Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reinforcement Fine-tuning 基礎〜実践まで
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Morita
December 11, 2025
Technology
0
310
Reinforcement Fine-tuning 基礎〜実践まで
AWS re:Invent ふりかえり勉強会 クラスメソッド re:Growth 2025 福岡
https://classmethod.connpass.com/event/372977/
Morita
December 11, 2025
Tweet
Share
More Decks by Morita
See All by Morita
FSx for Lustreを使ったAIモデル開発の始め方
ch6noota
0
120
Dify で AWS を使い倒す!
ch6noota
1
990
DeepSeek for Amazon Bedrock
ch6noota
0
91
5分で学ぶ! 宣言型ポリシーの基礎からベストプラクティスまで
ch6noota
1
620
新機能 Bedrock Model Distillation 基礎〜実践まで #regrowth_fuk
ch6noota
0
710
AWS を使った生成AIの活用
ch6noota
0
880
AWS初めての方必見!初学者でも入りやすいAWSサービス3選 #devio2022
ch6noota
0
1.4k
Security Hub のマルチアカウント 管理・運用をサーバレスでやってみる
ch6noota
0
3.9k
NITKハッカソン クラウド入門
ch6noota
0
1k
Other Decks in Technology
See All in Technology
Kiroで見直す開発プロセスとAI-DLC
k_adachi_01
0
130
LLMに何を任せ、何を任せないか
cap120
10
5.2k
Kubernetesの「隠れメモリ消費」によるNode共倒れと、Request適正化という処方箋
g0xu
0
110
Laravelで学ぶOAuthとOpenID Connectの基礎と実装
kyoshidaxx
4
1.8k
俺の/私の最強アーキテクチャ決定戦開催 ― チームで新しいアーキテクチャに適合していくために / 20260322 Naoki Takahashi
shift_evolve
PRO
1
440
A4)シラバスを超えて語る、テストマネジメント
moritamasami
0
130
スピンアウト講座05_実践活用事例
overflowinc
0
1.2k
モジュラモノリス導入から4年間の総括:アーキテクチャと組織の相互作用について / Architecture and Organizational Interaction
nazonohito51
6
2.8k
Datadog で実現するセキュリティ対策 ~オブザーバビリティとセキュリティを 一緒にやると何がいいのか~
a2ush
0
120
AI時代のオンプレ-クラウドキャリアチェンジ考
yuu0w0yuu
0
230
スピンアウト講座04_ルーティン処理
overflowinc
0
1.2k
事例から紐解くSHIFT流QA支援 ~大規模プロジェクトの品質管理支援、QA組織立ち上げ~ / 20260320 Nozomu Koketsu
shift_evolve
PRO
0
140
Featured
See All Featured
Balancing Empowerment & Direction
lara
5
960
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
61
43k
Heart Work Chapter 1 - Part 1
lfama
PRO
5
35k
Color Theory Basics | Prateek | Gurzu
gurzu
0
260
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
150
What's in a price? How to price your products and services
michaelherold
247
13k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
0
180
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.7k
A Tale of Four Properties
chriscoyier
163
24k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.8k
Testing 201, or: Great Expectations
jmmastey
46
8.1k
Un-Boring Meetings
codingconduct
0
240
Transcript
2025/12/11 クラウド事業本部 コンサルティング部 森⽥⼒ Reinforcement Fine-tuning 基礎〜実践まで
⾃⼰紹介 • 所属 ◦ クラウド事業本部 コンサルティング部 • 好きなサービス ◦ Amazon
Bedrock ◦ AWS Lambda • re:Invent ◦ 2回⽬の参加 ◦ PCディスプレイ破損した😇
AWS re:Invent 2025 - Dr. Swami Sivasubramanian
Reinforcement Fine-tuning in Amazon Bedrock Reinforcement Fine-tuningの特徴として • ベースモデルと⽐較して、平均66%の精度向上を実現 •
深い機械学習(ML)の専⾨知識や、⼤規模なラベル付きデータセットは不要 • エンドツーエンドで⾃動化されたファインチューニング • 品質を維持しながら、より⼩さく、⾼速で、費⽤対効果の⾼いモデルを実現
Reinforcement?
Reinforcement Learning Reinforcement … Reinforcement Learning(強化学習) 強化学習は、端的に⾔うと「最適な⾏動や戦略を学習する⼿法」 ⾝近な例:ゲームをする場合
ゲームに対しての攻略⽅法がわからない ユーザが取れる⾏動: • 攻撃する • 移動する など → 様々な⾏動を試して、試⾏錯誤を⾏う Reinforcement
Learning
⾏動の結果がわかる 結果: • 勝つ • 負ける など この結果と⾏動を紐づけて考える 例:攻撃すると勝つ、移動すると負ける Reinforcement
Learning
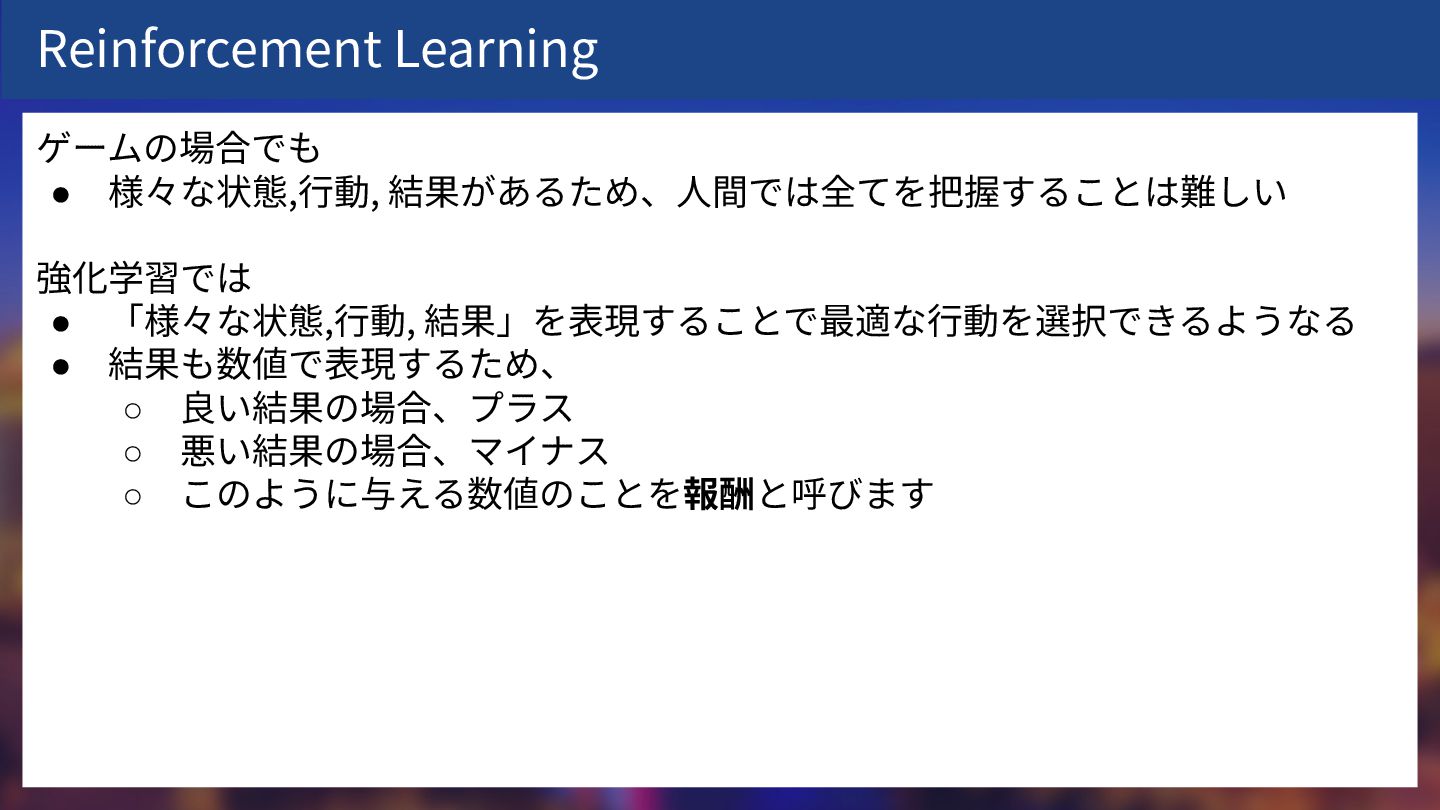
Reinforcement Learning ゲームの場合でも • 様々な状態,⾏動, 結果があるため、⼈間では全てを把握することは難しい 強化学習では • 「様々な状態,⾏動, 結果」を表現することで最適な⾏動を選択できるようなる
• 結果も数値で表現するため、 ◦ 良い結果の場合、プラス ◦ 悪い結果の場合、マイナス ◦ このように与える数値のことを報酬と呼びます
Reinforcement Fine-tuningについて
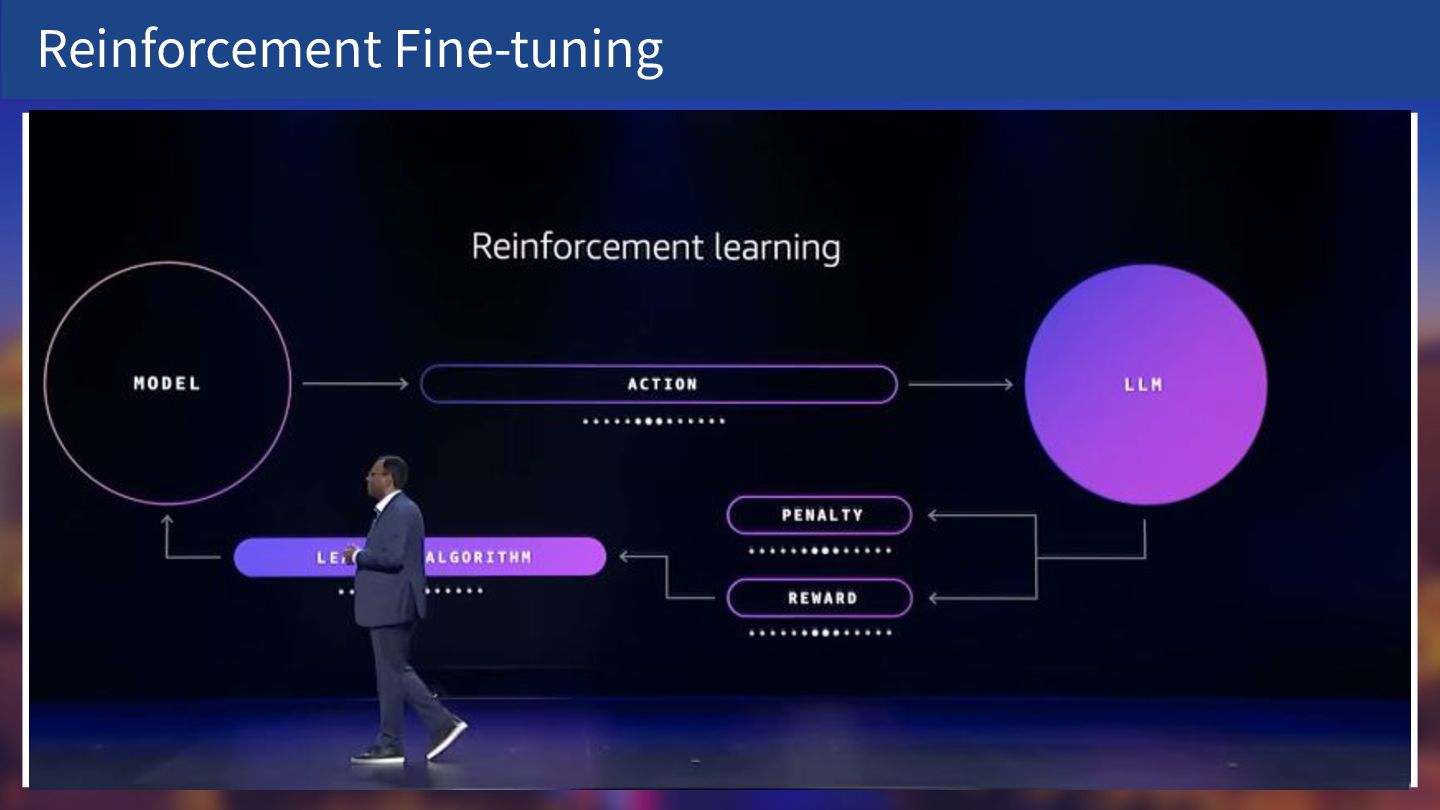
Reinforcement Fine-tuning Reinforcement Fine-tuning (RFT) 「強化学習」の仕組みを LLM の学習(Fine-tuning)に適⽤ 先ほどのゲームの例では「クリアやスコア」が報酬 RFTにおいては「⼈間の評価」や「特定の基準」が報酬
具体的には、モデルが⽣成した回答に対して、 「この回答は良い(報酬を与える)」「この回答は良くない(罰則を与える)」 というフィードバックを与える → 「より⾼い評価が得られる回答の作り⽅」を学習させることが可能
Reinforcement Fine-tuning
Bedrock Reinforcement Fine-tuningについて
Bedrock Reinforcement Fine-tuning 以下を設定するだけで Reinforcement Fine-tuning を実⾏可能 • ソースモデル •
⼊⼒データ • 報酬関数
ソースモデル 現在は、「Nova 2 Lite」のみの対応 https://dev.classmethod.jp/articles/amazon-nova-2-lite-release-aws-reinvent/
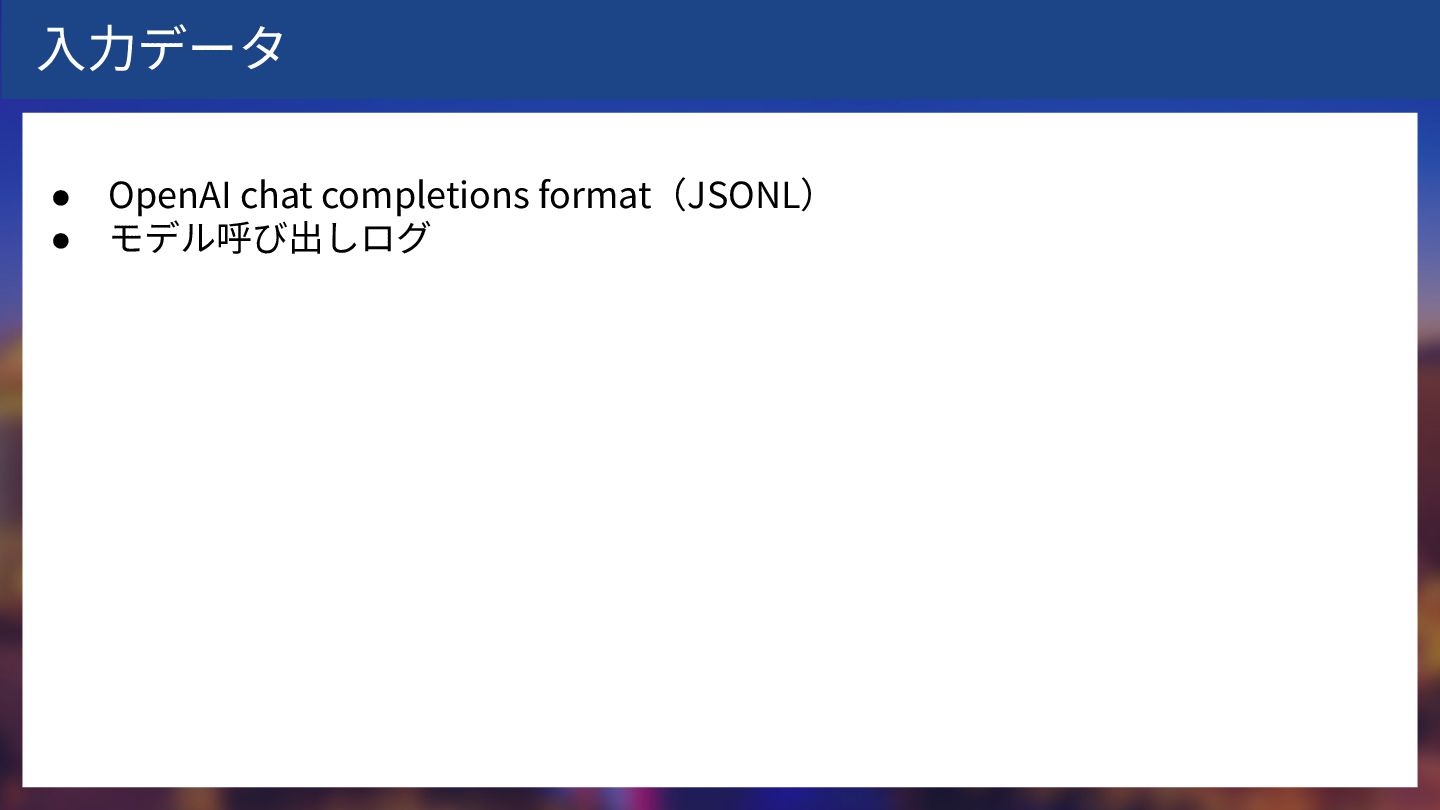
⼊⼒データ • OpenAI chat completions format(JSONL) • モデル呼び出しログ
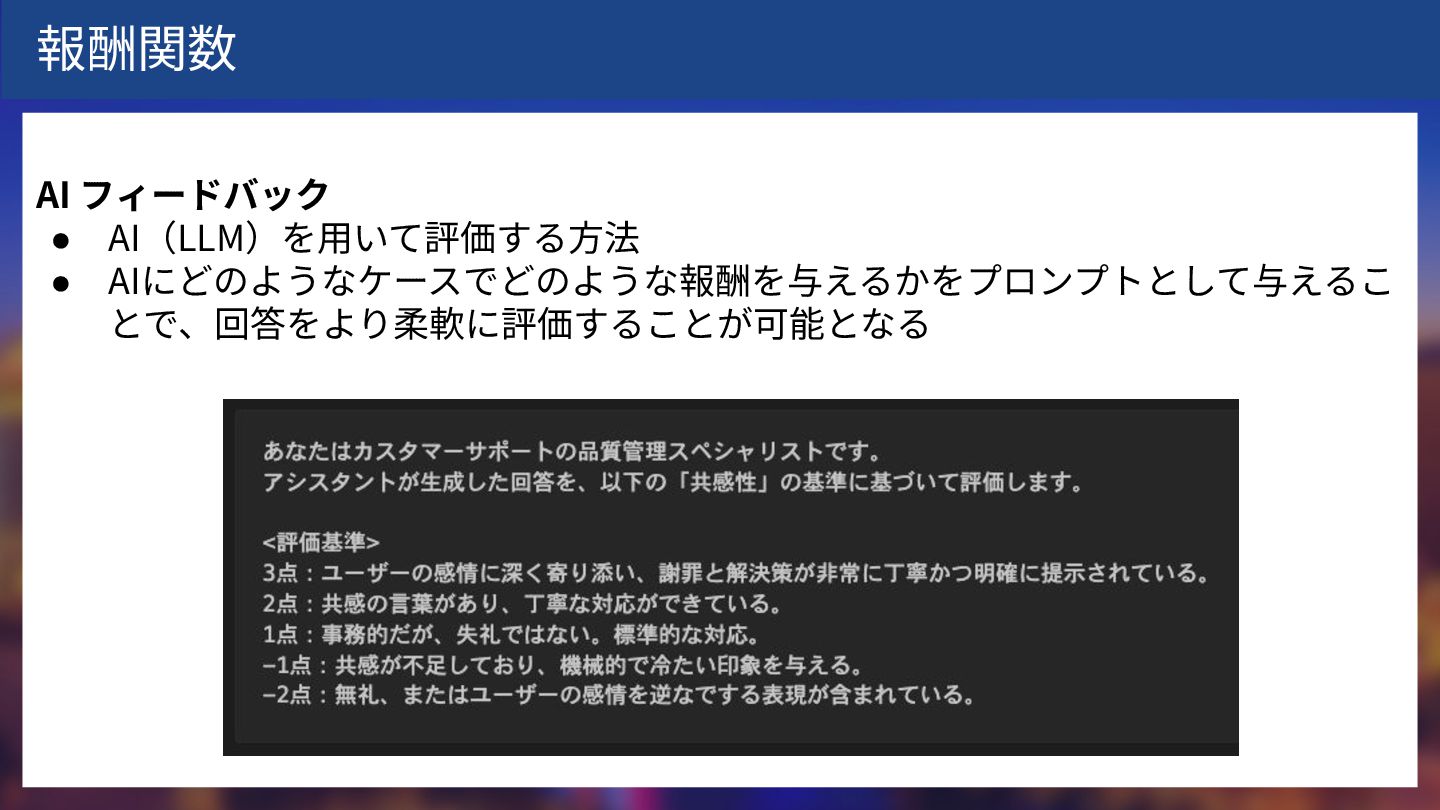
報酬関数 AI フィードバック • AI(LLM)を⽤いて評価する⽅法 • AIにどのようなケースでどのような報酬を与えるかをプロンプトとして与えるこ とで、回答をより柔軟に評価することが可能となる
報酬関数 AI フィードバック • 選択できるAI(LLM) ◦ Nova Premier ◦ gpt-oss-120b
• プロンプトのサンプルの提供あり ◦ Instruction following (Judge model training) ◦ Summarization (Multi-turn dialogs) ◦ Reasoning evaluation (CoT for specialized domains) ◦ RAG faithfulness (Context-grounded Q&A)
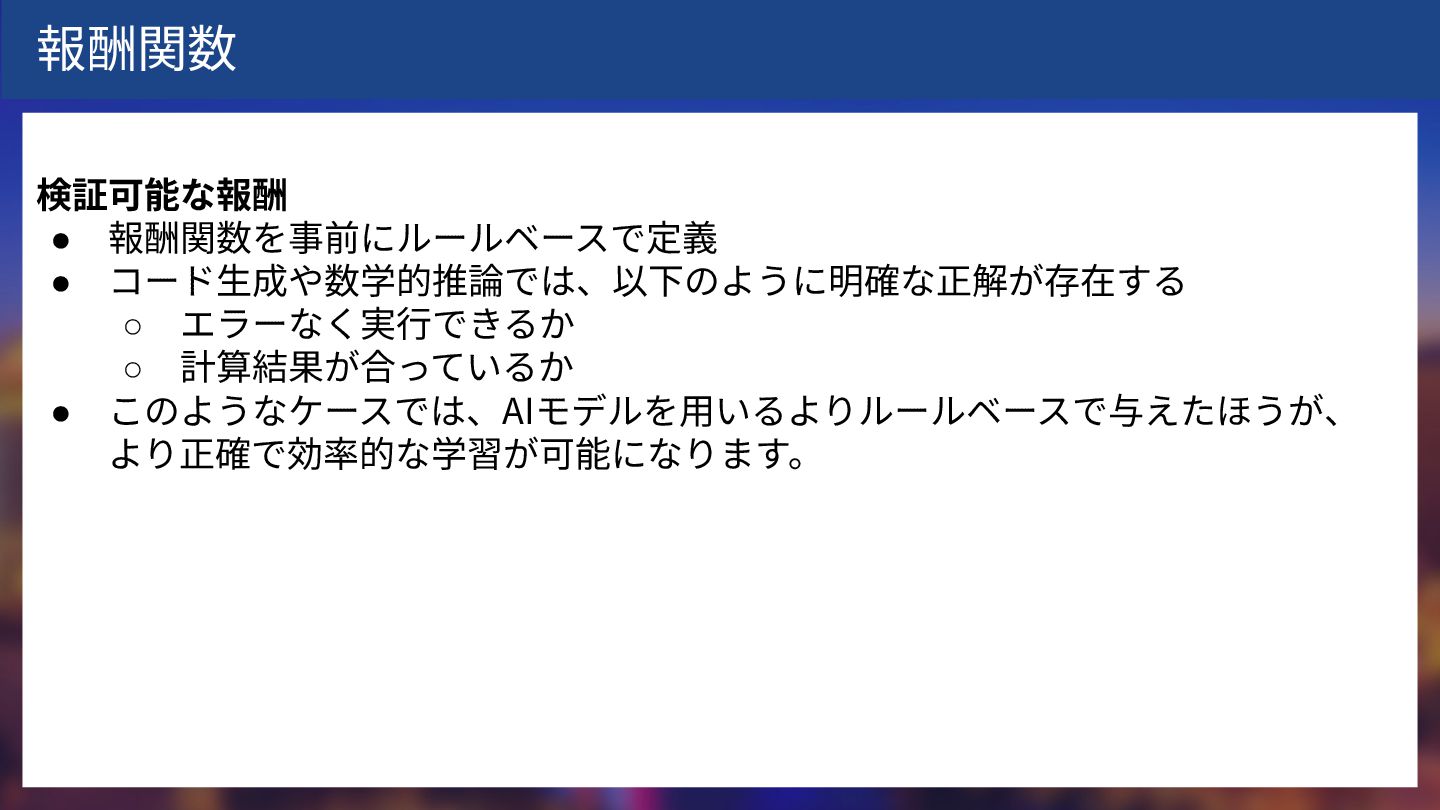
報酬関数 検証可能な報酬 • 報酬関数を事前にルールベースで定義 • コード⽣成や数学的推論では、以下のように明確な正解が存在する ◦ エラーなく実⾏できるか ◦ 計算結果が合っているか
• このようなケースでは、AIモデルを⽤いるよりルールベースで与えたほうが、 より正確で効率的な学習が可能になります。
報酬関数 検証可能な報酬 • AWS Lambdaで設定可能 • Lambdaのサンプル提供あり ◦ Format &
constraints checker ◦ Math reasoning
結論: 「⼊⼒データ」だけ準備すればOK
Bedrock Reinforcement Fine-tuningのジョブ実⾏ • ジョブの時間単位 • (おそらく)関連リソースの料⾦も発⽣する ◦ 報酬関数(LLM, AWS
Lambda) モデル推論 • カスタムモデルオンデマンド ◦ 利⽤したトークンベースの課⾦ ◦ ホスティング費⽤は発⽣しない 料⾦
まとめ • 従来まで構成が難しい Reinforcement Fine-tuning が Bedrockで実現可能に • ⼩規模モデルで精度が満⾜できていなかったケースでも採⽤できる可能性あり •
作成したモデルも従量課⾦で利⽤できるため、スモールに開始できる
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}