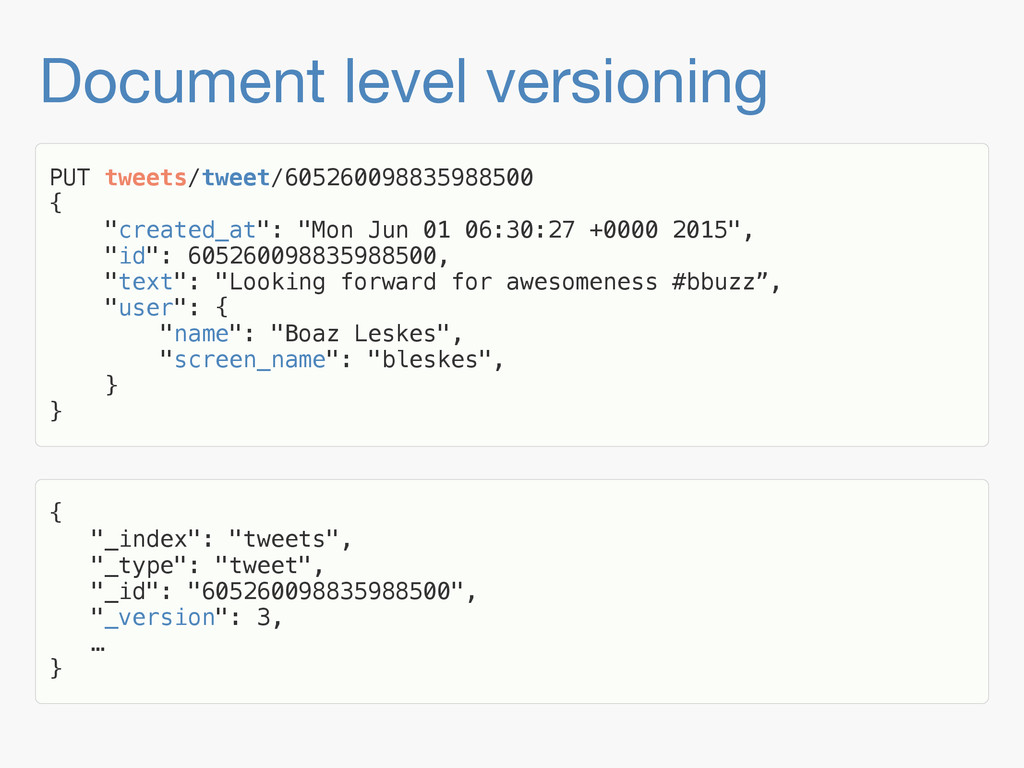
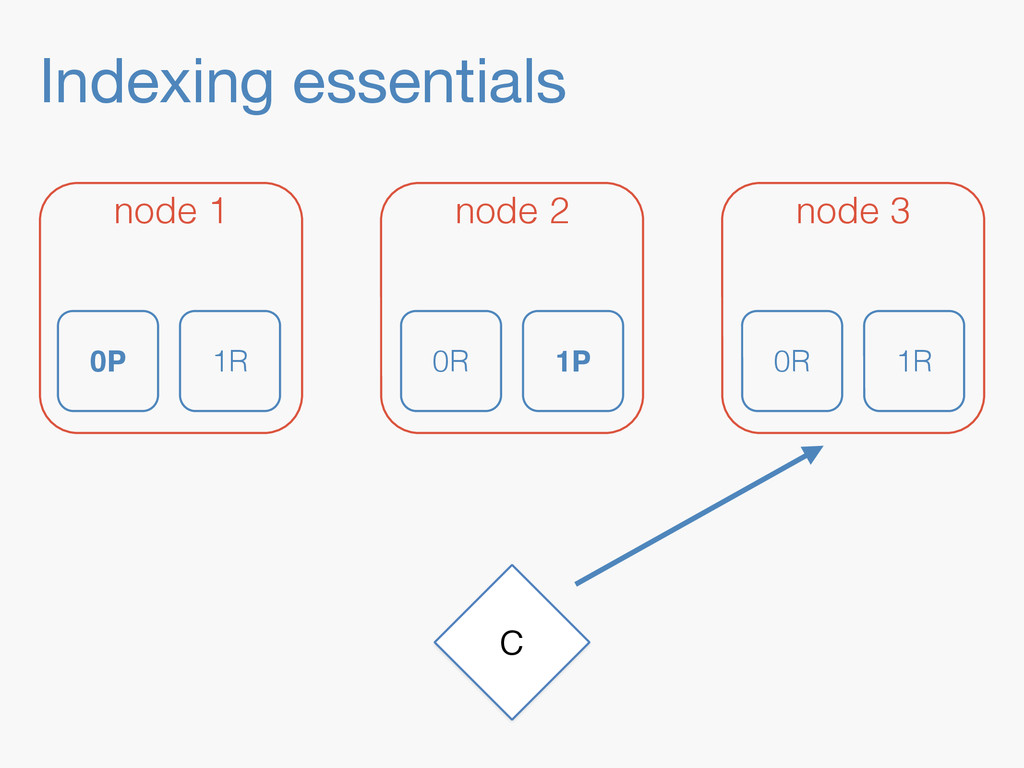
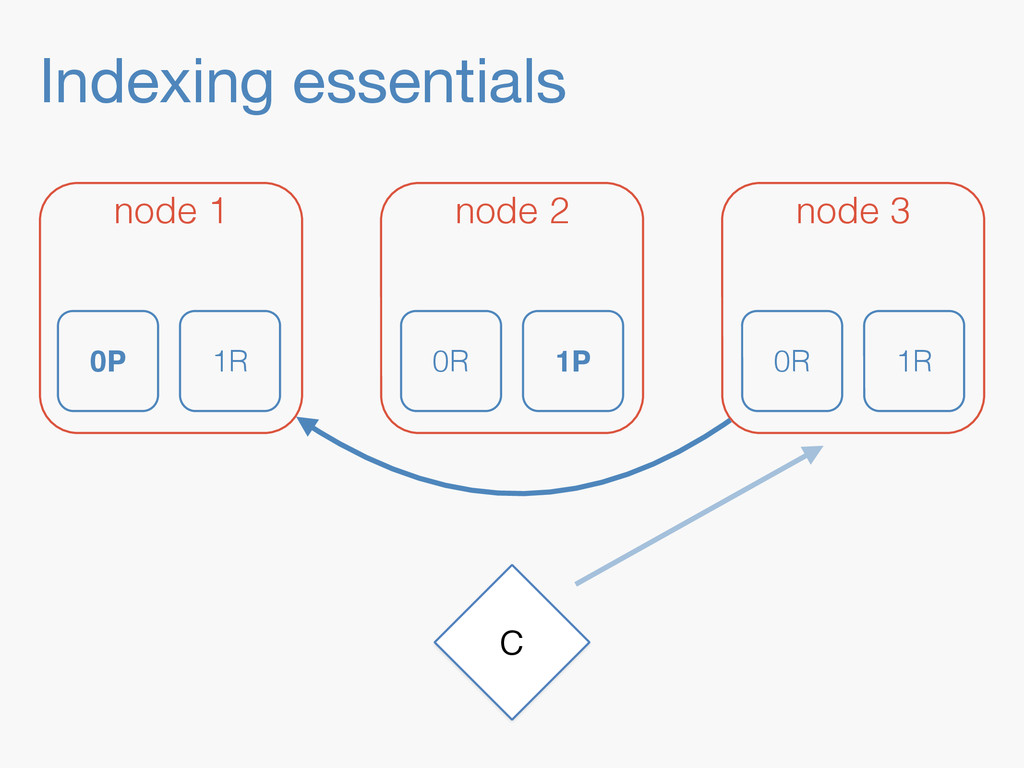
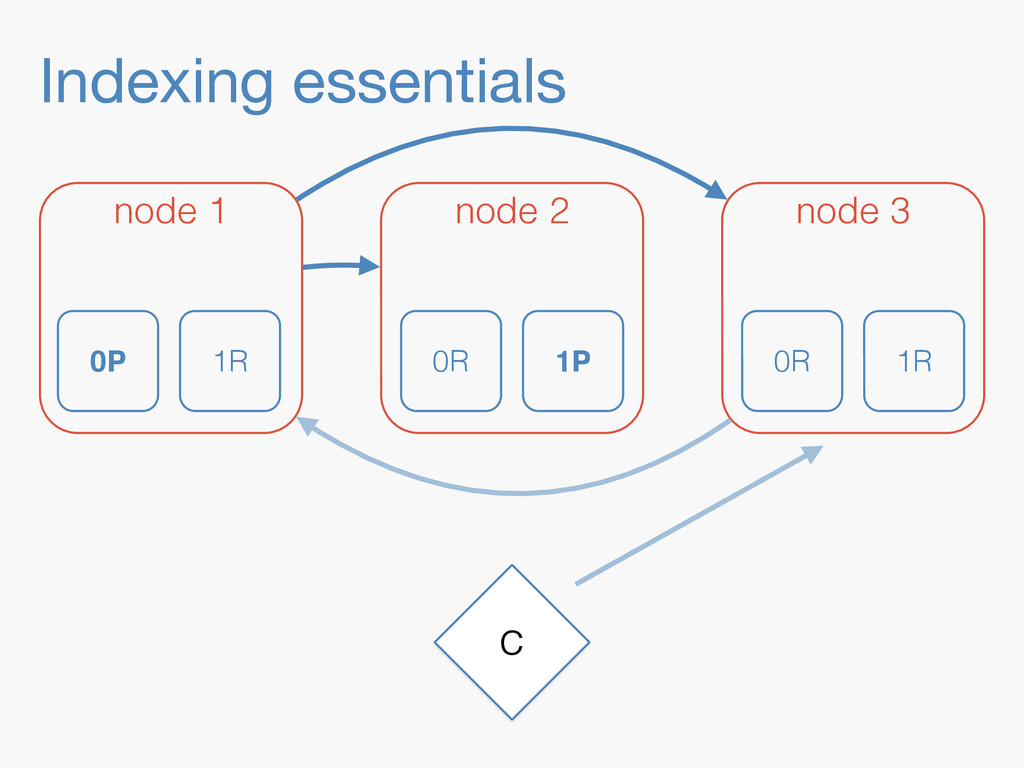
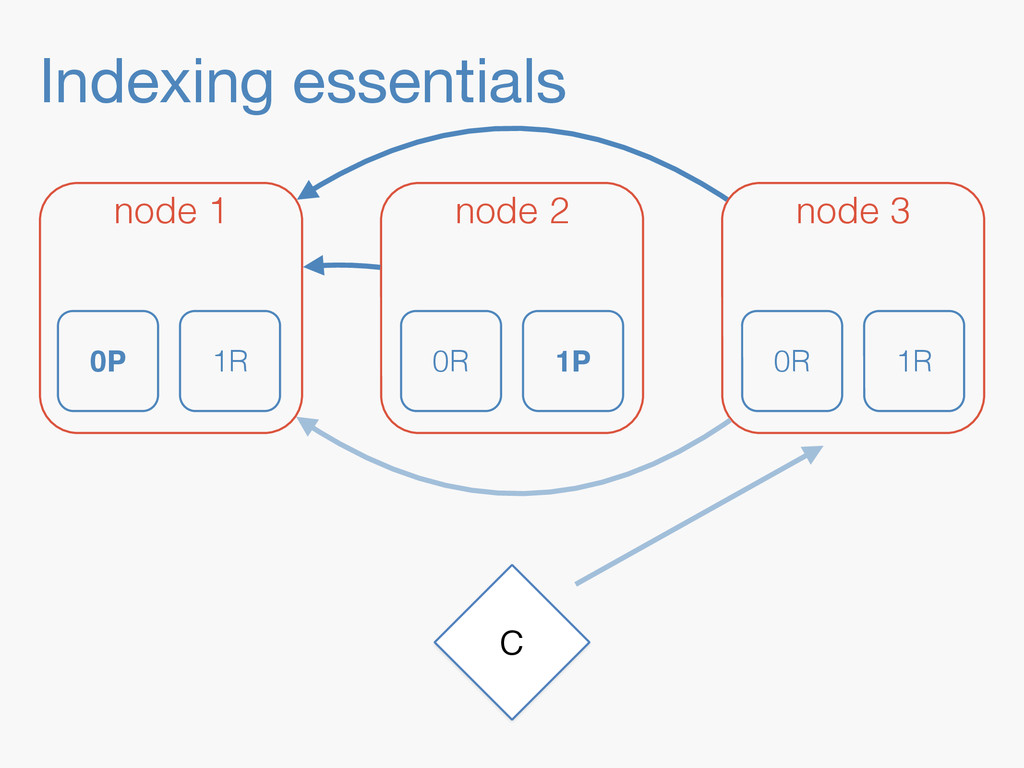
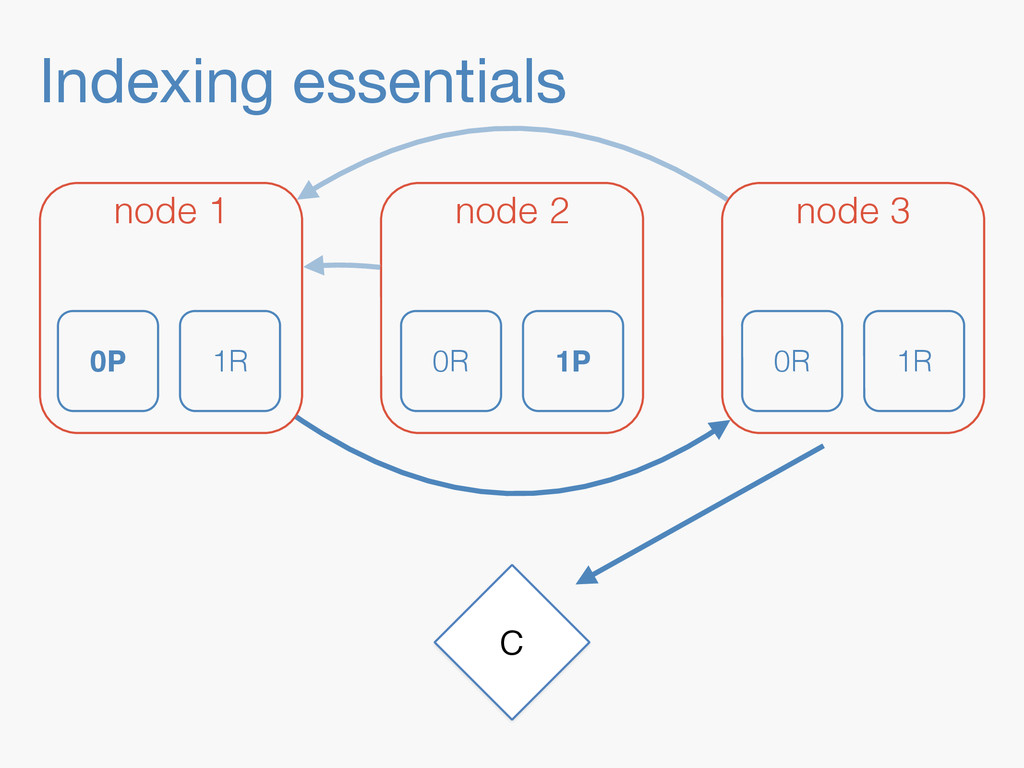
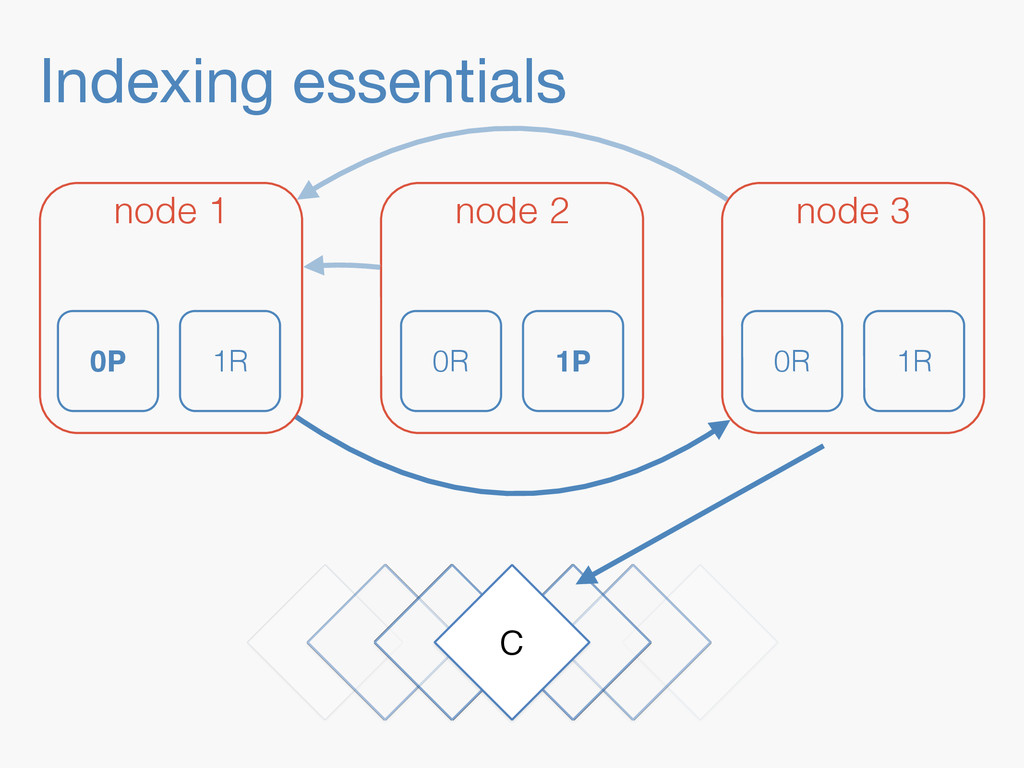
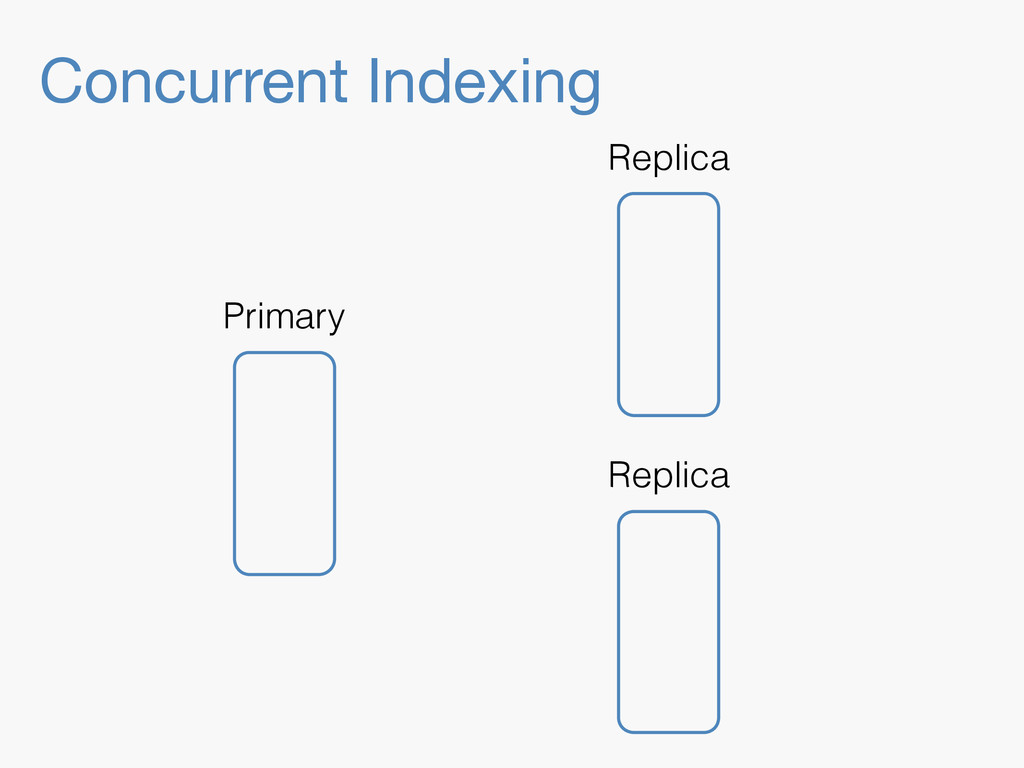
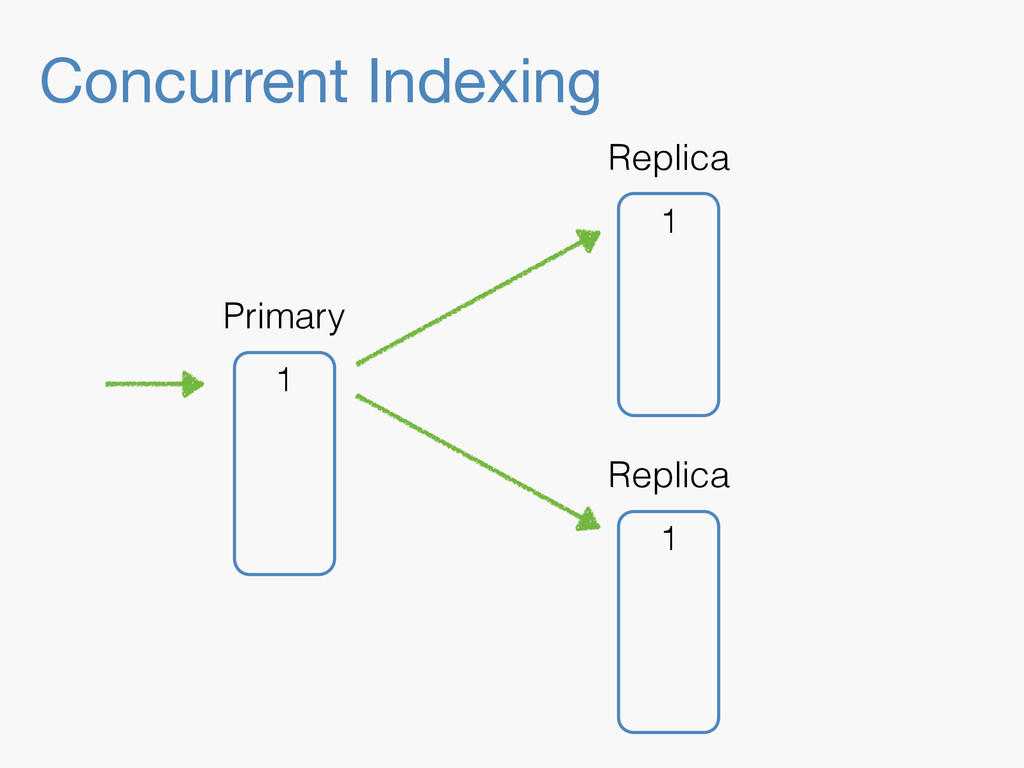
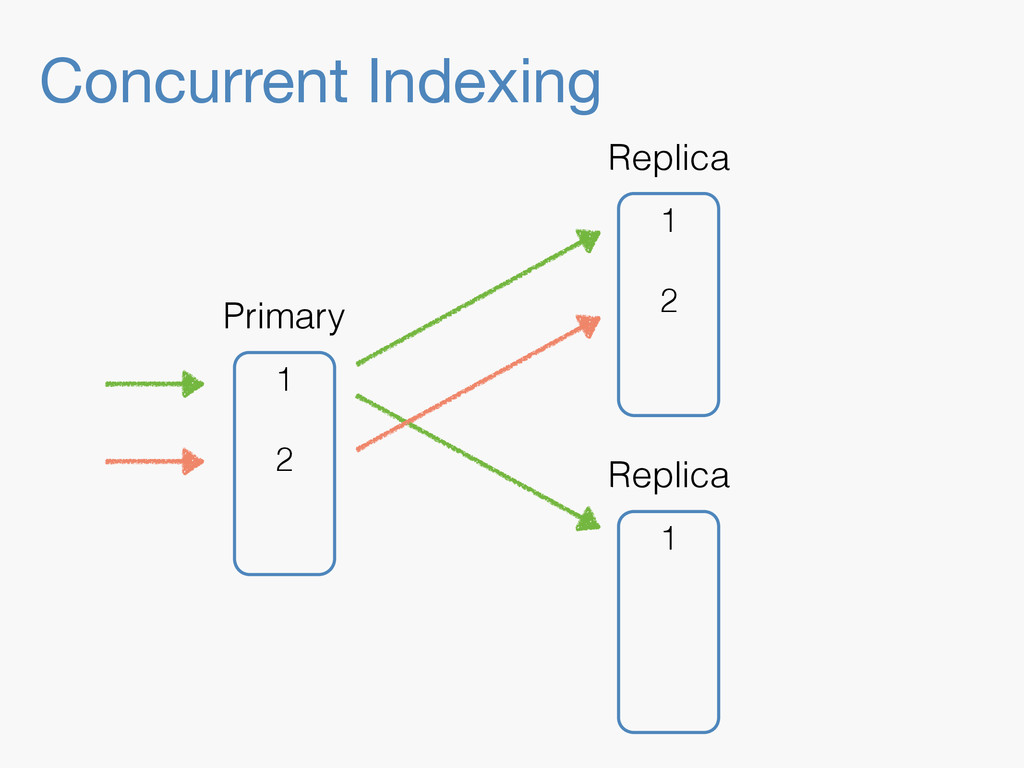
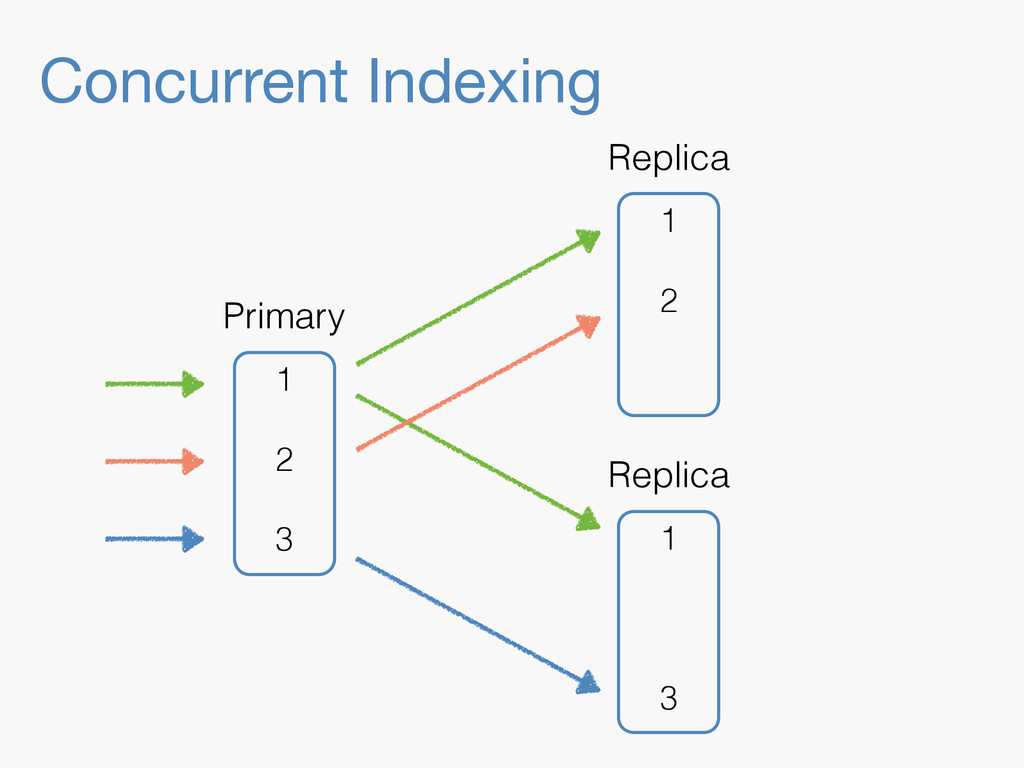
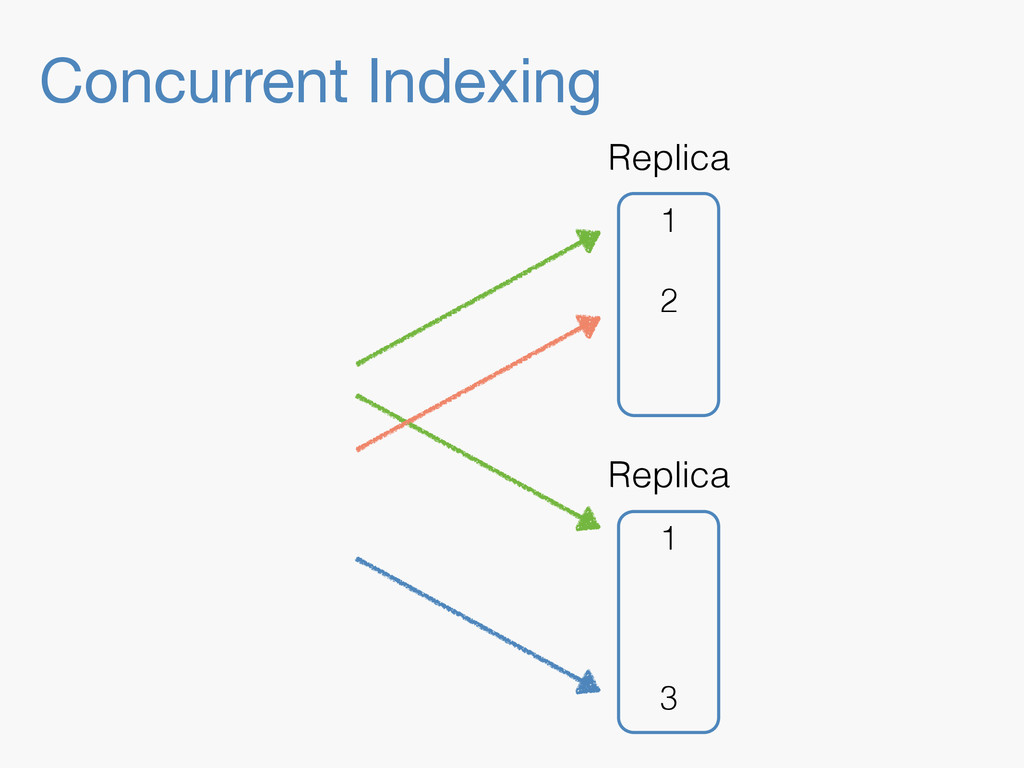
Sequence numbers assign a unique increasing number to every document change. They lay the foundations for higher level features such as a changes stream, or bringing a lagging replica up to speed quickly. Implementing them in a distributed system implies dealing with challenges far beyond the capabilities of a simple AtomicLong. They have to be robust enough to deal with problems like faulty servers, networking issues or sudden power outages. On top of that, they need to work in the highly concurrent indexing environment of systems like Elasticsearch. This talk will take you through the journey of designing such a system.
We will start by explaining the requirements. Then we'll evaluate solutions based on existing consensus algorithms, like ZooKeeper's ZAB and Raft, and why they are (in)sufficient for the task. Next we'll consider some alternate approaches, and finally end up with our proposed solution.
You don't need to be a consensus expert to enjoy this talk. Hopefully, you will leave with a better appreciation of the complexities of distributed systems and be inspired to learn more.
Talk given at Berlin Buzzwords 2015
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}