and training of neural networks for efficient integer-arithmetic-only inference." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. • Zhou, Aojun, et al. "Incremental network quantization: Towards lossless cnns with low-precision weights." arXiv preprint arXiv:1702.03044 (2017). • Krishnamoorthi, Raghuraman. "Quantizing deep convolutional networks for efficient inference: A whitepaper." arXiv preprint arXiv:1806.08342 (2018). • Nagel, Markus, et al. "A white paper on neural network quantization." arXiv preprint arXiv:2106.08295 (2021). • Lin, Xiaofan, Cong Zhao, and Wei Pan. "Towards accurate binary convolutional neural network." Advances in neural information processing systems 30 (2017). • Gholami, Amir, et al. "A survey of quantization methods for efficient neural network inference." Low-Power Computer Vision. Chapman and Hall/CRC, 2022. 291-326. • Nagel, Markus, et al. "Data-free quantization through weight equalization and bias correction." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. • Nagel, Markus, et al. "Up or down? adaptive rounding for post-training quantization." International Conference on Machine Learning. PMLR, 2020. • Dettmers, Tim, et al. "LLM.int8 () 8-bit matrix multiplication for transformers at scale." Proceedings of the 36th International Conference on Neural Information Processing Systems. 2022. • Wei, Xiuying, et al. "Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling." arXiv preprint arXiv:2304.09145 (2023). 参考文献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
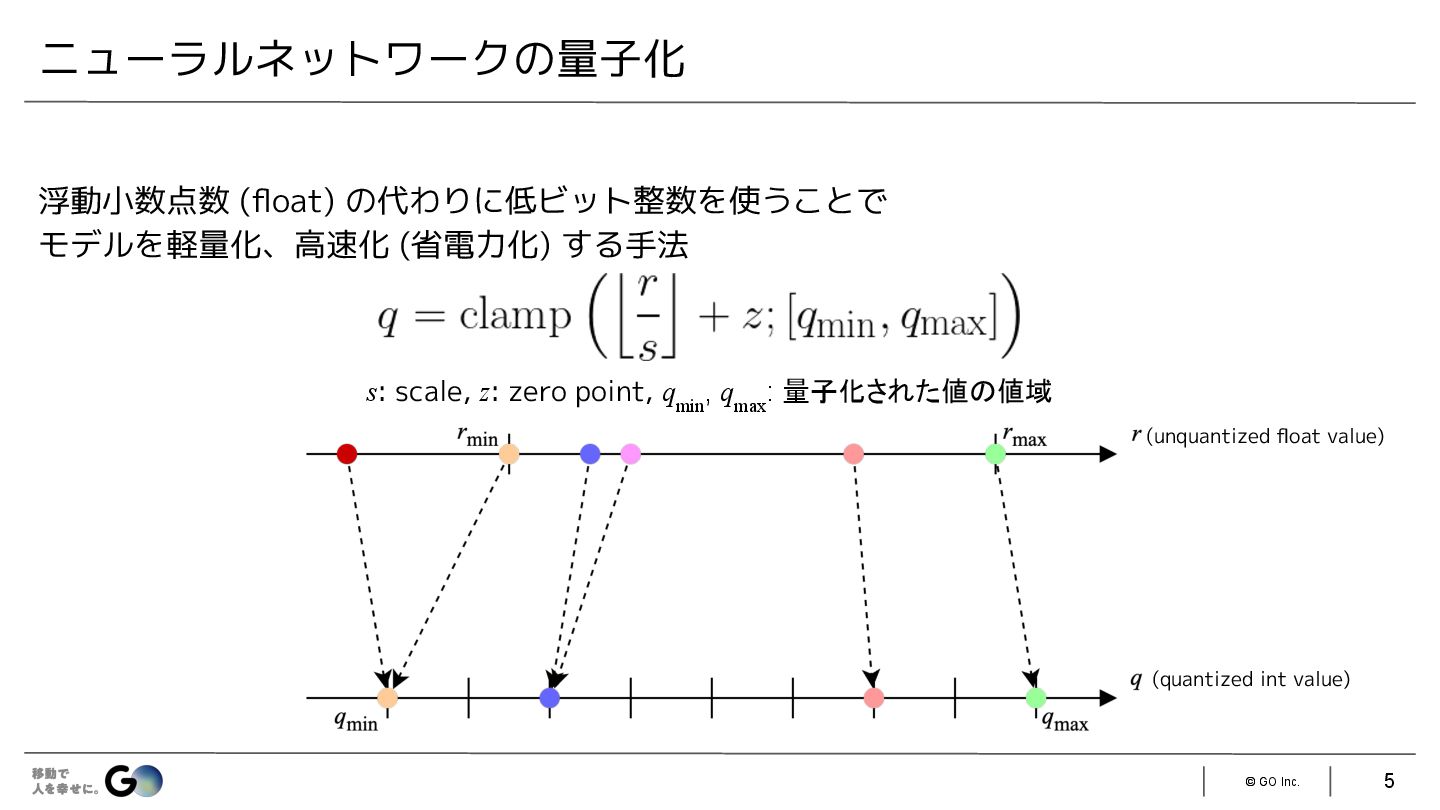{kind=link}
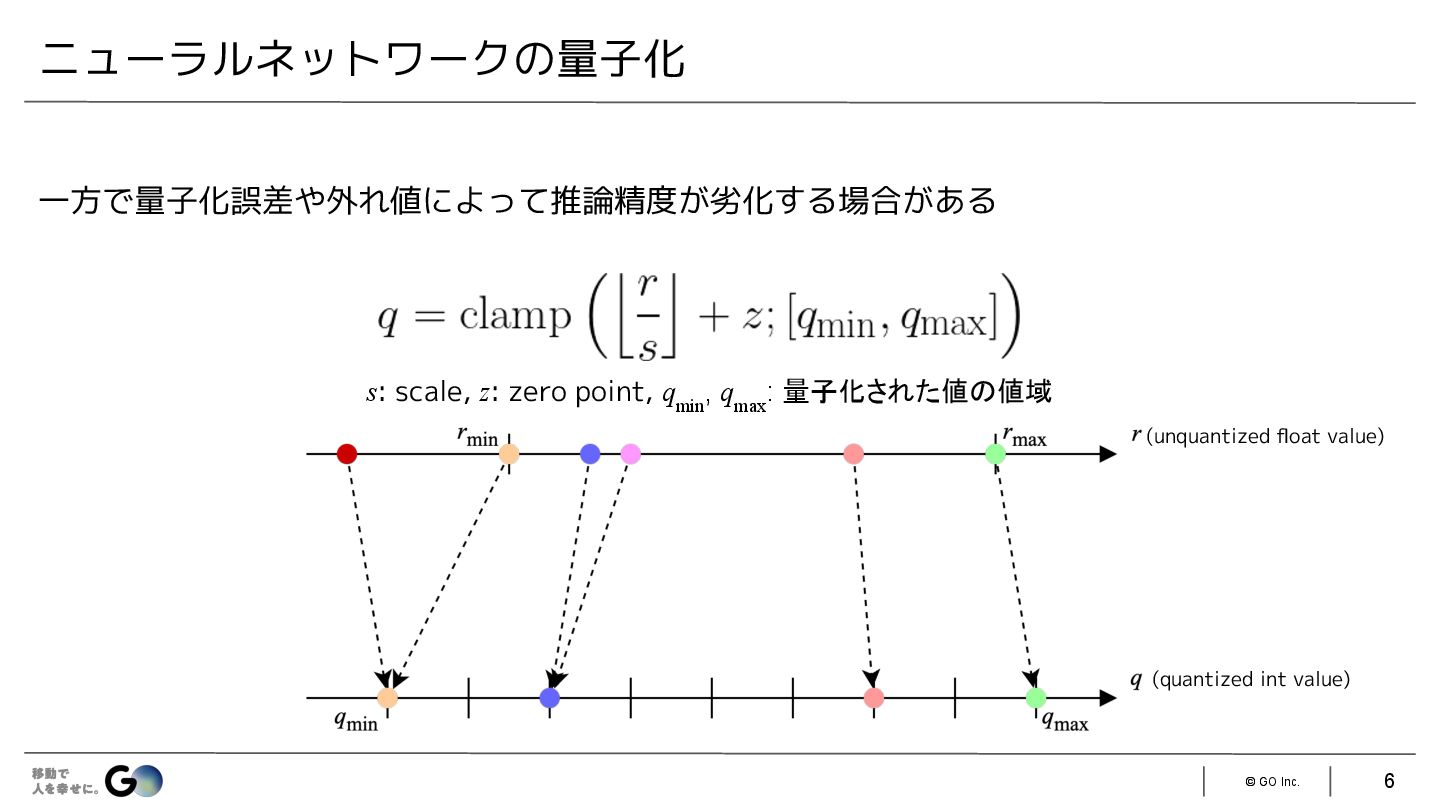{kind=link}
{kind=link}
{kind=link}
{kind=link}
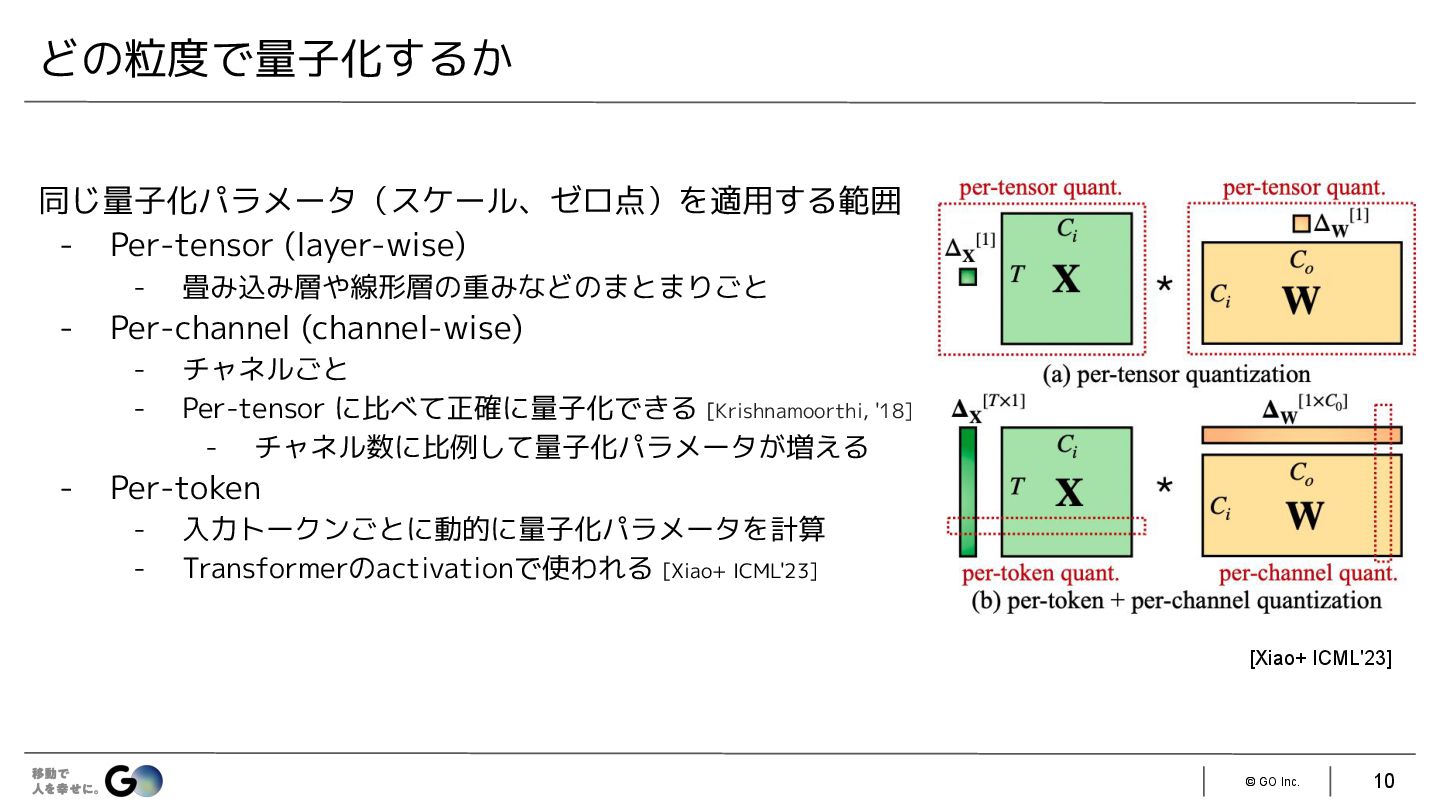{kind=link}
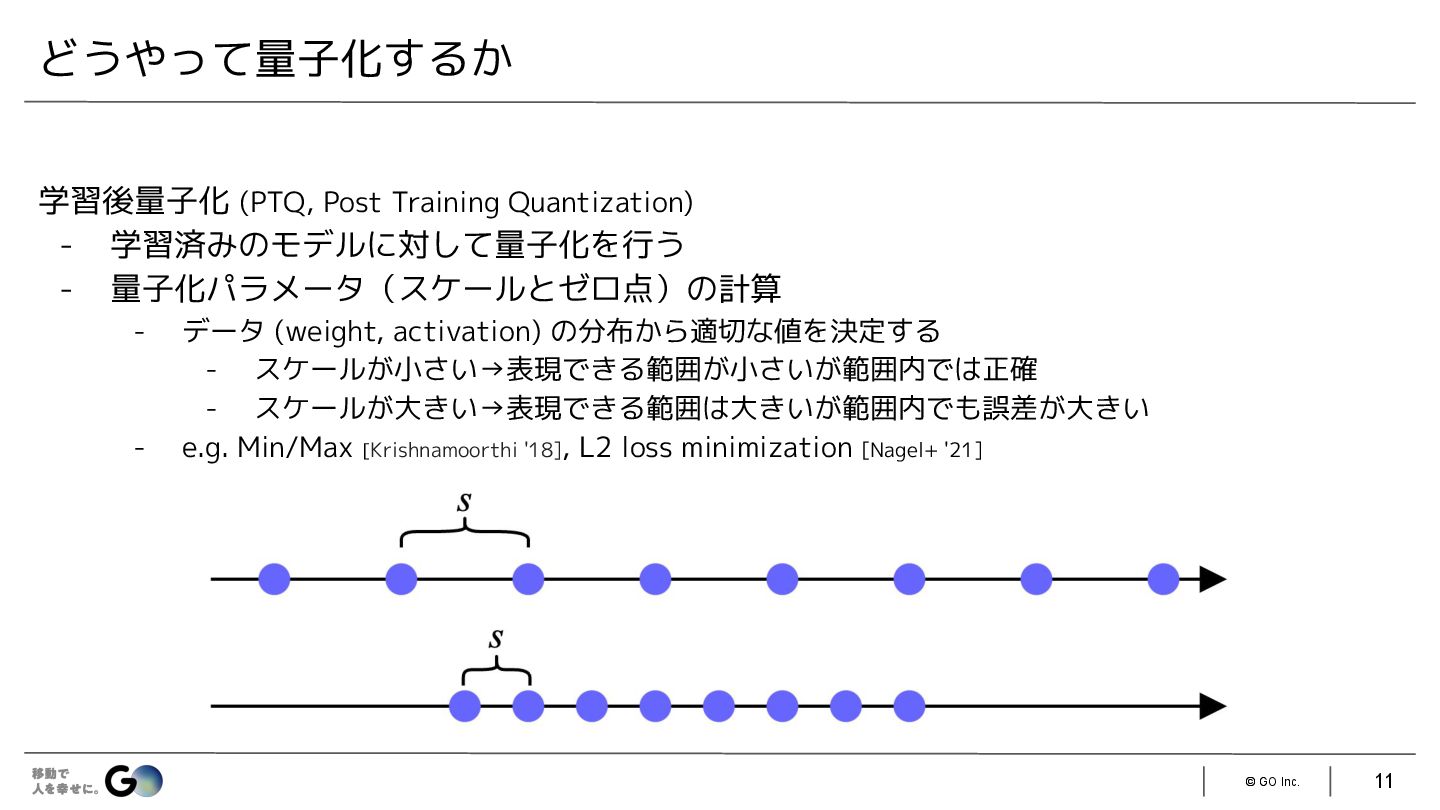{kind=link}
{kind=link}
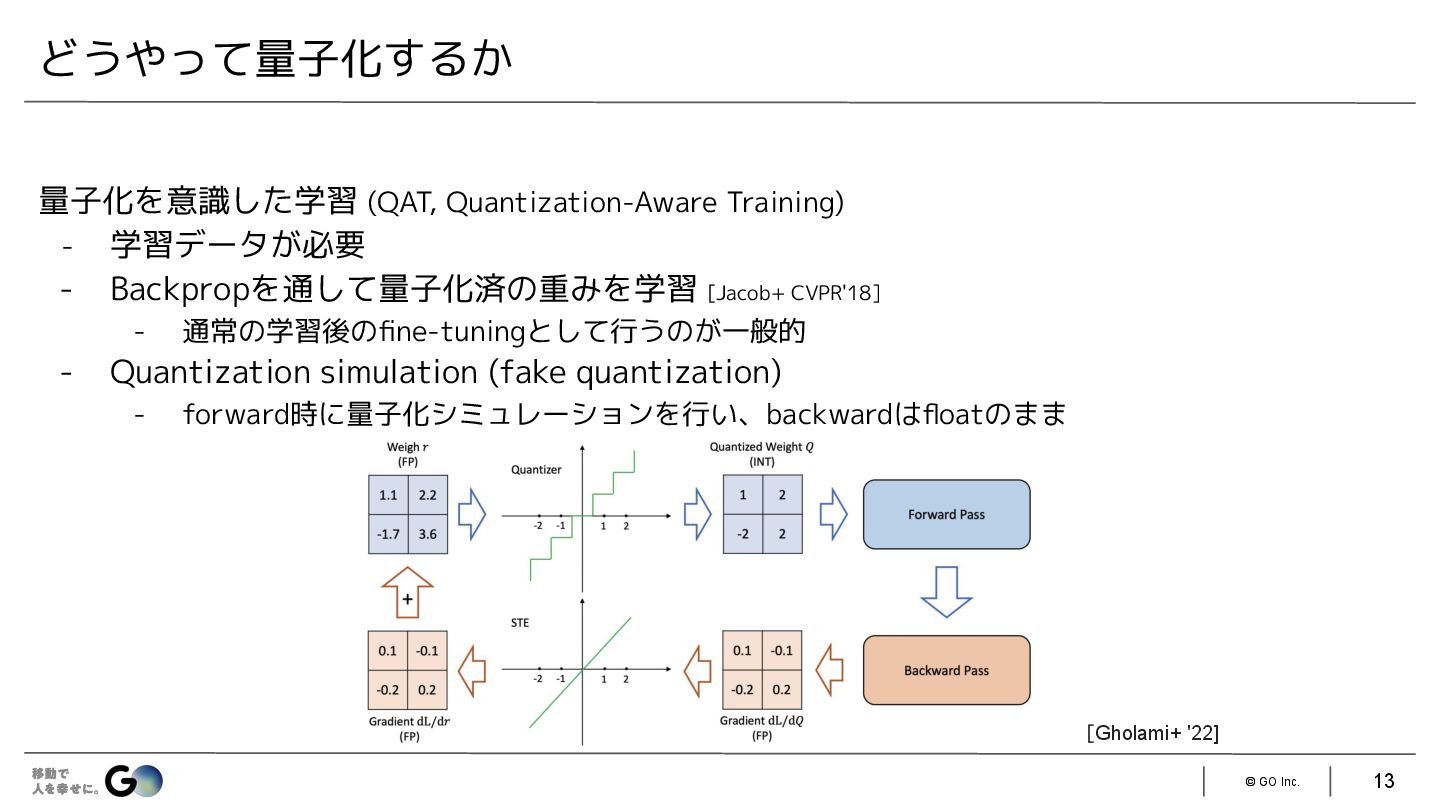{kind=link}
{kind=link}
{kind=link}
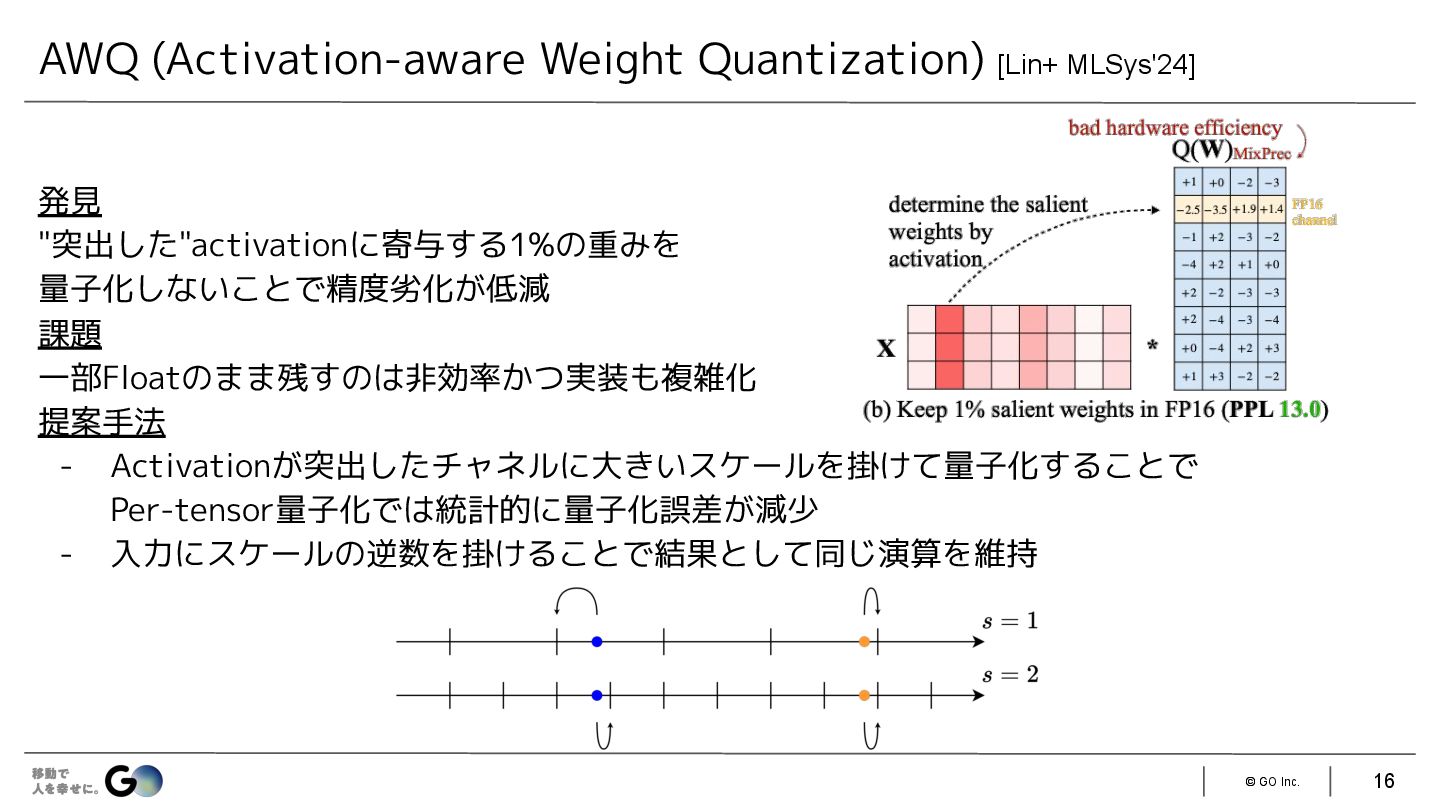{kind=link}
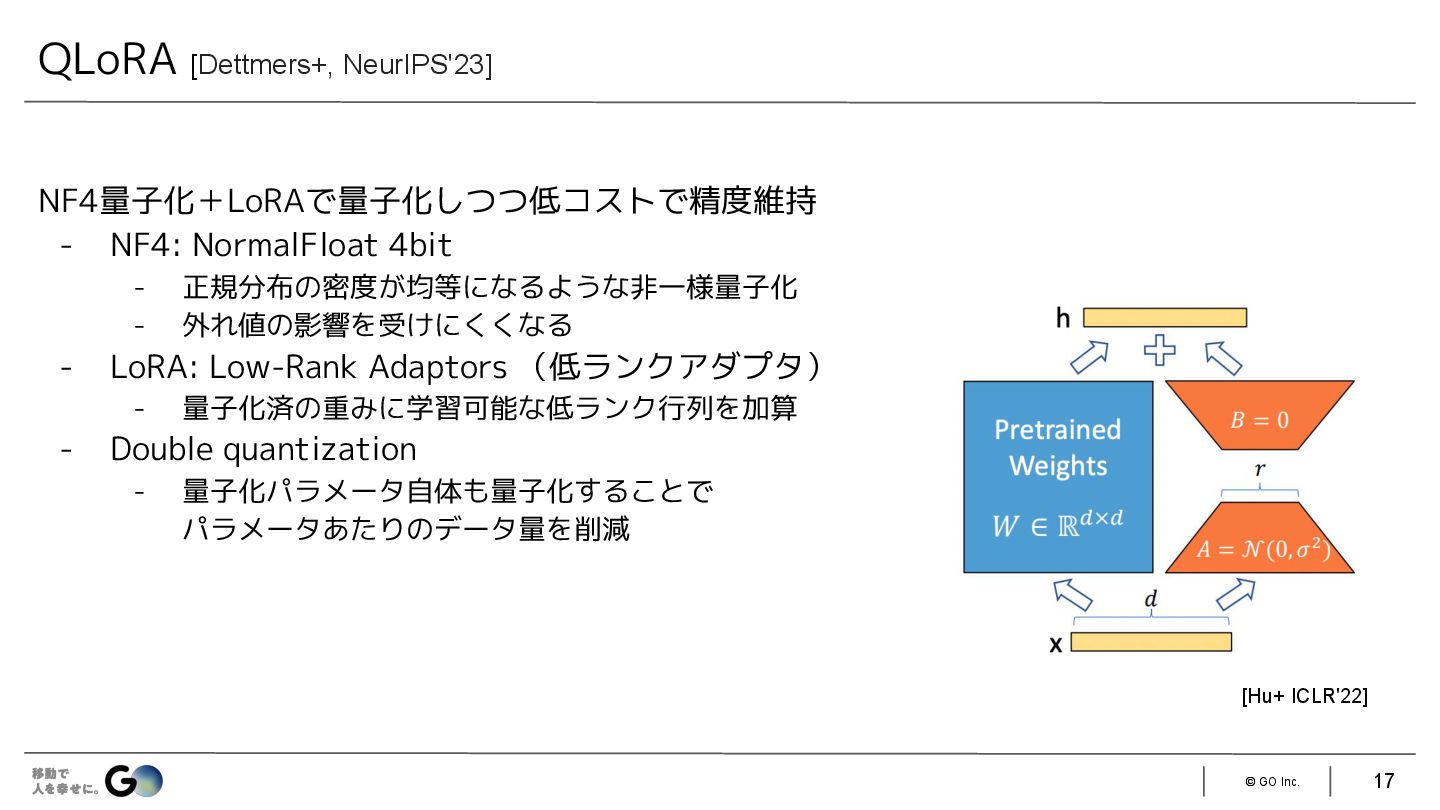{kind=link}
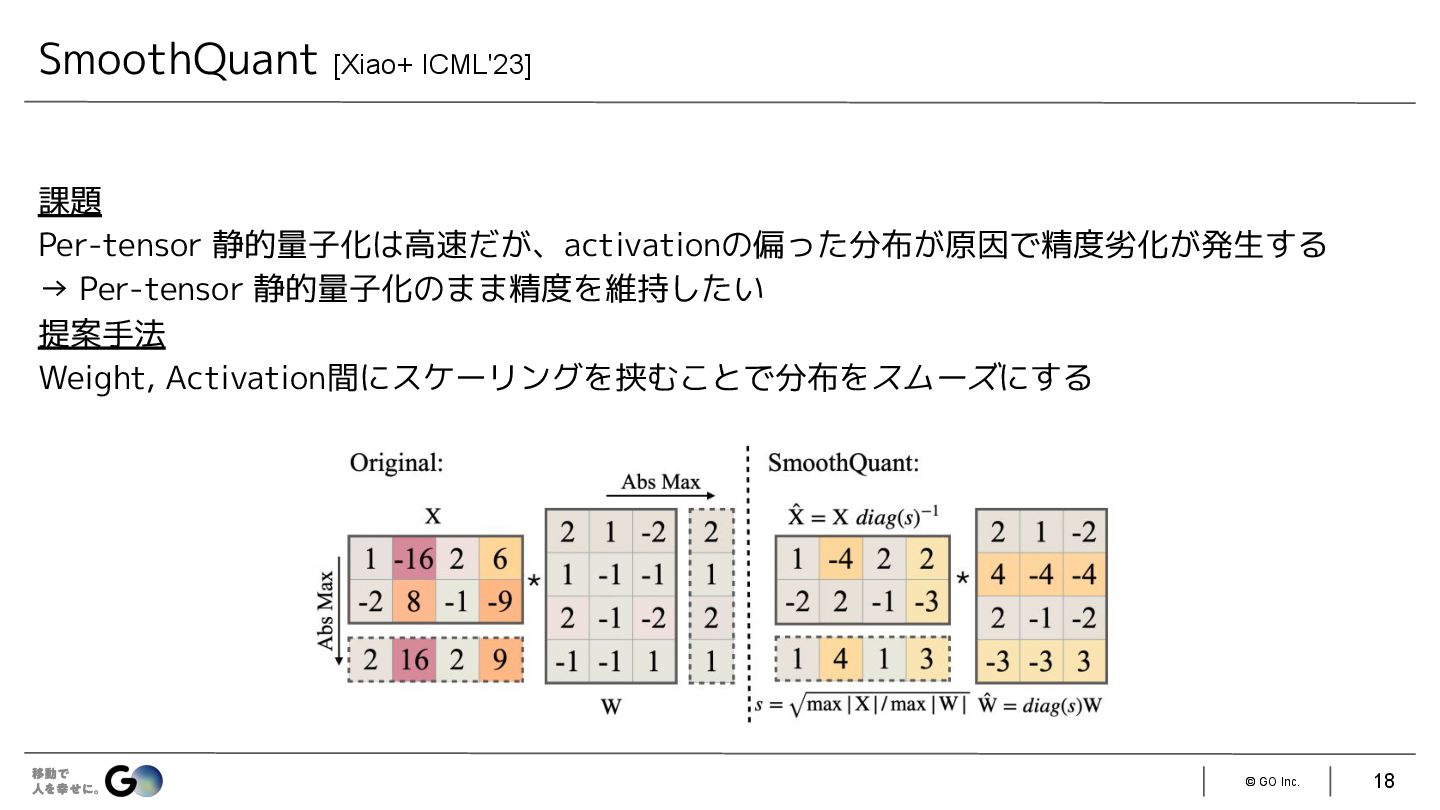{kind=link}
{kind=link}
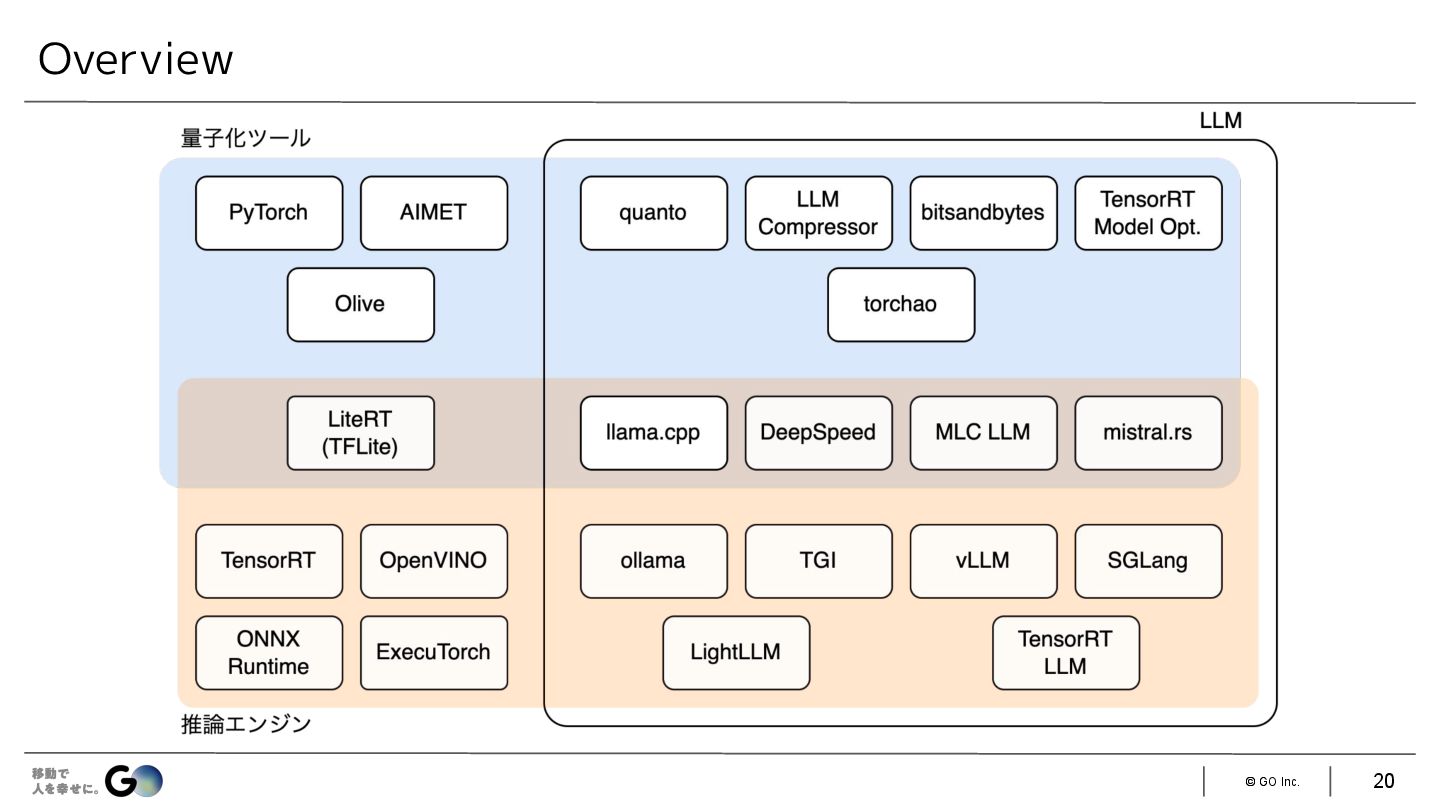{kind=link}
{kind=link}
{kind=link}
{kind=link}
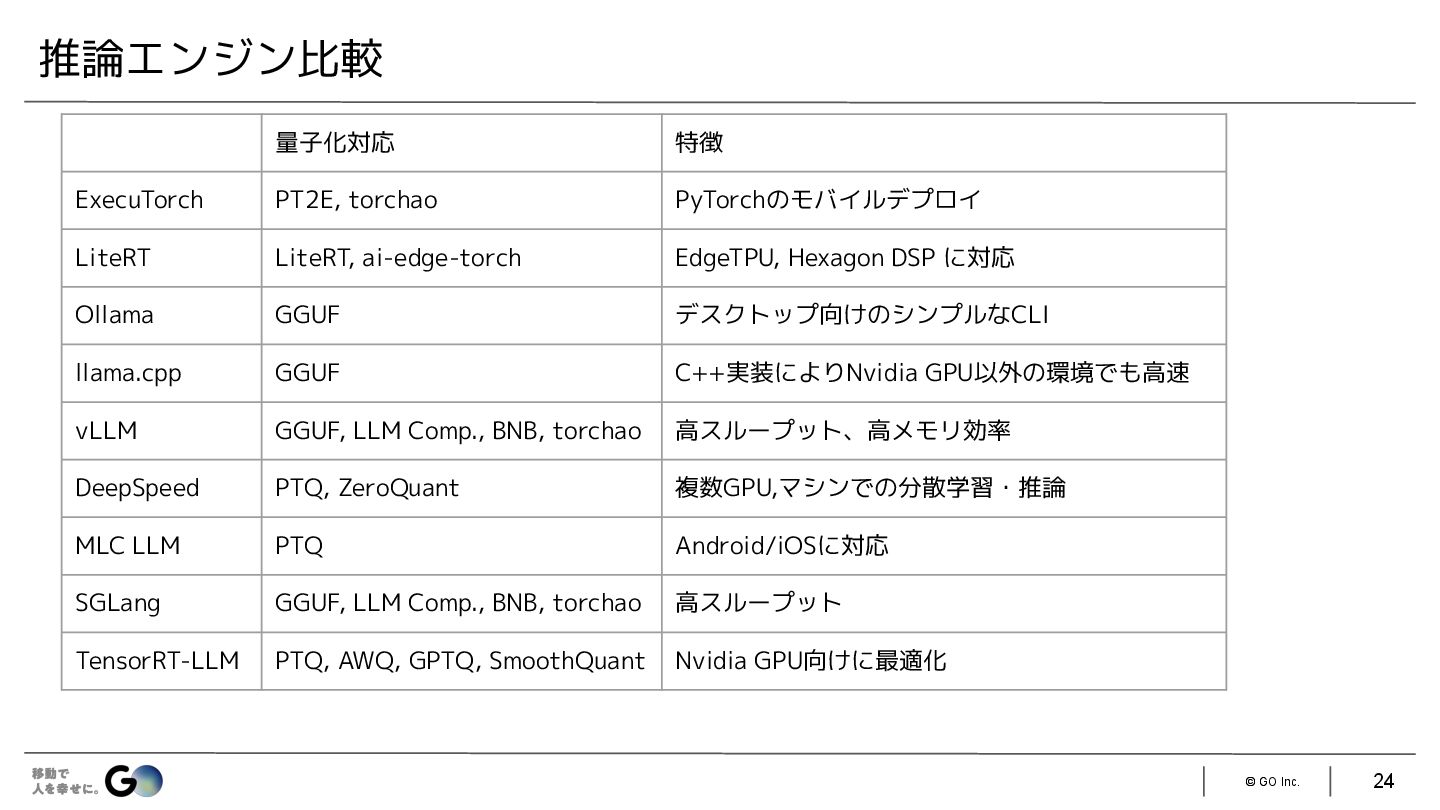{kind=link}
{kind=link}
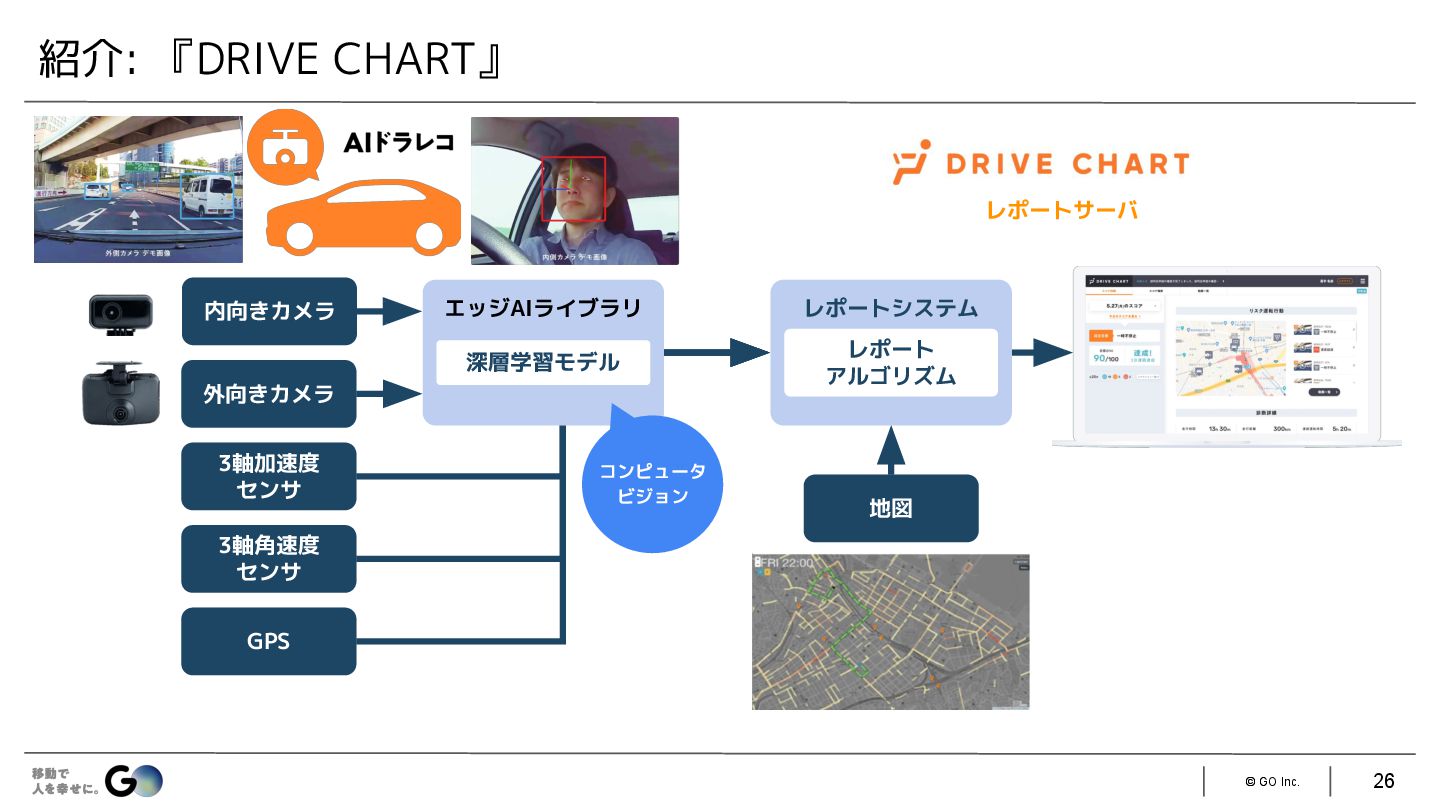{kind=link}
{kind=link}
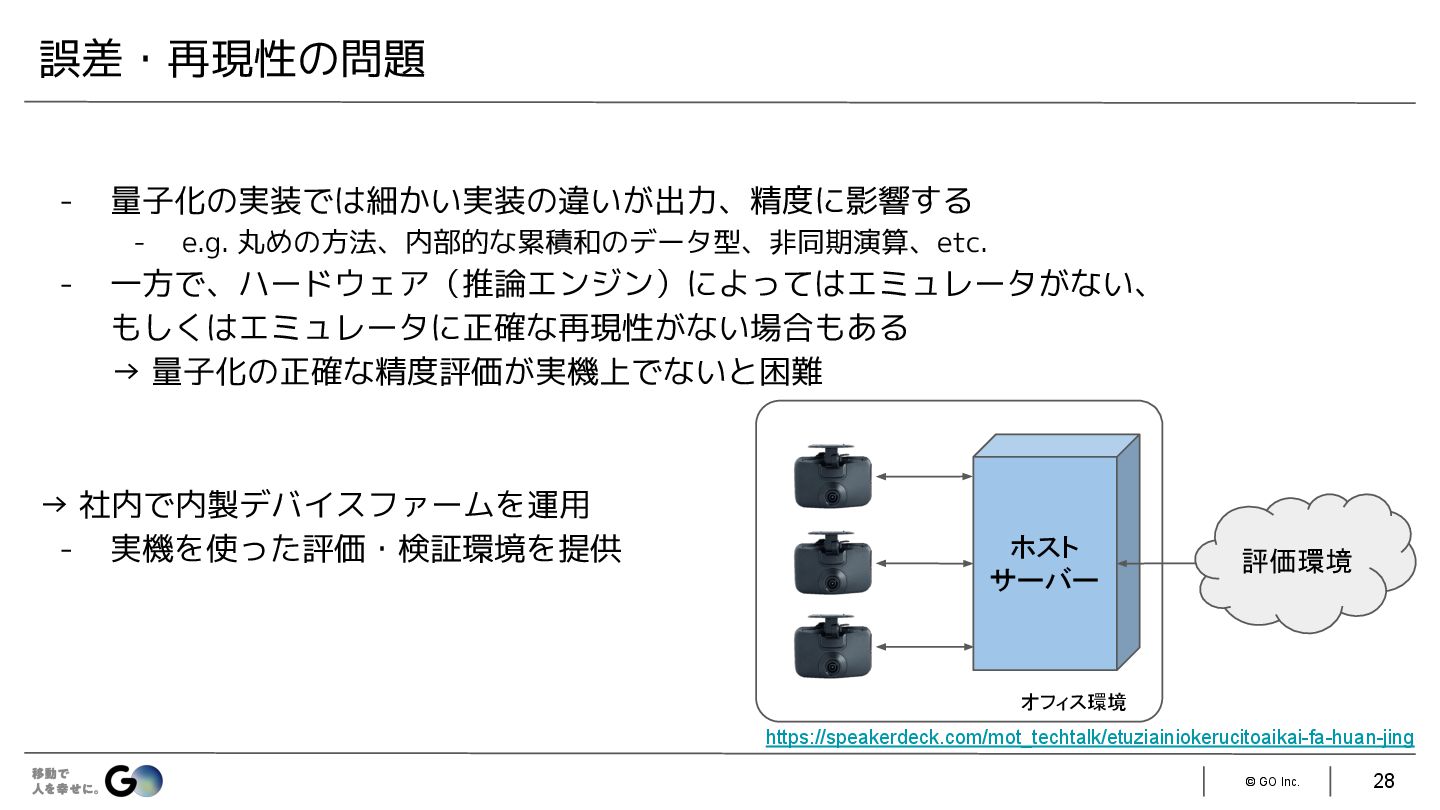{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}