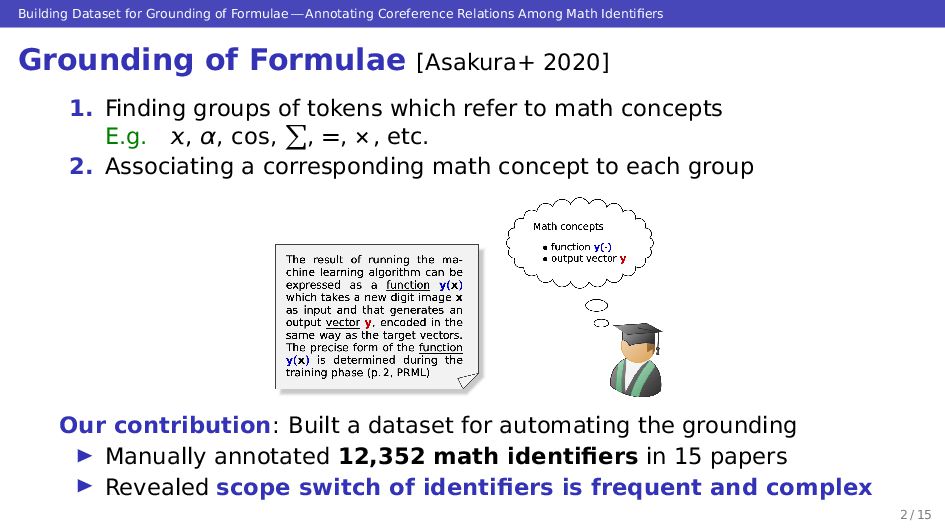
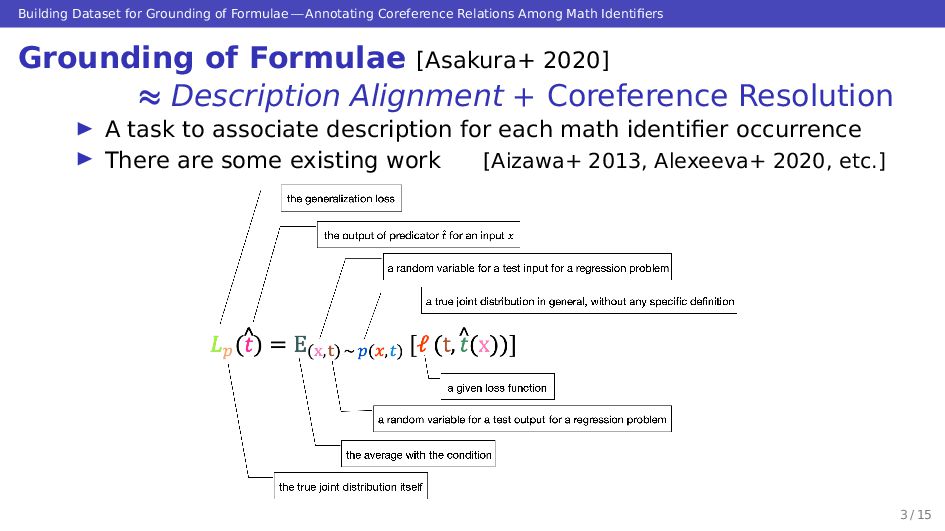
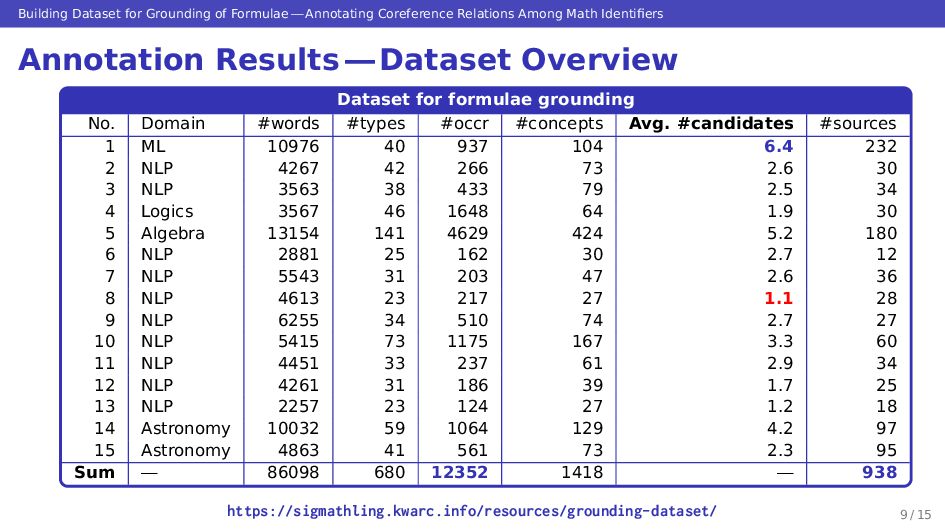
Grounding the meaning of each symbol in math formulae is important for automated understanding of scientific documents. Generally speaking, the meanings of math symbols are not necessarily constant, and the same symbol is used in multiple meanings. Therefore, coreference relations between symbols need to be identified for grounding, and the task has aspects of both description alignment and coreference analysis. In this study, we annotated 15 papers selected from arXiv.org with the grounding information. In total, 12,352 occurrences of math identifiers in these papers were annotated, and all coreference relations between them were made explicit in each paper. The constructed dataset shows that regardless of the ambiguity of symbols in math formulae, coreference relations can be labeled with a high inter-annotator agreement. The constructed dataset enables us to achieve automation of formula grounding, and in turn, make deeper use of the knowledge in scientific documents using techniques such as math information extraction. The built grounding dataset is available at https://sigmathling.kwarc.info/resources/grounding-dataset/.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}