the Docker API (can be a security issue) • Works for any container runtime (Docker, rkt, runC, LXD, etc.) • Automatically enhances process data with cgroup information 15
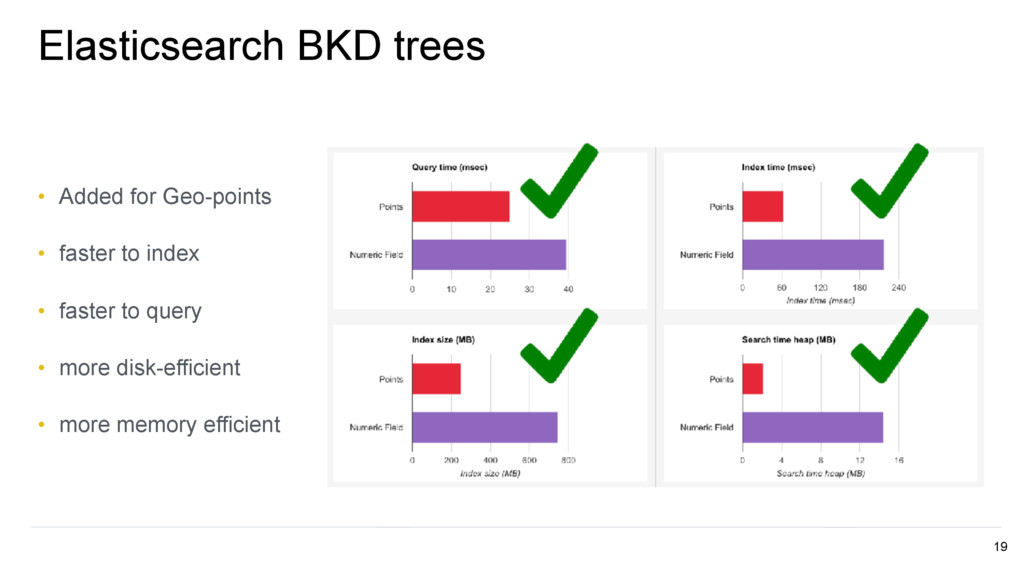
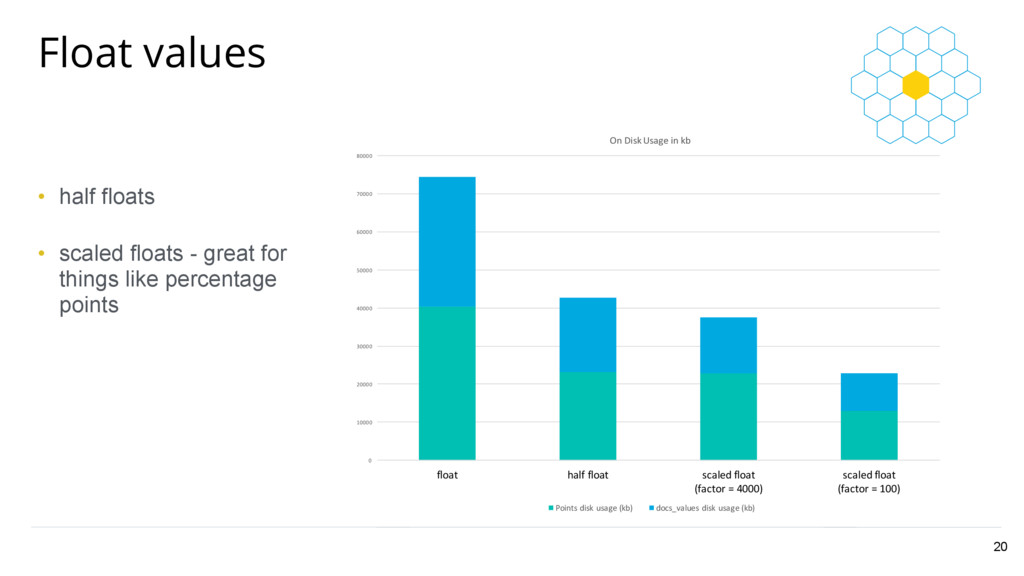
half float scaled float (factor = 4000) scaled float (factor = 100) On Disk Usage in kb Points disk usage (kb) docs_values disk usage (kb) Float values 20 • half floats • scaled floats - great for things like percentage points
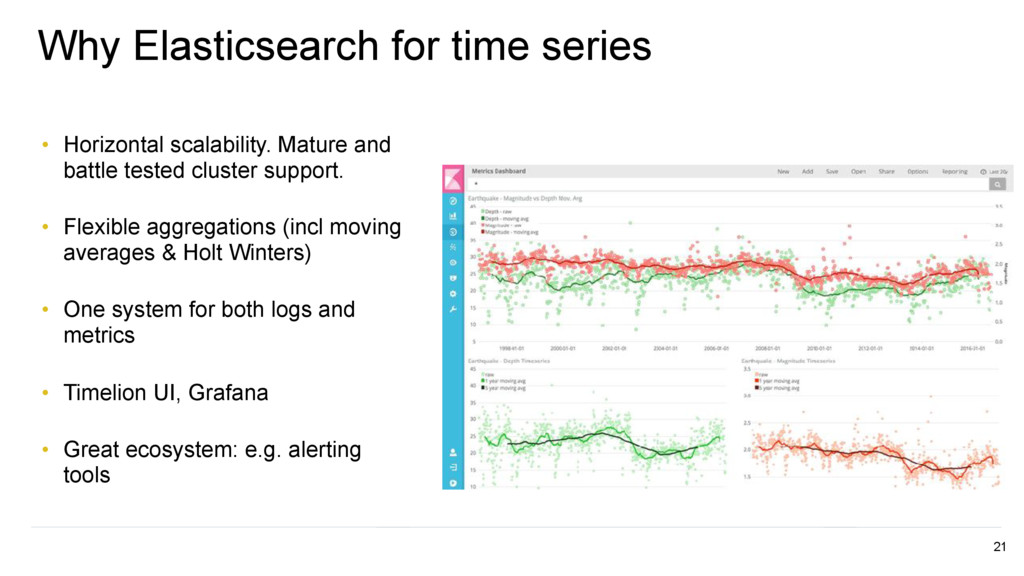
and battle tested cluster support. • Flexible aggregations (incl moving averages & Holt Winters) • One system for both logs and metrics • Timelion UI, Grafana • Great ecosystem: e.g. alerting tools 21
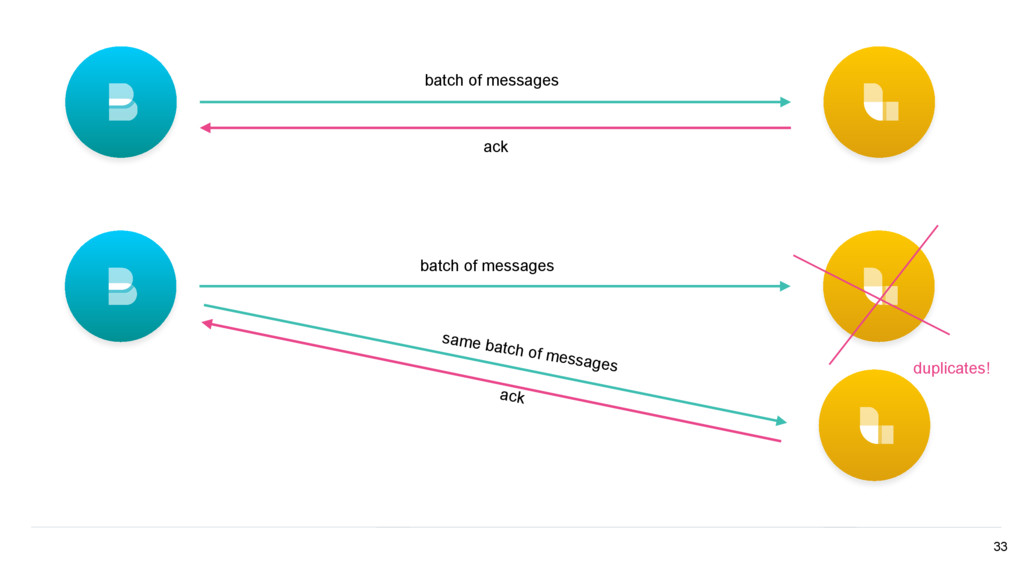
UUID for each log line • When indexing to Elasticsearch, use the create API • Deduplication happens in Elasticsearch • But ✦ Duplicates can still happen on Filebeat crashes ✦ Performance penalty at index time 34
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}