Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Continuous 3D Perception Model with Persistent ...
Search
Spatial AI Network
June 02, 2025
Technology
1
130
Continuous 3D Perception Model with Persistent State
新しい入力画像が観測される度に更新する三次元再構成のフレームワーク(CUT3R)
Spatial AI Network
June 02, 2025
Tweet
Share
More Decks by Spatial AI Network
See All by Spatial AI Network
GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
spatial_ai_network
0
71
High-Fidelity Lightweight Mesh Reconstruction from Point Clouds [CVPR 2025]
spatial_ai_network
1
120
Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
spatial_ai_network
0
140
Variational Surface Reconstruction Using Natural Neighbors (SIGGRAPH 2025)
spatial_ai_network
0
150
Matrix-Free Shared Intrinsics Bundle Adjustment (CVPR 2025)
spatial_ai_network
0
240
3D Gaussian Splattingにおける派生プリミティブの設計
spatial_ai_network
0
480
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models (CVPR2025 Best Paper Award Candidate)
spatial_ai_network
0
170
Vision-based 3D reconstruction for navigation and characterization of unknown, space-borne targets
spatial_ai_network
0
80
光学・物理原理に基づく深層画像生成
spatial_ai_network
2
530
Other Decks in Technology
See All in Technology
ソースを読む時の思考プロセスの例-MkDocs
sat
PRO
1
330
Okta Identity Governanceで実現する最小権限の原則
demaecan
0
200
20251027_findyさん_音声エージェントLT
almondo_event
2
500
Azure Well-Architected Framework入門
tomokusaba
1
140
AIの個性を理解し、指揮する
shoota
3
480
プロファイルとAIエージェントによる効率的なデバッグ / Effective debugging with profiler and AI assistant
ymotongpoo
1
550
ざっくり学ぶ 『エンジニアリングリーダー 技術組織を育てるリーダーシップと セルフマネジメント』 / 50 minute Engineering Leader
iwashi86
6
3.4k
AI連携の新常識! 話題のMCPをはじめて学ぶ!
makoakiba
0
160
AIがコードを書いてくれるなら、新米エンジニアは何をする? / komekaigi2025
nkzn
1
300
入院医療費算定業務をAIで支援する:包括医療費支払い制度とDPCコーディング (公開版)
hagino3000
0
120
Dify on AWS 環境構築手順
yosse95ai
0
170
GPUをつかってベクトル検索を 扱う手法のお話し ~NVIDIA cuVSとCAGRA~
fshuhe
0
270
Featured
See All Featured
Speed Design
sergeychernyshev
32
1.2k
Java REST API Framework Comparison - PWX 2021
mraible
34
8.9k
Designing Experiences People Love
moore
142
24k
Code Review Best Practice
trishagee
72
19k
The Power of CSS Pseudo Elements
geoffreycrofte
80
6k
Producing Creativity
orderedlist
PRO
348
40k
Designing for humans not robots
tammielis
254
26k
How to Think Like a Performance Engineer
csswizardry
27
2.2k
Why Our Code Smells
bkeepers
PRO
340
57k
Become a Pro
speakerdeck
PRO
29
5.6k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
GraphQLの誤解/rethinking-graphql
sonatard
73
11k
Transcript
Continuous 3D Perception Model with Persistent State Qianqian Wang1,2∗, Yifei
Zhang1∗, Aleksander Holynski1,2, Alexei A. Efros1, Angjoo Kanazawa1 1University of California, Berkeley 2Google DeepMind CVPR 2025 (Oral) 2025/5/27 Spatial AI Network 勉強会 (株)サイバーエージェント 片桐 敬太
論文情報 Project page:https://cut3r.github.io/ 論文(arXiv):https://arxiv.org/abs/2501.12387 コード(GitHub):https://github.com/CUT3R/CUT3R ※以下、本論文の画像を引用 論文選定のモチベーション 3DGSをビジネス活用している立場で”社会実装”にフォーカスして論文を選定
概要 CUT3R: Continuous Updating Transformer for 3D Reconstruction 新しい入力画像が観測される度に更新する三次元再構成のフレームワーク 入力: 動画、画像群(順不同) 出力: 静的・動的な三次元空間(三次元点群)、カメラの内部・外部パラメータ
背景 タブラ・ラサ(白紙状態)からの再構成 SfMやSLAMはゼロから再構成する必要があり、動的シーンに対応困難 学習ベースの再構成 少ない画像ペアからの再構成DUSt3Rなどは静的シーンに特化 人間の視覚認知に基づくアプローチ ・人間は過去の知識を活用し、継続的に新しい観測から学習 ・少ない情報から3Dの世界を解釈し、観測が増えるにつれて精緻化 ・観測していない領域も推論
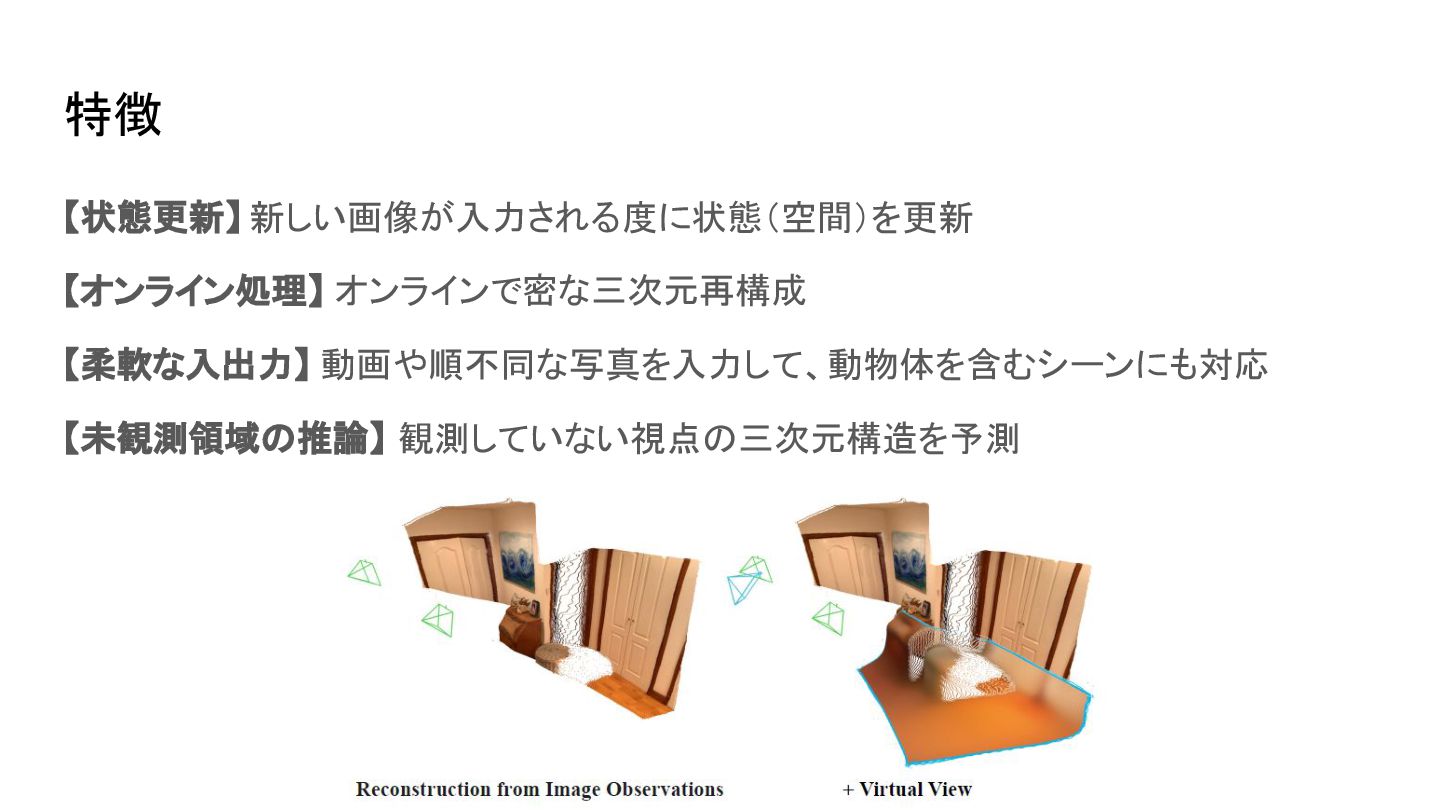
特徴 【状態更新】 新しい画像が入力される度に状態(空間)を更新 【オンライン処理】 オンラインで密な三次元再構成 【柔軟な入出力】 動画や順不同な写真を入力して、動物体を含むシーンにも対応 【未観測領域の推論】 観測していない視点の三次元構造を予測
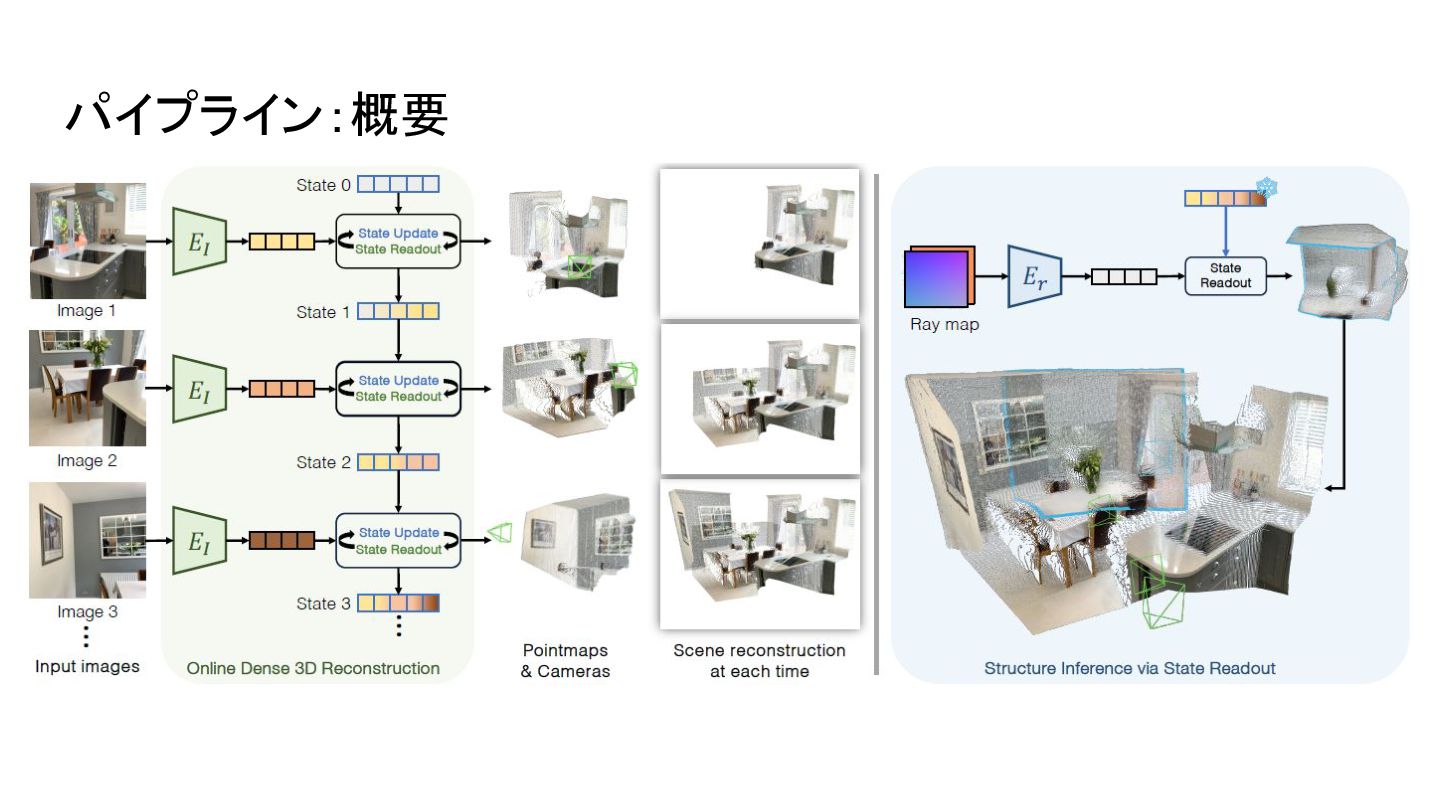
パイプライン:概要
パイプライン:入力からの状態更新&読み出し ・各入力画像はViTエンコーダで画像トークンに変換 ・状態トークンは現在の3Dシーンの情報を保持 ・入力の画像トークンは相互接続されたViTデコーダにより 状態トークンと相互作用 ・State Update: 現在の画像情報を状態に統合 ・State Readout: 状態に保存された過去の状態を読み 出して予測に利用
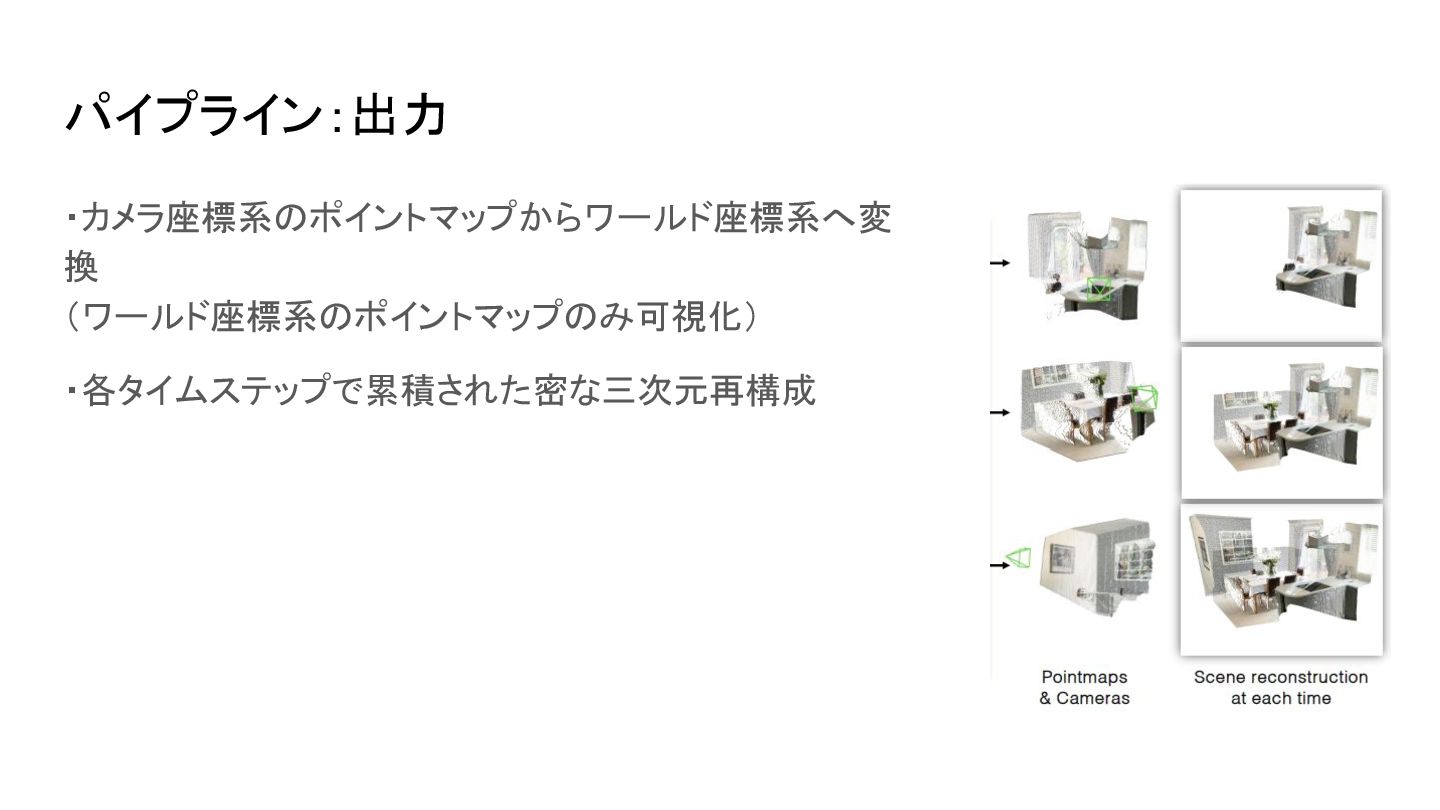
パイプライン:出力 ・カメラ座標系のポイントマップからワールド座標系へ変 換 (ワールド座標系のポイントマップのみ可視化) ・各タイムステップで累積された密な三次元再構成
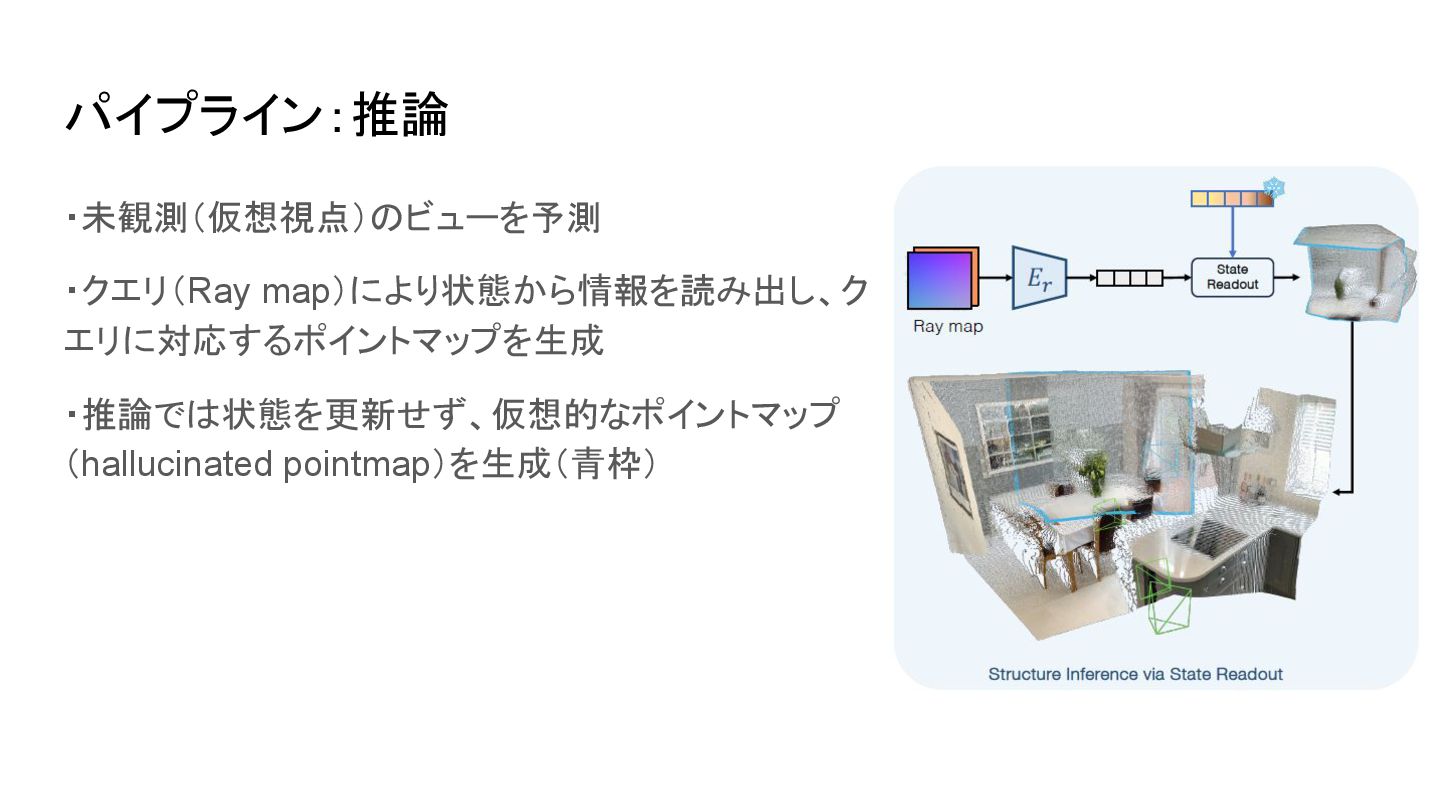
パイプライン:推論 ・未観測(仮想視点)のビューを予測 ・クエリ(Ray map)により状態から情報を読み出し、ク エリに対応するポイントマップを生成 ・推論では状態を更新せず、仮想的なポイントマップ (hallucinated pointmap)を生成(青枠)
提案手法:State-Input Interaction Mechanism ・状態の更新と読み出しは式(2)のCross-Attentionで相互作用 状態更新: 現在の画像情報から状態を更新 状態読み出し: 過去の情報を状態から読み出す 画像トークンと相互作用す る前後の状態トークン カメラのポーズトークン ViTによる画像トークン
状態に基づくカメラの ポーズトークン 状態に基づく画像トークン 入力画像
提案手法:State-Input Interaction Mechanism ・相互作用後にペアの入力画像から3D表現(ポイントマップ)を抽出 ・新たな観測により不確かだった領域の信頼度は向上していく DPT (Dense Prediction Transformer)で実装 MLPで実装
世界座標系の 位置姿勢(剛体) ポイントマップ ポイントマップに対応す る信頼度マップ
提案手法:Querying the State with Unseen Views ・仮想視点の内部・外部パラを各ピクセルの光線の原点と方向をエンコードしたレイマッ プで表現 ・レイマップはクエリとしてのみ機能して状態は更新されない クエリカメラのレイマップ
レイマップのトークン レイマップの各光線の色 式(2)と同様に状態を読 み込んだトークン
提案手法:Training Objective ・L_conf: MASt3Rによるポイントマップに信頼度cを考慮した回帰損失を適用 ・L_pose: カメラポーズを四元数qと並進τとして、予測と真値のL2ノルムを最小化 ・L_rgb: 色Iの予測と真値を一致させるMSE損失も適用 低い信頼度の学習を防止 レイマップが入力さ れる場合に適用 三次元構造の予測 カメラポーズの予測
光線の色を予測
提案手法:Training Strategy 【学習データ】 ・合成と実世界、静的と動的、空間と物体、屋内と屋外をカバーした32のデータセット ・静的シーンでは4ビューシーケンス(224×224) ・動的シーンと部分的なアノテーション(カメラポーズ...)も組込み ・様々な解像度(最大幅:512)とアスペクト比
提案手法:Training Strategy 【実装】 ・画像エンコーダにはViT-Largeモデルを使用 ・DUSt3Rの学習済みの重みで初期化 ・デコーダにはViT-Baseを使用 ・エンコーダとデコーダは16×16ピクセルのパッチで動作 ・状態は768次元の768トークンで構成 ・レイマップエンコーダは2ブロックの軽量エンコーダ ・初期学習率1e-4のAdam-Wオプティマイザを使用
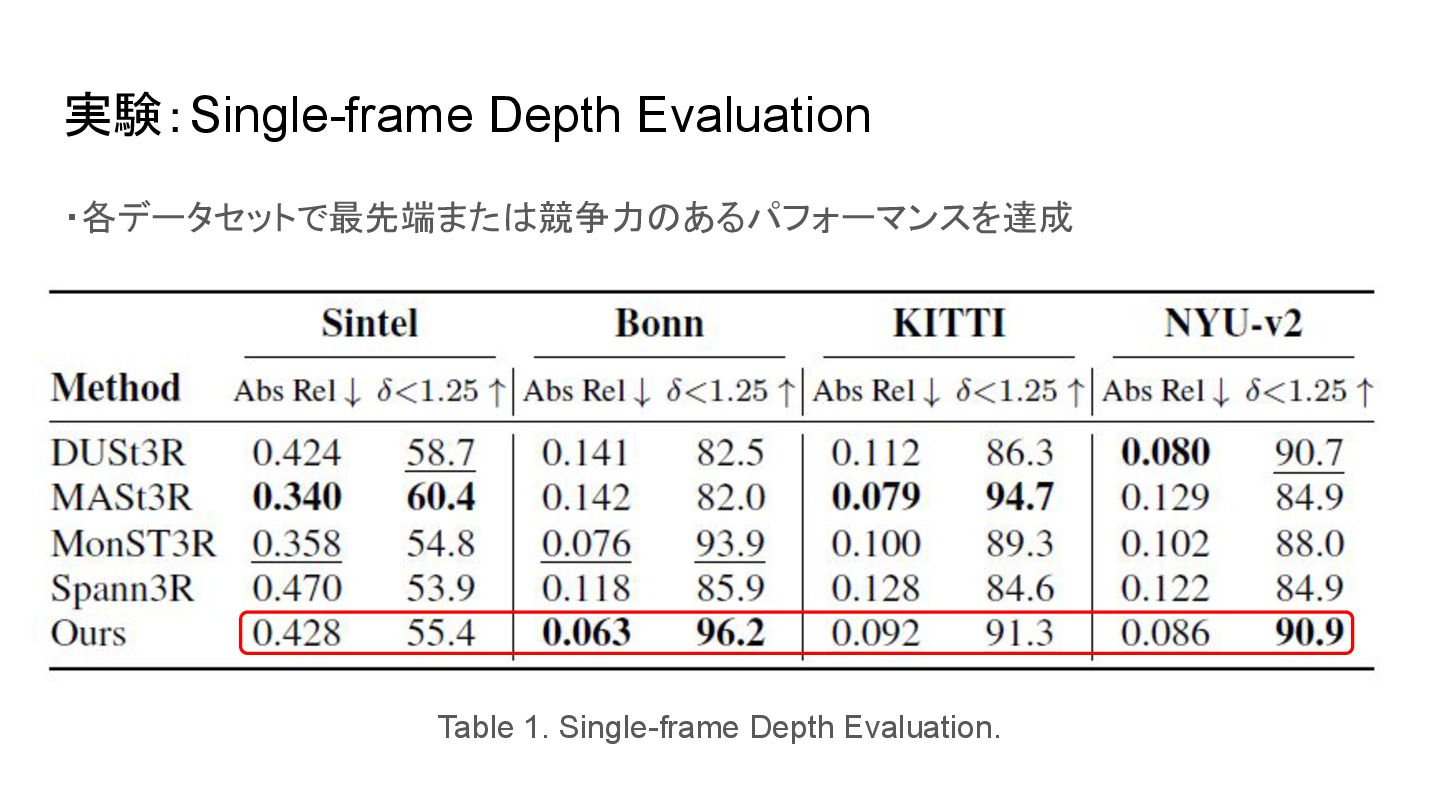
実験:Single-frame Depth Evaluation ・各データセットで最先端または競争力のあるパフォーマンスを達成 Table 1. Single-frame Depth Evaluation.
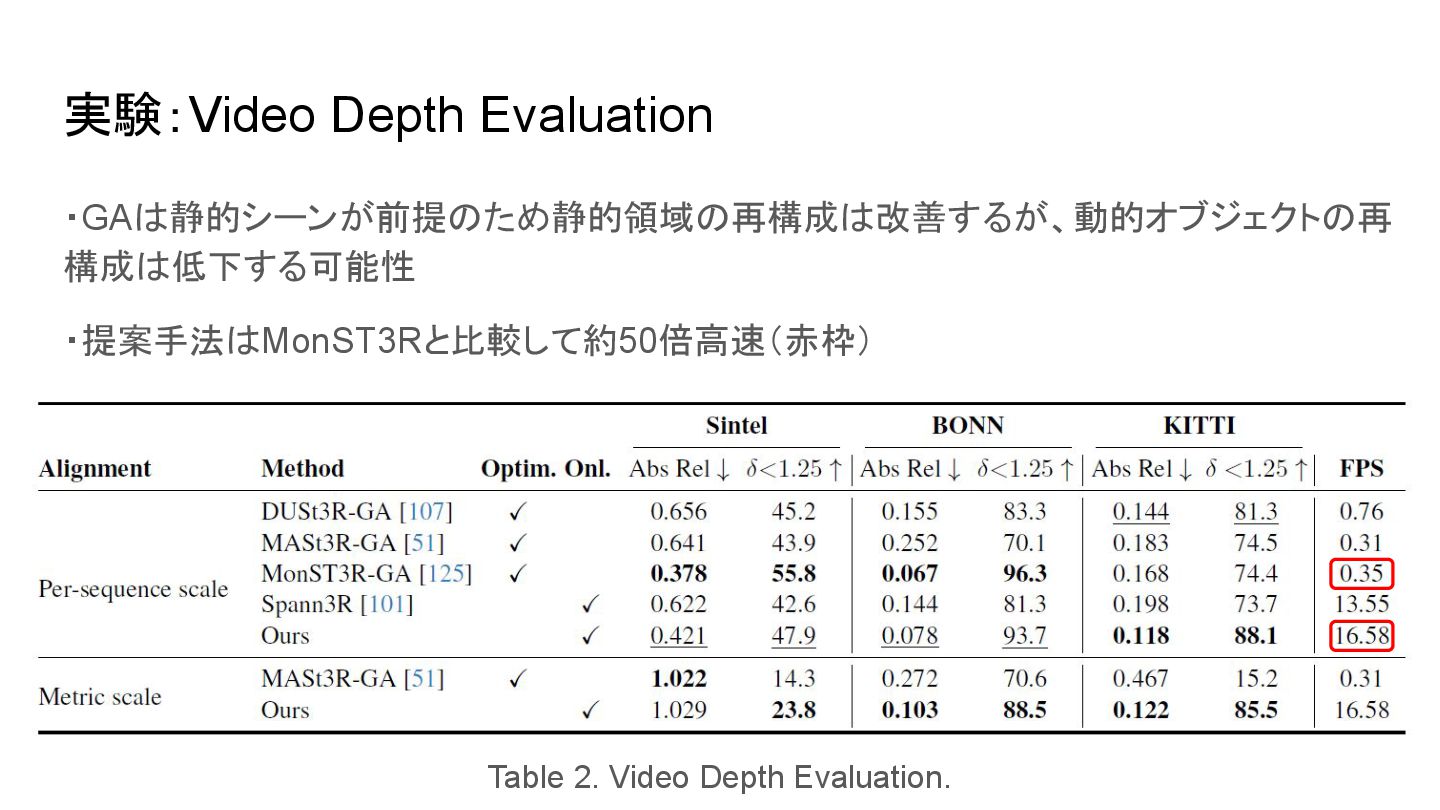
実験:Video Depth Evaluation ・GAは静的シーンが前提のため静的領域の再構成は改善するが、動的オブジェクトの再 構成は低下する可能性 ・提案手法はMonST3Rと比較して約50倍高速(赤枠) Table 2. Video Depth
Evaluation.
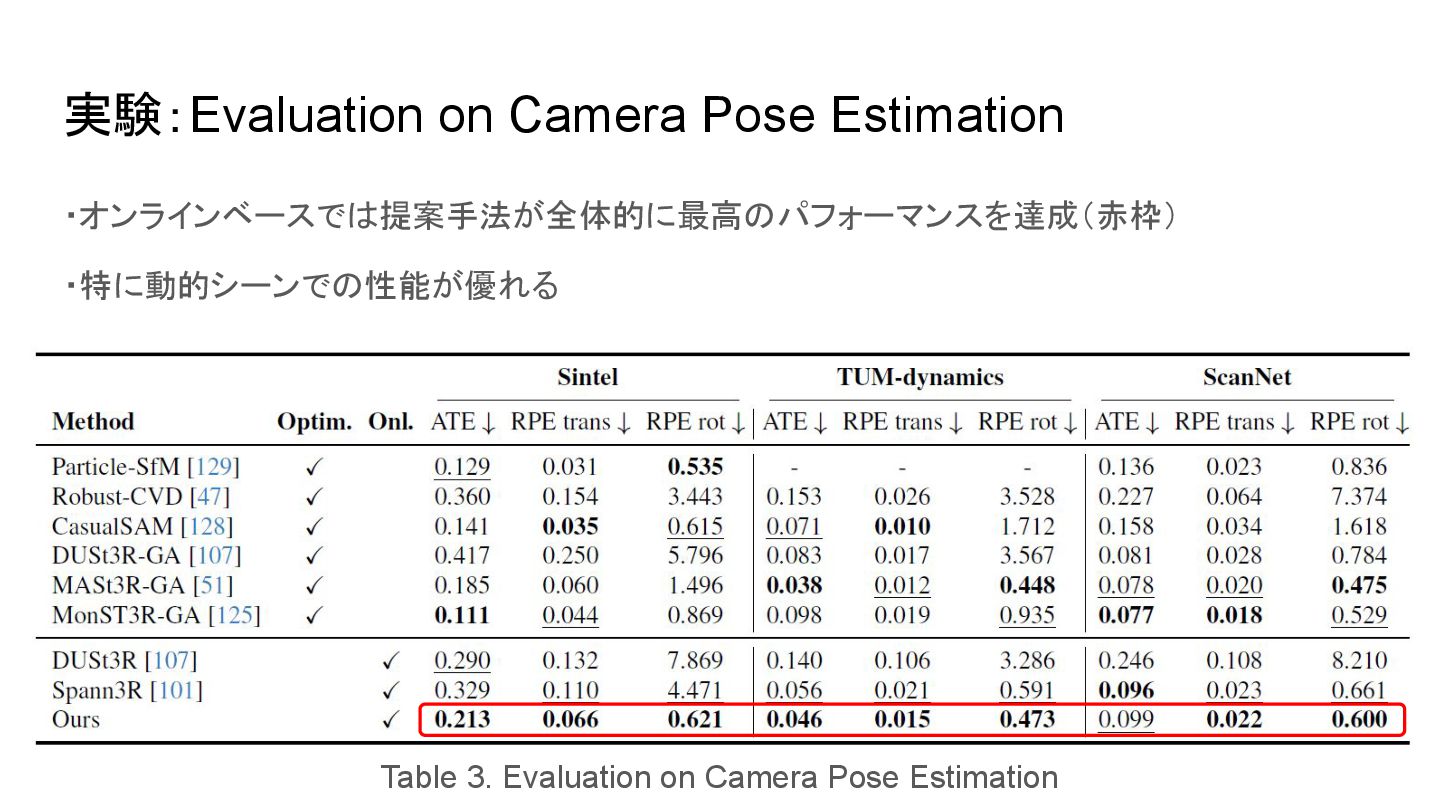
実験:Evaluation on Camera Pose Estimation ・オンラインベースでは提案手法が全体的に最高のパフォーマンスを達成(赤枠) ・特に動的シーンでの性能が優れる Table 3. Evaluation
on Camera Pose Estimation
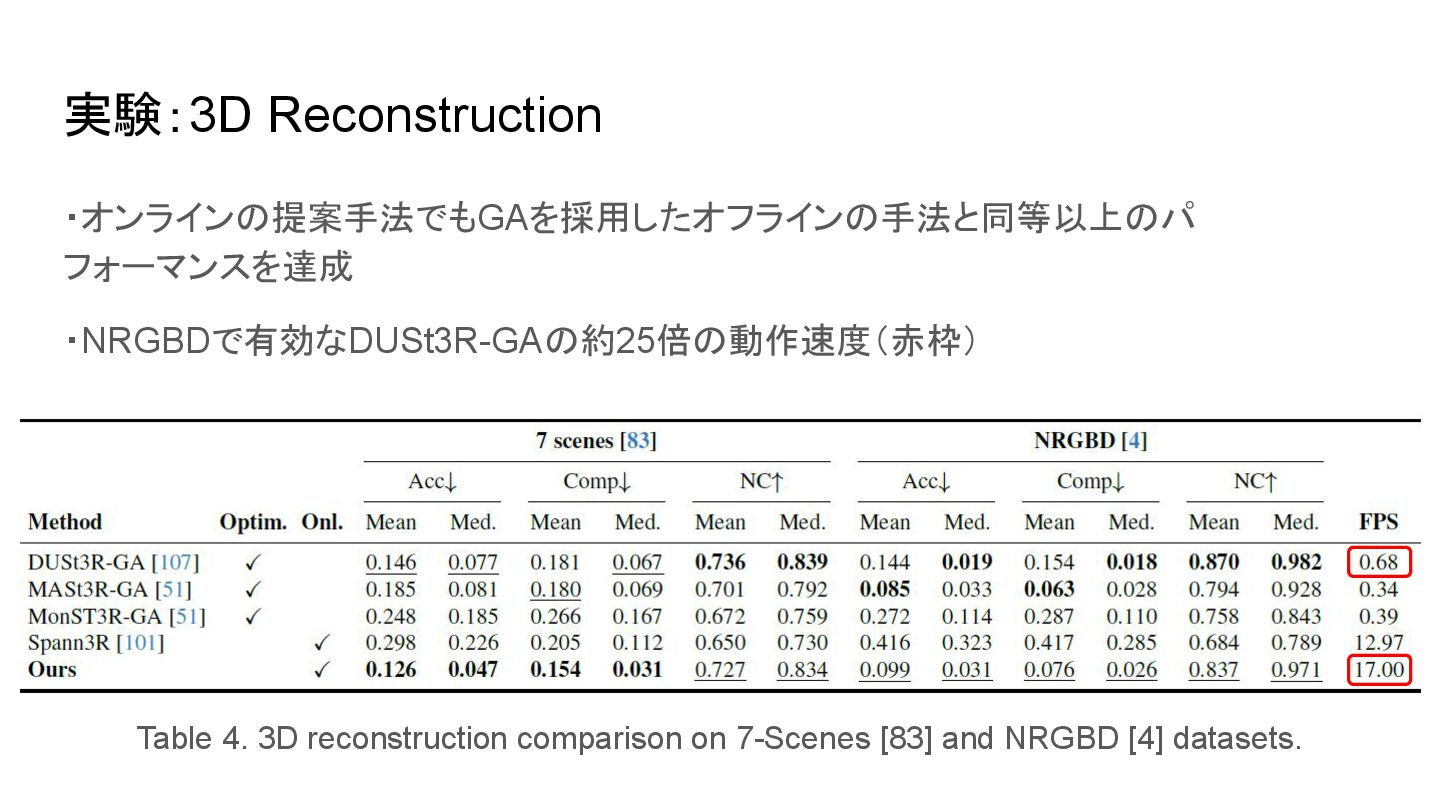
実験:3D Reconstruction ・オンラインの提案手法でもGAを採用したオフラインの手法と同等以上のパ フォーマンスを達成 ・NRGBDで有効なDUSt3R-GAの約25倍の動作速度(赤枠) Table 4. 3D reconstruction comparison
on 7-Scenes [83] and NRGBD [4] datasets.
実験:3D Reconstruction(可視化) Figure 4. Qualitative Results on In-the-wild Internet Videos.
制限 ・長いシーケンスではグローバルアラインメントがないためドリフトの可能性 ・生成的ではなく決定論的アプローチのため、視点から遠く離れた視点を外挿する場 合にボケやすい ・再帰型ネットワークのトレーニングでは時間がかかる
まとめ ・状態表現を更新可能なオンラインの三次元再構成モデル(CUT3R)を提案 ・ビデオや写真コレクションの入力と、静的・動的シーンの出力に対応 所感 ・CUT3Rから3DGS等の自由視点画像生成のタスクへ応用できると価値が高まる ・大容量、高解像度のデータセットにも適用できると実運用しやすい ・動的シーンの中でも長い年月で変化する環境に対してもワークできると面白い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}