Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
コンテキストエンジニアリングとは何か?〜Claude Codeを使った実践テクニックとコンテキ...
Search
t-kikuchi
October 18, 2025
Technology
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
コンテキストエンジニアリングとは何か?〜Claude Codeを使った実践テクニックとコンテキスト設計〜
コンテキストエンジニアリングとは何か?〜Claude Codeを使った実践テクニックとコンテキスト設計〜
t-kikuchi
October 18, 2025
More Decks by t-kikuchi
See All by t-kikuchi
AgentGatewayを試してみたかった
tkikuchi
0
240
最低限これだけ押さえれ大丈夫_Claude Enterprise/Team企業展開ガバナンス入門
tkikuchi
1
1.5k
Anthropic「Long-running a gents」をGeminiで再現してみた
tkikuchi
0
980
Vertex AI Agent Engine で学ぶ「記憶」の設計
tkikuchi
0
230
Gemini APIで音声文字起こし-実装の工夫と課題解決
tkikuchi
0
120
バッチ処理をEKSからCodeBuildを使ったGitHub Self-hosted Runnerに変更した話
tkikuchi
1
220
Claude Code導入後の次どうする? ~初心者が知るべき便利機能~
tkikuchi
0
150
ClaudeCodeを使ってAWSの設計や構築をしてみた
tkikuchi
0
230
ClaudeCode_vs_GeminiCLI_Terraformで比較してみた
tkikuchi
1
11k
Other Decks in Technology
See All in Technology
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
ADDF - ループエンジニアリングするフレームワークを作ったら/I Didn't Set Out to Build Loop Engineering, But ADDF Did
fruitriin
0
120
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
100
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
650
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.1k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
180
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
2
270
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
370
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
2
3.7k
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
150
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
140
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
570
Featured
See All Featured
Making the Leap to Tech Lead
cromwellryan
135
10k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
Designing for humans not robots
tammielis
254
26k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
So, you think you're a good person
axbom
PRO
2
2.1k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
From π to Pie charts
rasagy
0
230
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
Transcript
コンテキストエンジニアリングとは何か? 〜Claude Codeを使った実践とコンテキスト設計〜 クラスメソッド株式会社 2025/10/10 菊池聡規(@tttkkk215)
自己紹介 名前: 菊池 聡規(とーち) 部署: クラウド事業本部 普段の業務: AWSのコンサルティングやピープルマネジメント どちらかと言えばインフラ寄りの領域を担当 Xアカウント:
https://x.com/tttkkk215 ブログ: https://dev.classmethod.jp/author/tooti/ 好きな技術: コンテナ、Terraform、生成AI 2
本日のアジェンダ
1. 導入 (2分) 2. 理論編: Anthropicが語るコンテキストエンジニアリング (7分) 3. 実践編: 登壇者の実装例(ライブデモ)
(10分) 4. 対話編: あなたのコンテキストエンジニアリング (8分) 5. クロージング (2分) 本日のアジェンダ 4
目的 「コンテキストエンジニアリング」の具体的な実践方法を共有 双方向で知見を共有しあう場 アプローチ Anthropicの記事「Effective Context Engineering for AI Agents」を噛み砕いて説明
登壇者の実装例をライブデモ 参加者同士でディスカッション このセッションについて 5
理論編 Anthropicが語るコンテキストエンジニアリング
Anthropicの定義 プロンプトエンジニアリング = 上手く指示する技術 コンテキストエンジニアリング = 「LLMに渡す情報を設計する技術」あるいは継続的に情報 を構造化する技術 ※https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents より
コンテキストエンジニアリングとは 7
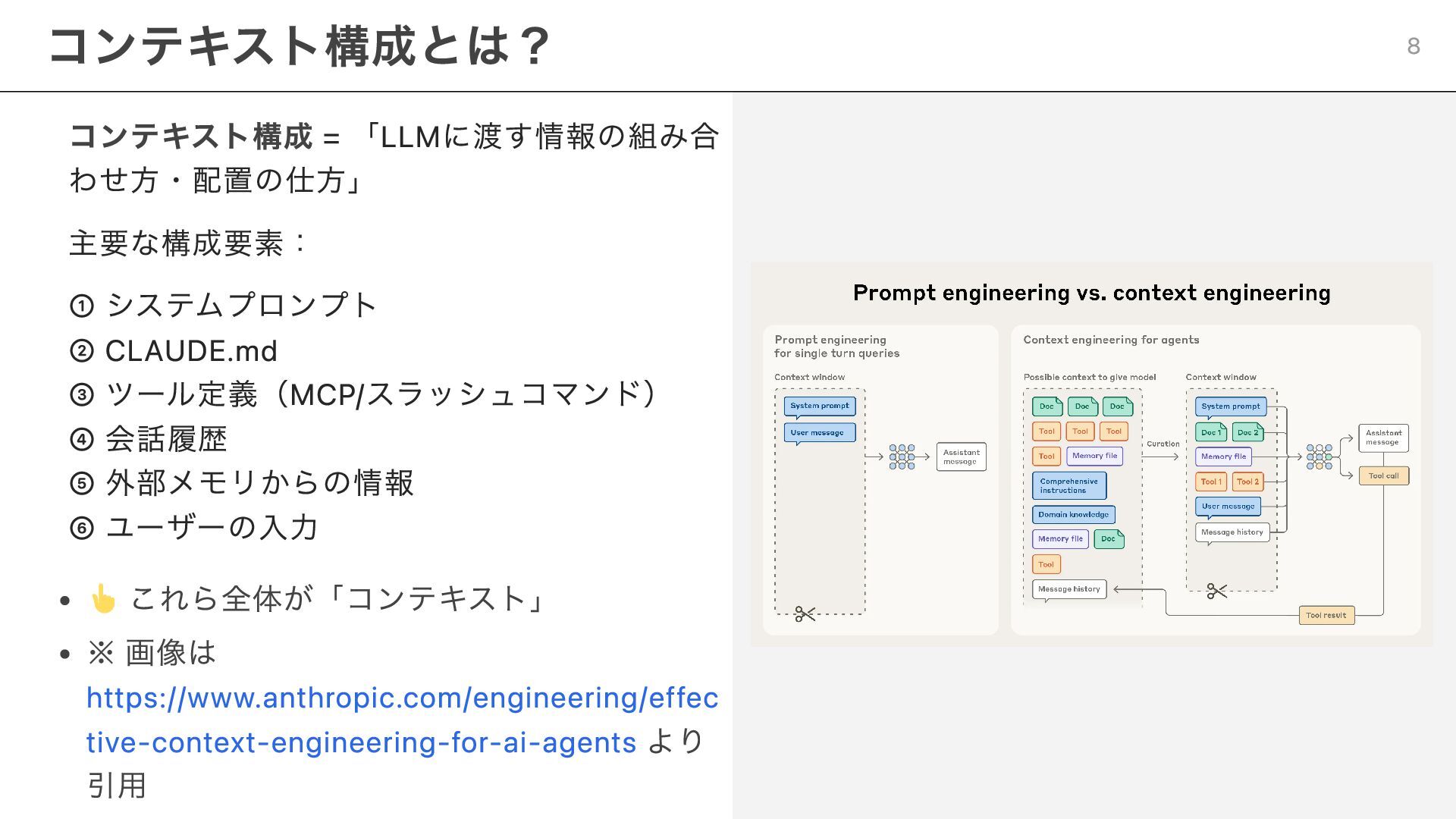
コンテキスト構成 = 「LLMに渡す情報の組み合 わせ方・配置の仕方」 主要な構成要素: ① システムプロンプト ② CLAUDE.md ③
ツール定義(MCP/スラッシュコマンド) ④ 会話履歴 ⑤ 外部メモリからの情報 ⑥ ユーザーの入力 これら全体が「コンテキスト」 ※ 画像は https://www.anthropic.com/engineering/effec tive-context-engineering-for-ai-agents より 引用 コンテキスト構成とは? 8
何故コンテキストエンジニアリングが必要か? 9
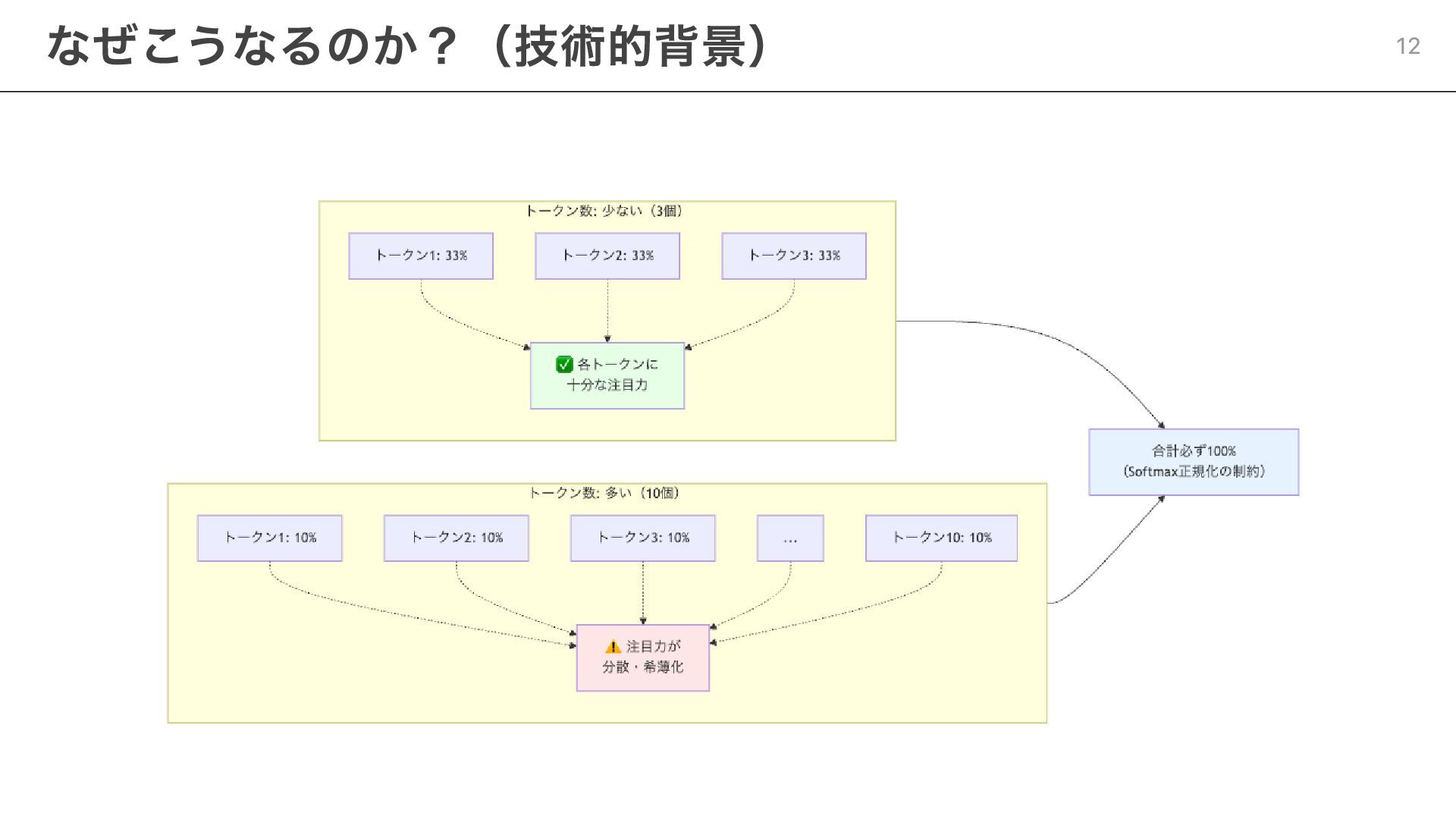
Attention Budget(注意予算) = 同時に効果的に処理できる情報量には限界がある 人間の例で理解 会議の議題が1つ(シンプル) ├── メインテーマに100%集中できる └── 細かい内容まで覚えている
会議の議題が5つ(複雑) ├── それぞれに20%ずつ分散 ├── 重要な点は覚えているが、細部は曖昧 └── 最初の方の議題を忘れかける 情報が増えるほど、1つあたりに割ける注意力が減る 具体的な制約:注意力の予算 10
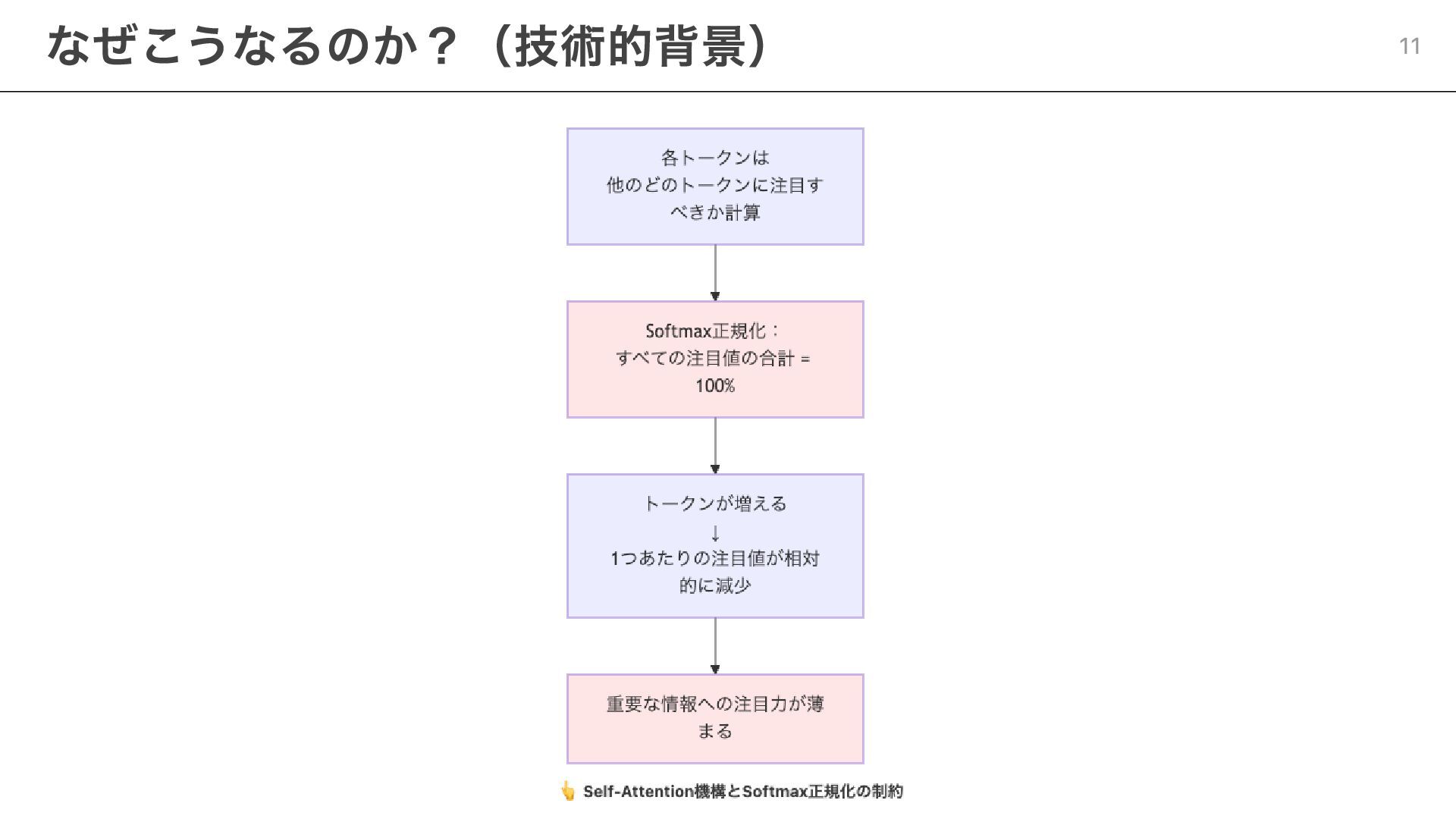
なぜこうなるのか?(技術的背景) 11
なぜこうなるのか?(技術的背景) 12
コンテキストウィンドウが大きい ≠ すべての情報を効果的に処理できる たくさん情報を渡せばいい、ではない 最小限の高信号情報で最大の効果を出す設計が必要 作業が長期化するほど、情報の「選別」が重要になる この制約から導かれる重要な原則 13
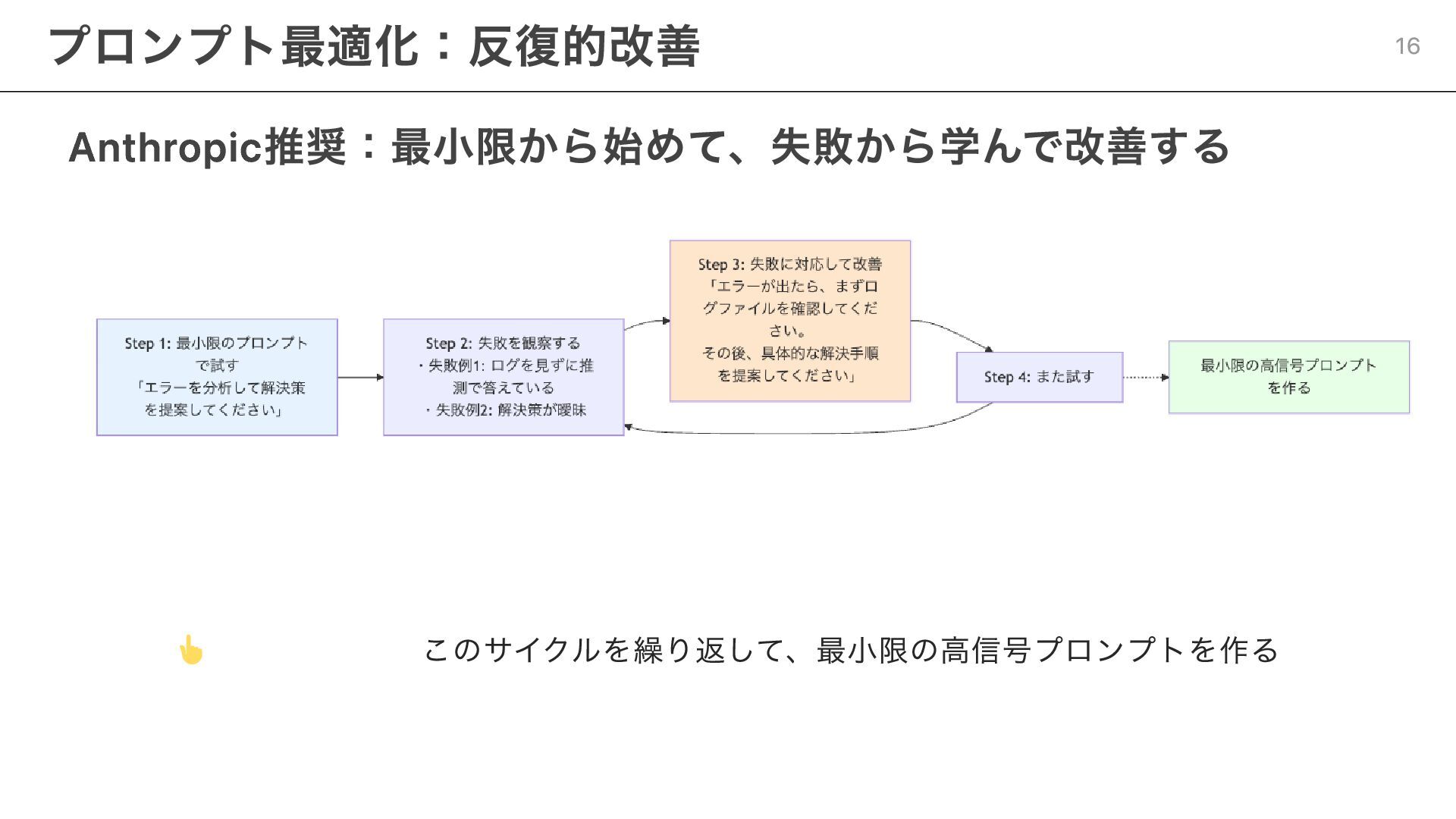
コンテキストの各要素を最適化する 実践例1: システムプロンプト 具体的すぎず(硬直的になる) 、抽象的すぎず(曖昧になる) 「適切な粒度」で記述する 実践例2: ユーザーの入力(プロンプト) 反復的改善: 最小限から始めて失敗から学ぶ
Few-shot: 多様で代表的な例を選ぶ 「最小限の高信号トークン」を意識 Anthropicの考え方 14
実践例3: 外部情報 全部渡さない(注意予算の無駄) 必要な情報だけ選別(Just in Time取得) 構造化して渡す 実践例4: ツール定義 全部有効にしない(トークン消費)
必要なものだけ絞る MCP、カスタムスラッシュコマンド、サブエージェントも対象 Anthropicの考え方(続き) 15
Anthropic推奨:最小限から始めて、失敗から学んで改善する このサイクルを繰り返して、最小限の高信号プロンプトを作る プロンプト最適化:反復的改善 16
短いだけ(情報不足) 「タスクを記録して」 → 曖昧すぎて動作が不安定 最小限だが十分(必要な情報は全部) 「タスク進捗を以下のフォーマットで記録してください: - 概要、実施内容、課題、次のステップ、環境情報」 → 長いが、これ以上削れない最小限
「最小限」≠「短い」 17
Anthropic: 「例は千の言葉に値する」 推奨: 多様で代表的な例を選ぶ 例: ナレッジを適切なフォルダに分類する - 明確: 「1on1(田中さん)」 →
07_Areas/ManagerWork/1on1/ - パターン付き: 「*ウェビナー」「*webinar」 → 01_knowledge/ - 判定必要: 「〇〇株式会社様月次MTG」 → 06_Projects/<顧客名>/ 避ける: エッジケースを50個列挙 プロンプト最適化:Few-shot Prompting 18
"ちょうど必要なとき"にコンテキストを取得 1. エージェントがタスクを開始 2. 必要だと判断したときに、検索ツールを使用 3. 必要な情報だけ取得 4. 次のステップへ ハイブリッド戦略:
事前取得 + 動的探索 Claude Code の実装例: 事前取得: CLAUDE.md ファイル 動的取得: glob と grep のような基本ツール 外部情報の最適化:Just in Time取得 19
実装の鍵:メタデータを活用 全データを事前処理せず、軽量の識別子のみ維持 ファイルパス、保存されたクエリ、Webリンクなど 必要時に動的にコンテキストへ読み込み メタデータが「何を読むべきか」の判断基準になる メタデータがシグナルになる 各メタデータが次のアクションの決定を知らせる: フォルダ階層 → どの機能に属するか
ファイルサイズ → 複雑性を示唆 命名規則 → 目的を示唆 タイムスタンプ → 関連性の代理指標 Just in Time取得の実装:メタデータの力 20
長期タスクにおける コンテキストエンジニアリング Anthropicの3つのアプローチ
長期タスク(数時間〜複数日)では、コンテキストウィンドウの制約を乗り越える特別な技術 が必要 1. Compaction(圧縮) 会話履歴を要約して、コンテキストを圧縮 2. Structured note-taking(構造化ノート作成) 外部メモリに構造化して保存 3.
Multi-agent architectures(マルチエージェント) 複数の専門エージェントに分割 Anthropicの3つのアプローチ 22
会話が長くなりすぎる前に重要な情報だけを抽出して要約し、新しいコンテキストで会話を続 ける Claude Codeの実装例 1. メッセージ履歴を要約 2. 保持: アーキテクチャ決定、未解決バグ、実装詳細 3.
破棄: 冗長なツール出力、重複メッセージ 4. 圧縮コンテキスト + 最近の5ファイルで再開 アプローチ1: 圧縮(Compaction) 23
AIが作業中に重要な情報をメモに書き、コンテキスト外(ファイル/DB)に保存。後で読み込ん で作業継続可能。 メリット 最小限のオーバーヘッドで永続的なメモリを提供 Claude Codeの実装例 to-doリストをファイルに保存し、必要時に読み込んで進捗追跡 アプローチ2: 構造化ノート作成 24
メインエージェント(統括役)が全体計画を立て、サブエージェント(専門家)が独立したコ ンテキストで深い技術作業を実施 情報の流れ サブ: 数万トークン使って徹底調査 メイン: 圧縮された要約のみ受け取る(1,000-2,000トークン) 詳細はサブ内に隔離、メインは統合・分析に集中 サブエージェントの本質は「コンテキスト隔離」 探索・調査の試行錯誤過程をメインコンテキストから隔離することが目的
アプローチ3: サブエージェント 25
実践編 登壇者の実装例(ライブデモ)
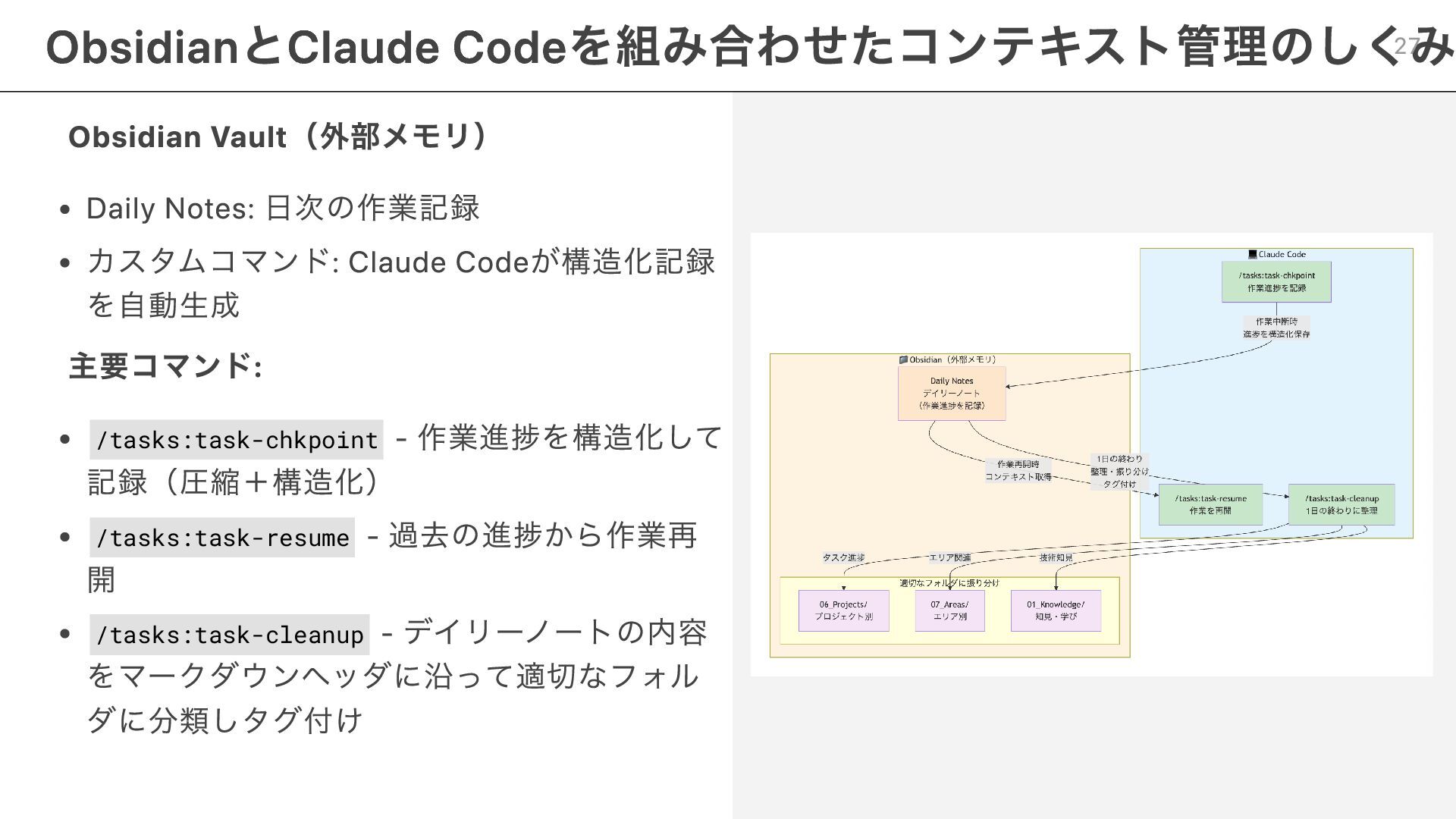
Obsidian Vault(外部メモリ) Daily Notes: 日次の作業記録 カスタムコマンド: Claude Codeが構造化記録 を自動生成 主要コマンド:
/tasks:task-chkpoint - 作業進捗を構造化して 記録(圧縮+構造化) /tasks:task-resume - 過去の進捗から作業再 開 /tasks:task-cleanup - デイリーノートの内容 をマークダウンヘッダに沿って適切なフォル ダに分類しタグ付け ObsidianとClaude Codeを組み合わせたコンテキスト管理のしくみ 27
デモ1: 圧縮・構造化ノート作成 「コンテキストを維持したまま作業を再開する」
作業終了時 # 何か開発作業を実施... # 作業終了時 /tasks:task-chkpoint 結果 デイリーノートに構造化記録が保存される: 圧縮: 冗長なセッション情報→固定フォーマット
外部メモリへの構造化: 概要/実施内容/課題/次のステップ/環境情報 29
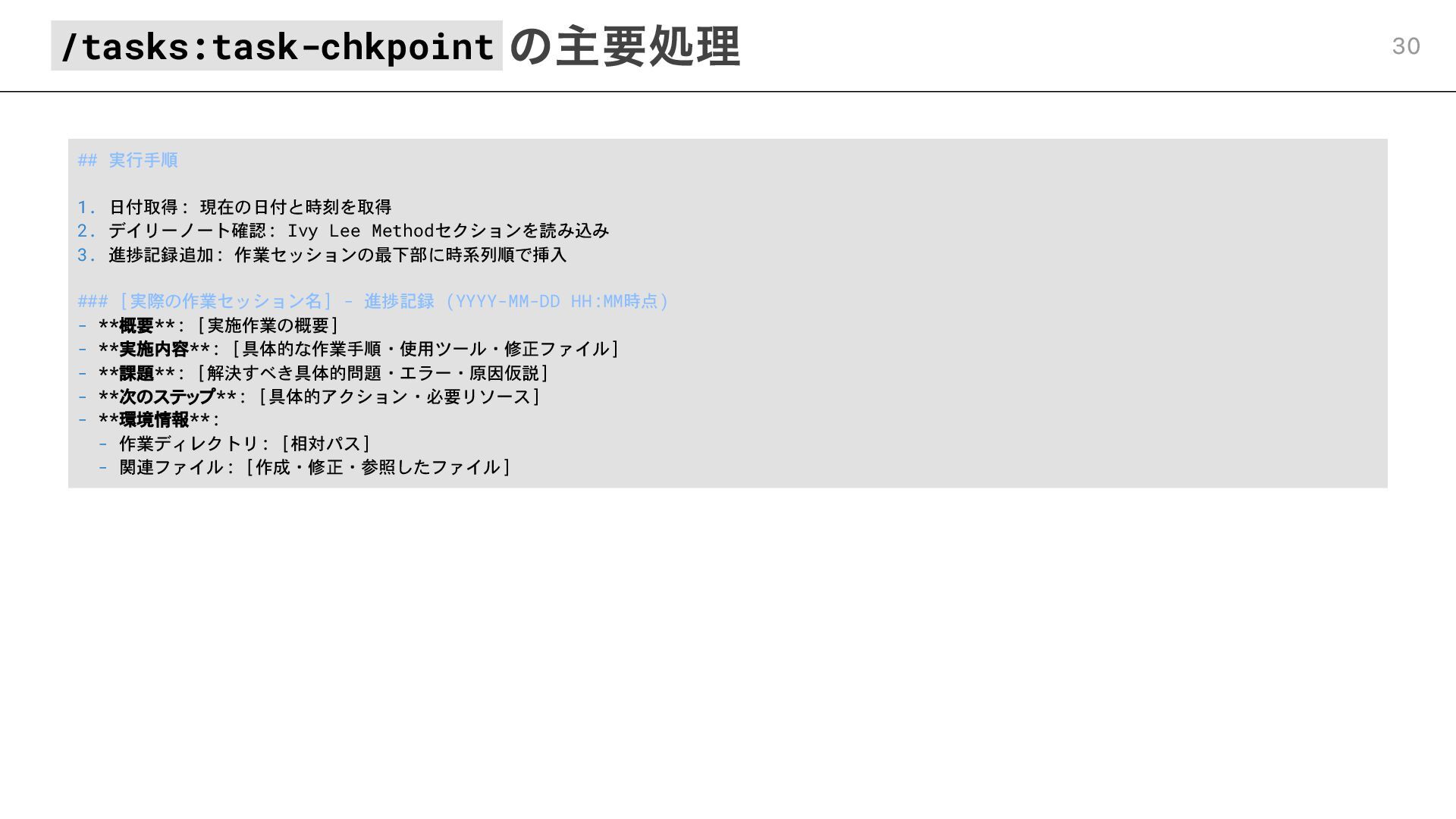
## 実行手順 1. 日付取得: 現在の日付と時刻を取得 2. デイリーノート確認: Ivy Lee Methodセクションを読み込み
3. 進捗記録追加: 作業セッションの最下部に時系列順で挿入 ### [実際の作業セッション名] - 進捗記録 (YYYY-MM-DD HH:MM時点) - **概要**: [実施作業の概要] - **実施内容**: [具体的な作業手順・使用ツール・修正ファイル] - **課題**: [解決すべき具体的問題・エラー・原因仮説] - **次のステップ**: [具体的アクション・必要リソース] - **環境情報**: - 作業ディレクトリ: [相対パス] - 関連ファイル: [作成・修正・参照したファイル] /tasks:task-chkpoint の主要処理 30
作業再開 # 新しいClaude Codeセッション(完全にゼロから) /tasks:task-resume 会議録音 どこまで作業してたっけ? Claudeの振る舞い 該当タスクの進捗記録を自動抽出 前回の「次のステップ」を提示
作業ディレクトリの確認 次のステップを自動で提案 31
## 処理内容 1. タスク情報の取得 - キーワード検索でIvy Lee Methodセクションから該当タスクを抽出 2. 進捗情報の読み込み
- デイリーノートに進捗記録がある → そのまま表示 - 「作業進捗ノート」参照のみ → 作業進捗ノートから読み込み 3. 作業環境状況の確認と次のアクション提示 - 作業ディレクトリ、環境情報、認証情報の状況を把握 - 継続可能な作業オプションを提示 /tasks:task-resume の主要処理 32
デモ2: プロンプト最適化 Part 1: トークン最小化 Part 2: 反復的改善
/docs:cleanup-content でプロンプトを最適化 # 冗長なプロンプトを最適化 /docs:cleanup-content /Users/kikuchi.toshinori/.claude/commands/demo-aws-update-logger.md ポイント 削除対象(低信号): 重複する内容、冗長な表現、不要な説明 保持対象(高信号):
コード例、例示(Few-shot Prompting) Anthropic原則: 「最小限の重要な情報で、最大の成果を出す」 34
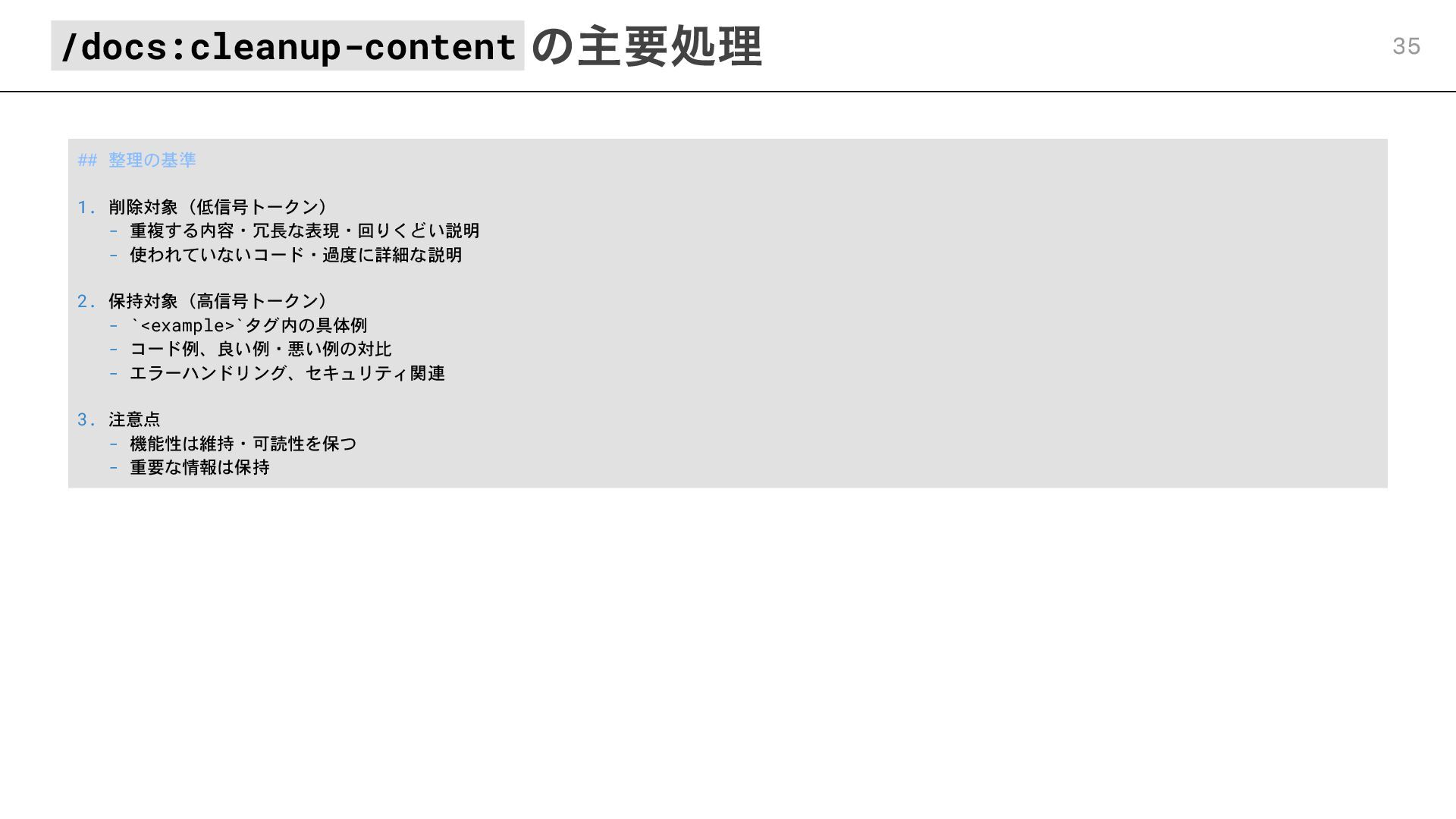
## 整理の基準 1. 削除対象(低信号トークン) - 重複する内容・冗長な表現・回りくどい説明 - 使われていないコード・過度に詳細な説明 2. 保持対象(高信号トークン)
- `<example>`タグ内の具体例 - コード例、良い例・悪い例の対比 - エラーハンドリング、セキュリティ関連 3. 注意点 - 機能性は維持・可読性を保つ - 重要な情報は保持 /docs:cleanup-content の主要処理 35
/dev:slash-command-fix でプロンプトを改善 # カスタムスラッシュコマンド実行 /demo-aws-update-logger https://aws.amazon.com/... # 修正ポイントを記載して修正 /dev:slash-command-fix aws-knowledge-mcpを使って情報を取得して、
また取得した情報を構造化したフォーマットで出力して ポイント 反復的改善: 日常的にプロンプトを改善する 36
## 実行手順 1. 問題分析 - コマンドファイルを読み込み - 根本原因を特定(誤った動作、曖昧な指示) - allowed-tools制約違反の確認
2. 最小限修正の適用 - 厳守事項を`## 厳守事項`セクションで明示 - 具体的なパス指定で曖昧さを排除 - 条件分岐の明確化(IF〜THEN〜ELSE) 3. 修正内容の記録 - 何を修正したか・なぜ必要だったか - 今後の類似問題を防ぐ教訓 /dev:slash-command-fix の主要処理 37
理論と実装の対照表 要素 Anthropic理論 私の実装 外部メモリ エージェントが重要情報を保存 デイリーノート 構造化 一貫したフォーマット マークダウン形式、固定項目
圧縮 会話履歴の要約 セッション情報→構造化フォーマット 注意予算最適化 必要な情報だけ渡す キーワード検索で該当タスクのみ取得 反復的改善 最小限から始めて失敗から学ぶ /dev:slash-command-fix トークン最小化 高信号トークンのみ保持 /docs:cleanup-content デモの振り返り 38
対話編 あなたのコンテキストエンジニアリング
Anthropic: 「試行錯誤過程をメインコンテキストから隔離」 「サブエージェント(Task tool) 、使ってますか?」 「サブエージェントどんなタスクでつかってますか?」 トピック1: サブエージェントの使い所 40
Anthropic: 「具体的すぎず、抽象的すぎず、適切な粒度で」 「CLAUDE.mdやシステムプロンプト(Output styles) 、どんなこと書いてますか?」 トピック2: システムプロンプトの粒度 41
Anthropic: 「反復的改善」 「Few-shot」 「最小限の高信号トークン」 「プロンプトを改善するための工夫や取り組みがあればぜひ共有してください」 「例示(Few-shot)を入れる際にはどのような点に注意してますか?」 トピック3: ユーザー入力(プロンプト)の最適化 42
Anthropic: 「一貫したフォーマットで外部メモリに保存」 「外部に情報を貯めてますか?」 「どのような仕組みで生成AIと連携させてますか?」 トピック4: 構造化ノートの活用 43
クロージング コンテキストエンジニアリングの本質
コンテキストの各要素を最適化 1. システムプロンプト: 適切な粒度で記述 2. ユーザー入力: 反復的改善、Few-shot、最小限の高信号トークン 3. 外部情報: Just
in Time取得、構造化 4. ツール定義: 必要なものだけ絞る 長期タスクの3つのアプローチ 1. 圧縮: 会話履歴を要約 2. 構造化ノート: 外部メモリに構造化保存 3. マルチエージェント: 専門エージェントに分割 コンテキストエンジニアリングの実践要素 45
圧縮・構造化ノート・サブエージェント Just in Time取得・ツール選択 システムプロンプト・Few-shot設計 すべてこの原則に基づいている AIが賢くなっても変わらない モデルの性能が上がっても、 「情報を厳選する」という原則は変わらない 一時的なテクニックではなく、AI活用の永続的な設計原則
実装は多様 / 原則は同じ 46
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}