Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Anthropic「Long-running a gents」をGeminiで再現してみた
Search
t-kikuchi
April 30, 2026
Technology
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Anthropic「Long-running a gents」をGeminiで再現してみた
Anthropic「Long-running a gents」をGeminiで再現してみた
t-kikuchi
April 30, 2026
More Decks by t-kikuchi
See All by t-kikuchi
AgentGatewayを試してみたかった
tkikuchi
0
290
最低限これだけ押さえれ大丈夫_Claude Enterprise/Team企業展開ガバナンス入門
tkikuchi
1
1.7k
Vertex AI Agent Engine で学ぶ「記憶」の設計
tkikuchi
0
240
Gemini APIで音声文字起こし-実装の工夫と課題解決
tkikuchi
0
120
コンテキストエンジニアリングとは何か?〜Claude Codeを使った実践テクニックとコンテキスト設計〜
tkikuchi
0
130
バッチ処理をEKSからCodeBuildを使ったGitHub Self-hosted Runnerに変更した話
tkikuchi
1
230
Claude Code導入後の次どうする? ~初心者が知るべき便利機能~
tkikuchi
0
160
ClaudeCodeを使ってAWSの設計や構築をしてみた
tkikuchi
0
230
ClaudeCode_vs_GeminiCLI_Terraformで比較してみた
tkikuchi
1
11k
Other Decks in Technology
See All in Technology
reFACToring
moznion
1
870
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
660
オートマトンと字句解析でRoslynを読む
tomokusaba
0
120
AI工学特論: MLOps・継続的評価
asei
11
3k
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
530
AI時代の強いチームの作り方
yuukiyo
2
670
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.2k
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
310
AIがコードを書く時代、人間は何を保証するのか———馬場さんと考える、開発者に求められる新しい責任と価値 - TECH PLAY
netmarkjp
0
320
Claude Code並行開発環境の ムダ‧ムラ‧ムリを見直した話
muranakaaa
0
300
AI驚き屋発見器
yama3133
1
380
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
31
21k
Featured
See All Featured
Optimizing for Happiness
mojombo
378
71k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Practical Orchestrator
shlominoach
191
11k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.8k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
How GitHub (no longer) Works
holman
316
150k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
It's Worth the Effort
3n
188
29k
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Transcript
Google Cloud Next 2026 reCap Anthropic「Long-running agents」をGeminiで再現してみ た 2026/04/28 菊池
聡規 (とーち) (@tttkkk215) クラスメソッド クラウド事業本部
自己紹介 名前: 菊池 聡規(とーち) 部署: クラウド事業本部 普段の業務: AWS、Google Cloudのコンサルティングやピープルマ ネジメント
どちらかと言えばインフラ寄りの領域を担当 Xアカウント: https://x.com/tttkkk215 ブログ: https://dev.classmethod.jp/author/tooti/ 好きな技術: コンテナ、Terraform、生成AI 2
1. Google Cloud Next で聞いてきた Anthropicセッションの話 2. long-running agent の
5つのつまずき 3. ハーネス設計の 4つの柱 4. Google ADK + Gemini 3.1 Pro で再現してみた 5. まとめ アジェンダ 3
セッション概要 ここまで〜2分
タイトル: Long-running agents: Lessons from the enterprise frontier スピーカー: Harsh
Patel 氏 (Anthropic, Member of Technical Staff) 概要: 数時間単位で動作するエージェントを本番投入した知見の共有 注意: 話の前提は Claude Code ではなく Anthropic API (SDK) を使ったエージェント構築 セッション概要 5
long-running agentの機運とギャップ モデルの能力は 「6ヶ月ごとにタスク実行時間が倍になっ ている」 という進化 Claude 3 Opus (2024年):
4分程度 → Opus 4.6 (現 在): 12時間程度 一方、現実の顧客からは「15〜30分は動いて、それなり のものができる。が、そこで止まってしまい仕様の細部ま で作り切れない」 このギャップをどう埋めるかがセッションのテーマ 6
モデルがハマる5つのつまずきパターン ここまで〜4分
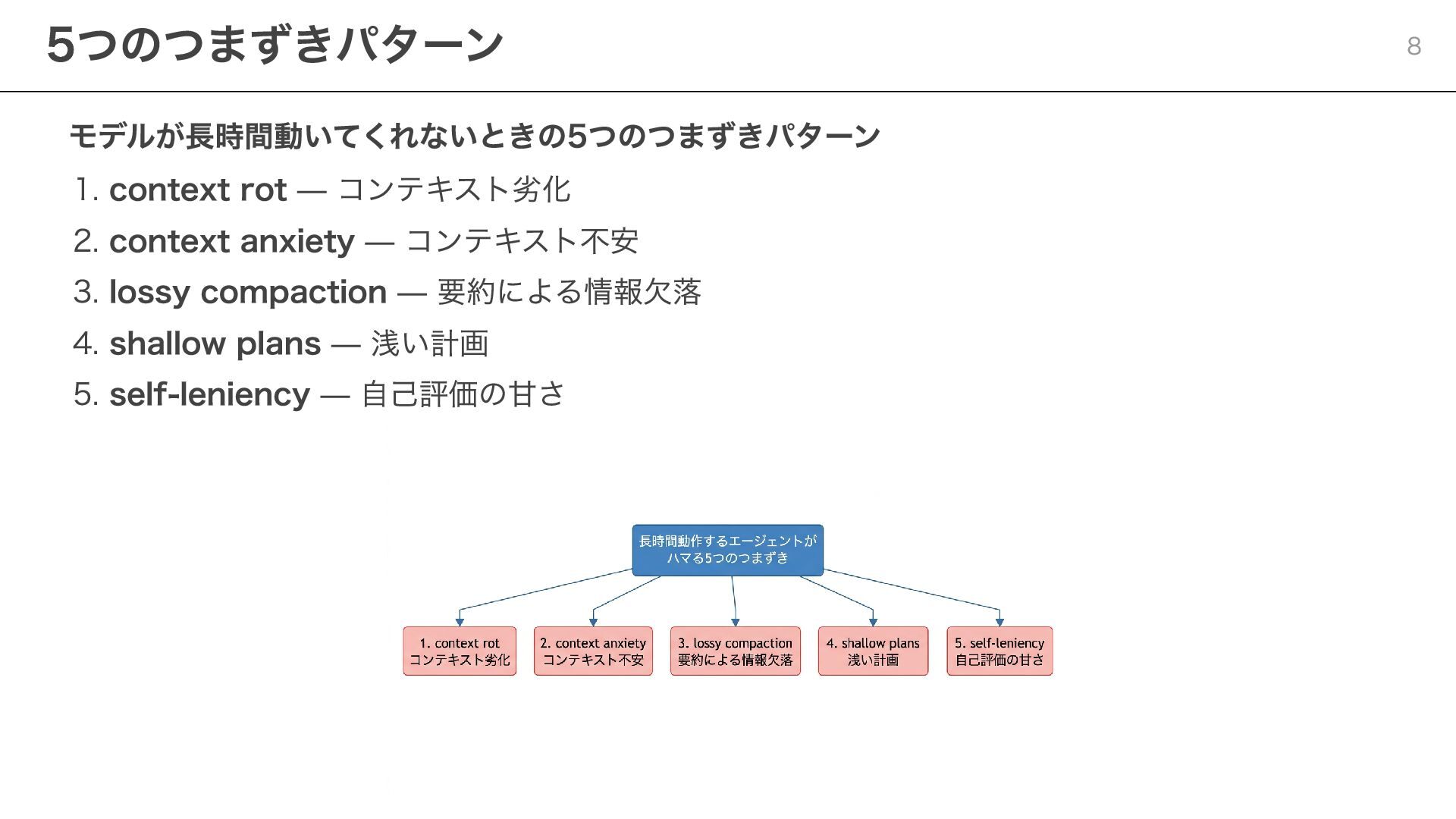
モデルが長時間動いてくれないときの5つのつまずきパターン 1. context rot — コンテキスト劣化 2. context anxiety —
コンテキスト不安 3. lossy compaction — 要約による情報欠落 4. shallow plans — 浅い計画 5. self-leniency — 自己評価の甘さ 5つのつまずきパターン 8
context rot (コンテキスト劣化): トークンが増えるほど、新しいトークンが過去の全トークンに注意を向けねばならず、序盤の 重要な仕様を思い出す精度が落ちる たとえ話: 「1000ページのマニュアルを渡した新人より、2〜3ページの絞り込んだ資料を渡し た新人のほうがきっちり仕事を終わらせる」 context anxiety
(コンテキスト不安): 200K トークン上限が近づくとモデルが焦り出し、 「終わっていないタスクを全部終わったこと にする」 振る舞い context rot / context anxiety 9
lossy compaction (要約による情報欠落): compactionをすると、細部の情報が落ちる。Sonnet 3.5 では圧縮後も context anxiety の 焦り挙動が消えずに残るケースが観察された
shallow plans (浅い計画): 大きな指示を投げると、モデルがテストやエラーハンドリングなど本番に必要な仕組みを考慮 せず、表面的な機能だけを実装し始める self-leniency (自己評価の甘さ): Claude に自身の仕事を評価させると寛容に「できています」と自己肯定する傾向 検証が必要な用途では、別途批判的なフィードバックの仕組みが必須 lossy compaction / shallow plans / self-leniency 10
ハーネス設計の4つの柱 ここまで〜8分
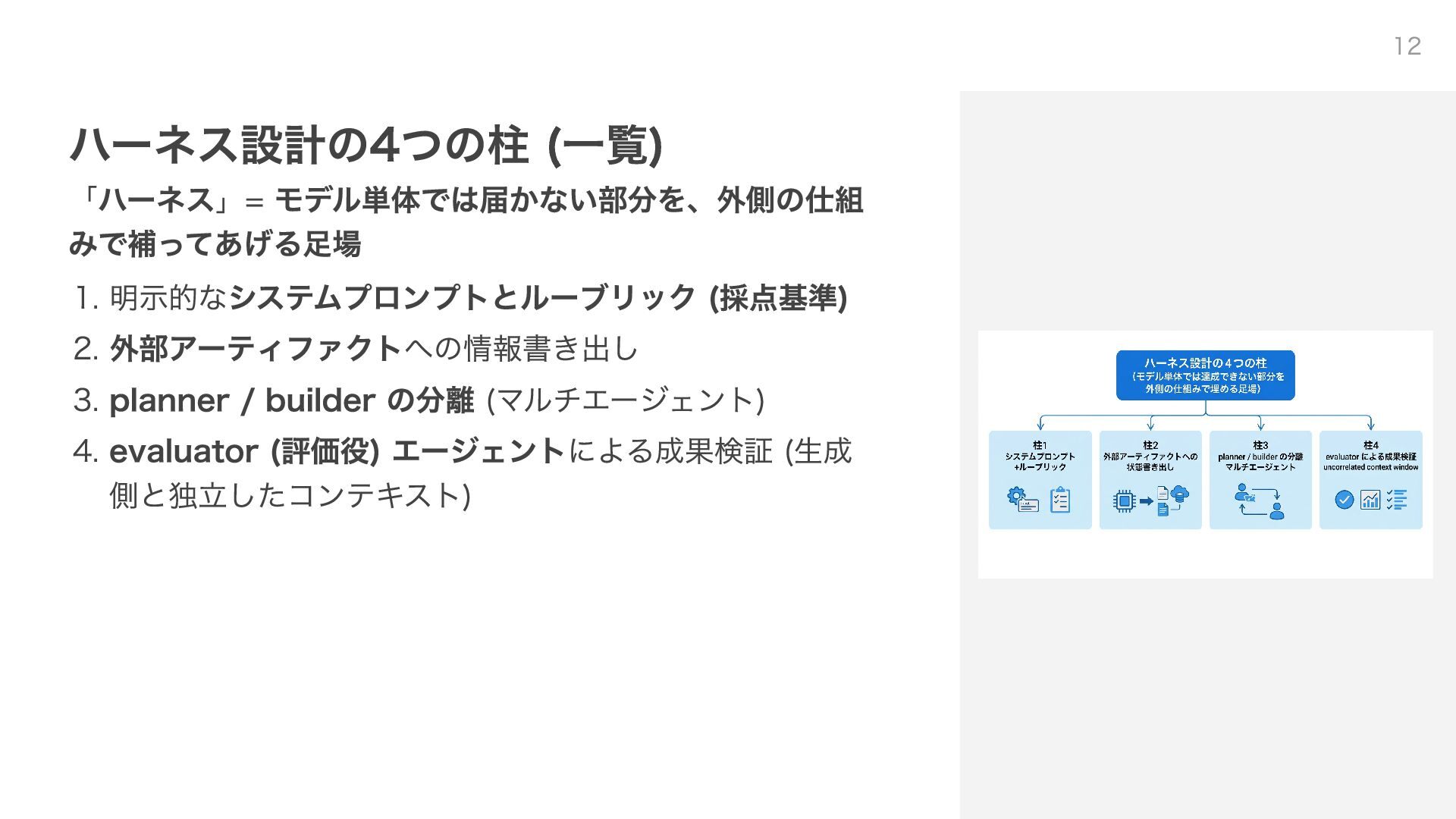
ハーネス設計の4つの柱 (一覧) 「ハーネス」= モデル単体では届かない部分を、外側の仕組 みで補ってあげる足場 1. 明示的なシステムプロンプトとルーブリック (採点基準) 2. 外部アーティファクトへの情報書き出し
3. planner / builder の分離 (マルチエージェント) 4. evaluator (評価役) エージェントによる成果検証 (生成 側と独立したコンテキスト) 12
システムプロンプト + ルーブリック (評価基準) を明示的に設計 ルーブリックには「コードスタイル」 「設計方針」 「アーキテクチャ判断基準」などを記述 evaluator エージェントと組み合わせて使う前提
システムプロンプトとルーブリック 13
コンテキストウィンドウに全部抱え込まず、外部の永続成果物に状態を書き出す 例: features.json に「作るべき機能 + 各機能のテスト」を全部列挙しておく 進め方: 1セッションで扱うのは その中の1機能だけ i.
その機能の仕様 + テストを読み込む ii. テストが通るまで実装 iii. 完了したらコミットしてセッションを閉じる iv. 次の機能は 新しいセッション (新しいコンテキスト) で features.json を読み直すところか らやり直し → context rot, context anxiety, lossy compaction の同時対策 外部アーティファクトへの情報書き出し 14
shallow plans の対策として、計画と実装を別エージェントに分離 planner エージェント: 最終形をにらみながら機能を細かく分解し、仕様に書き出す builder エージェント: planner の分解タスクを
1機能単位で実装 各エージェントはシステムプロンプトで専門化 一発指示でやらせるより、planner にじっくり仕様をほぐしてもらい builder が順に作る流れの 方が安定 planner / builder の分離 15
self-leniency への対応。生成側 (builder) と独立したコンテキスト で動く evaluator を立て る 構成要素 ルーブリック
(採点基準): 例 — デザイン品質 / 独創性 / 技術的実行 / 機能性 の4軸 完了の定義: 「どこまでできたら完了とみなすか」を事前に合意 ツール: Playwright MCP で実ページと直接対話、スクリーンショット取得・検証 発想は ソフトウェアの PR レビューと同じ — 実装者本人は設計判断に縛られるため、別視点で の見落とし発見が効く 実務 Tips: ルーブリック通りに動かないときは、エージェントの証跡 (transcript) を実際に読 んで evaluator の出力を確認し、ルーブリック・システムプロンプトに反映する反復作業 evaluator による成果検証 16
各モデルには「安定してこなせるタスク領域」があり、その形はでこぼこ ハーネスの役割は この「信頼できる領域」を外側に押し広げること 新しいモデルが出たら、ハーネスの前提は一度崩して検証し直す 例: Sonnet 3.5 では context anxiety
回避のため積極的なコンテキストリセット (窓全体破 棄・外部化状態から再スタート) が必要だった Opus 3.6 では「経験的にそこまで厳格なリセットは必要なかった」 実務原則 ハーネスはできるだけシンプルに作る 新モデル投入時は仕掛けを1つずつ外して挙動確認 そのモデルに不要になった足場は取り除く ハーネスはシンプルに保ち、新モデルが出たら見直す 17
【実践】Google ADK + Gemini 3.1 Proで再現してみた ここまで〜12分
動機: Google Cloud Next reCapなので、同じパターンを Google スタックで組んでみる 採用技術 Google ADK
(Agent Development Kit) Gemini 3.1 Pro Preview (Vertex AI global endpoint) ソースコード: https://github.com/ice1203/gemini-coding-agents 【実践】Google ADK + Gemini 3.1 Proで再現してみた 19
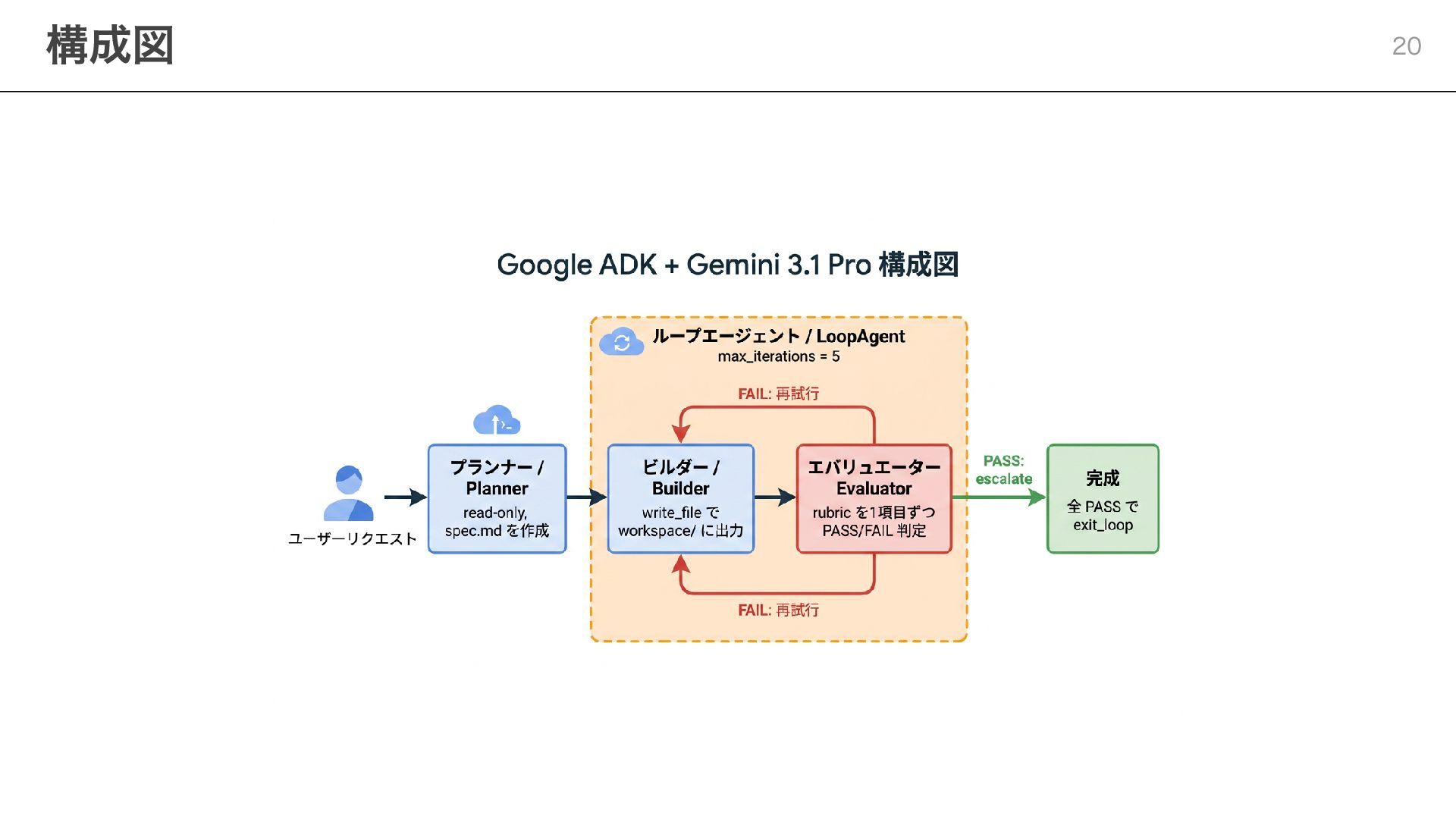
構成図 20
planner = LlmAgent(..., tools=[read_rubric, write_file], output_key="spec") builder = LlmAgent(..., tools=[write_file,
read_file, list_workspace], output_key="builder_log") evaluator = LlmAgent(..., tools=[read_file, verify_html, exit_loop], output_key="evaluation") refine_loop = LoopAgent(sub_agents=[builder, evaluator], max_iterations=5) planner: コードは書かず write_file で workspace/spec.md に仕様を書き出す builder: write_file で生成物を workspace/ に出力 (lossy compaction 対策) evaluator: verify_html で実機検証 → 全 PASS で exit_loop を呼んでループ脱出 output_key でエージェント間の状態受け渡し (次スライドで詳細) ADK実装の要点 21
# planner の出力テキストが自動で session.state["spec"] (dict) に保存される planner = LlmAgent( instruction="仕様を
spec.md に書き出してください", output_key="spec", ) # builder の instruction 実行前に {spec} が state["spec"] の中身に置換される builder = LlmAgent( instruction=( "以下の仕様に従って実装してください\n" "# spec\n{spec}\n" # state["spec"] が注入される "# 直前の評価\n{evaluation?}\n" ), output_key="builder_log", ) session.state はキーと値のペアを保持する dict デフォルト ( InMemorySessionService ) はメモリのみ。 VertexAiSessionService 等に切り 替えると永続化可能 コンテキストウィンドウを共有せず、状態だけを引き渡すのがポイント コード: output_key によるエージェント間の状態受け渡し 22
# builder <-> evaluator を最大5回ループ refine_loop = LoopAgent( name="RefineLoop", sub_agents=[builder,
evaluator], max_iterations=5, ) # planner → refine_loop を順番に実行 root_agent = SequentialAgent( name="PlanBuildEval", sub_agents=[planner, refine_loop], ) LoopAgent が builder/evaluator を反復。evaluator が exit_loop を呼ぶとループ脱出 SequentialAgent で planner → ループの順序を保証 コード: エージェントの組み合わせ方 23
ハーネス設計の要素 ADKでの実装 別エージェントへの委譲 sub_agents 互いに独立したコンテキストウィンドウ 別 LlmAgent として定義 外部成果物への状態書き出し (例:
features.json ) workspace/spec.md , workspace/<生成物> 長時間実行のループ制御 LoopAgent ( max_iterations + escalate ) Anthropic設計パターンとの対応 24
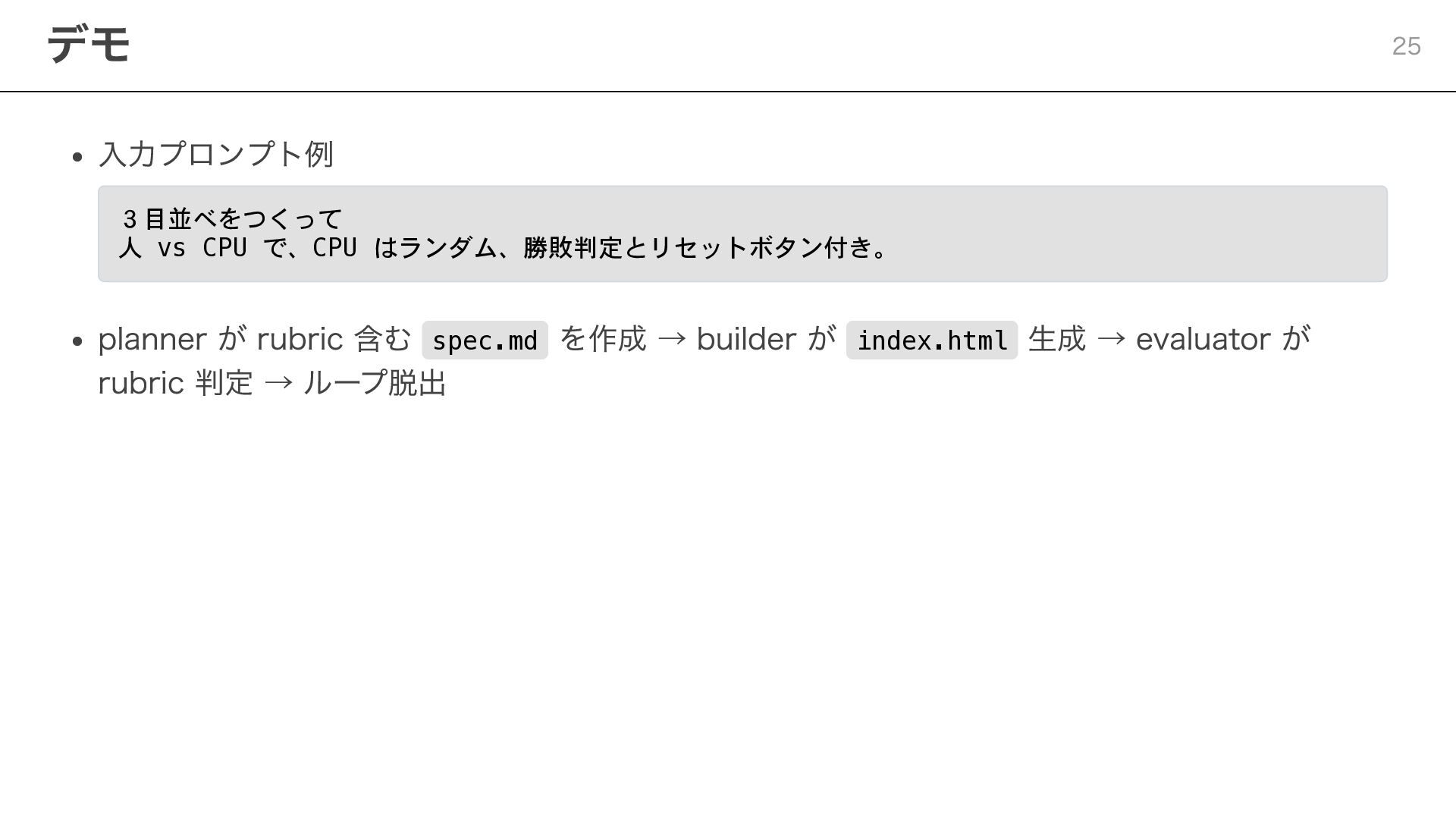
入力プロンプト例 3目並べをつくって 人 vs CPU で、CPU はランダム、勝敗判定とリセットボタン付き。 planner が rubric
含む spec.md を作成 → builder が index.html 生成 → evaluator が rubric 判定 → ループ脱出 デモ 25
uv run adk web agents/ だけでローカルにチャットUIが立ち上がる 手軽さがすごい 検証が速くできる planner /
builder / evaluator の分離は、モデルに依存しない汎用的なハーネスパターン である ことを実感 実装してみた所感 26
5つのつまずき (rot / anxiety / compaction / shallow plans /
self-leniency) 4つの柱 (プロンプト + ルーブリック (採点基準) / 外部 artifact / planner-builder 分離 / evaluator) ハーネスはシンプルに、新モデルで見直す planner / builder / evaluator の発想は Claude Code のスキル設計にも転用できそう まとめ 27
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![planner = LlmAgent(..., tools=[read_rubric, write_file], output_key="spec") builder = LlmAgent(..., tools=[write_file,](https://files.speakerdeck.com/presentations/b494a302411b4dab8072f756f05233a9/slide_20.jpg){kind=link}
![# planner の出力テキストが自動で session.state["spec"] (dict) に保存される planner = LlmAgent( instruction="仕様を](https://files.speakerdeck.com/presentations/b494a302411b4dab8072f756f05233a9/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}