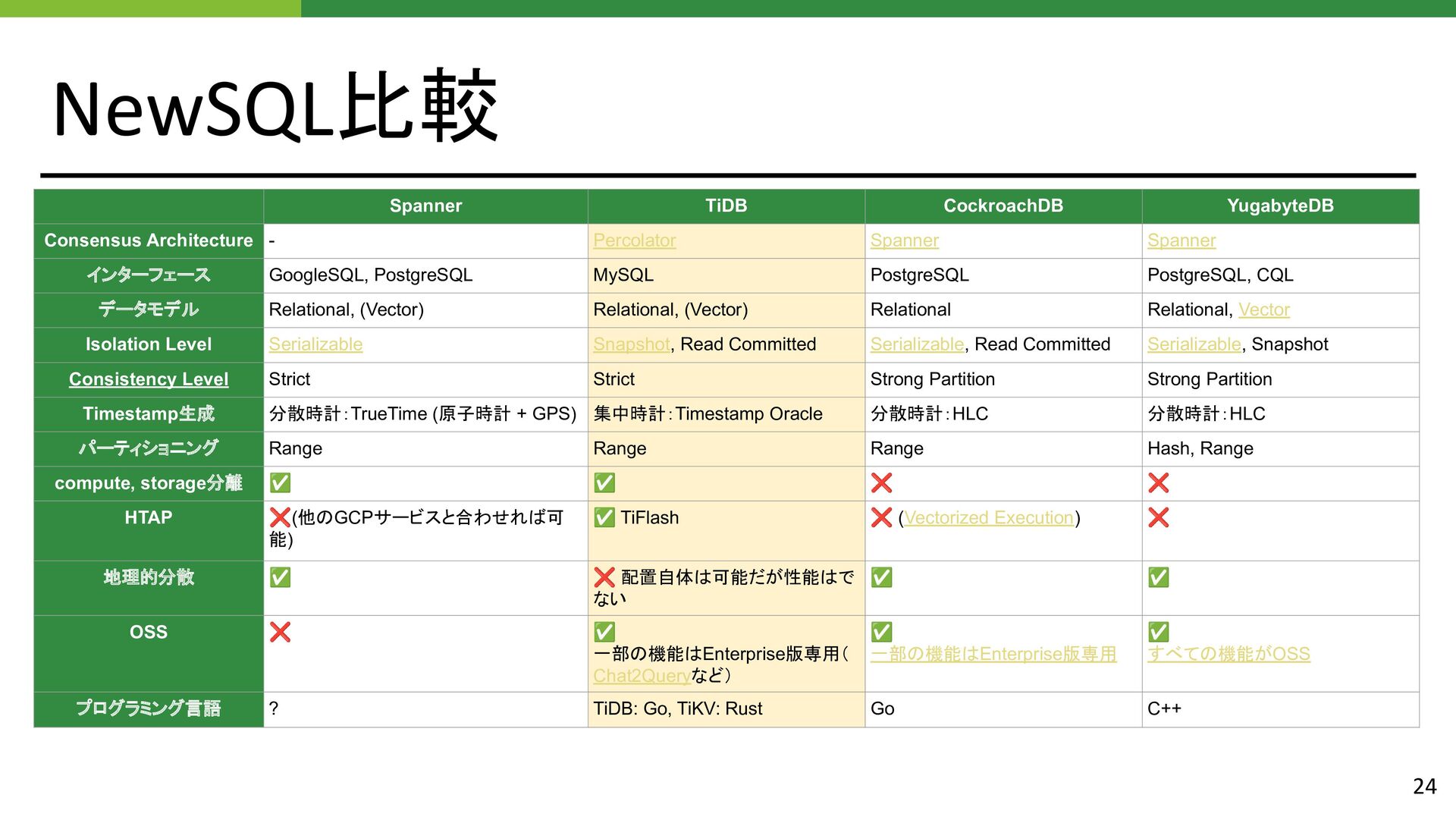
Spanner インターフェース GoogleSQL, PostgreSQL MySQL PostgreSQL PostgreSQL, CQL データモデル Relational, (Vector) Relational, (Vector) Relational Relational, Vector Isolation Level Serializable Snapshot, Read Committed Serializable, Read Committed Serializable, Snapshot Consistency Level Strict Strict Strong Partition Strong Partition Timestamp生成 分散時計:TrueTime (原子時計 + GPS) 集中時計:Timestamp Oracle 分散時計:HLC 分散時計:HLC パーティショニング Range Range Range Hash, Range compute, storage分離 ✅ ✅ ❌ ❌ HTAP ❌(他のGCPサービスと合わせれば可 能) ✅ TiFlash ❌ (Vectorized Execution) ❌ 地理的分散 ✅ ❌ 配置自体は可能だが性能はで ない ✅ ✅ OSS ❌ ✅ 一部の機能はEnterprise版専用( Chat2Queryなど) ✅ 一部の機能はEnterprise版専用 ✅ すべての機能がOSS プログラミング言語 ? TiDB: Go, TiKV: Rust Go C++ 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
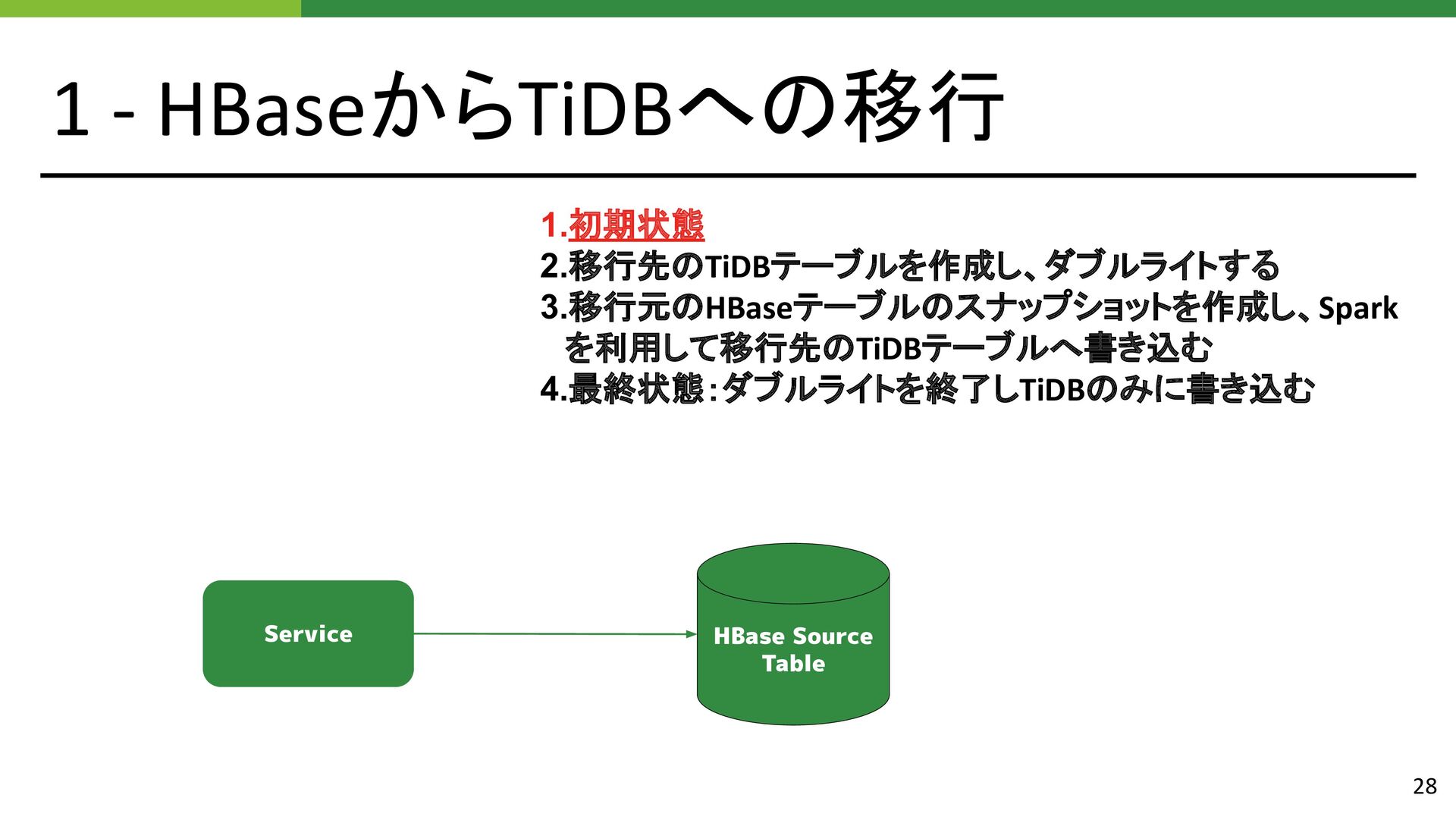{kind=link}
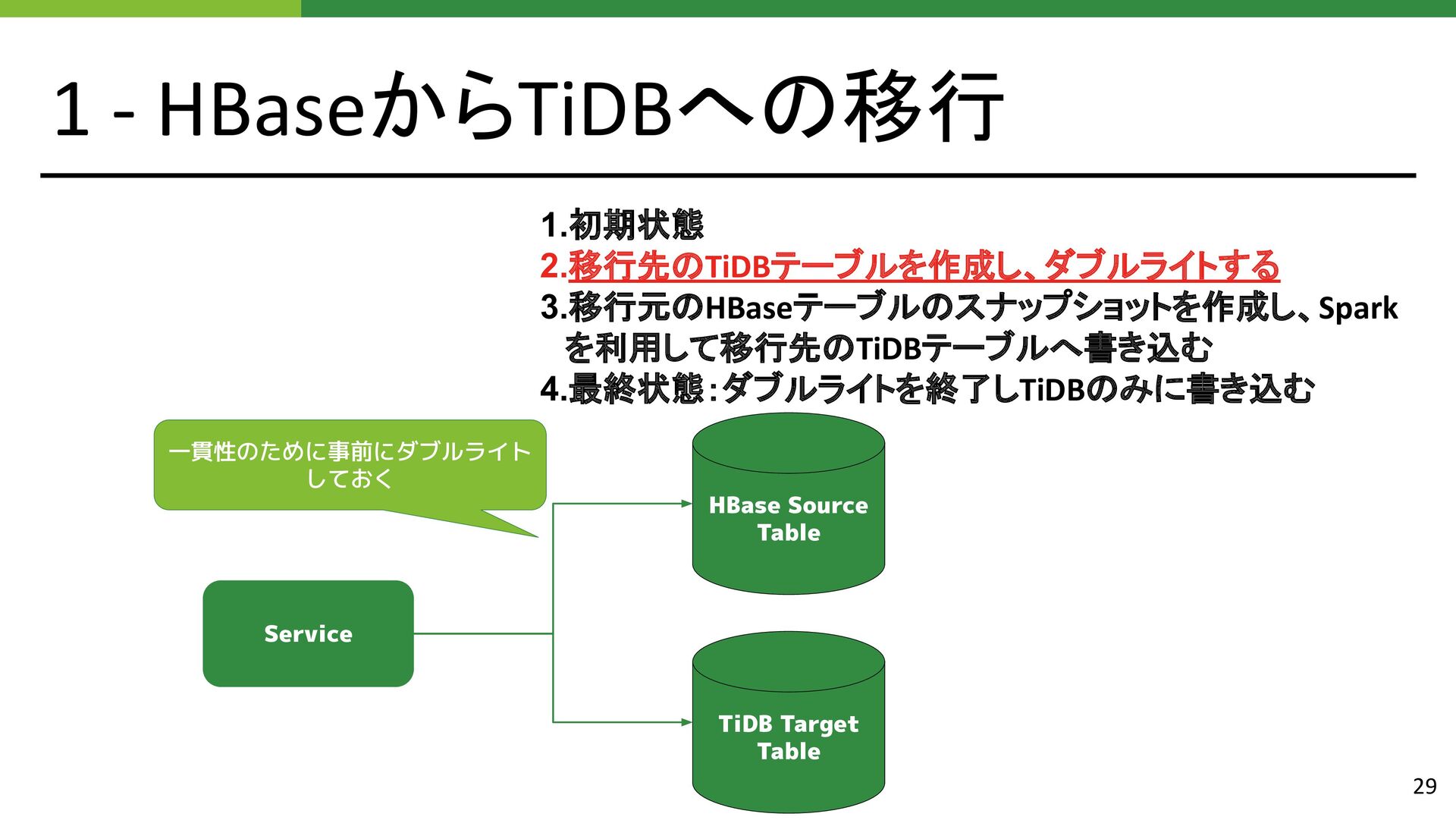{kind=link}
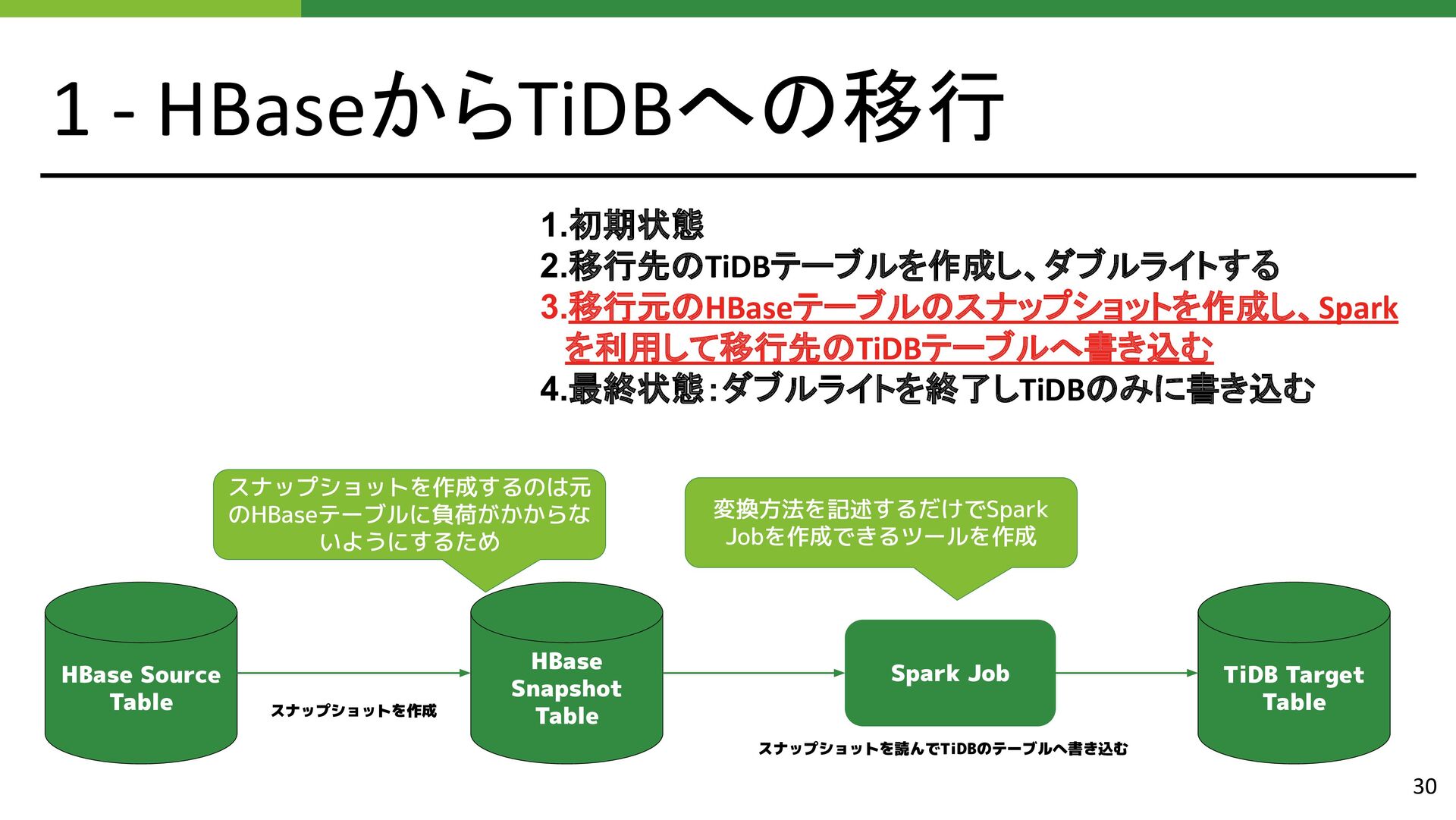{kind=link}
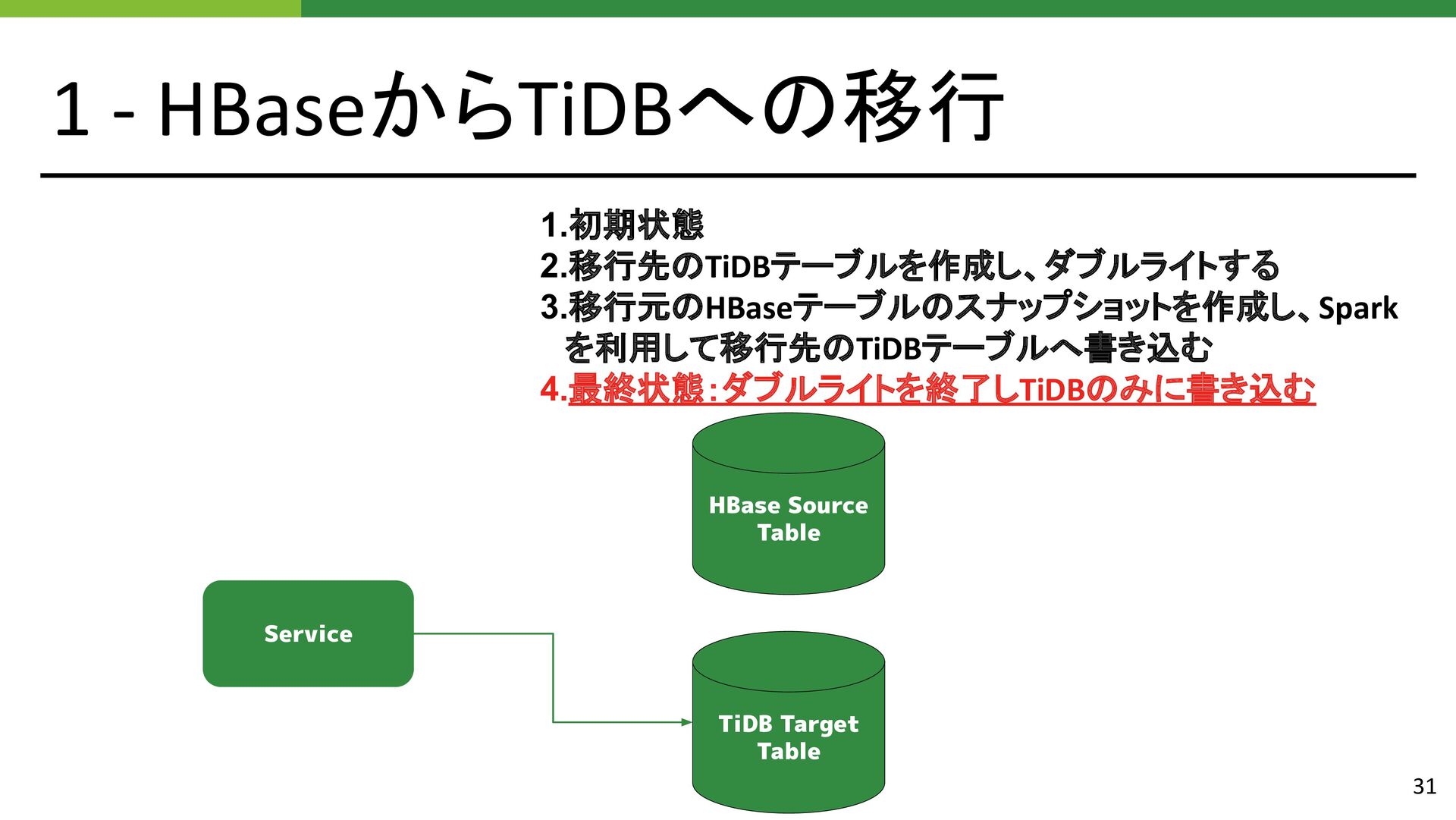{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
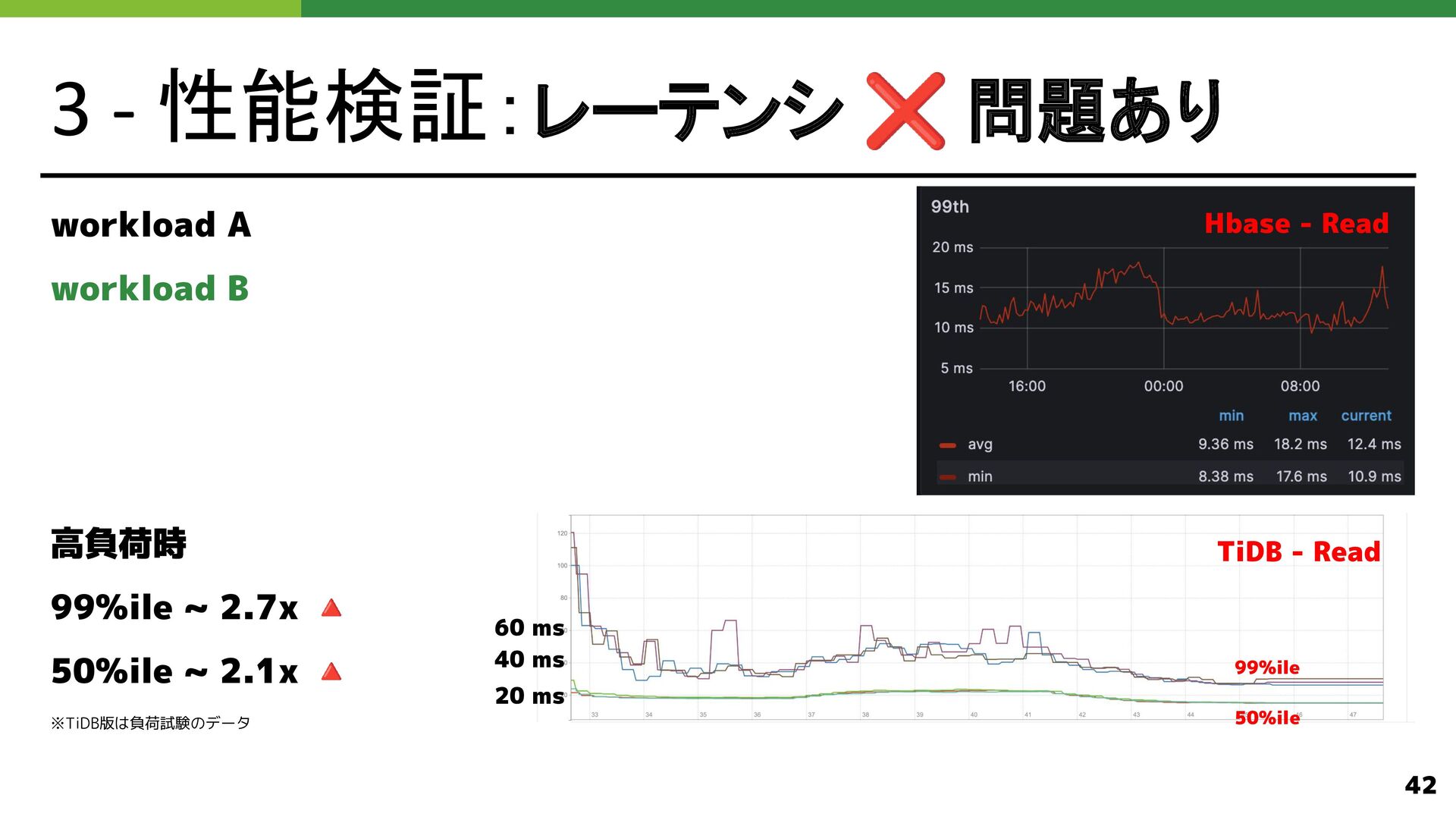{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}