This presentation presents a full stack solution for managing Machine Learning with Kubernetes along with a turnkey solution (kubeflow) that can be deployed to most supported kubernetes services.
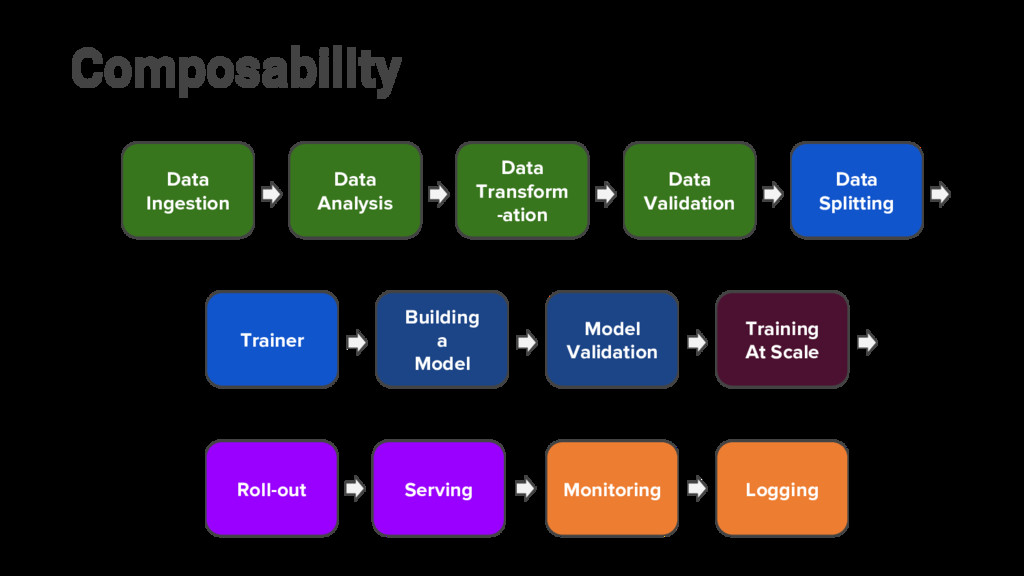
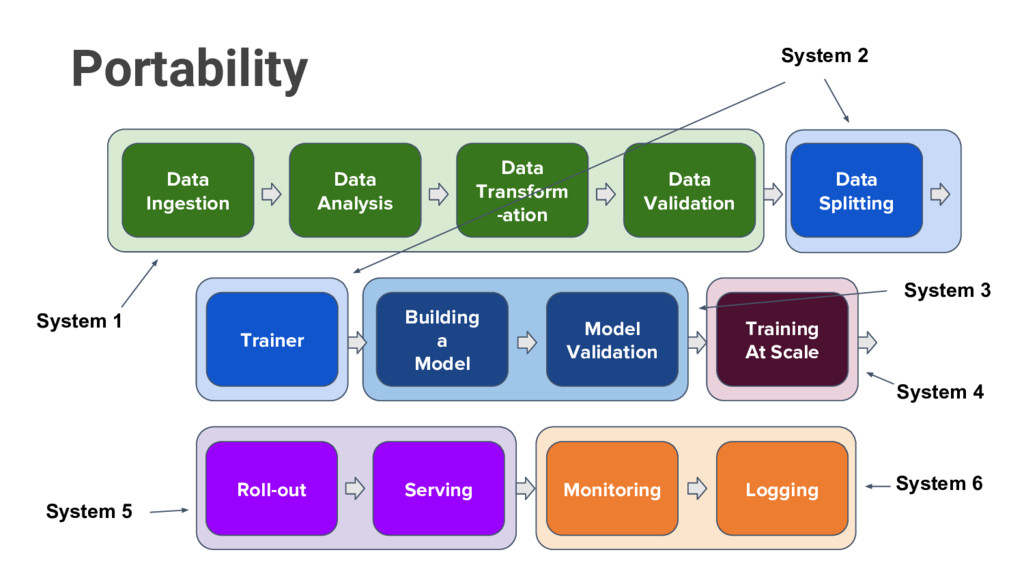
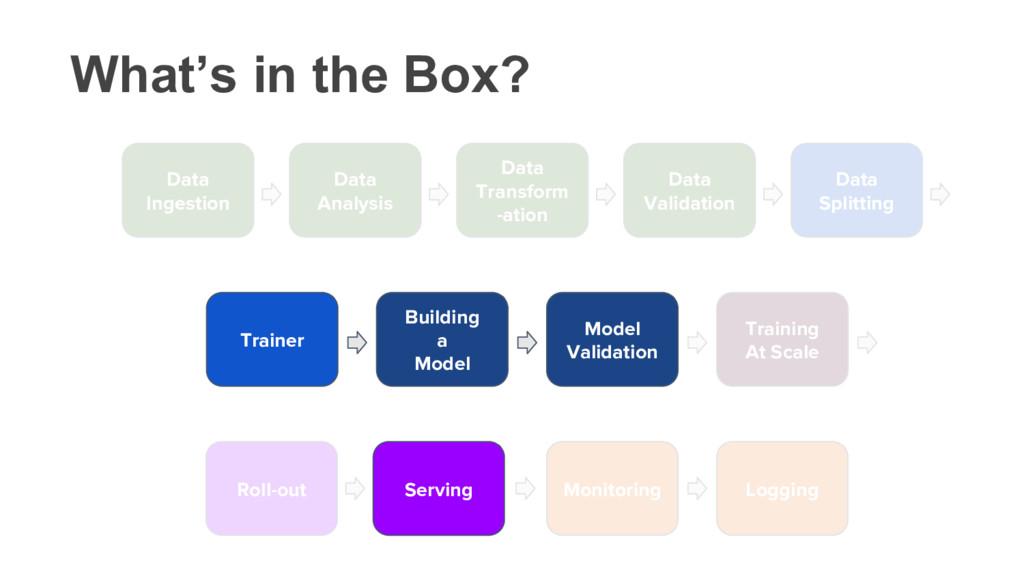
3 System 1 Data Ingestion Data Analysis Data Transform -ation Data Validation Building a Model Model Validation Serving Logging Monitoring Roll-out System 2 Data Splitting Trainer Portability
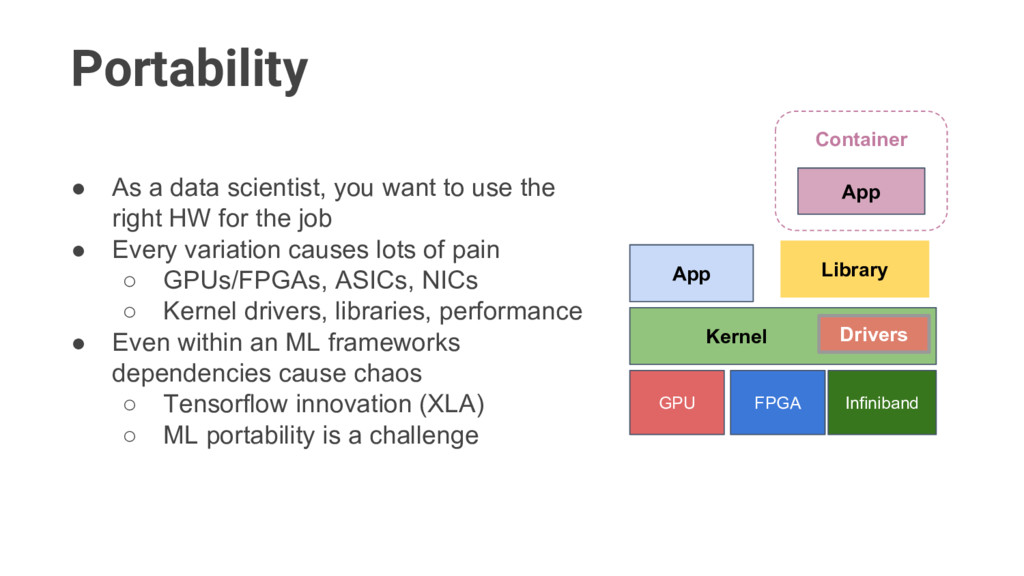
right HW for the job • Every variation causes lots of pain ◦ GPUs/FPGAs, ASICs, NICs ◦ Kernel drivers, libraries, performance • Even within an ML frameworks dependencies cause chaos ◦ Tensorflow innovation (XLA) ◦ ML portability is a challenge Container Kernel GPU FPGA Infiniband Drivers Library App App Portability
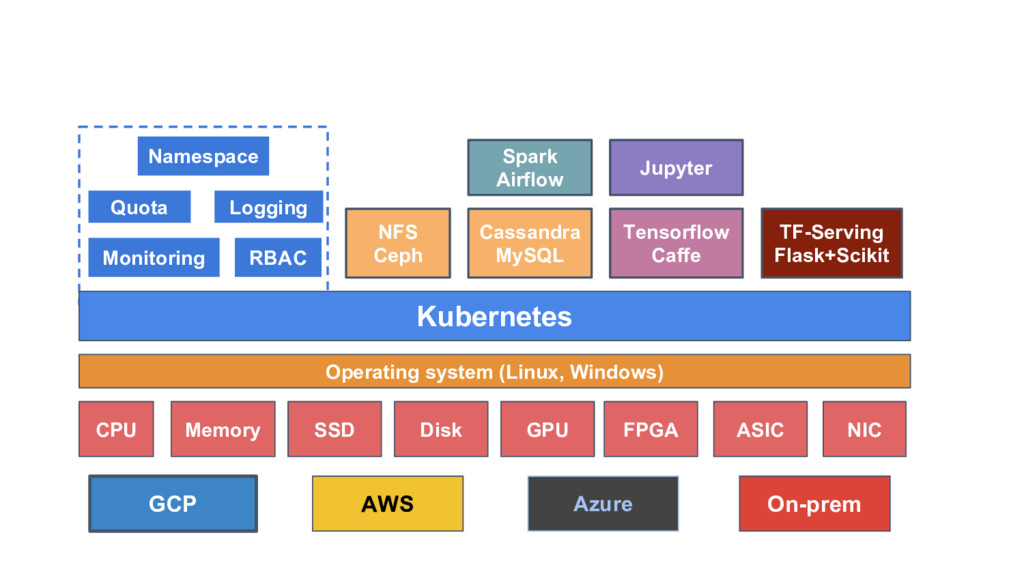
◦ GPUs already in progress ◦ Support for FPGAs, high perf NICs under discussion • Existing Controllers simplify devops challenges ◦ k8s Jobs for Training ◦ k8s Deployments for Serving • Scales to 1000s of nodes • Container packaging already a standard ◦ Standard base images for ML workloads
Autoscaling cluster based on workload metrics ◦ Priority eviction for removal of low priority jobs ◦ Scaled to large number of pods (experiments) • Assumes “adequate” network bandwidth • Also passes through cluster specs for specific needs ◦ Data Gravity is supported ◦ Node labels for Heterogeneous HW (more in the future) ◦ Manage SW drivers and HW health via addons
Choose from existing popular tools ◦ Uses yaml manifests for creation • Portability ◦ Build using cloud native, portable Kubernetes APIs ◦ Let K8s community solve for your deployment • Scalability ◦ TF already supports CPU/GPU/distributed ◦ K8s scales to 5k nodes with same stack
Weave, CaiCloud, many more • What’s next... ◦ Easy to use accelerator integration ◦ Support for other popular tools like Spark ML, XGBoost, sklearn ◦ Autoscaled TF Serving ◦ tf.transform (programmatic data transforms) ◦ Model analysis (sliced metrics, time series graphs, visualizations embedded in notebooks) • You tell us! (Or better yet, help!)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://github.com/google/kubeflow slack: kubeflow (http://kubeflow.slack.com) twitter: @kubeflow @aronchick ([email protected]) @vishnukanan ([email protected])`](https://files.speakerdeck.com/presentations/d3d9e17f11544e969a5fbba7ae95cd23/slide_48.jpg){kind=link}
{kind=link}