イベント概要
第52回 MLOps コミュニティイベントです!
第52回は株式会社MIXI 谷様、株式会社オープンストリーム 高岡様による発表になります。
MLOps コミュニティでは次回以降の発表者を募集しております。発表したい方はこちらより奮ってご応募ください!
発表申し込みフォーム
ハッシュタグ:#mlopsコミュニティ
発表内容
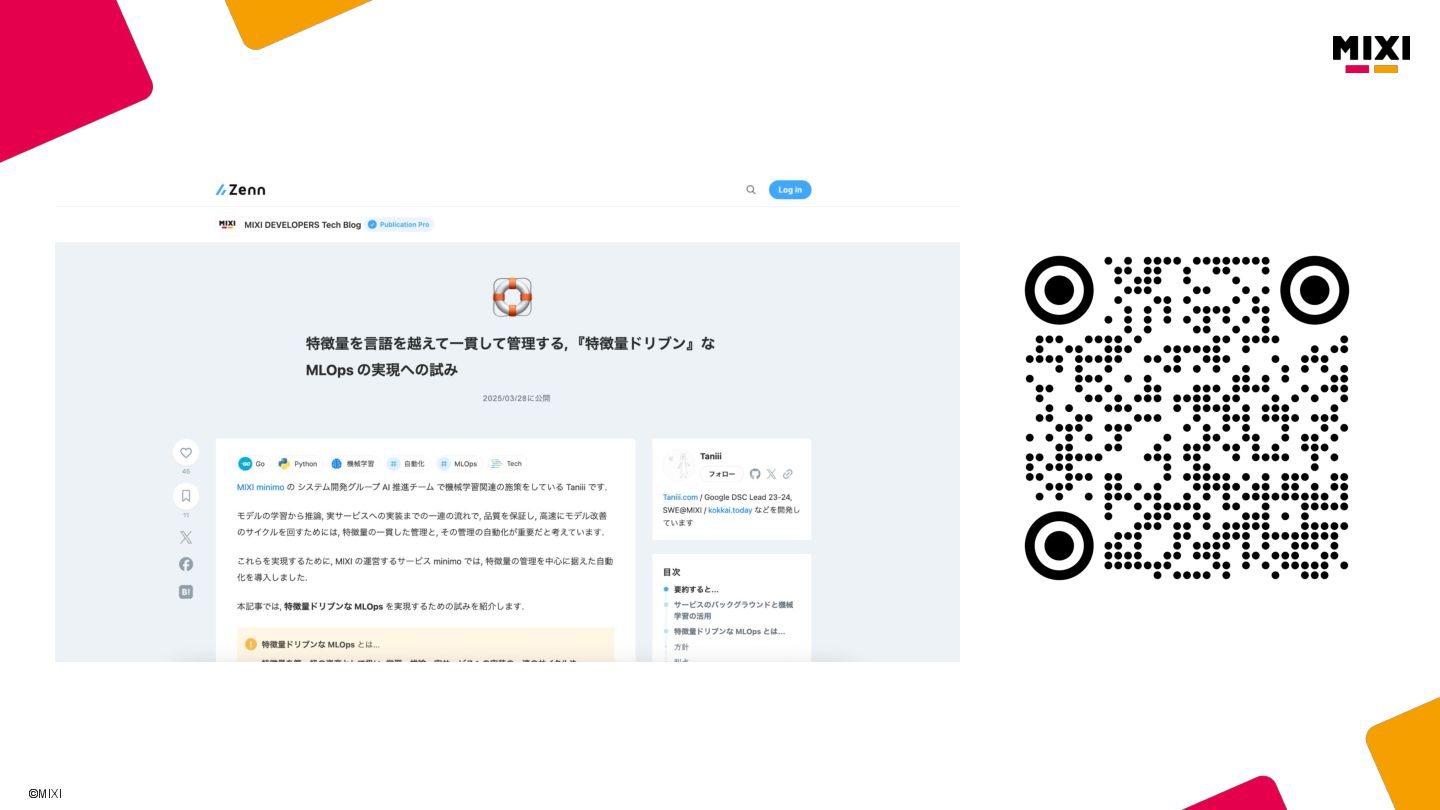
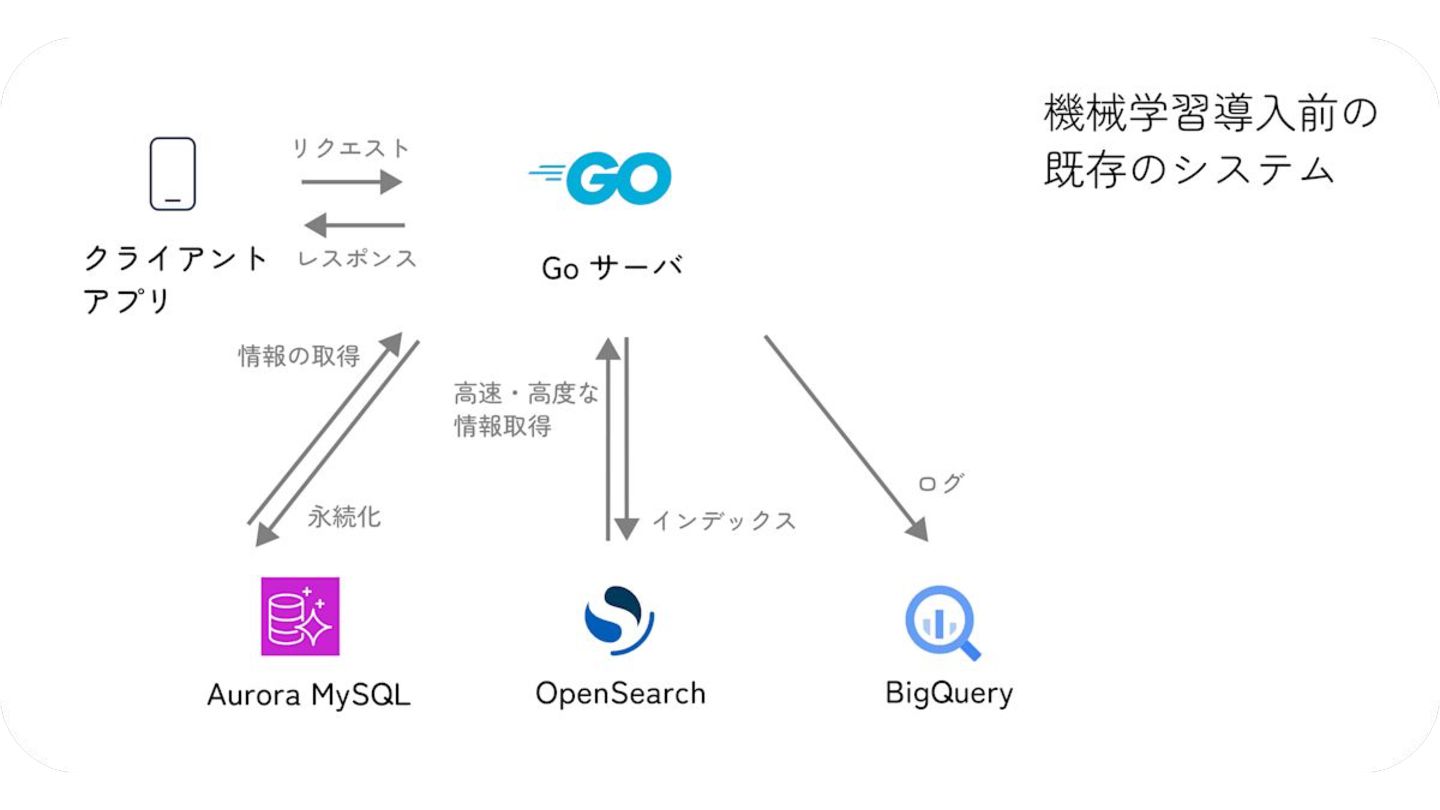
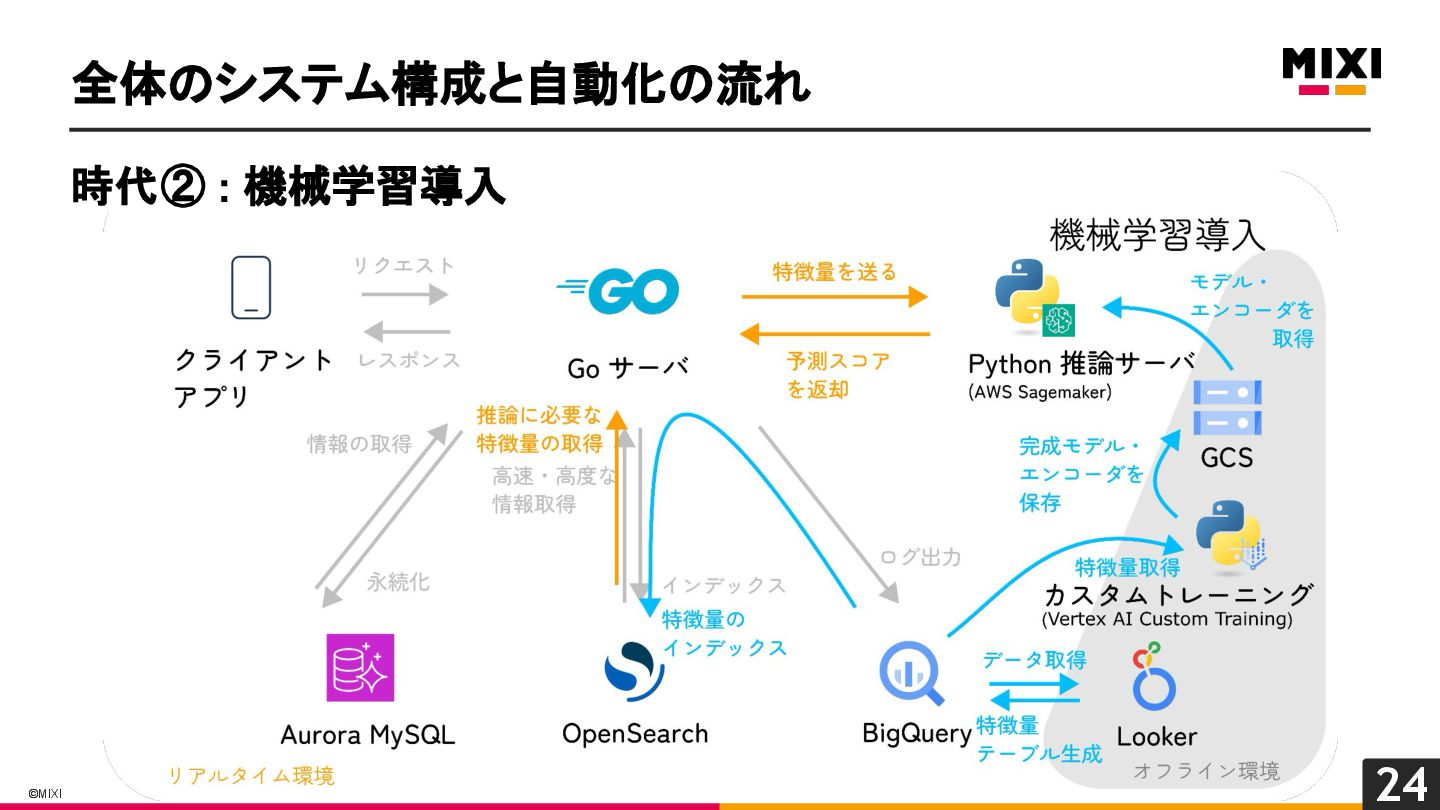
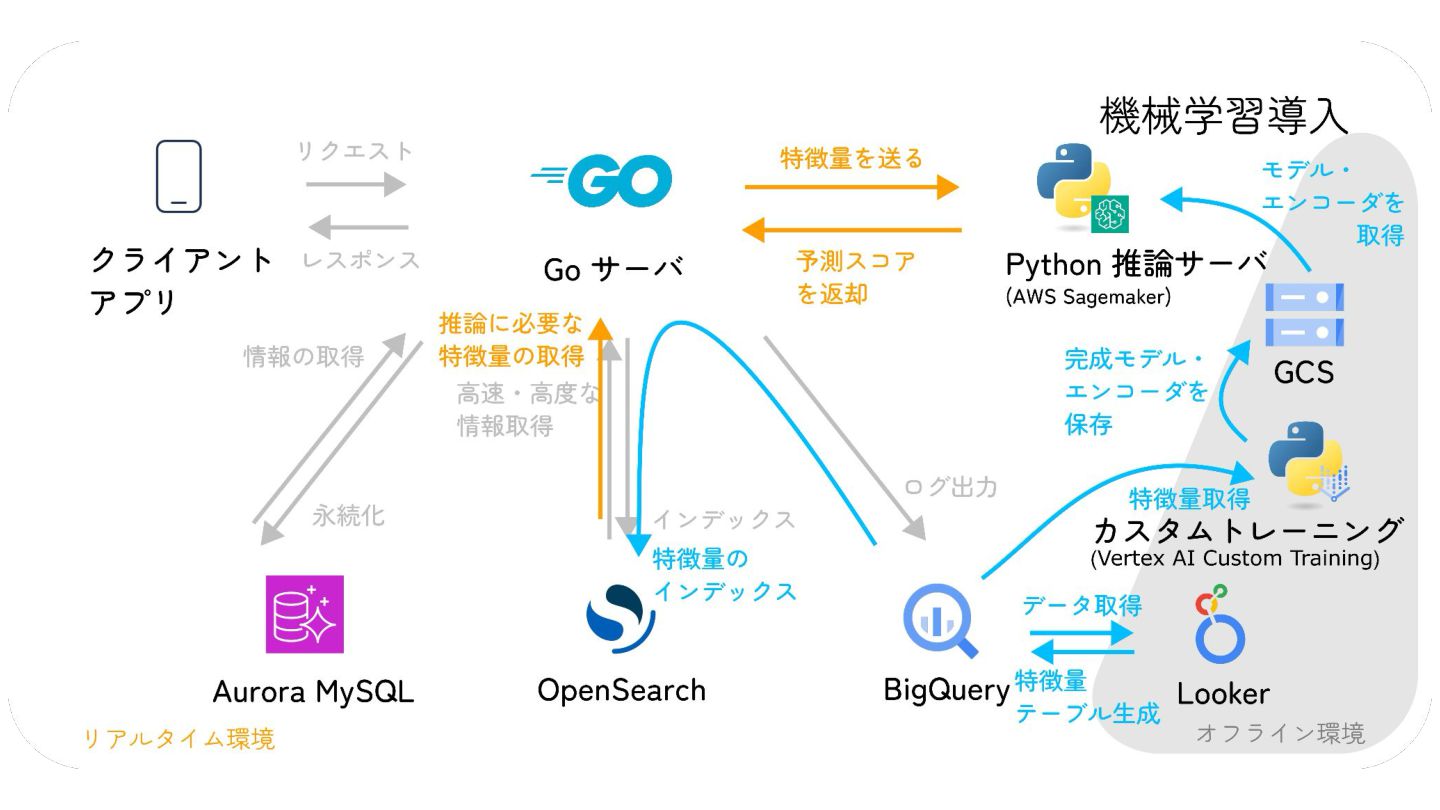
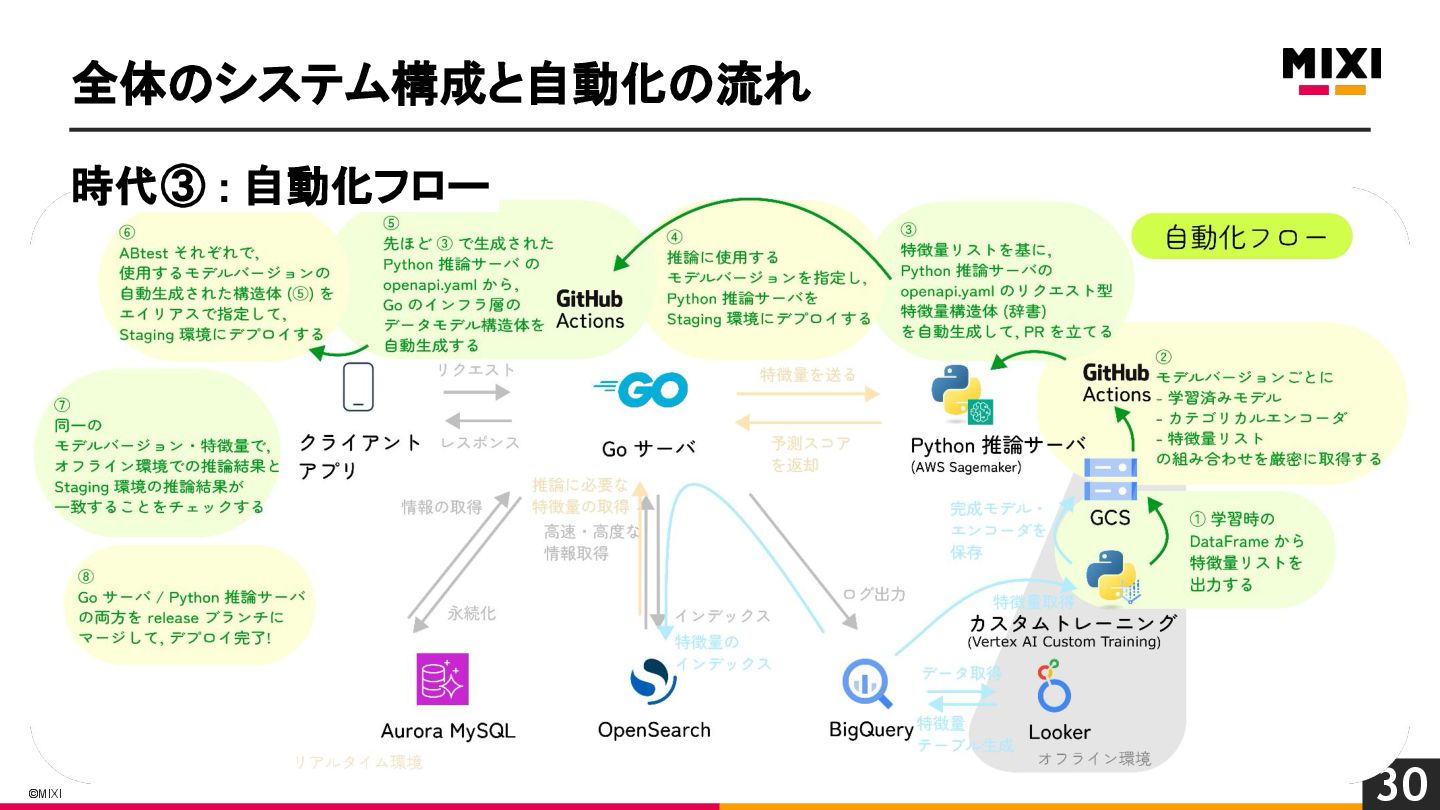
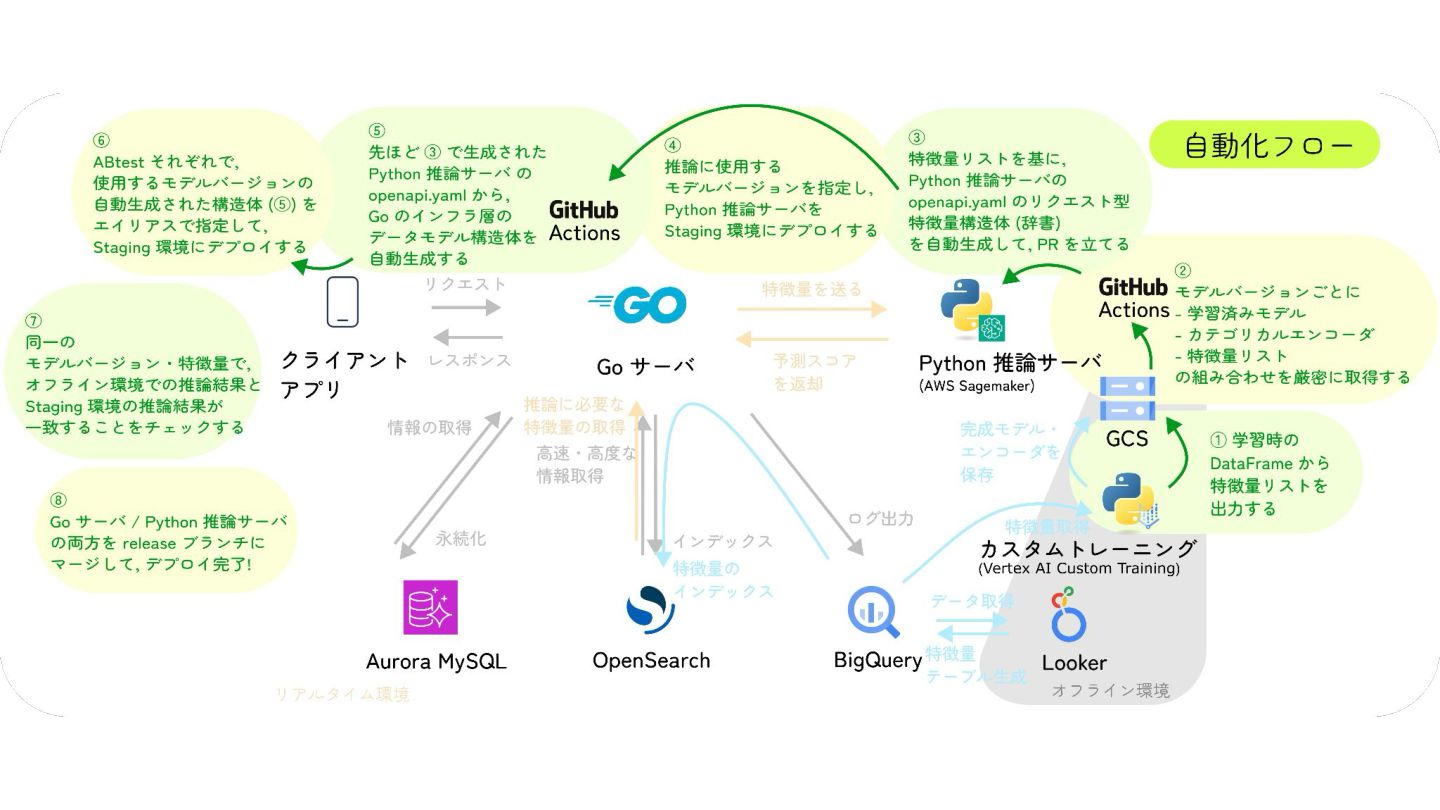
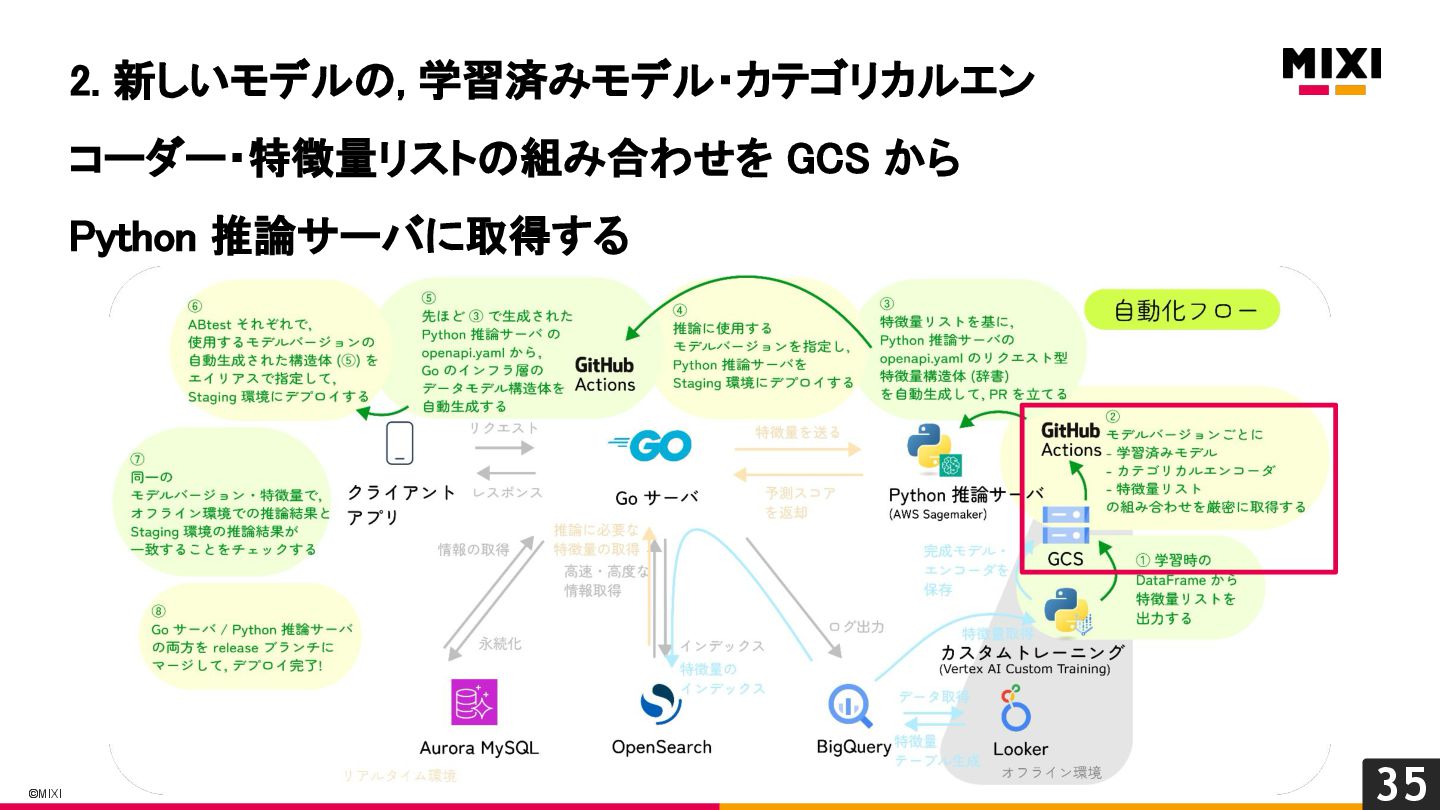
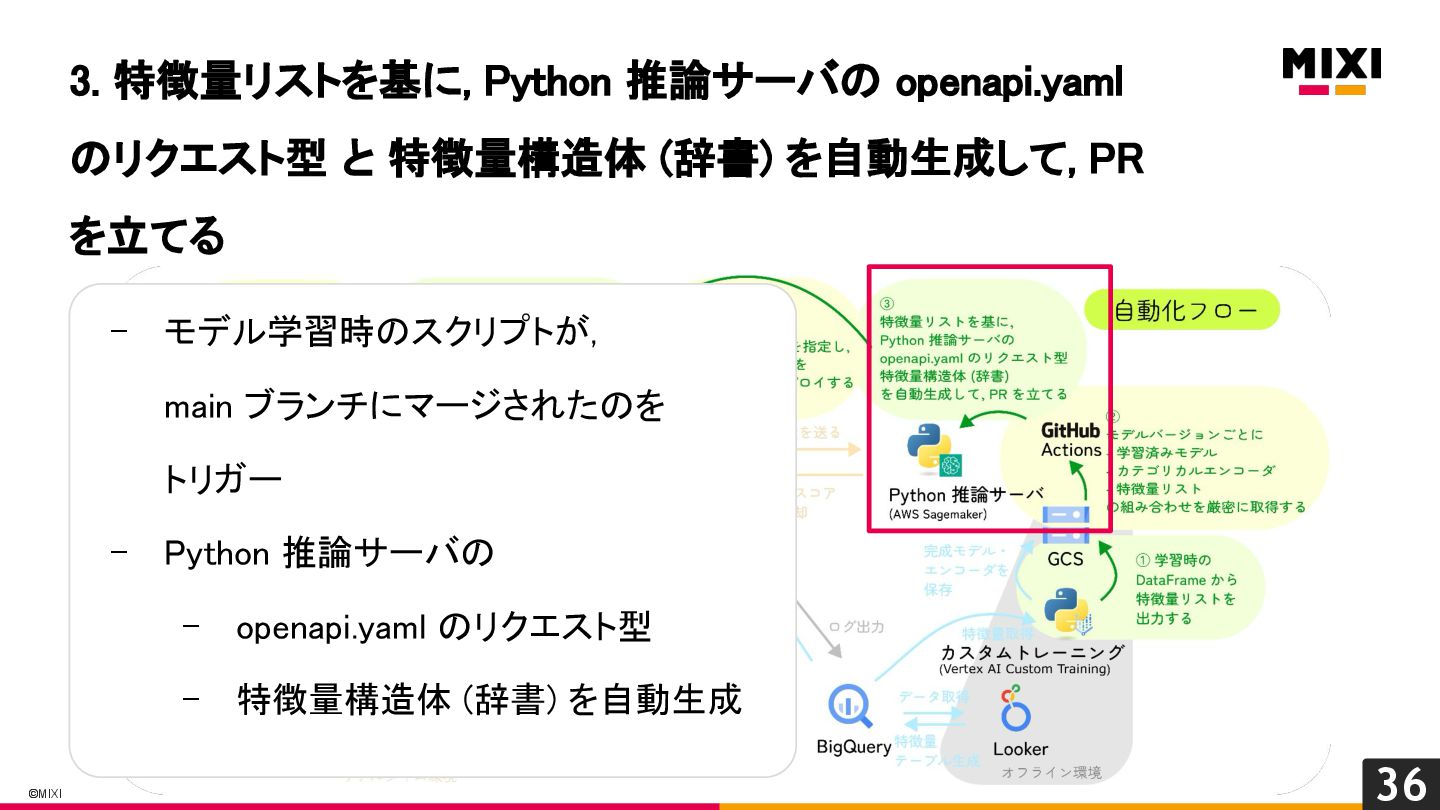
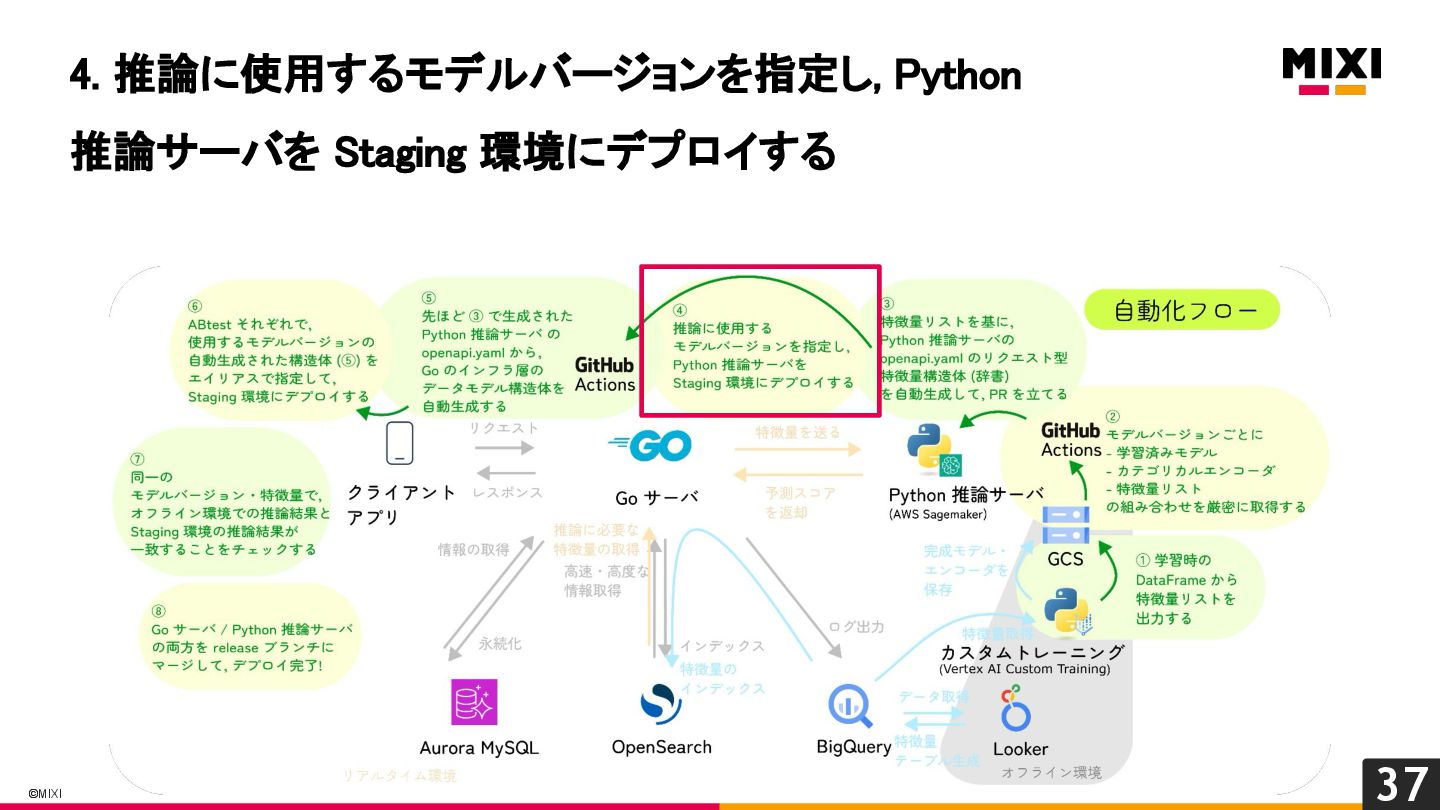
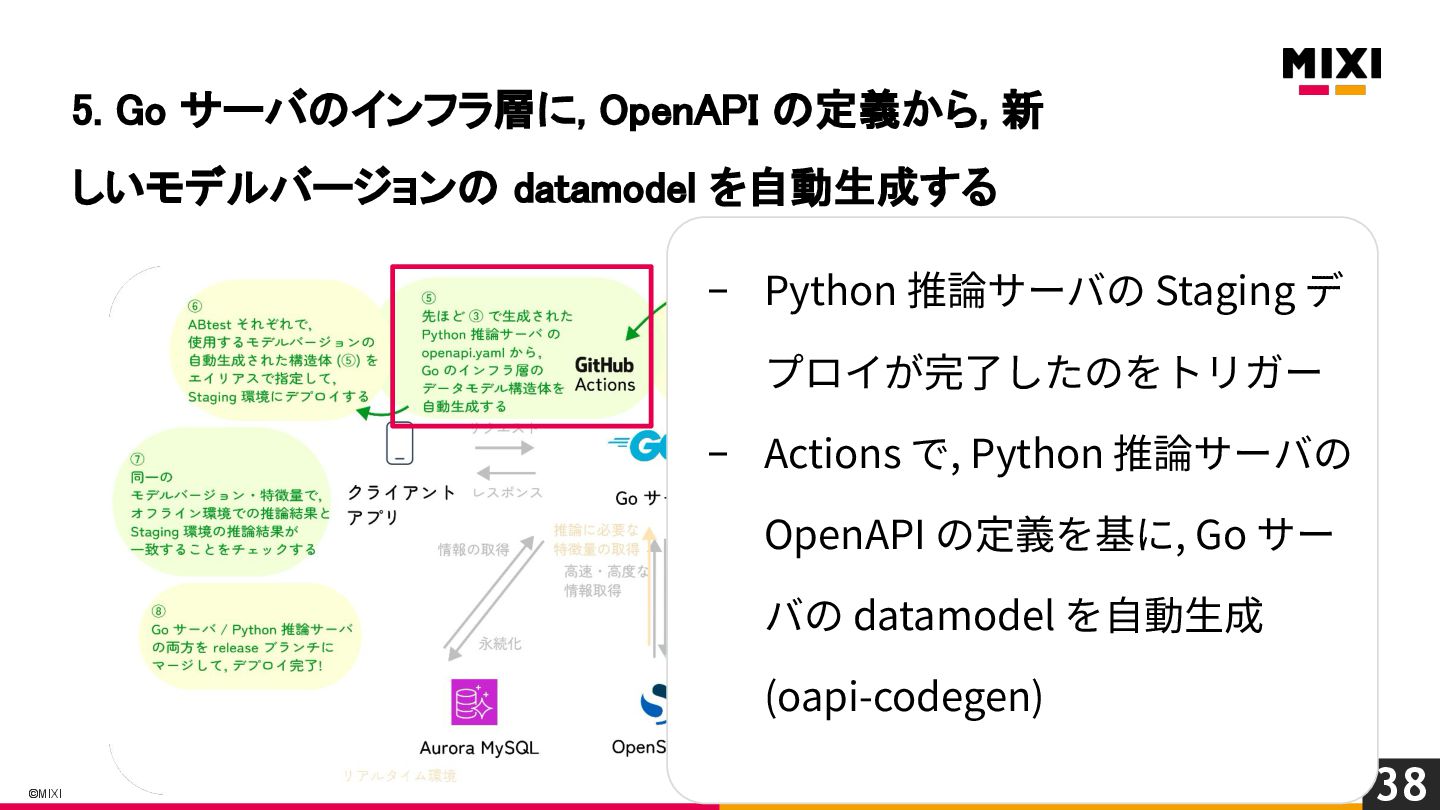
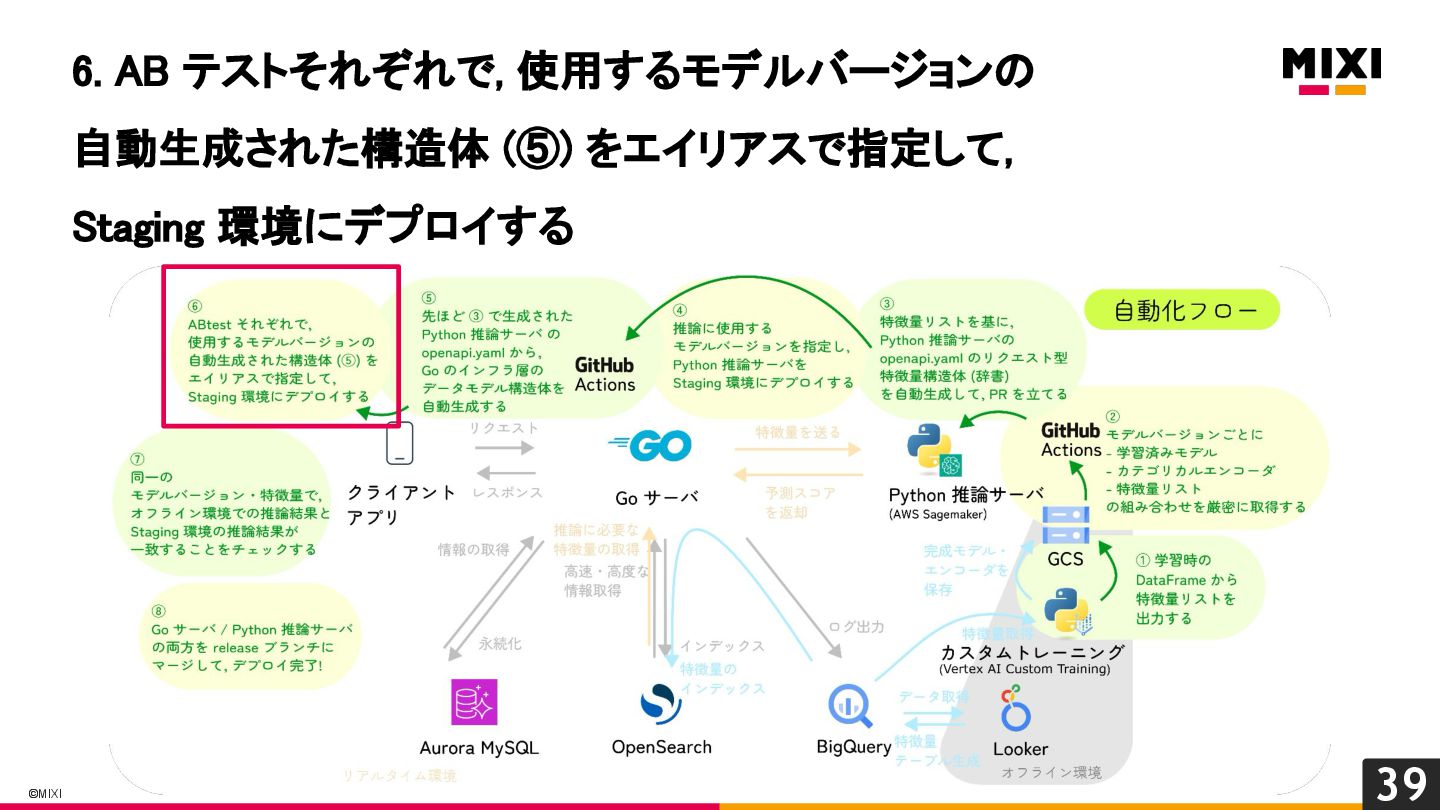
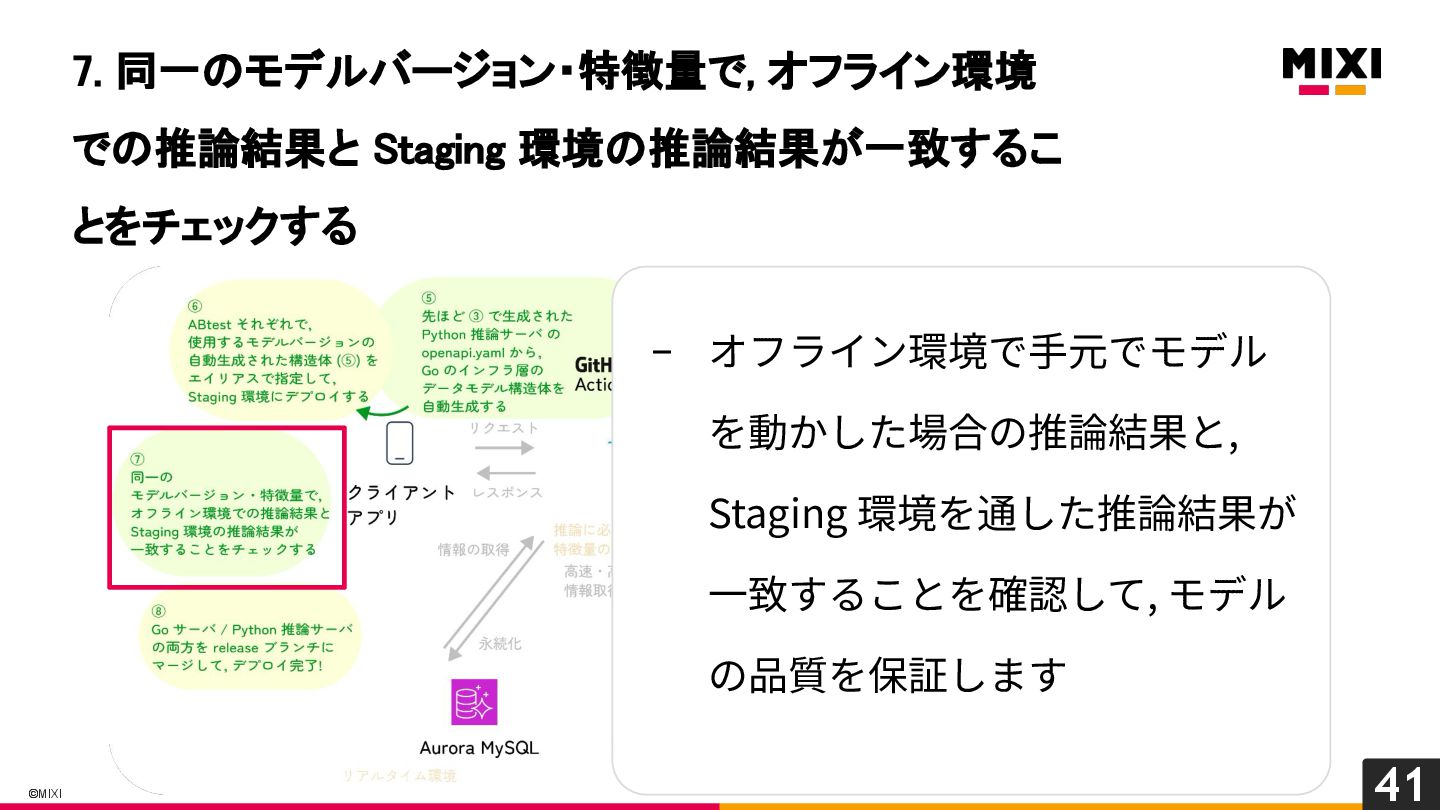
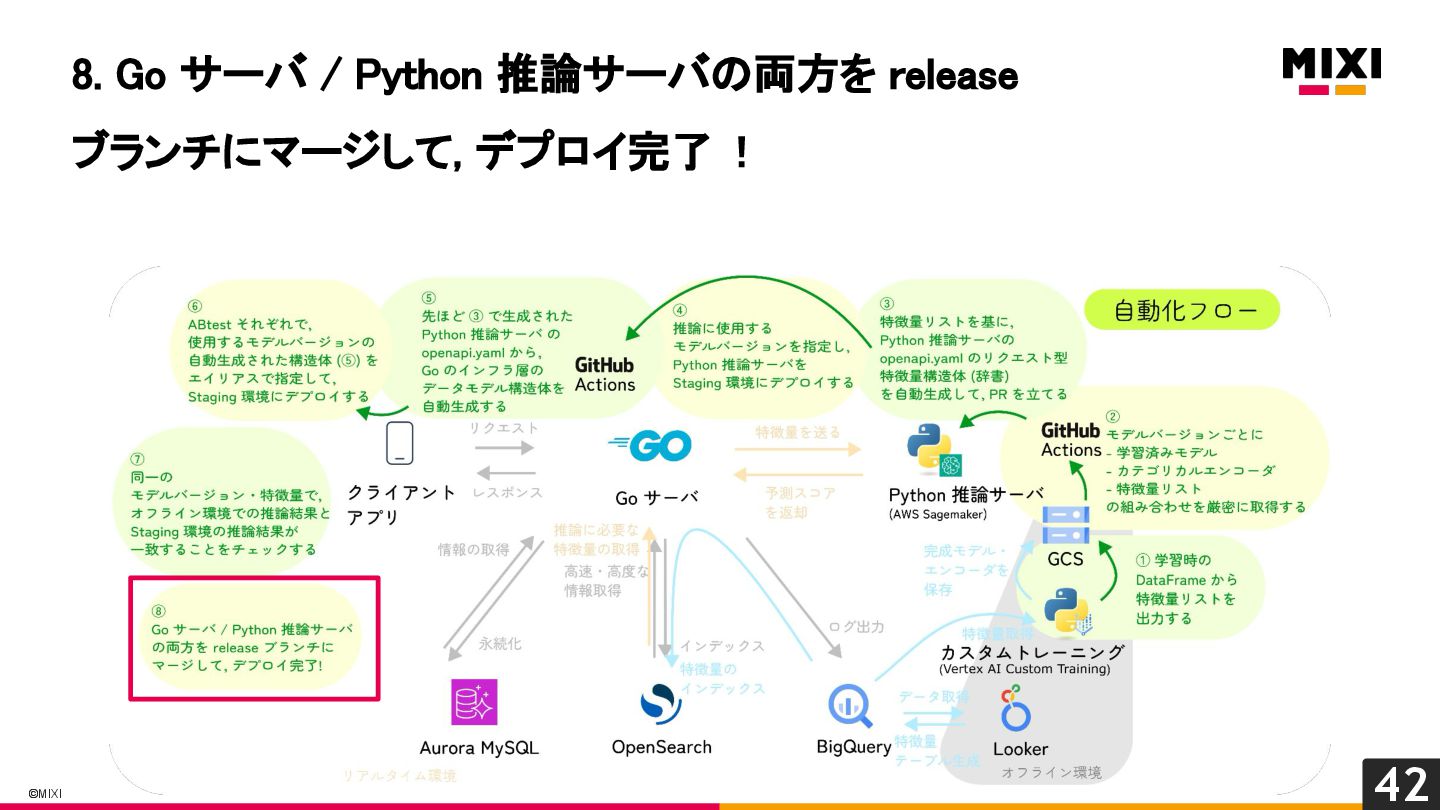
特徴量を言語を越えて一貫して管理する, 『特徴量ドリブン』な MLOps の実現への試み
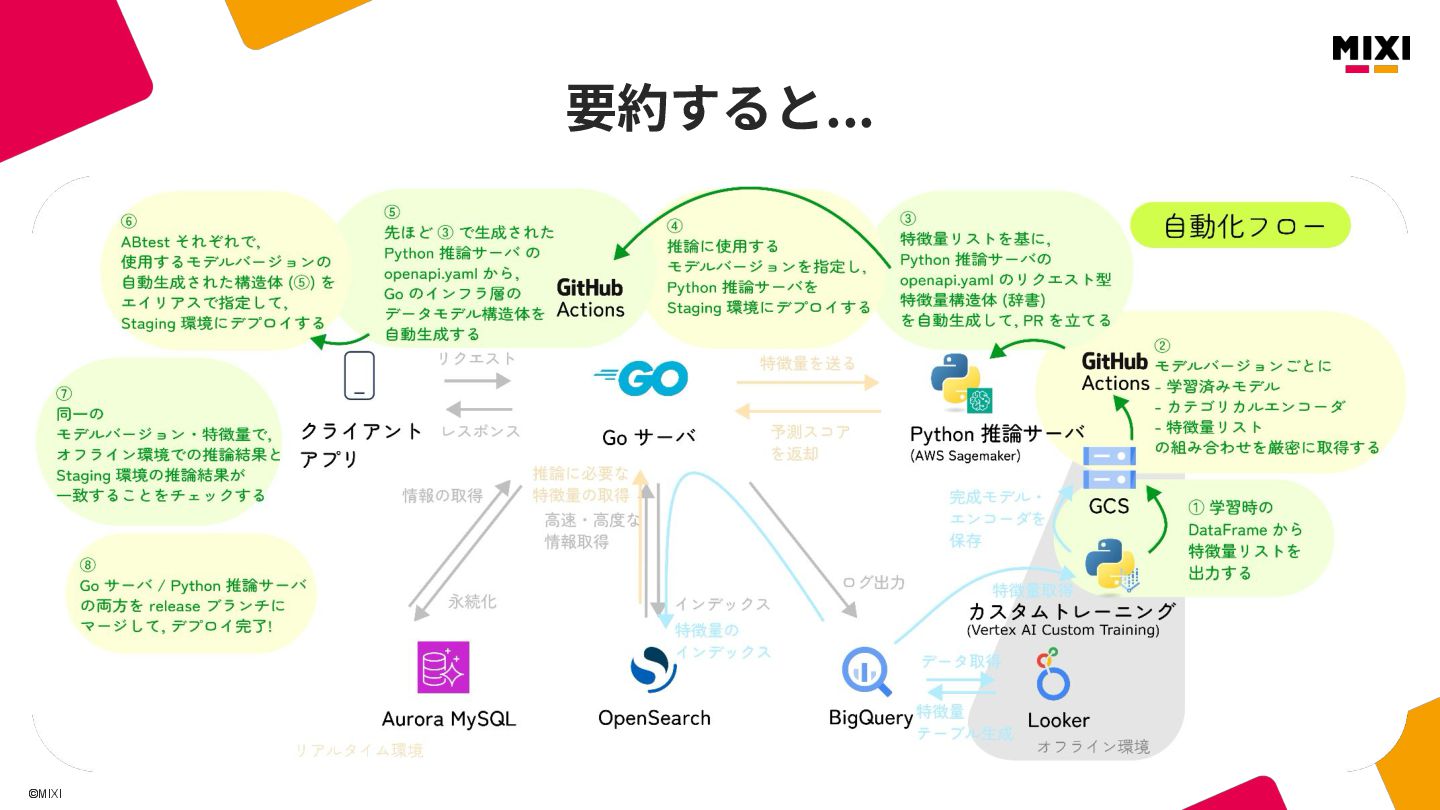
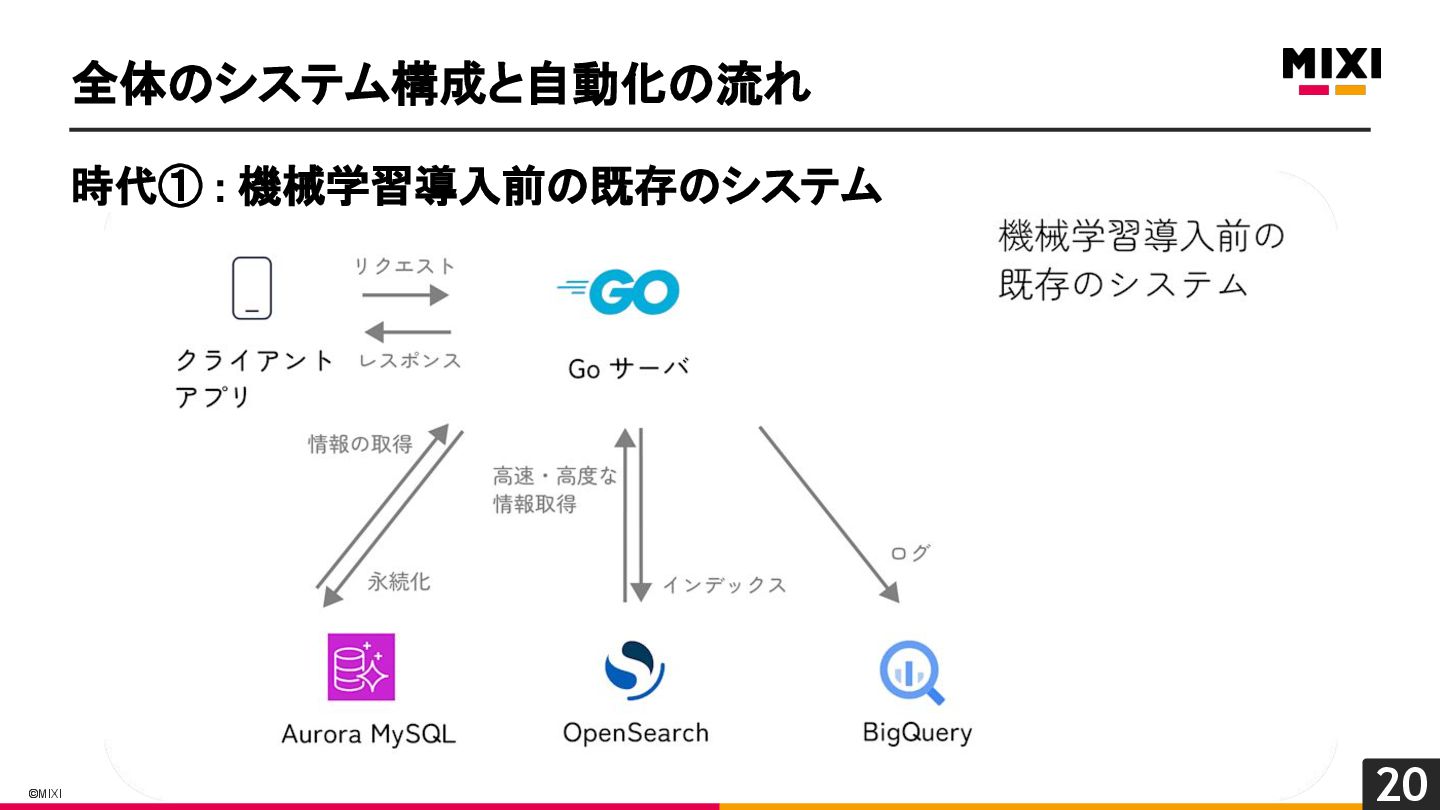
MIXI の運営するサービス minimo は、今年リリースから11周年を迎え、より最適な体験のためにAI/機械学習の導入を進めています。 モデルの学習から推論、実サービスへの実装までの一連の流れで、品質を保証し、高速にモデル改善のサイクルを回すためには、特徴量の一貫した管理と、その管理の自動化が重要だと考えています。 これらを実現するために、minimo では特徴量の管理を中心に据えた自動化を導入しました。 今回は、特徴量ドリブンな MLOps を実現するために行なった試みを紹介します。
関連記事: https://zenn.dev/mixi/articles/mixi-feature-driven-mlops
株式会社MIXI 谷 知拓 (Taniii)
株式会社MIXI minimo事業部 システム開発グループ AI推進チーム。最近は、既存サービスへのAI/機械学習の導入を中心に起案から設計・実装まで行なっています。大学では、LLMを用いた汎用推薦システムの研究をしています。個人開発も好きです。
X: https://x.com/taniiicom
企業ページ: https://mixi.co.jp/
採用ページ: https://mixigroup-recruit.mixi.co.jp/jobs/
MLOps ツール “Knitfab” を作ったワケ
私達は MLOps を支援する基盤となるツール “Knitfab” を開発しています。 この製品は、私達が参画した機械学習モデル開発の経験から、ぜひ欲しい、と思って開発を始めたものです。 今回は、 Knitfab の生まれた経緯と、MLOps における我々のペインポイントとアプローチについてお話します。
高岡 陽太 様
株式会社オープンストリームで、MLOps 基盤ツール Knitfab を開発しています。
Knitfab on Github
会場
オンライン開催 (URLは別途ご案内)
タイムテーブル
時間 内容 スピーカー
19:00 ~ 19:10 はじめに MLOps勉強会事務局
19:10 ~ 19:35 特徴量を言語を越えて一貫して管理する, 『特徴量ドリブン』な MLOps の実現への試み 谷 知拓 (Taniii) 様
19:35 ~ 19:55 MLOps ツール “Knitfab” を作ったワケ 高岡 陽太 様
19:55 ~ 20:10 Q&A
20:10 ~ Ask-the-speaker
配信スポンサー
株式会社ディー・エヌ・エー様
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}