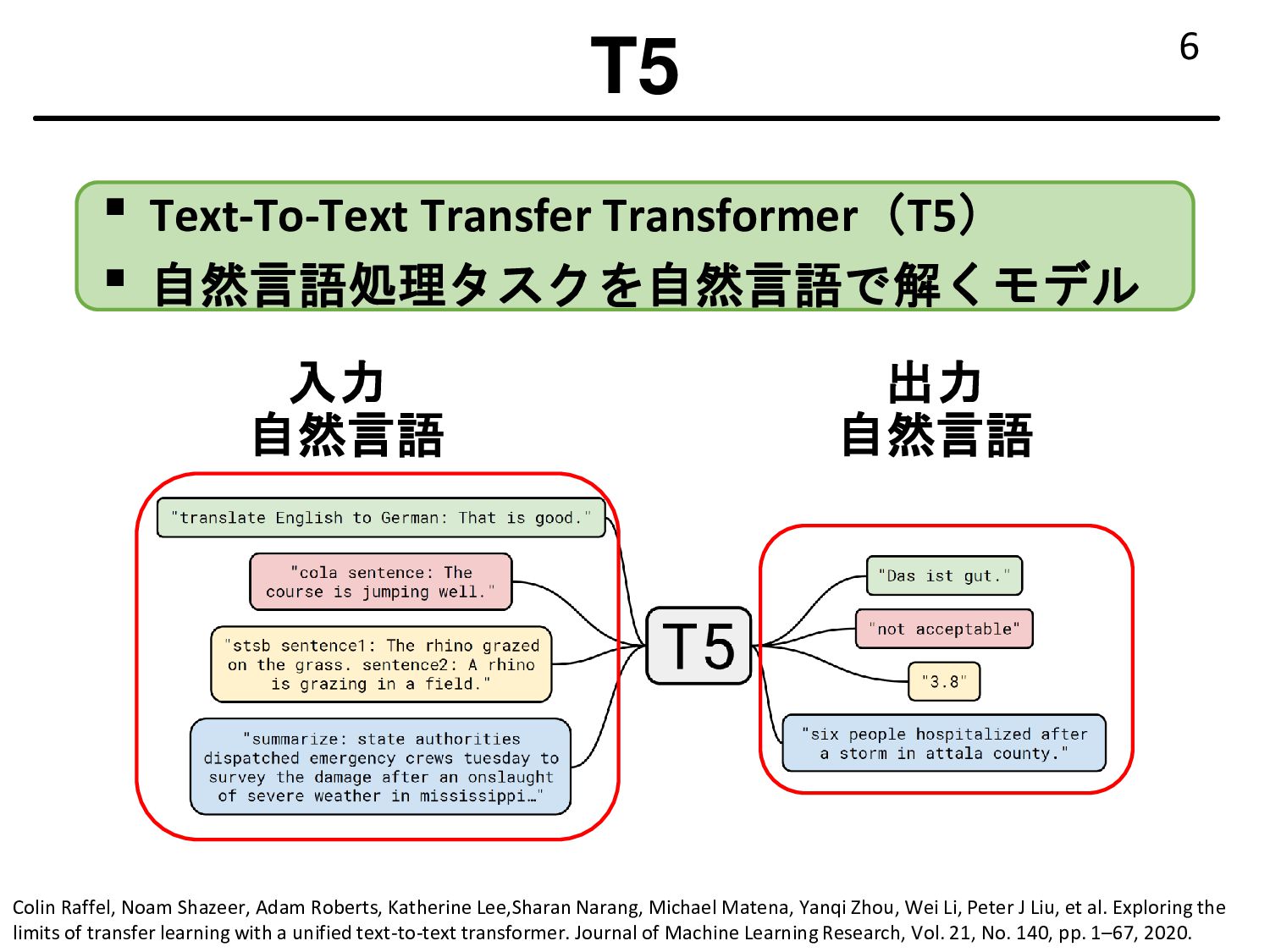
Noam Shazeer, Adam Roberts, Katherine Lee,Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, Vol. 21, No. 140, pp. 1–67, 2020. 自然言語 出力 入力 自然言語
{kind=link}
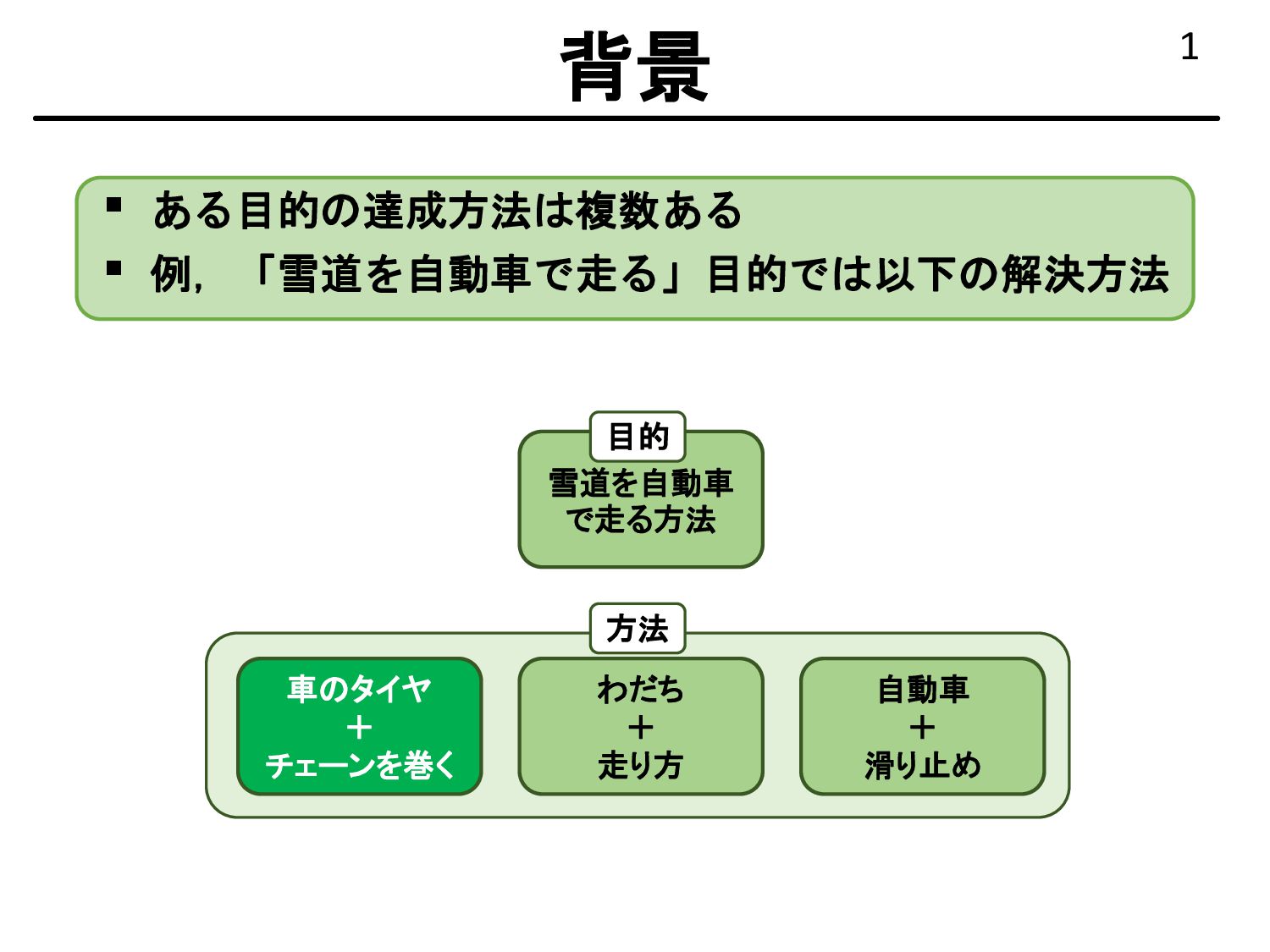{kind=link}
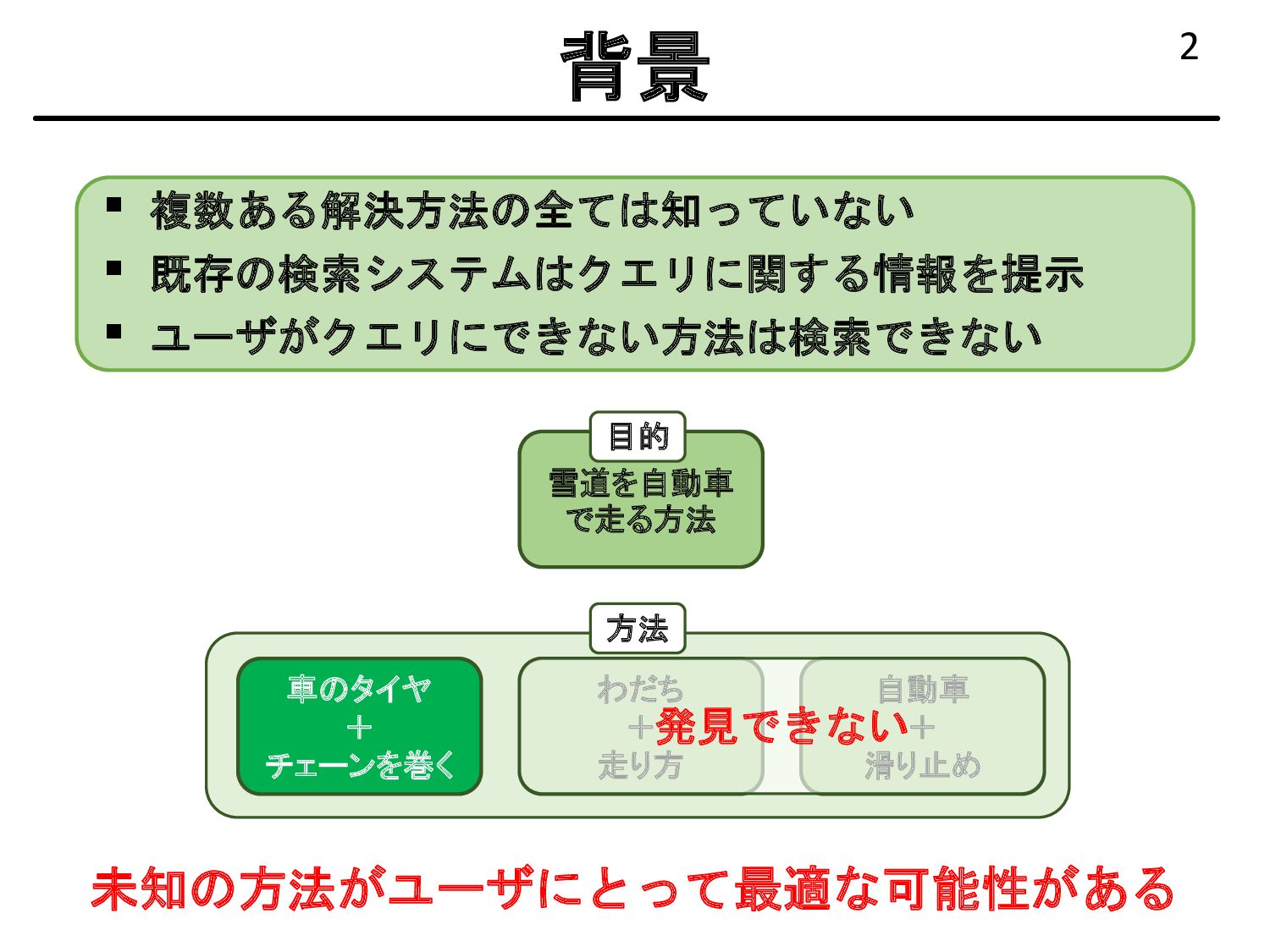{kind=link}
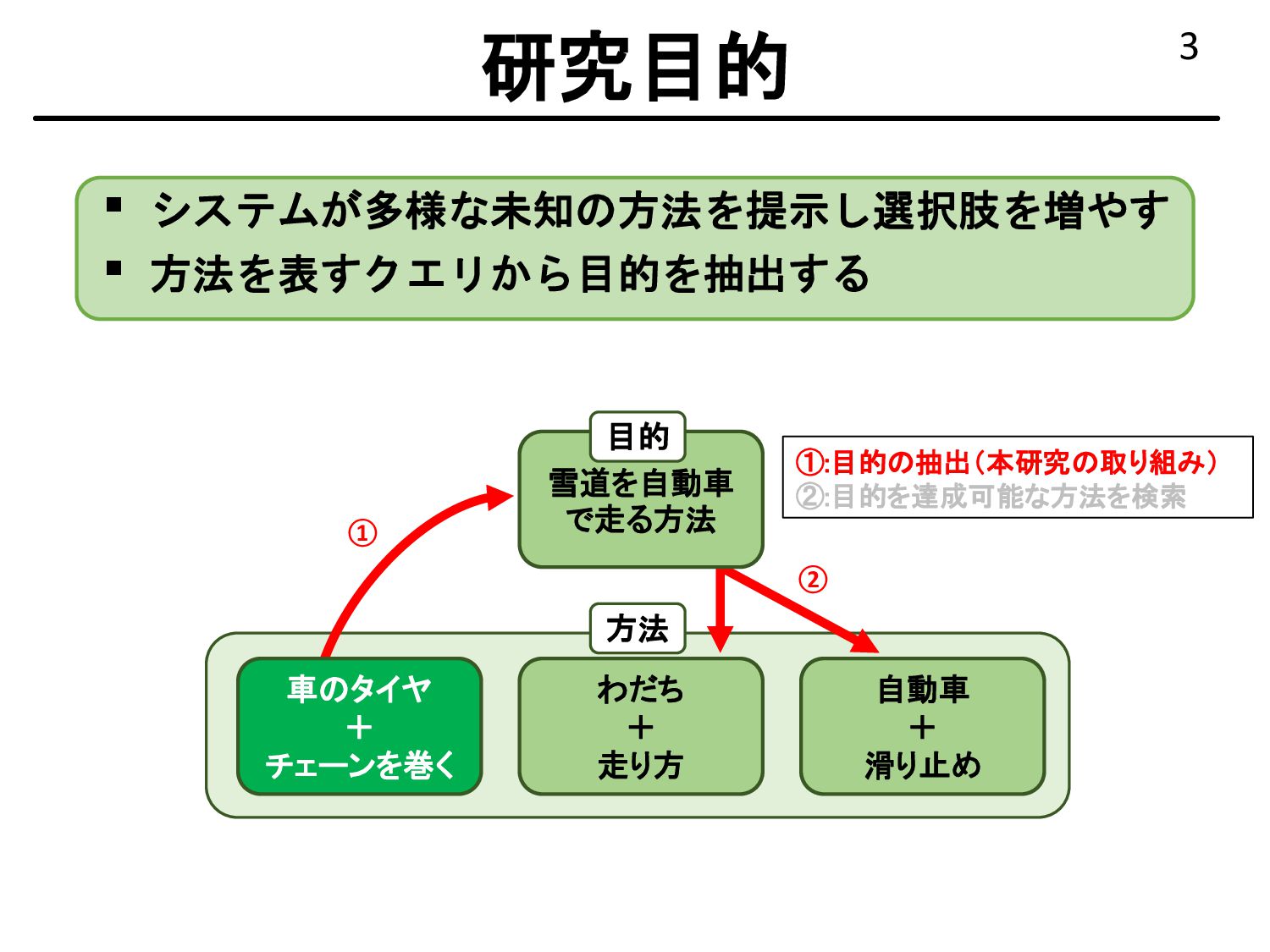{kind=link}
![4 ▪ クエリ修正前後のクエリの関係を分類した研究[1] 関連研究 [1] Paolo Boldi; Francesco Bonchi; Carlos](https://files.speakerdeck.com/presentations/85c6cb85454941c2b2b920c876452b60/slide_4.jpg){kind=link}
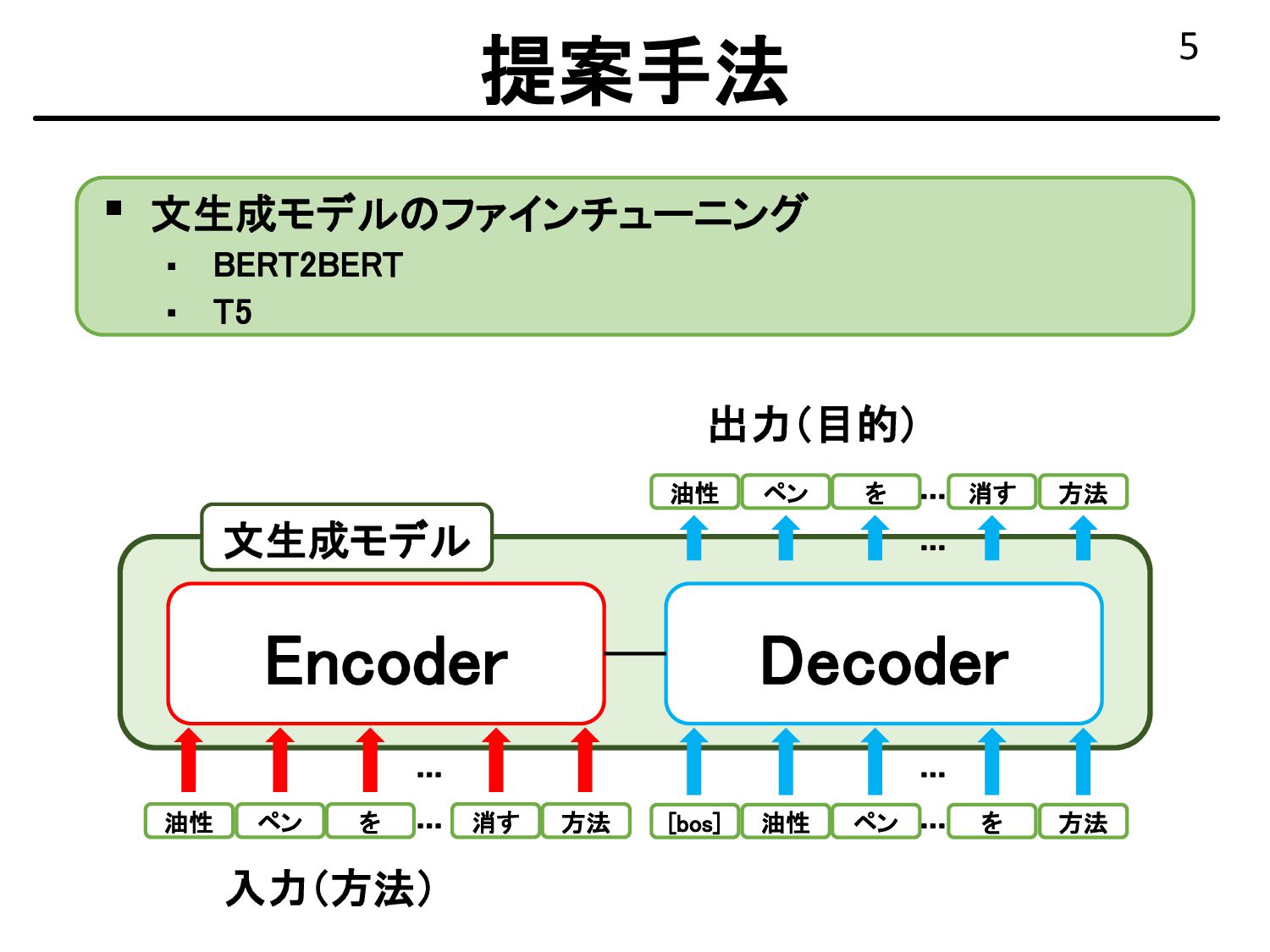{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
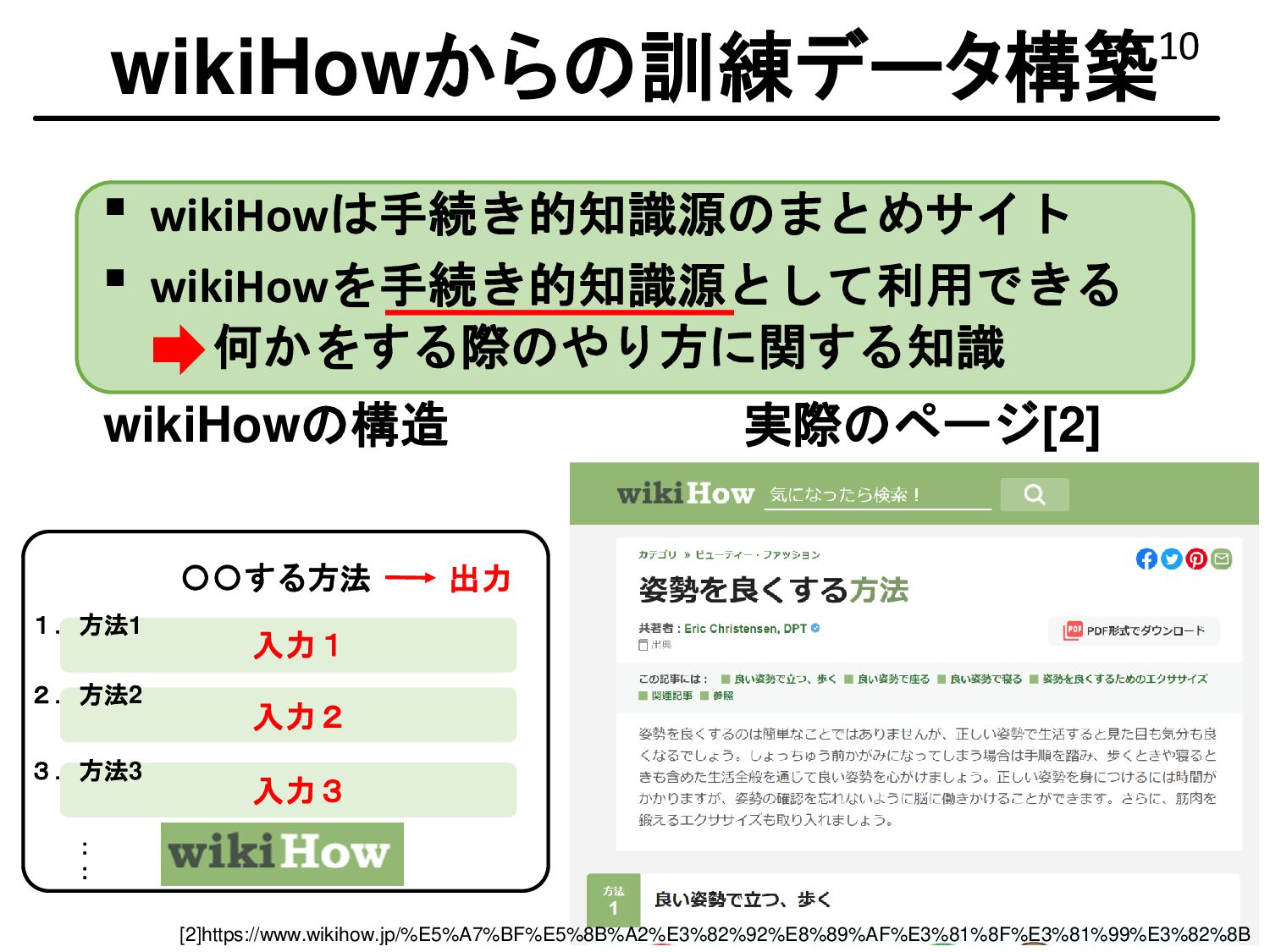{kind=link}
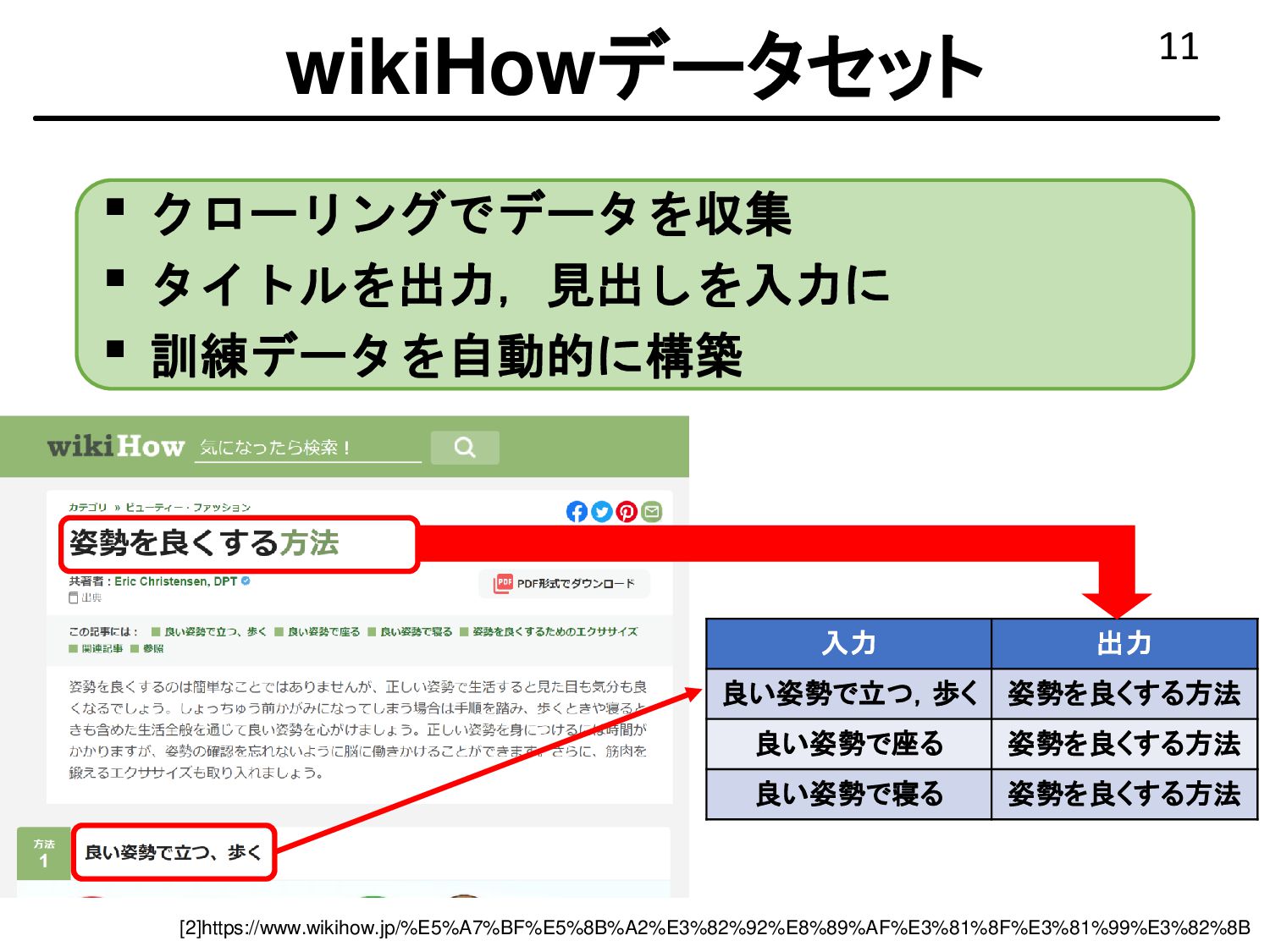{kind=link}
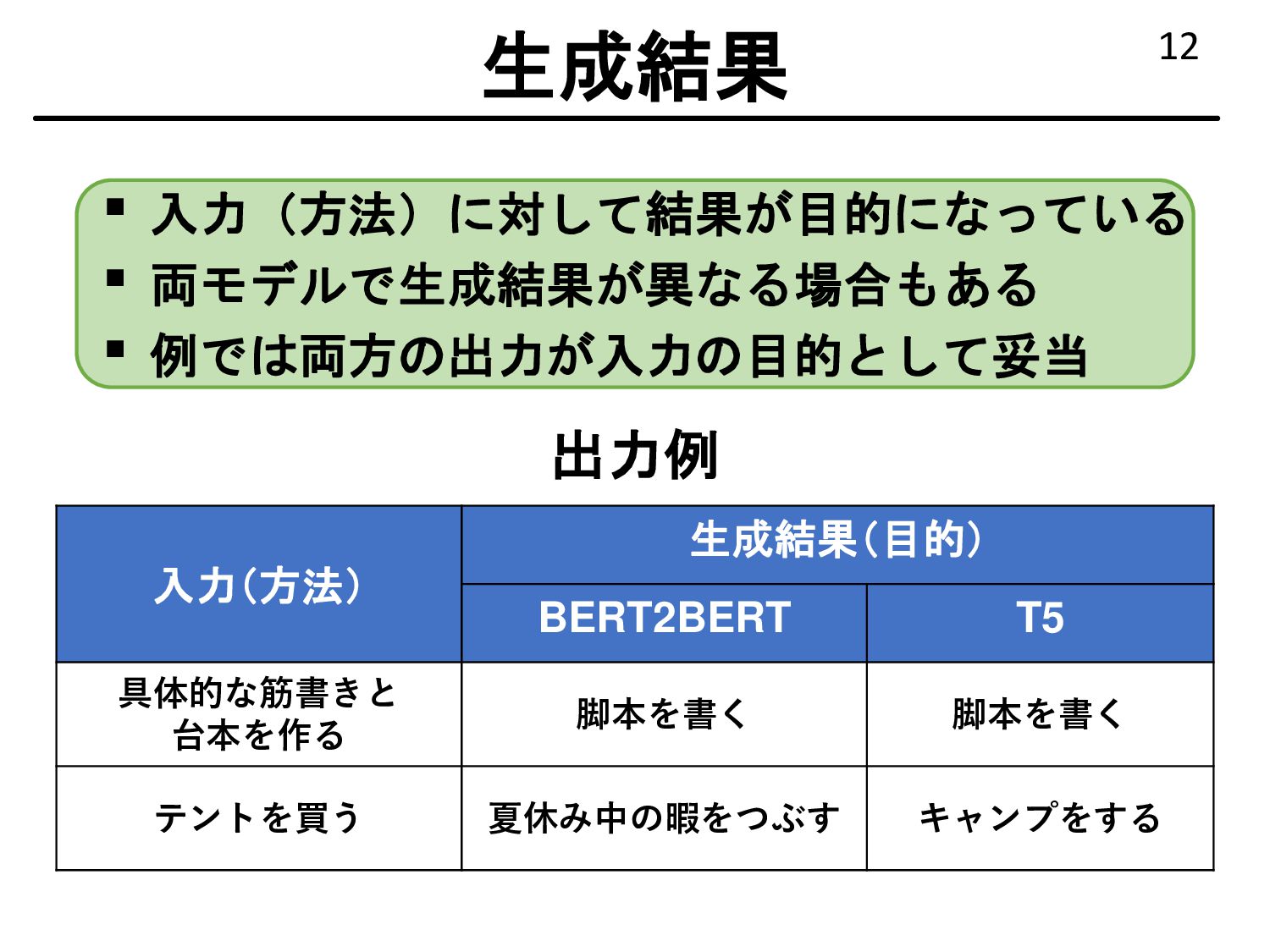{kind=link}
{kind=link}
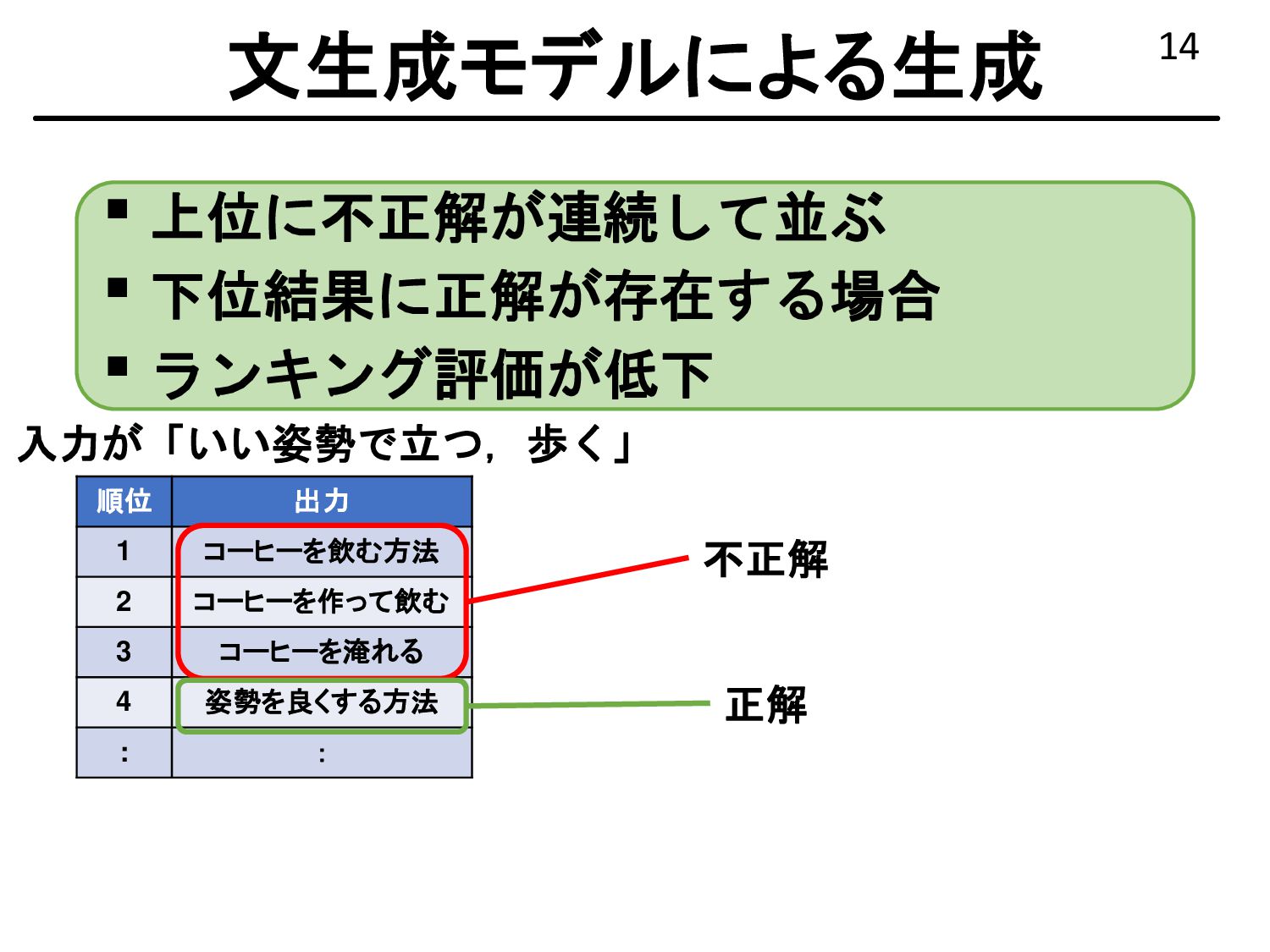{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
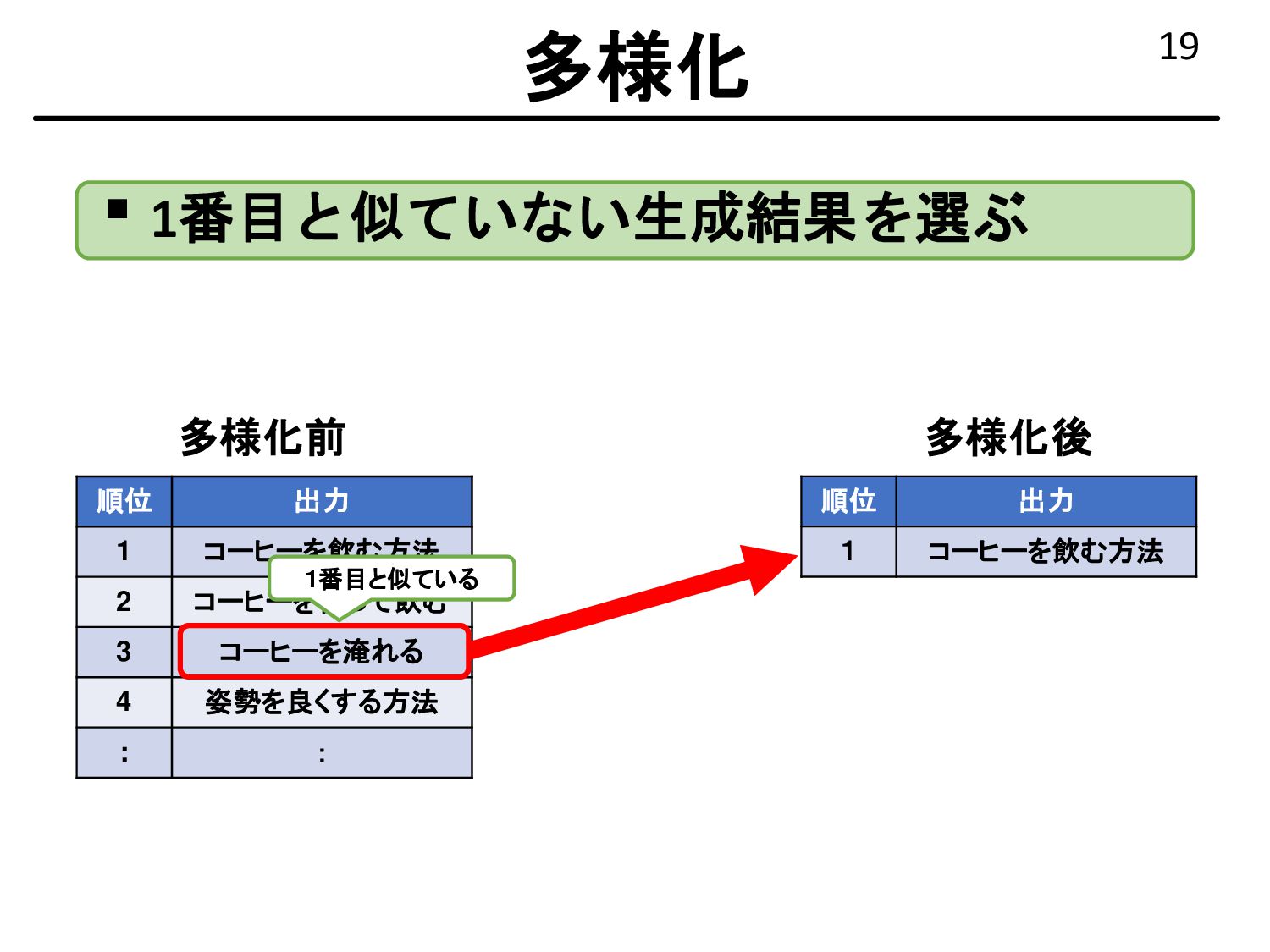{kind=link}
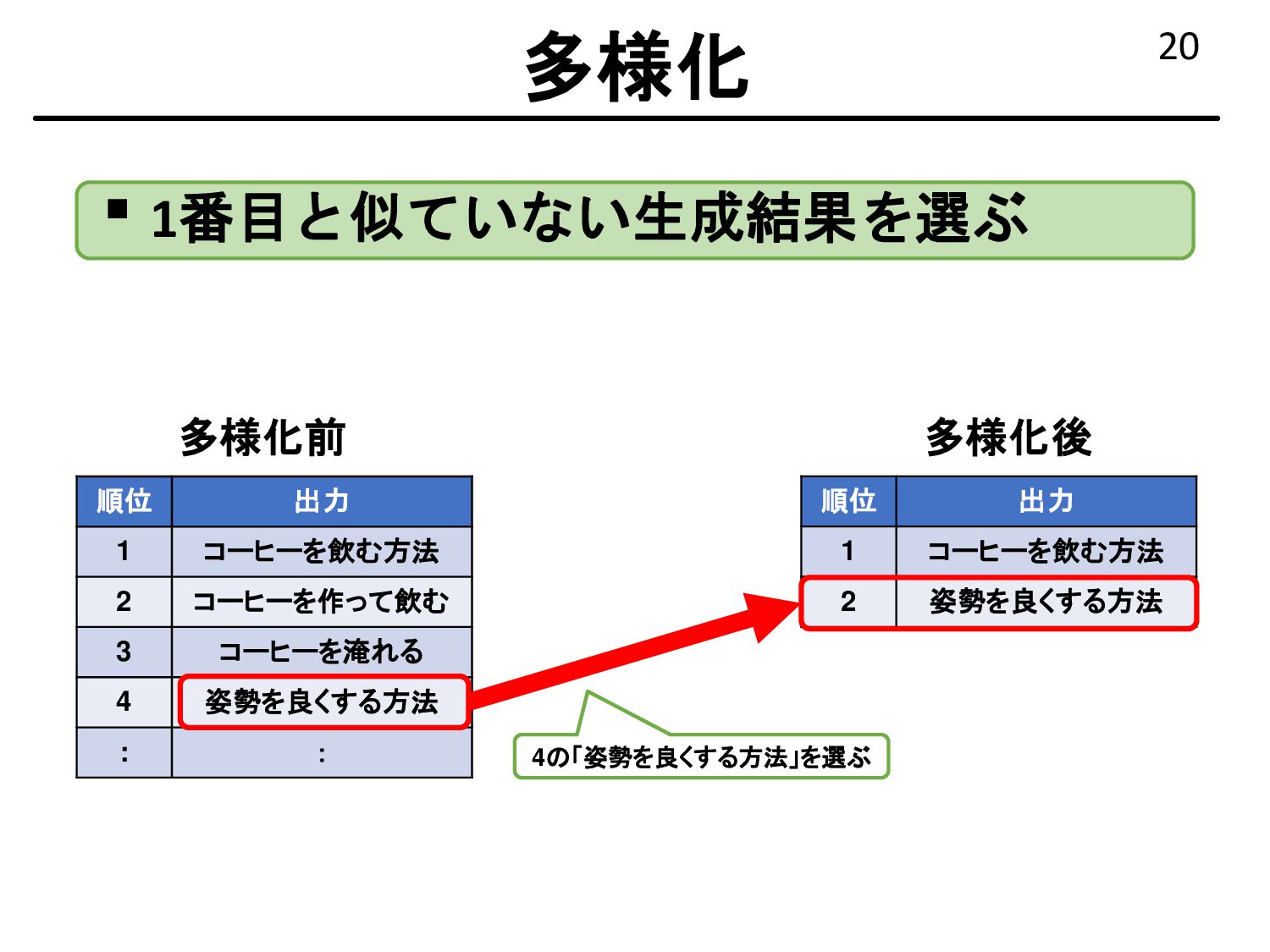{kind=link}
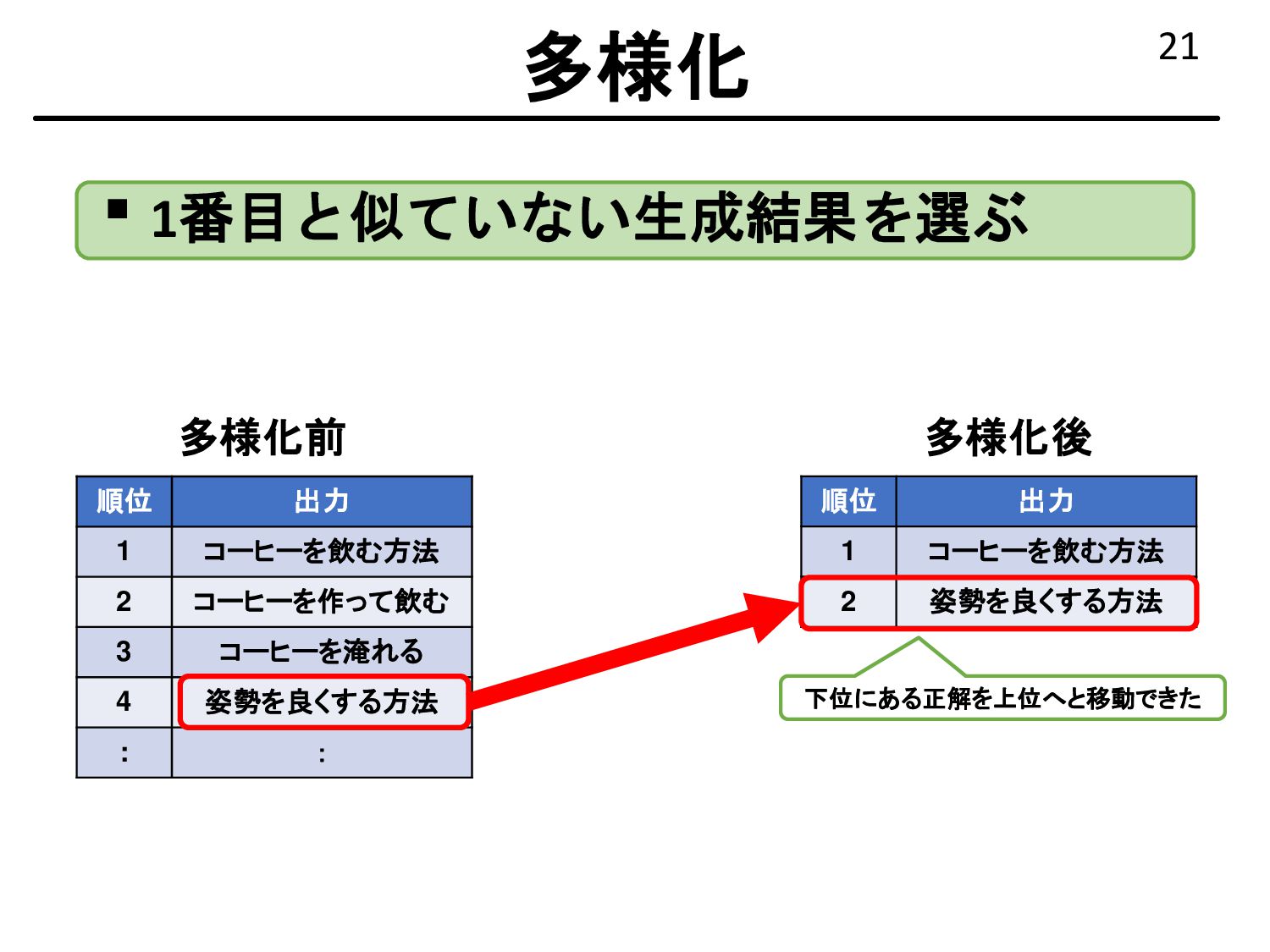{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
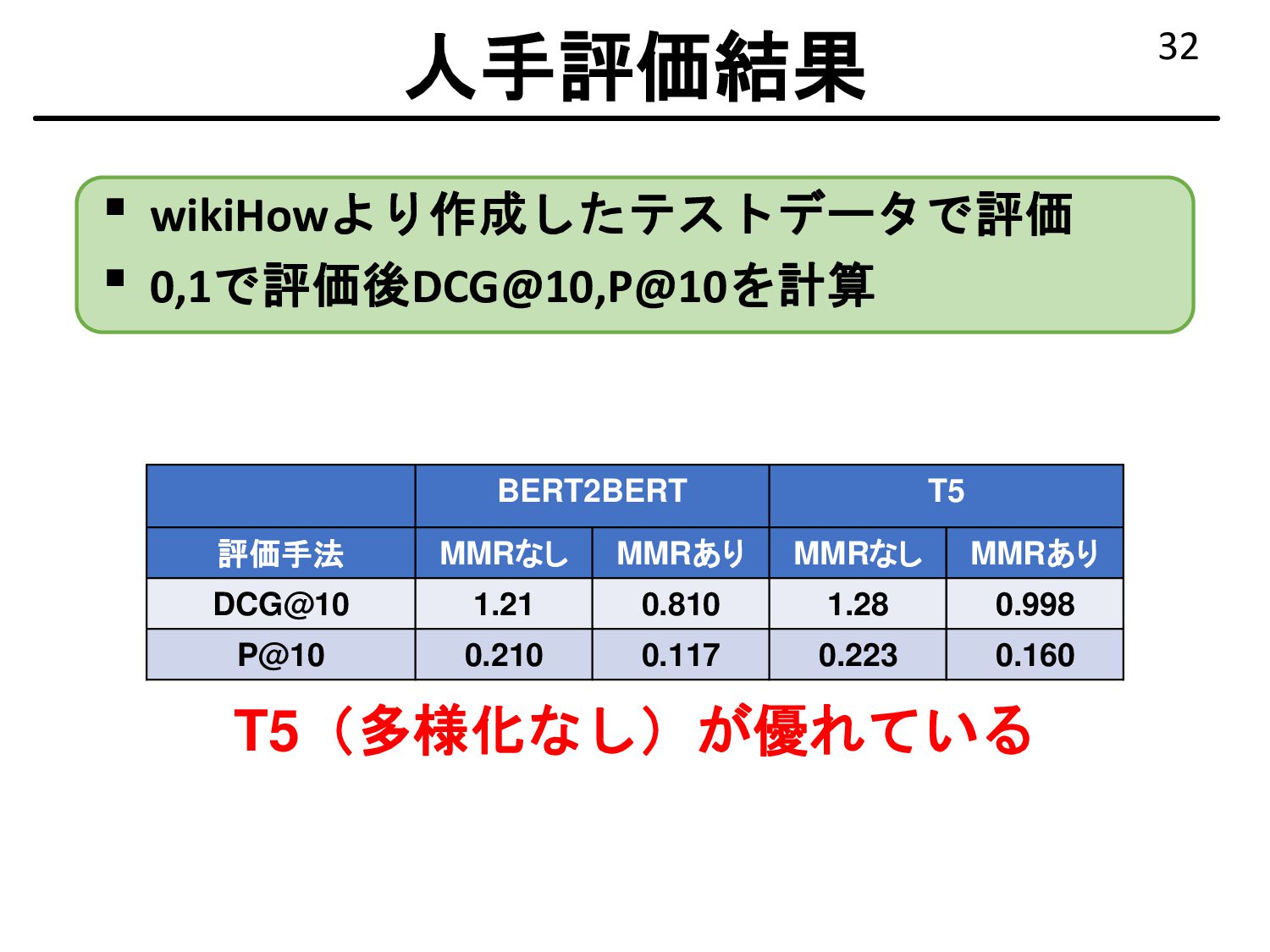{kind=link}
{kind=link}
{kind=link}
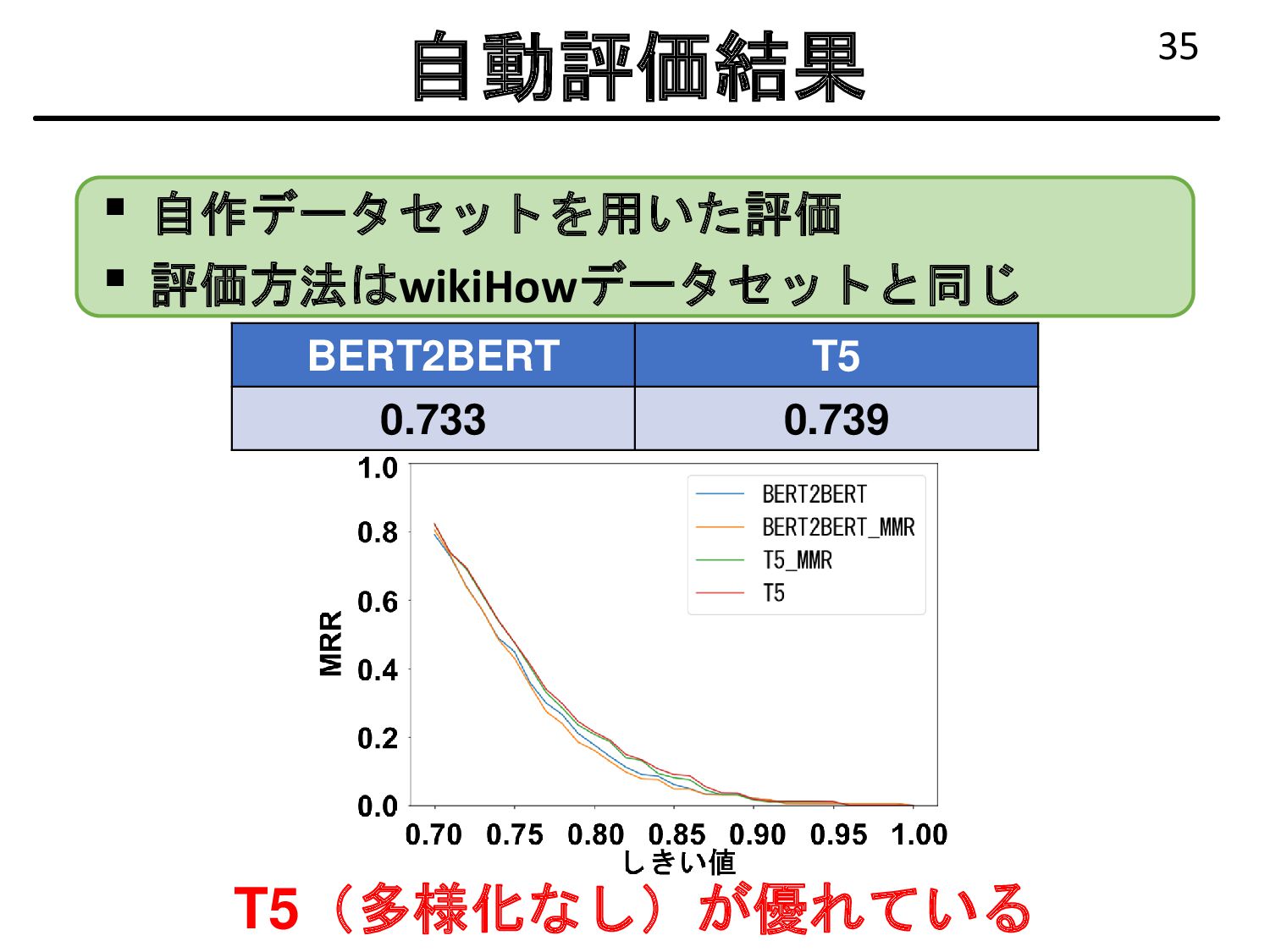{kind=link}
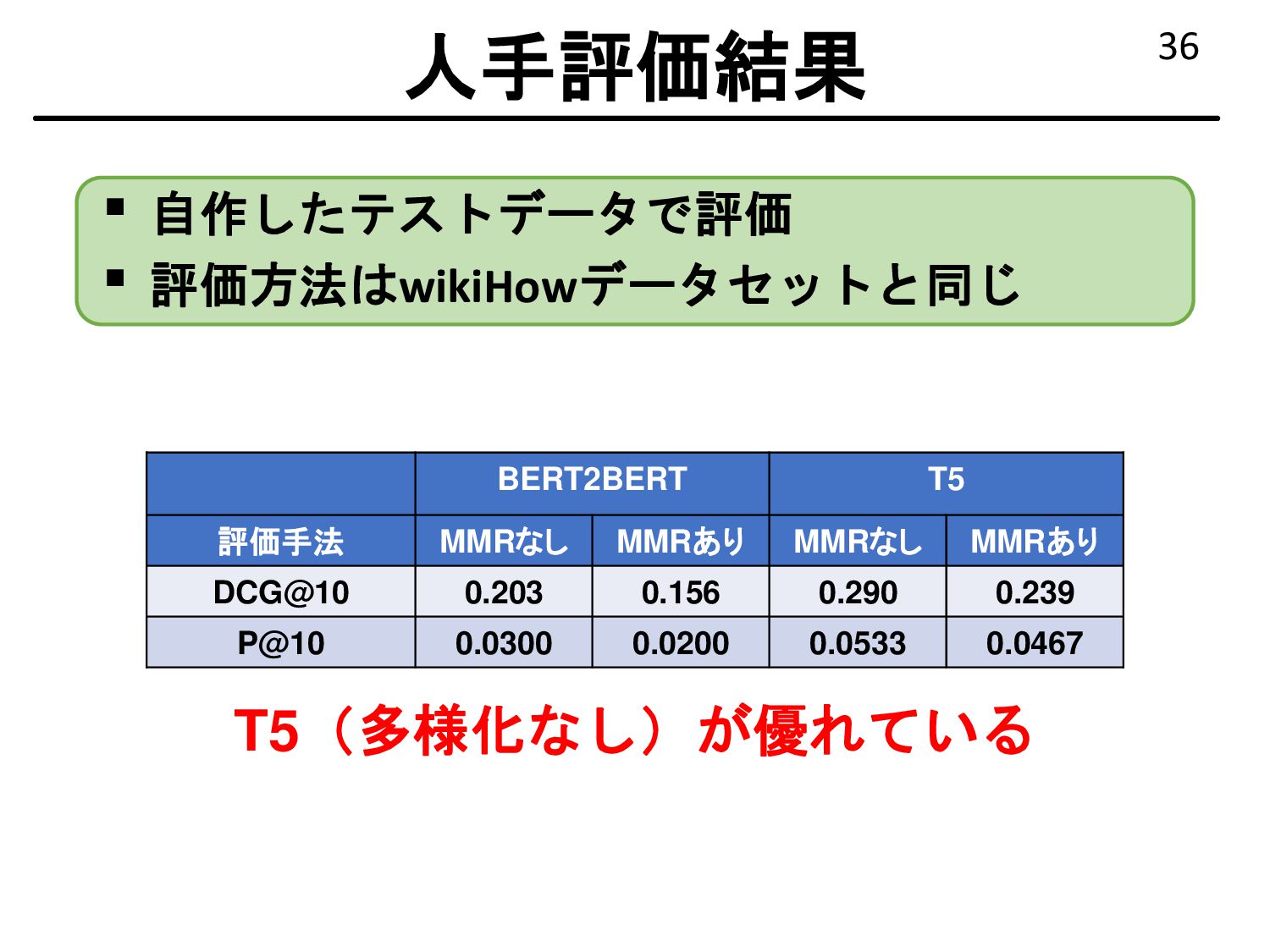{kind=link}
{kind=link}
{kind=link}