第64回 コンピュータビジョン勉強会@関東(前編)CVPR2025読み会での発表資料です。
https://kantocv.connpass.com/event/359922/
プロジェクトURL:
https://obrookes.github.io/panaf-fgbg.github.io/
paper: https://openaccess.thecvf.com/content/CVPR2025/papers/Brookes_The_PanAf-FGBG_Dataset_Understanding_the_Impact_of_Backgrounds_in_Wildlife_CVPR_2025_paper.pdf
arXiv: https://arxiv.org/abs/2502.21201
{kind=link}
{kind=link}
![© DeNA Co., Ltd. 3 [paper] [arXiv] [プロジェクトページ] • 概要](https://files.speakerdeck.com/presentations/6eb3c5315d6847f288166bdd7eb68aed/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
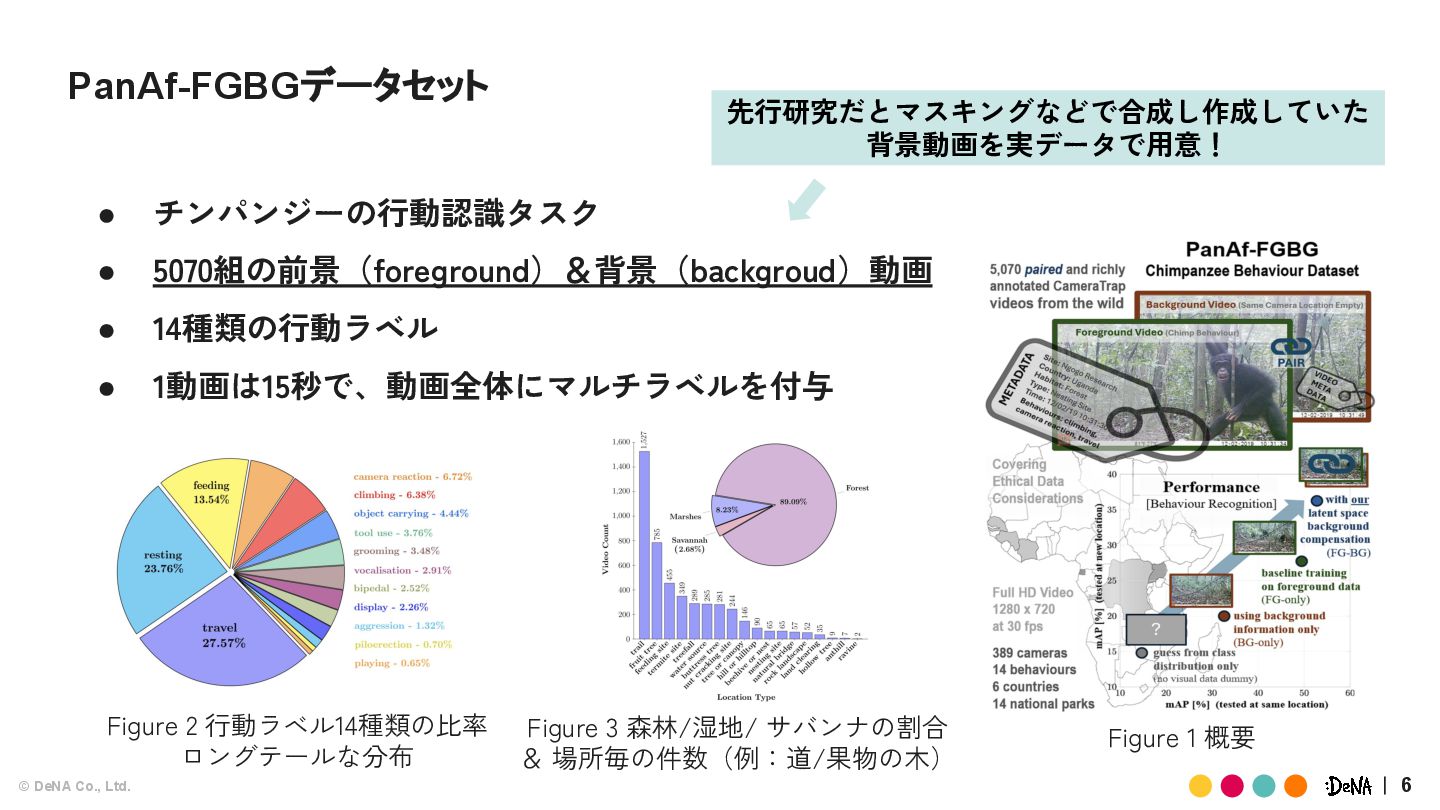{kind=link}
{kind=link}
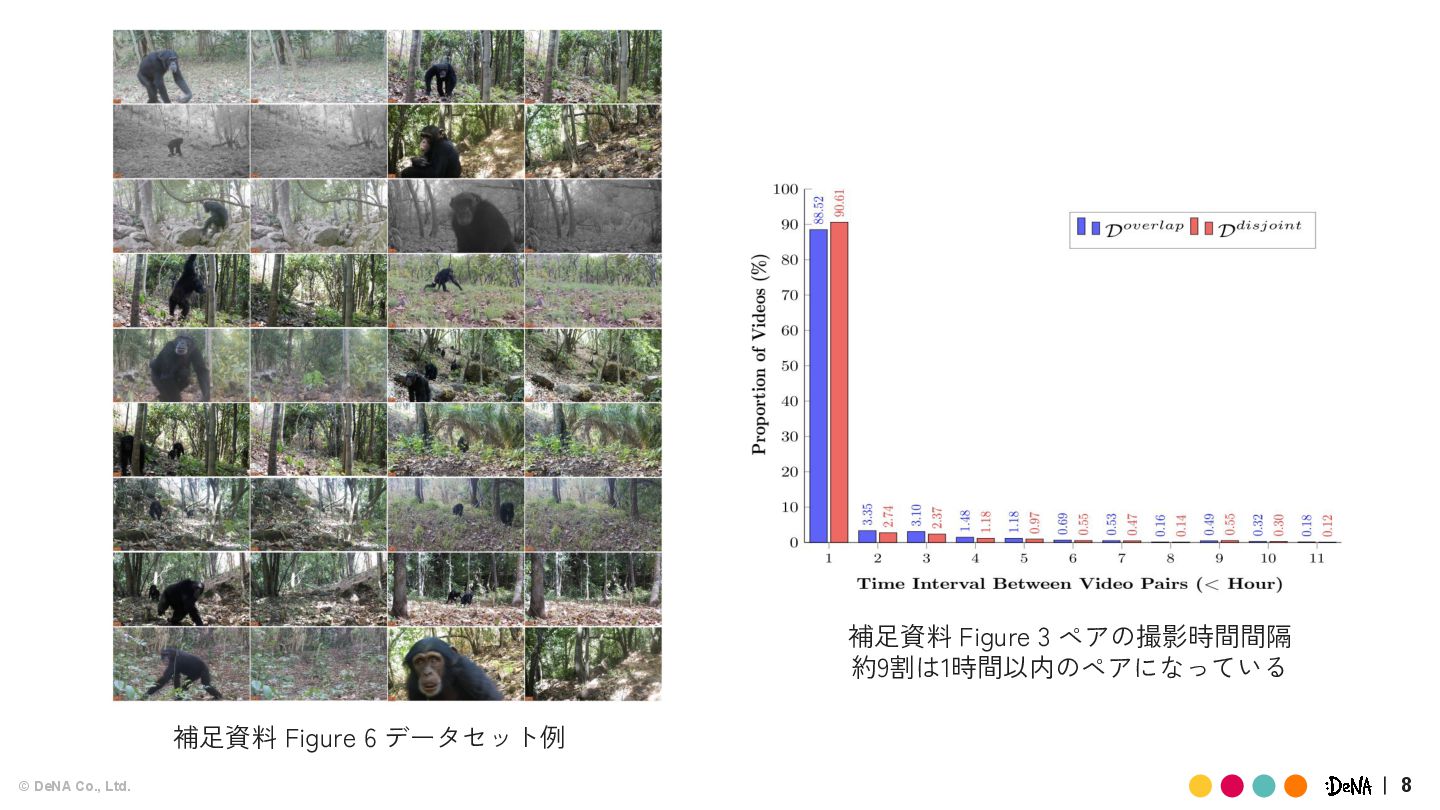{kind=link}
{kind=link}
{kind=link}
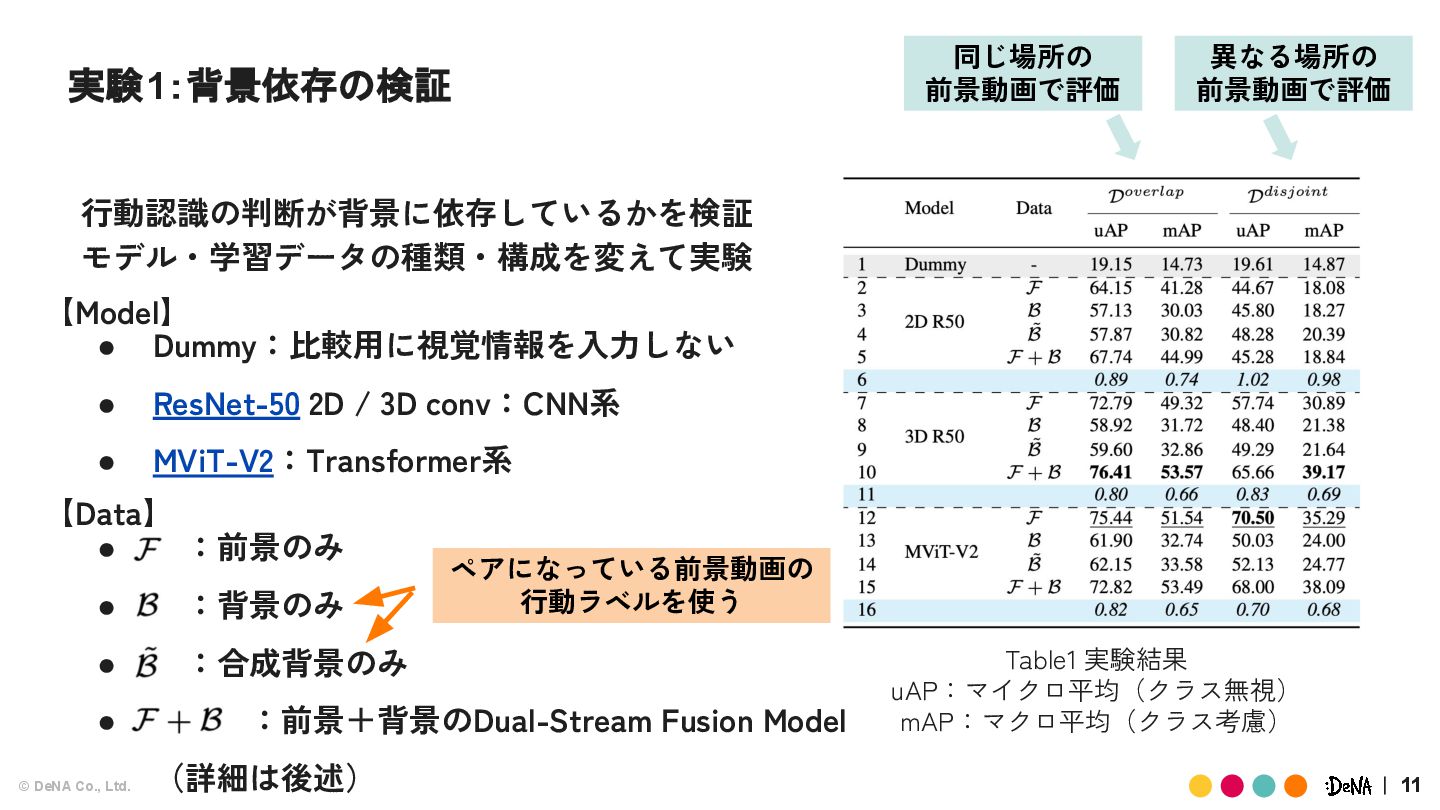{kind=link}
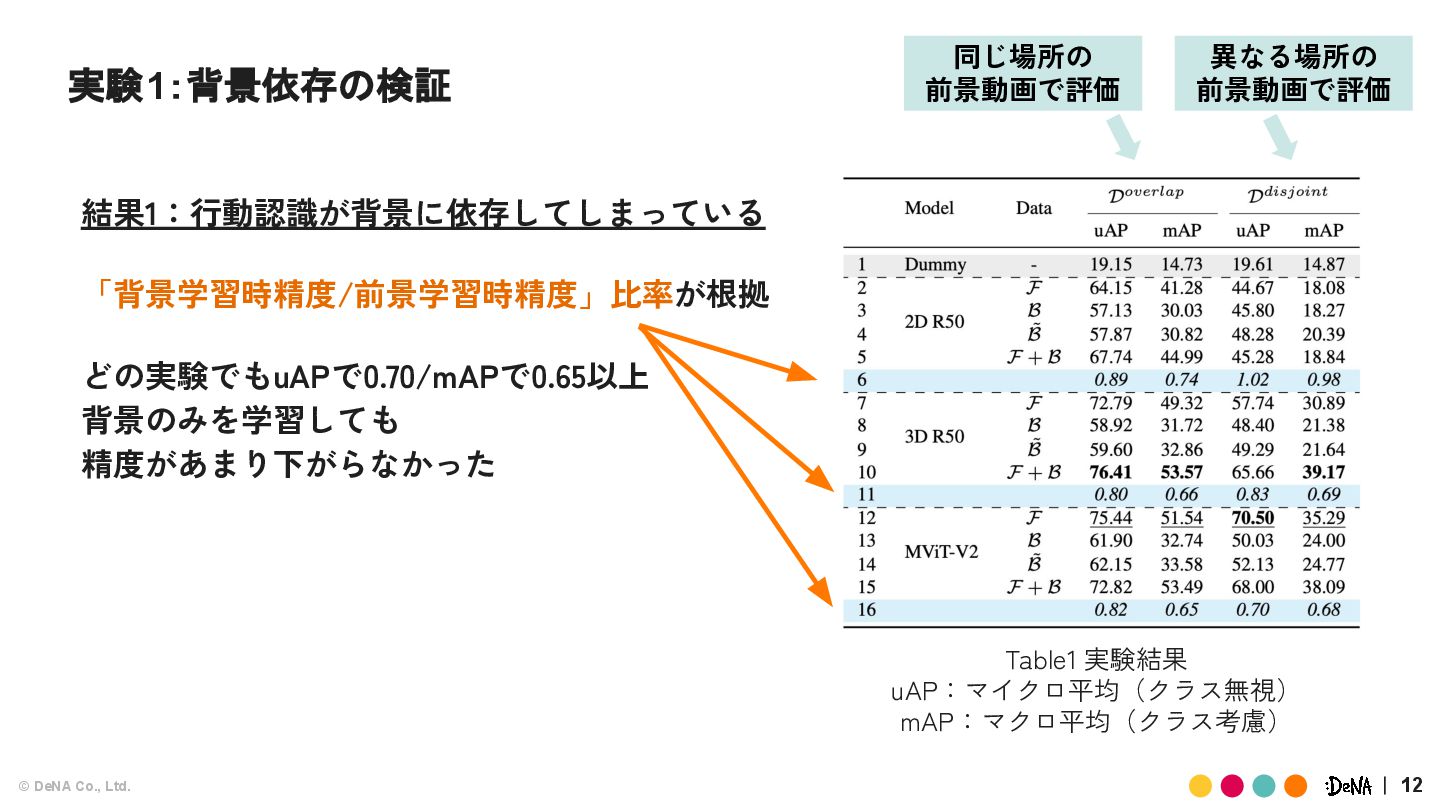{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
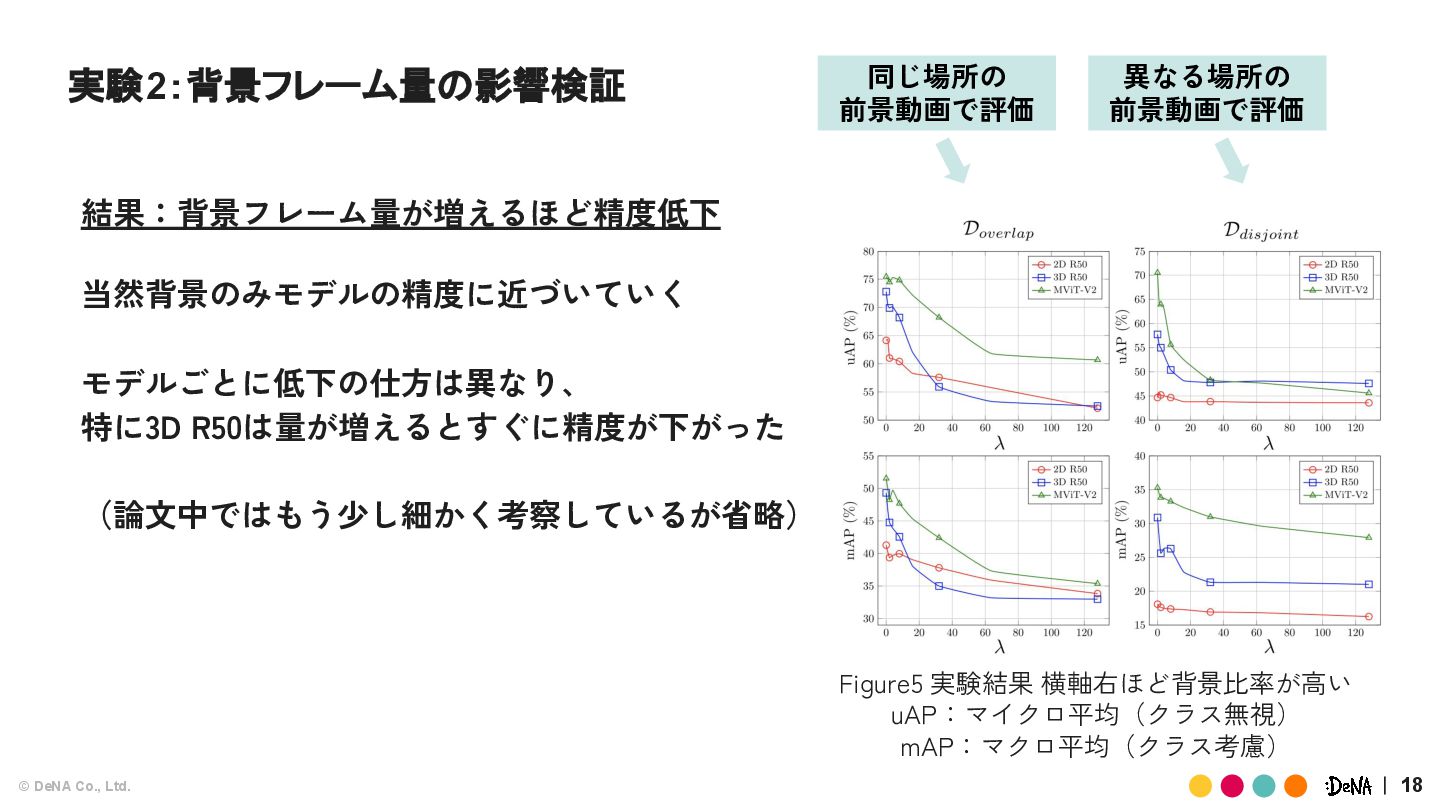{kind=link}
{kind=link}
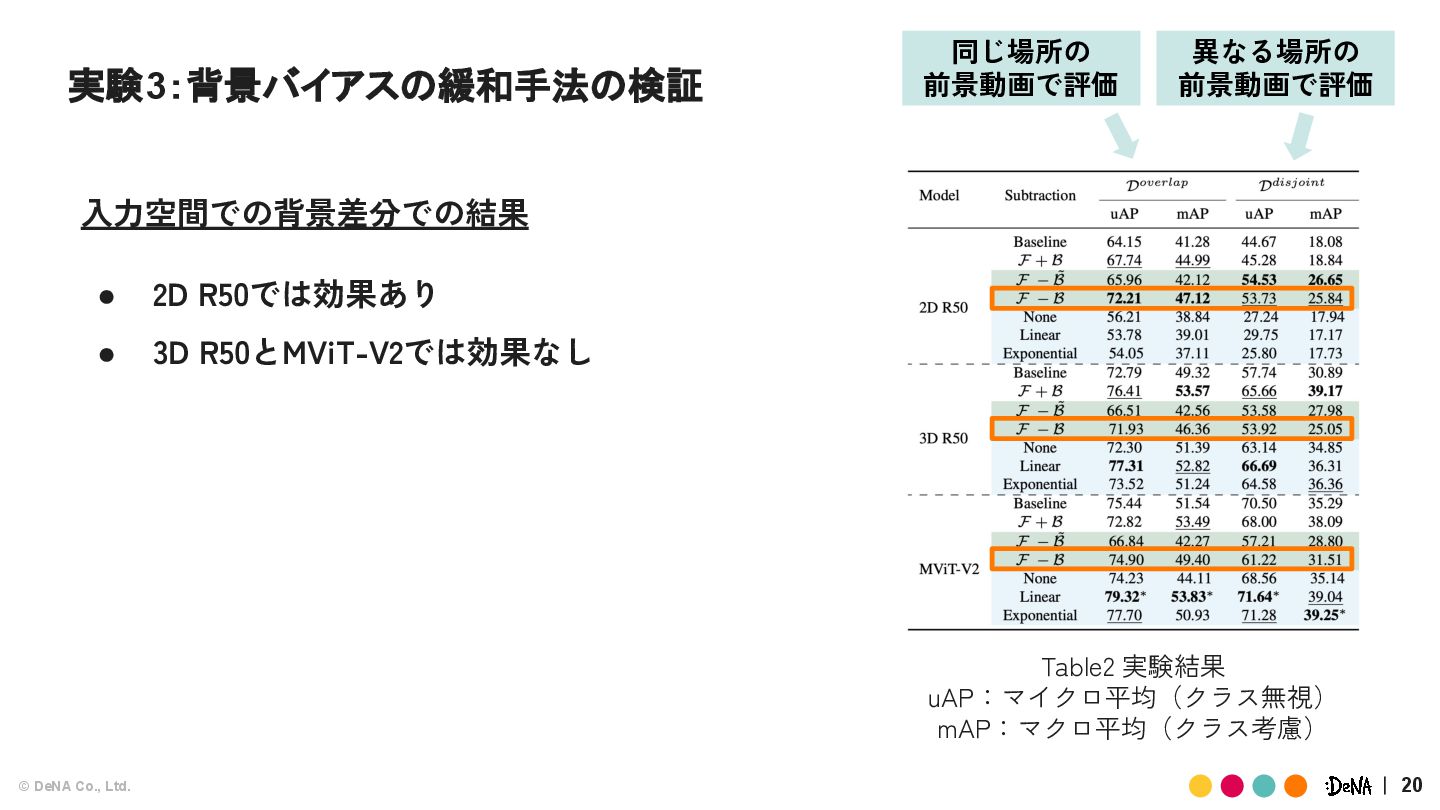{kind=link}
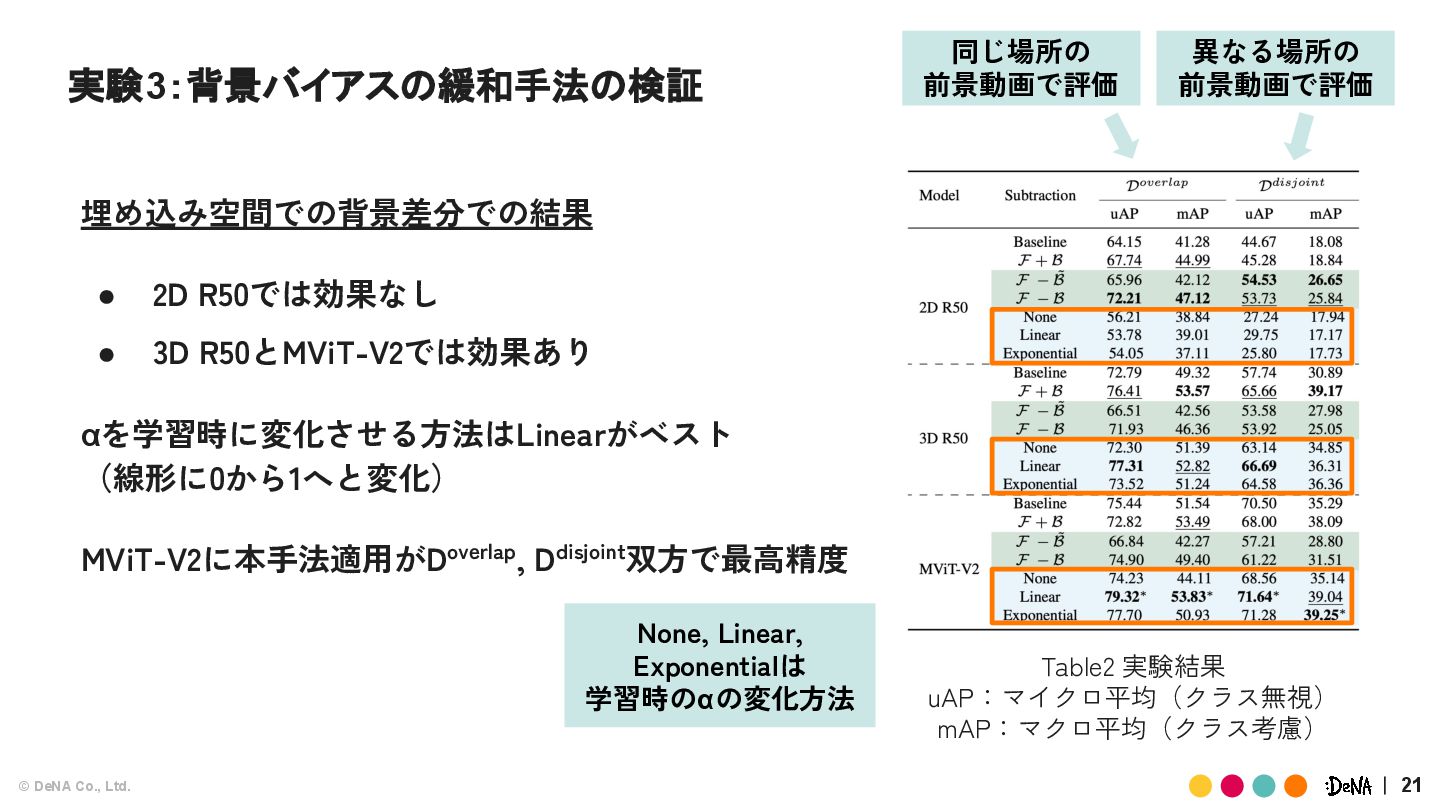{kind=link}
{kind=link}