https://pingcap.co.jp/tidb-user-day/jul-2024/
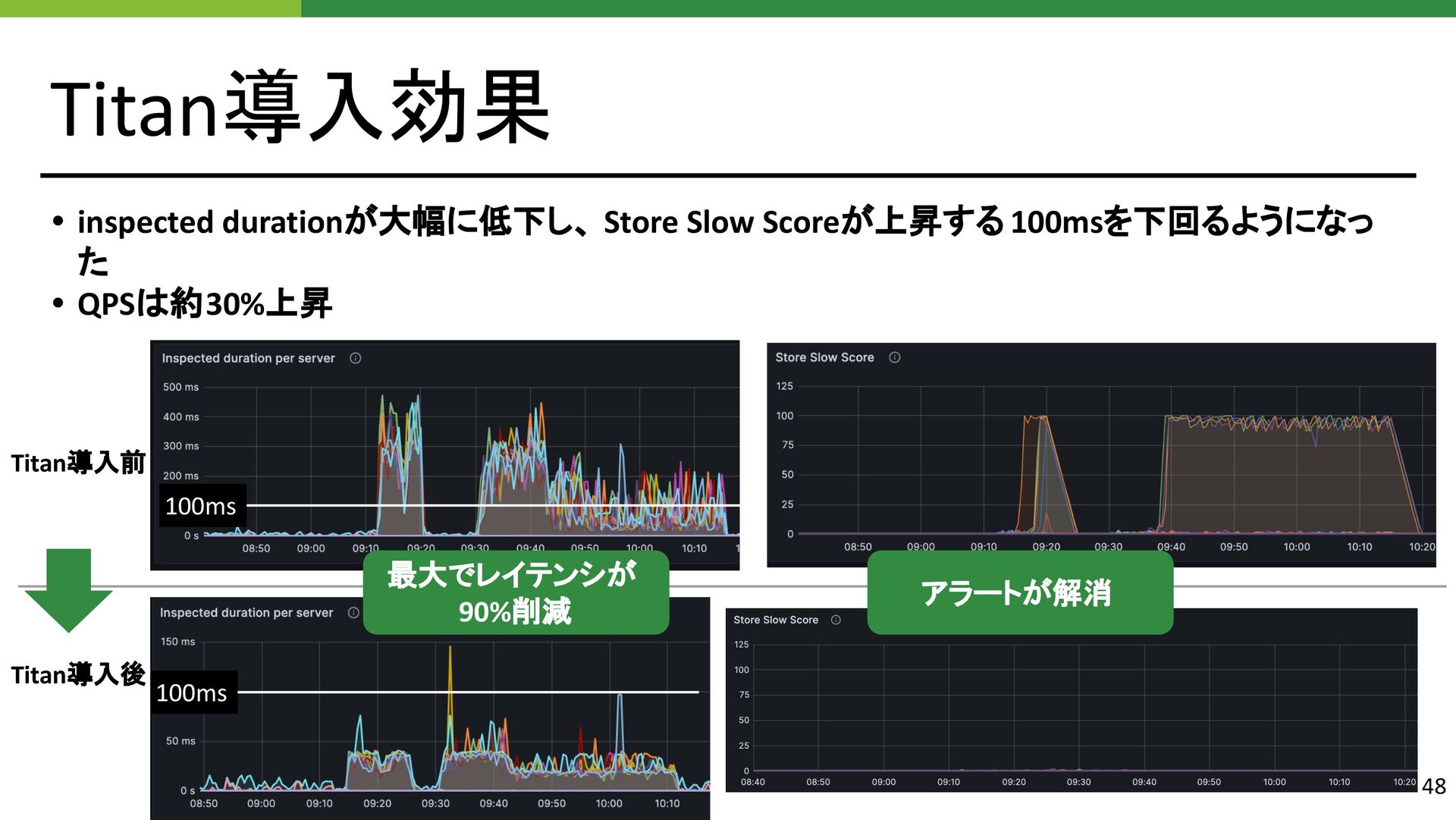
株式会社サイバーエージェントでは、様々なサービスから取得したデータをリアルタイムに分析するための大規模データ処理基盤を開発・運用しています。そして運用負担を軽減するため、OLTPクエリに使用していたHBaseをTiDBに置き換えて約半年運用しています。本発表では、まずHBaseの課題とTiDBの選定理由を説明します。次にHBaseからTiDBへの移行方法を紹介し、移行後の性能と運用面での変化について報告します。また、移行後に発生した大規模データのバッチ書き込みにおける性能問題と、その改善方法についても解説します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
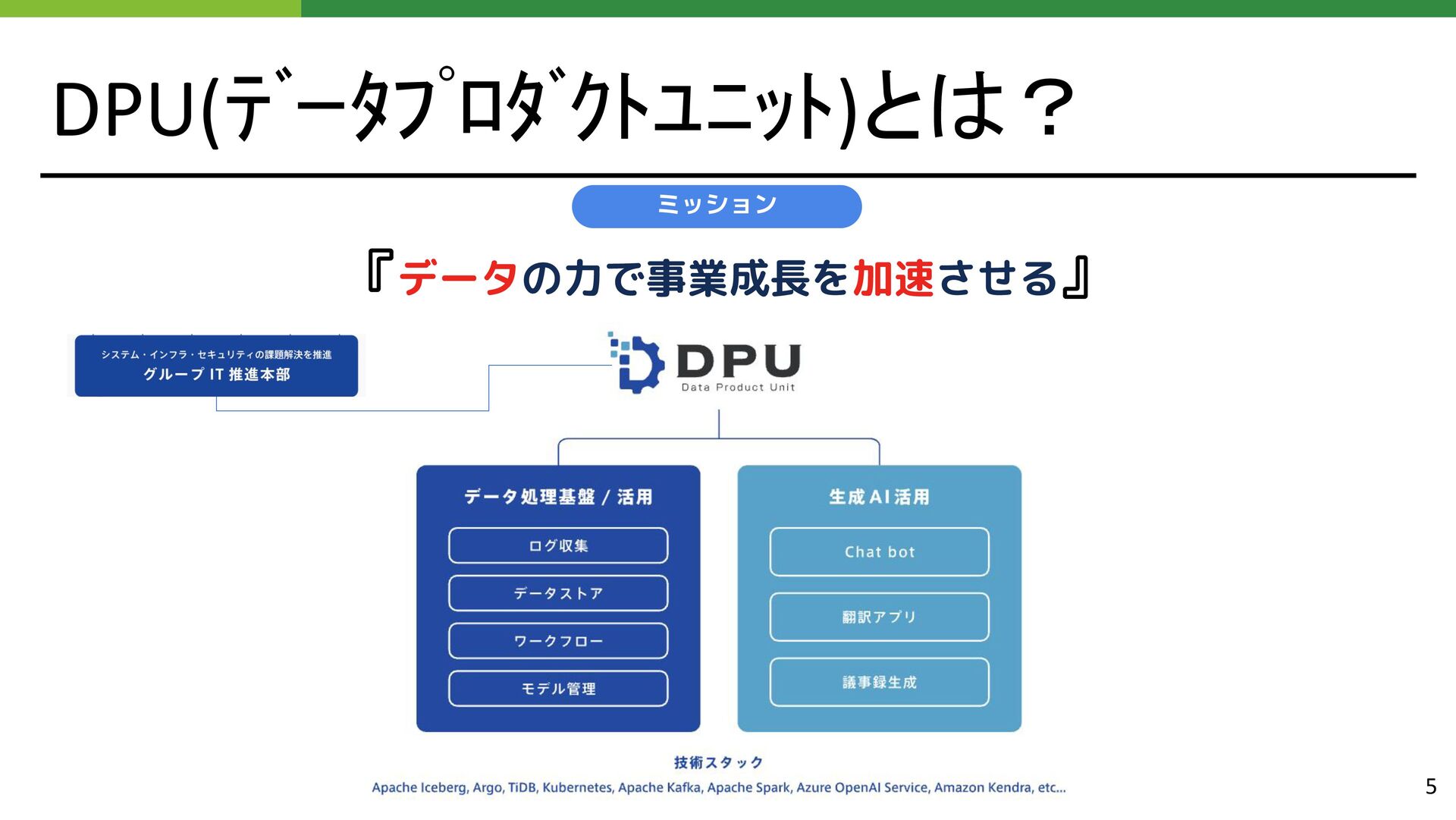{kind=link}
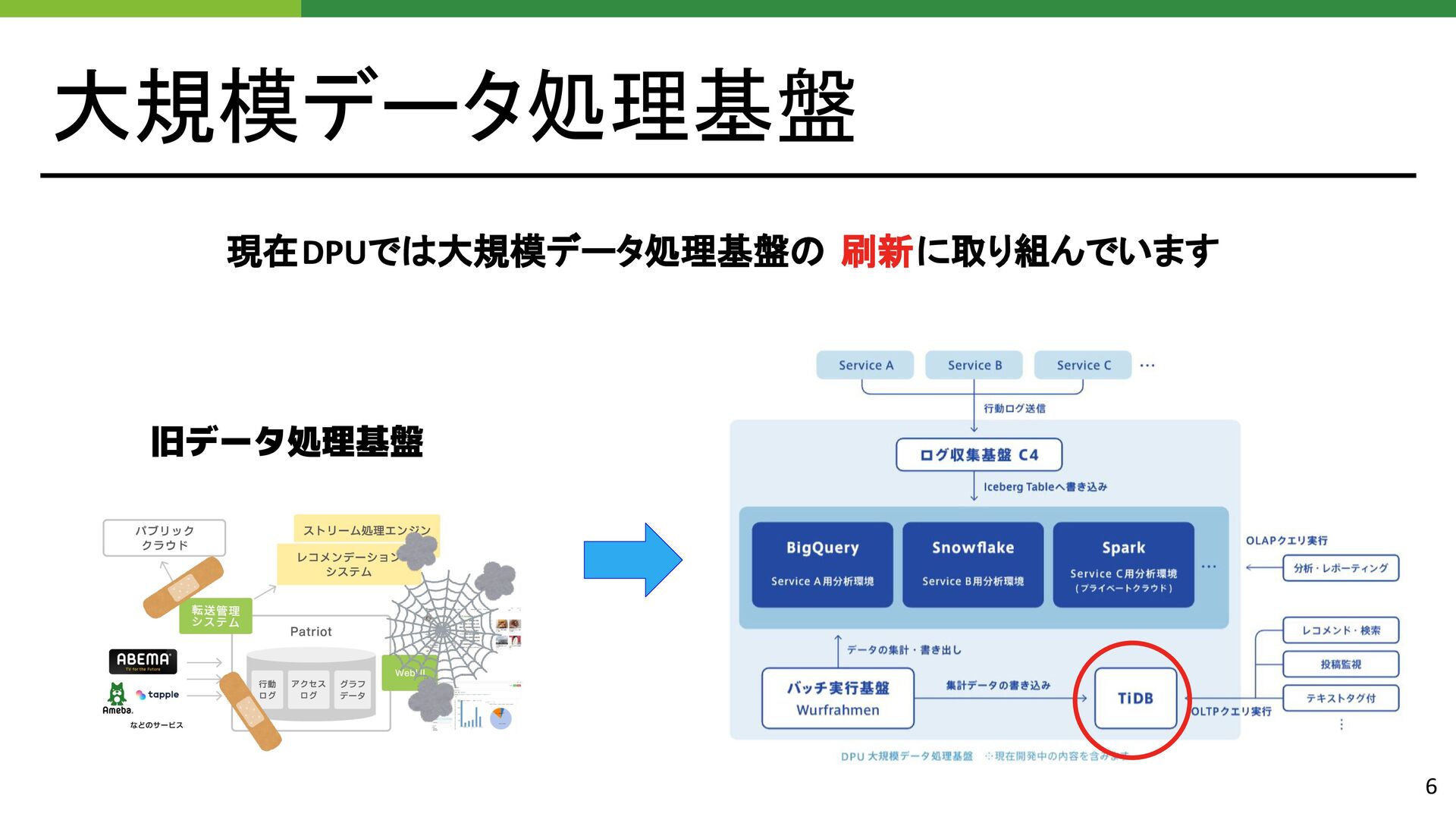{kind=link}
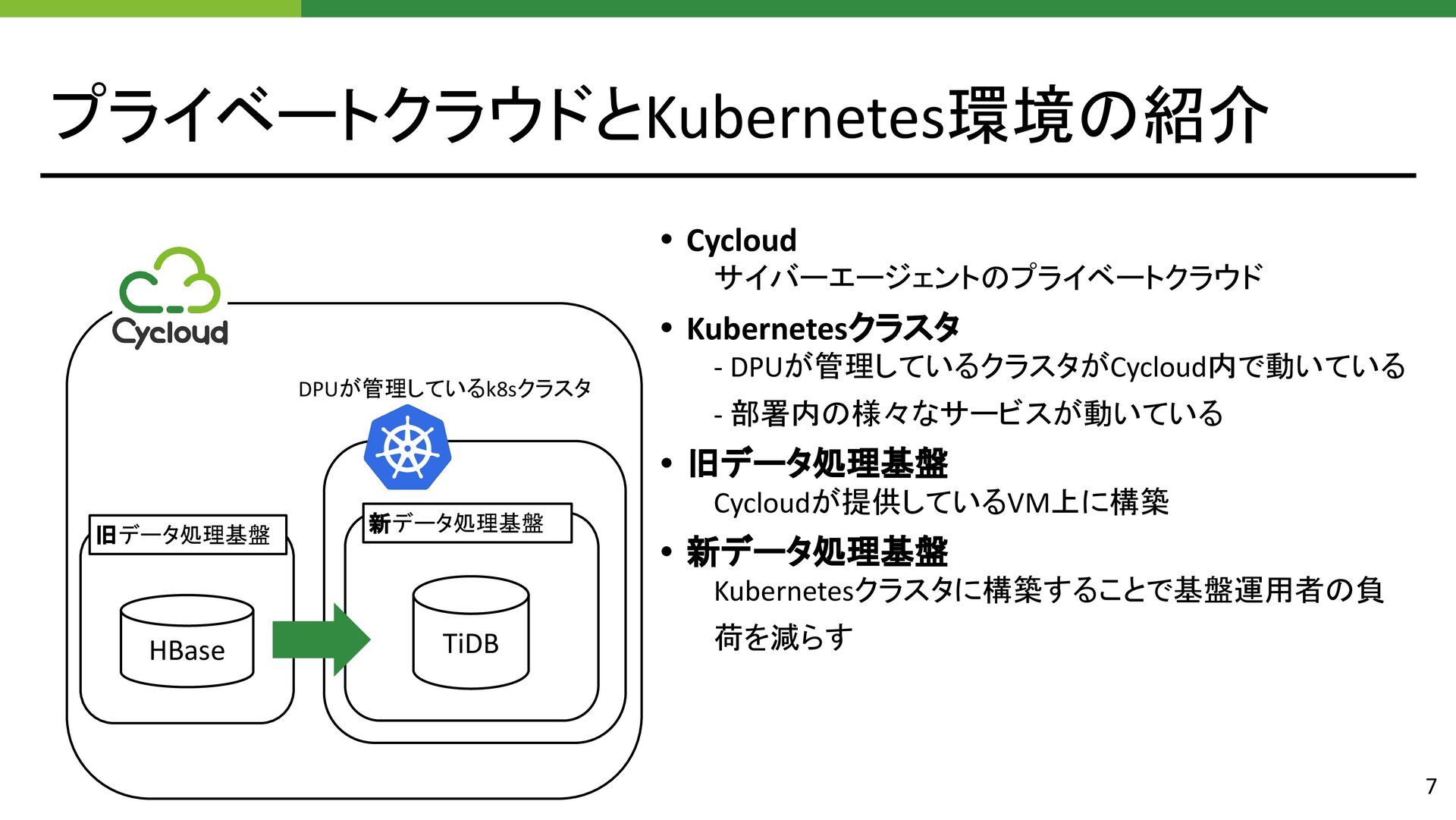{kind=link}
{kind=link}
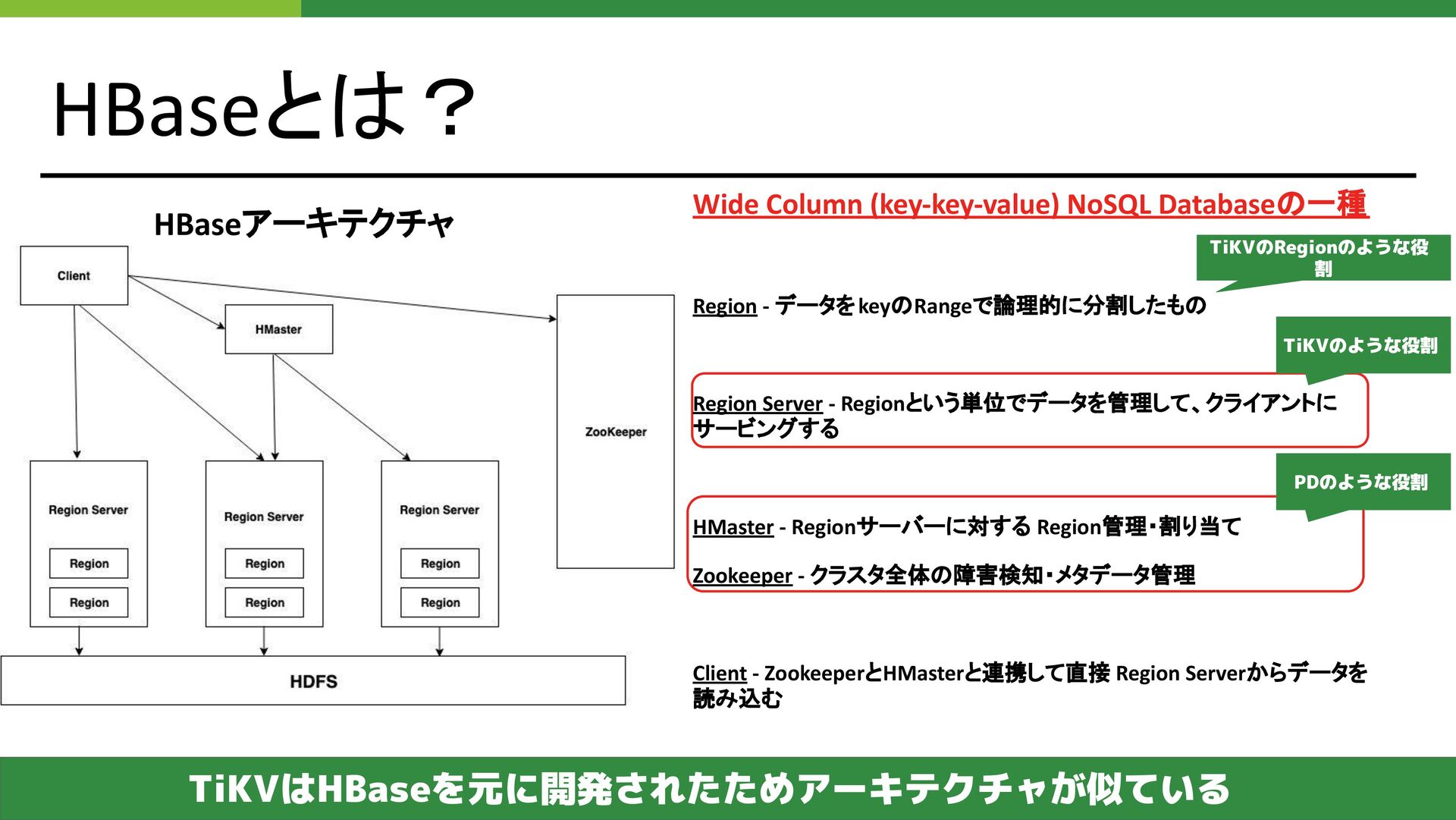{kind=link}
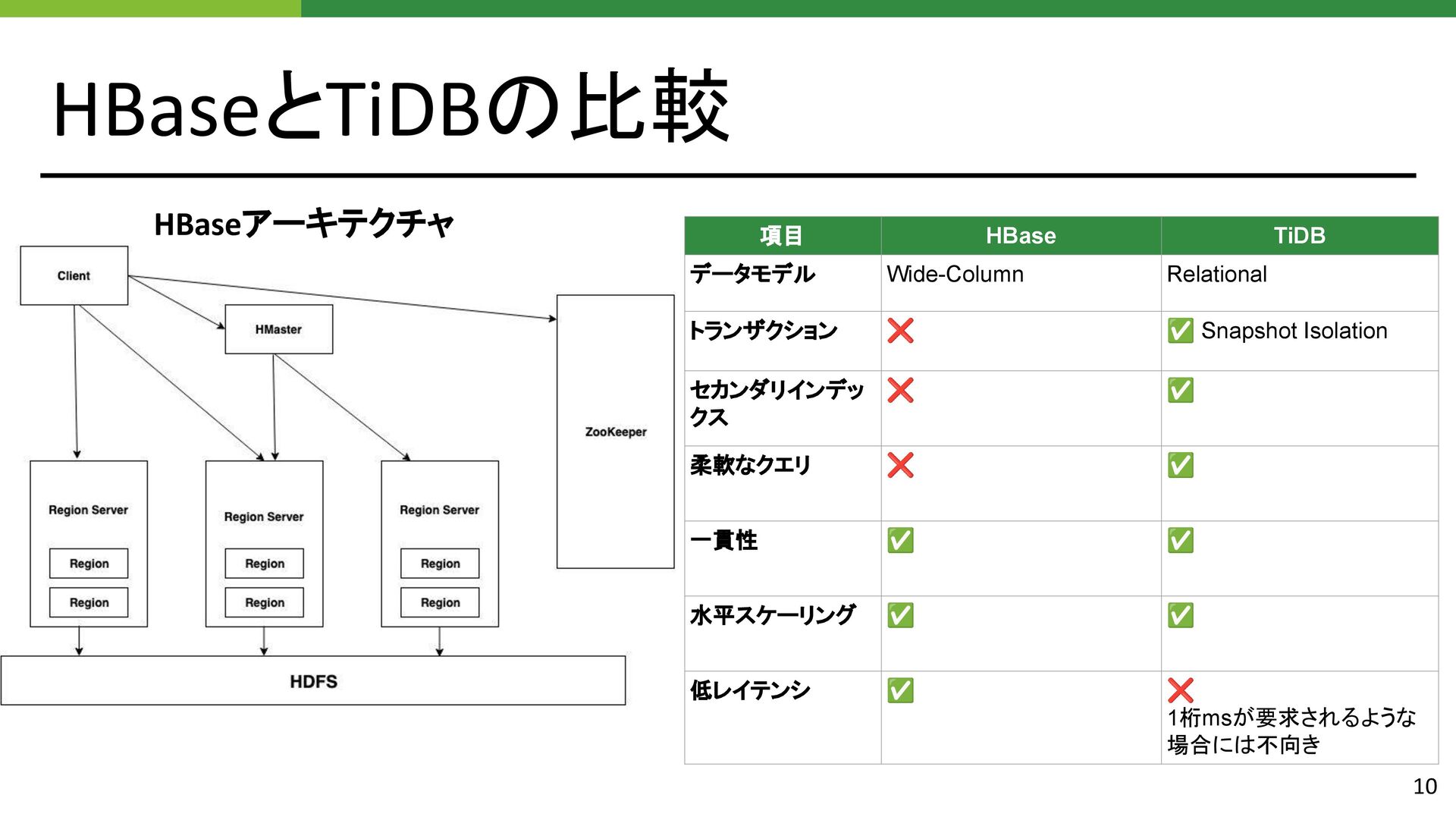{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
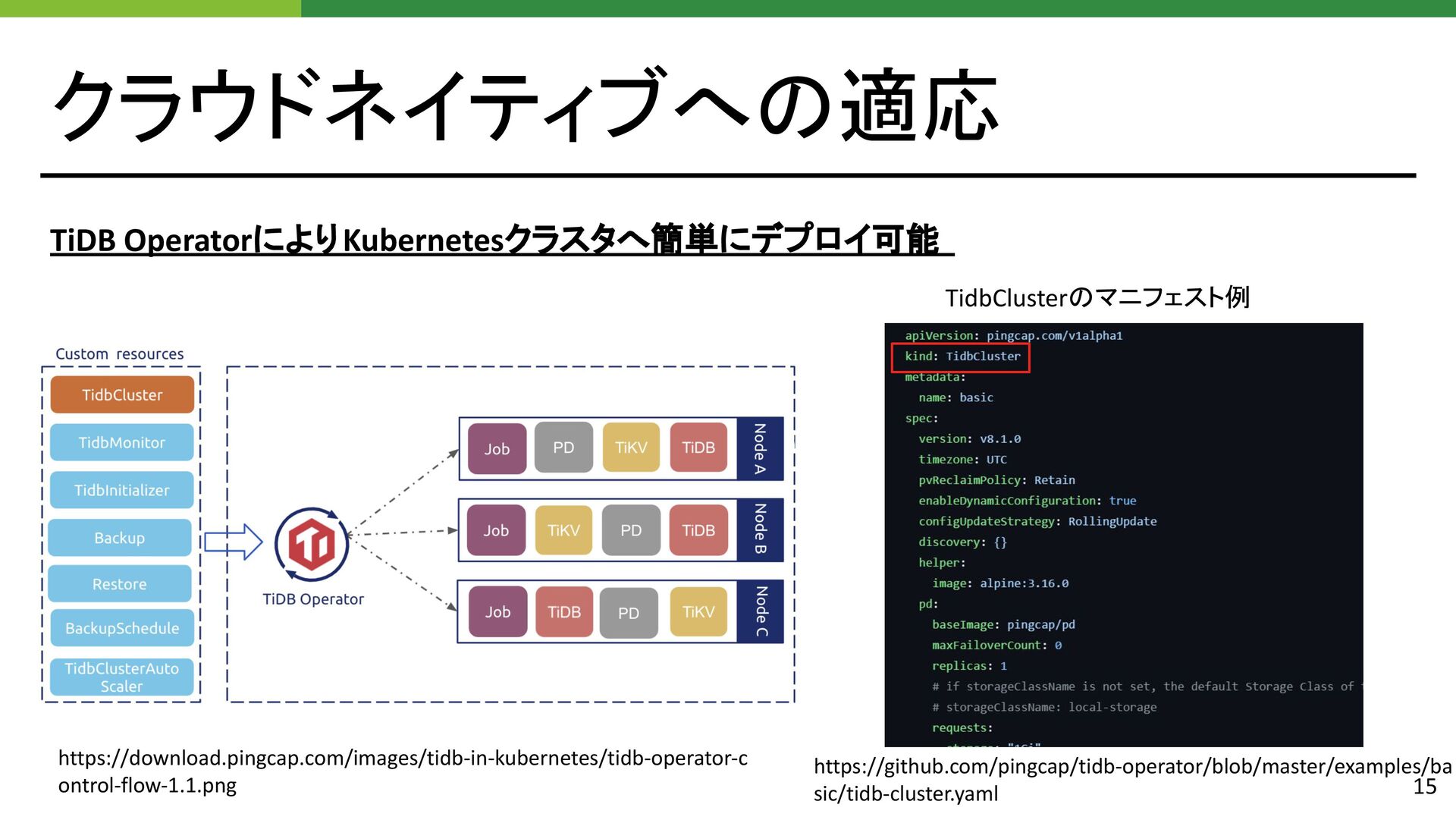{kind=link}
{kind=link}
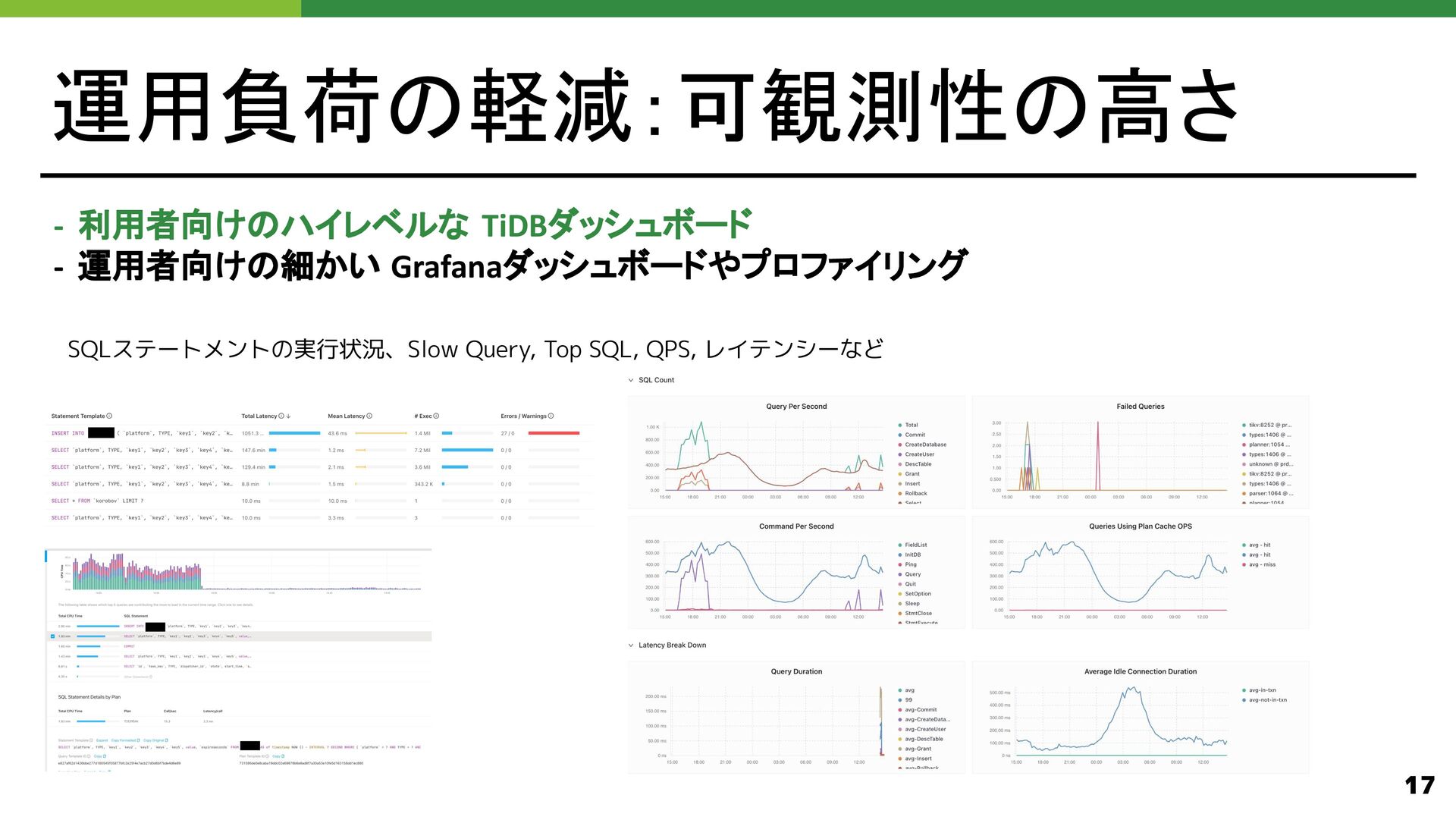{kind=link}
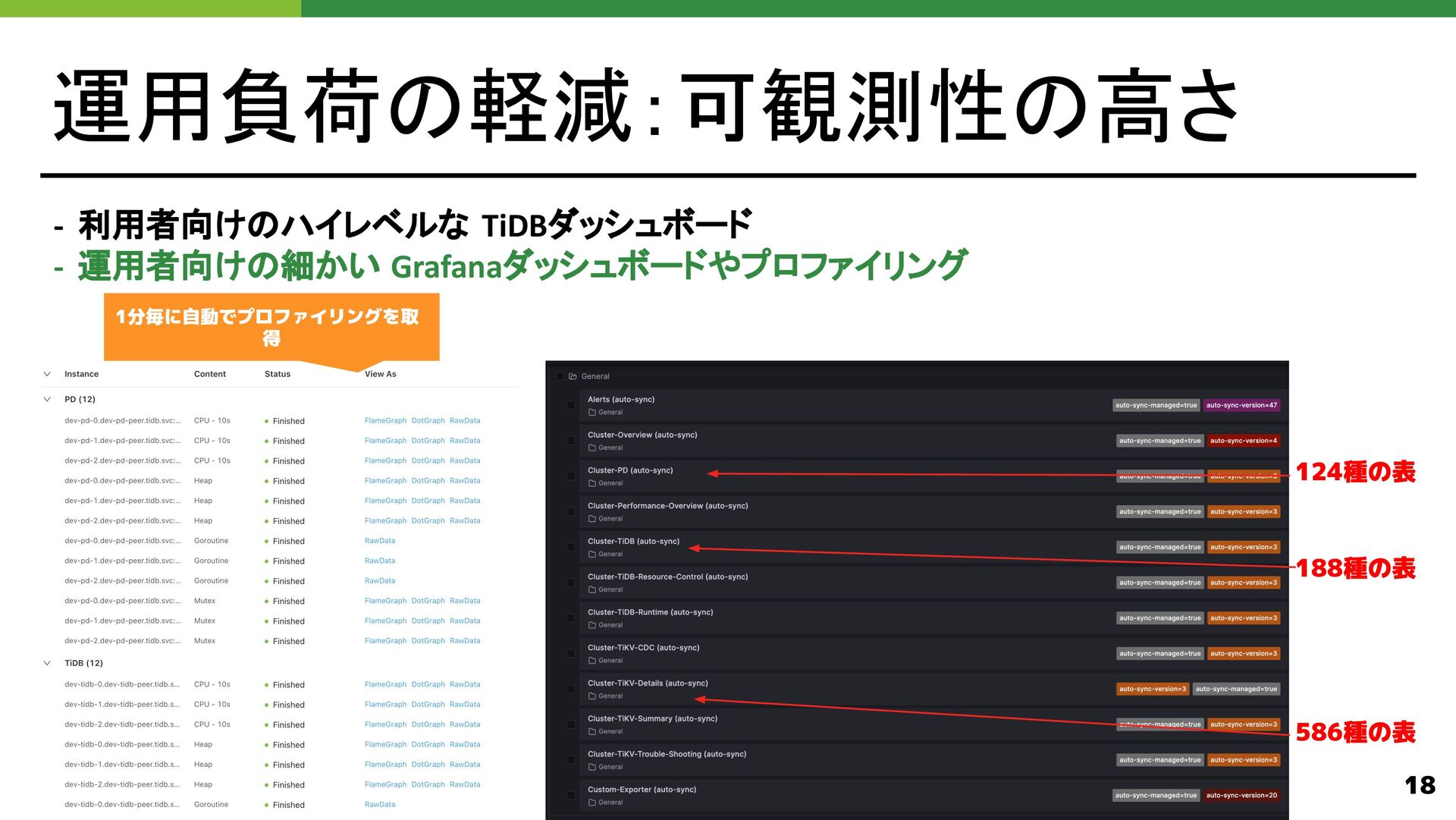{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
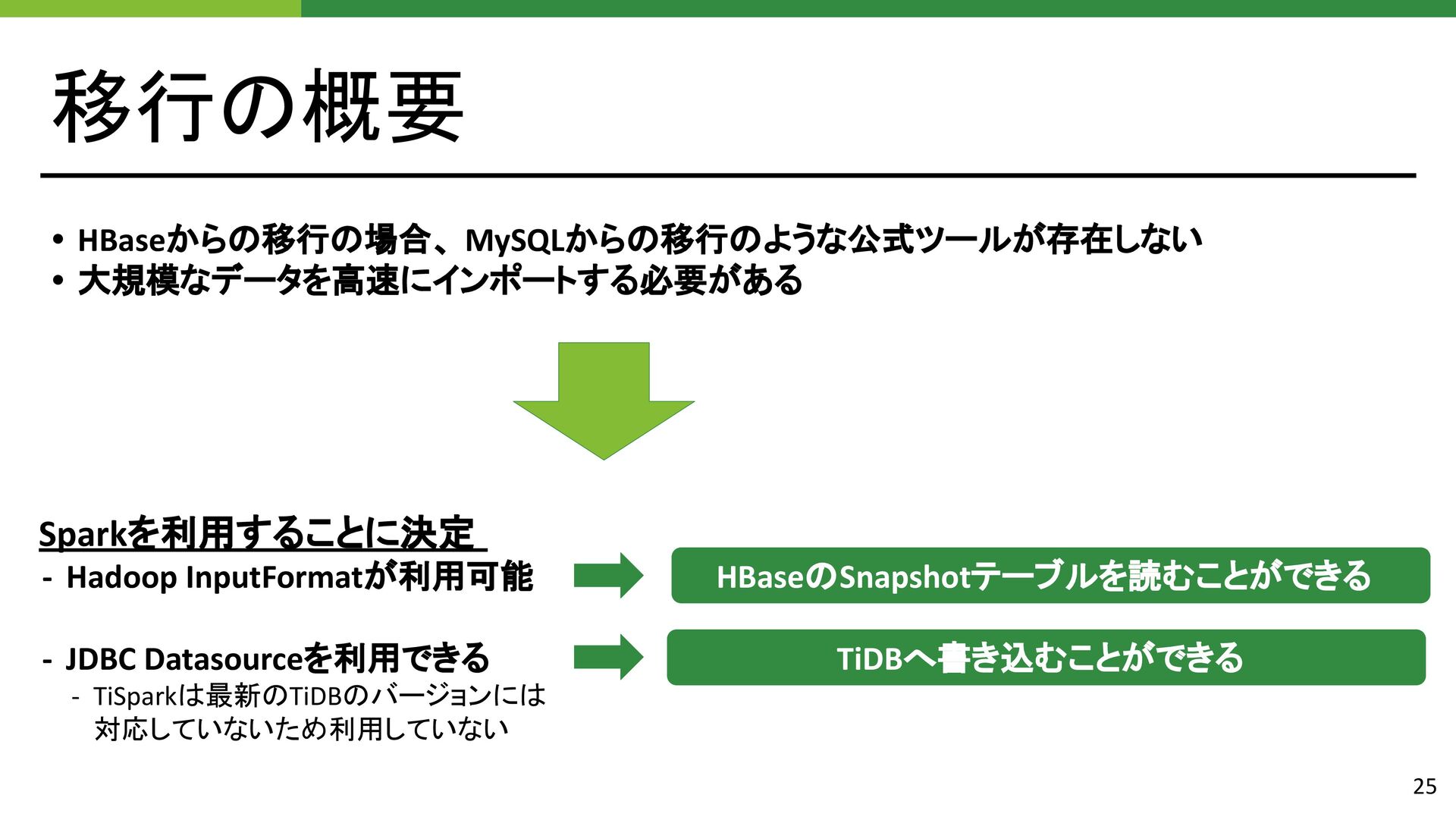{kind=link}
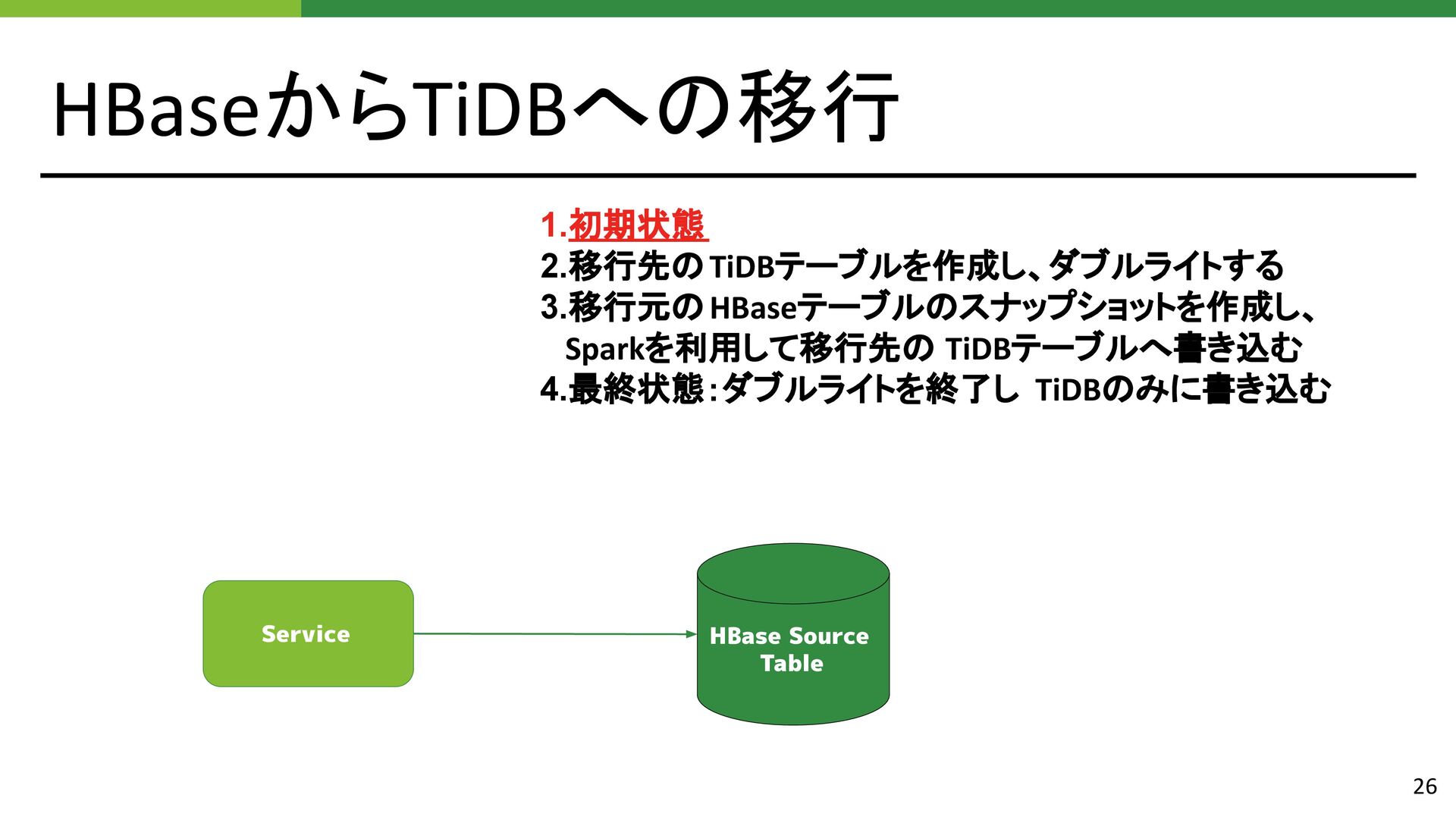{kind=link}
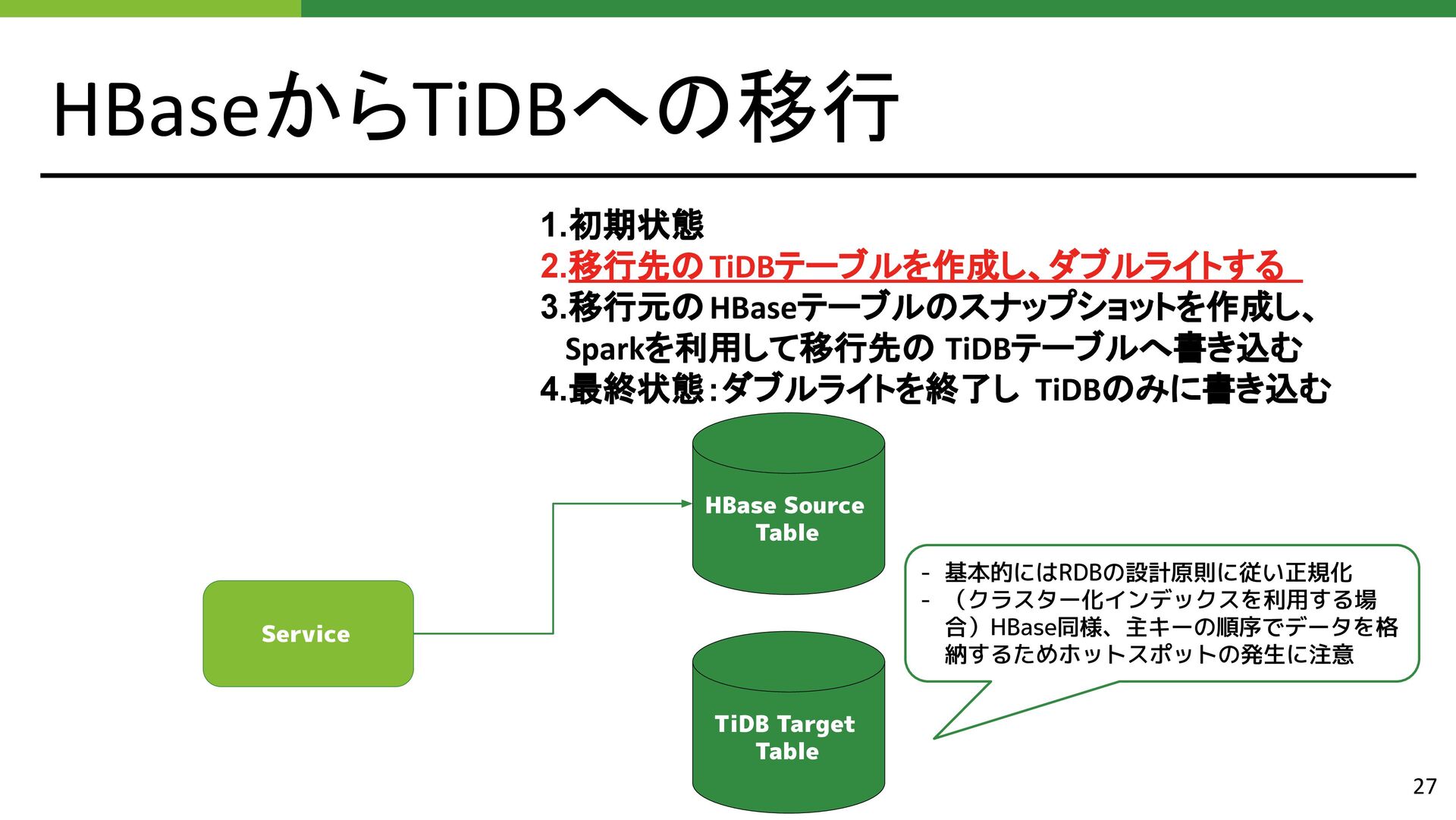{kind=link}
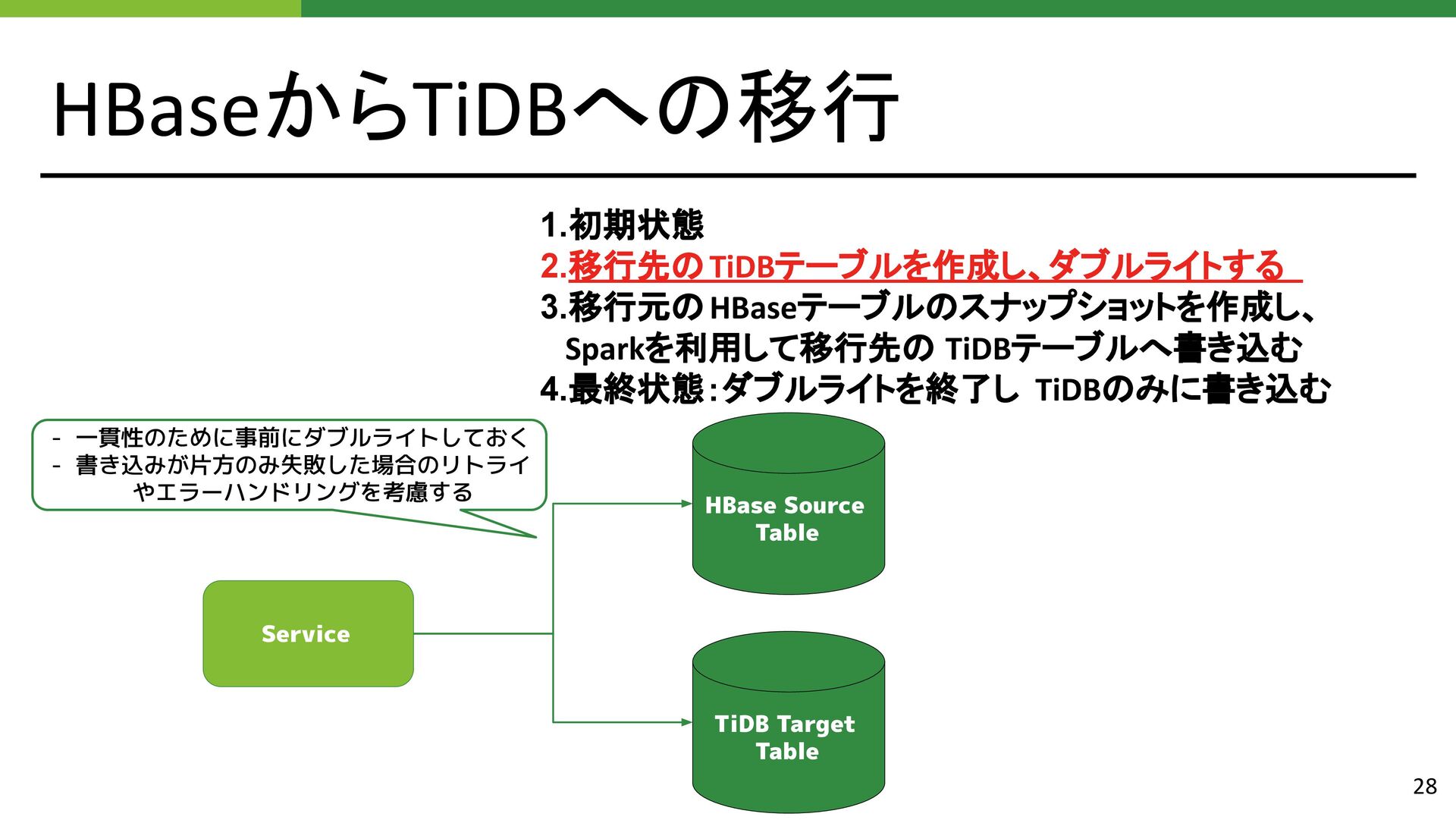{kind=link}
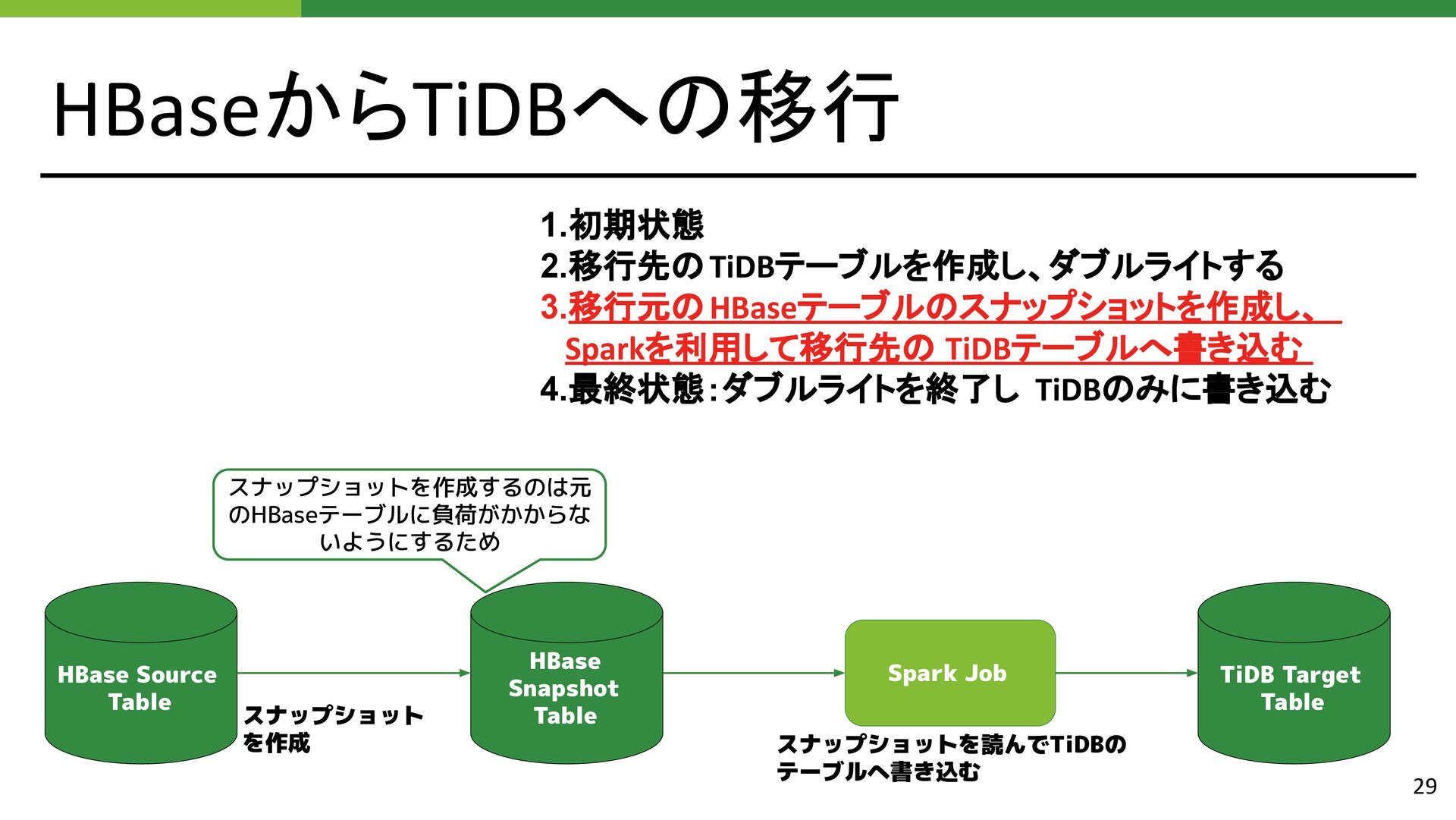{kind=link}
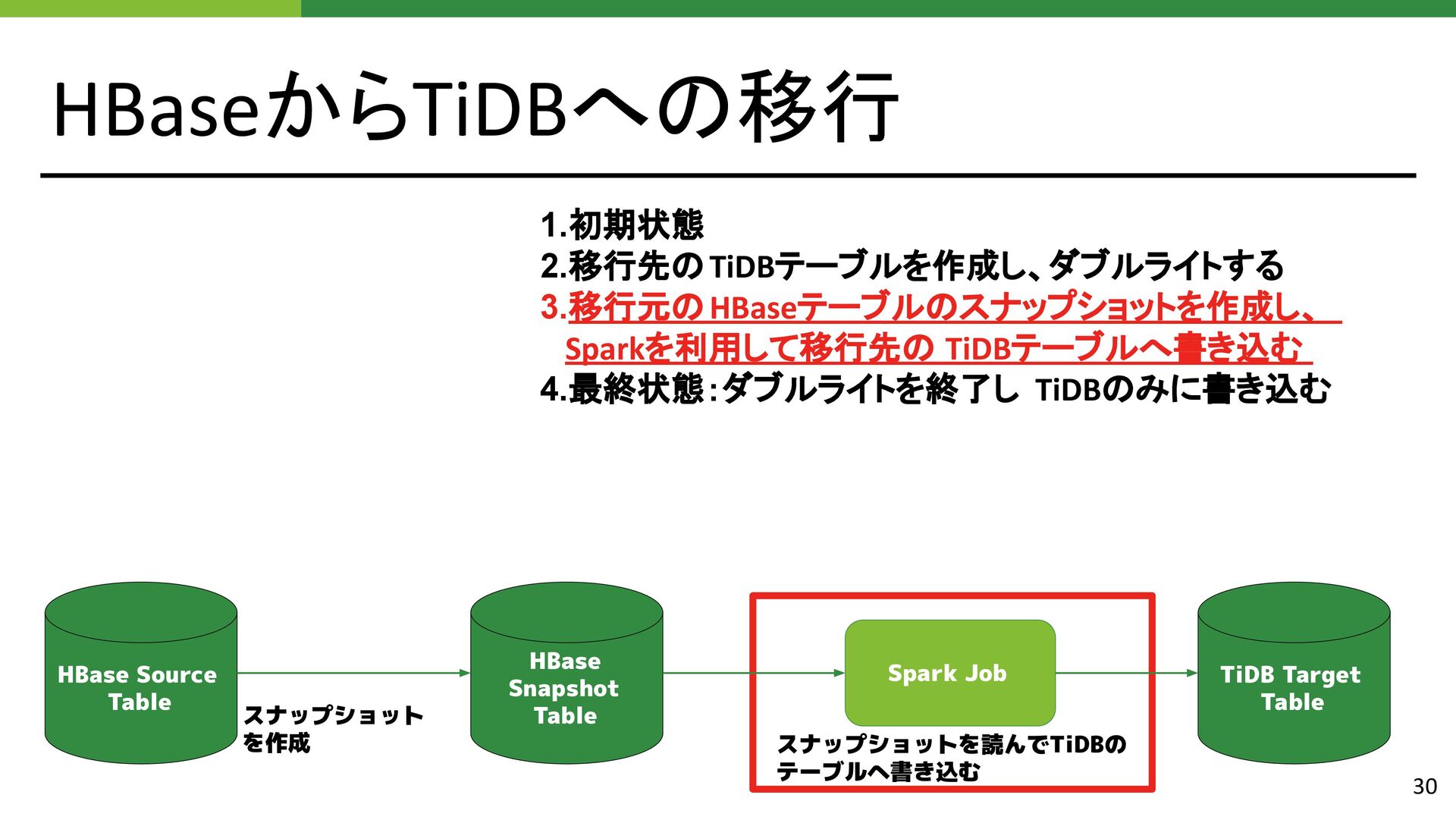{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
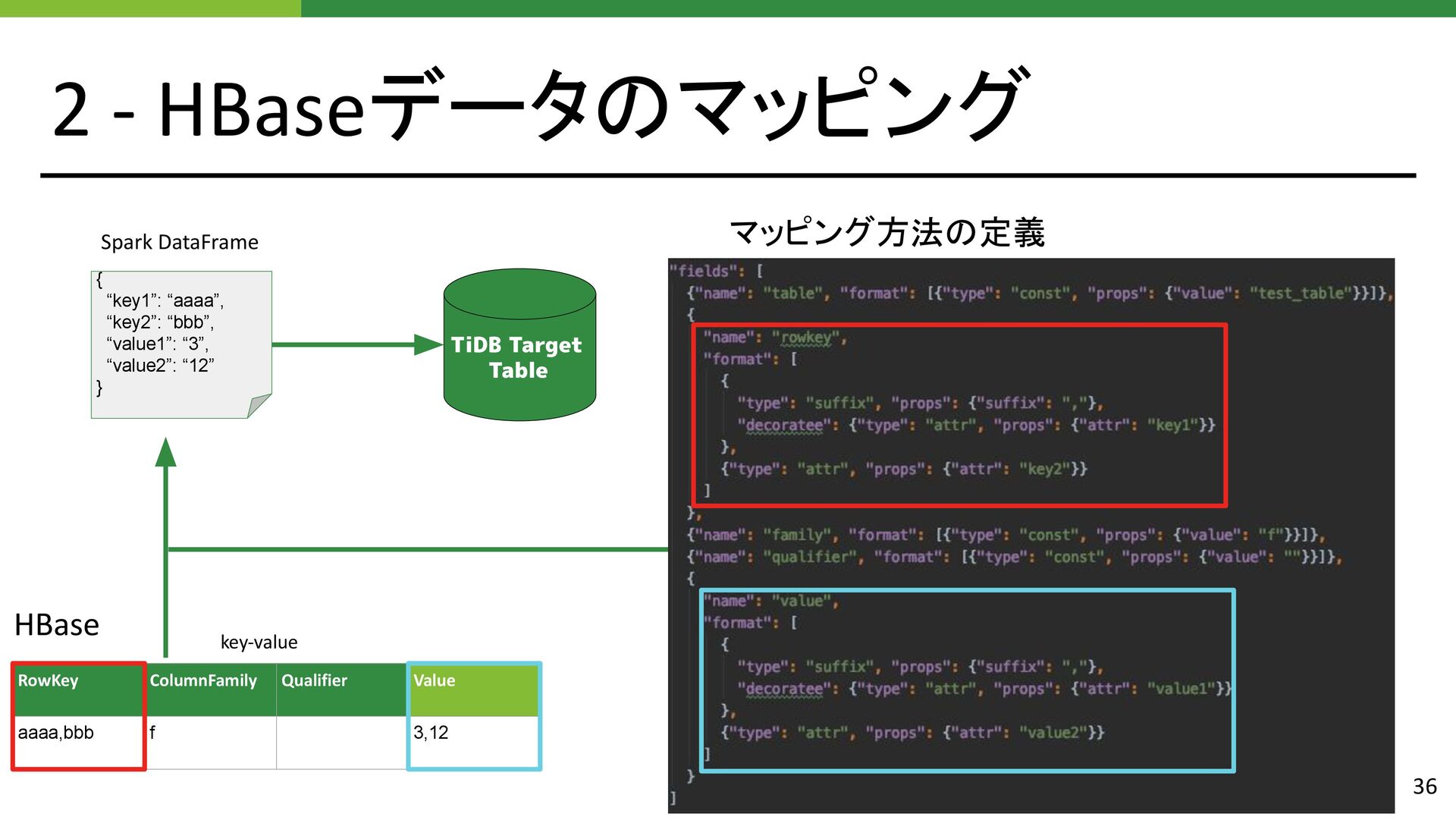{kind=link}
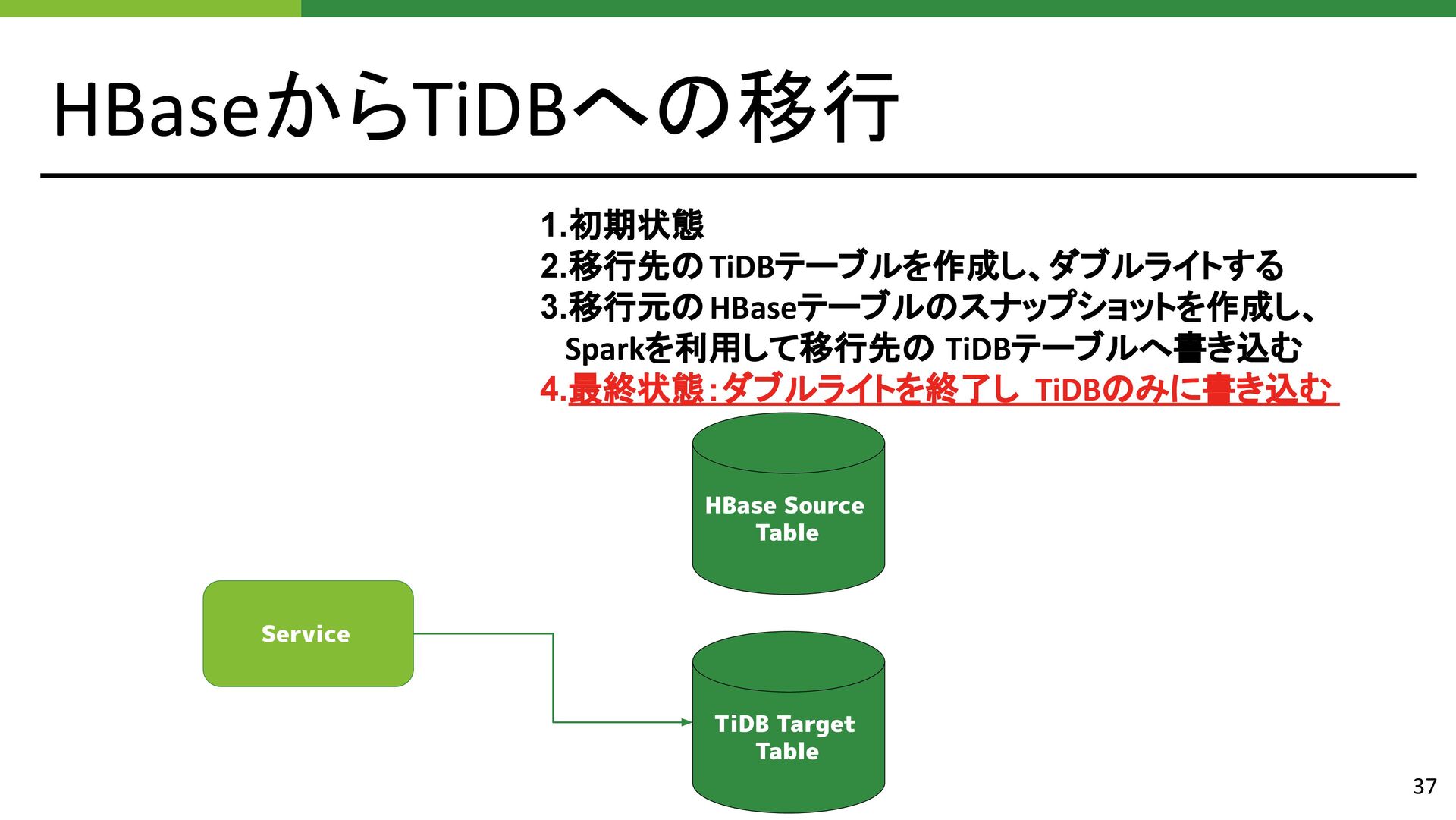{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
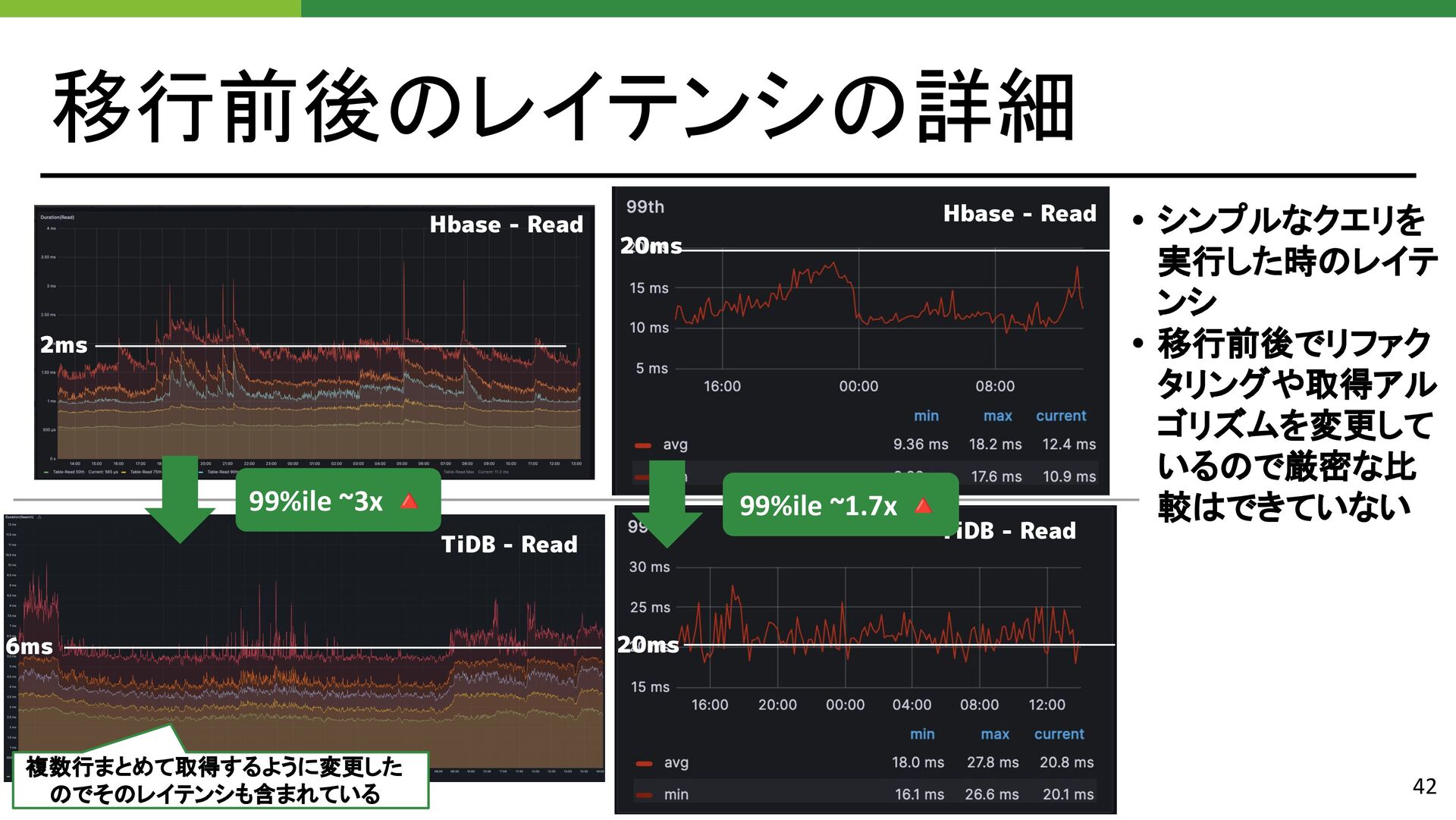{kind=link}
{kind=link}
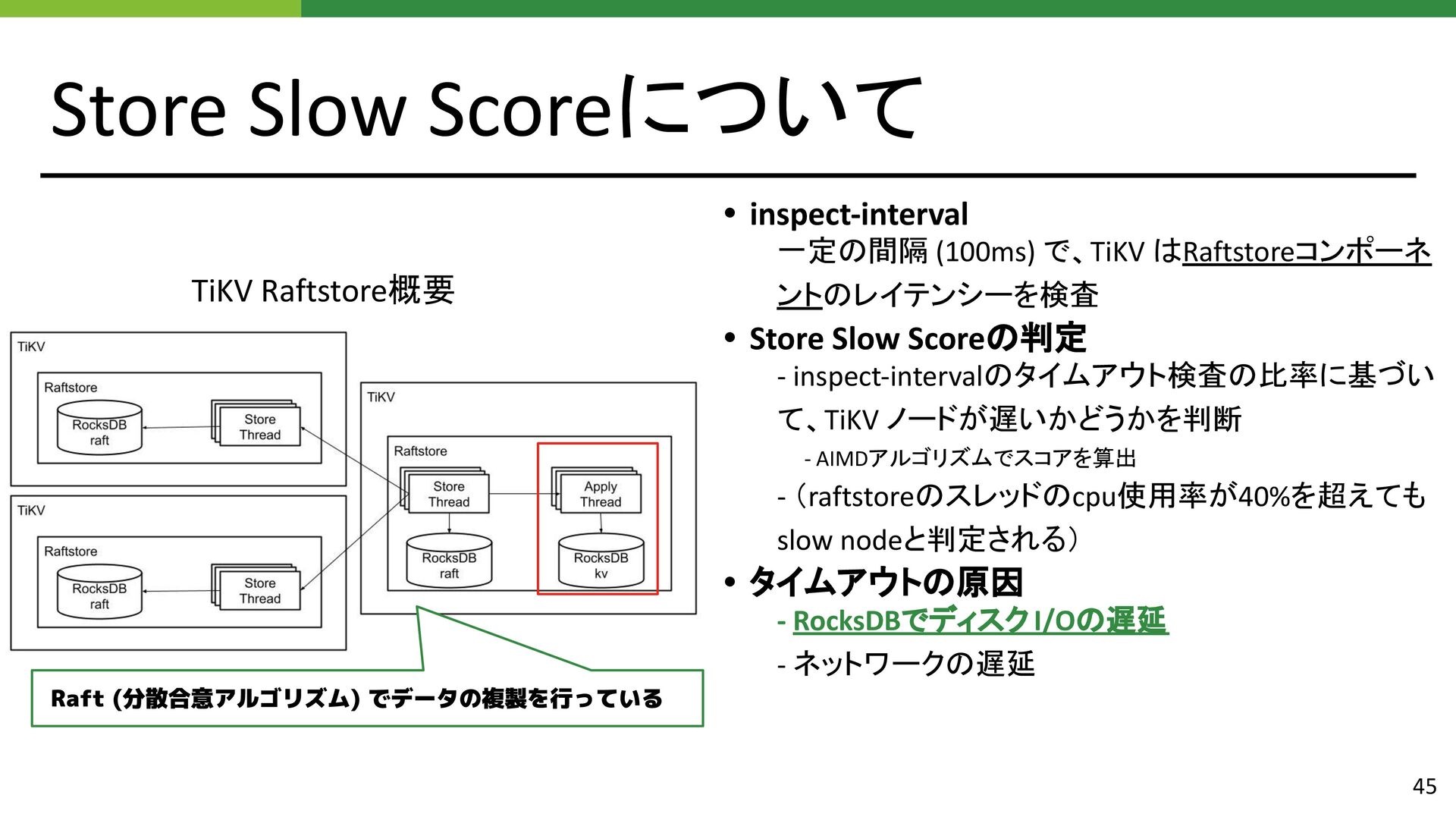
{kind=link}
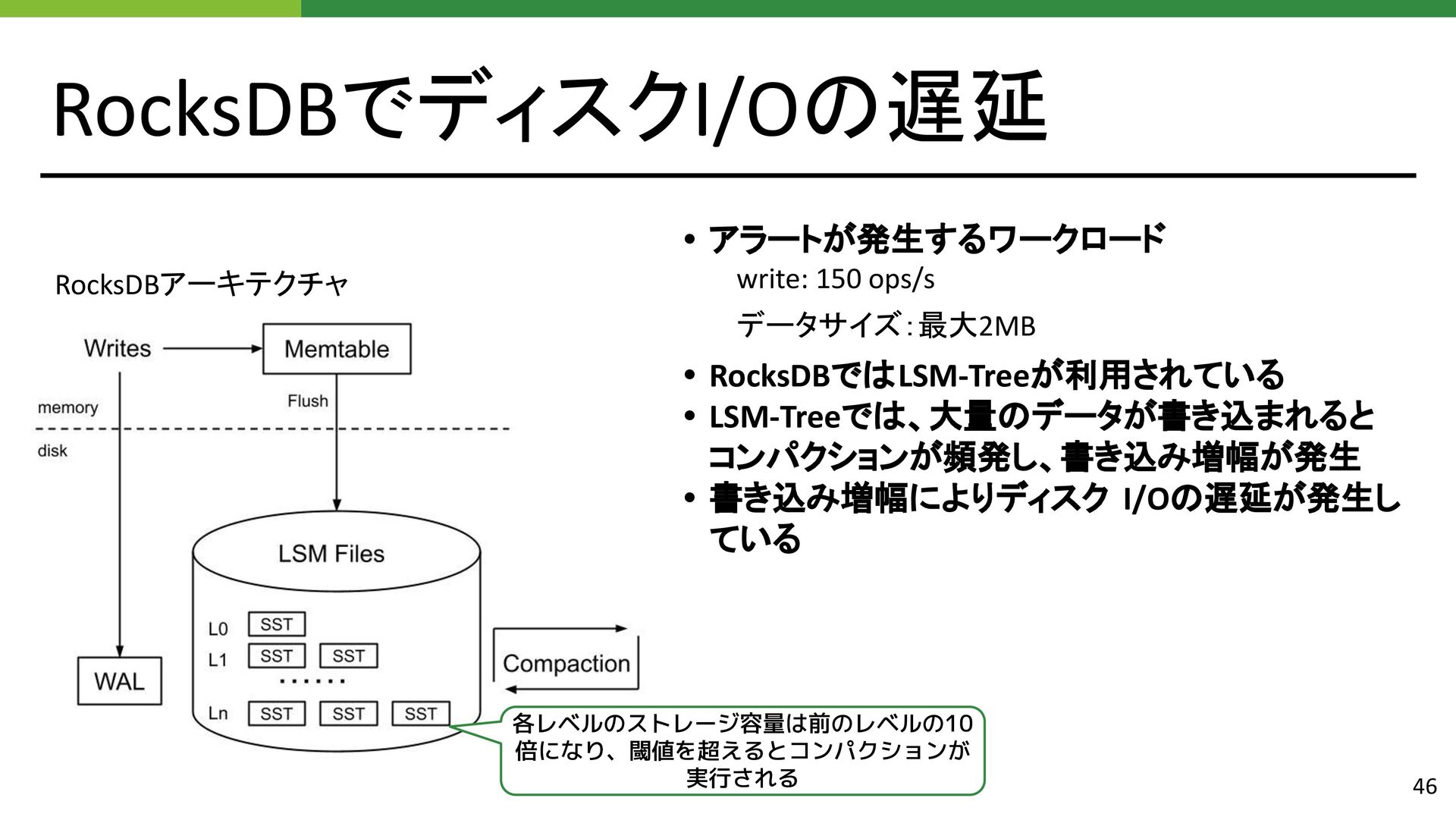
{kind=link}
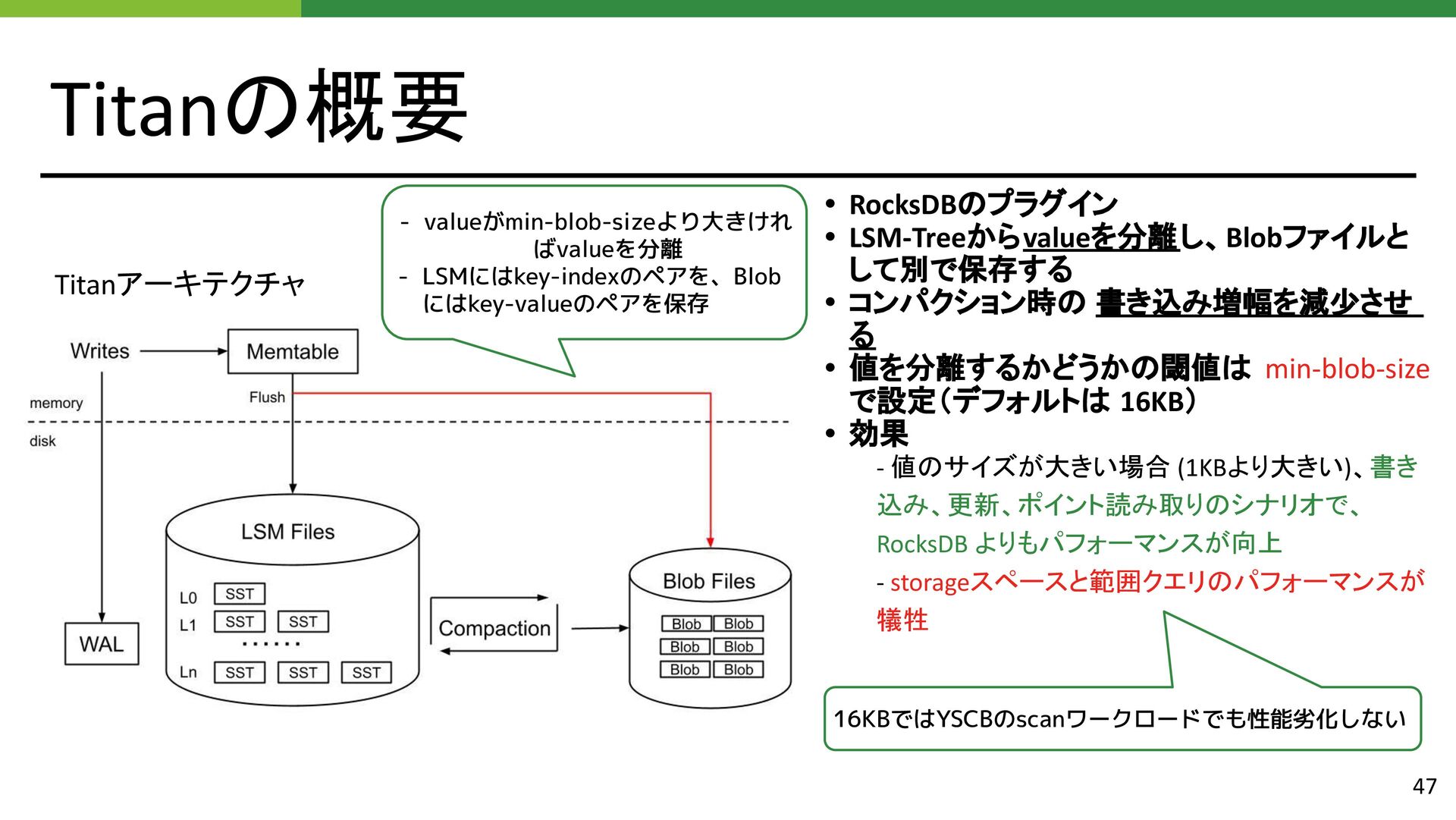
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}