The v&v (vein and vision) of algorithms about AlphaGo and AlphaGo Zero
==========================================================
【2019/10/10:Revision History】
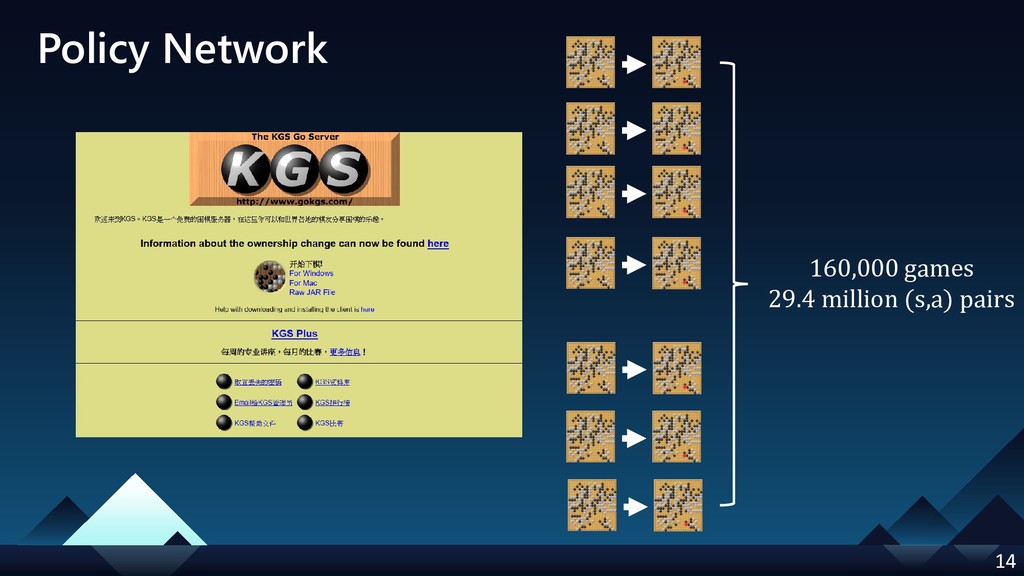
[p.14] correct the size of KGS data: 30 million -> 160,000 games & 29.4 million (s,a) pairs
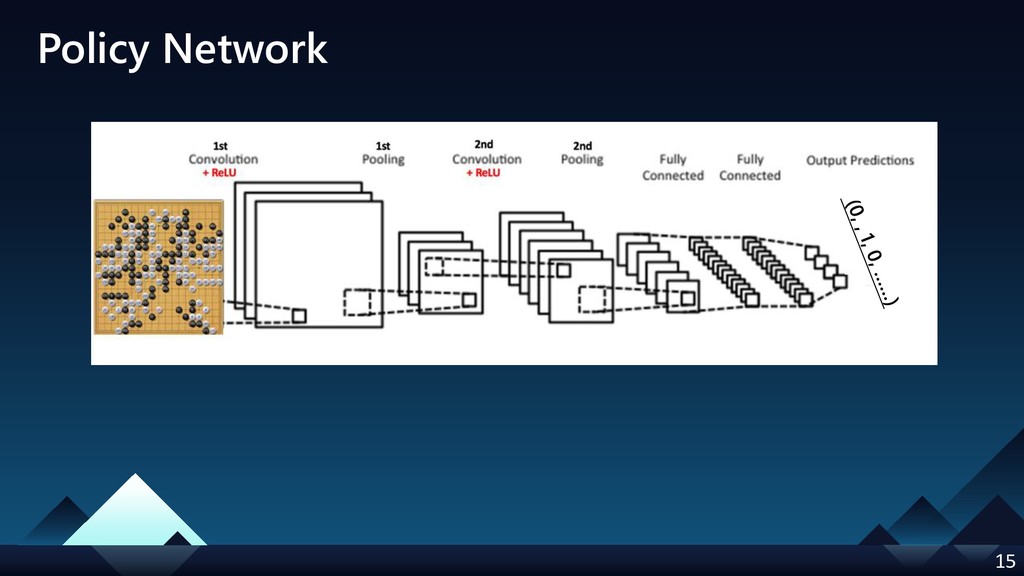
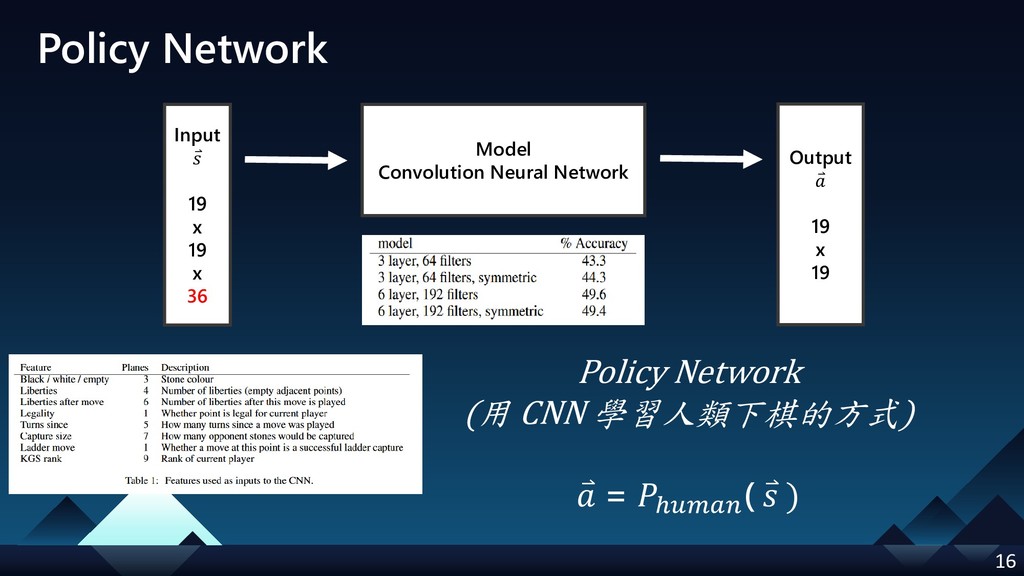
[p.16] correct the input size of policy nework (19x19x48 -> 19x19x36); additional 36 features description from paper.
[p.72] add information: the generated 30 million games(data) from self-play for AlphaGo
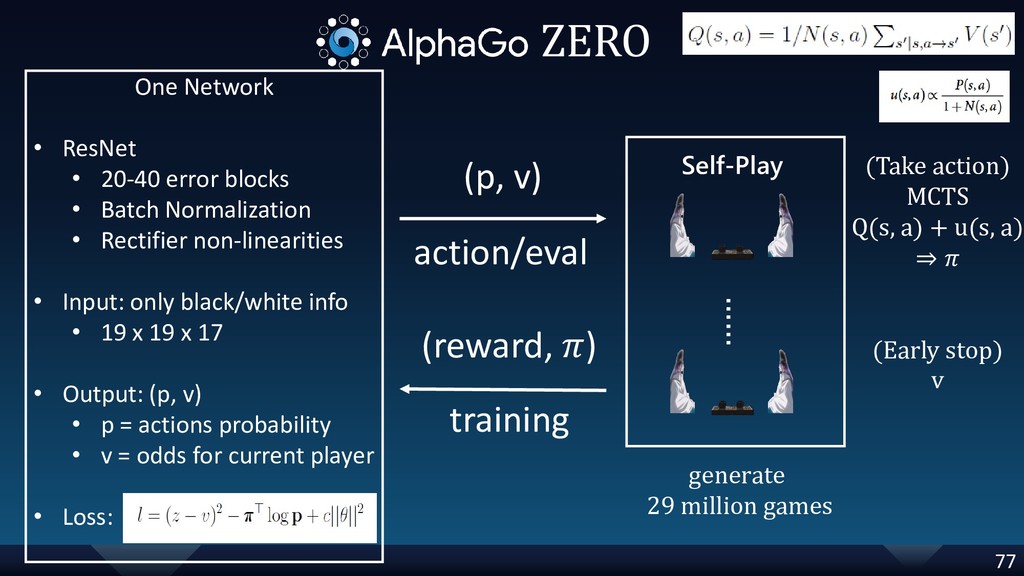
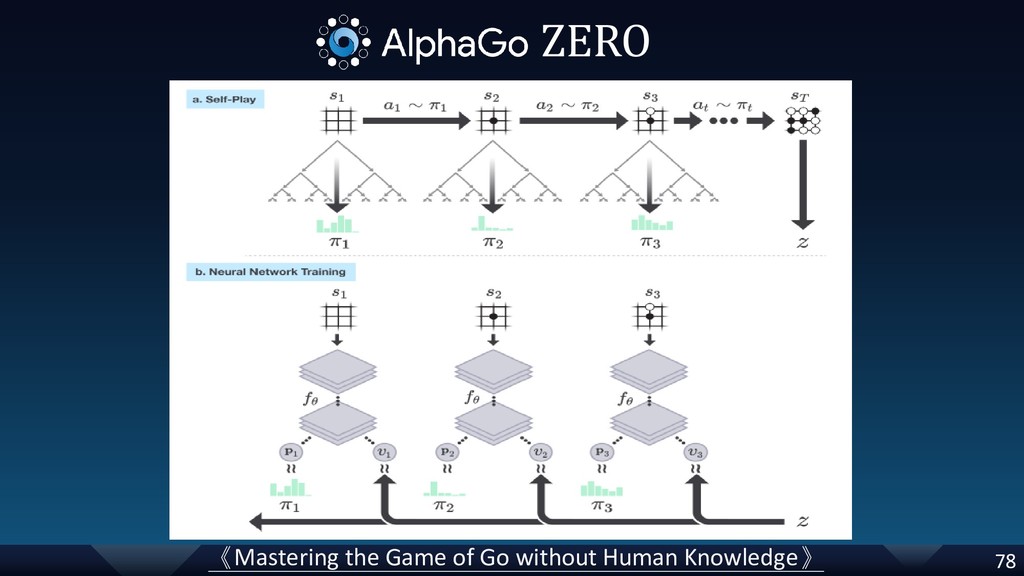
[p.77] correct input size (7 -> 17); add information: the generated 29 million games(data) from self-play for AlphaGoZero
[p.84] update hyperlinks of reference papers
==========================================================
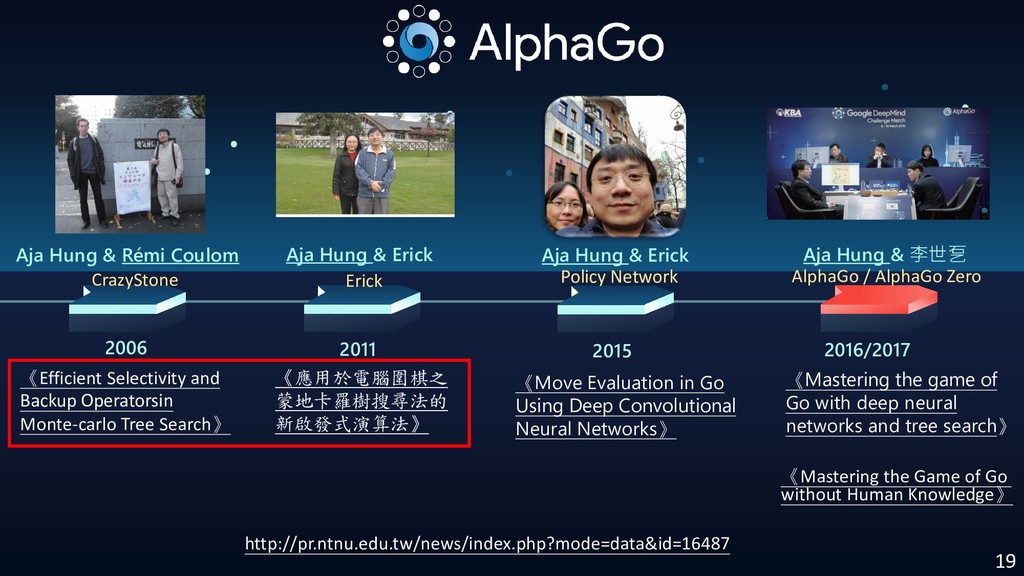
- Development history (Aja Huang, Rémi Coulom)
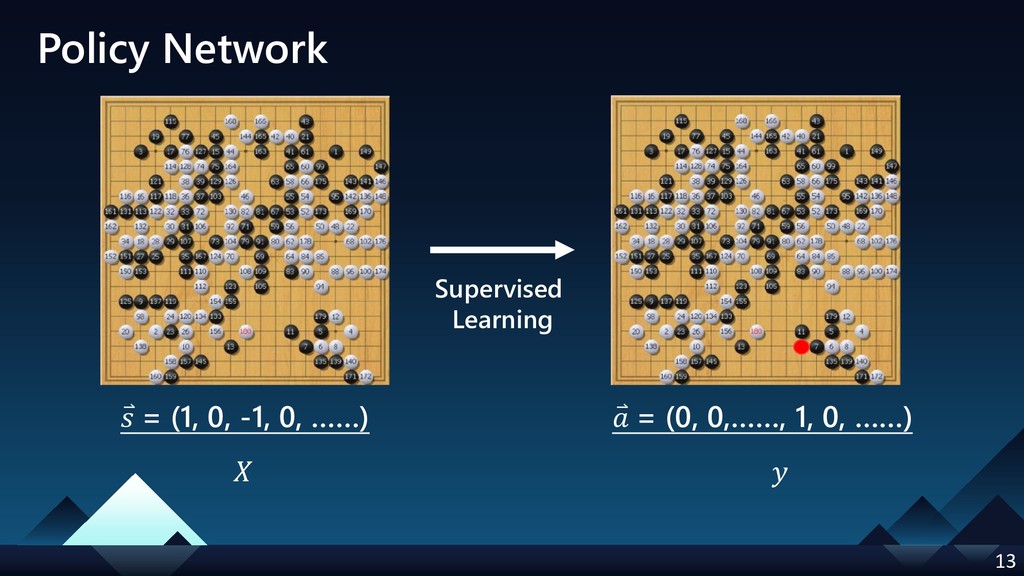
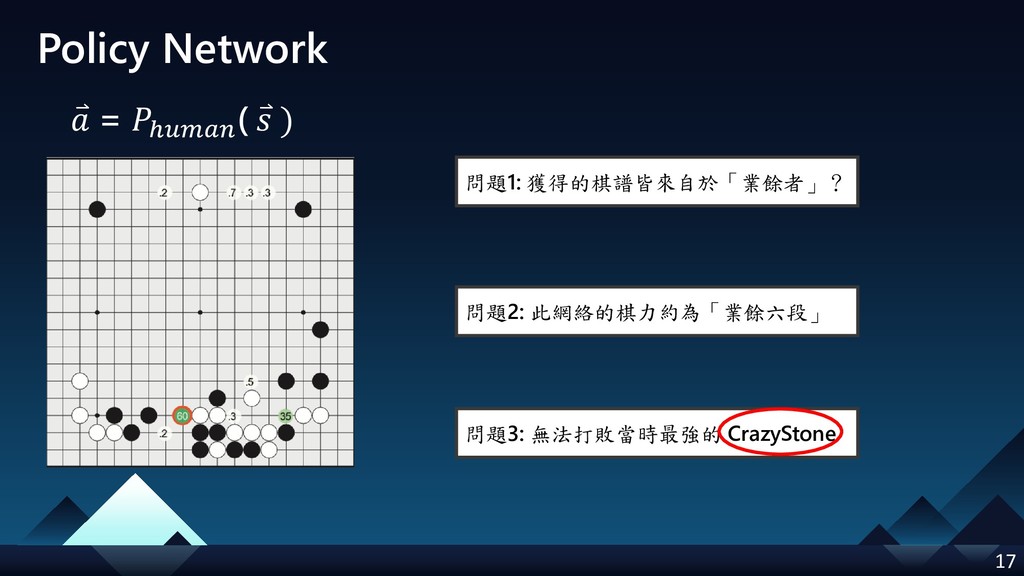
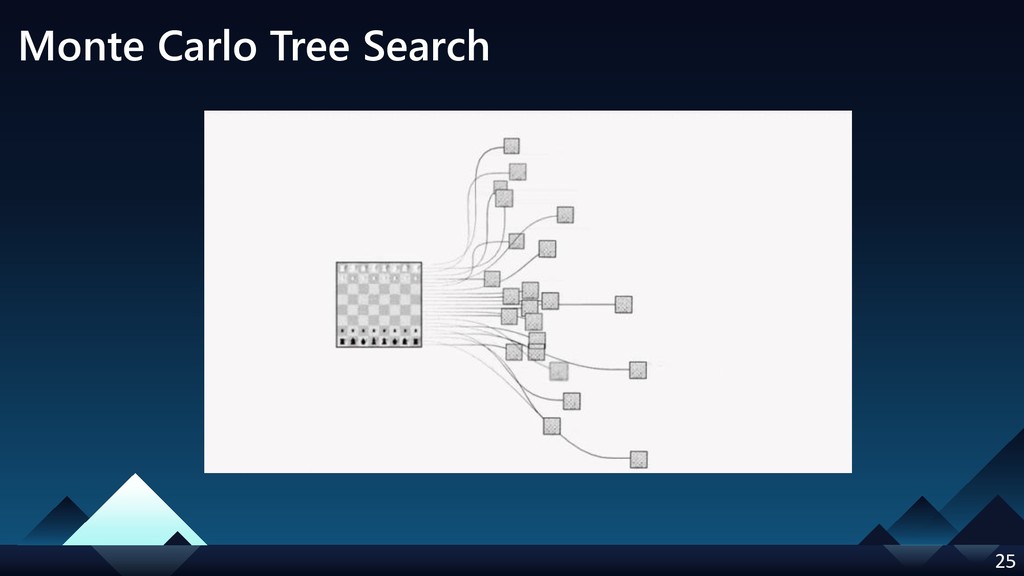
- Policy Network
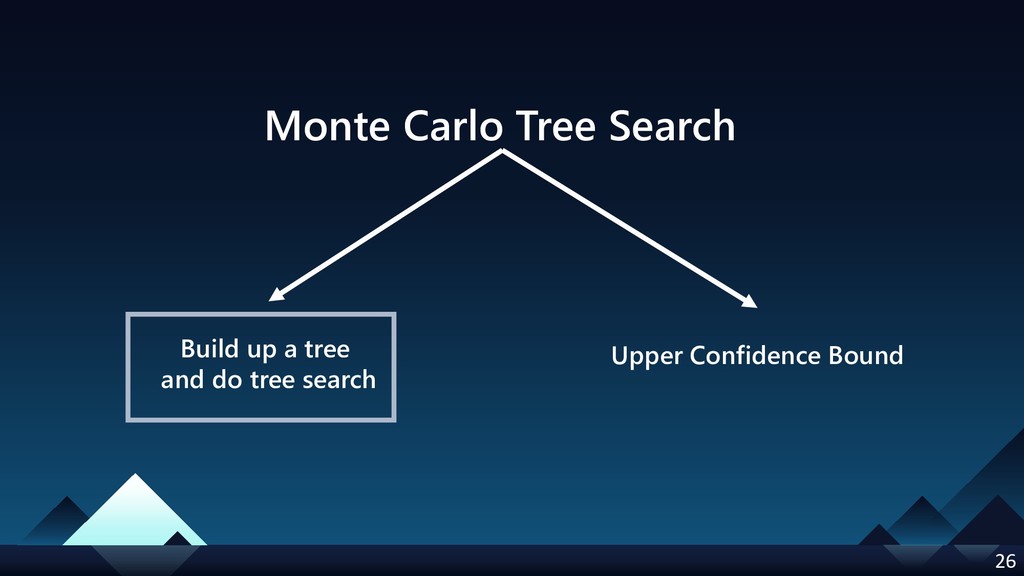
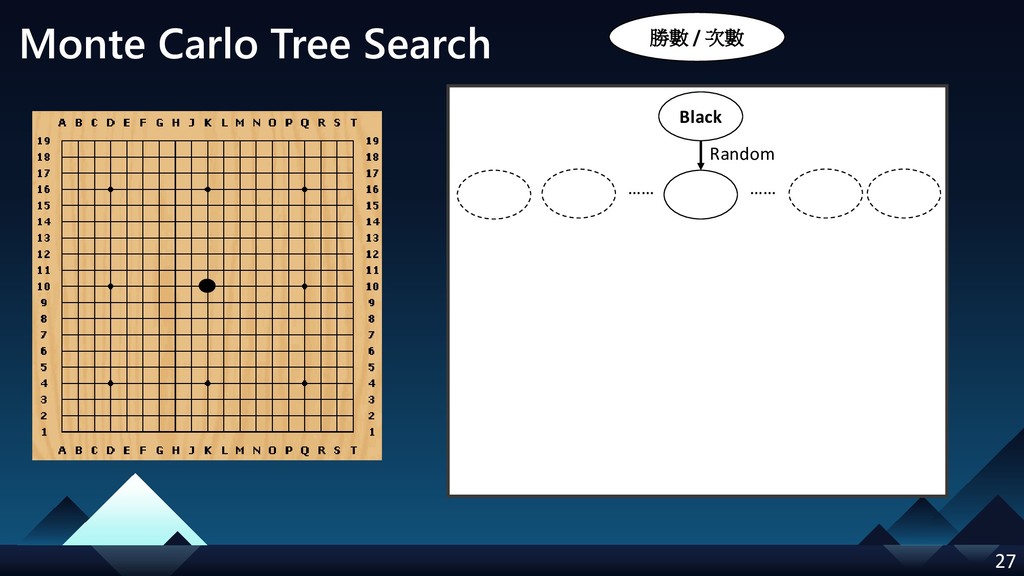
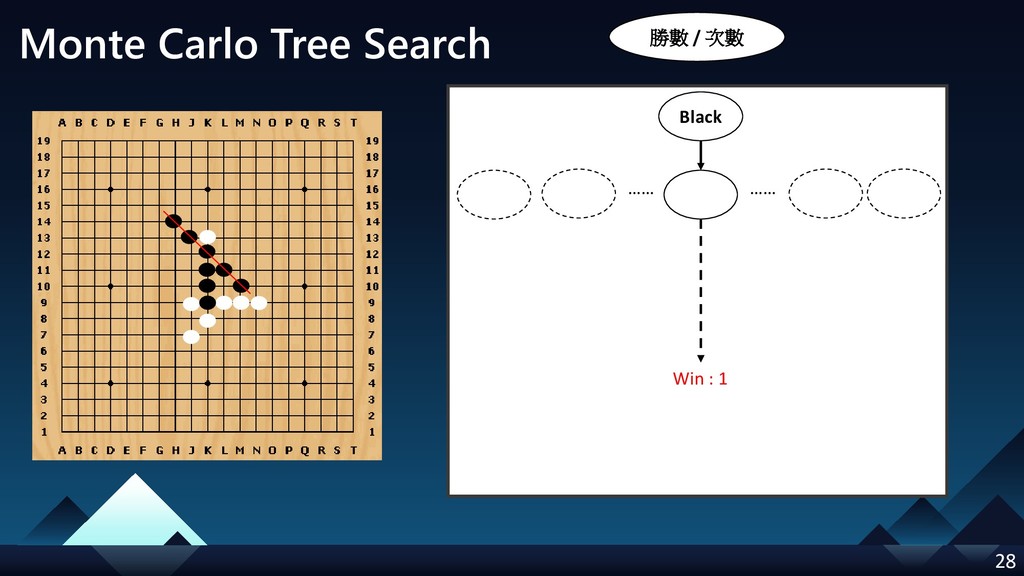
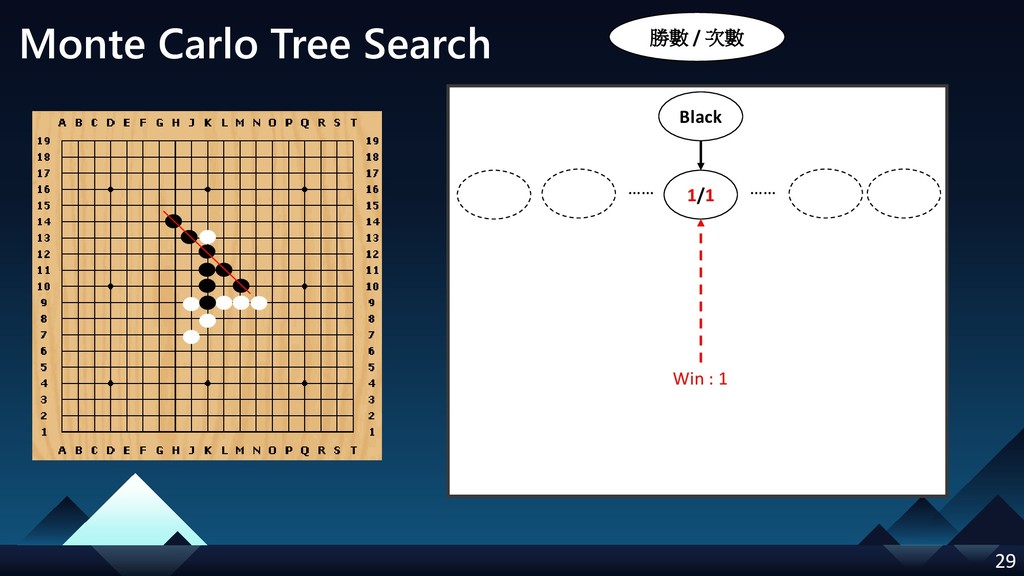
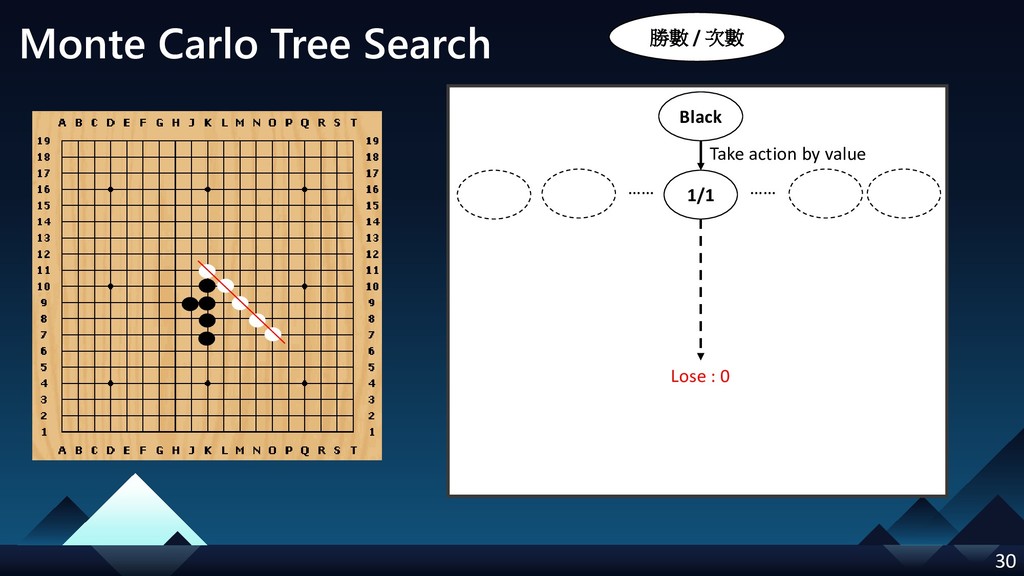
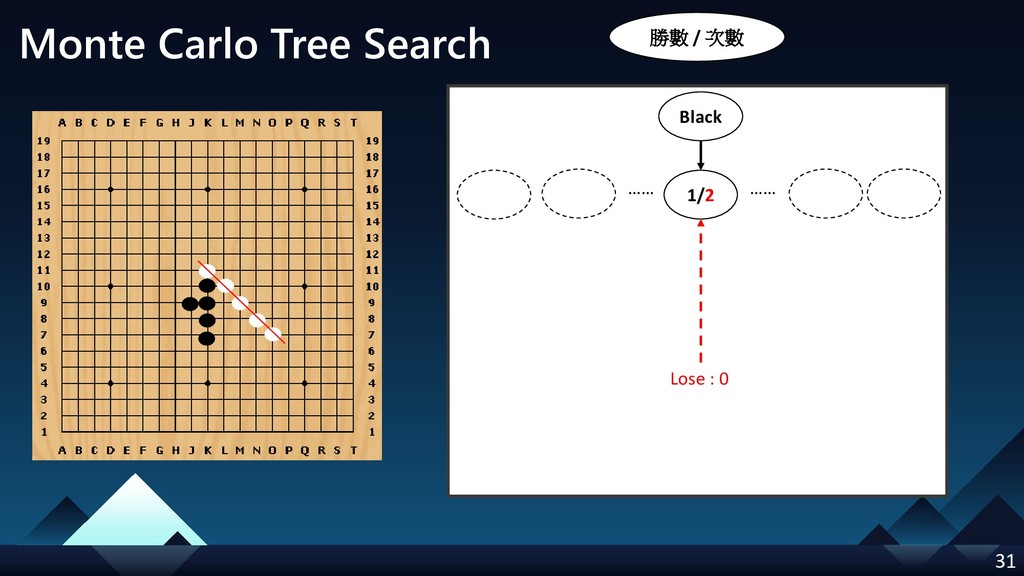
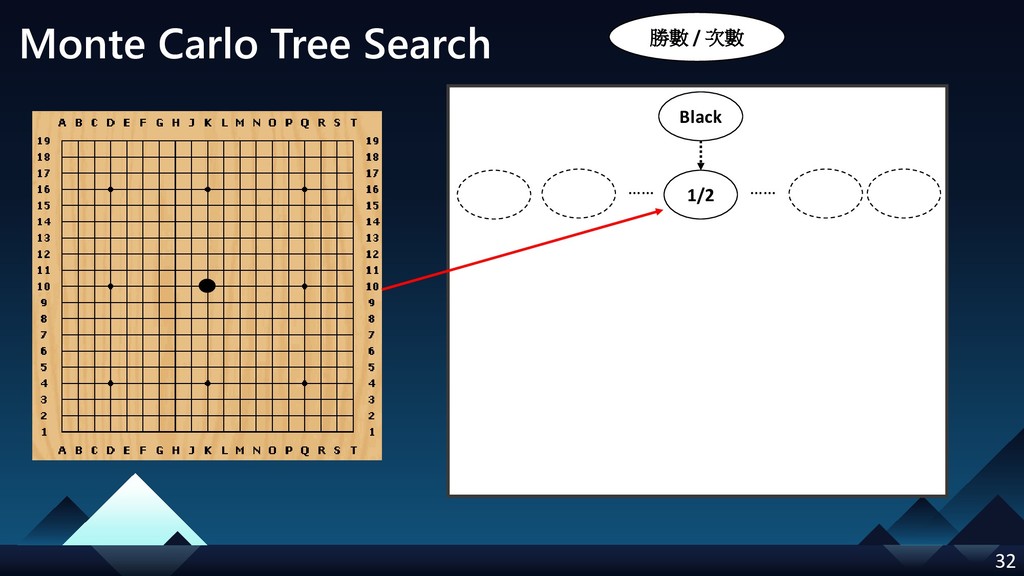
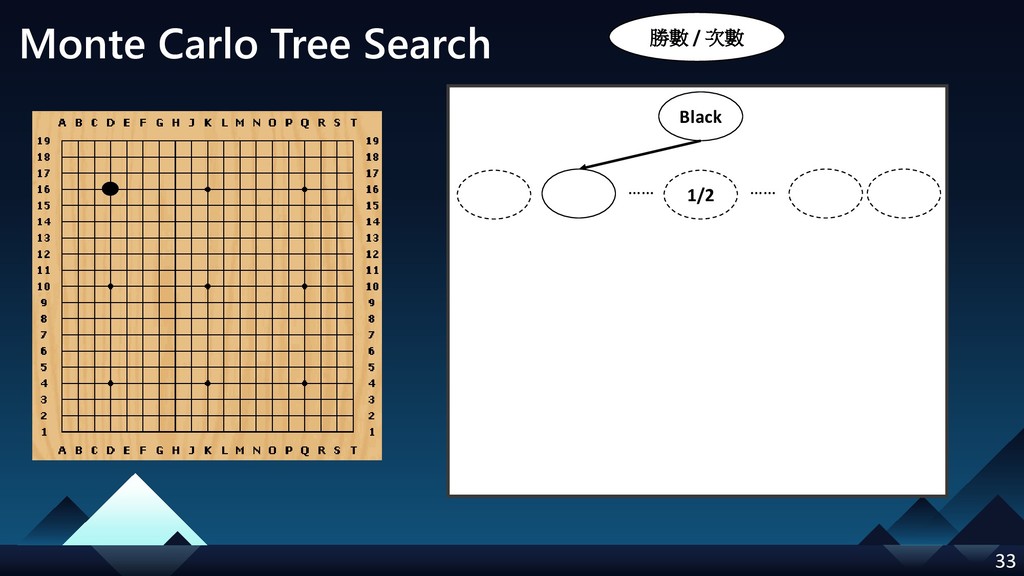
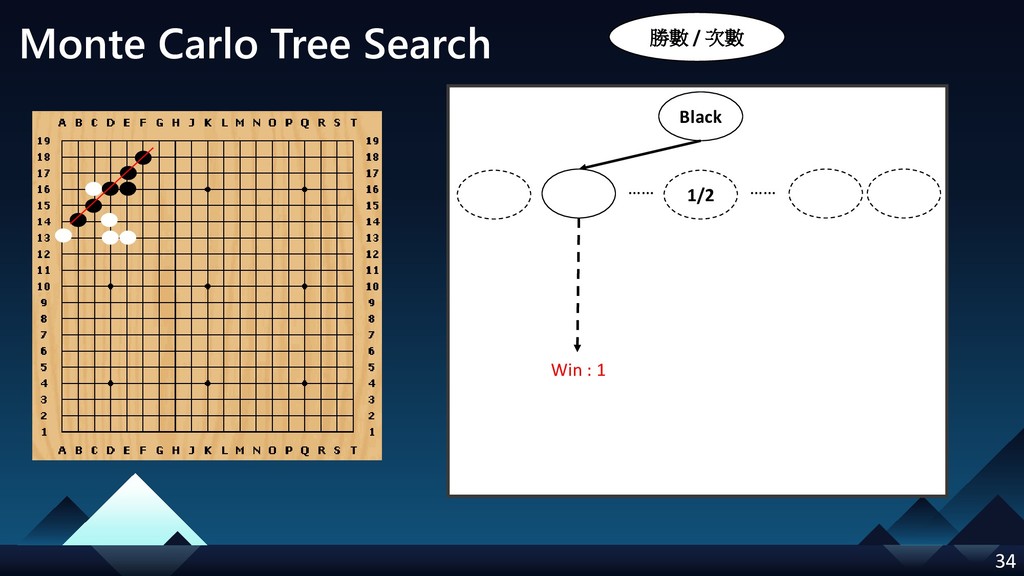
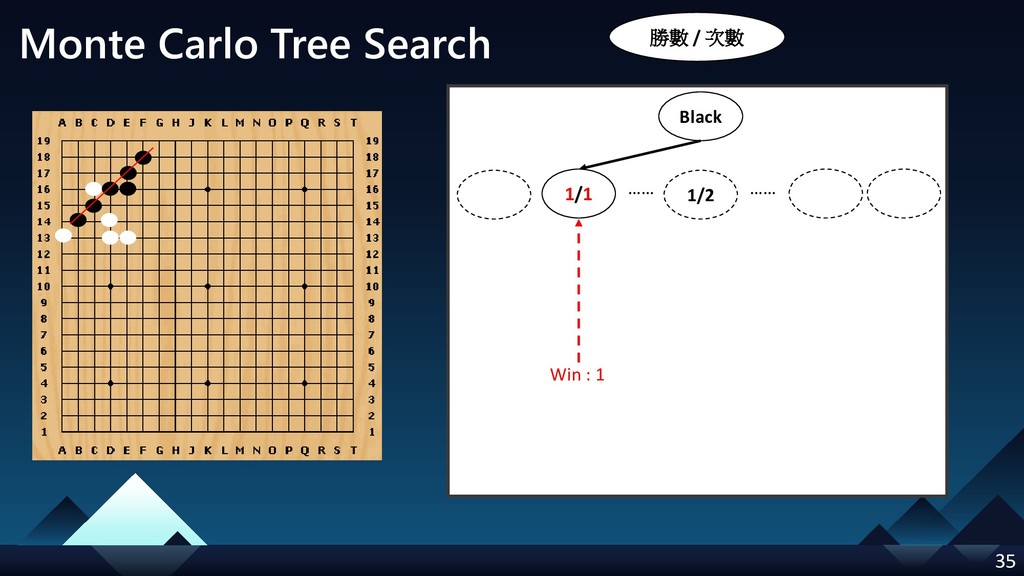
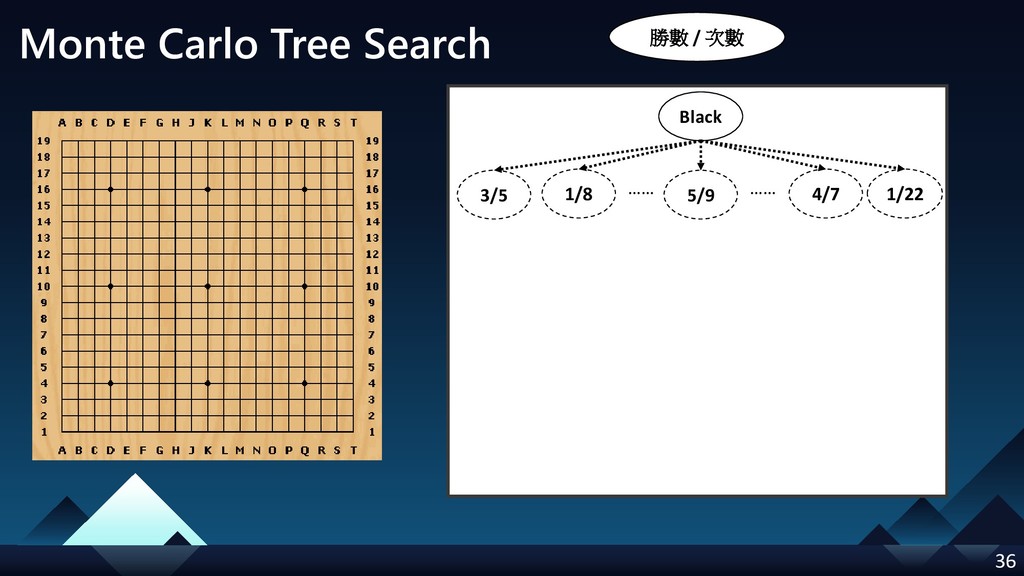
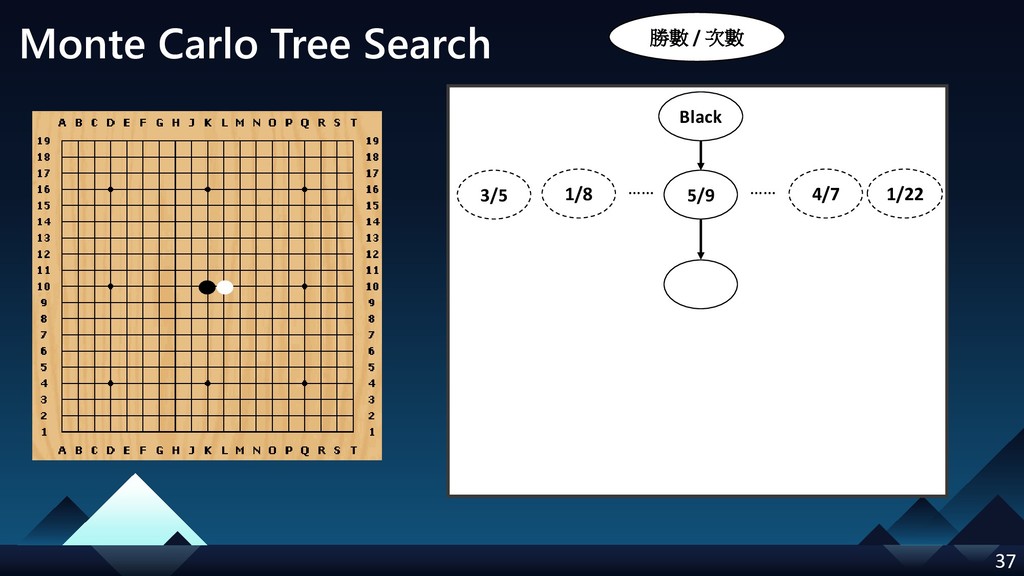
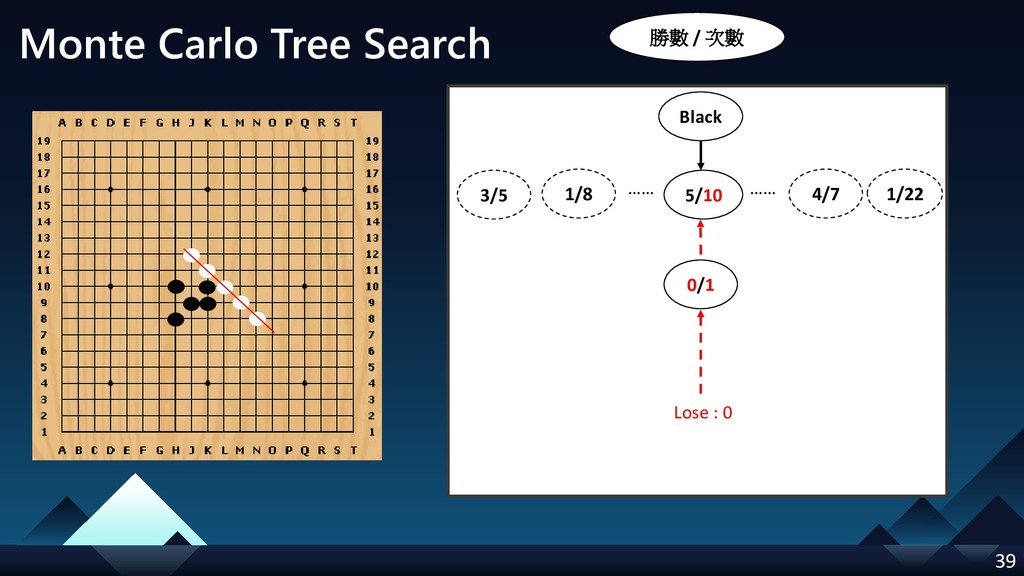
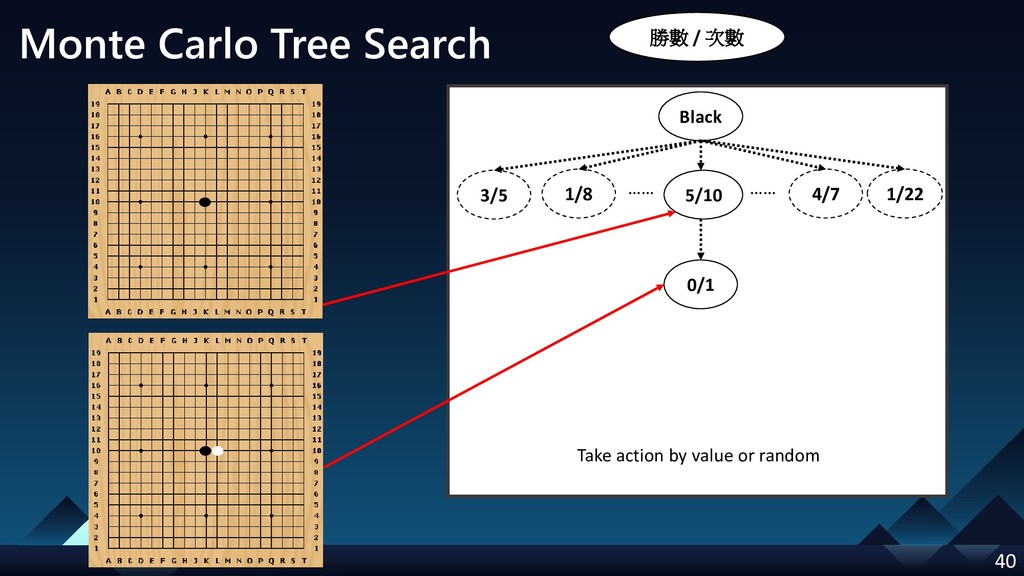
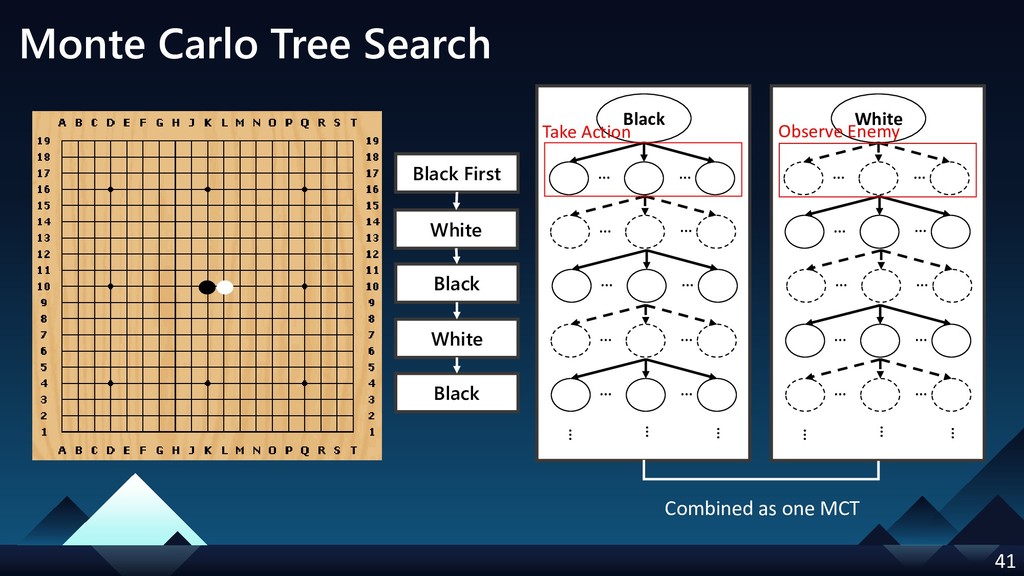
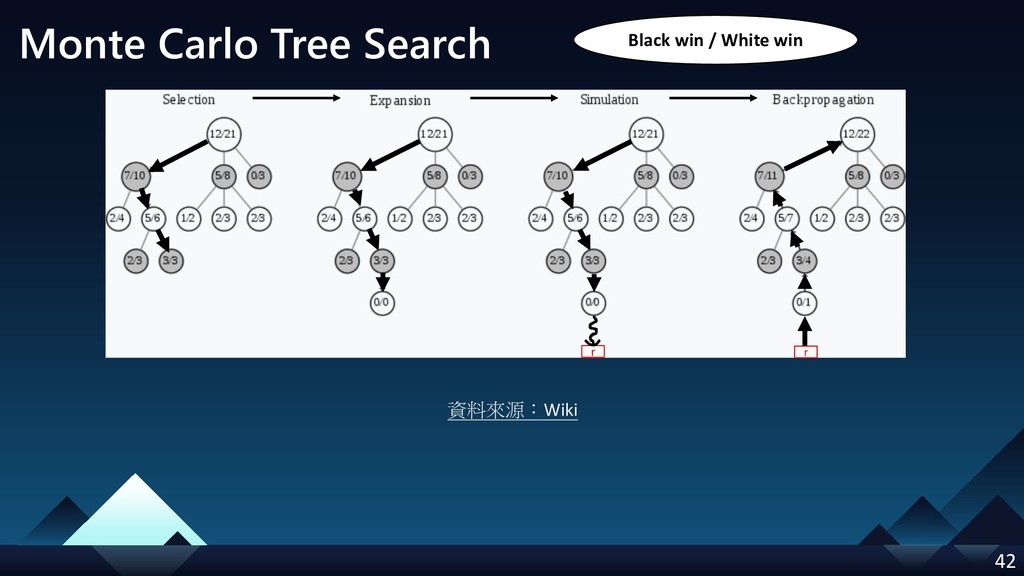
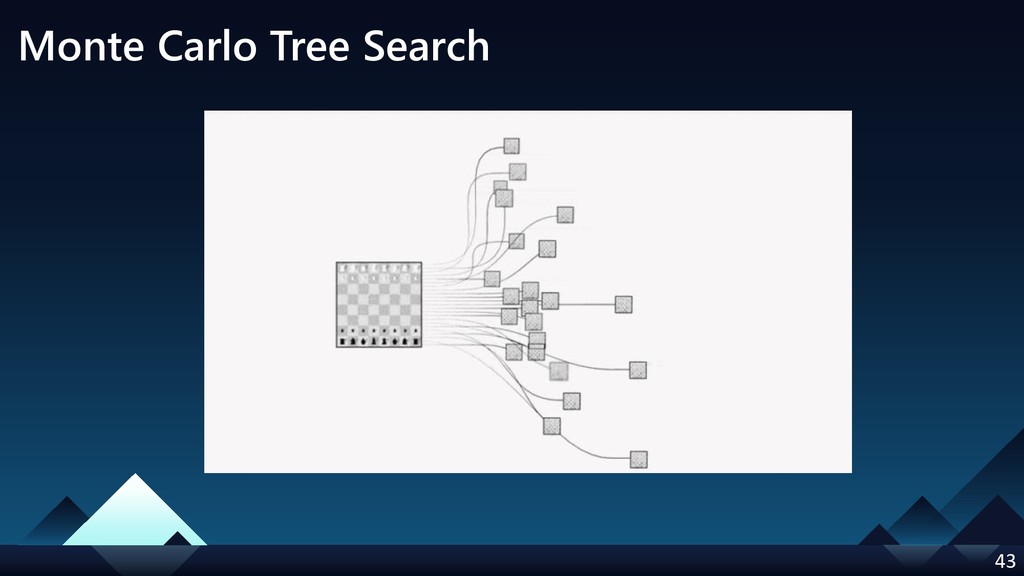
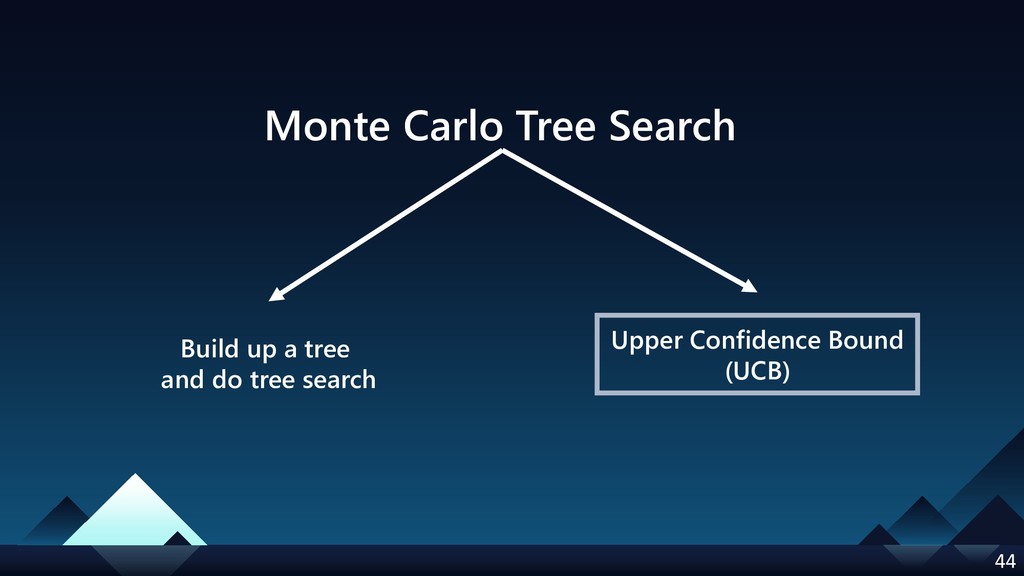
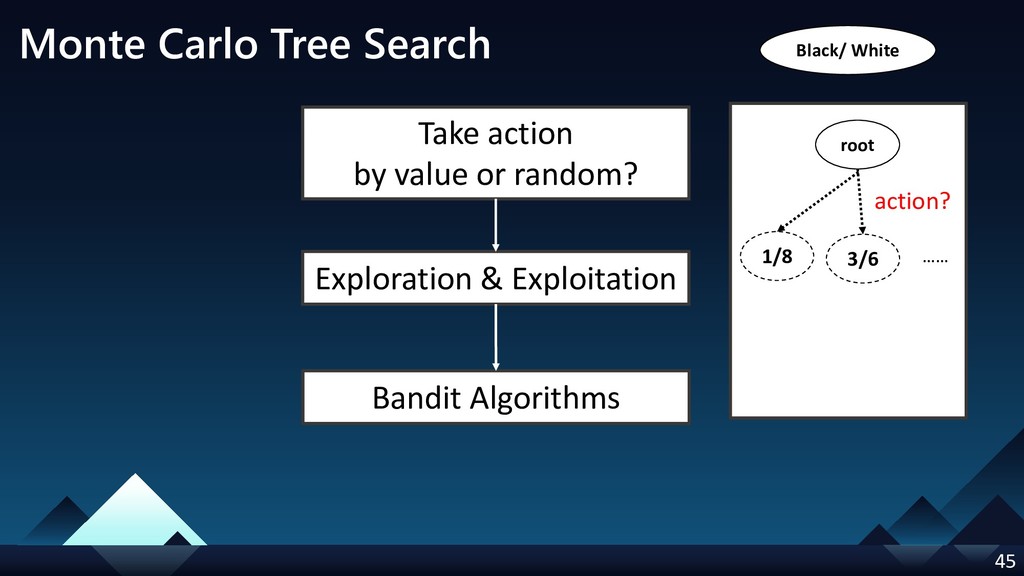
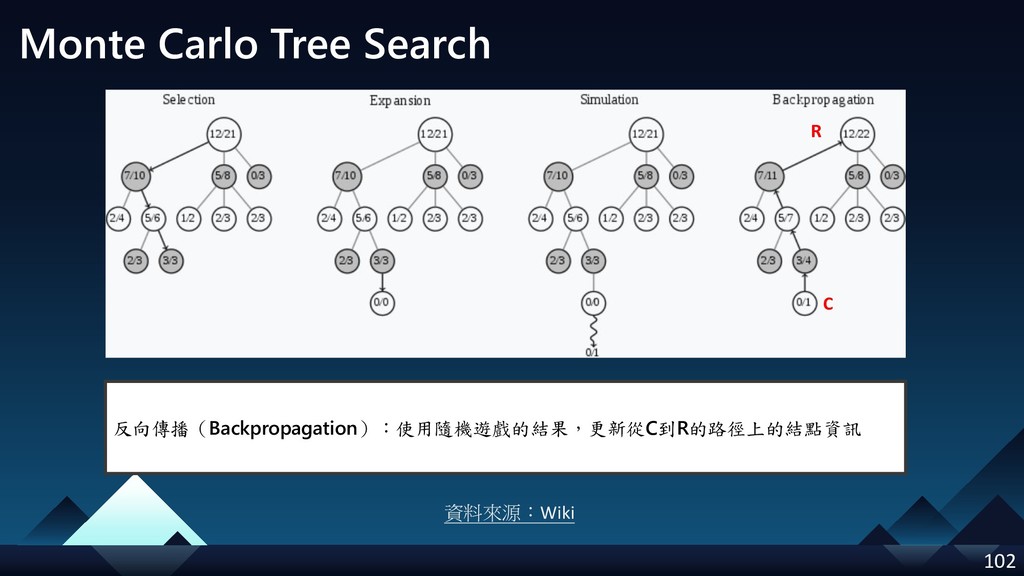
- Monte Carlo Tree Search
- Value Network
- Self Play
- Different structure between AlphaGo and AlphaGo Zero
==========================================================
[2018.07.20] For POLab (https://github.com/PO-LAB) Summer Rookie Training
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
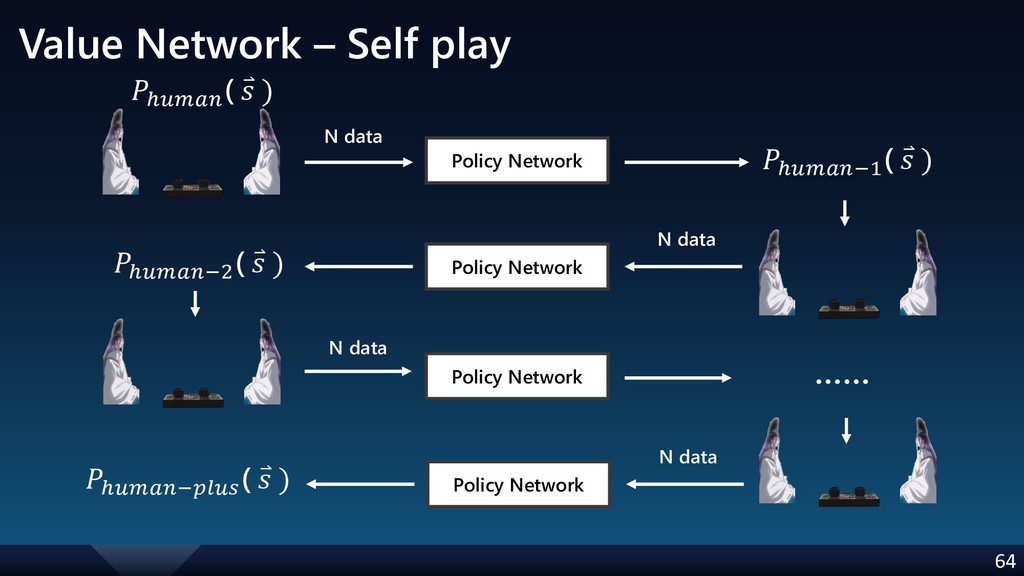{kind=link}
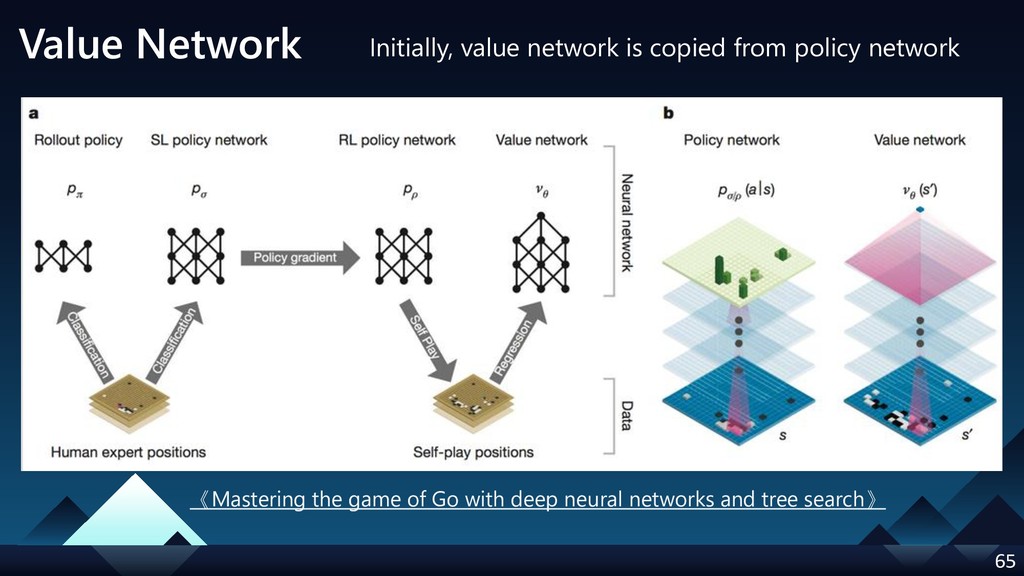{kind=link}
{kind=link}
{kind=link}
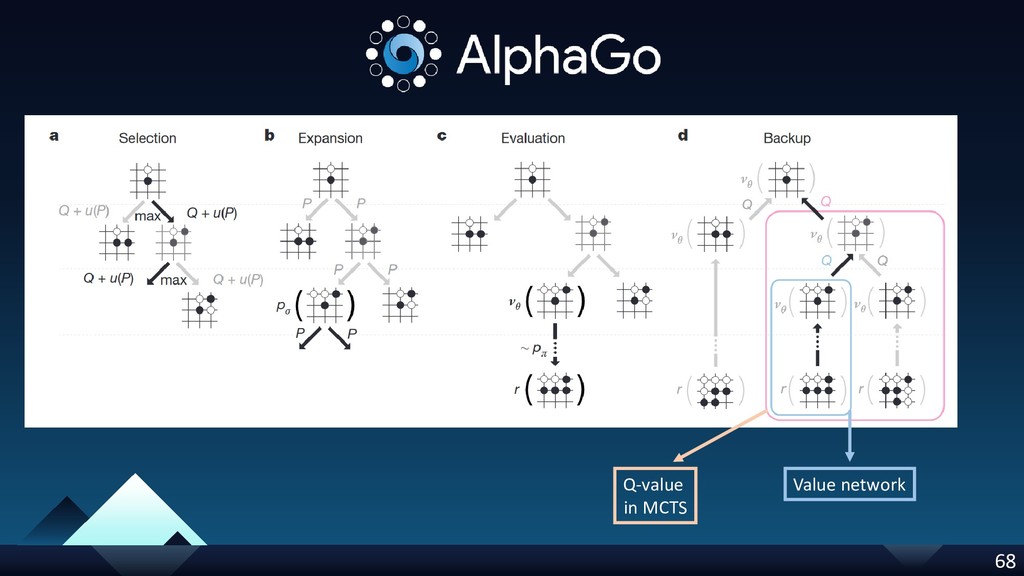{kind=link}
![v(s’) Q(s, a) [λ = 0] Q(s, a) [λ =](https://files.speakerdeck.com/presentations/d70ff5a6ac1e42efb8a8791285c9a3ac/slide_68.jpg){kind=link}
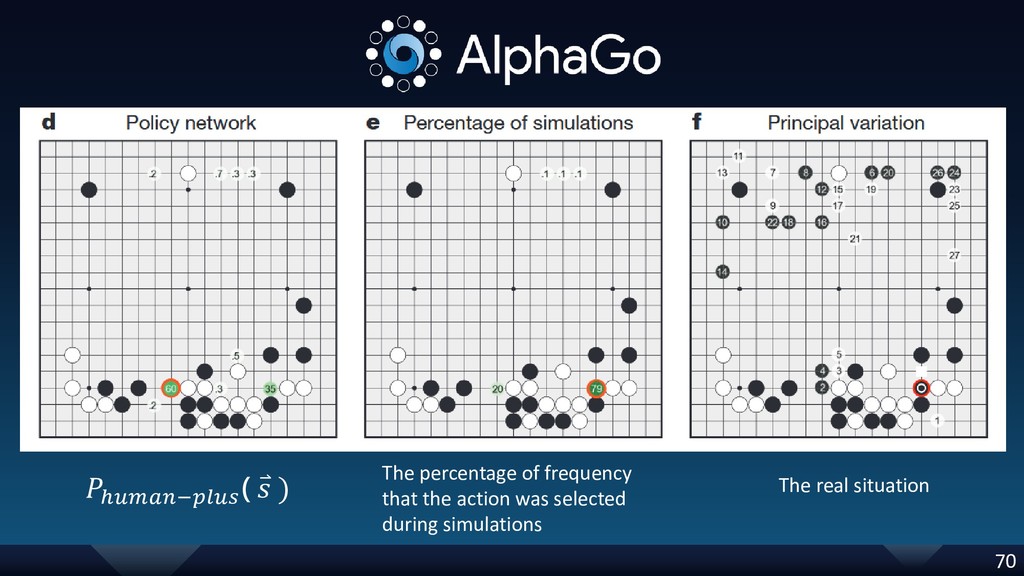{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
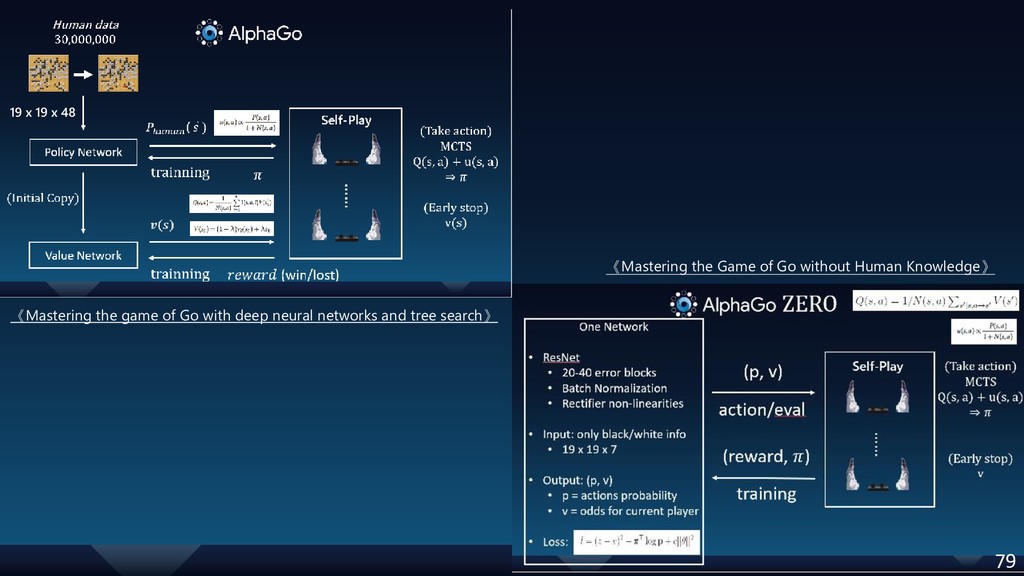{kind=link}
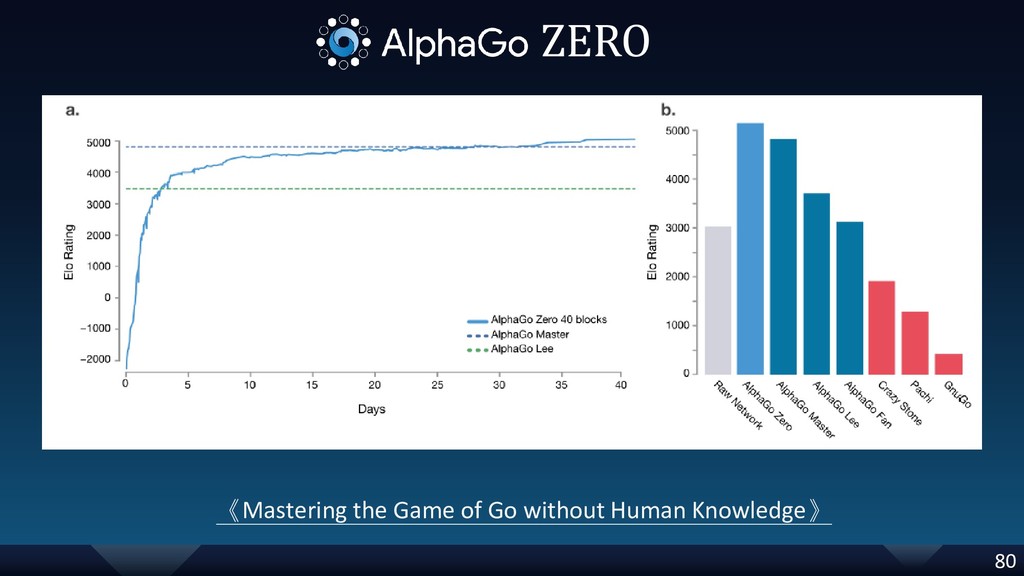{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
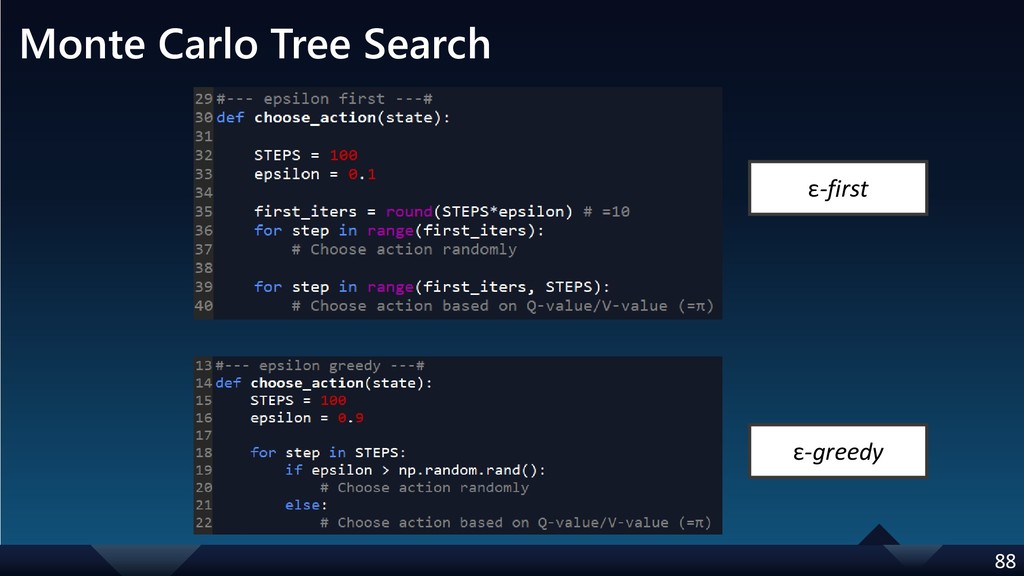{kind=link}
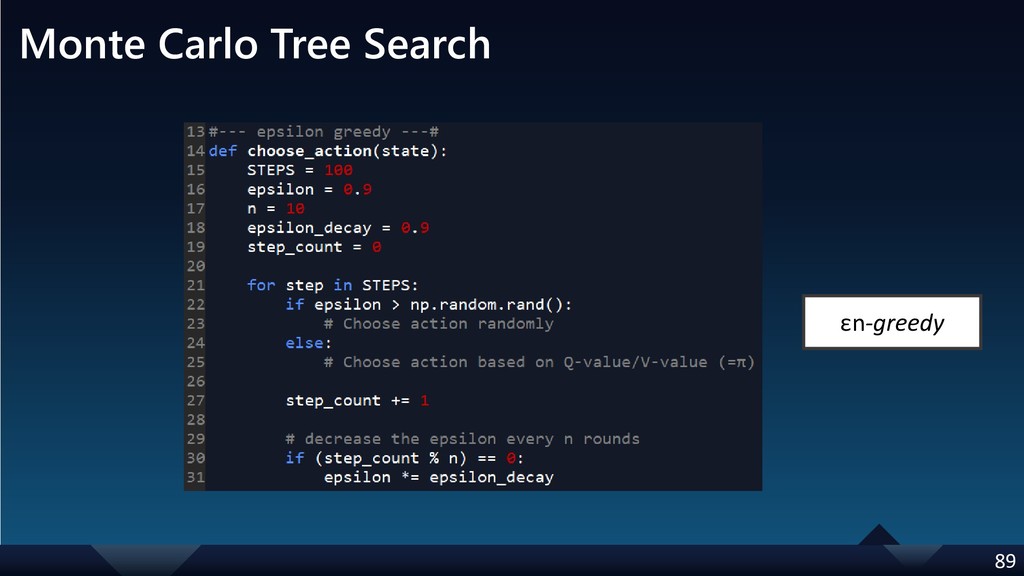{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}