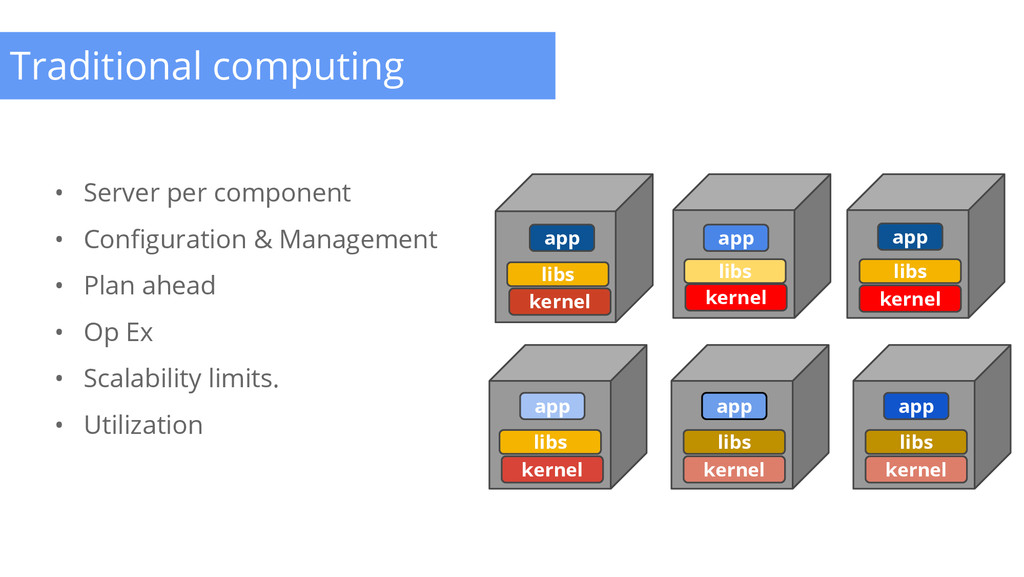
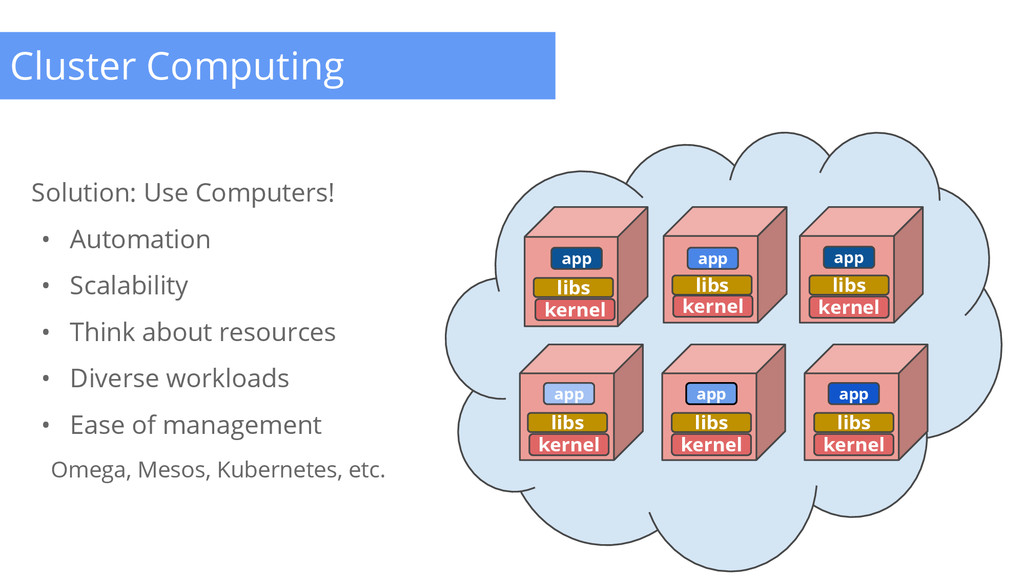
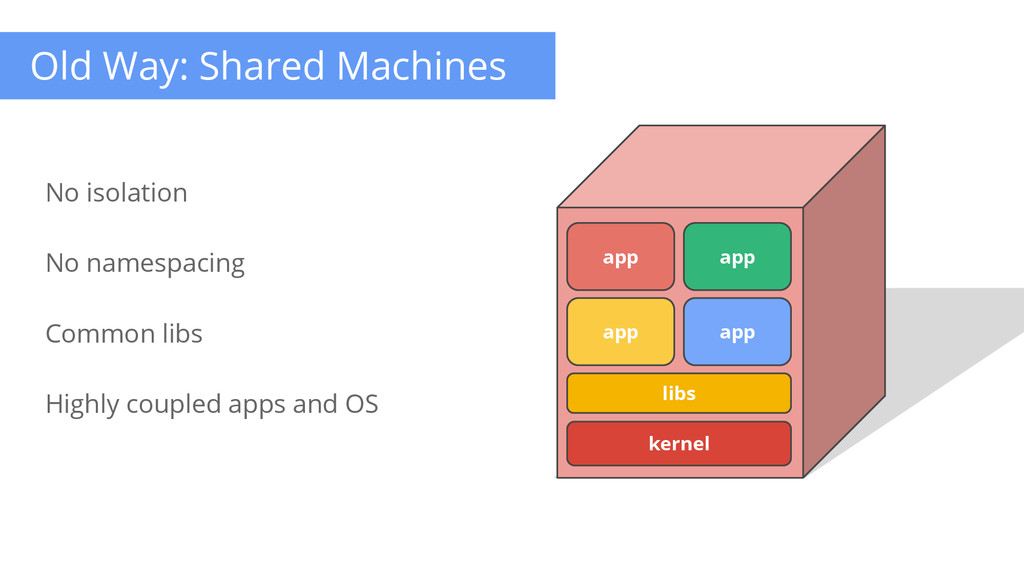
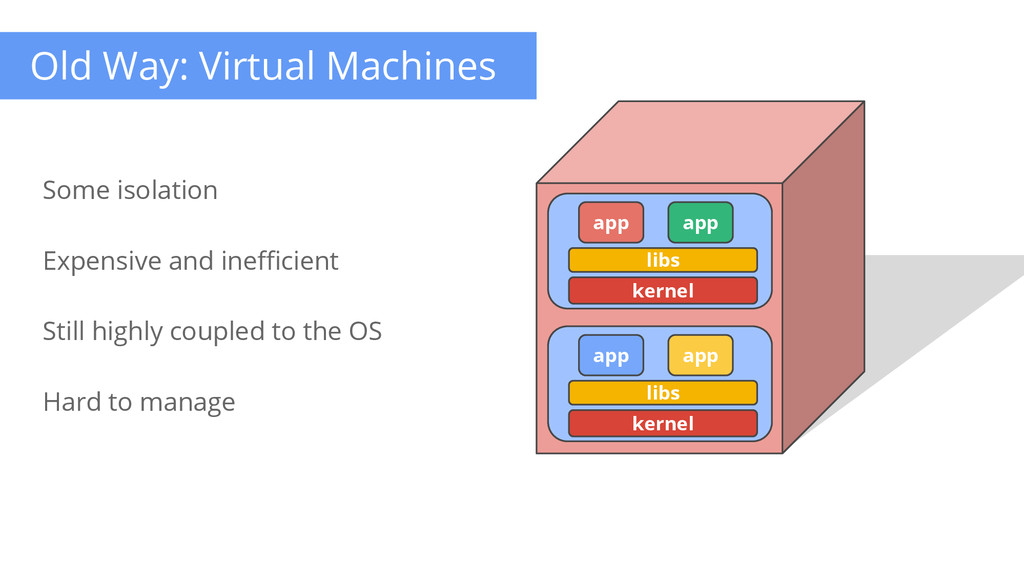
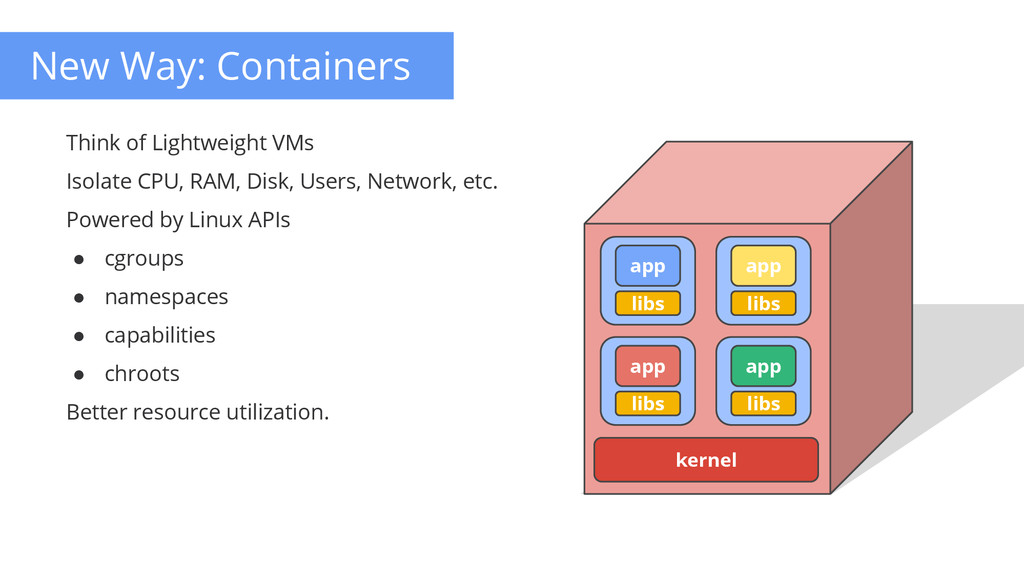
Can we do better? 1. Place multiple application on one machine 2. Partition the physical machine - VMs 3. Partition the resources on a physical machine - cgroups, namespaces (isolation) Smarter Node Management Capacity vs Usage
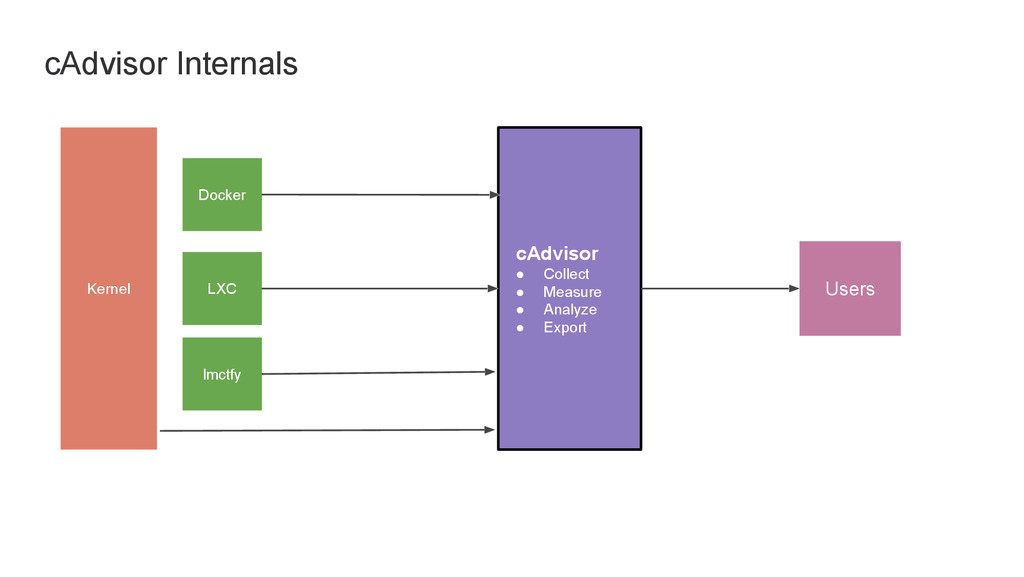
and performance of applications Google OSS project Written in Go; tiny resource footprint. Supports Docker containers natively. Lxc and raw cgroup supported. Understands Cpu, memory, filesystem and network utilization Easy to use REST Api Runs in a docker container
using cAdvisor Default monitoring solution in kubernetes Filesystem based API to support other Cluster mangement systems. CoreOS support using Filesystem API Discovers and collects stats from cAdvisors running on all the nodes Pushes data to InfluxDB or BigQuery Typical setup: Heapster + InfluxDB + Grafana
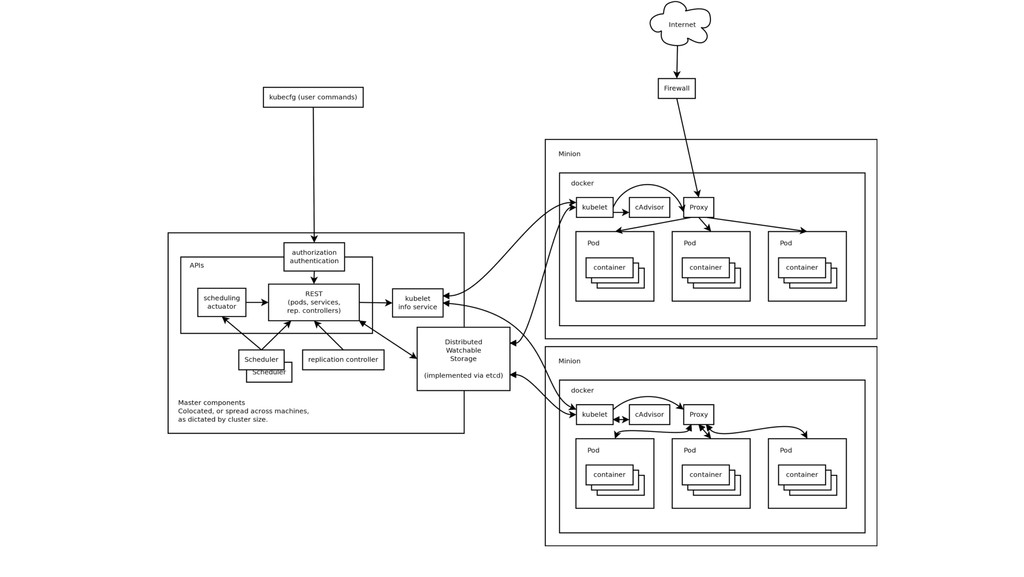
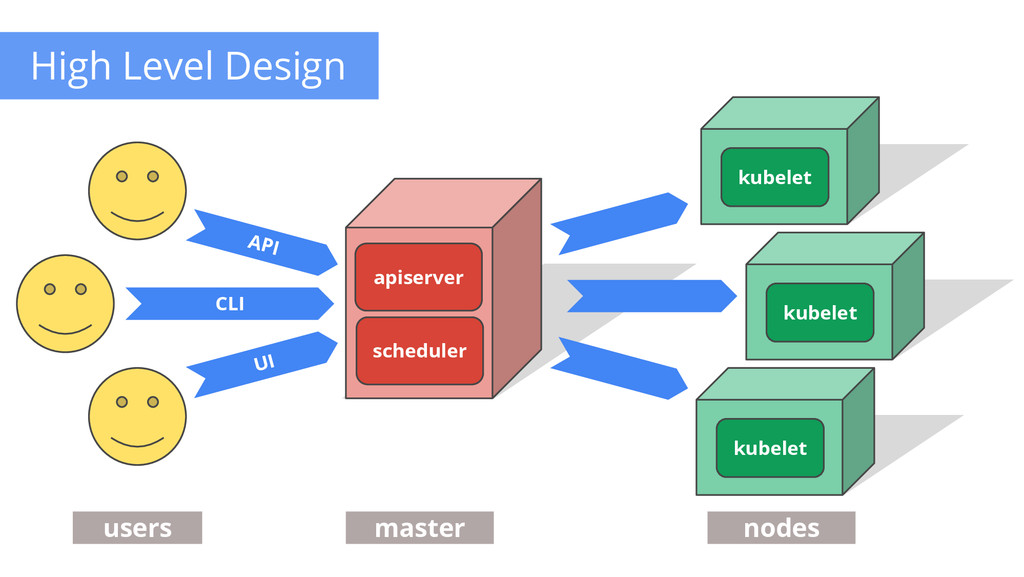
also the root of the word “Governor” • Container orchestrator • Runs Docker containers • Supports multiple cloud and bare- metal environments • Inspired and informed by Google’s experiences • Open source, written in Go Manage applications, not machines
sealed application package (Docker) Pod: A small group of tightly coupled Containers example: content syncer & web server Controller: A loop that drives current state towards desired state example: replication controller Service: A set of running pods that work together example: load-balanced backends Labels: Identifying metadata attached to other objects example: phase=canary vs. phase=prod Selector: A query against labels, producing a set result example: all pods where label phase == prod
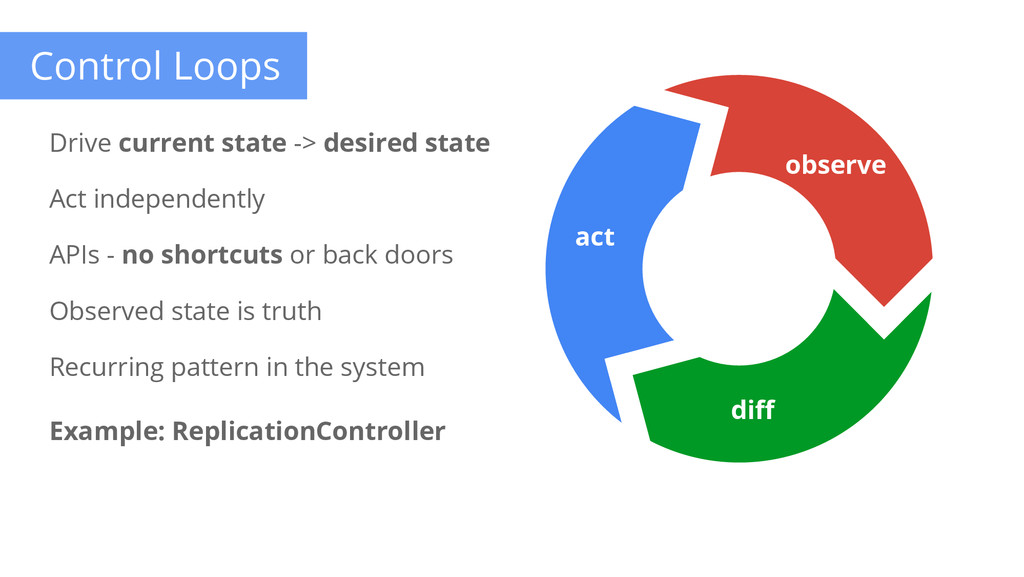
imperative: State your desired results, let the system actuate Control loops: Observe, rectify, repeat Simple > Complex: Try to do as little as possible Modularity: Components, interfaces, & plugins Legacy compatible: Requiring apps to change is a non-starter Network-centric: IP addresses are cheap No grouping: Labels are the only groups Cattle > Pets: Manage your workload in bulk Open > Closed: Open Source, standards, REST, JSON, etc.
state -> desired state Act independently APIs - no shortcuts or back doors Observed state is truth Recurring pattern in the system Example: ReplicationController observe diff act
for all master state Hidden behind an abstract interface Stateless means scalable Watchable • this is a fundamental primitive • don’t poll, watch Using CoreOS etcd
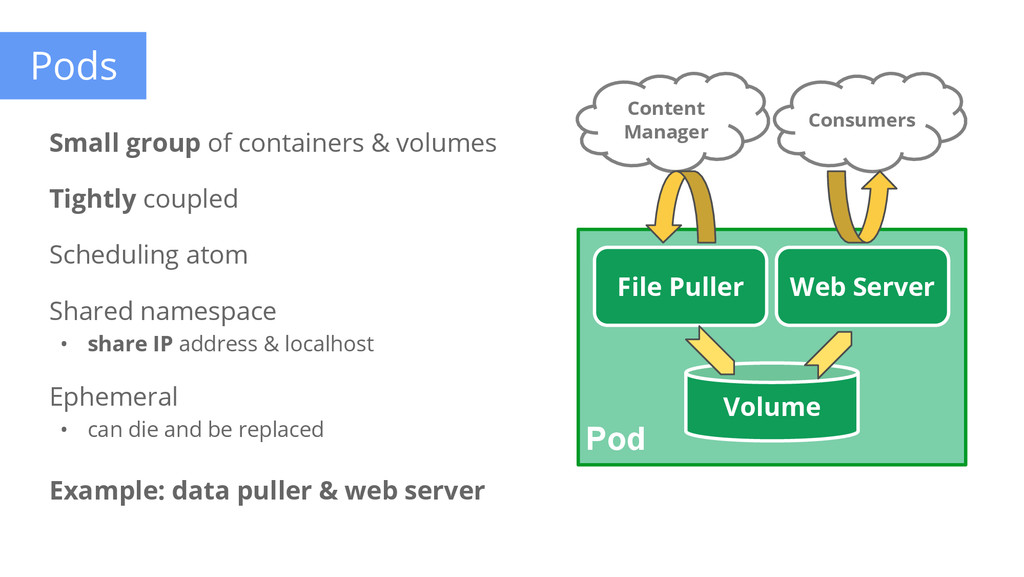
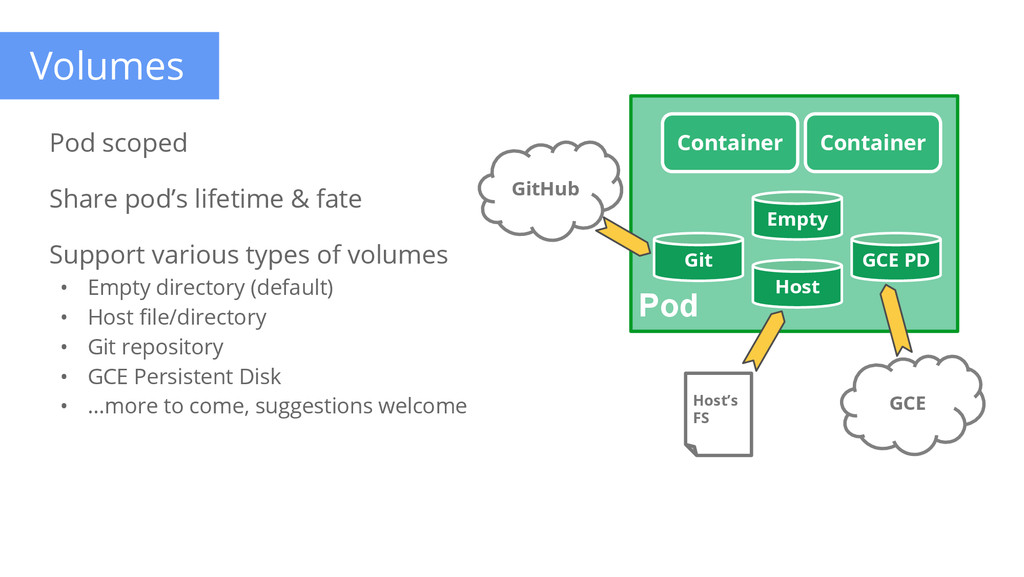
containers & volumes Tightly coupled Scheduling atom Shared namespace • share IP address & localhost Ephemeral • can die and be replaced Example: data puller & web server Pod File Puller Web Server Volume Consumers Content Manager
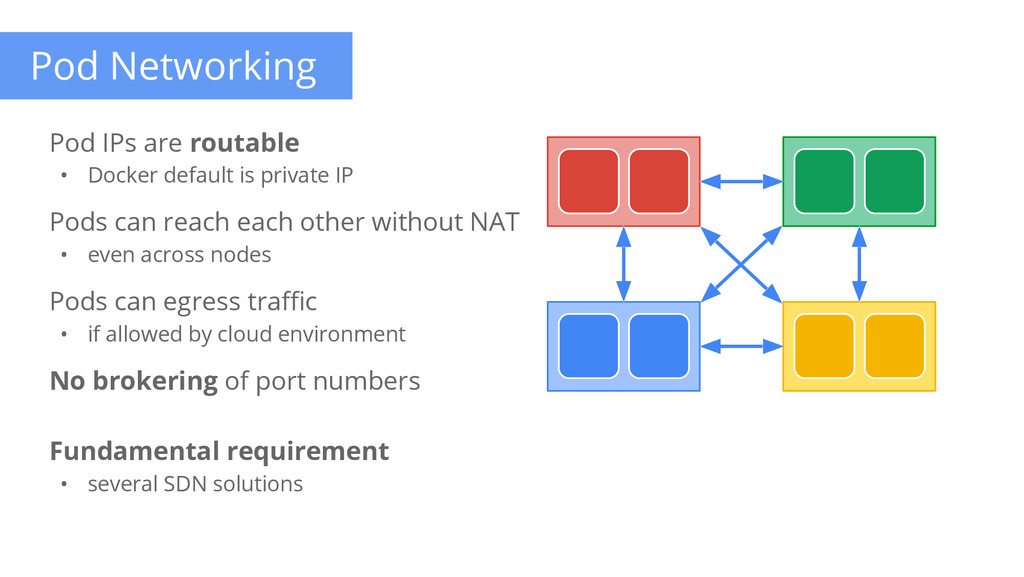
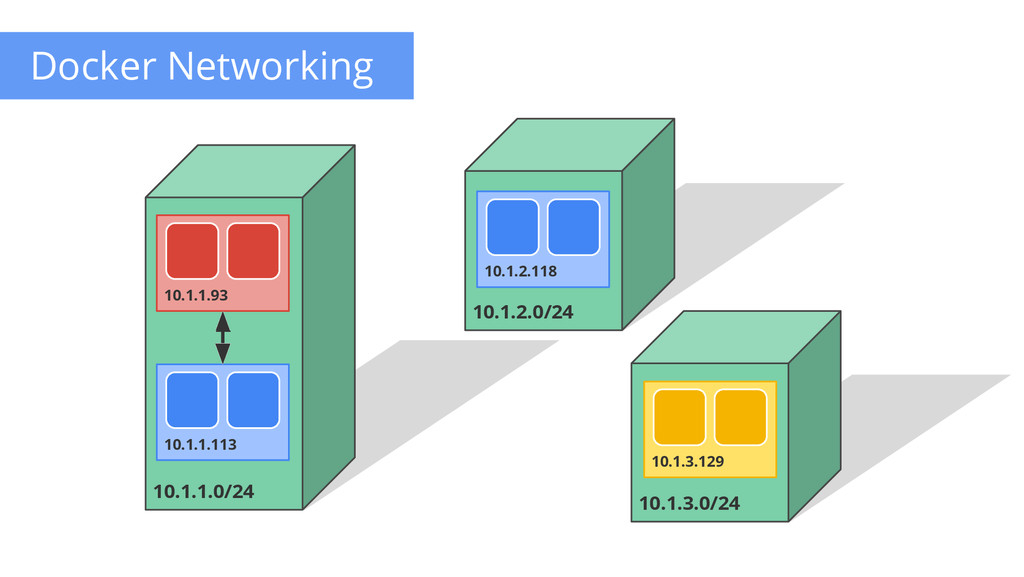
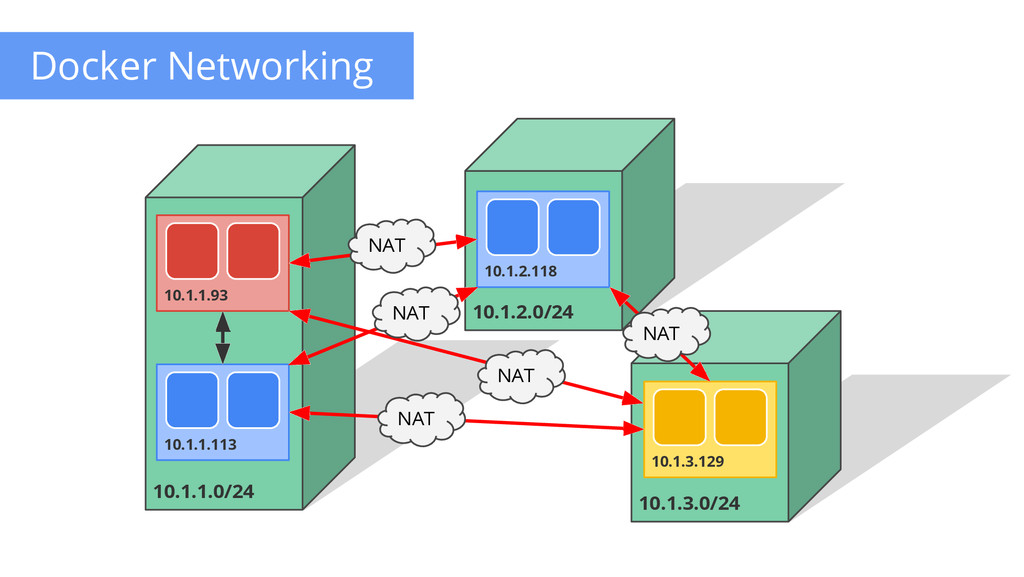
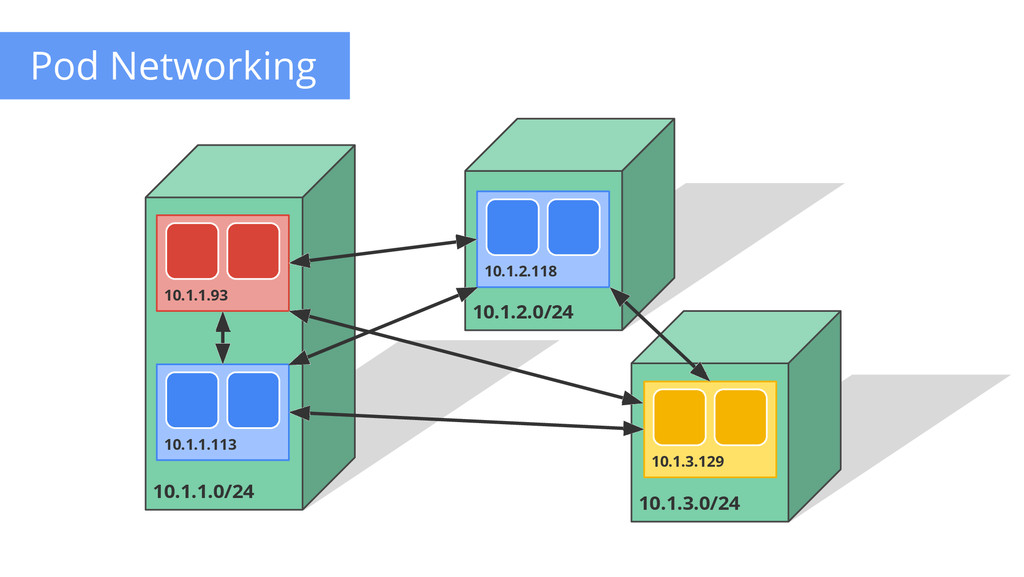
are routable • Docker default is private IP Pods can reach each other without NAT • even across nodes Pods can egress traffic • if allowed by cloud environment No brokering of port numbers Fundamental requirement • several SDN solutions
to a node, pods do not move • restart policy means restart in-place Pods can be observed pending, running, succeeded, or failed • failed is really the end - no more restarts • no complex state machine logic Pods are not rescheduled by the scheduler or apiserver • even if a node dies • controllers are responsible for this • keeps the scheduler simple
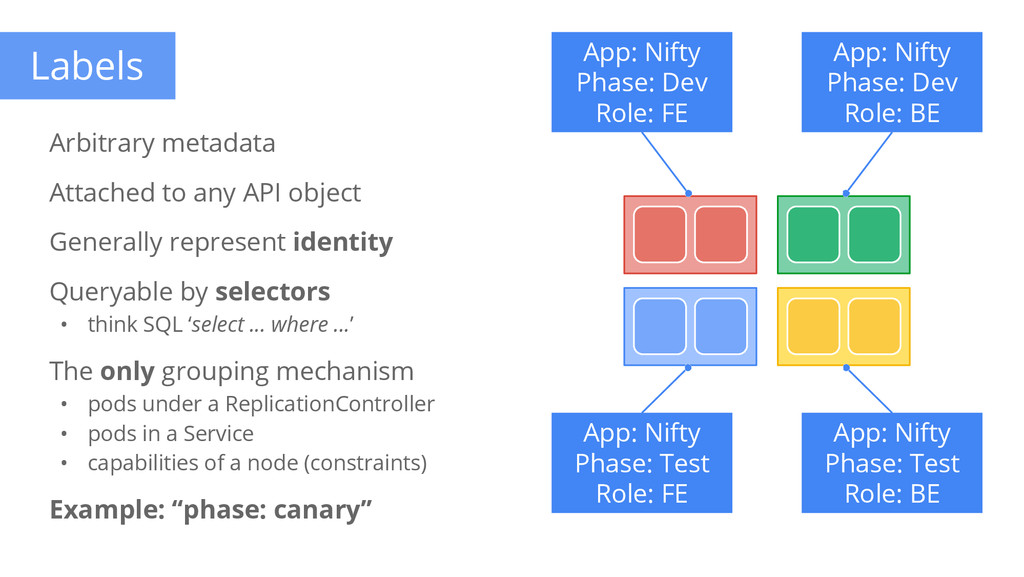
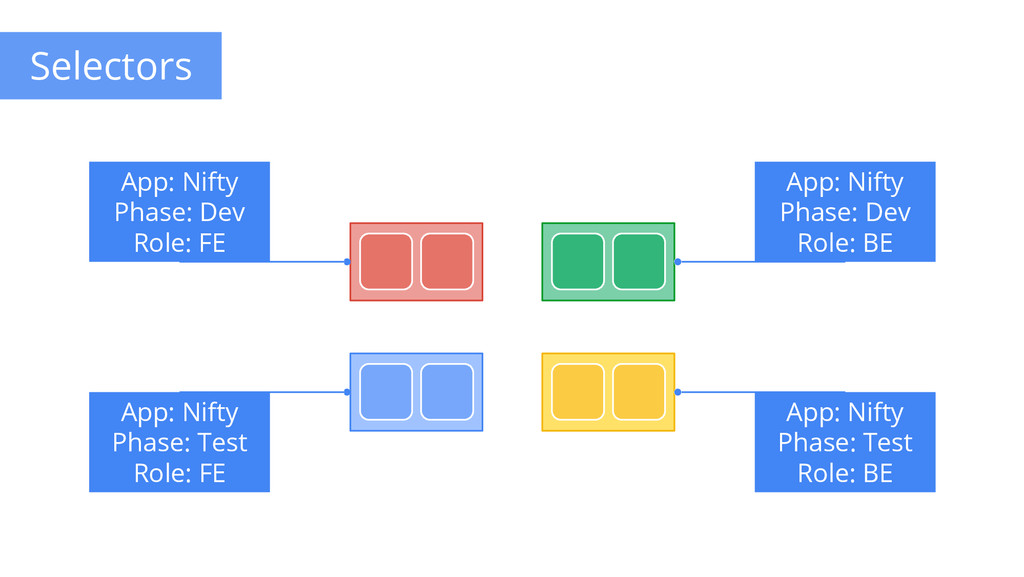
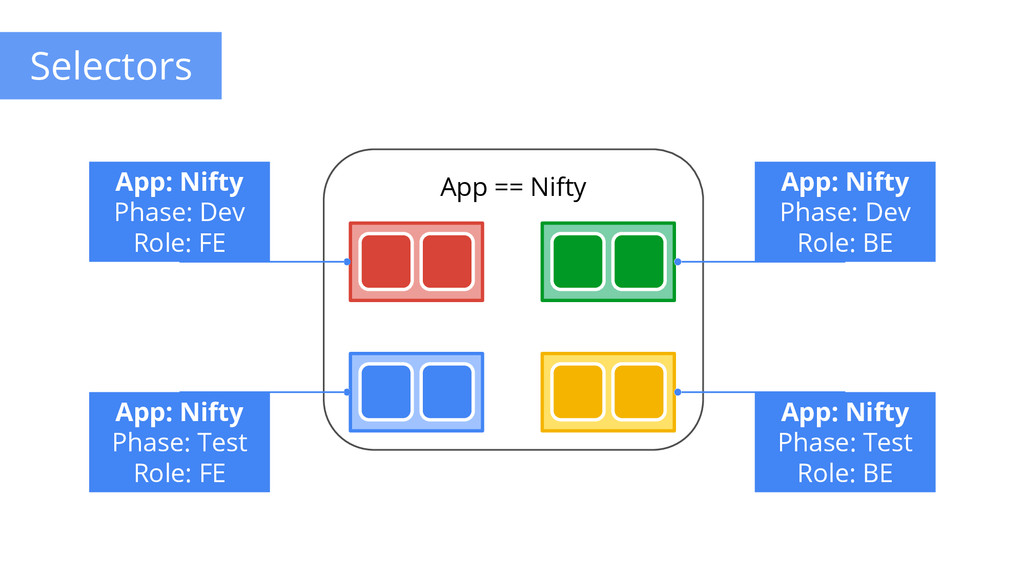
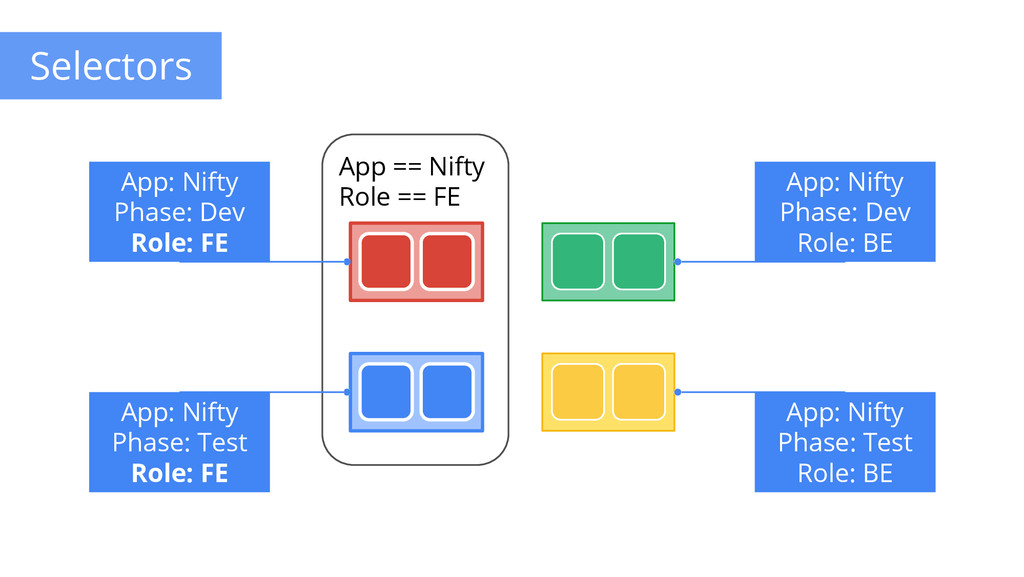
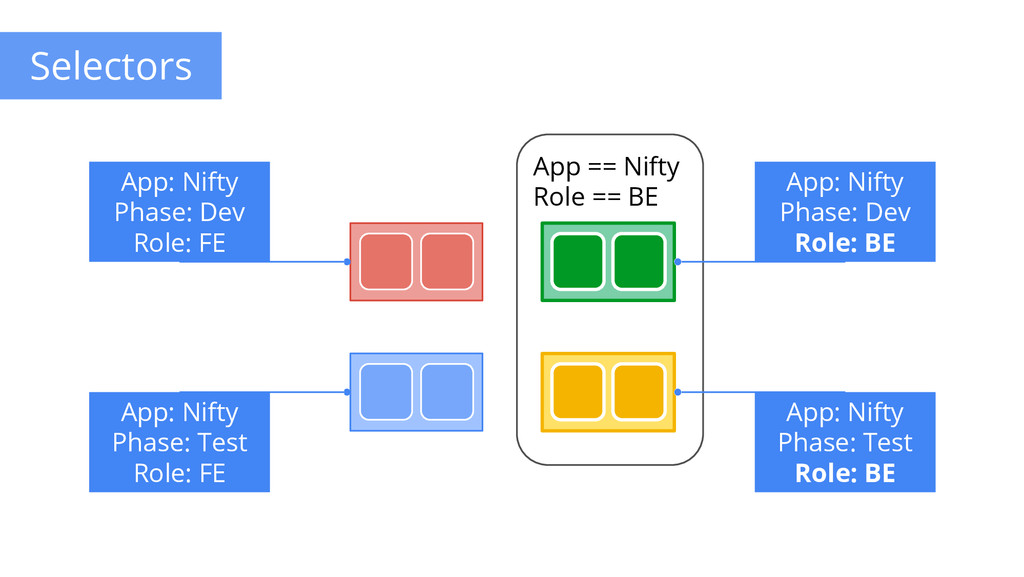
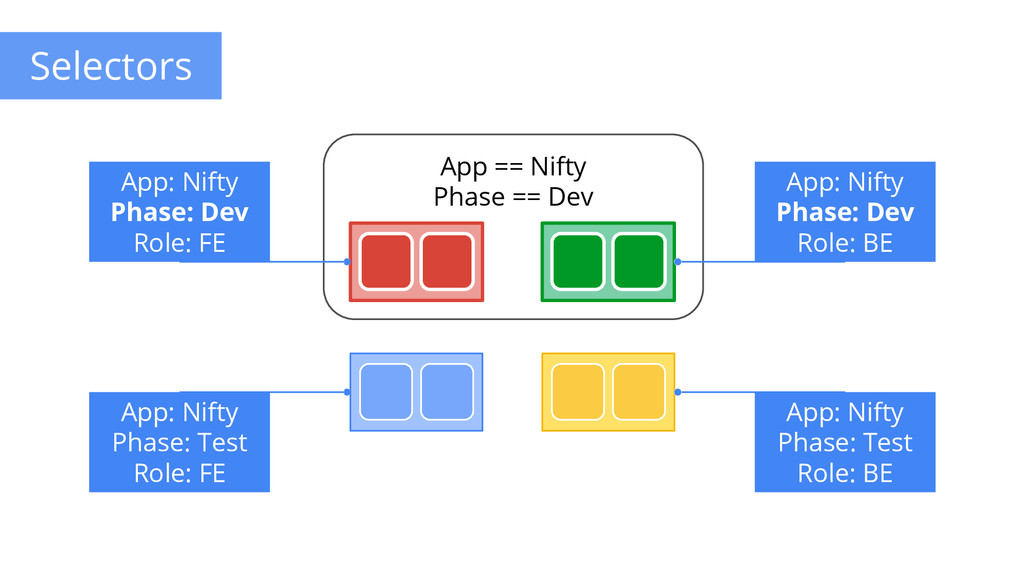
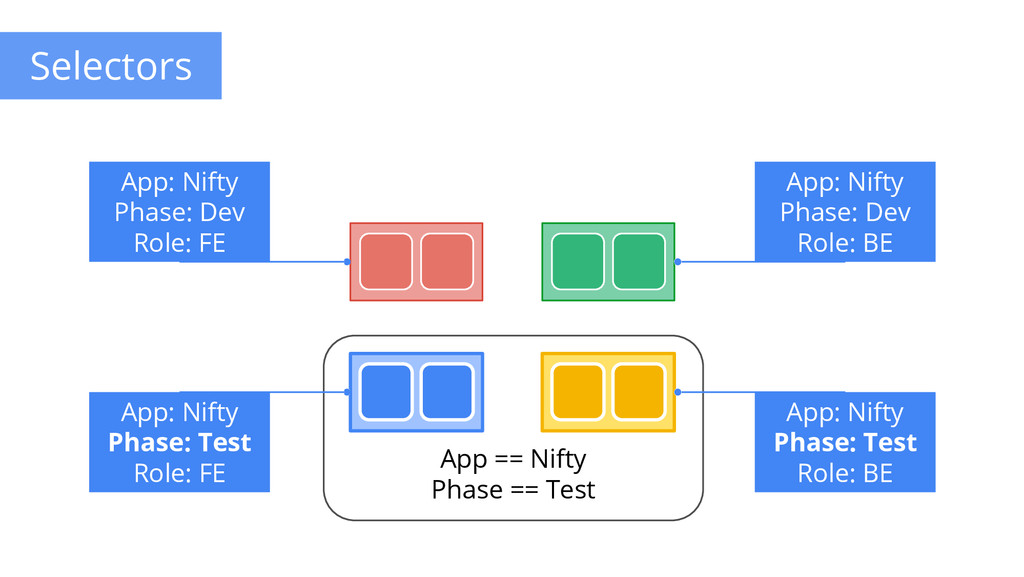
to any API object Generally represent identity Queryable by selectors • think SQL ‘select ... where ...’ The only grouping mechanism • pods under a ReplicationController • pods in a Service • capabilities of a node (constraints) Example: “phase: canary” App: Nifty Phase: Dev Role: FE App: Nifty Phase: Dev Role: BE App: Nifty Phase: Test Role: FE App: Nifty Phase: Test Role: BE
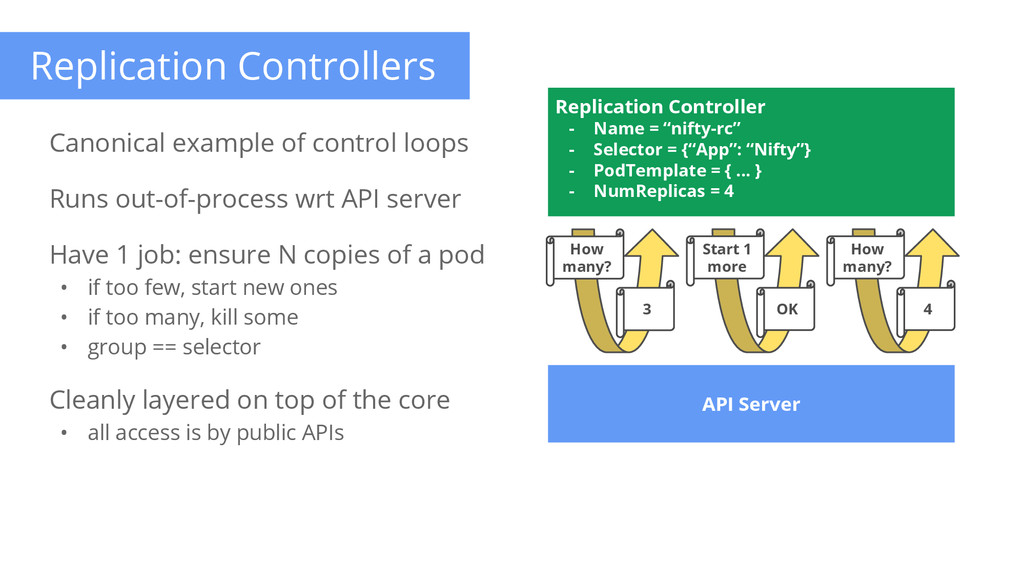
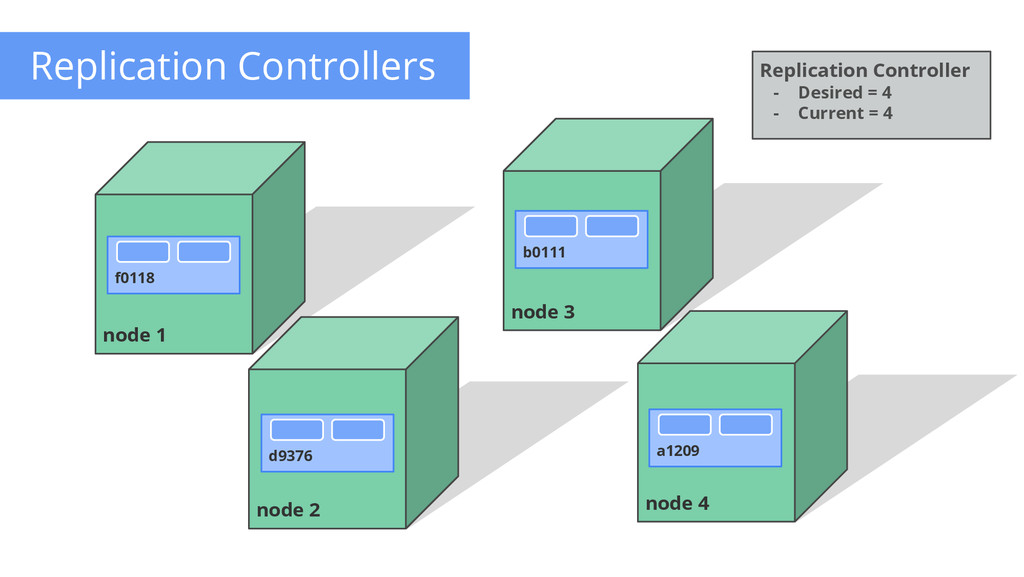
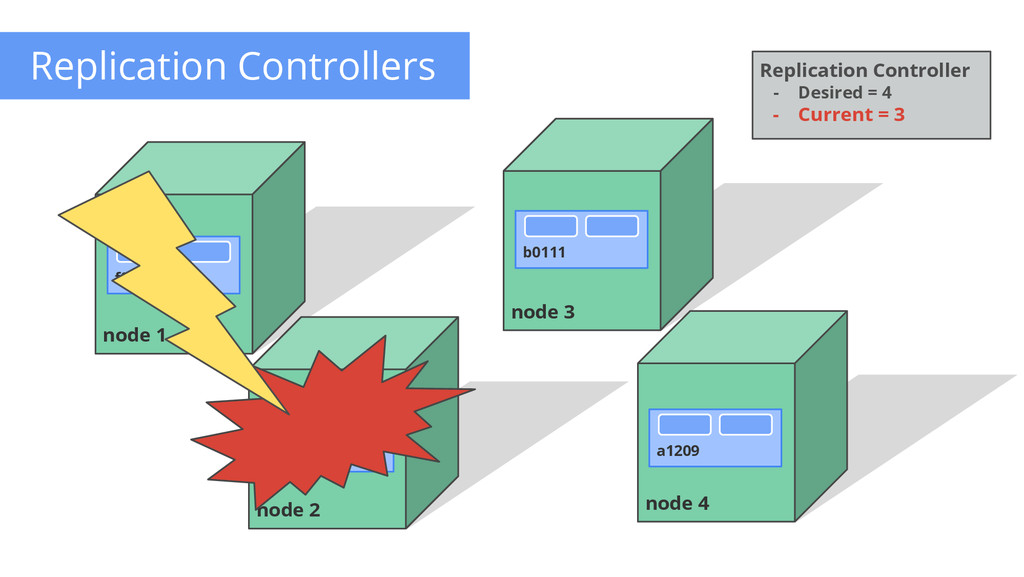
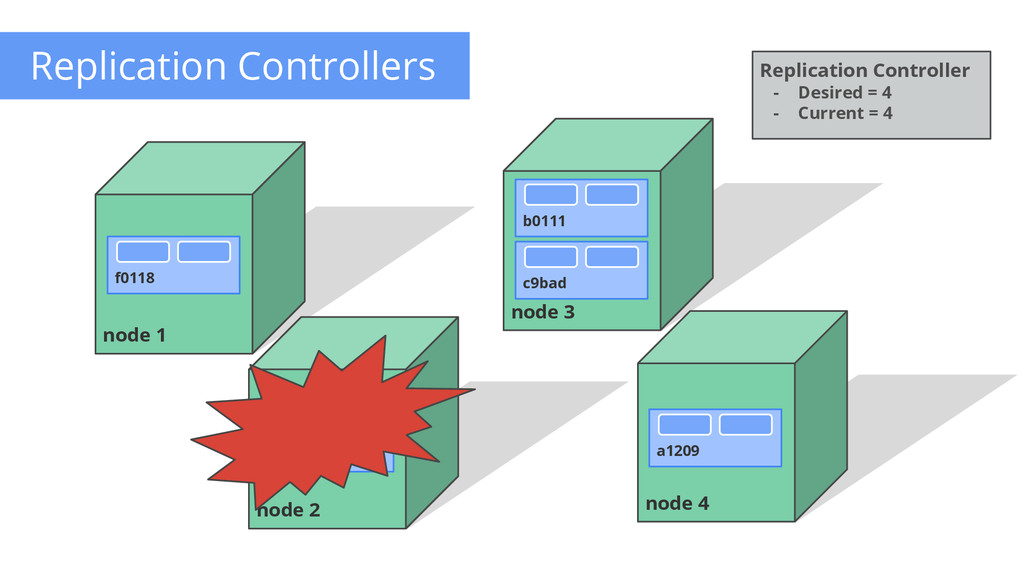
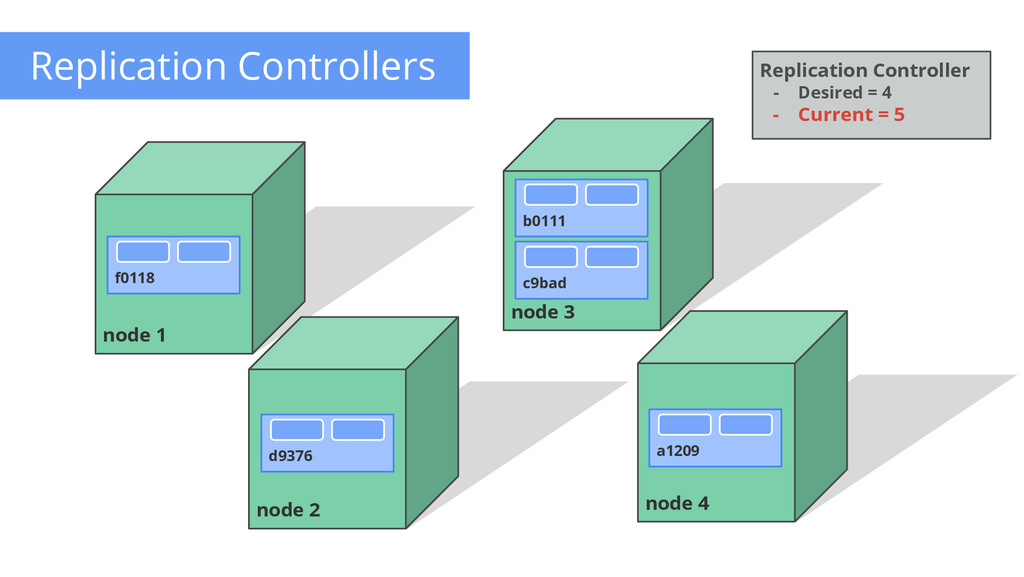
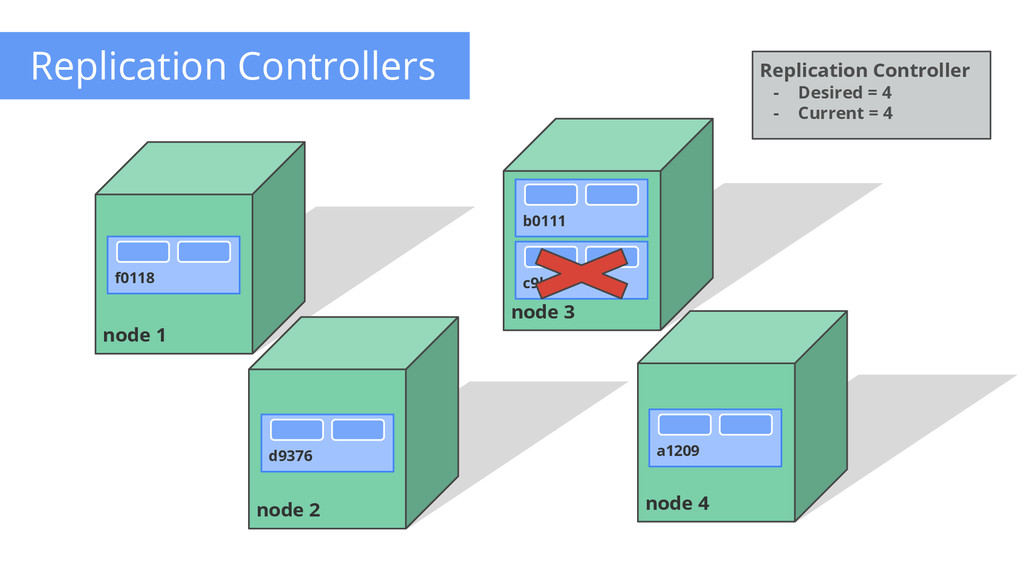
of control loops Runs out-of-process wrt API server Have 1 job: ensure N copies of a pod • if too few, start new ones • if too many, kill some • group == selector Cleanly layered on top of the core • all access is by public APIs Replication Controller - Name = “nifty-rc” - Selector = {“App”: “Nifty”} - PodTemplate = { ... } - NumReplicas = 4 API Server How many? 3 Start 1 more OK How many? 4
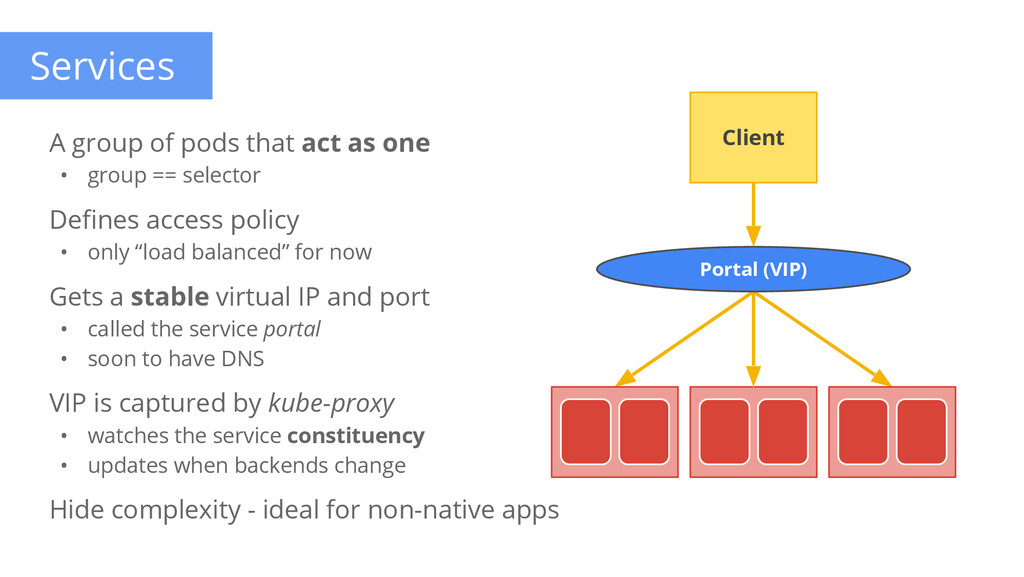
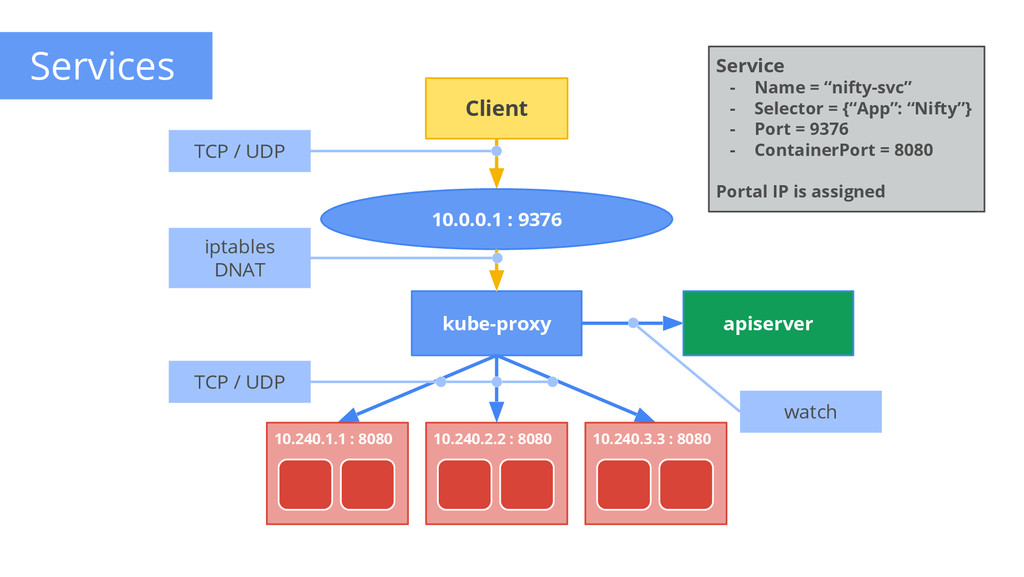
pods that act as one • group == selector Defines access policy • only “load balanced” for now Gets a stable virtual IP and port • called the service portal • soon to have DNS VIP is captured by kube-proxy • watches the service constituency • updates when backends change Hide complexity - ideal for non-native apps Portal (VIP) Client
DNS, etc. All run as pods in the cluster - no special treatment, no back doors Open-source solutions for everything • cadvisor + influxdb + heapster == cluster monitoring • fluentd + elasticsearch + kibana == cluster logging • skydns + kube2sky == cluster DNS Can be easily replaced by custom solutions • Modular clusters to fit your needs
sourced in June, 2014 Google just launched Google Container Engine (GKE) • hosted Kubernetes • https://cloud.google.com/container-engine/ Roadmap: • https://github.com/GoogleCloudPlatform/kubernetes/blob/master/docs/roadmap.md Driving towards a 1.0 release in O(months)
Up Containers is a new way of working Requires new concepts and new tools Google has a lot of experience... ...but we are listening to the users Workload portability is important!
Open Source We want your help! http://kubernetes.io https://github.com/google/cadvisor https://github.com/GoogleCloudPlatform/heapster irc.freenode.net #google-containers
• Repeatability • Isolation • Quality of service • Accounting • Visibility • Portability A fundamentally different way of managing applications Images by Connie Zhou
management. Easy to use Build, test and deploy - anywhere Provides resource isolation and security Big ecosystem exists around Docker WIP - better resource isolation, hardening, performance, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}