TransformerをベースにしたDeep Learning Model • Attention Is All You Need (2017 Google) でTransformerが提案された • 大規模化&マルチモーダル化のトレンド • e.g. ◦ Open AI:GPT-4 ◦ Google:Gemini,Gemma ◦ Anthropic:Claude3 https://arxiv.org/abs/1706.03762 https://speakerdeck.com/pfn/llmnoxian-zai
◦ Gemini for xxx ▪ Workspaces ▪ Google Cloud ◦ Microsoft Copilot ◦ GitHub Copilot ◦ Slack AI https://slack.com/intl/ja-jp/blog/news/slack-ai-has-arrived
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
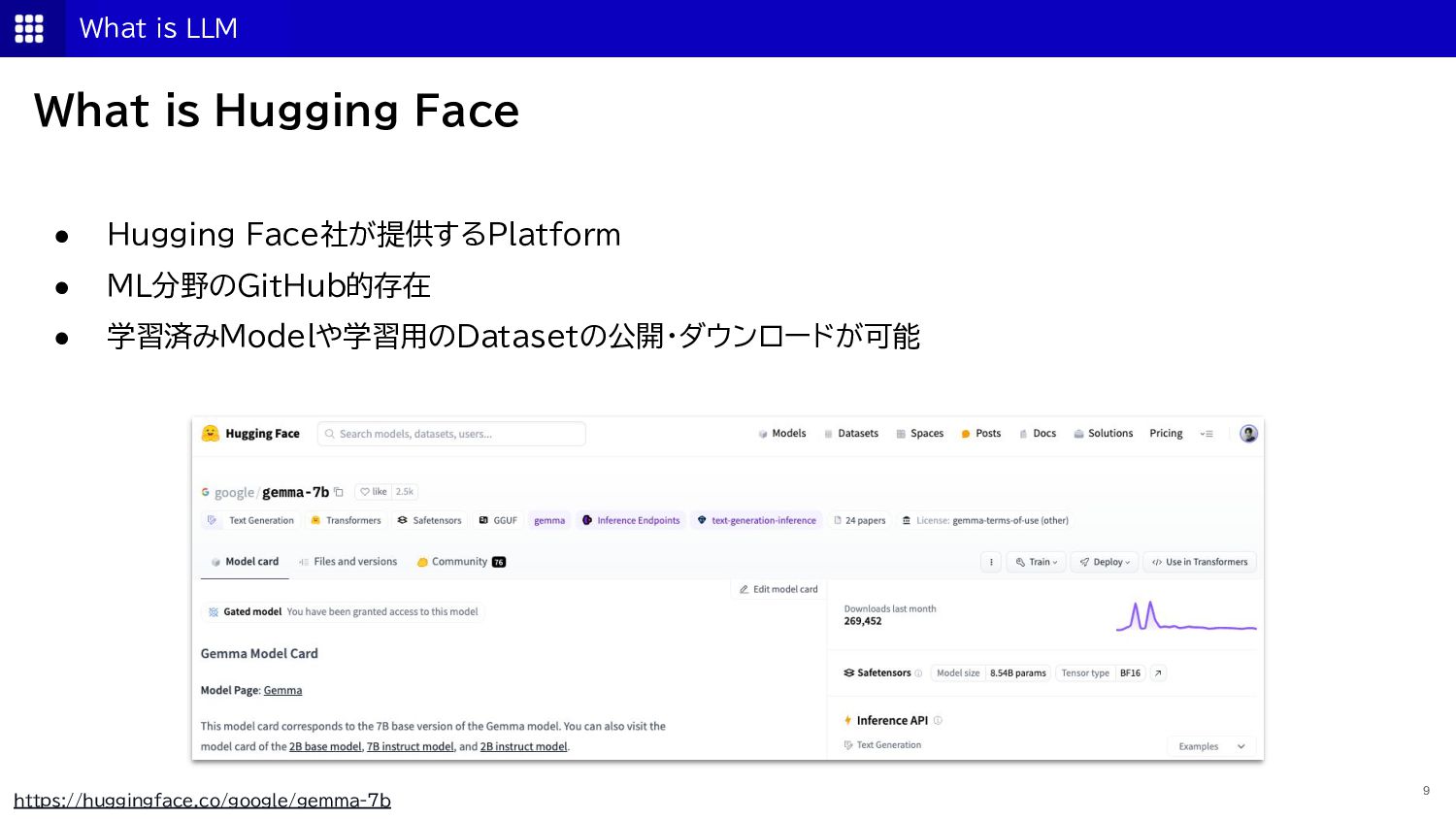{kind=link}
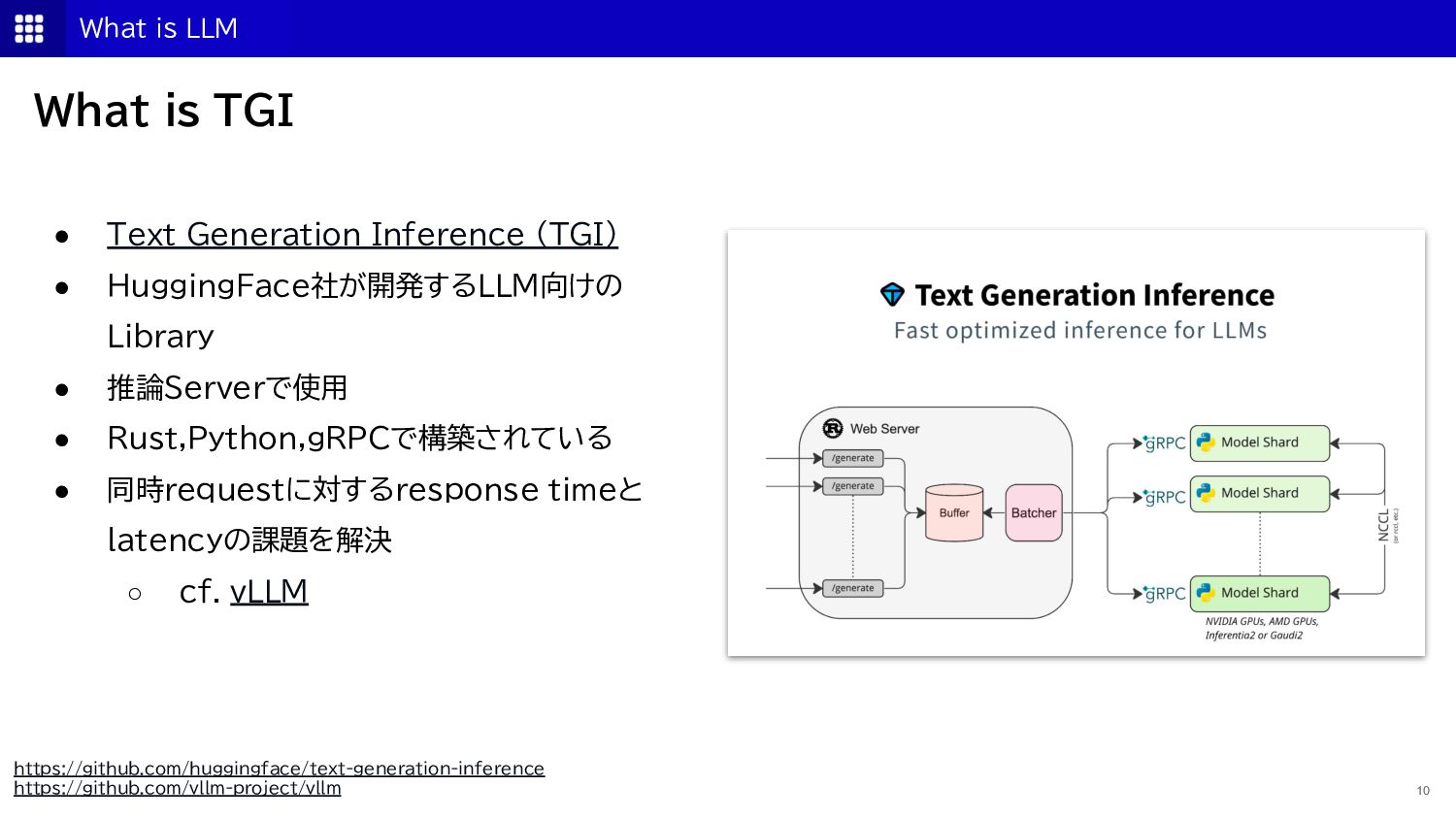{kind=link}
{kind=link}
{kind=link}
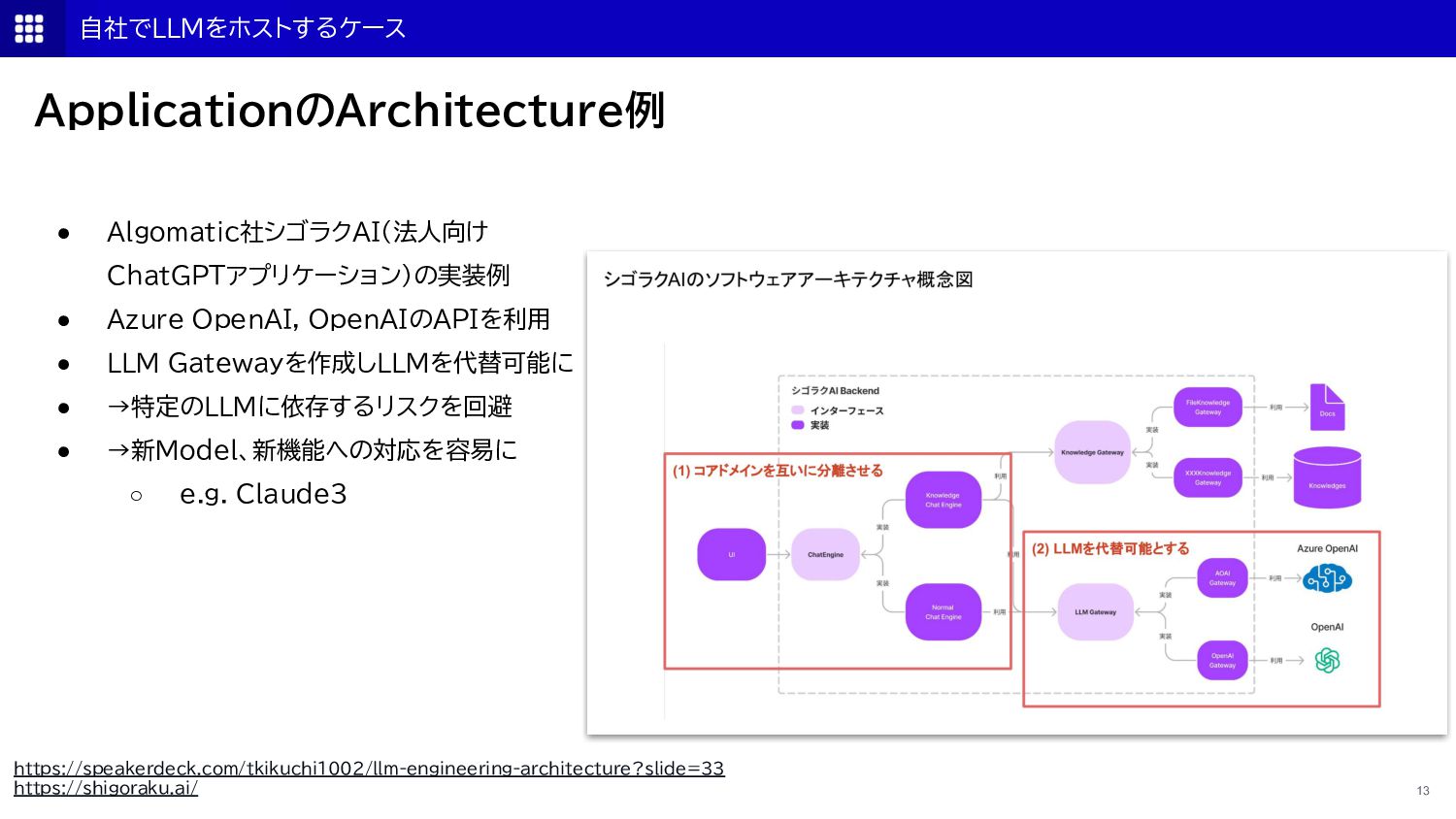{kind=link}
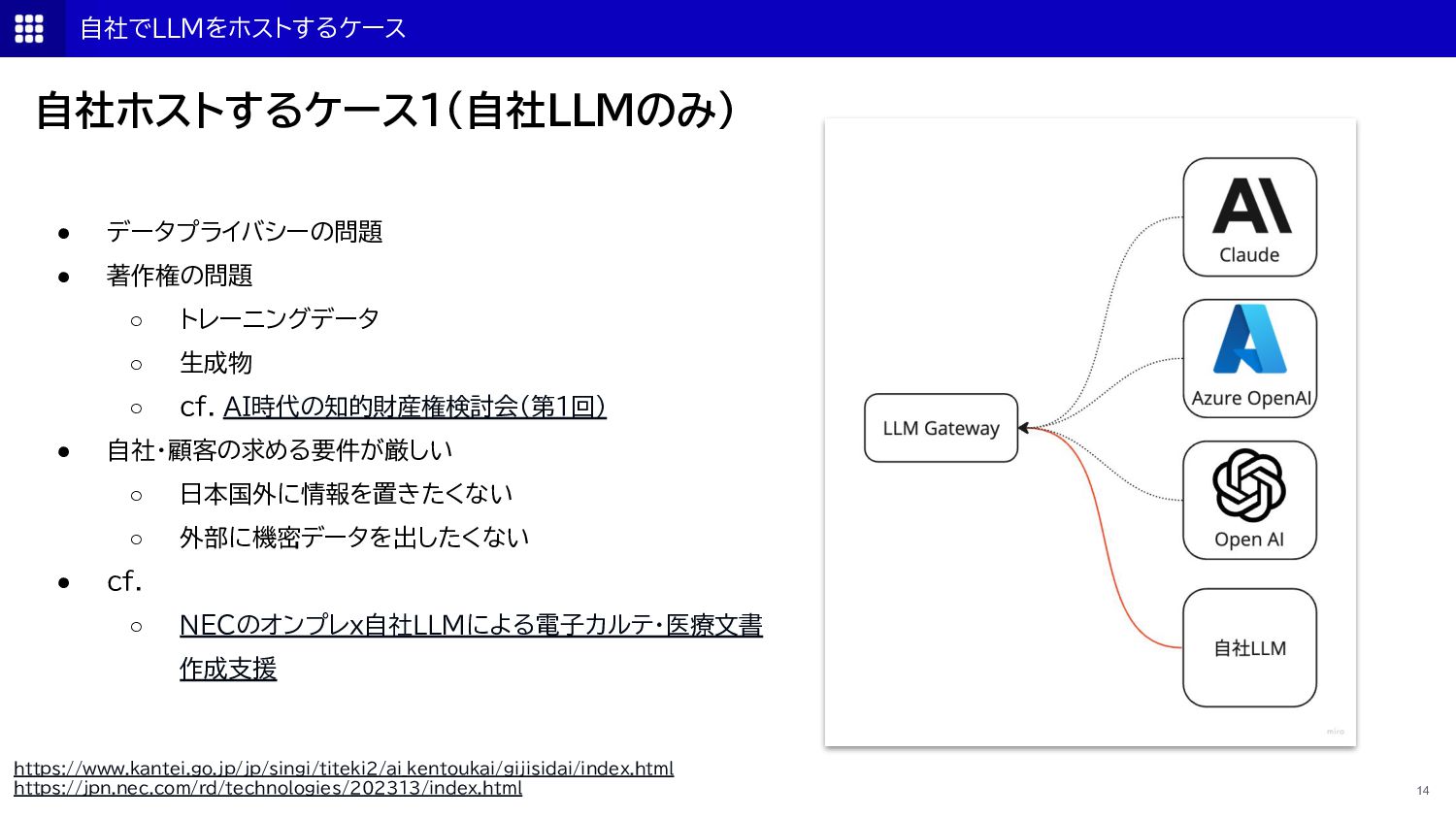{kind=link}
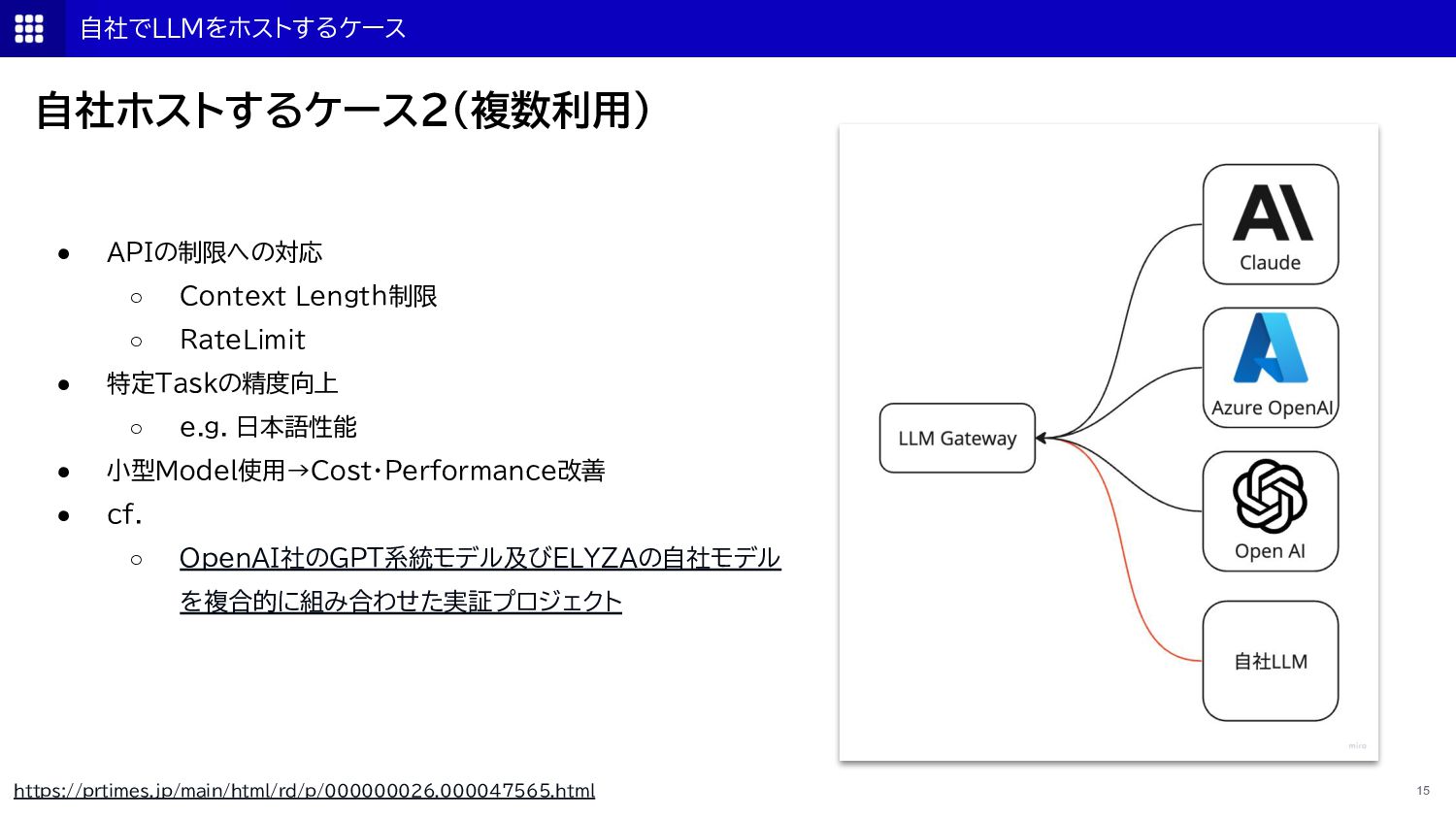{kind=link}
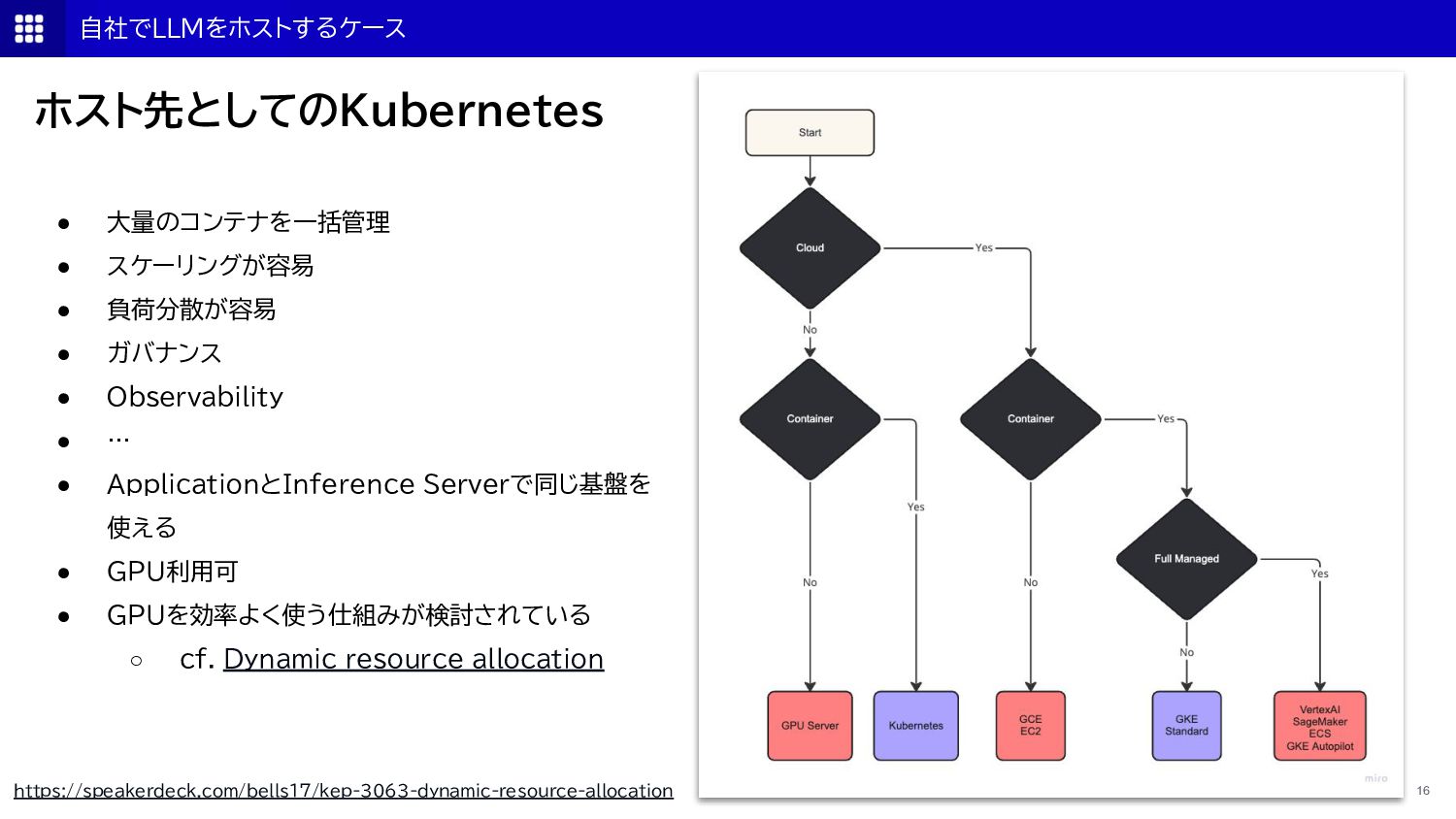{kind=link}
{kind=link}
{kind=link}
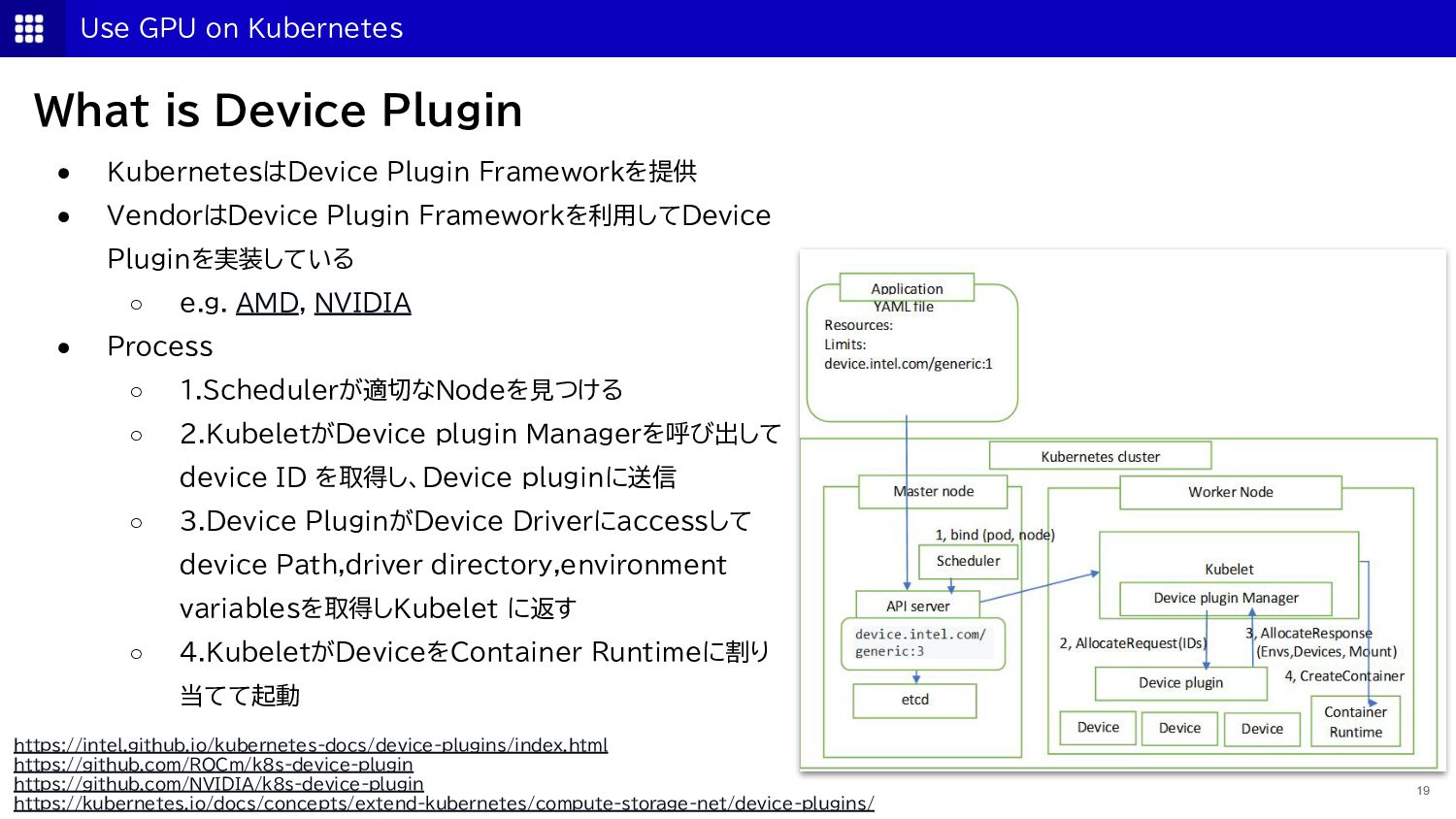{kind=link}
{kind=link}
{kind=link}
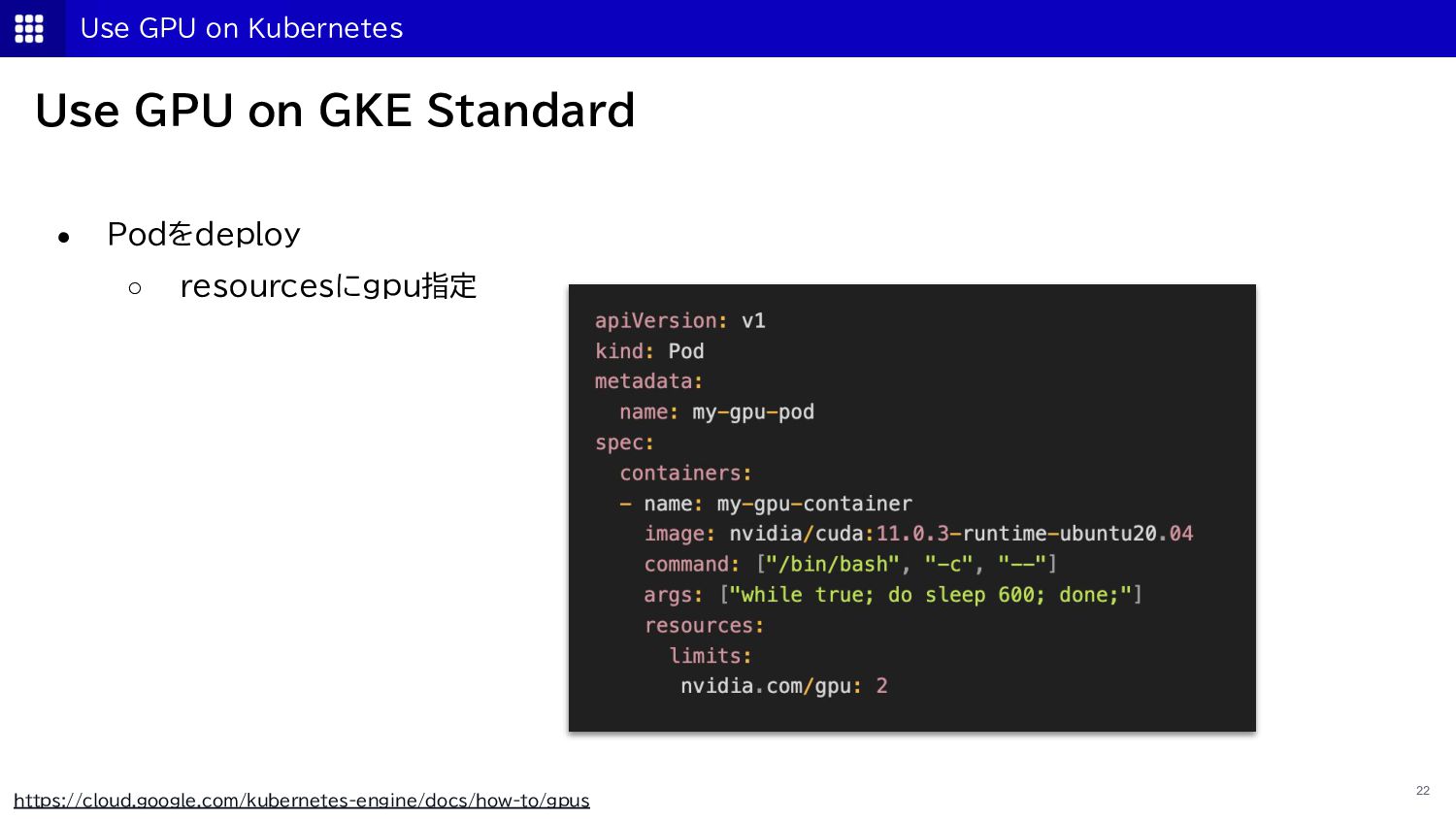{kind=link}
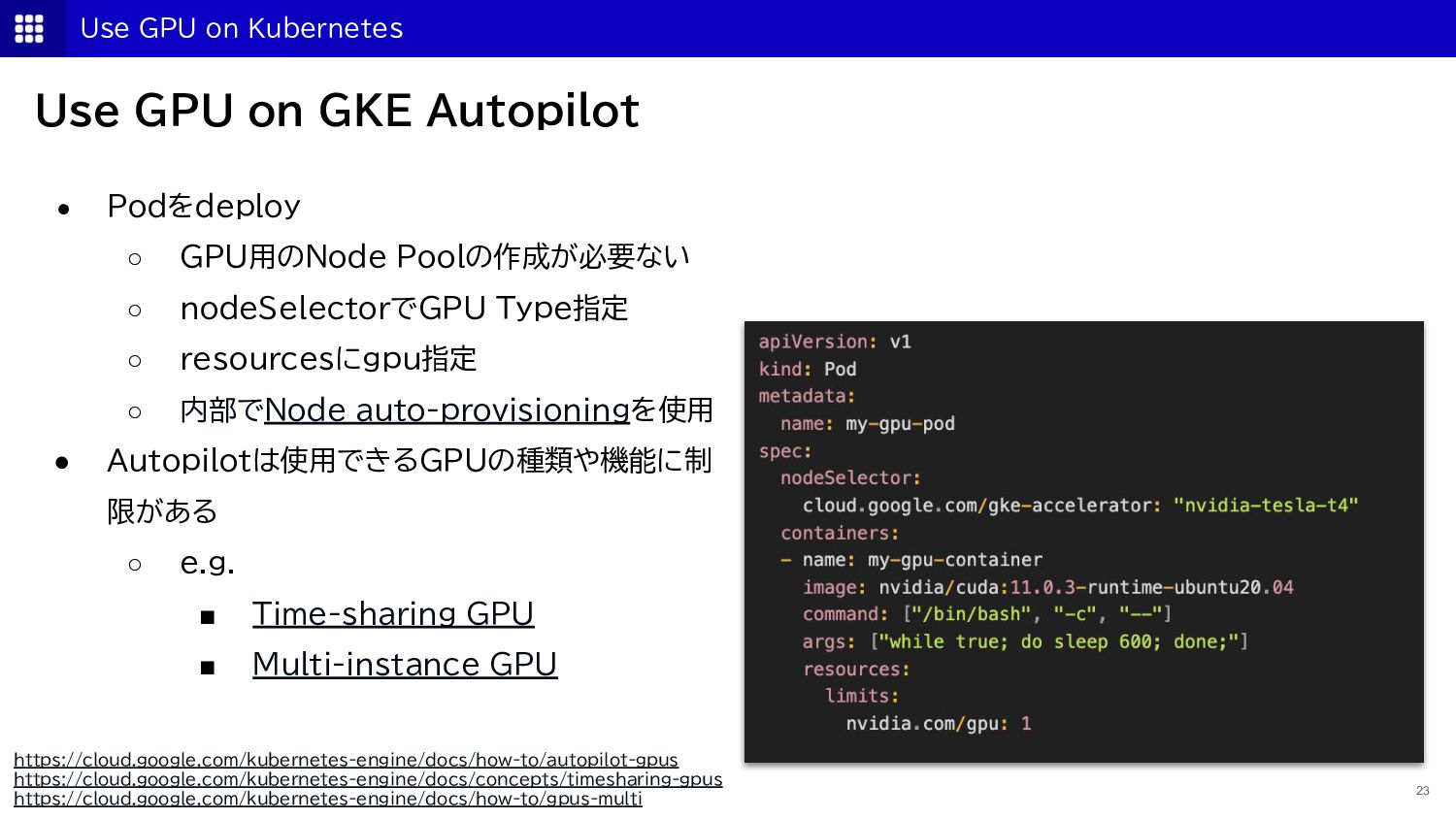{kind=link}
{kind=link}
{kind=link}
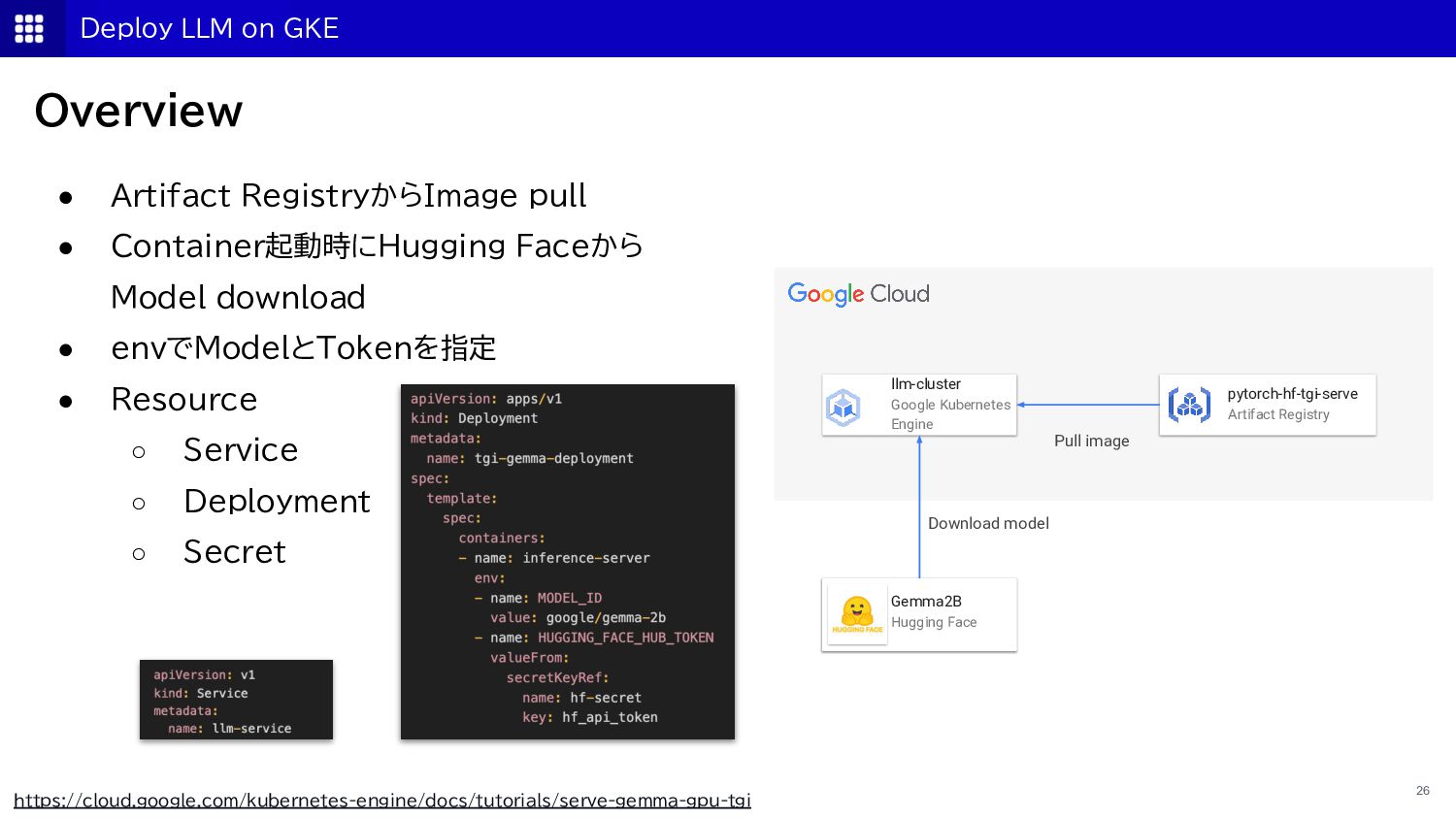{kind=link}
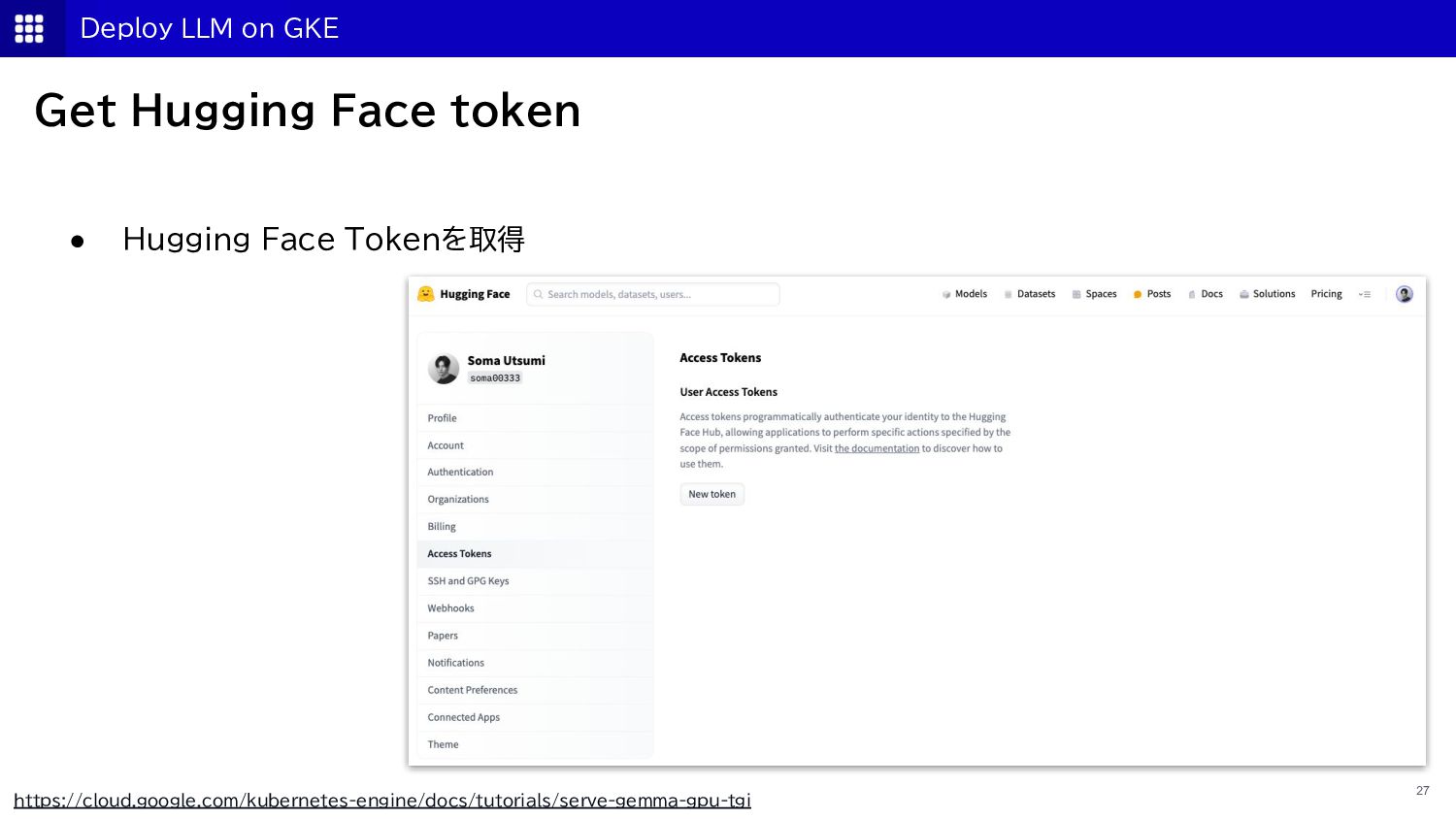{kind=link}
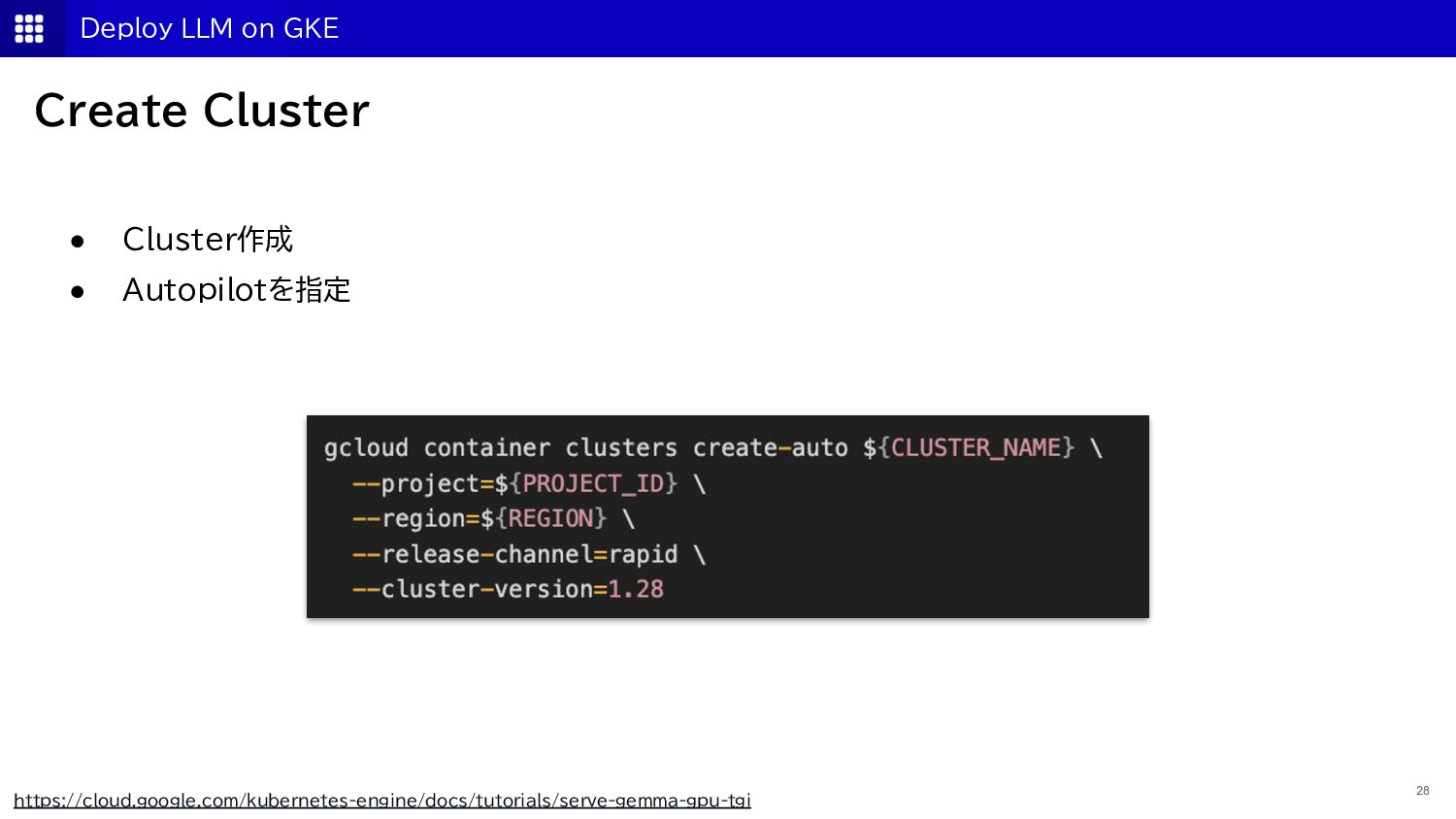{kind=link}
{kind=link}
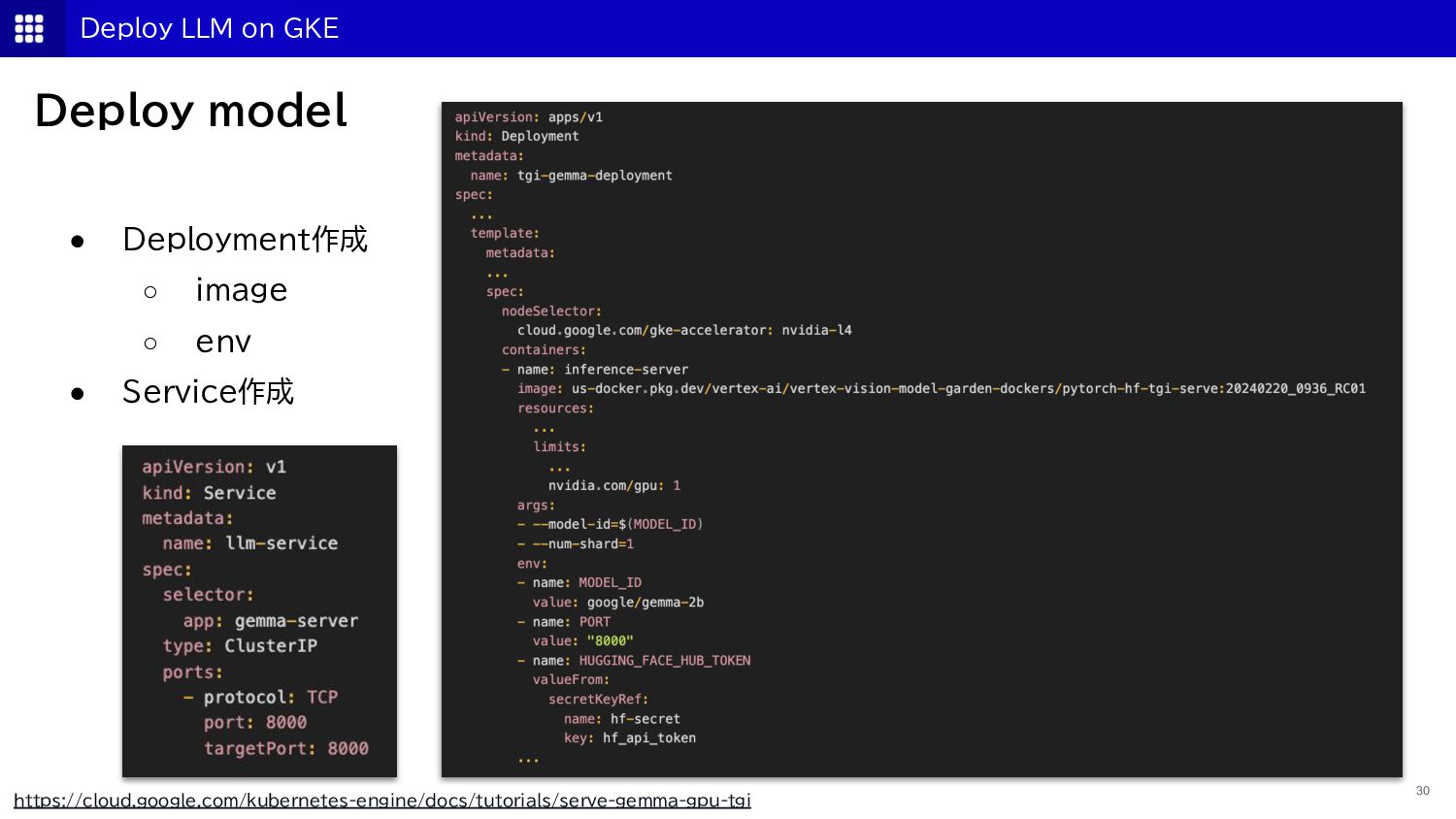{kind=link}
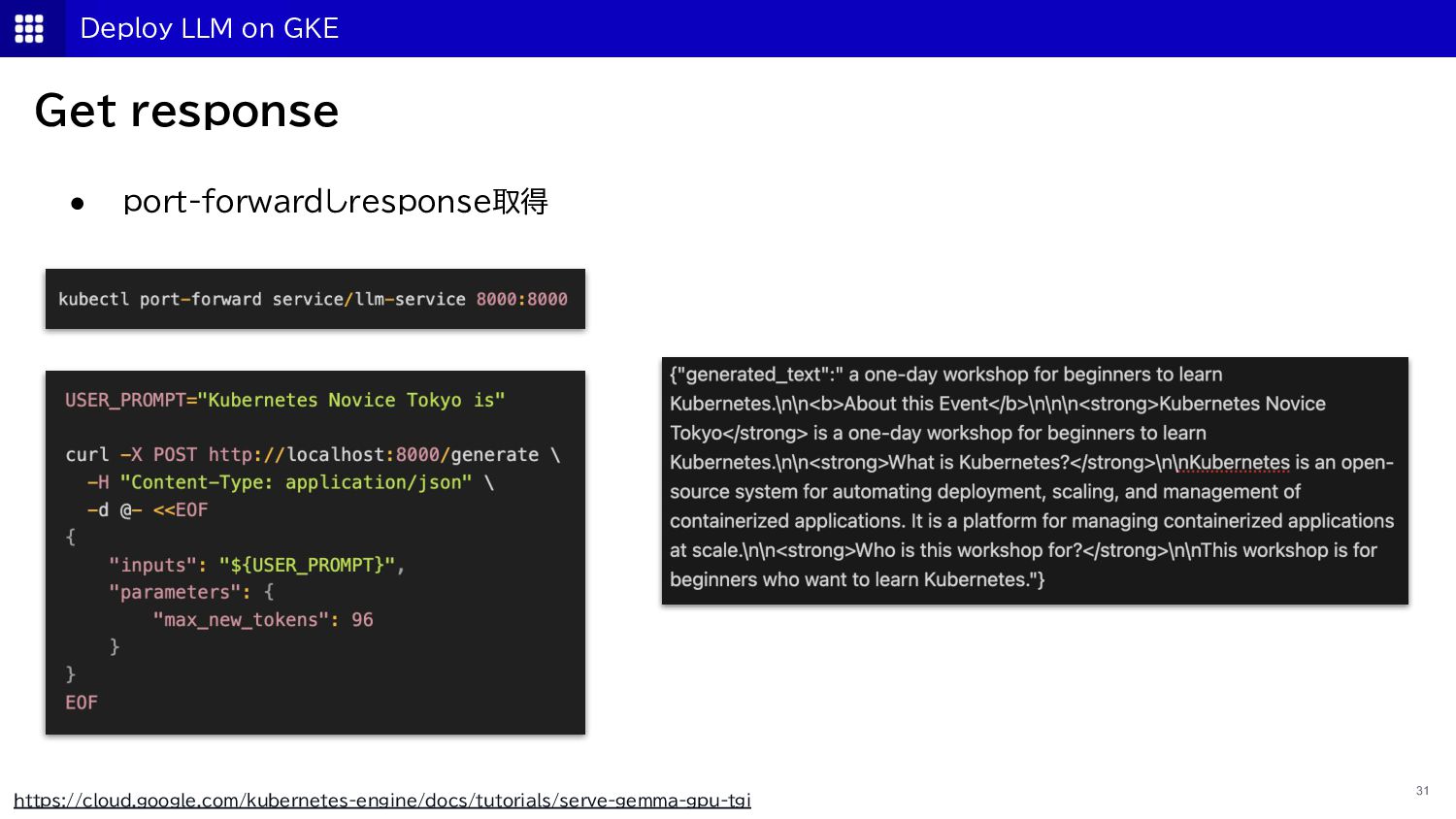{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}