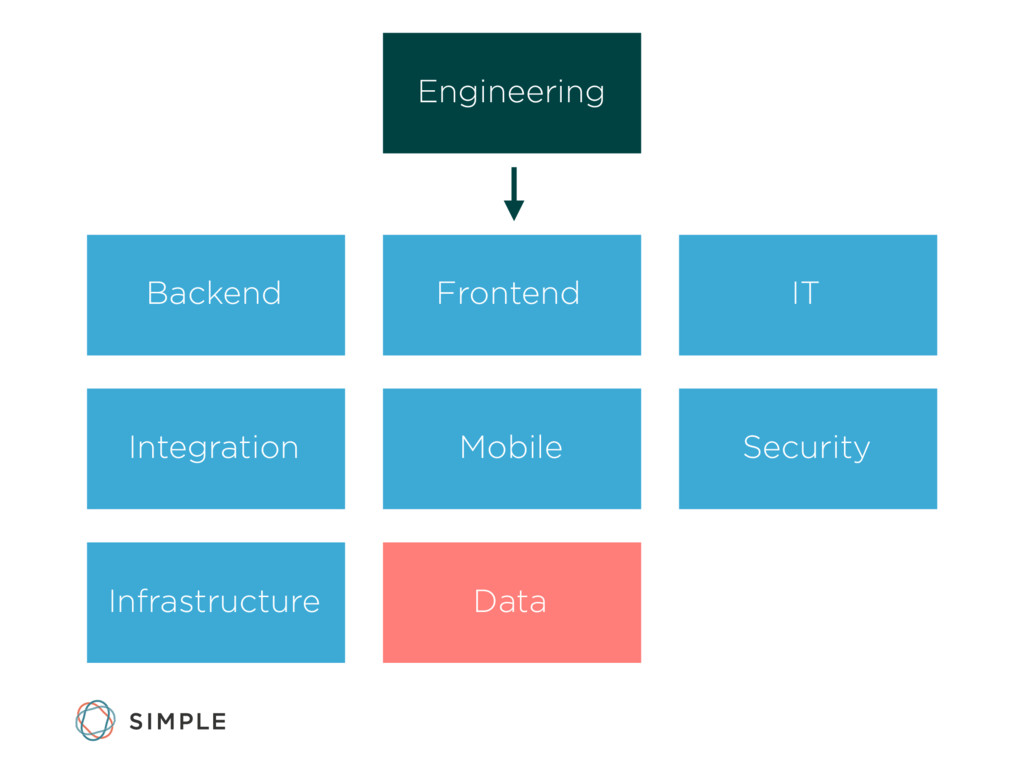
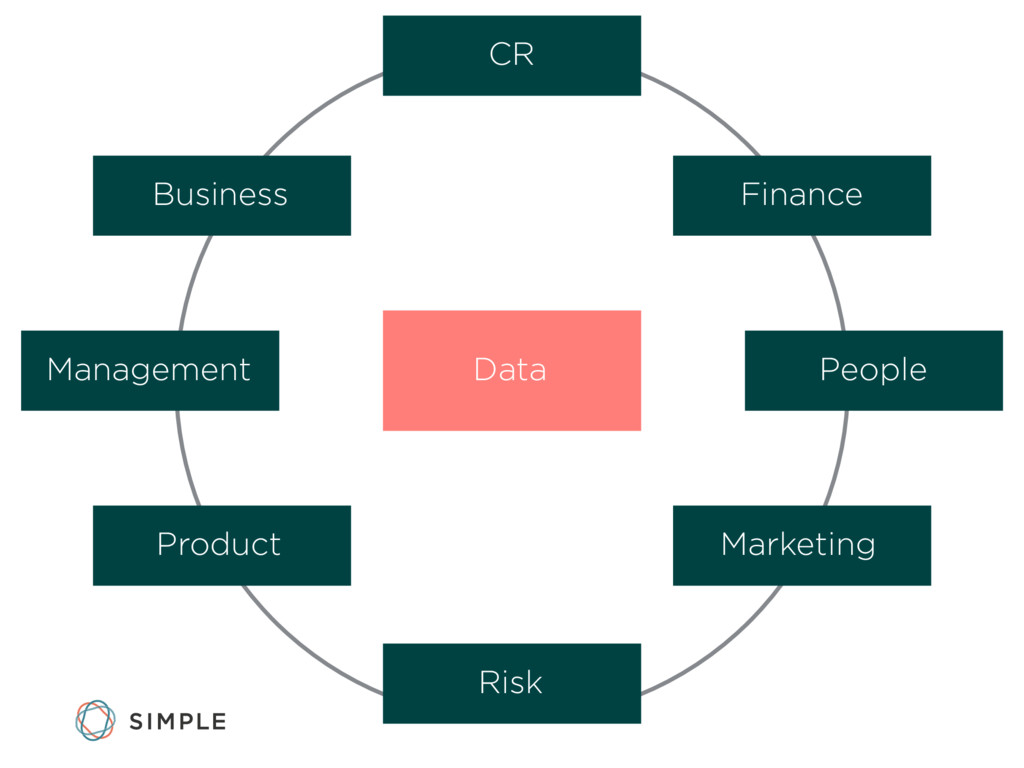
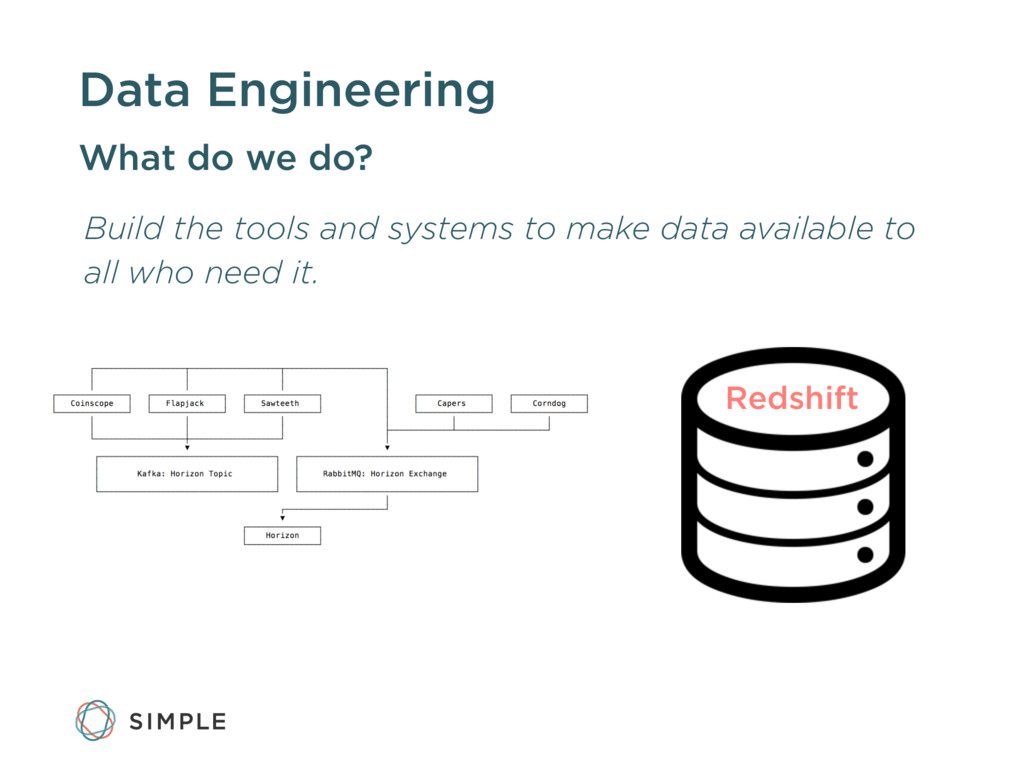
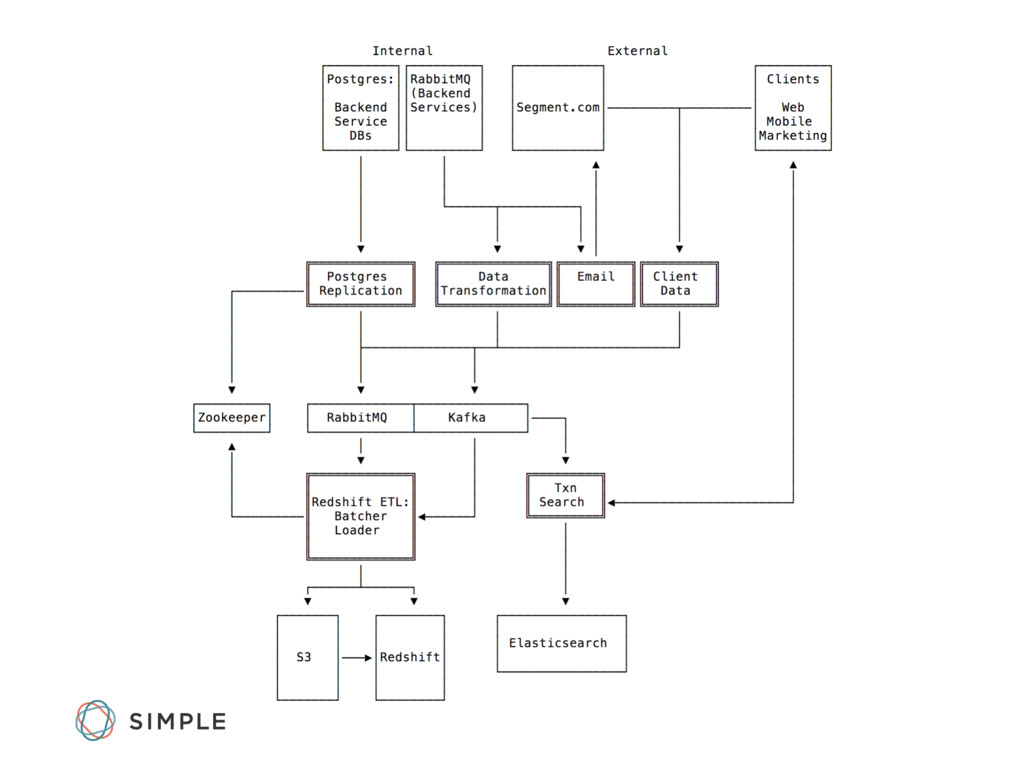
Simple's Data Engineering team has spent the past year and a half building data pipelines to enable the customer service, marketing, finance, and leadership teams to make data-driven decisions.
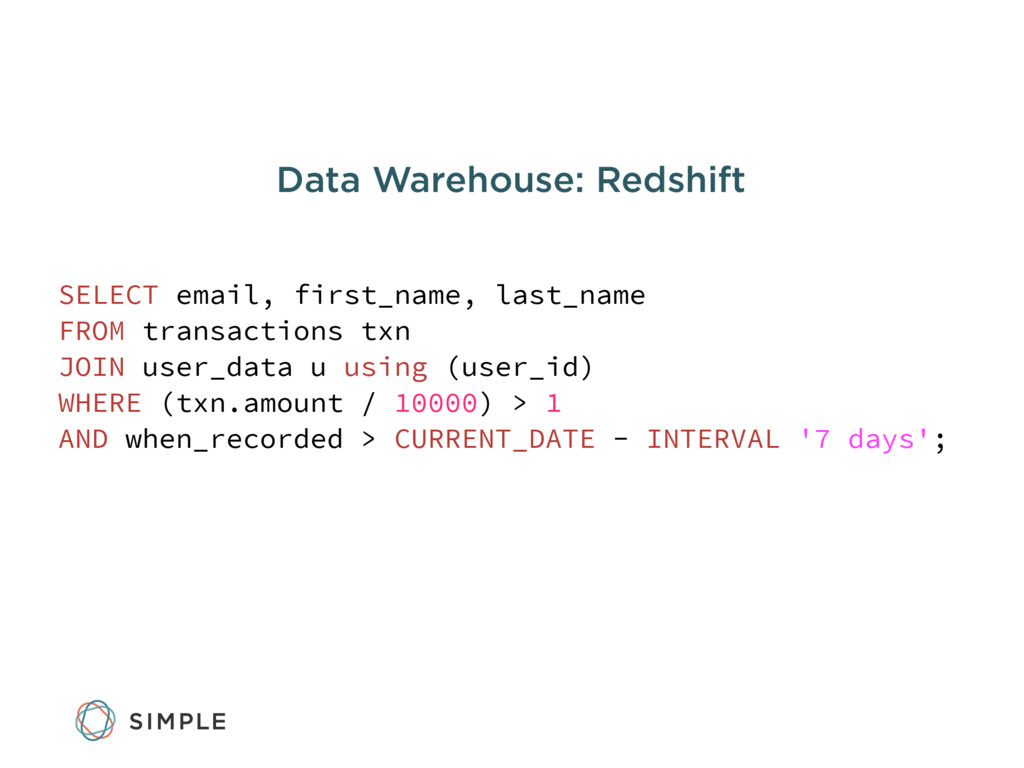
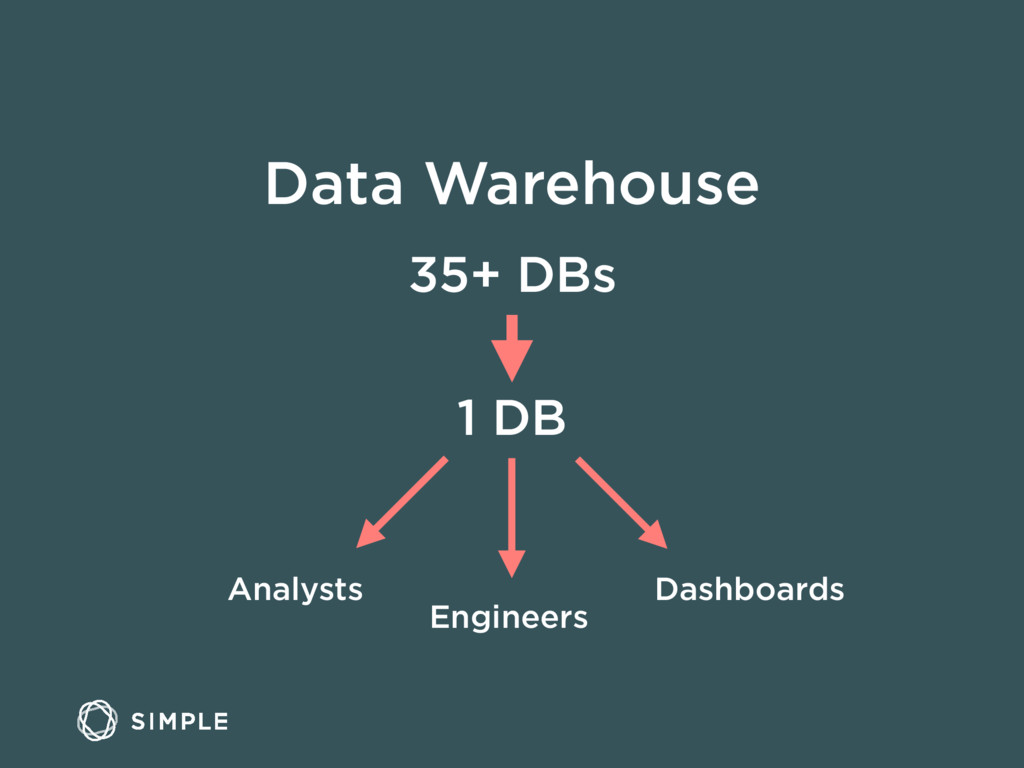
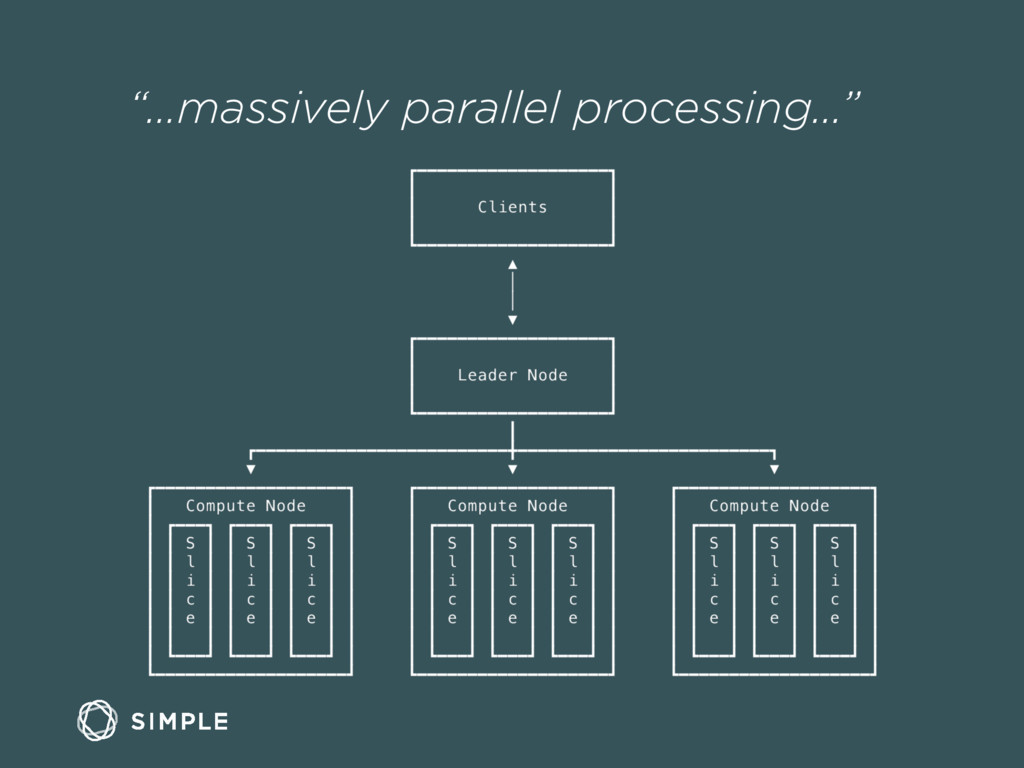
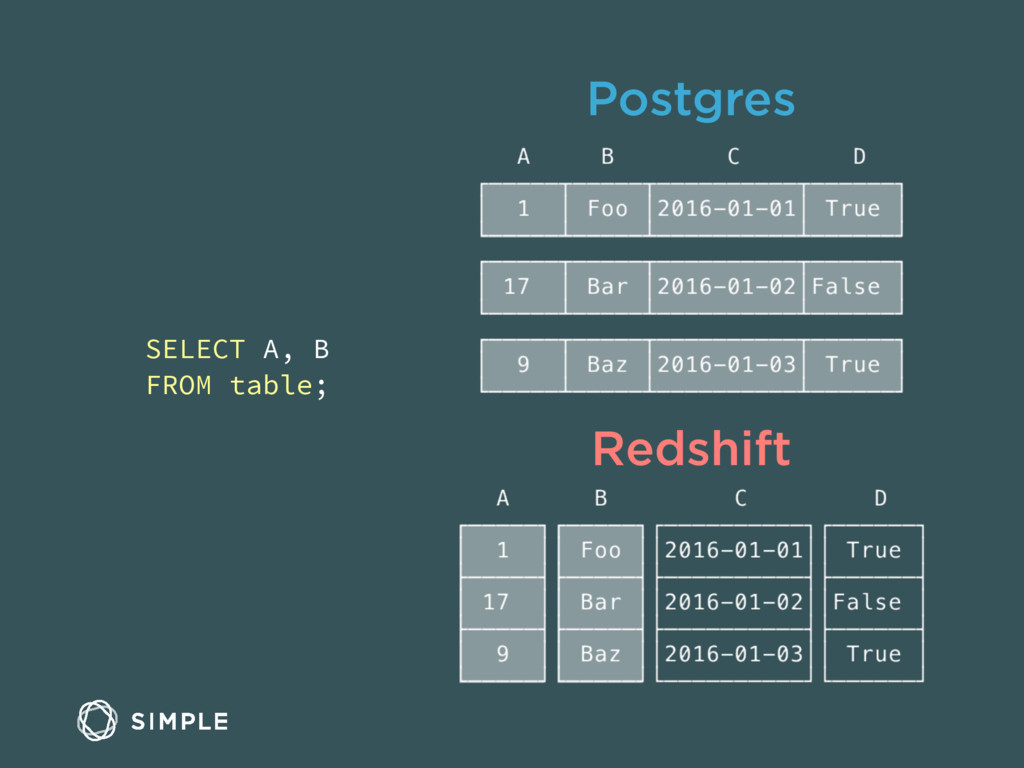
We'll walk through why the data team chose certain open source tools, including Kafka, RabbitMQ, Postgres, Celery, and Elasticsearch. We'll also discuss the advantages to using Amazon Redshift for data warehousing and some of the lessons learned operating it in production.
Finally, we'll touch on the team's choices for the languages used in the data engineering stack, including Scala, Java, Clojure, and Python.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
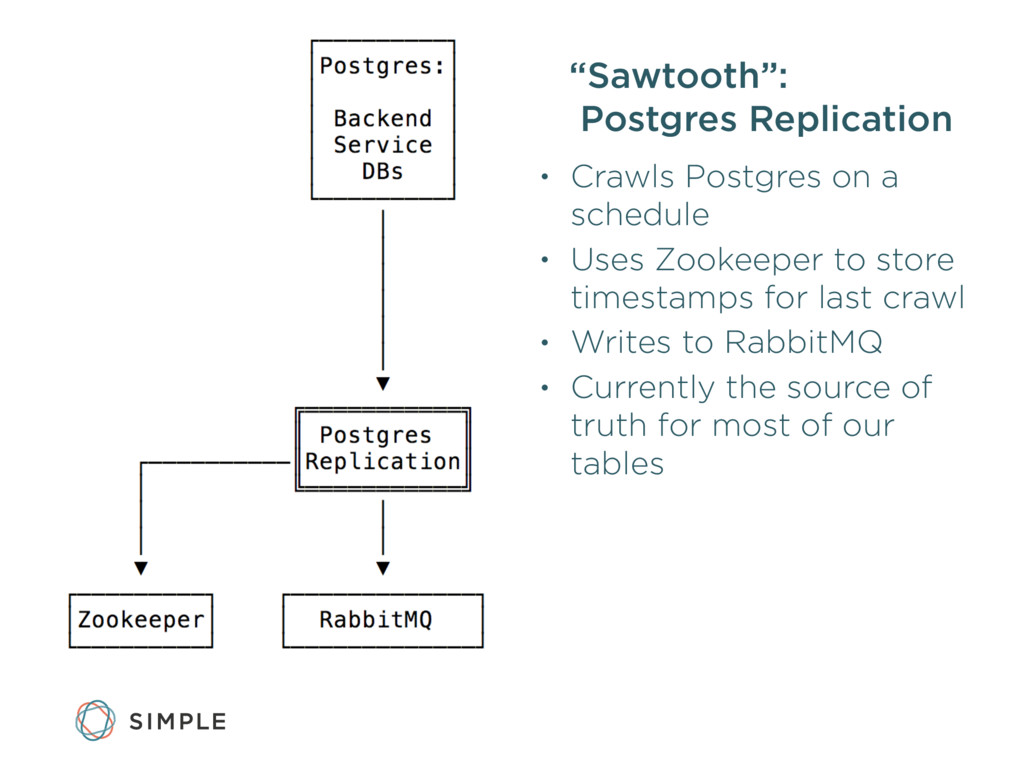{kind=link}
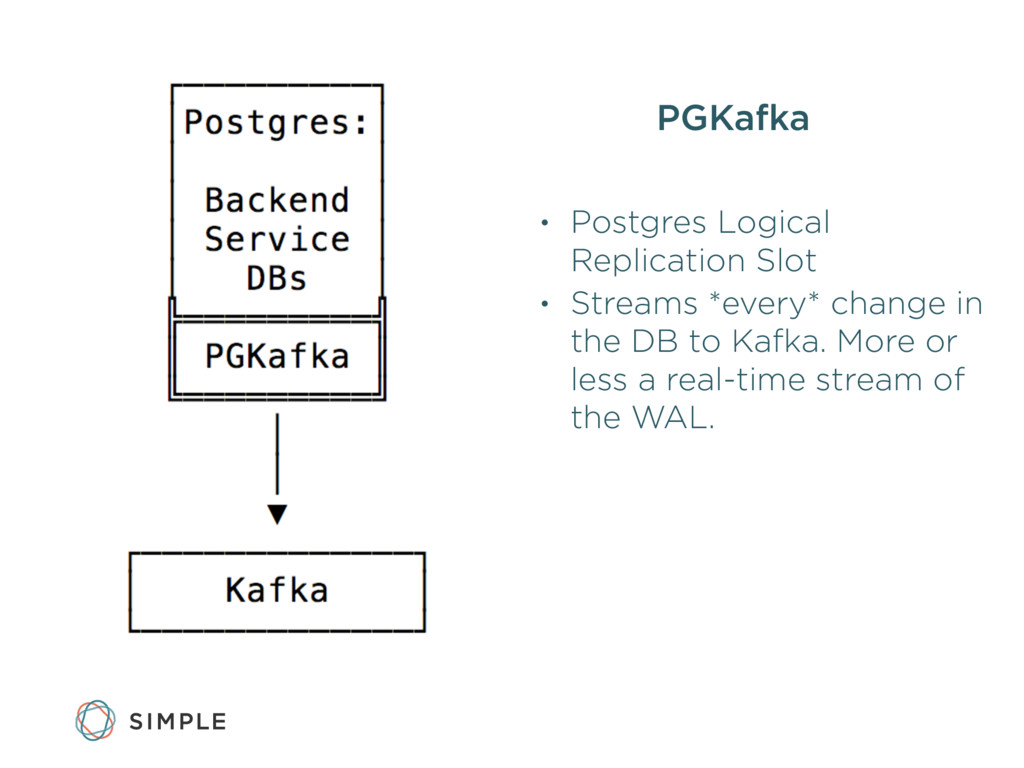{kind=link}
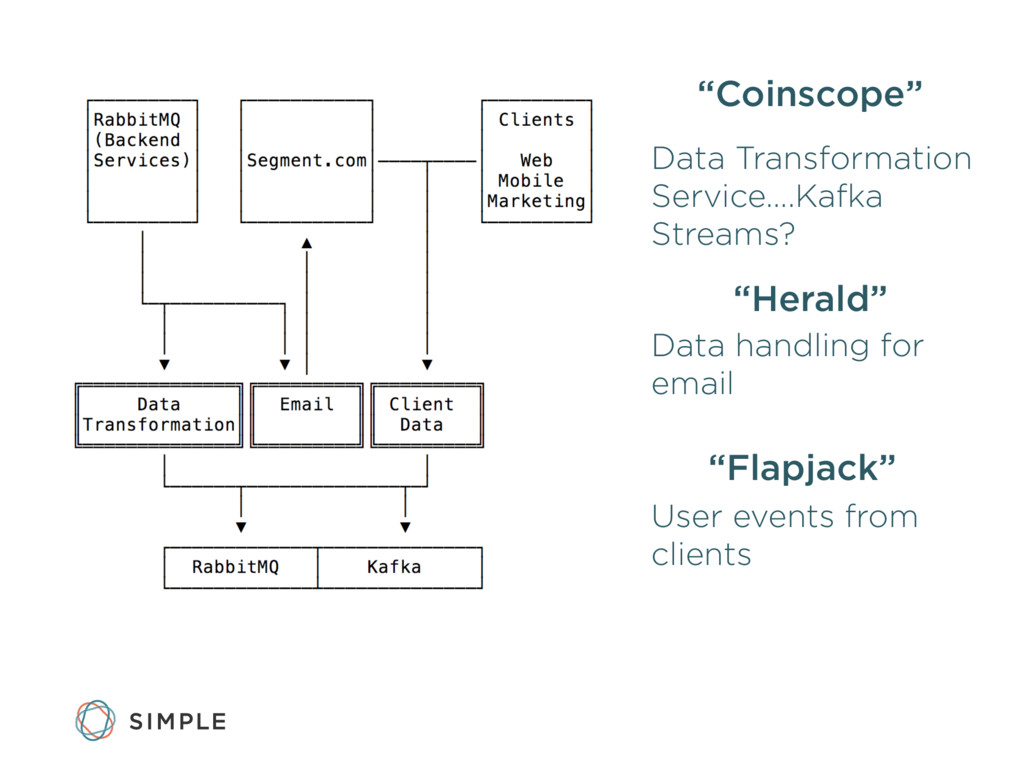{kind=link}
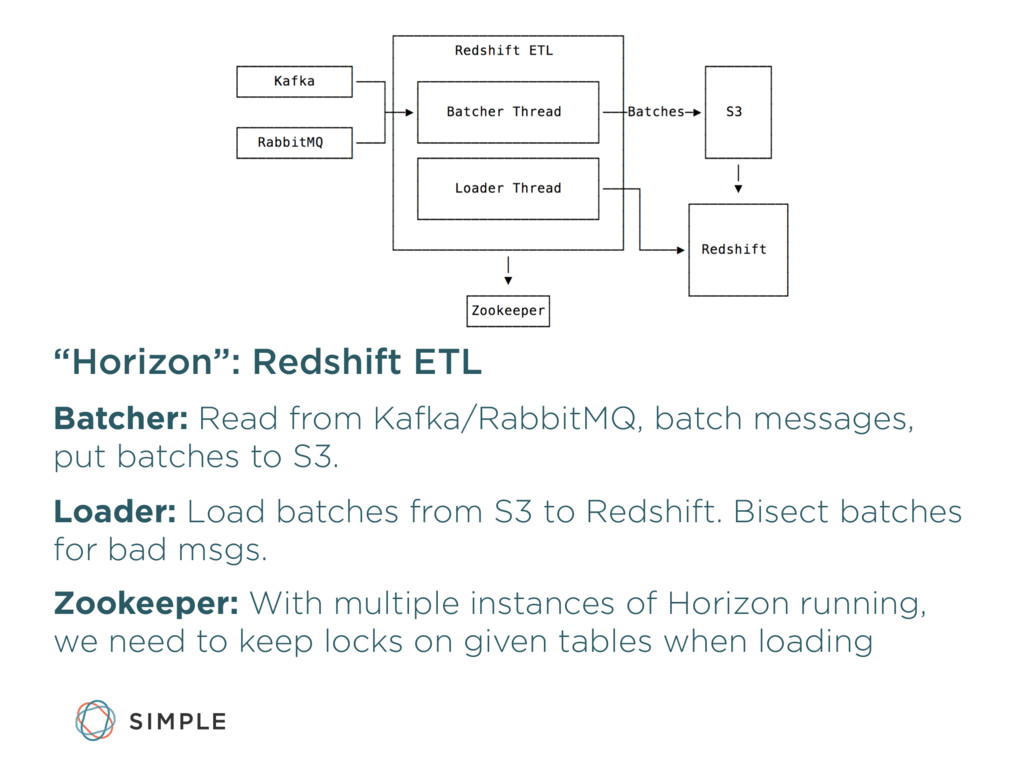{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}