members of Collections ‧ Collections belong to Databases ‧ Indexes on any key in a document ‧ Javascript interface for queries ‧ Trivial Sharding of data
and query anything inside document (composite keys, 2d/geo indexing) ‧ Great documentation ‧ Great examples (e.g. randomization) ‧ Emphasis on Just Works™ ‧ Drivers in many languages ‧ Active community
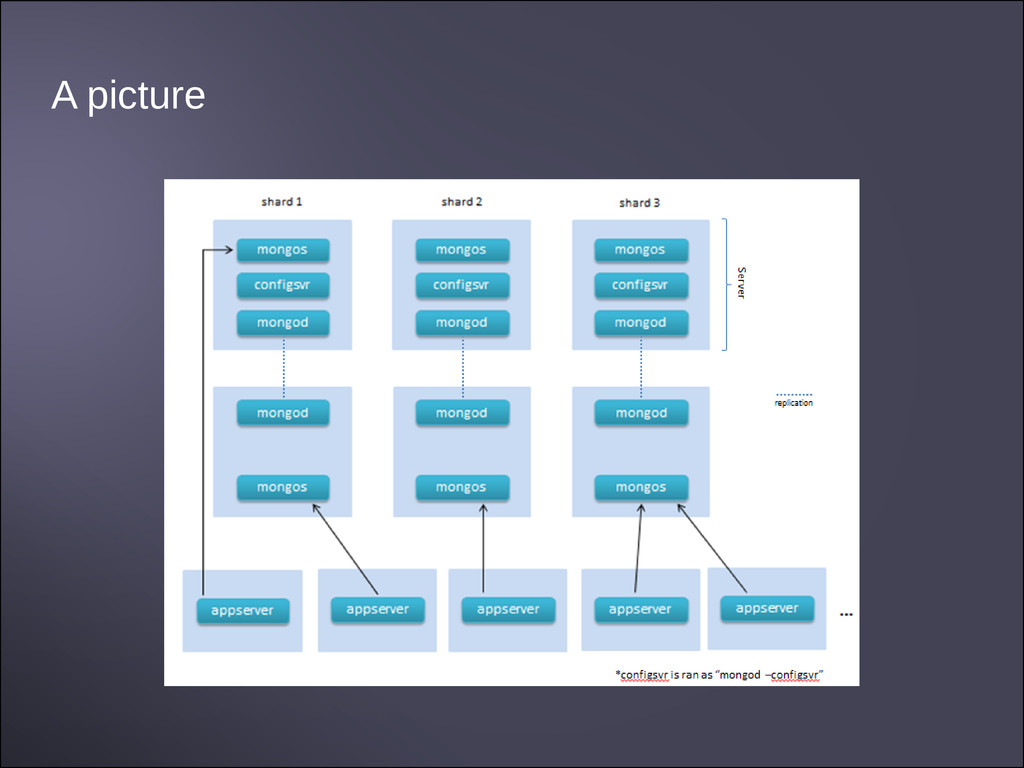
the magic, route requests to the right place • Collate responses from shards, etc. • Apps connect to “mongos” ‧ Config servers • Min 3x for redundancy • Knows about dbs, shards, slaves
console means you can do powerful things on the terminal ‧ JS interface exposes lots of data • Size of indexes • Comprehensive info about where db/collections stored • Location, status and health of nodes
get large (e.g. we have 4gb of indexes on a big collection) ‧ You need to aim to have all indexes+data in ram ‧ MapReduce is available but meh • Improving with each release, possible to hack onto hadoop
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}