Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Stable Virtual Camera:Generative View Synthesis...
Search
Spatial AI Network
June 06, 2025
0
54
Stable Virtual Camera:Generative View Synthesis with Diffusion Models
- 単一の拡散モデルによる少視点新規視点合成
- 大きな視点変化に伴う合成品質の低下と3Dシーンの一貫性の欠如という従来手法の課題を克服
Spatial AI Network
June 06, 2025
Tweet
Share
More Decks by Spatial AI Network
See All by Spatial AI Network
Exploring ways to enhance robustnessof 3D reconstruction using COLMAP
spatial_ai_network
0
36
CL-Splats: Continual Learning of Gaussian Splatting with Local Optimization
spatial_ai_network
0
14
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
spatial_ai_network
0
32
Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
spatial_ai_network
0
64
HyRF: Hybrid Radiance Fields for Memory-efficient and High-quality Novel View Synthesis
spatial_ai_network
0
40
GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Surfaces
spatial_ai_network
0
110
GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control
spatial_ai_network
1
85
High-Fidelity Lightweight Mesh Reconstruction from Point Clouds [CVPR 2025]
spatial_ai_network
1
130
Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
spatial_ai_network
0
160
Featured
See All Featured
Done Done
chrislema
186
16k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
192
62k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.6k
Making the Leap to Tech Lead
cromwellryan
135
9.6k
Designing for Performance
lara
610
69k
GraphQLの誤解/rethinking-graphql
sonatard
73
11k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.3k
Statistics for Hackers
jakevdp
799
230k
Writing Fast Ruby
sferik
630
62k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
1
51
Building Applications with DynamoDB
mza
96
6.8k
Fireside Chat
paigeccino
41
3.7k
Transcript
2025/05/13 Spatial AI Network 勉強会 STABLE VIRTUAL CAMERA: Generative View
Synthesis with Diffusion Models 発表者:勝又海 (CyberAgent)
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 2
Affiliation:Stability AI, Oxford, UC Berkeley 書誌情報:arXiv:2503.14489 URL:stable-virtual-camera.github.io/ Code:github.com/Stability-AI/stable-virtual-camera Demo:huggingface.co/spaces/stabilityai/stable-virtual-camera Jensen (Jinghao) Zhou, Hang Gao, Vikram Voleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, Varun Jampani STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 3
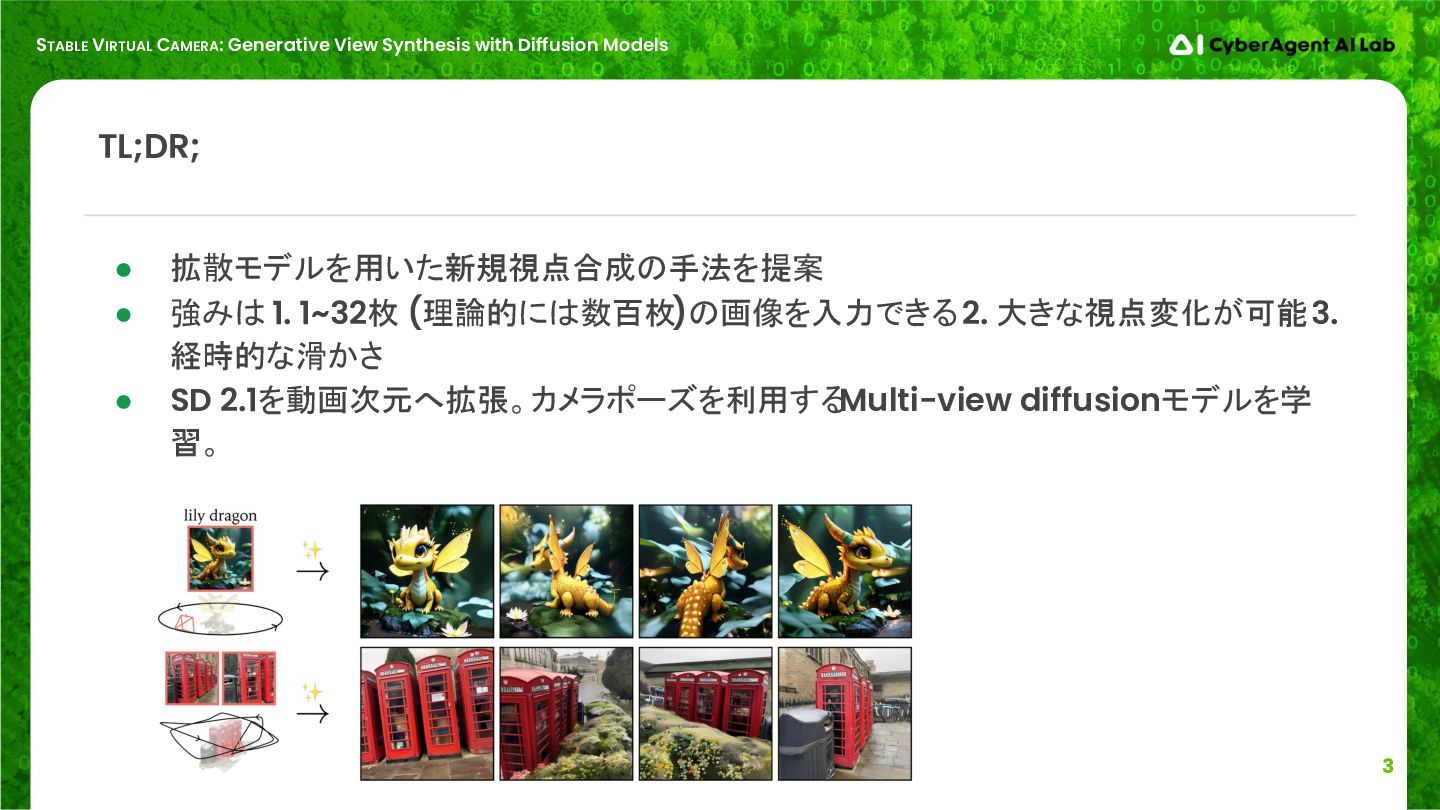
TL;DR; • 拡散モデルを用いた新規視点合成の手法を提案 • 強みは 1. 1~32枚 (理論的には数百枚)の画像を入力できる 2. 大きな視点変化が可能 3. 経時的な滑かさ • SD 2.1を動画次元へ拡張。カメラポーズを利用する Multi-view diffusionモデルを学 習。
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 4
タスク:新規視点合成 Task: Novel View Synthesis (NVS) 画像とカメラポーズのペアの集合 (1<=P)が与えられ 観測されない新たな視点からの画像を合成する https://kaldir.vc.in.tum.de/scannetpp/benchmark/nvs データセット 目的関数 :画像 :カメラポーズ :新規視点数 :合成画像
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 5
様々な新規視点合成タスク Types of NVS Tasks 対象シーン:オブジェクト、シーン 入力視点数:single (P = 1), sparse (P <= 8), semi-dense (9 < P ≲ 50), dense (50 ≲ P) Set NVS vs. Trajectory NVS:生成したいターゲットカメラに順序があり、滑らかな軌跡に 沿っているか [Mildenhall+, ECCV'20]
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 6
既存手法の限界 Limitations of NVS models 1. 大きな視点変化に対応できない (MotionCtrl [Wang+ SIGGRAPH’24], ViewCrafter [Yu+ arXiv’24]) 2. フレーム間で滑らかでない変化が発生する (CAT3D [Gao+ NeurIPS'24], ReconFusion [Wu+ CVPR’24]) 3. 入力視点数に制約がある MotionCtrl
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 7
本研究の位置付け Positioning the study
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 8
主な貢献 Contributions 1. 大きな視点変化に対応し連続するフレーム間での滑らかな生成の実現 ↑学習時の入力フレーム数の柔軟化とフレーム間の関係を捉える 1D self-attentionの 利用 2. 任意長のカメラパスに対応した画像の生成 ↑Procedural two-pass samplingによる段階的な生成と入力と生成視点数に応じ た生成戦略の採用
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 9
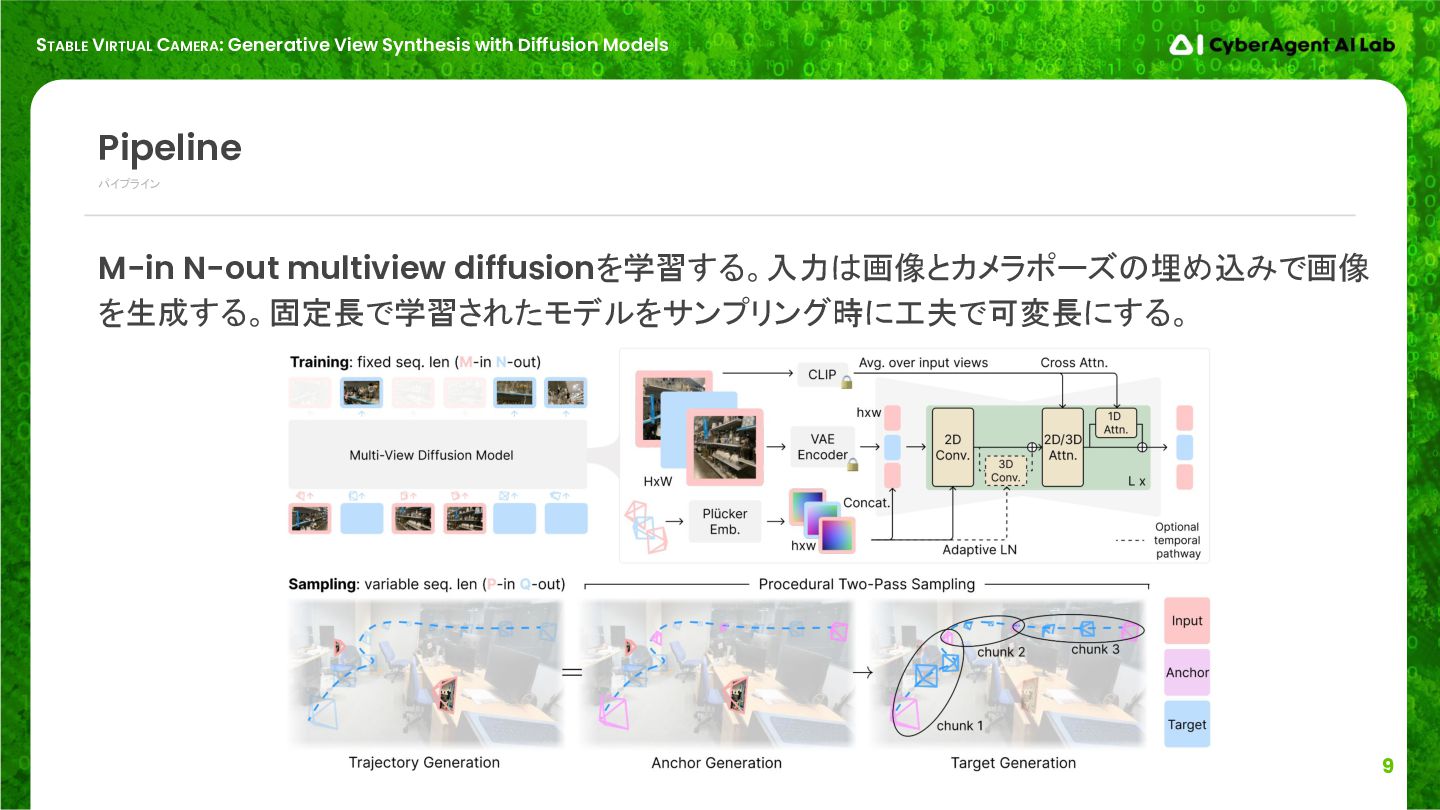
M-in N-out multiview diffusionを学習する。入力は画像とカメラポーズの埋め込みで画像 を生成する。固定長で学習されたモデルをサンプリング時に工夫で可変長にする。 パイプライン Pipeline
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 10
Latent diffusion Latent Diffusion Stable Diffusion 2.1 (SD)のDiffusion U-Netを拡張する。 AutoencoderはSDのものをそのまま利用し、画像の埋め込みを行う。入力の拡張を行い、 CLIP画像埋め込み、カメラポーズの条件付けを可能にする。
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 11
3D Self-Attention 3D Self-Attention Stable diffusionのU-Netの2D self-attentionを3D self-attentionに変更する。 Self-attentionのパラメータ数は入力と出力のチャンネル数にのみ依存しており、入力サイ ズには依存しないため、オリジナルのパラメータを使える。 [Gao+ NeurIPS'24]
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 12
1D self-Attention 1D Self-Attention 3D self-attentionは計算量の都合上、常に適用できないため、 1D self-attentionを用い ることで計算量を抑えたまま、視点間の一貫性を担保できる。
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 13
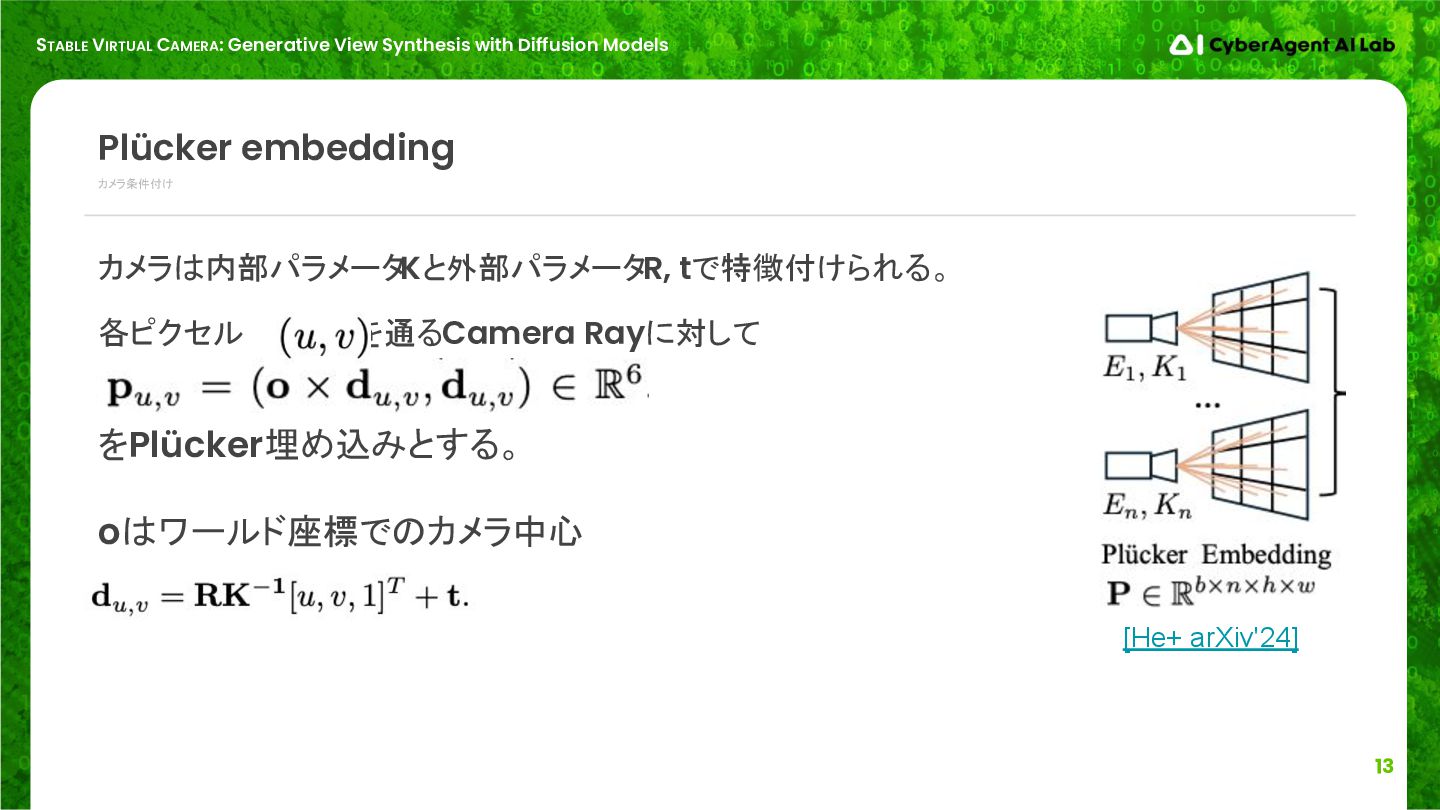
カメラ条件付け Plücker embedding カメラは内部パラメータKと外部パラメータR, tで特徴付けられる。 各ピクセル を通るCamera Rayに対して をPlücker埋め込みとする。 oはワールド座標でのカメラ中心 [He+ arXiv'24]
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 14
CLIP埋め込み CLIP image embedding SV3D [Voleti+ ECCV'24]に従ってCLIP image embeddingを生成条件に利用する。入 力が複数なので平均を取って入力にする。 CAT3D [Gao+, NeurIPS'24]では3D self-attention layerで入力視点の情報を利用でき るため使っていないとしているが、 self-attention layerよりも大域的な特徴を活用しやすい のではないか?
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 15
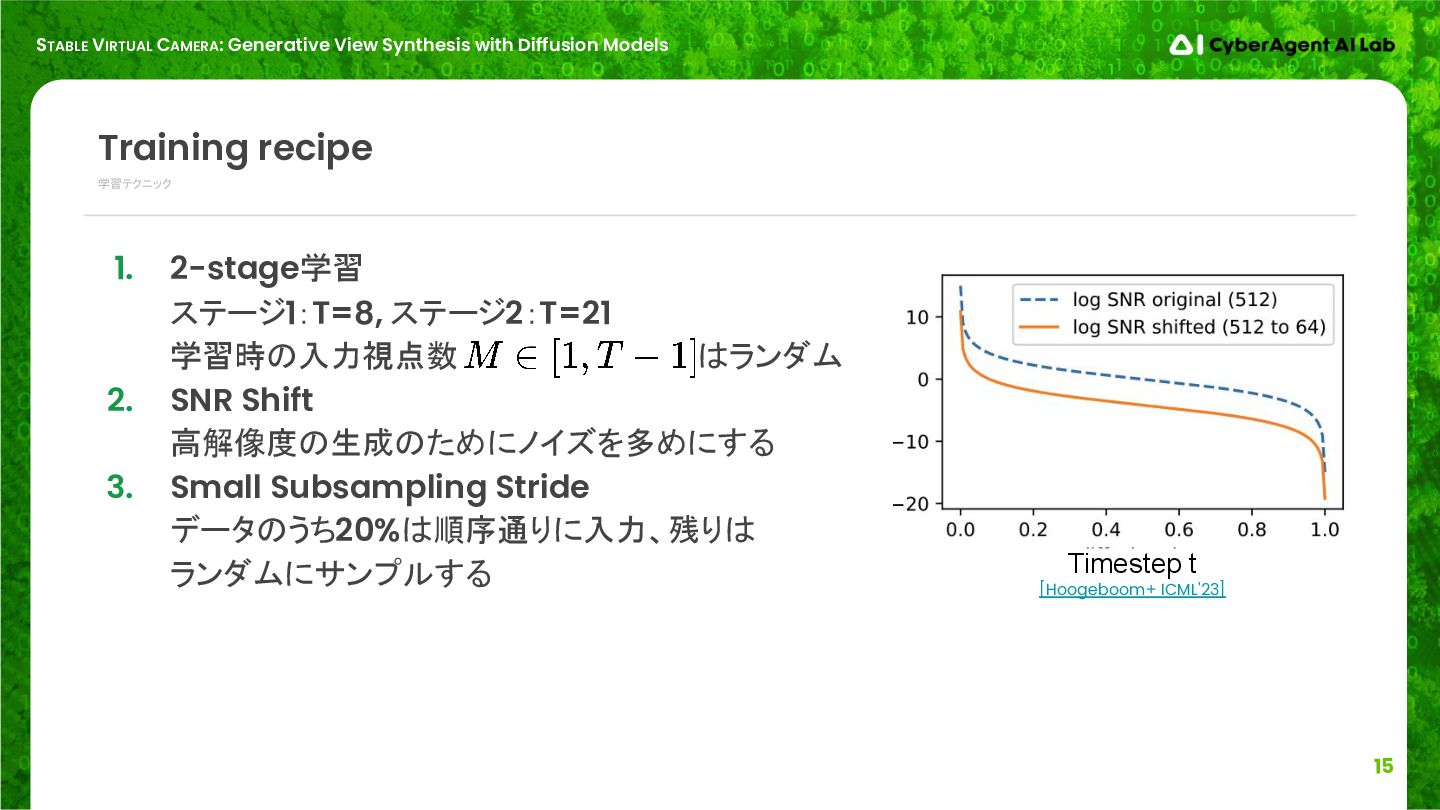
学習テクニック Training recipe 1. 2-stage学習 ステージ1:T=8, ステージ2:T=21 学習時の入力視点数 はランダム 2. SNR Shift 高解像度の生成のためにノイズを多めにする 3. Small Subsampling Stride データのうち20%は順序通りに入力、残りは ランダムにサンプルする Timestep t [Hoogeboom+ ICML'23]
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 16
ビデオ学習 Optional Video Training 3D Convを追加して, 隣接フレーム(カメラ)間の関係 性を強調 → 隣接フレームの滑らかさが向上 (trajectory NVS)で 効果あり 公式の公開実装には未実装 https://arxiv.org/pdf/2304.08818
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 17
推論 2-Pass Procedural Sampling for “P-in Q-out” NVS One-Passサンプリング Anchor pass + Chunk pass P + Qi <= Tとなるようにチャンクに分割し、はじめに T - P個以下のアンカーを生成する。その 後生成したアンカーを用いてチャンクに分割されたターゲット視点を生成する。ターゲットの生成 にはnearestとinterpの2種類のアプローチを検討
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 18
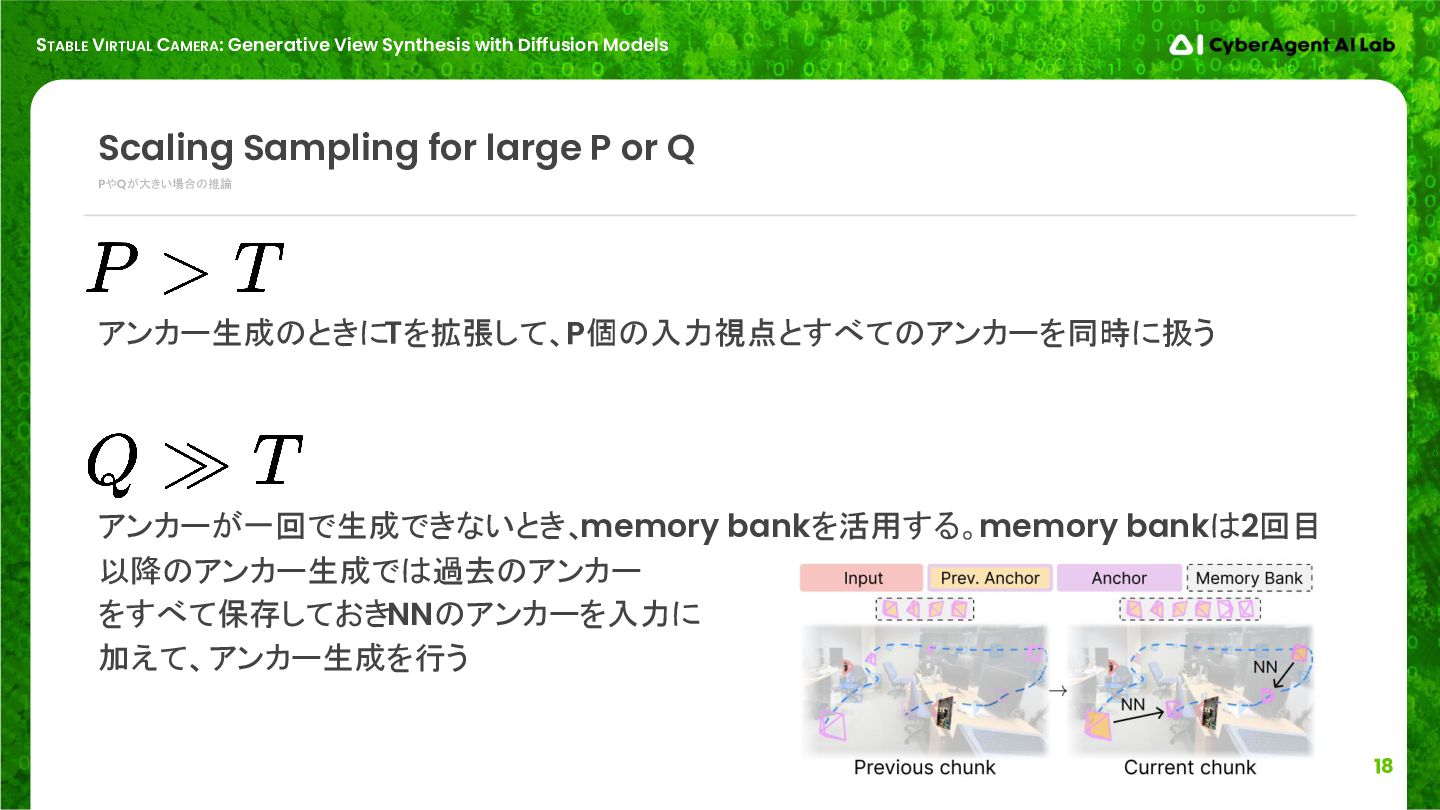
PやQが大きい場合の推論 Scaling Sampling for large P or Q アンカー生成のときにTを拡張して、P個の入力視点とすべてのアンカーを同時に扱う アンカーが一回で生成できないとき、 memory bankを活用する。memory bankは2回目 以降のアンカー生成では過去のアンカー をすべて保存しておきNNのアンカーを入力に 加えて、アンカー生成を行う
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 19
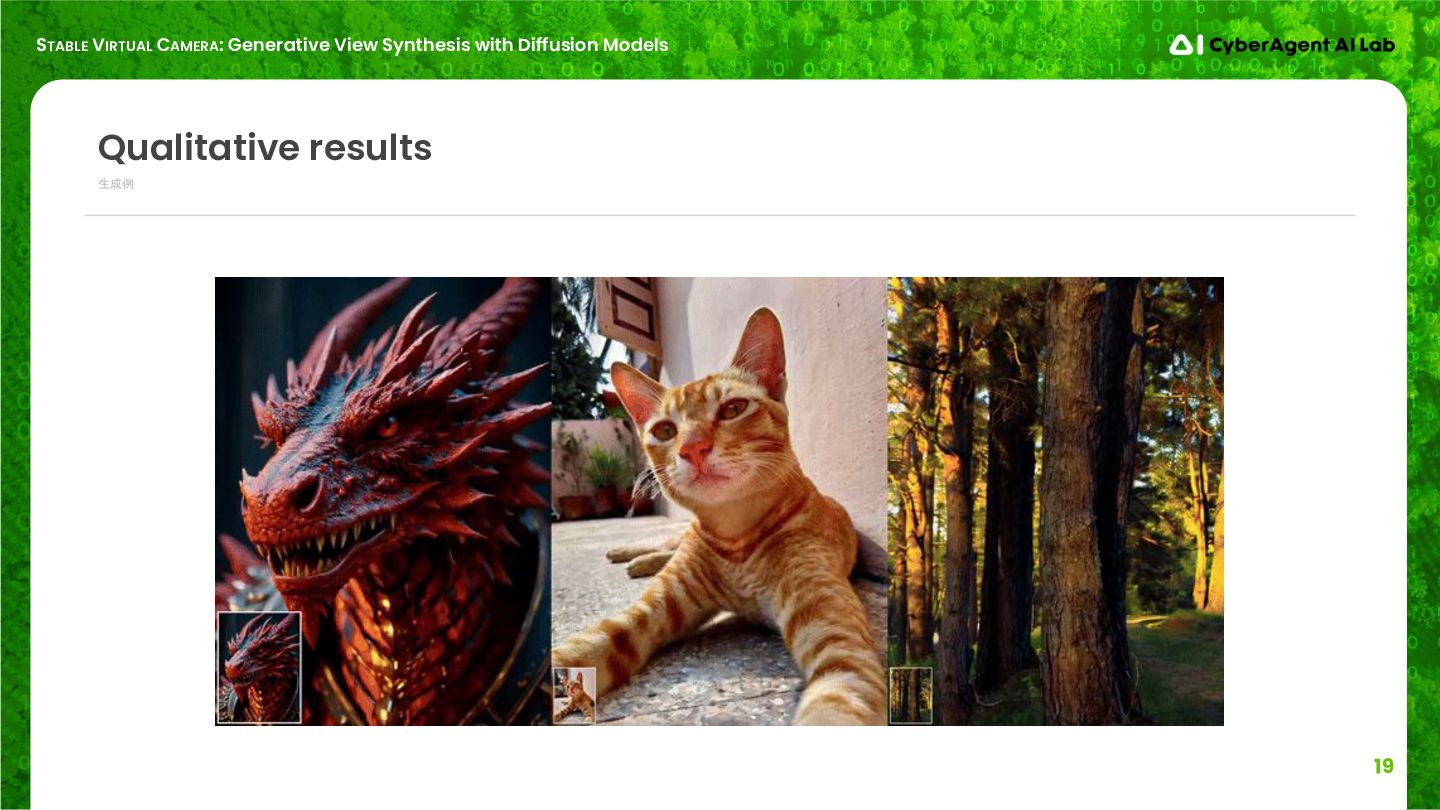
生成例 Qualitative results
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 20
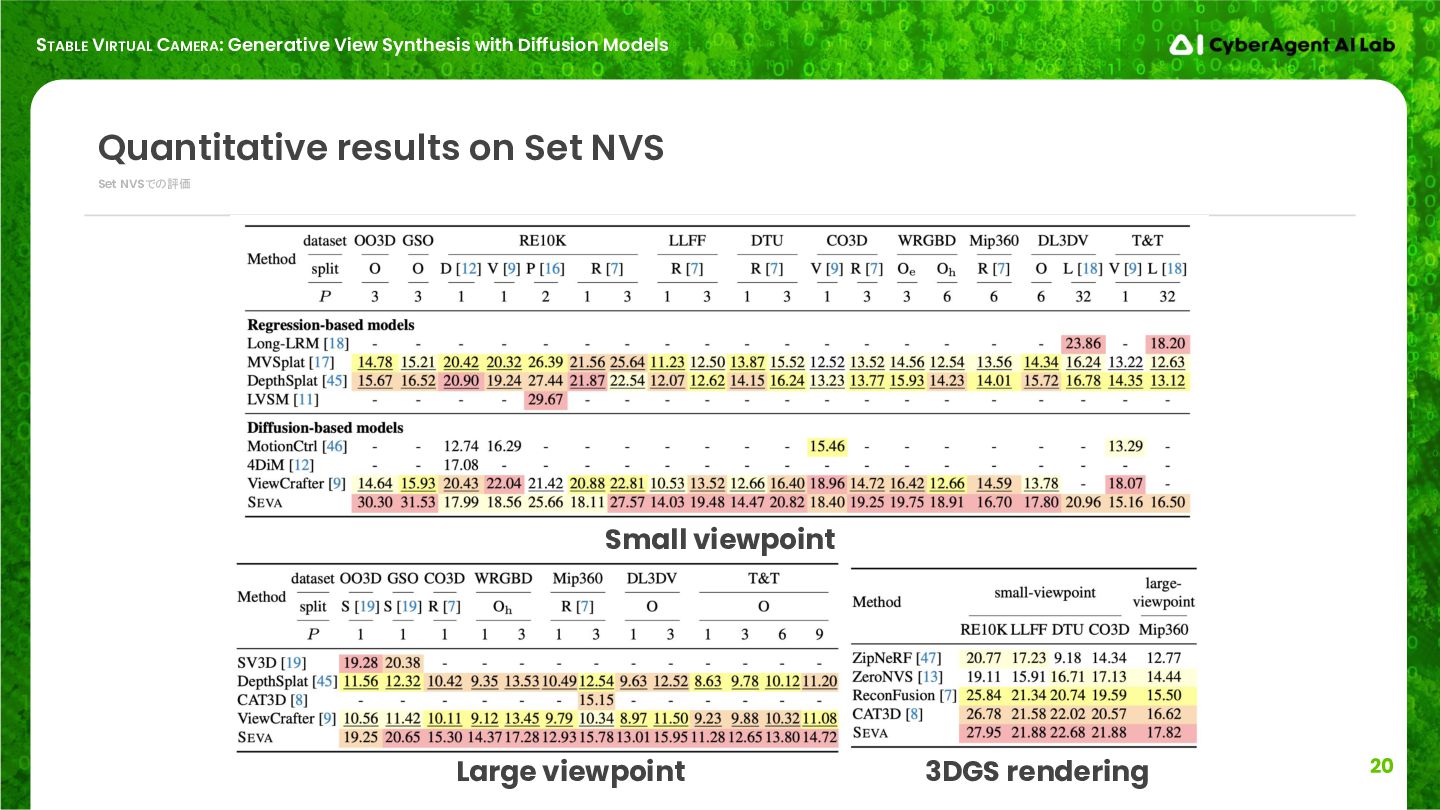
Set NVSでの評価 Quantitative results on Set NVS Small viewpoint Large viewpoint 3DGS rendering
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 21
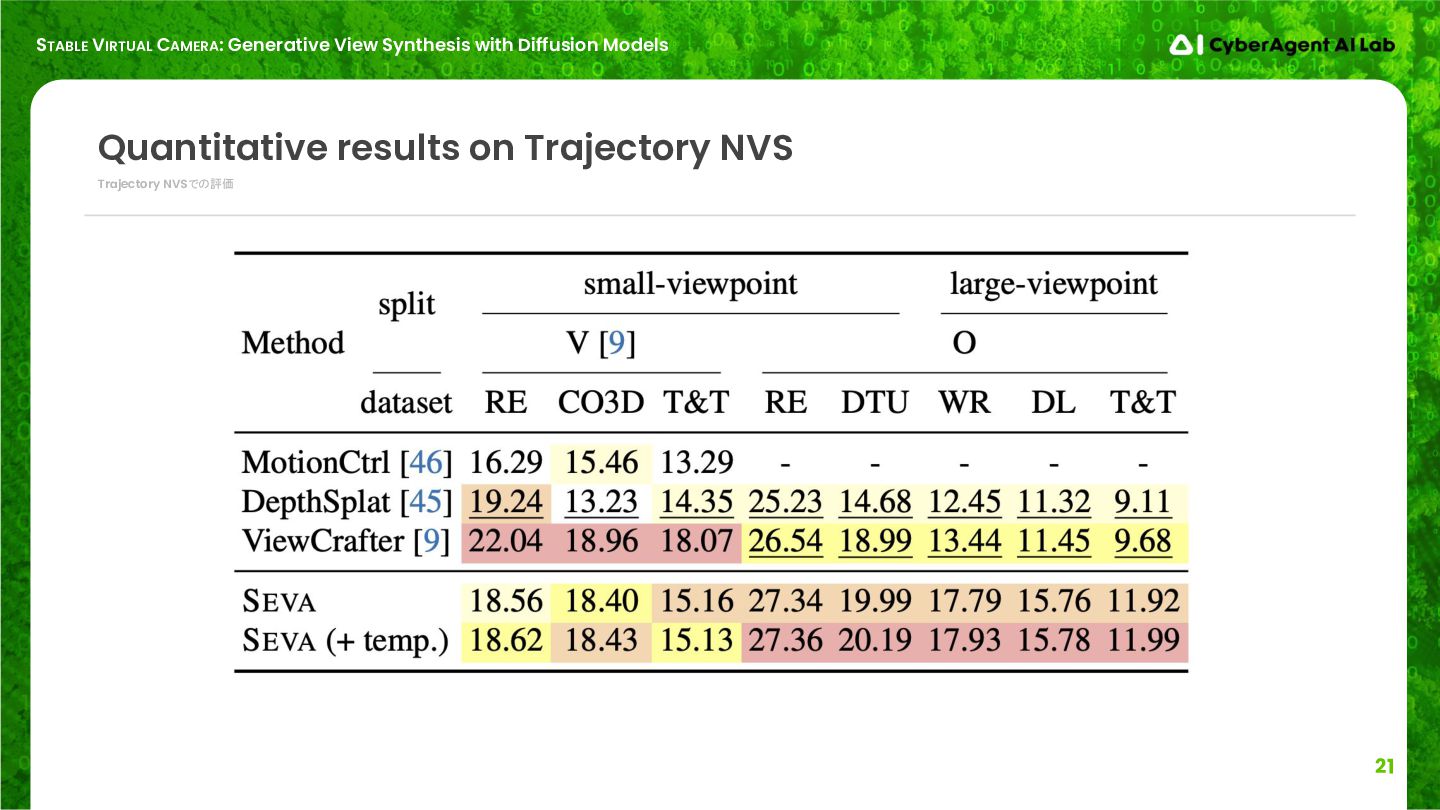
Trajectory NVSでの評価 Quantitative results on Trajectory NVS
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 22
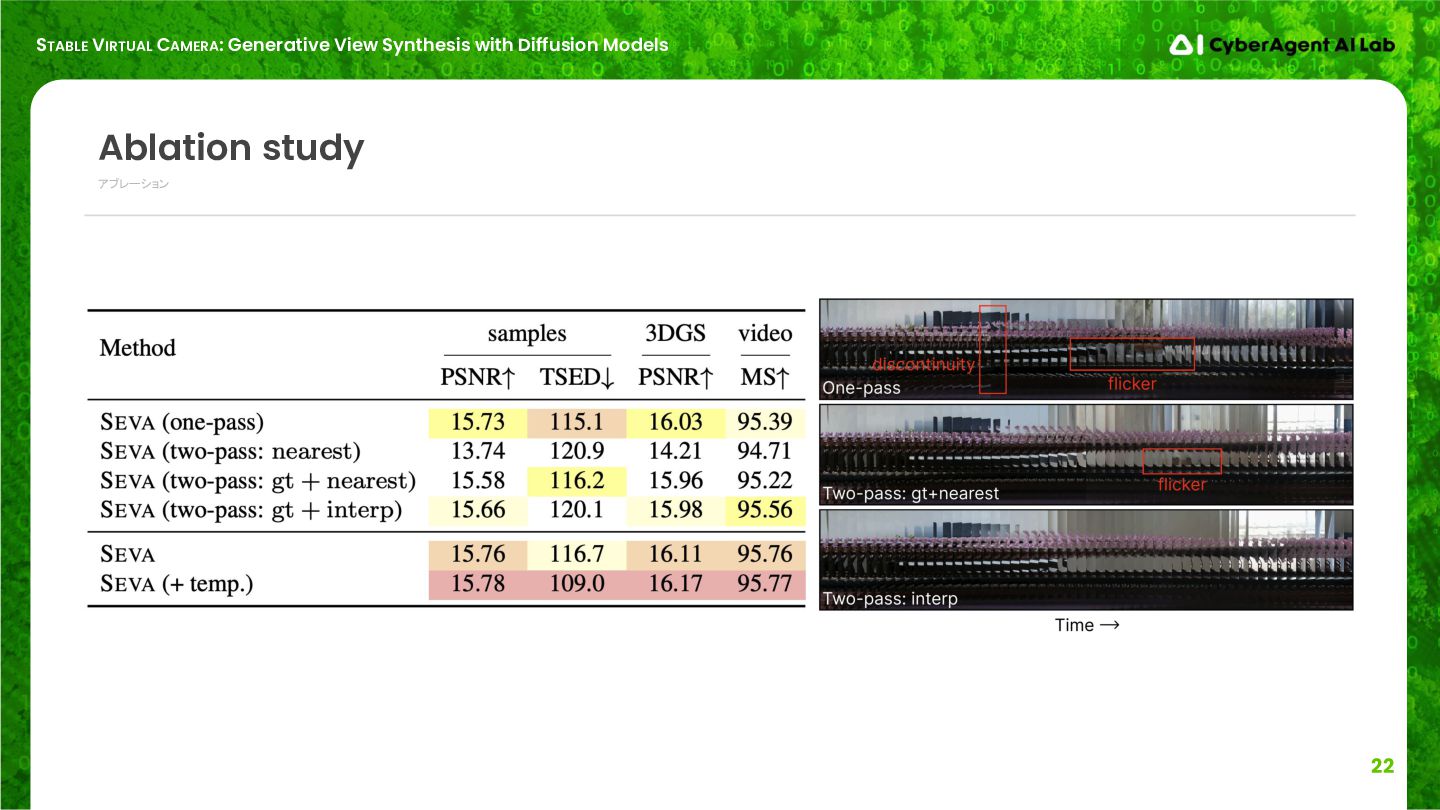
アブレーション Ablation study
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 23
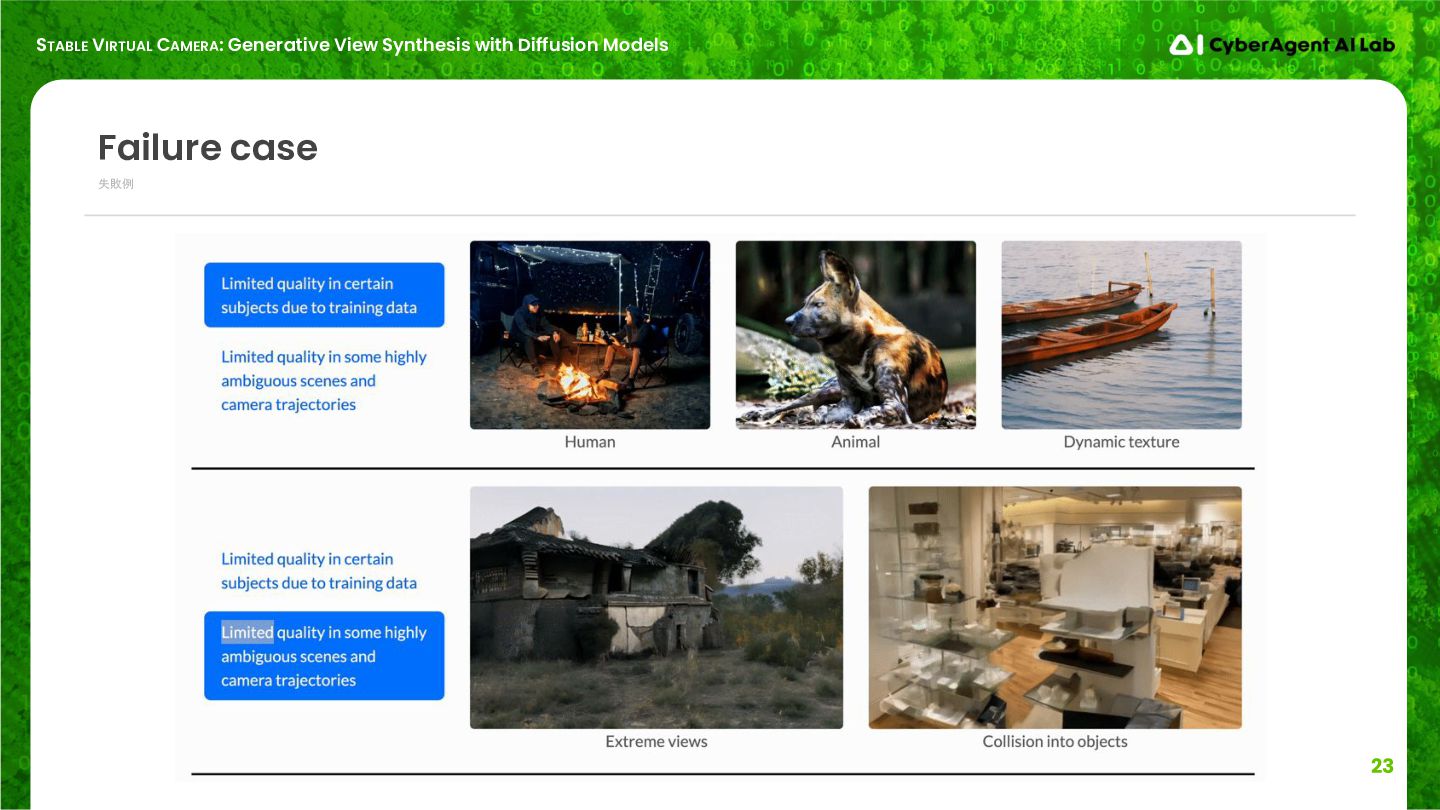
失敗例 Failure case
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models 24
まとめ Conslusion • 単一モデルによるSparse-view NVSの手法 ◦ 後工程としてのNeRF distillationを必要としない • 入力視点数に柔軟性を導入 ◦ 多様なNVSタスクを解ける • 拡散モデルによるサンプリングが必要なので遅い ◦ 3DGSなどの表現を学習することで高速化可能 • 動的シーンが未対応
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}