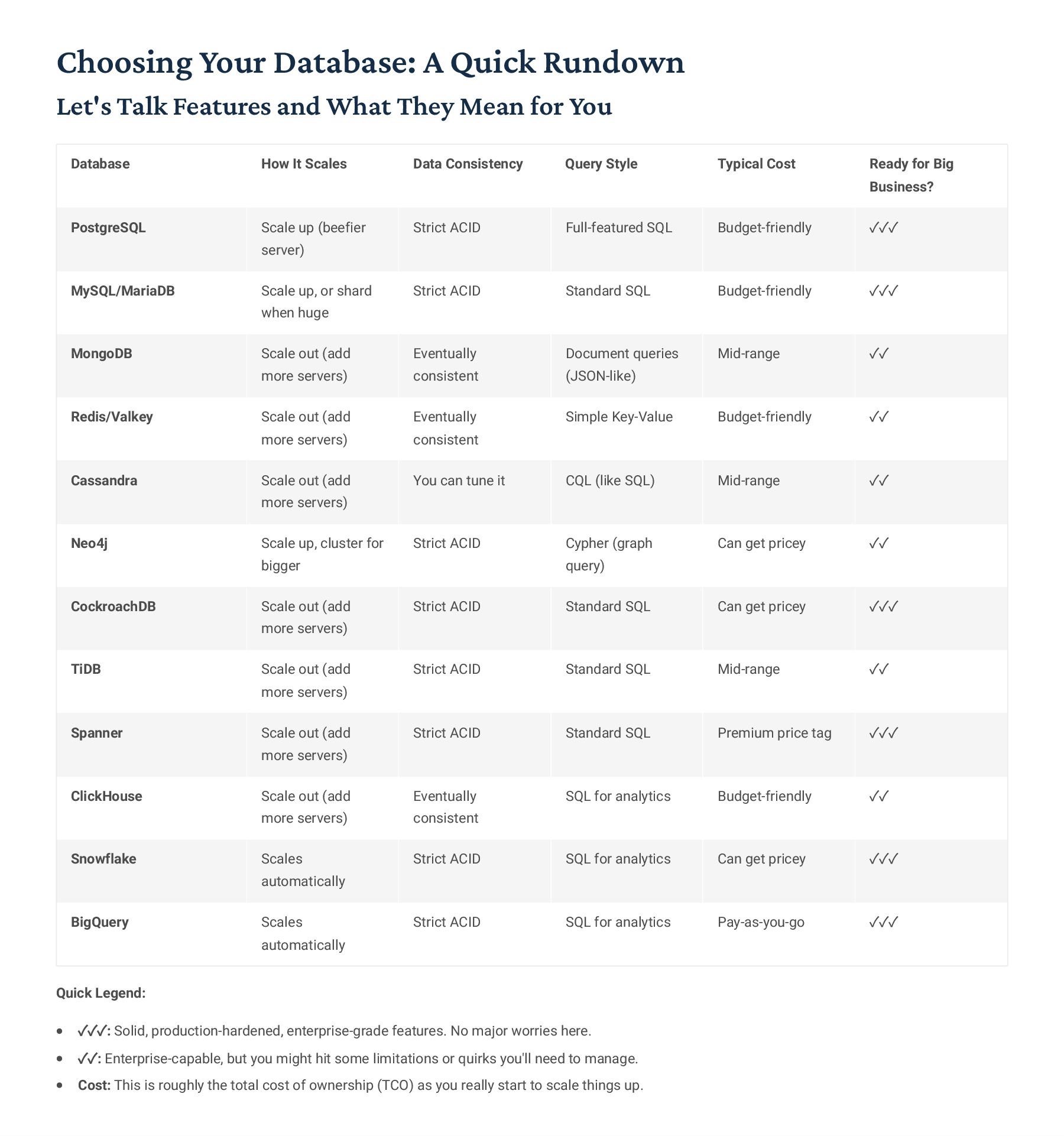
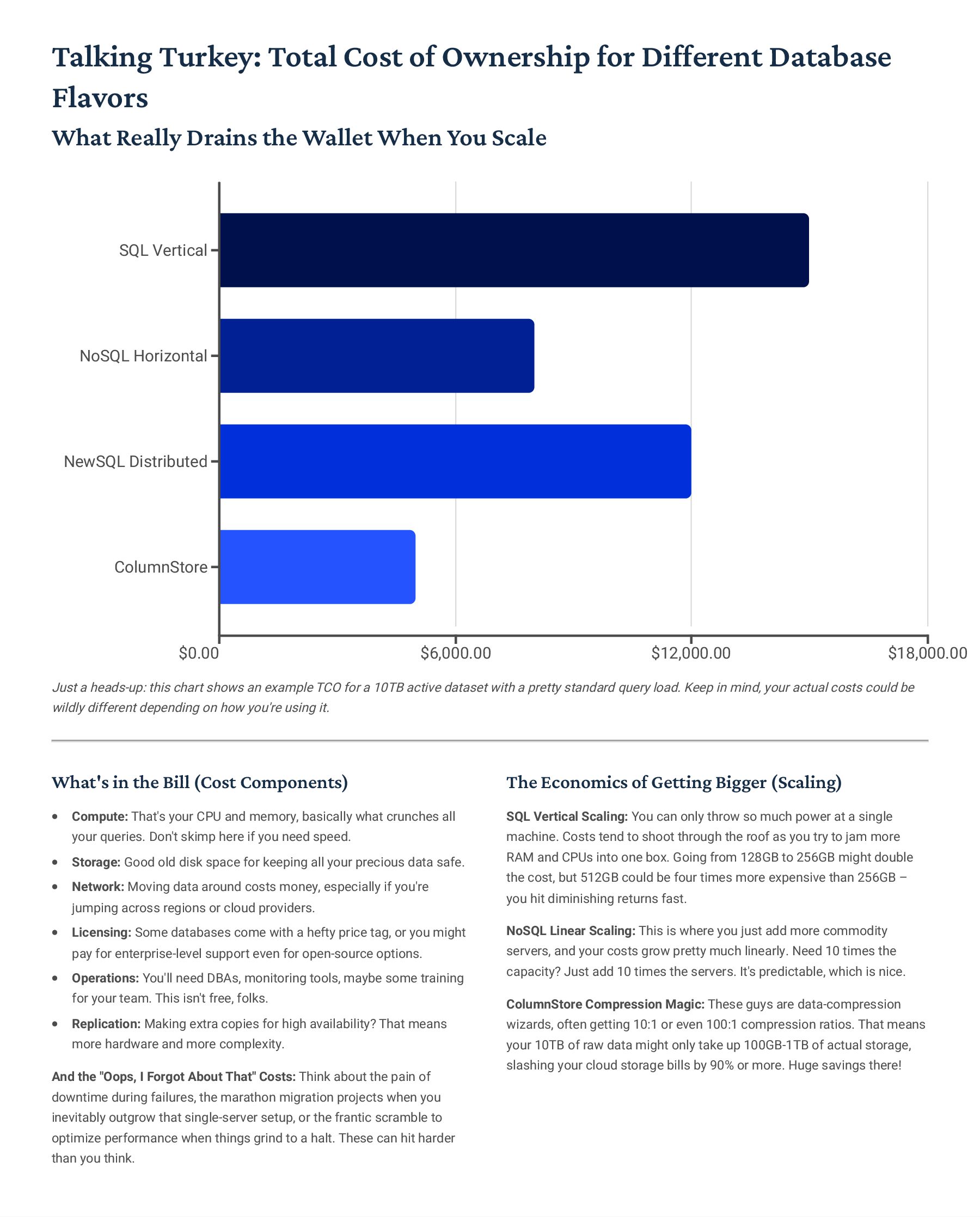
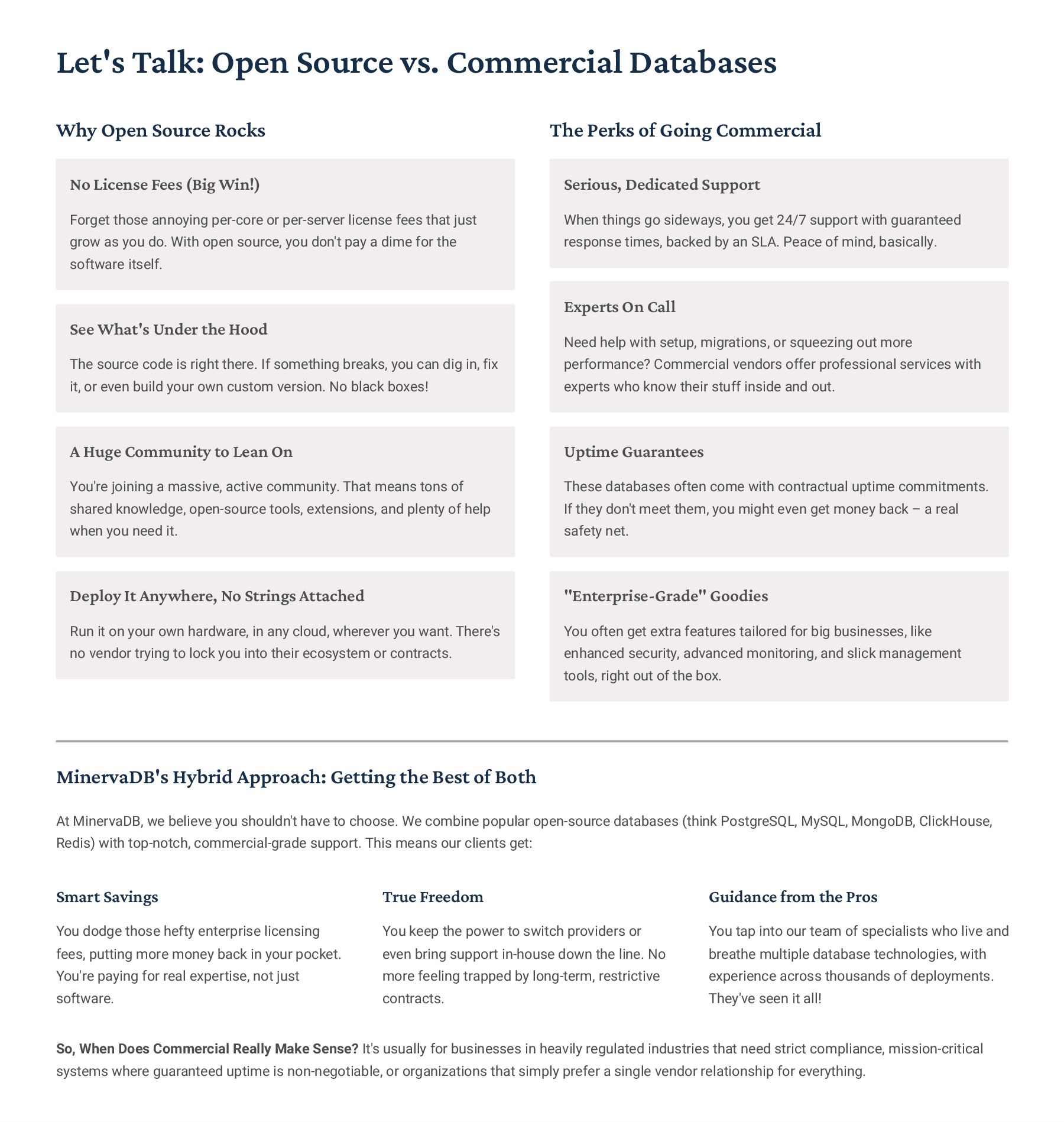
for Blazing-Fast Analytics So, How Do Column Stores Actually Keep Data? Alright, picture this: your standard row stores just grab a whole record4 like [id:1, name:"Alice", age:30, city:"NYC"]4and save it all together. But column stores? They flip that on its head. They group data by the attribute. So instead, you'd see something like id:[1,2], then name: ["Alice","Bob"], then age:[30,25], and finally city:["NYC","LA"], all as separate chunks. It9s a totally different way to organize things! Why This Design Kicks Butt for Analytics Only Read What You Need: Imagine you're just trying to figure out the age distribution. The system literally only bothers with the 'age' column, leaving all the other irrelevant data untouched. That's a huge time-saver. CPU Power Unleashed: Our CPUs actually love working with batches of the same kind of data. Column stores let them do 'vectorized processing,' meaning they can chew through arrays of identical values super-efficiently, often using fancy SIMD instructions. Seriously Good Compression: Because each column holds similar data types (think all ages, or all names), it compresses *way* better than a mixed-up row. We're talking serious space savings here. Late Materialization: This is pretty neat. We only bother reconstructing a full row when we absolutely need to for the final result. All the intermediate calculations? Done on the compressed, column-wise data. The Encoding & Compression Magic Behind It All Dictionary Encoding Got a bunch of repeated strings, like city names? We just swap 'em out for a small integer ID. So "NYC" becomes 1, "LA" becomes 2. It's awesome for saving space and makes comparisons lightning fast because we're just comparing numbers. Run-Length Encoding (RLE) When you have long stretches of identical values4say, a column full of "active" statuses4RLE just stores the value once, plus a count. So, [A,A,A,B,B,C] turns into [(A,3),(B,2),(C,1)]. Super efficient! Bit-Packing Why use a full 32-bit integer for a value that only ranges from 0-255? Bit-packing lets us use just the minimal number of bits required, like 8 bits instead of 32. Every bit counts! Delta Encoding This is great for data that changes incrementally, like a sequence of timestamps. Instead of storing each absolute value, we just store the first value and then the small differences (deltas) to the next ones. So [1000, 1001, 1002] could become [1000, +1, +1]. Real-World Compression Ratios: Honestly, in production, we often see mind-blowing compression ratios4anywhere from 10:1 up to 100:1, depending on how "samey" your data is. This dramatically cuts down storage costs and, more importantly, slashes I/O, which is always a bottleneck!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}