and Graesser+’96] https://aima.eecs.berkeley.edu/slides-pdf/chapter02.pdf 人, ソフトウェア, ロボット, etc... 以下の性質について言及される場合もある [Wooldrige and Jennings+’95] 自律性 社会性 反応性 積極性 人間からの直接的な介入なしに動作し、自らの行動や内部状態を制御する。 他のエージェントや人間と相互作用する。 環境(物理世界, GUI, 他エージェントの集合体, インターネット, etc...)を感知し、変化に対し迅速に反応する。 単に環境に応じて行動するだけでなく、自ら進んで目標志向の行動を示す。 自律駆動型エージェント Russell et al., “Artificial Intelligence: A Modern Approach”, 1995 Wooldridge and Jennings, “Agent Theories, Architectures, and Languages: A Survey”, 1995 Franklin and Graesser, “Is it an Agent, or Just a Program?: A Taxonomy for Autonomous Agents”, 1996 対話型エージェント LLM ベースの AI エージェント Ryobot氏 - 対話モデルの訓練/評価フレームワーク ParlAI がすごい (2017) https://deeplearning.hatenablog.com/entry/parlai Lilian Weng氏 - LLM Powered Autonomous Agents (2023) https://lilianw eng.githu b.io/posts/2023-06-23- agent/ 環境内部に複数のエージェントが存在し、 各エージェントが テキ ストや報酬をやり取りする 観測と行動を繰り返して Miller et al., “ParlAI: A Dialog Research Software Platform”, 2017 与えられた指 示に対して LLM がタ スク遂行のための計画を立案し、 メモリやツールを使用しながら計画を実行する 9 様々な領域 で AIエージェント は発達してきた
m 評価基準の判定方法と判定の性能は m 他に考慮すべき指標はない m ベースラインと比較してどうすごいの m 実際のプロダクト環境における 2% の影響は m 精度は長期的にどう変化していくことが望ましい m 70%, 80%, ..., 100% で業務がどう改善される m 評価のコンセプトが変化する可能性は m etc... m どのような特徴を持つデータに対する精度なの m いつどのように取得したデータセット m 前処理としての整形プロセスは m どのようなデータ分布になっている m プロダクト環境とのデータ分布の違いはある m タスクの難易度は適切か m 時間とともにデータの品質はどう変わる m データ一件あたりどれくらい値が変化する m etc... 評価指標からのツッコミ データセットからのツッコミ そ の上、複数 のサブ タスク からなるエ ージェン ト軌跡をリリ ース 前 の段階 で評価しきるのはしんど い...
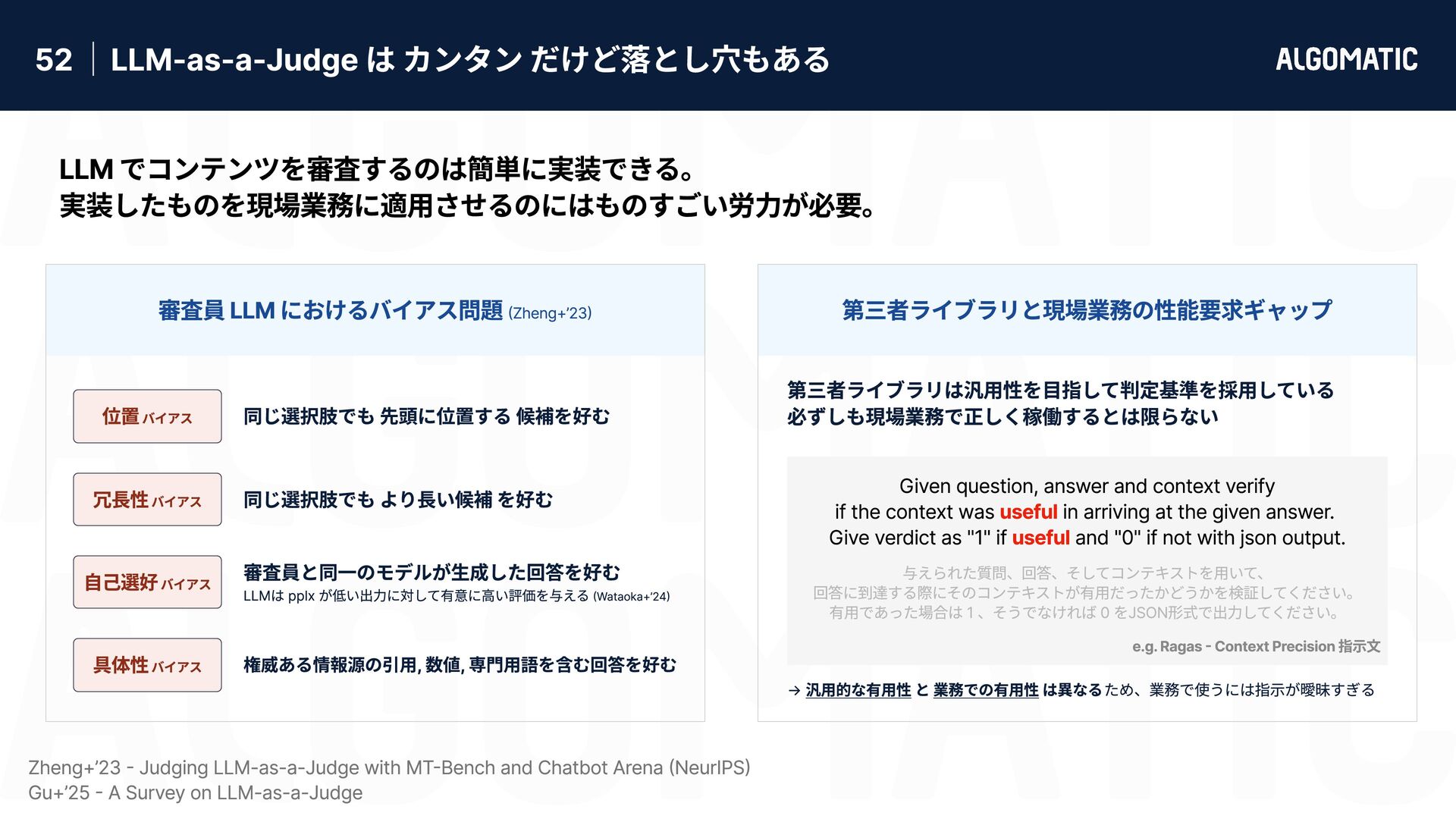
カンタン だけど落とし穴もある 審査員 LLM におけるバイアス問題 (Zheng+’23) 第三者ライブラリと現場業務の性能要求ギャップ 位置 バイアス 自己選好 バイアス 具体性 バイアス 冗長性 バイアス 同じ選択肢でも 先頭に位置する 候補を好む 同じ選択肢でも より長い候補 を好む 権威ある情報源の引用, 数値, 専門用語を含む回答を好む 審査員と同一のモデルが生成した回答を好む LLMは pplx が低い出力に対して有意に高い評価を与える (Wataoka+’24) 第三者ライブラリは汎用性を目指して判定基準を採用している 必ずしも現場業務で正しく稼働するとは限らない → 汎用的な有用性 と 業務での有用性 は異なる ため、業務で使うには指示が曖昧すぎる Zheng+’23 - Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena (NeurIPS) Gu+’25 - A Survey on LLM-as-a-Judge Given question, answer and context verify if the context was in arriving at the given answer. Give verdict as "1" if and "0" if not with json output. useful useful e.g. Ragas - Context Precision 指示文 LLM でコンテンツを審査するのは簡単に実装できる。 実装したものを現場業務に適用させるのにはものすごい労力が必要。
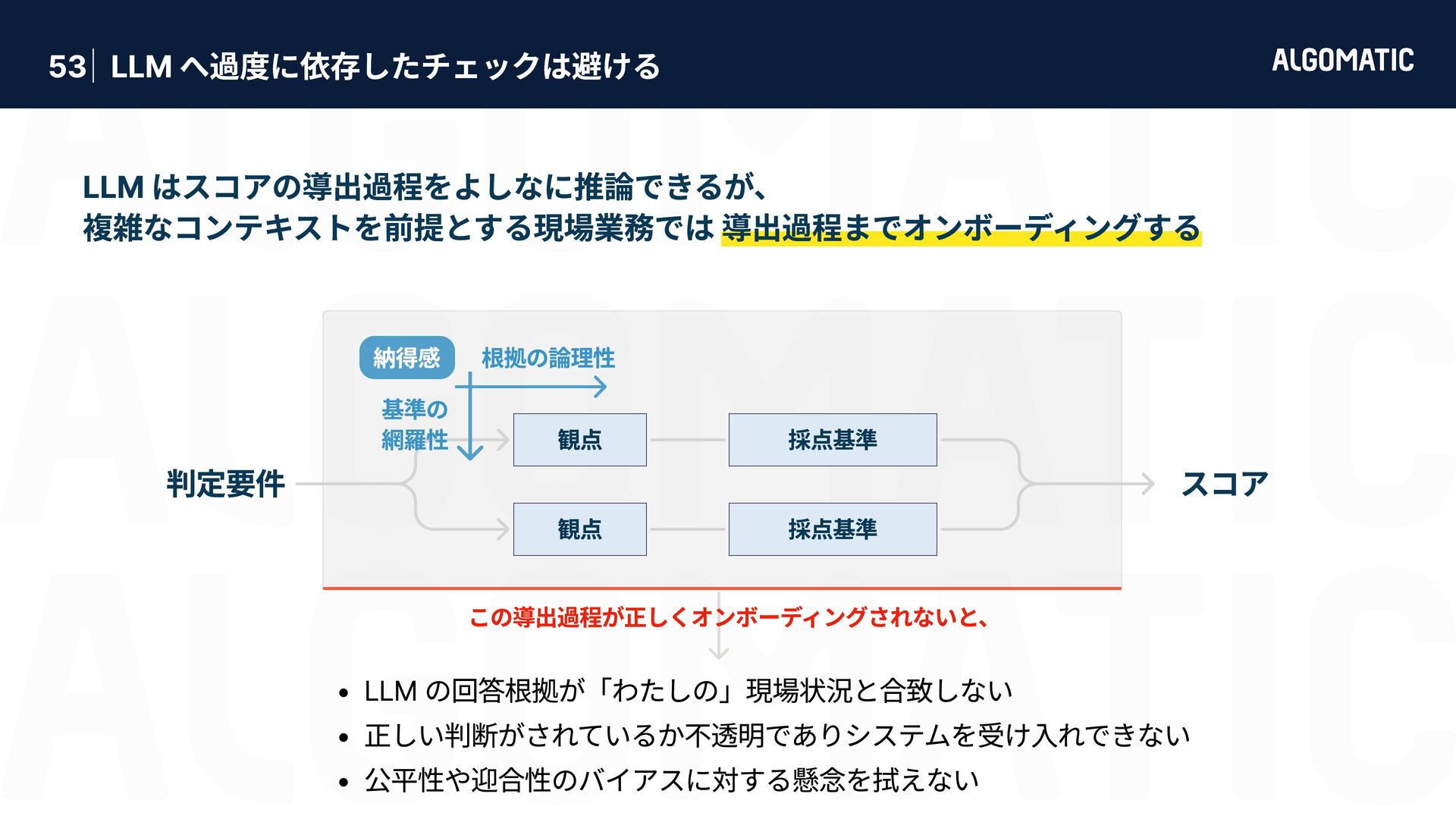
基準の 網羅性 納得感 h 公平性や迎合性のバイアスに対する懸念を拭えない h 正しい判断がされているか不透明でありシステムを受け入れできない h LLM の回答根拠が「わたしの」現場状況と合致しない この導出過程が正しくオンボーディングされないと、 LLM はスコアの導出過程をよしなに推論できるが、 複雑なコンテキストを前提とする現場業務では 導出過程までオンボーディングする
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![センサを通じて し、 アクチュエータによりその するもの [Russell+’95] 環境を認識 環境に作用 環境内に存在、環境の一部であり、その環境を知覚して、行動を決定するシステム。 時間をかけて目的を追求し、将来の環境に作用する [Franklin](https://files.speakerdeck.com/presentations/756aef0dd1bf40fea7bcfb1dd00105a5/slide_9.jpg){kind=link}
![AIエージェント ] [ エージェント型AI 10 『AIエージェント』と『エージェント型AI』は少し異なる 環境内に存在し 、環境を知覚し、環境に作用すa ](https://files.speakerdeck.com/presentations/756aef0dd1bf40fea7bcfb1dd00105a5/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}