Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Web系企業研究所における研究開発を加速させるエコシステム / Ecosystem accel...
Search
chck
October 08, 2021
Research
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
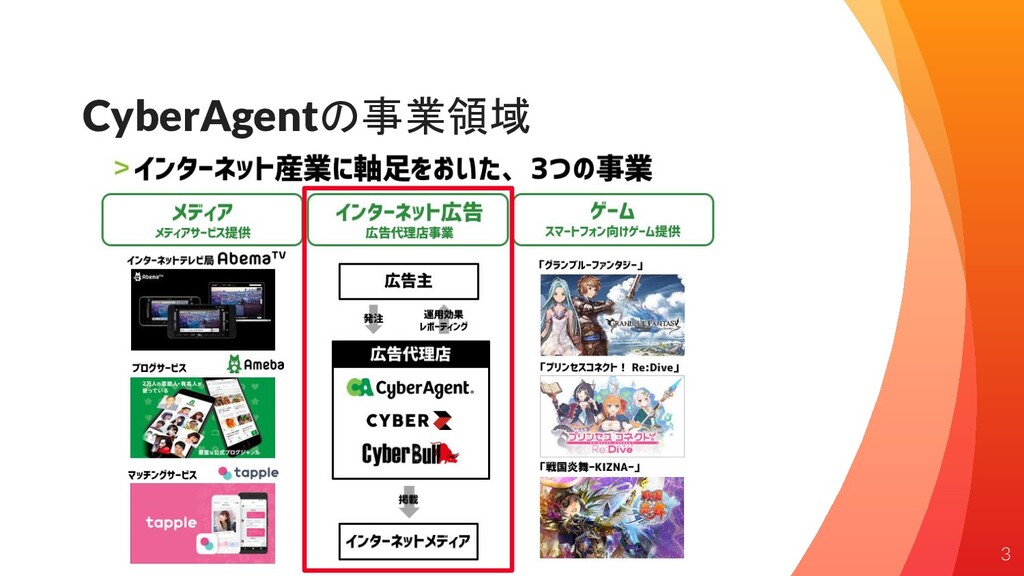
Web系企業研究所における研究開発を加速させるエコシステム / Ecosystem accelerates our R&D in CyberAgent AI Lab
PRMU #202110
での発表資料です
chck
October 08, 2021
More Decks by chck
See All by chck
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.8k
CyberAgent AI Lab研修 / Container for Research
chck
1
2.4k
CyberAgent AI Lab研修 / Code Review in a Team
chck
3
2.4k
論文読み会 / Socio-Technical Anti-Patterns in Building ML-Enabled Software: Insights from Leaders on the Forefront
chck
0
140
CyberAgent AI事業本部MLOps研修Container編 / Container for MLOps
chck
3
6k
論文読み会 / GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models
chck
0
96
論文読み会 / On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
chck
0
73
論文読み会 / GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
chck
0
69
Other Decks in Research
See All in Research
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
110
Using our influence and power for patient safety
helenbevan
0
370
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
260
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
580
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
320
IA for theory
gpeyre
0
270
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
120
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.6k
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
880
Featured
See All Featured
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Un-Boring Meetings
codingconduct
0
350
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
For a Future-Friendly Web
brad_frost
183
10k
Designing for Performance
lara
611
70k
Into the Great Unknown - MozCon
thekraken
41
2.6k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Transcript
Web系企業研究所における 研究開発を加速させるエコシステム PRMU研究会 20211008 Yuki IWAZAKI@chck / CyberAgent AI Lab
Hello! I am Yuki IWAZAKI@chck ◦ 2014...Backend Engineer in DSP
└2018-...Research Engineer in AI Lab ◦ Ad x Multimedia (Vision & Language) 2
CyberAgentの事業領域 3
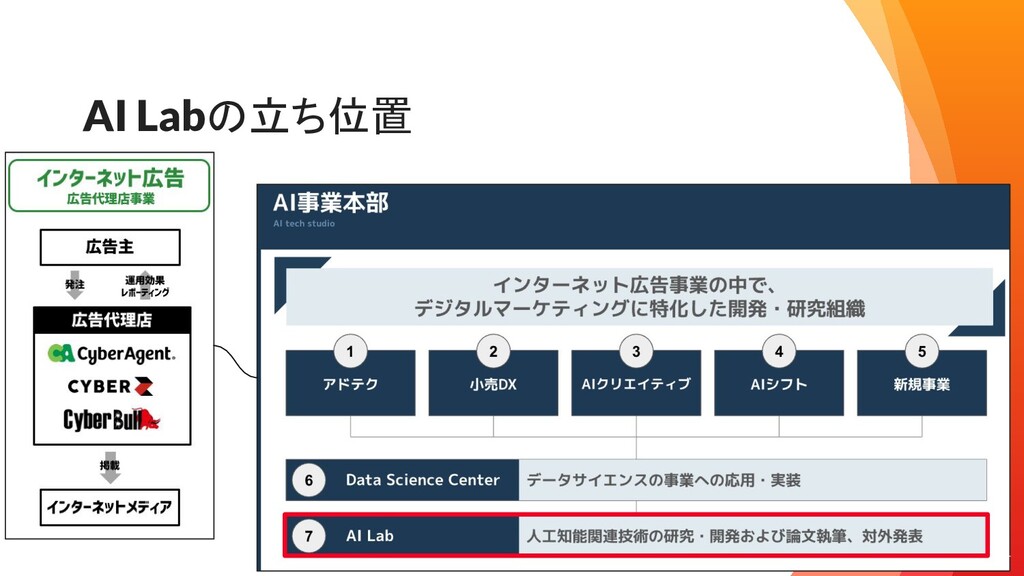
AI Labの立ち位置 4
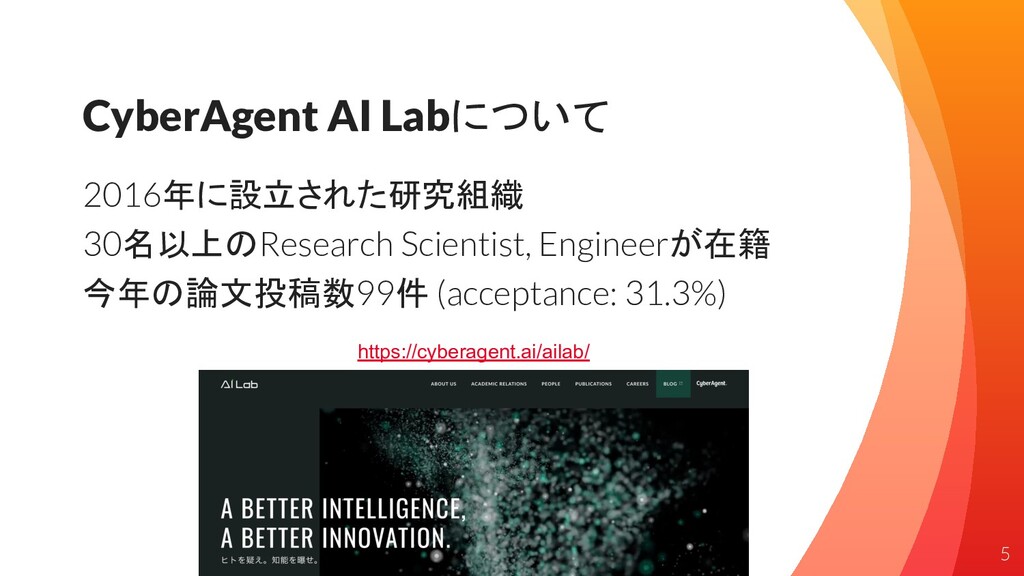
CyberAgent AI Labについて 2016年に設立された研究組織 30名以上のResearch Scientist, Engineerが在籍 今年の論文投稿数99件 (acceptance: 31.3%)
https://cyberagent.ai/ailab/ 5
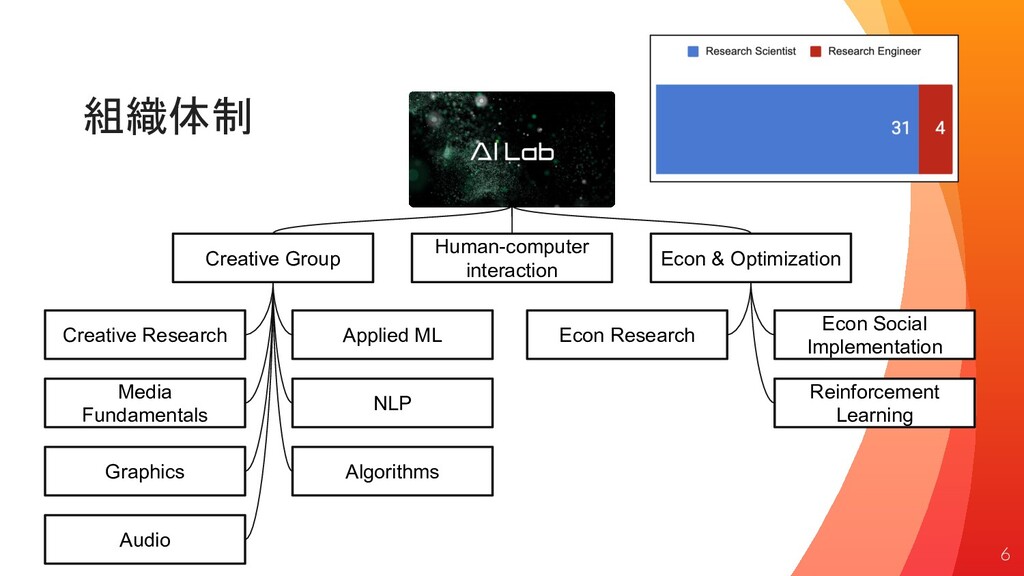
組織体制 AI Lab Creative Group Human-computer interaction Econ & Optimization
Creative Research NLP Applied ML Algorithms Graphics Audio Media Fundamentals Econ Research Econ Social Implementation Reinforcement Learning 6
AI LabにおけるR&Dの進め方 • 学術貢献 -> 論文投稿, 学会発表, 特許 ◦ Proposal
first, Bottom up ▪ 会社の事業領域に関連する基礎, 応用研究 • 事業貢献 -> コンサル, EDA, Modeling ◦ Task first, Top down ▪ プロダクトと連携して課題解決 7
AI LabにおけるR&Dの進め方 • 学術貢献 -> 論文投稿, 学会発表 ◦ Proposal first,
Bottom up ▪ 会社の事業領域に関連する基礎, 応用研究 • 事業貢献 -> コンサル, EDA, Modeling ◦ Task first, Top down ▪ プロダクトと連携して課題解決 8
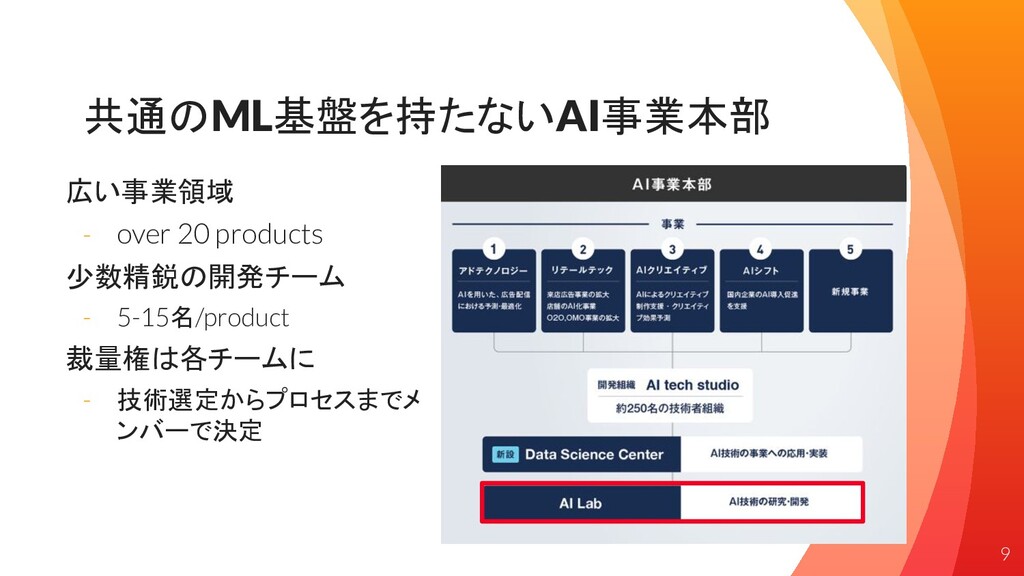
共通のML基盤を持たないAI事業本部 広い事業領域 - over 20 products 少数精鋭の開発チーム - 5-15名/product 裁量権は各チームに
- 技術選定からプロセスまでメ ンバーで決定 9
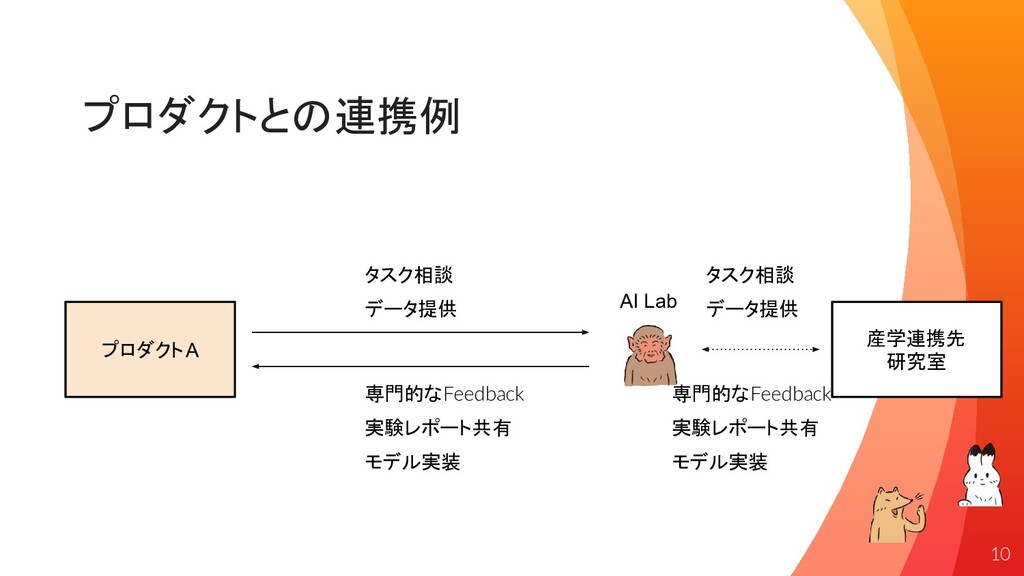
プロダクトとの連携例 タスク相談 モデル実装 データ提供 実験レポート共有 プロダクトA AI Lab 専門的なFeedback 産学連携先
研究室 データ提供 タスク相談 専門的なFeedback モデル実装 実験レポート共有 10
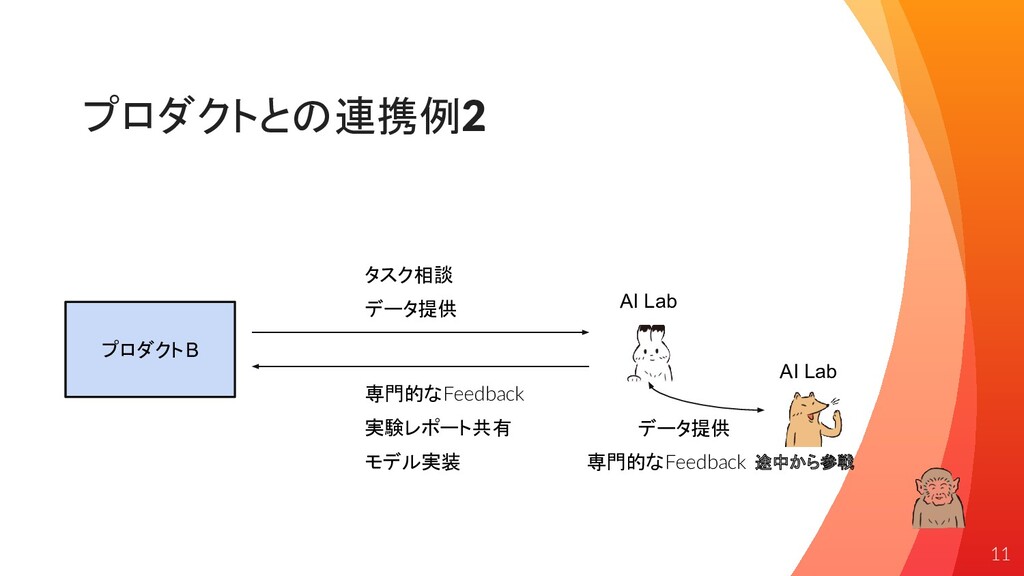
プロダクトとの連携例2 タスク相談 モデル実装 データ提供 実験レポート共有 プロダクトB AI Lab 専門的なFeedback 途中から参戦
データ提供 専門的なFeedback AI Lab 11
研究組織における3つの課題 1. データ管理 2. モデル管理 3. 実験管理 12
1. データ管理
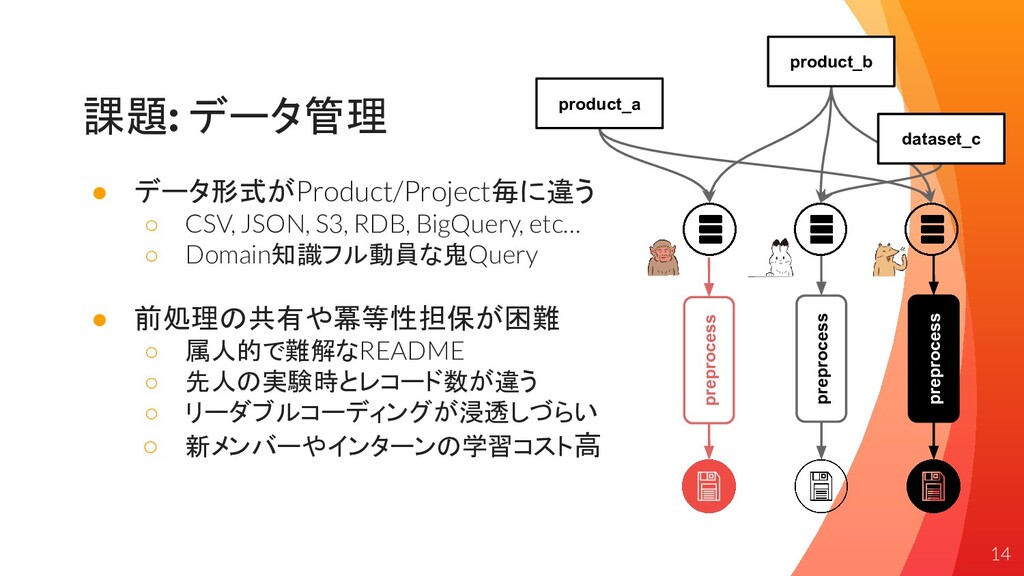
課題: データ管理 • データ形式がProduct/Project毎に違う ◦ CSV, JSON, S3, RDB, BigQuery,
etc… ◦ Domain知識フル動員な鬼Query • 前処理の共有や冪等性担保が困難 ◦ 属人的で難解なREADME ◦ 先人の実験時とレコード数が違う ◦ リーダブルコーディングが浸透しづらい ◦ 新メンバーやインターンの学習コスト高 preprocess preprocess preprocess product_a dataset_c product_b 14
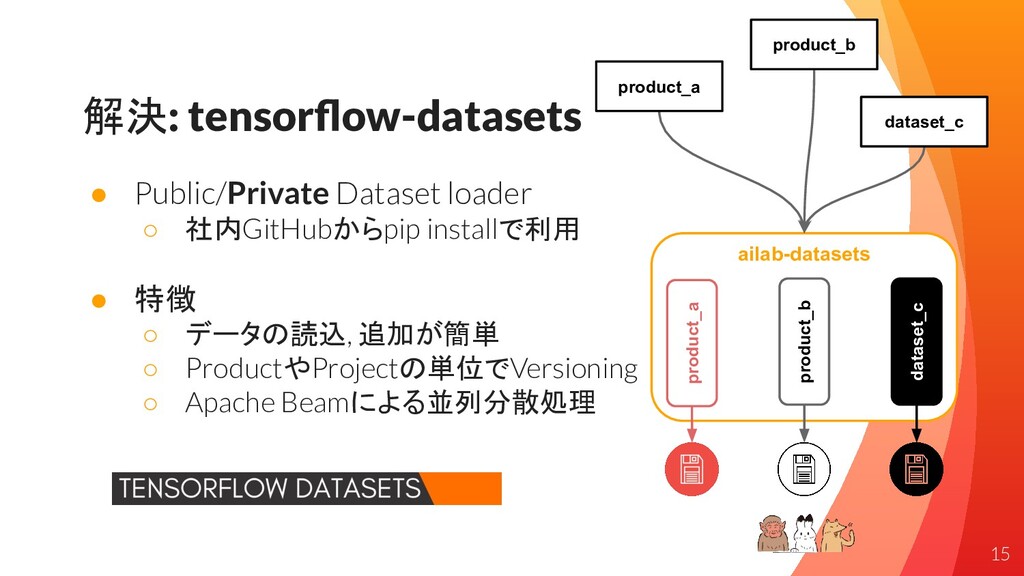
解決: tensorflow-datasets • Public/Private Dataset loader ◦ 社内GitHubからpip installで利用 •
特徴 ◦ データの読込, 追加が簡単 ◦ ProductやProjectの単位でVersioning ◦ Apache Beamによる並列分散処理 product_a product_b dataset_c product_a dataset_c product_b ailab-datasets 15
tensorflow-datasets: load tf.dataやnumpy, pandas形式でloadできる 16
tensorflow-datasets: load tf.dataやnumpy, pandas形式でloadできる 17 Datasetを指定 Iterationの定義
tensorflow-datasets: load tf.dataやnumpy, pandas形式でloadできる 18 tf.data numpy pandas
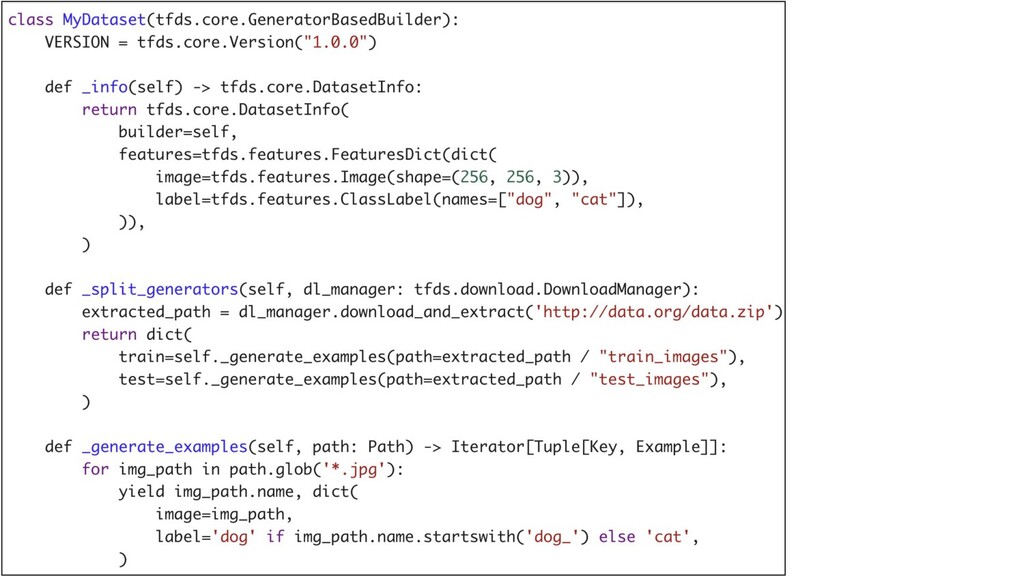
tensorflow-datasets: create tfds cliからtemplateを生成 19
20
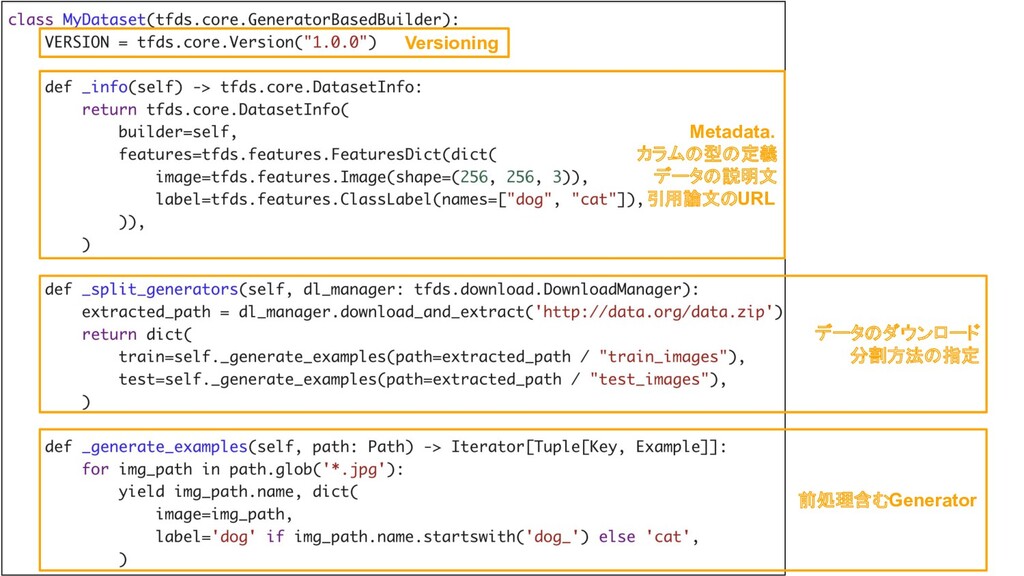
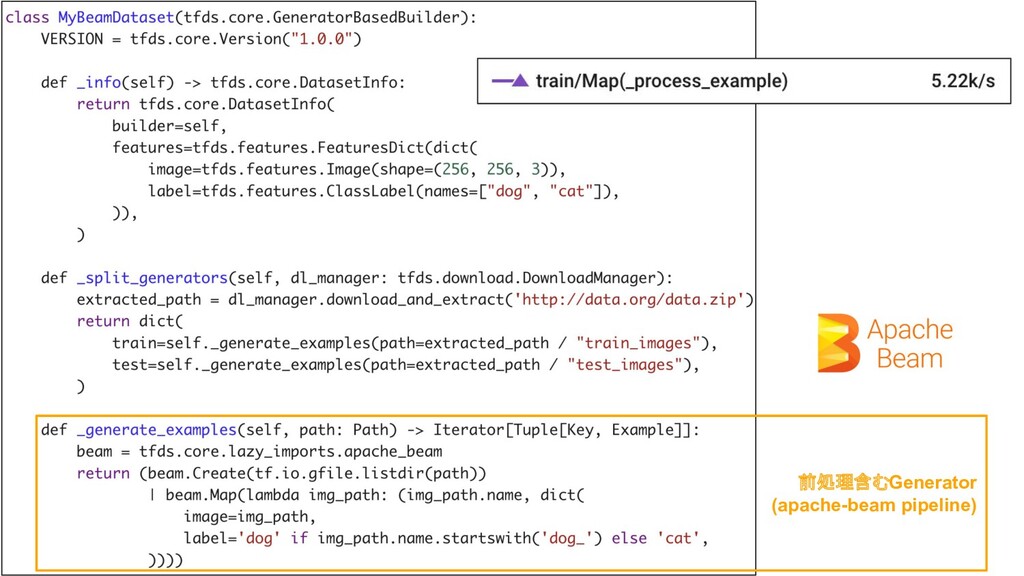
21 Versioning Metadata. カラムの型の定義 データの説明文 引用論文のURL データのダウンロード 分割方法の指定 前処理含むGenerator
22
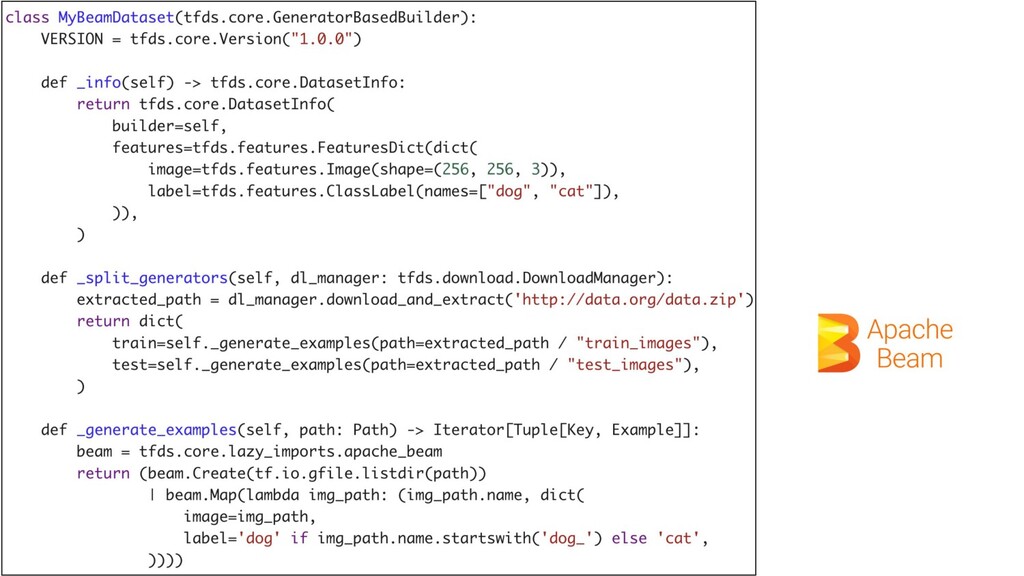
23 前処理含むGenerator (apache-beam pipeline)
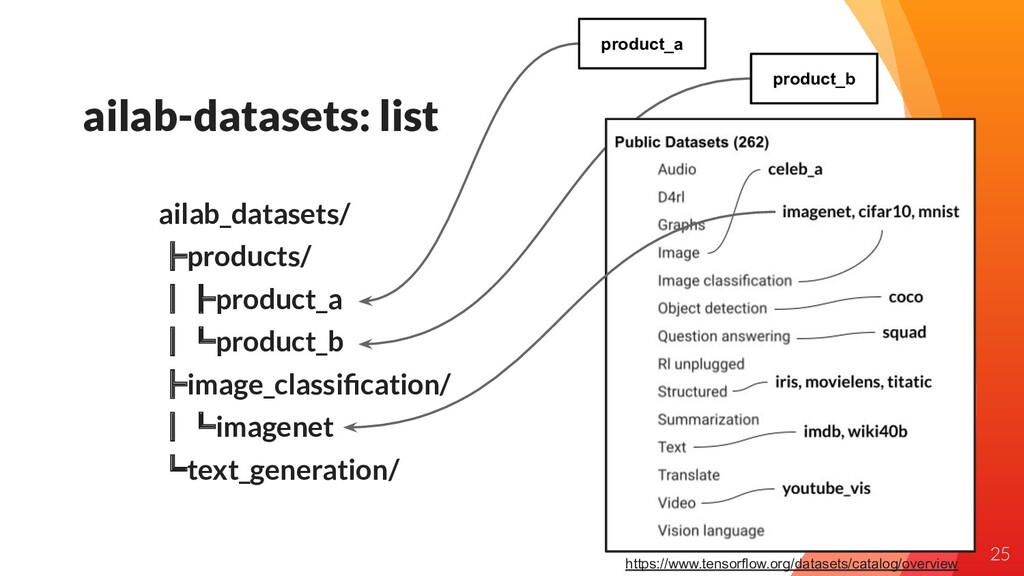
ailab-datasets: list product_a product_b ailab_datasets/ ┣products/ ┃┣product_a ┃┗product_b ┣image_classification/ ┃┗imagenet
┗text_generation/ https://www.tensorflow.org/datasets/catalog/overview 25
2. モデル管理
課題: モデル管理 • モデルの再発明が多発 ◦ 似たタスク前に誰かがやっていたような ◦ benchmark取りたいが再実装した方が早そう • 研究者間でモデルの重みシェアしたい
◦ 既にどんなモデルがあるか把握しづらい ◦ Aさんの学習済モデルはBさんのテーマで応用できるかも • Public pre-trained modelのprivate版がほしい ◦ ResNet(on imagenet)やBERT(on jawiki)の社内データ版 27
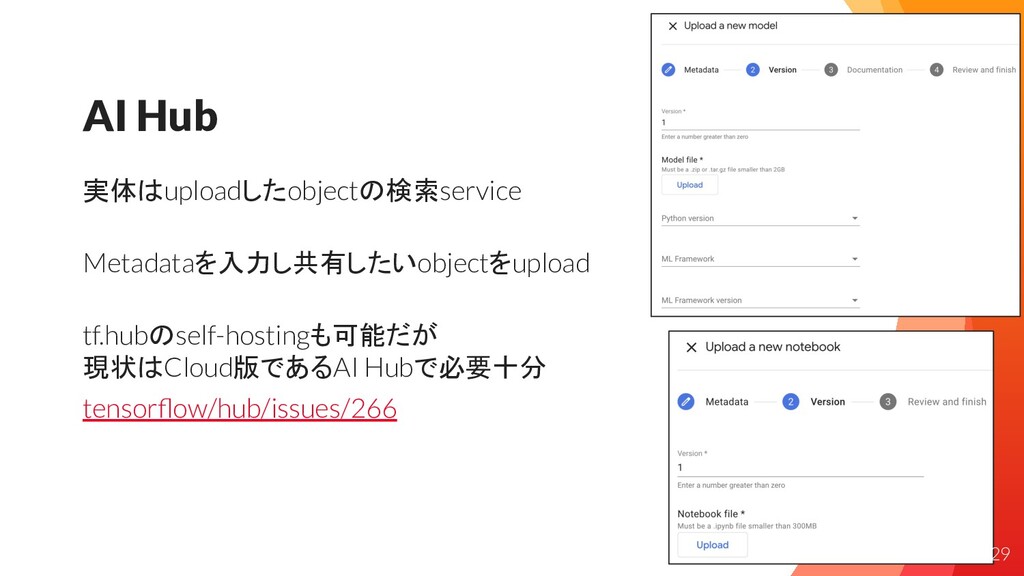
解決: AI Hub tensorflow-hubのManaged版であるAI Hub(GCP)を利用 学習済モデルやNotebookがPrivateに共有可能 28
AI Hub 実体はuploadしたobjectの検索service Metadataを入力し共有したいobjectをupload tf.hubのself-hostingも可能だが 現状はCloud版であるAI Hubで必要十分 tensorflow/hub/issues/266 29
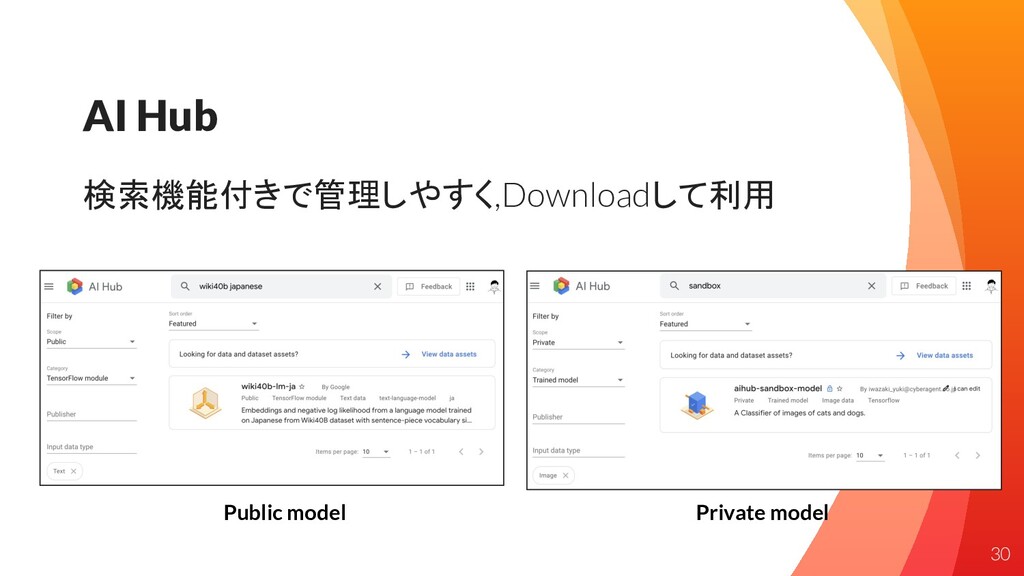
AI Hub 検索機能付きで管理しやすく,Downloadして利用 30 Public model Private model
3. 実験管理
課題: 実験管理 Teamや個人で実験管理がしたい Free: MLflow, Keepsake, TensorBoard SaaS: Neptune.ai, Comet.ml,
Wandb MLflowはServer構築が面倒 SaaS系は個人の無料枠を超えると高い 32
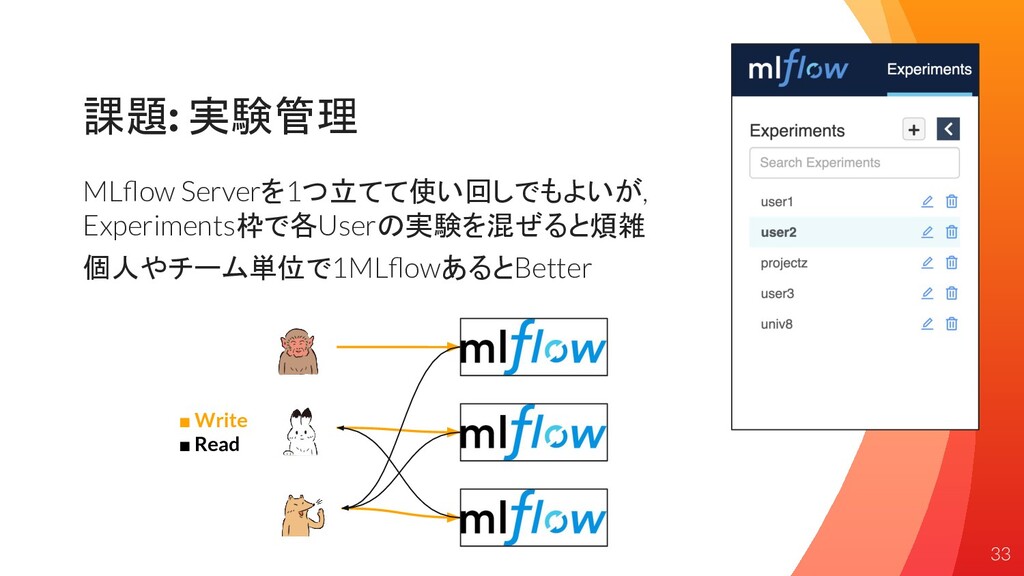
課題: 実験管理 MLflow Serverを1つ立てて使い回しでもよいが, Experiments枠で各Userの実験を混ぜると煩雑 個人やチーム単位で1MLflowあるとBetter 33 ▪ Write ▪
Read
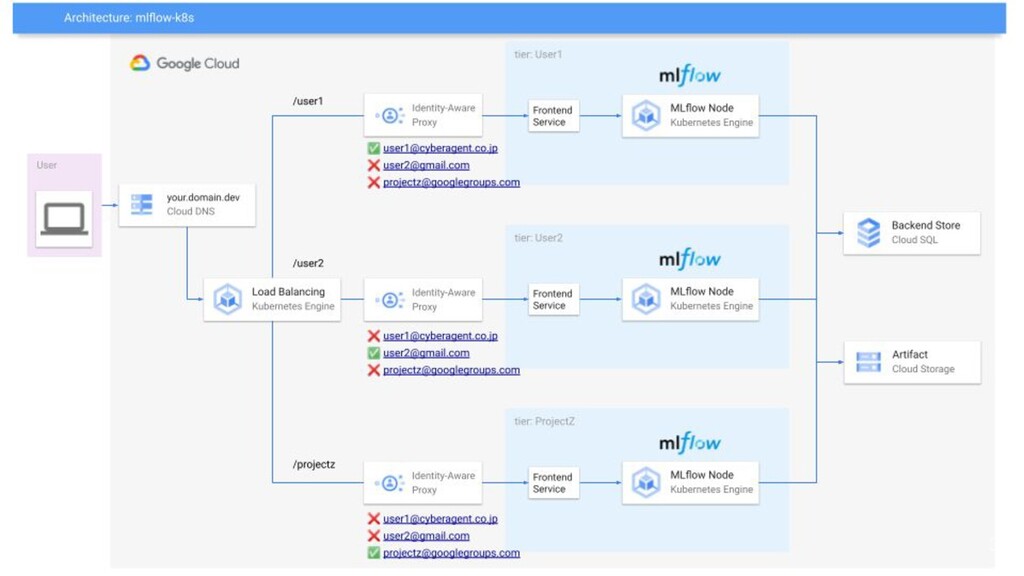
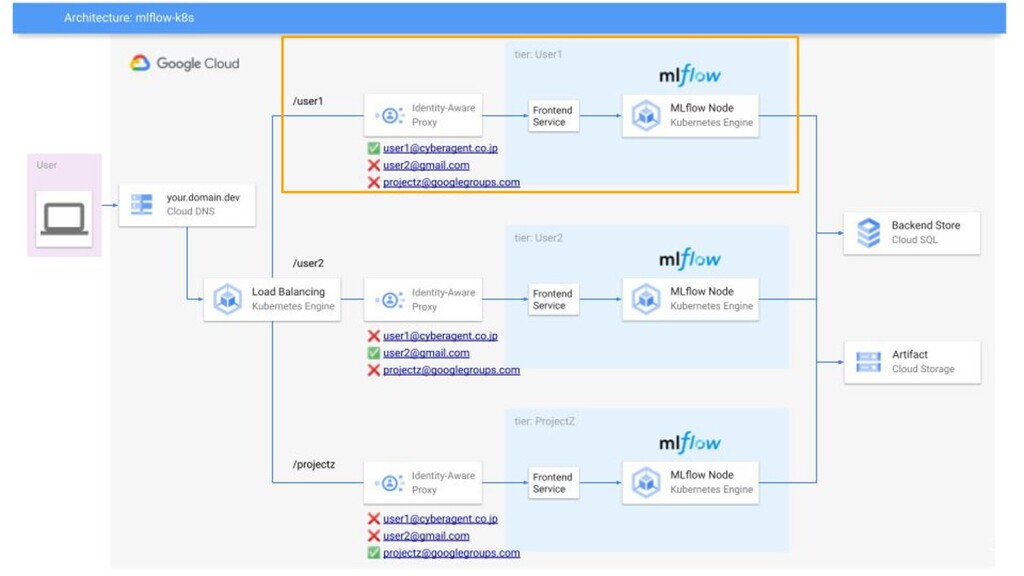
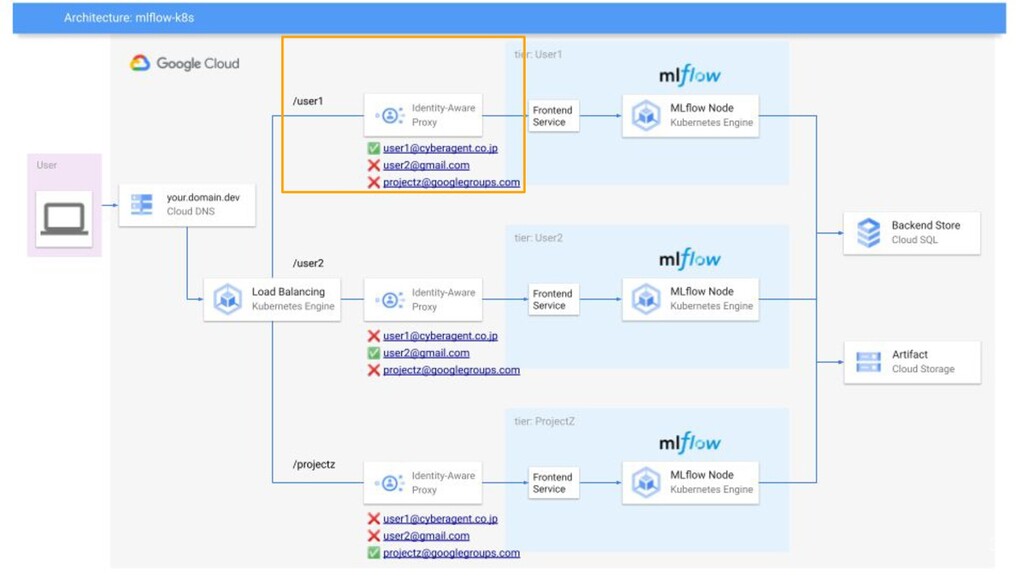
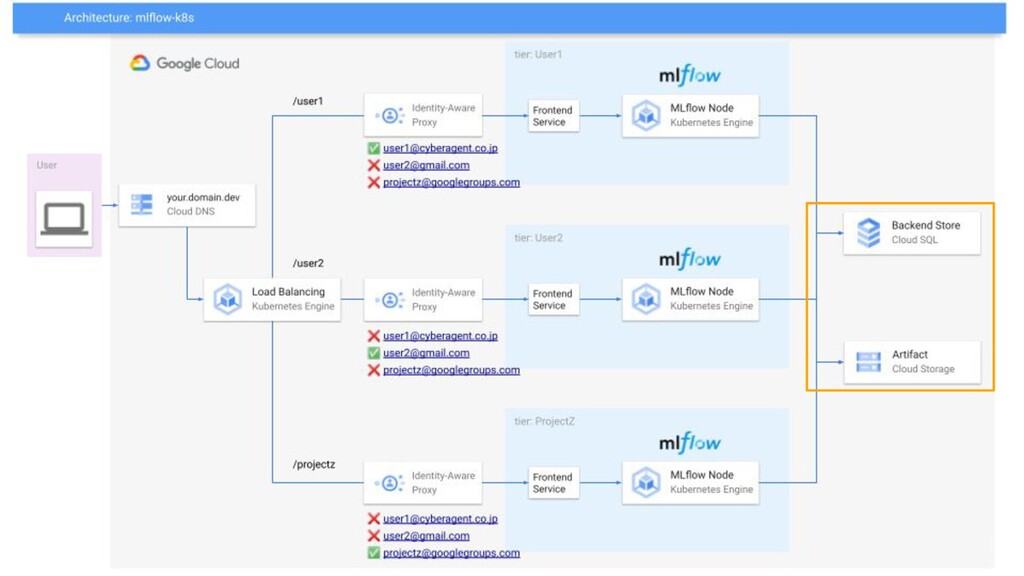
解決: MLflow Cluster • AI Lab共通のMLflow Clusterを構築 • 特徴 ◦
実験管理は各人独立したendpointを提供 ◦ OSSのMLflow Tracking ServerをLab PrivateでHosting ◦ GCP Resourceで各ユーザはCost/Server管理要らず ◦ Google Account Whitelistで共同研究先との利用にも 34
35
36
37
38
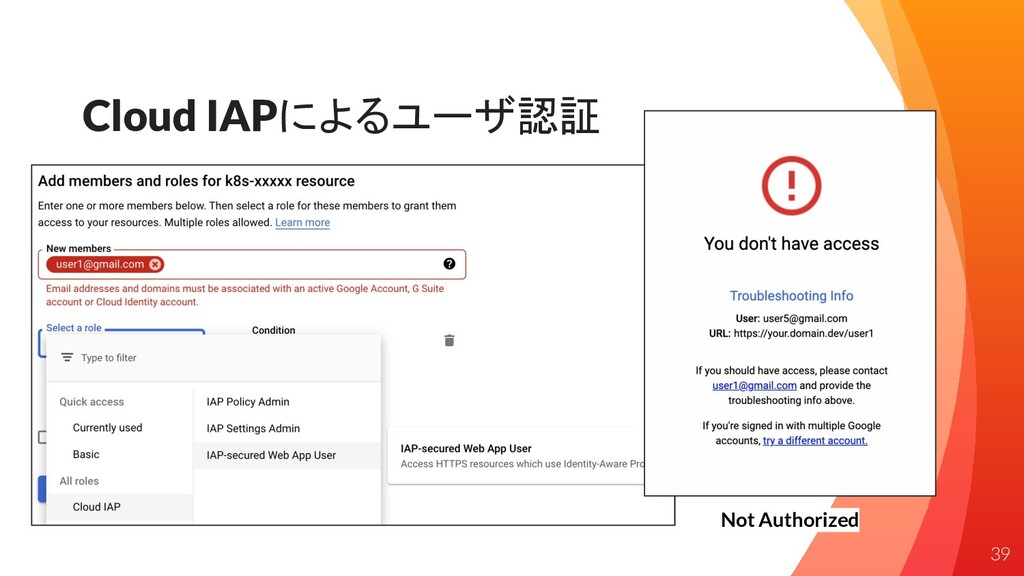
Cloud IAPによるユーザ認証 39 Not Authorized
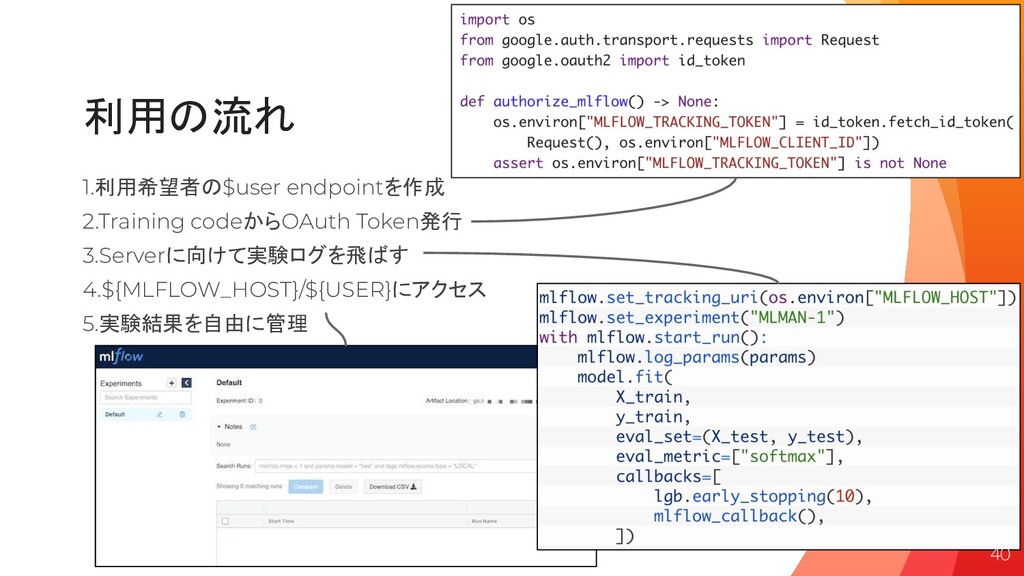
利用の流れ 1.利用希望者の$user endpointを作成 2.Training codeからOAuth Token発行 3.Serverに向けて実験ログを飛ばす 4.${MLFLOW_HOST}/${USER}にアクセス 5.実験結果を自由に管理 40
MLflow Cluster構築ハンズオン Blog公開したのでぜひ https://cyberagent.ai/blog/research/15272/ 41
Summary - 実験の流れ - Data (tensorflow-datasets) - -> Preprocess (tft,
tf.data, numpy, pandas) - -> Training (ai platform training) - -> Save model (AI Hub) - -> Report (MLflow) OSSを上手くwrapすることで メンテコストを抑えた実験サポート環境を実現 42
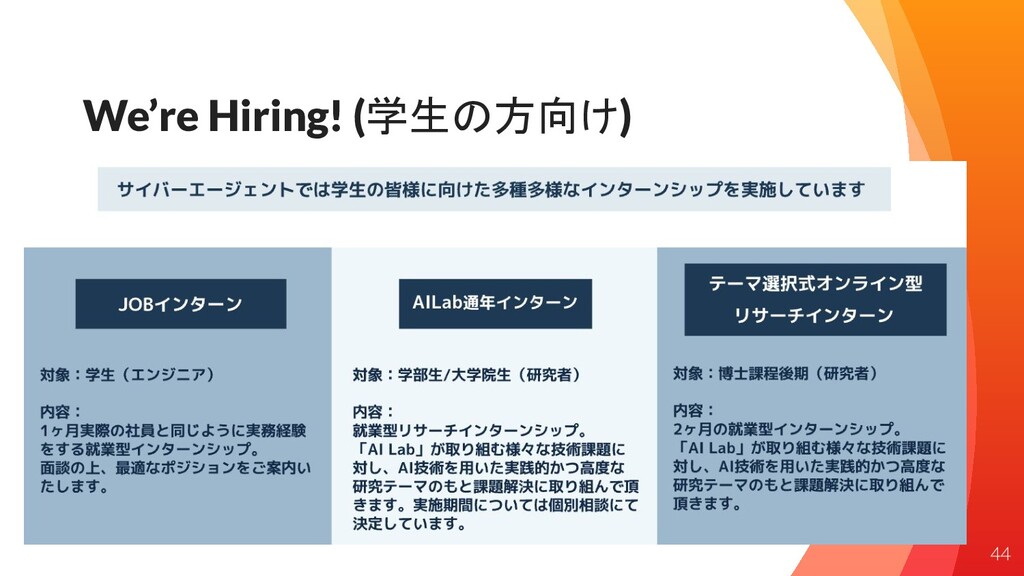
We’re Hiring! (学生の方向け) 44
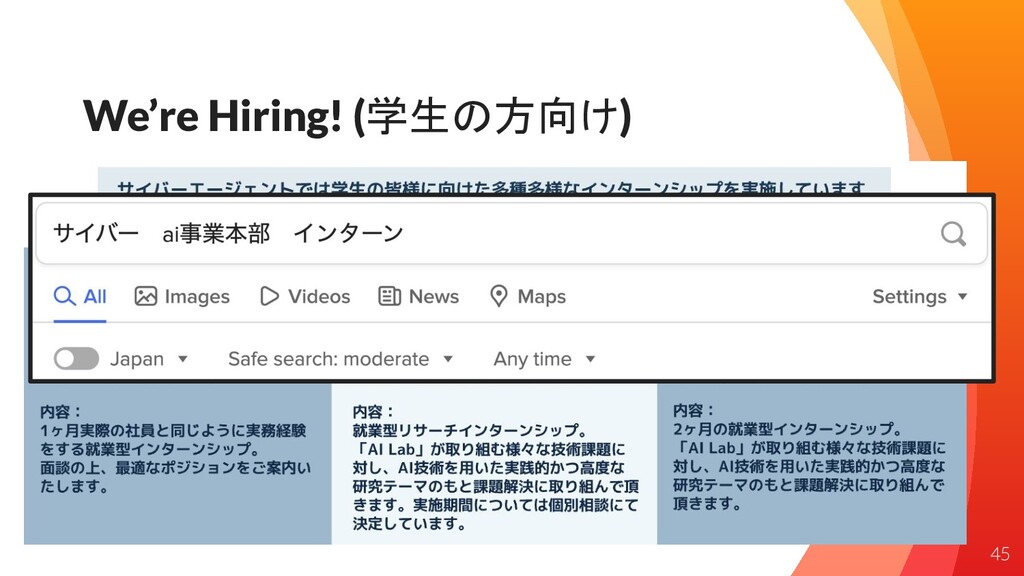
We’re Hiring! (学生の方向け) 45
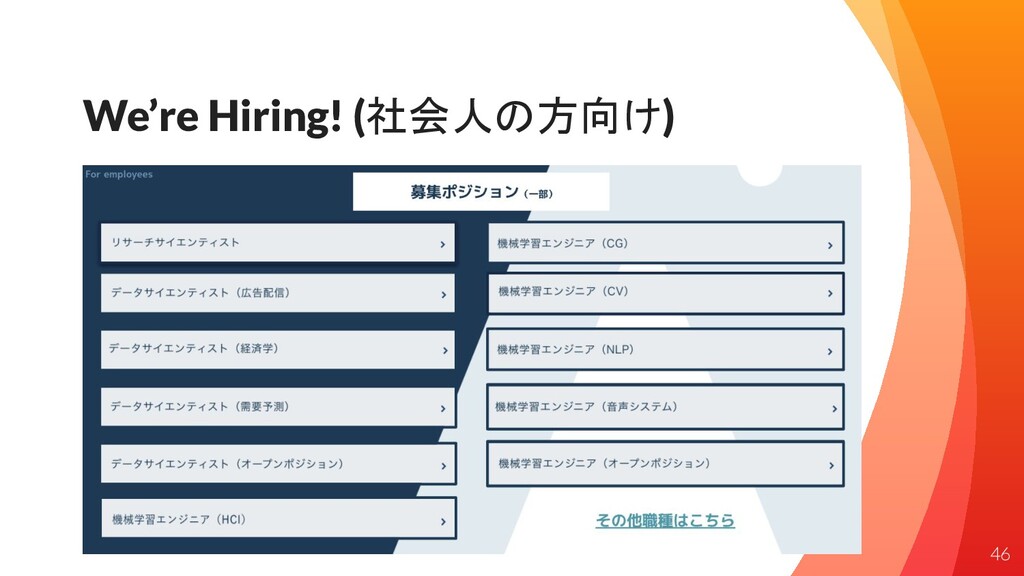
We’re Hiring! (社会人の方向け) 46
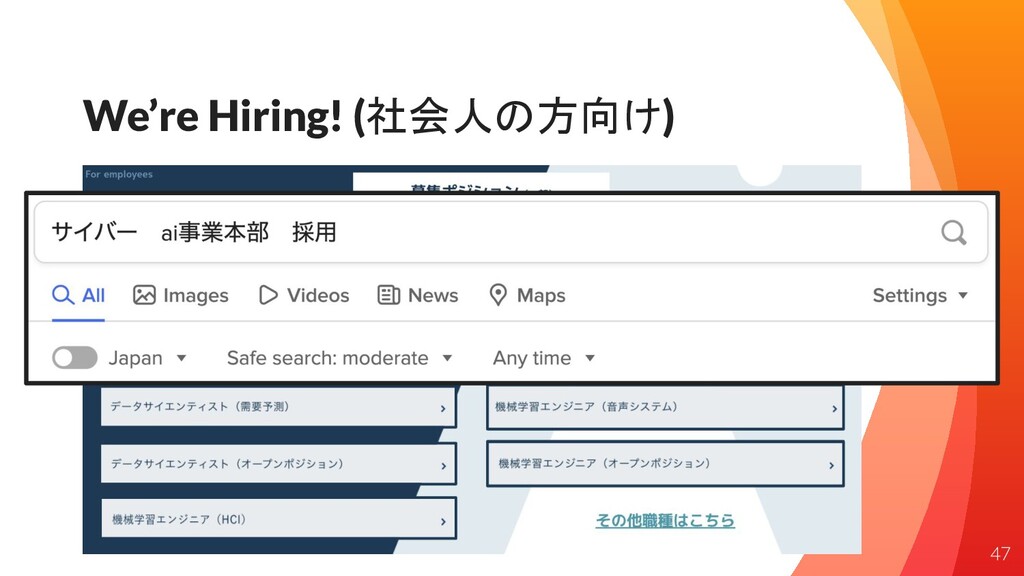
We’re Hiring! (社会人の方向け) 47
48 Thanks! Any questions? You can find me at: ◦
github.com/chck ◦
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}