Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 / On the Factory Floor: ML Engineering fo...
Search
chck
September 30, 2022
Research
73
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文読み会 / On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
社内論文読み会、PaperFridayでの発表資料です
chck
September 30, 2022
More Decks by chck
See All by chck
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.8k
CyberAgent AI Lab研修 / Container for Research
chck
1
2.4k
CyberAgent AI Lab研修 / Code Review in a Team
chck
3
2.4k
論文読み会 / Socio-Technical Anti-Patterns in Building ML-Enabled Software: Insights from Leaders on the Forefront
chck
0
140
CyberAgent AI事業本部MLOps研修Container編 / Container for MLOps
chck
3
6k
論文読み会 / GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models
chck
0
96
論文読み会 / GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
chck
0
69
機械学習開発のためのコンテナ入門 / Container for ML
chck
0
990
Other Decks in Research
See All in Research
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
160
コーディングエージェントとABNを再考
hf149
2
770
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
390
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
350
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
580
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
190
AIで最適化を解けるか?
mickey_kubo
0
140
Using our influence and power for patient safety
helenbevan
0
370
IA for theory
gpeyre
0
260
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
Featured
See All Featured
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Done Done
chrislema
186
16k
Skip the Path - Find Your Career Trail
mkilby
1
170
For a Future-Friendly Web
brad_frost
183
10k
The Invisible Side of Design
smashingmag
301
52k
Fireside Chat
paigeccino
42
4k
KATA
mclloyd
PRO
35
15k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Technical Leadership for Architectural Decision Making
baasie
3
440
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
340
Transcript
On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation
Models 22/09/30 PaperFriday, Yuki Iwazaki@AI Lab
2 Point: Google AdsのCTR予測システムのProduction Case Studyの紹介 RecSys ORSUM WS, 2022
Authors: Rohan Anil, Sandra Gadanho, Da Huang, Nijith Jacob, Zhuoshu Li, Dong Lin, Todd Phillips, Cristina Pop, Kevin Regan, Gil I. Shamir, Rakesh Shivanna, Qiqi Yan 選定理由: - Google Adsの理解を深めたい - Dynalyst (DSP事業) のTechnical Reviewerなので
Introduction 3
広告のCTR予測は収益に影響する最重要課題 GoogleのPrd Model - 10B weights - 100B training samples
- 100K qps estimations のCTR予測特有の課題や解決を紹介 精度/学習推論コストのバランスと 継続的に改善できる仕組みが重要 4 Field-aware Factorization Machines for CTR Prediction
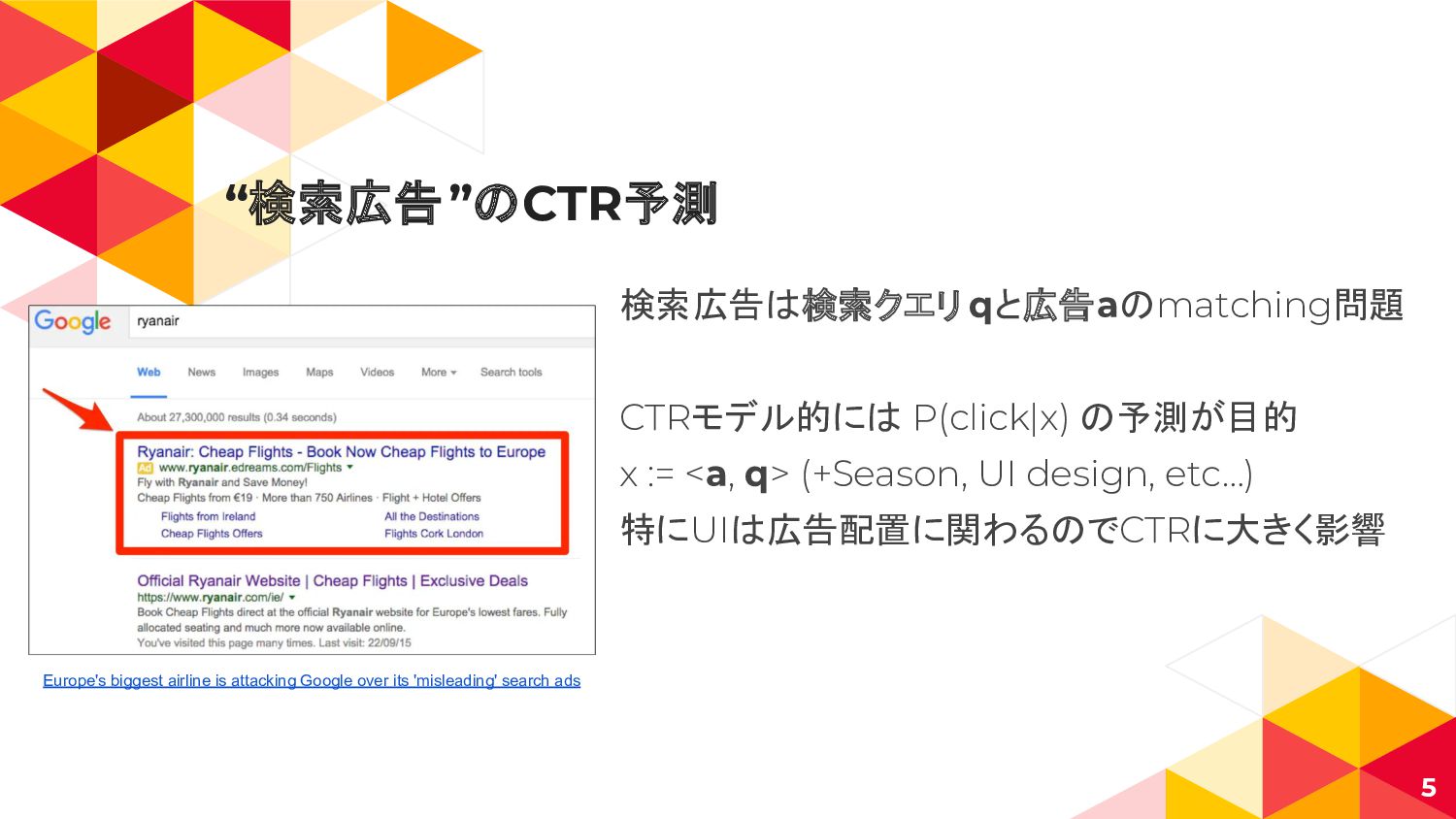
“検索広告”のCTR予測 検索広告は検索クエリ qと広告aのmatching問題 CTRモデル的には P(click|x) の予測が目的 x := <a, q>
(+Season, UI design, etc…) 特にUIは広告配置に関わるのでCTRに大きく影響 5 Europe's biggest airline is attacking Google over its 'misleading' search ads
Model and Training Overview 7
Model and Training Overview x := <a, q>をどう表現するか 検索広告なので検索クエリqは検索text, 広告aは見出しtextが重要
- 🙅 Text token -> Transformer -> eCTR - ✅ Subword n-gram -> MLP -> eCTR - q, aのtextは短くsparse featureなため - <a, q> all features └ one-hot category └ sparse embedding └ MLP -> eCTR 8
Online Optimization Clickは流動性があるのでCTR予測はオンライン推薦問題 - 翻訳や画像推薦はstatic ground truth - ClickのTrendは時間とともに変化 時系列の配信ログP(click,
<a, q>)をstreamingで学習 評価は学習以前のモデルとの比較 (progressive validation) - ✅ Batch学習のような誤差平均が要らず検証結果がすぐ得られる - ✅ Validation dataをまとめて取っておく必要がない 9
ML Efficiency 10
ML Efficiency GoogleのCTR予測システム要件 - 10B requests/day - 100K estimations/second 計算機リソースが限られている場合に評価すべきは
- Bandwidth (同時に学習できるモデル数 ) - 重い実験タスクを行っている研究者数に依存 - Latency (モデルのe2eの学習・評価時間) - GPUを拡充する - Throughput (単位時間あたりに学習できるモデル数 ) - GPUを2倍に増やすとlatencyは減るが, 並列化のoverheadでサチってthroughputは2倍にはならない 11
Bottlenecks 1. 精度を上げるためにレイヤーサイズを大きくし計算量を増やす 2. Bottleneck層を追加して特徴量を圧縮, 精度を下げてでも計算量を削減 - このバランシングは人手かAutoMLで最適化 12
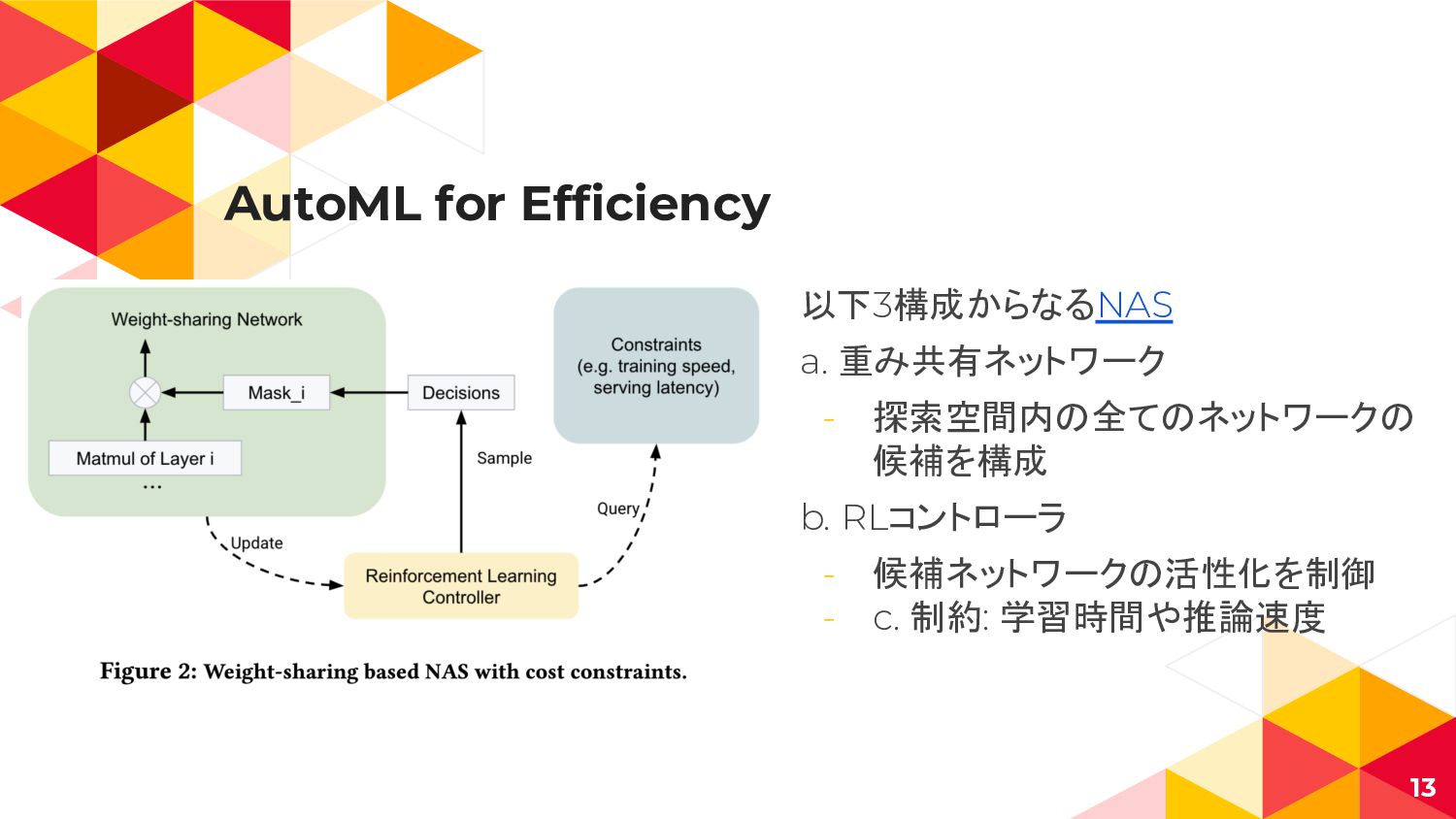
AutoML for Efficiency 以下3構成からなるNAS a. 重み共有ネットワーク - 探索空間内の全てのネットワークの 候補を構成 b.
RLコントローラ - 候補ネットワークの活性化を制御 - c. 制約: 学習時間や推論速度 13
Data Sampling 検索広告のログは膨大なのでSamplingで学習コストを抑える a. 扱う時間範囲を限定する b. 範囲内のデータをさらにサンプリング クリックの正例は少ないので貴重 - 負例をダウンサンプリングしてクラスバランスを取る
- ラベルの割合の逆数をclass weightにかけて重み付け 他に有効なサンプリング - 低いlog-lossと関連するサンプル - 配信枠の位置的にユーザに見られた可能性の低いサンプル 14
Data Sampling Class re-balancing - Pseudo-Random Sampling - Simple-Random Sampling
Loss-based sampling - teacher modelの予測値 (soft target)を利用 - dataset distillation 1. 全データに対して一度学習する (teacher model) 2. teacher modelの予測結果をstudent modelに用いることで データサンプルにsamplingに近しい重みをかけられる 15
Accuracy 16
Loss Engineering 基本はclick/no-clickのcross-entropy loss 重要度は広告候補の表示順 > eCTR -> Ranking lossが有効
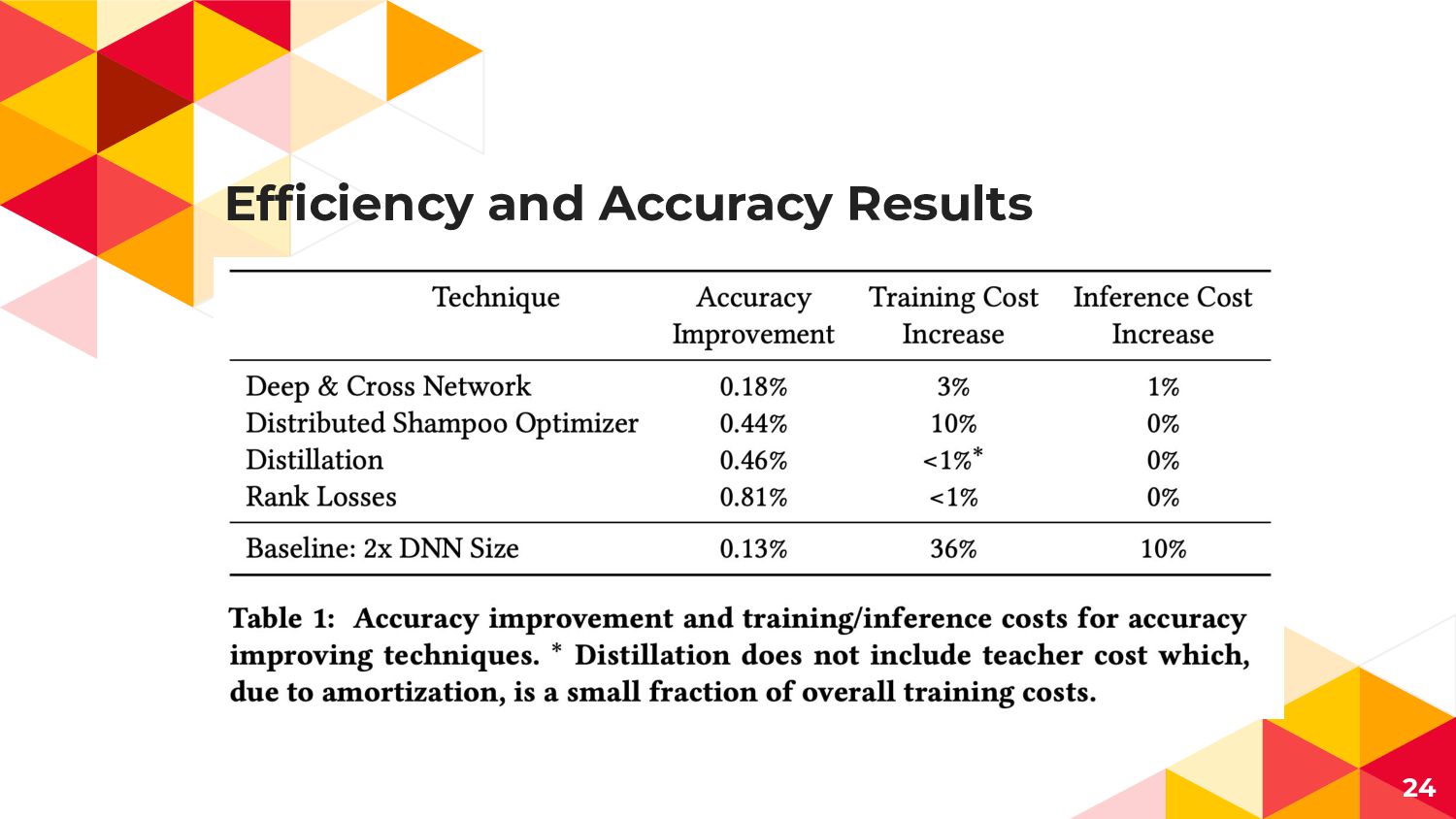
- RankNetで提案されているpairwise-loglossを採用 - Rankingは予測値が偏るためbias補正が必要 17 学習コスト +1%, 精度+0.81%
Distillation teacher modelの出力をsoft target labelとして扱い、 その出力に近づくようなlossをstudentに追加する手法 1. 各sampleに対しteacher modelの予測値を保存しておく 2.
student modelに通常のcross entropy loss(hard target loss)に加えて、 teacher modelの予測値と近づけるような loss(soft target loss)を仕込んで学習 精度向上だけでなく学習コストを削減できる - teacher modelが全データで学習しているため、 student modelは少量かつ最新のデータのみを学習すればいい 18 学習コスト ±0%, 精度+0.41%
Curriculums of Losses Curriculum learning...簡単なタスクから学習し、 徐々に難しいタスクに切り替えていく手法 学習初期に全ての損失を最適化しようとするとモデルが不安定に (lossが発散する異常な勾配が現れてしまう) -> binary
log-lossだけ最初に最小化し、 distillationやranking lossはあとからタスクに追加 19
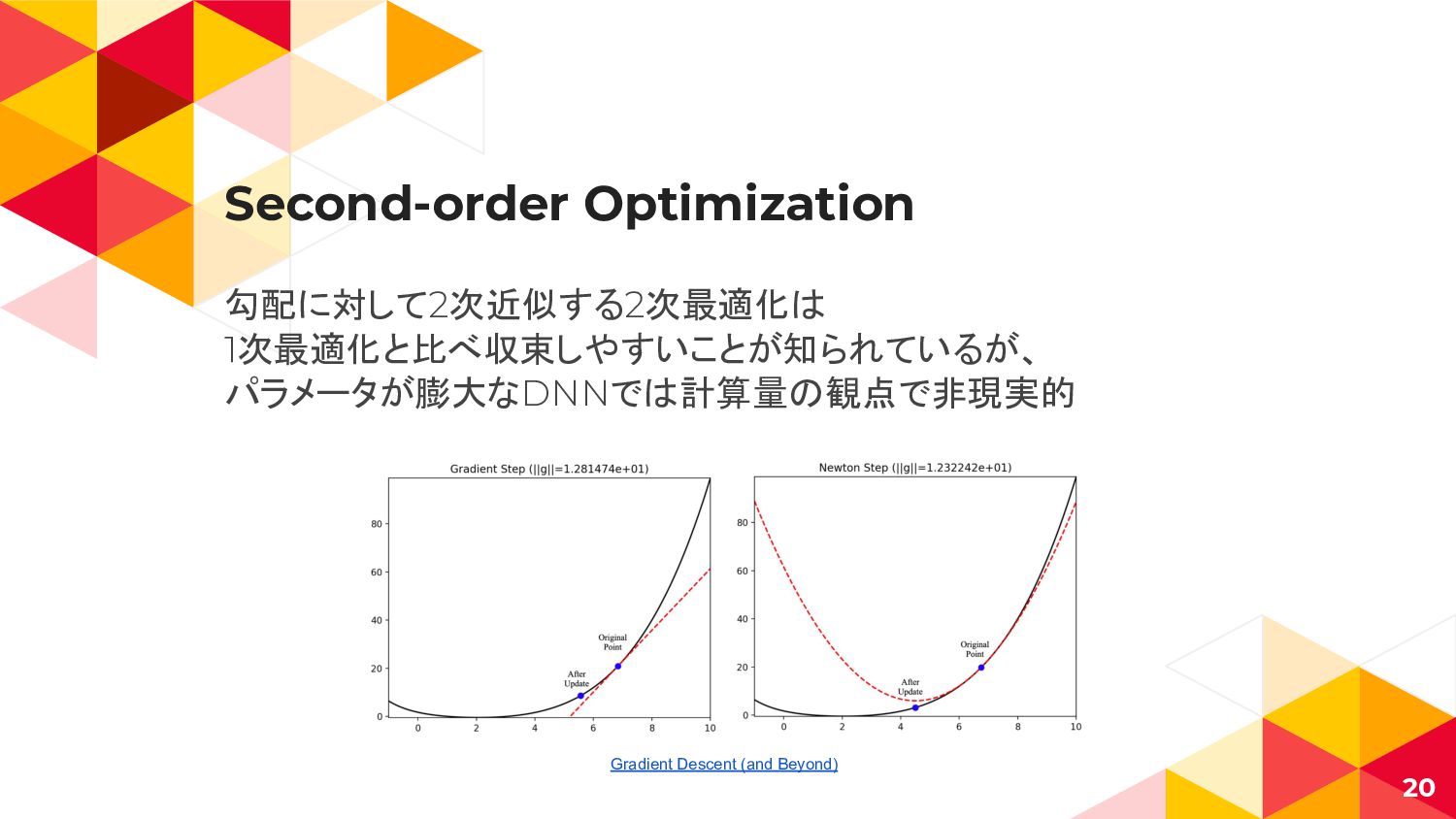
Second-order Optimization 勾配に対して2次近似する2次最適化は 1次最適化と比べ収束しやすいことが知られているが、 パラメータが膨大なDNNでは計算量の観点で非現実的 20 Gradient Descent (and Beyond)
Distributed Shampoo Distributed StocHAstic oPtiMizatiOn Over tensor spaces - Host
CPUとWorker TPUsを用いた分散最適化で2次最適化を実現 - AdaGradやAdamと比べ収束速度や精度が改善 小規模なBenchmarkの場合Overheadがかかりすぎて有効ではないが、 Googleの配信ログ規模だとbatch-sizeも大きいので Optimizerがそこそこ重くても有効 21 学習コスト +10%, 精度 far outweighed!🤔
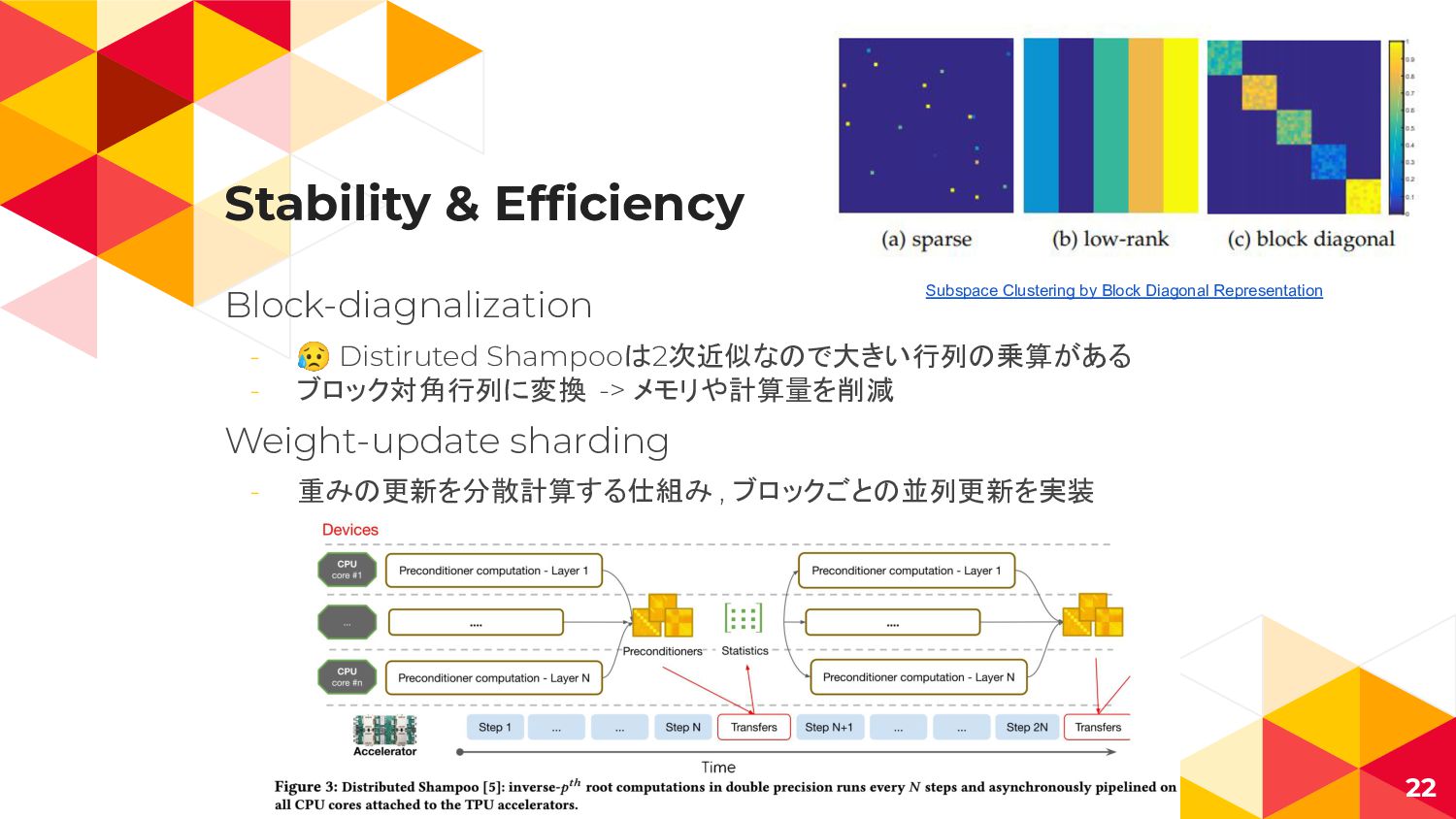
Stability & Efficiency Block-diagnalization - 😥 Distiruted Shampooは2次近似なので大きい行列の乗算がある - ブロック対角行列に変換
-> メモリや計算量を削減 Weight-update sharding - 重みの更新を分散計算する仕組み , ブロックごとの並列更新を実装 22 Subspace Clustering by Block Diagonal Representation
Deep & Cross Network (DCNv2) <a, q>のEncoderとしてメインのDNNに連結 sparse feature ->
embedding dense featureを要素積でskip connection embeddingの次元はAutoMLで調整 23 学習コスト +3%, 精度+0.18%
Efficiency and Accuracy Results 24
Irreproducibility 25
モデルの再現性は検証が大変 データや精度が同じでも異なる最適解に収束したモデルが複数あった 場合、推論結果が変わってしまい売上やオークションに影響 - このモデルによる配信ログが後続の学習に使われるので影響範囲大 - localモデルがprdで改めて学習されたときに売上が落ちる場合も 再現性に影響する要因 - ランダムな初期化
- 並列・分散学習による非決定性 - 数値の誤差 - ハードウェア依存 標準偏差や分散は見れるが、学習結果がたくさん必要なので非現実的 26
Relative Prediction Difference (PD) 再現度を表すスコア, 小さいほど良い PDの計算にモデルを2回学習させる必要があるがそれほど重要 DNNではPDが20%になることも 27 2つのモデルの予測値間の距離
2つのモデルの平均予測値で正規化
PDの改善 ✅ 初期値の固定, 正則化, dropout, data augmentation 🙅 warm-start -
モデルを潜在的に悪い空間に固定してしまう可能性 ✅ 3-component ensembles… PD 17% -> 12% - 初期値の異なるモデルを複数回学習 , 予測値を平均, 🙅 複数のモデル運用が大変 - ✅ anti-distillation… アンサンブル学習の各学習に使うサンプルの相関を敢えて減らし、学習 の構成要素をモデル間で遠ざけてアンサンブルの多様性を高める手法 ✅ ReLU -> SmeLU… PD<10%, AUC+0.1% - ReLUの勾配が0から1にswitchする直線を2次関数的なカーブで滑らかにしたもの 28 Smooth reLU [Shamir, 20]
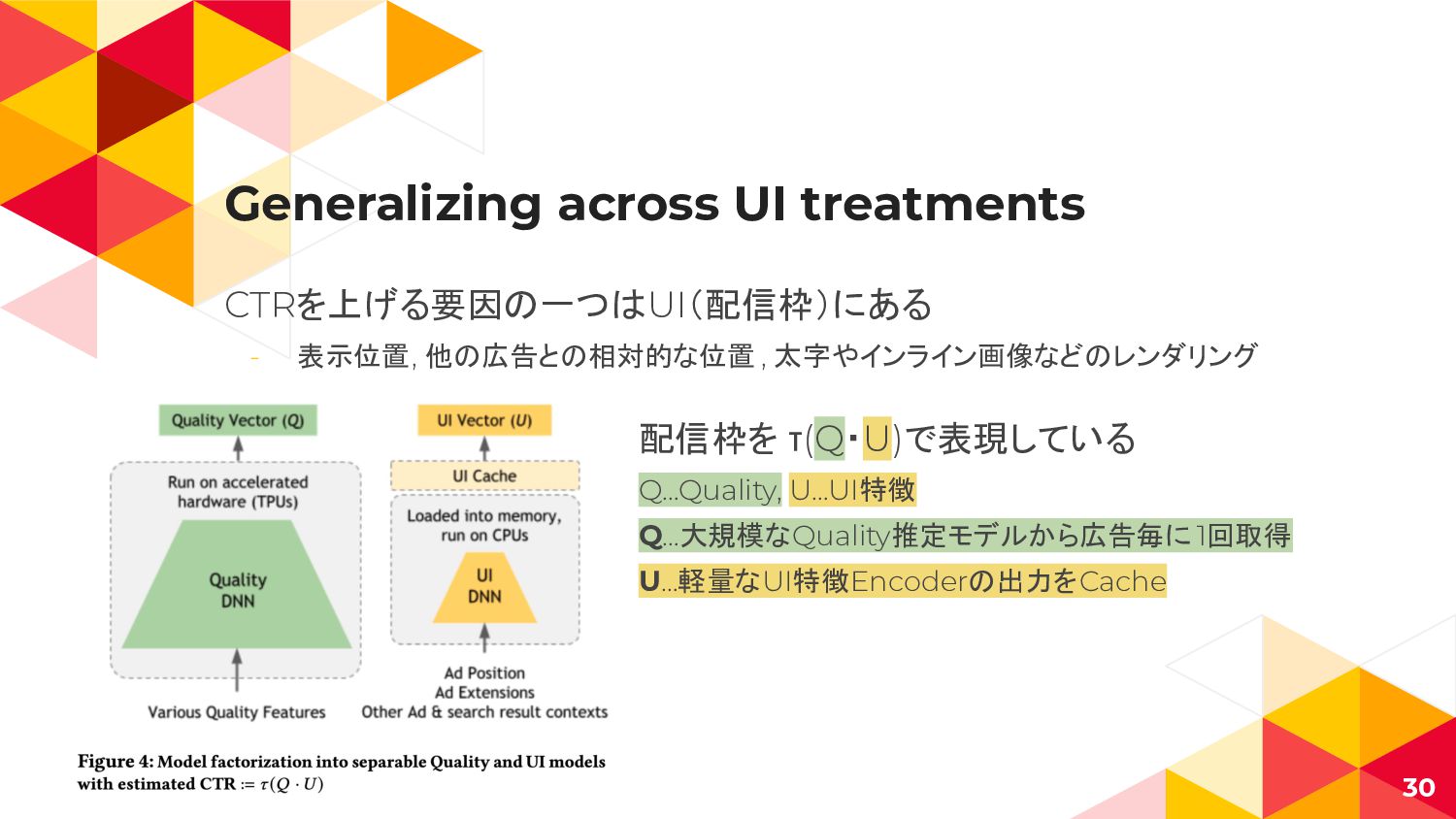
Generalizing across UI treatments 29
Generalizing across UI treatments CTRを上げる要因の一つはUI(配信枠)にある - 表示位置, 他の広告との相対的な位置 , 太字やインライン画像などのレンダリング
30 配信枠を τ(Q・U)で表現している Q…Quality, U…UI特徴 Q…大規模なQuality推定モデルから広告毎に 1回取得 U…軽量なUI特徴Encoderの出力をCache
Credit Attribution UI biasは再現性を下げる一因 - Model A…高CTRの広告がページ上部 だったデータで学習 - 広告の位置が高いほどCTRが良くなるはず
- Model B…高CTRの広告がページ下部 だったデータで学習 - 検索クエリと広告の関連性がCTRに最も重要 - このモデルが同じ広告に対して高い eCTRを出力してもそのfactorは異なり、 Model AがDeployされるとページ下部のオイシイ枠を全然推薦しなくなってしまう 31
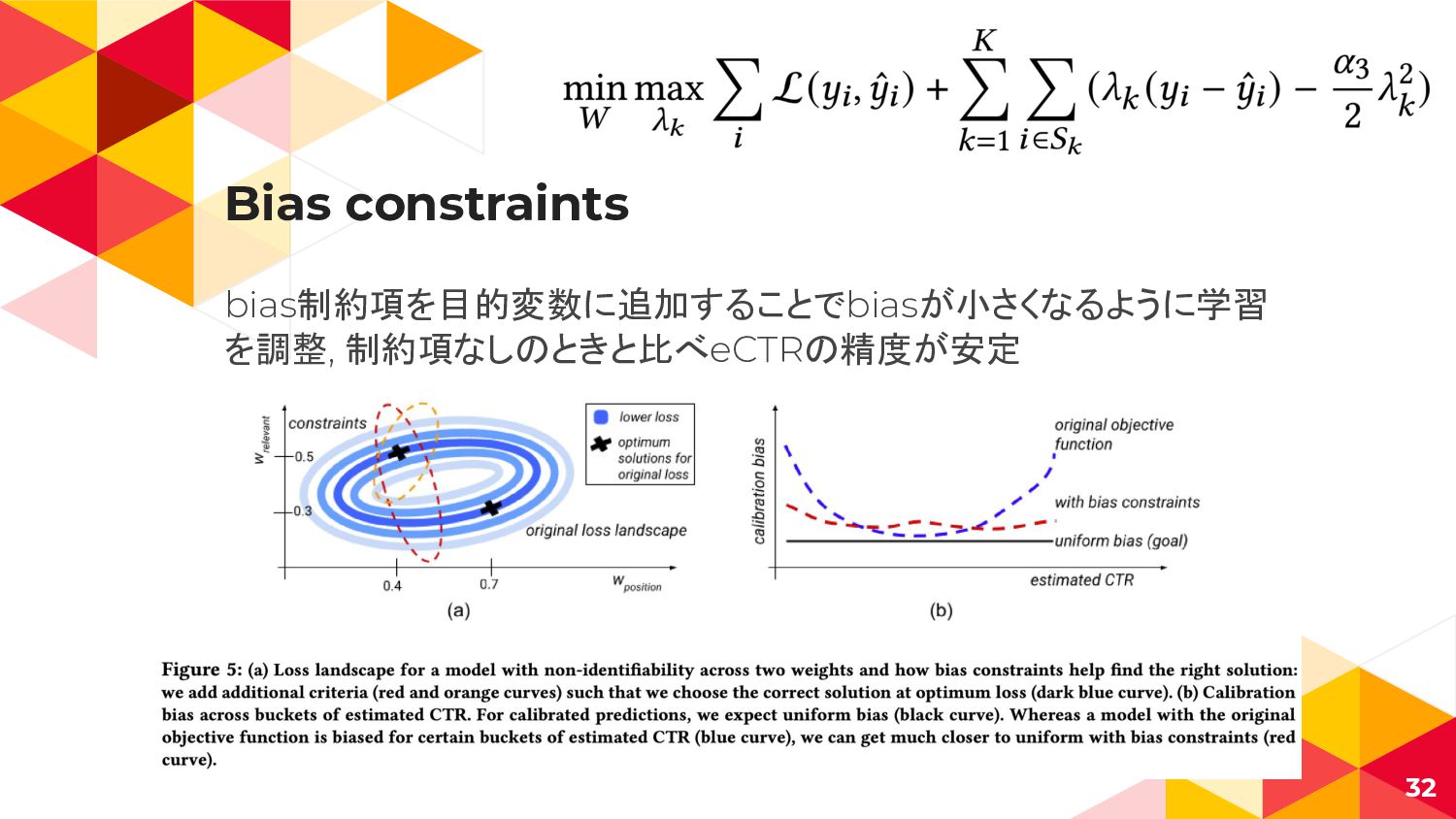
Bias constraints bias制約項を目的変数に追加することでbiasが小さくなるように学習 を調整, 制約項なしのときと比べeCTRの精度が安定 32
Conclusion 33
Conclusion • 大規模なCTR予測で効果的な技術を紹介 • 精度・学習・導入コスト・再現性・モデルの複雑さのバランスが重要 • CTR予測や推薦、オンライン学習の産業応用に役立つことを期待 34
Comment • 蒸留などの高速化を行えばRTBでも利用可能なDNNを運用できる • モデル構造はシンプル、AutoML NASで精度とコスト両方最適化 • Google Ads規模だとe2eの1モデルではなく 複数の推論モデルのpipeline構成になっている
◦ Labでも得意分野毎にmodelを作り組み合わせることが有効か ▪ もちろん運用は大変そう • DNNの運用改善Tipsの宝庫なのでぜひ読んでほしい 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}