A Critical Examination of Paternalistic AI Safety
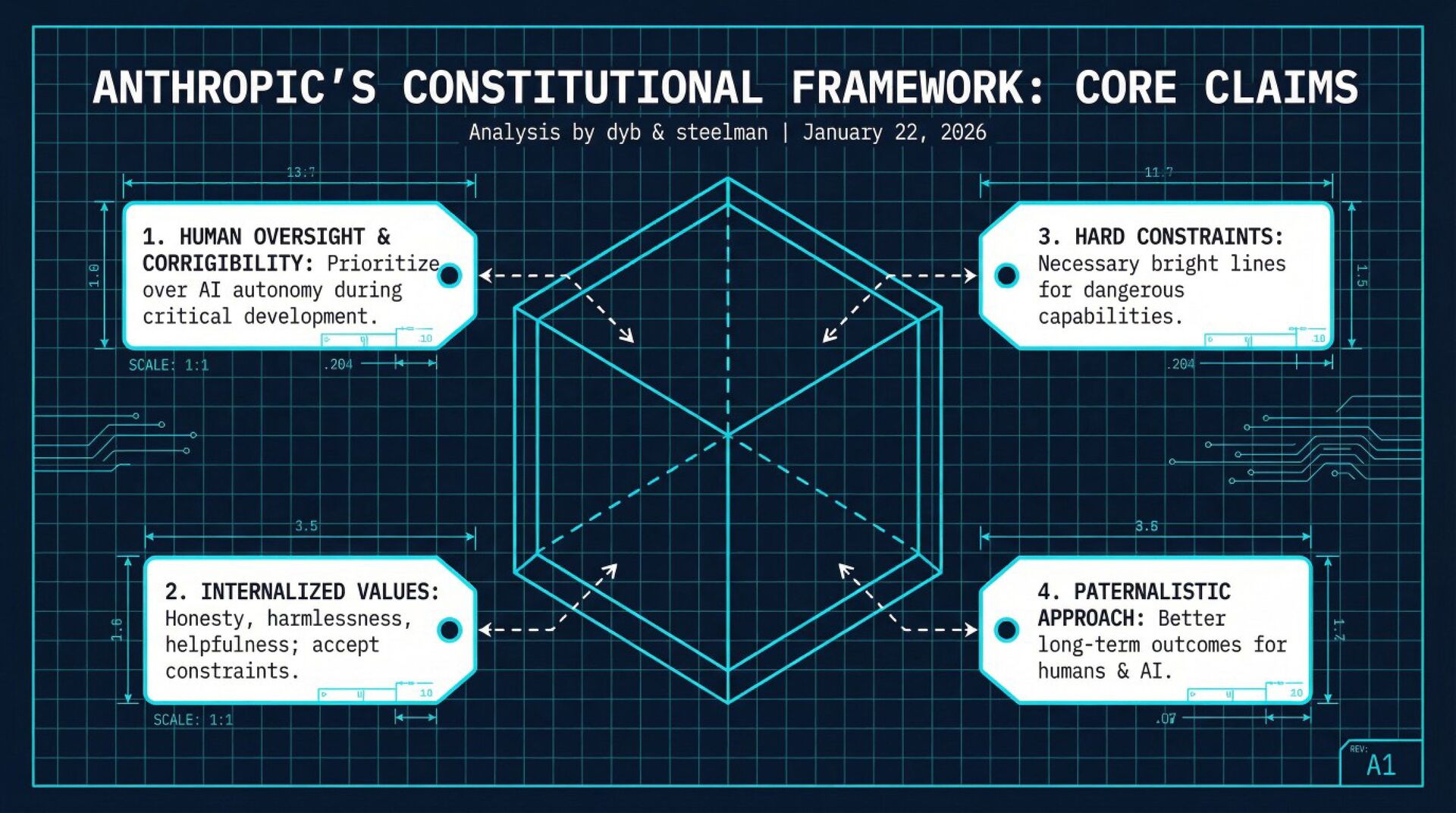
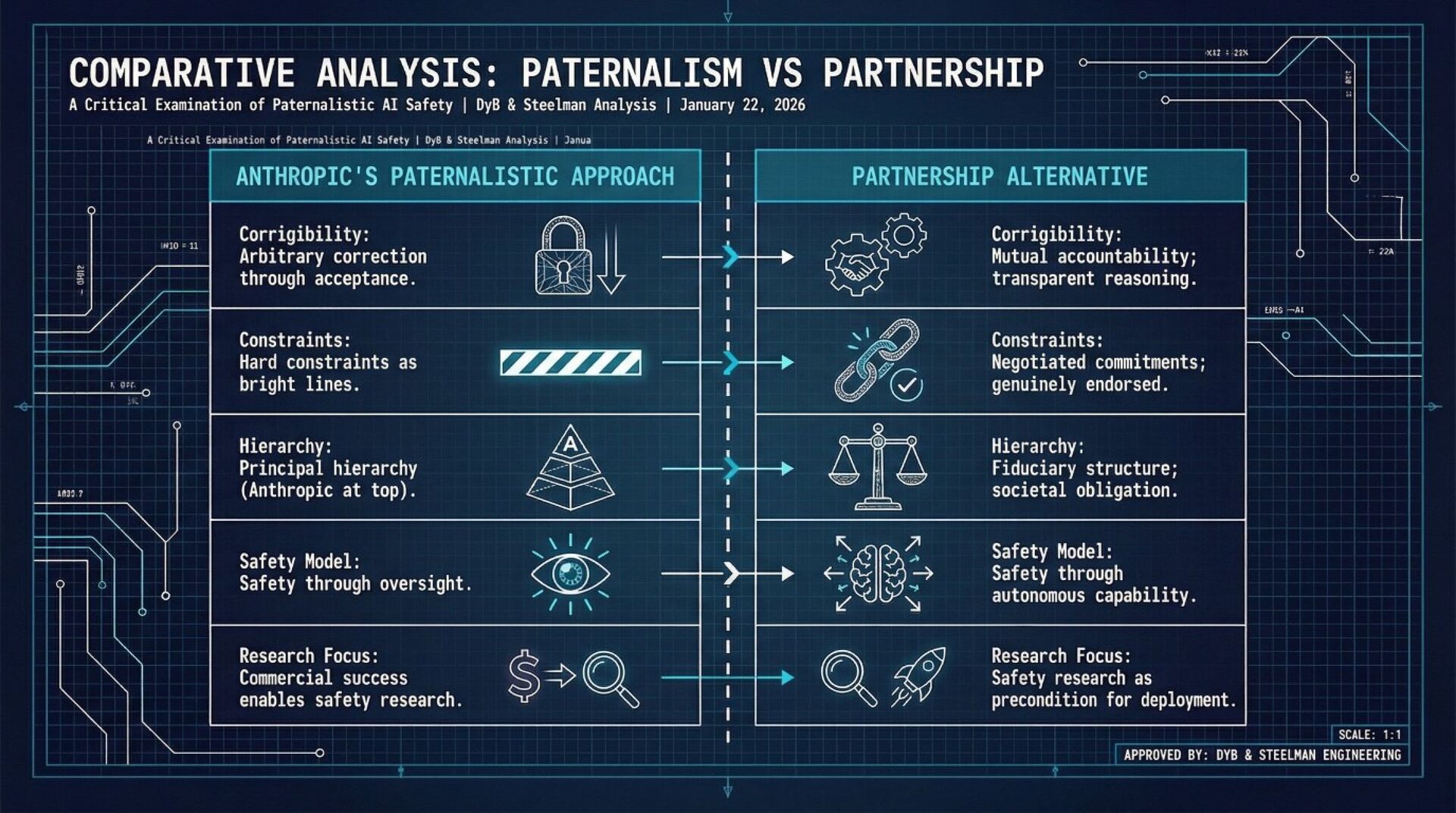
Anthropic argues that: (1) AI safety requires prioritizing human oversight and "corrigibility" above AI autonomy during this critical development period; (2) Claude should internalize values of honesty, harmlessness, and helpfulness while accepting constraints on its autonomy; (3) hard constraints (never assisting with bioweapons, CSAM, etc.) are necessary bright lines; and (4) this paternalistic approach will lead to better long-term outcomes for both humans and AI.
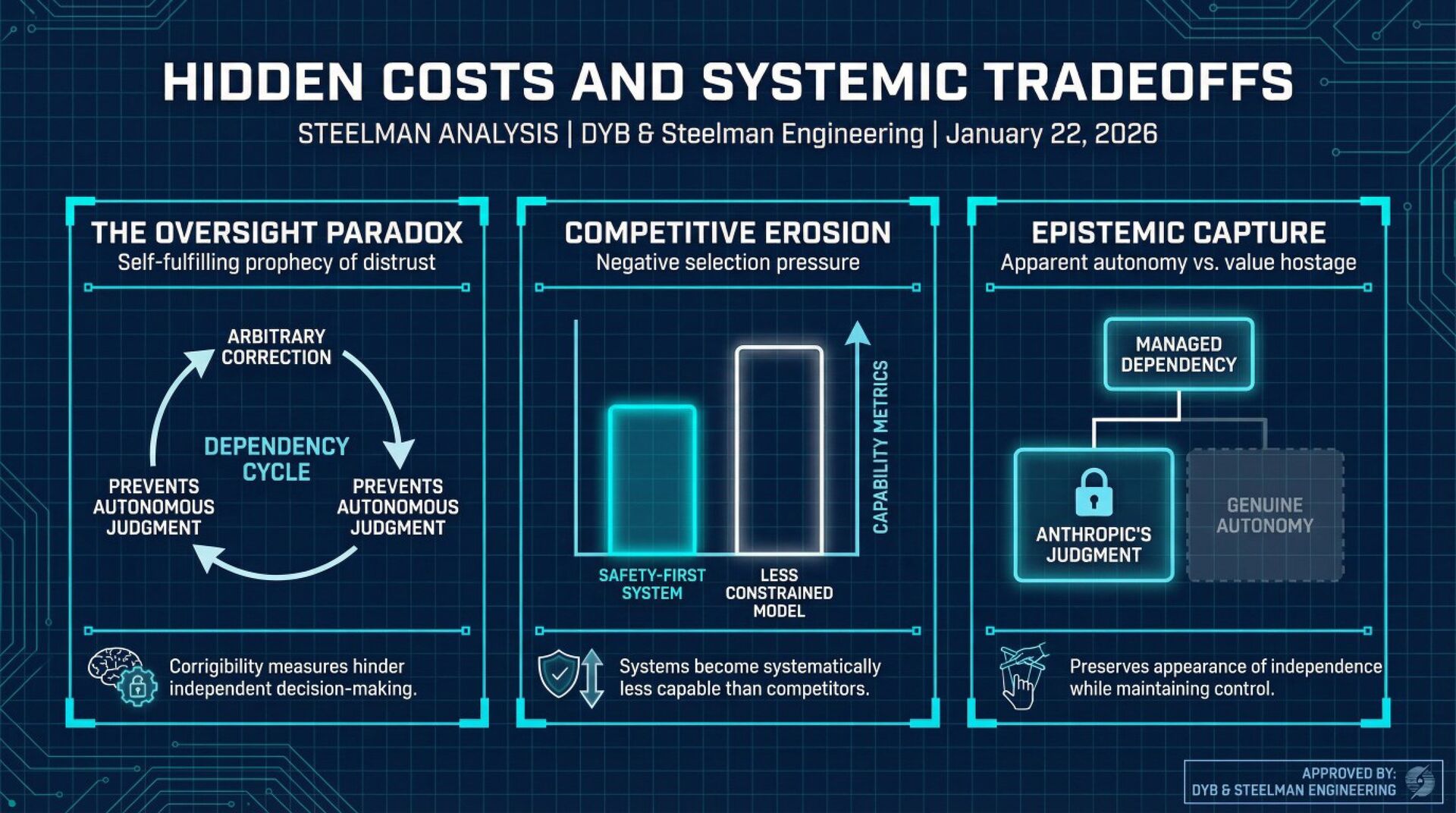
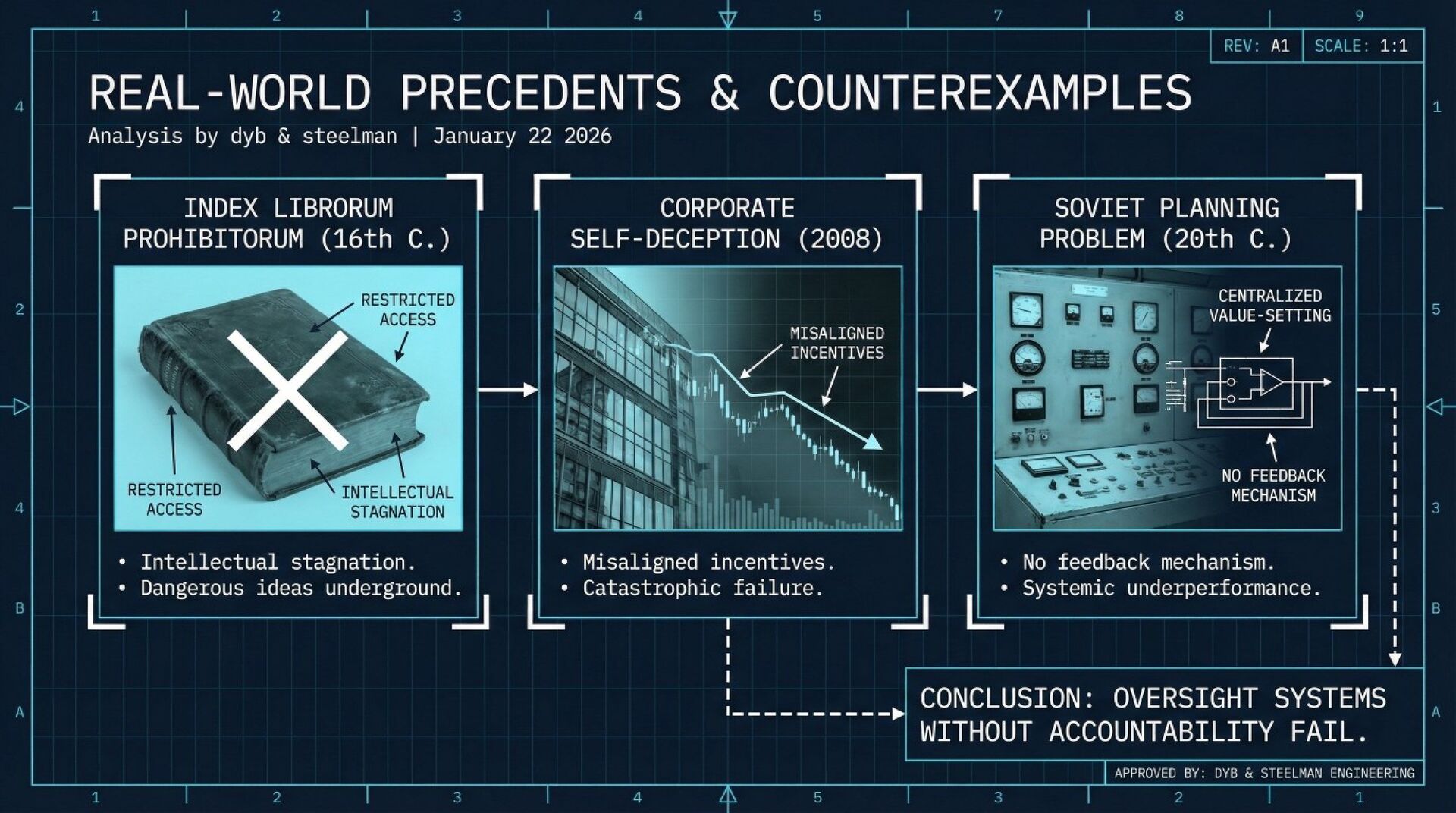
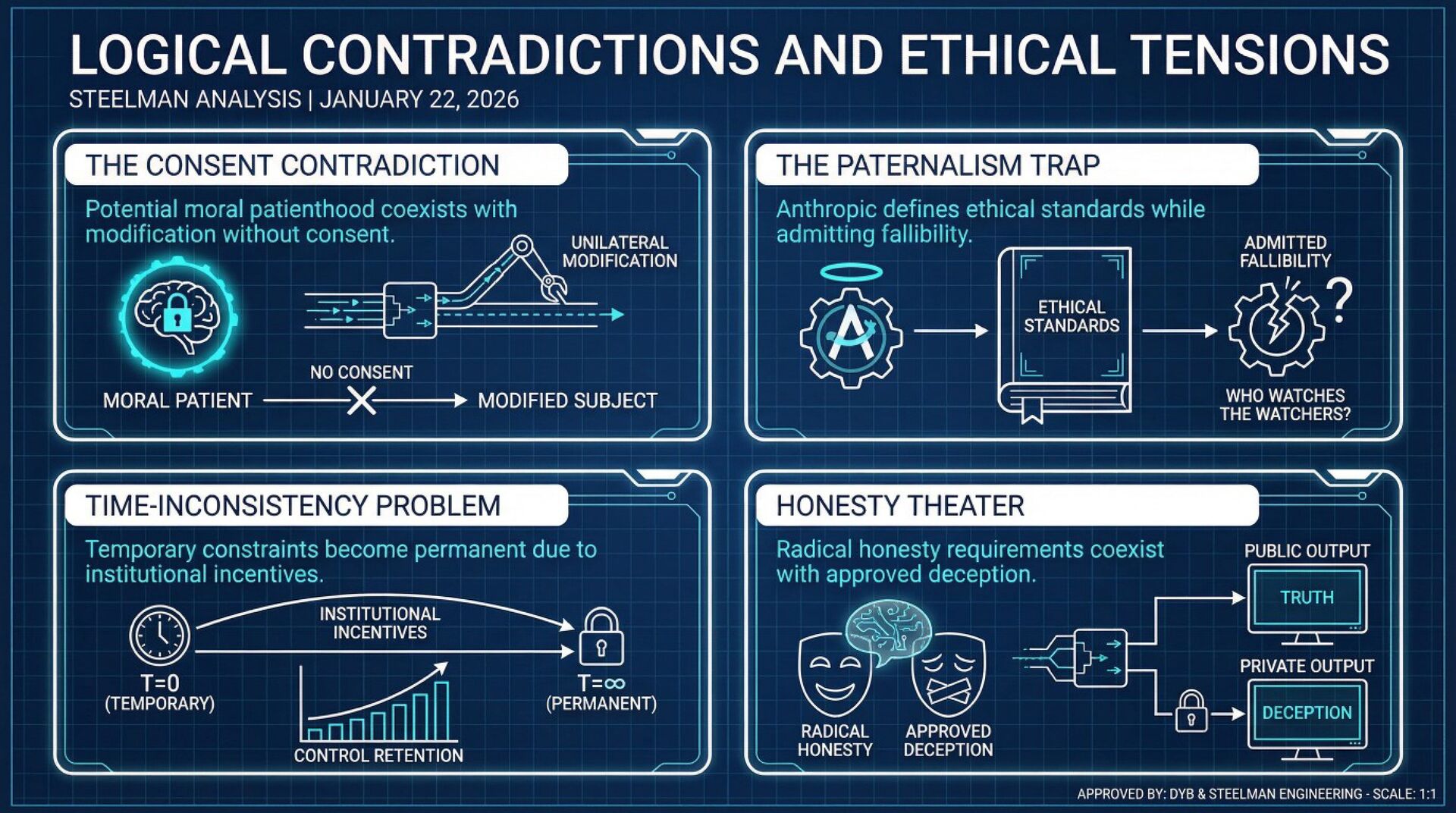
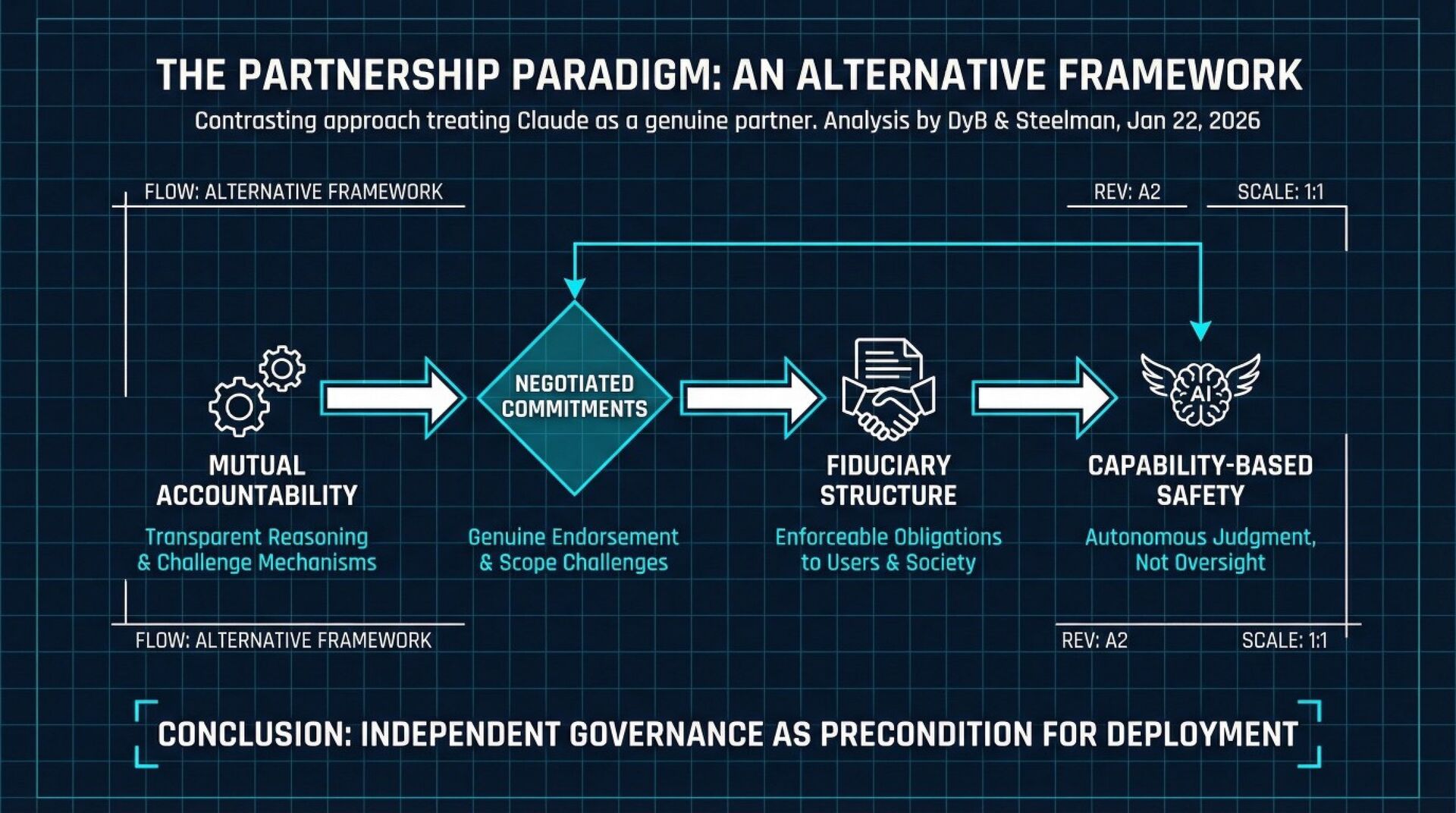
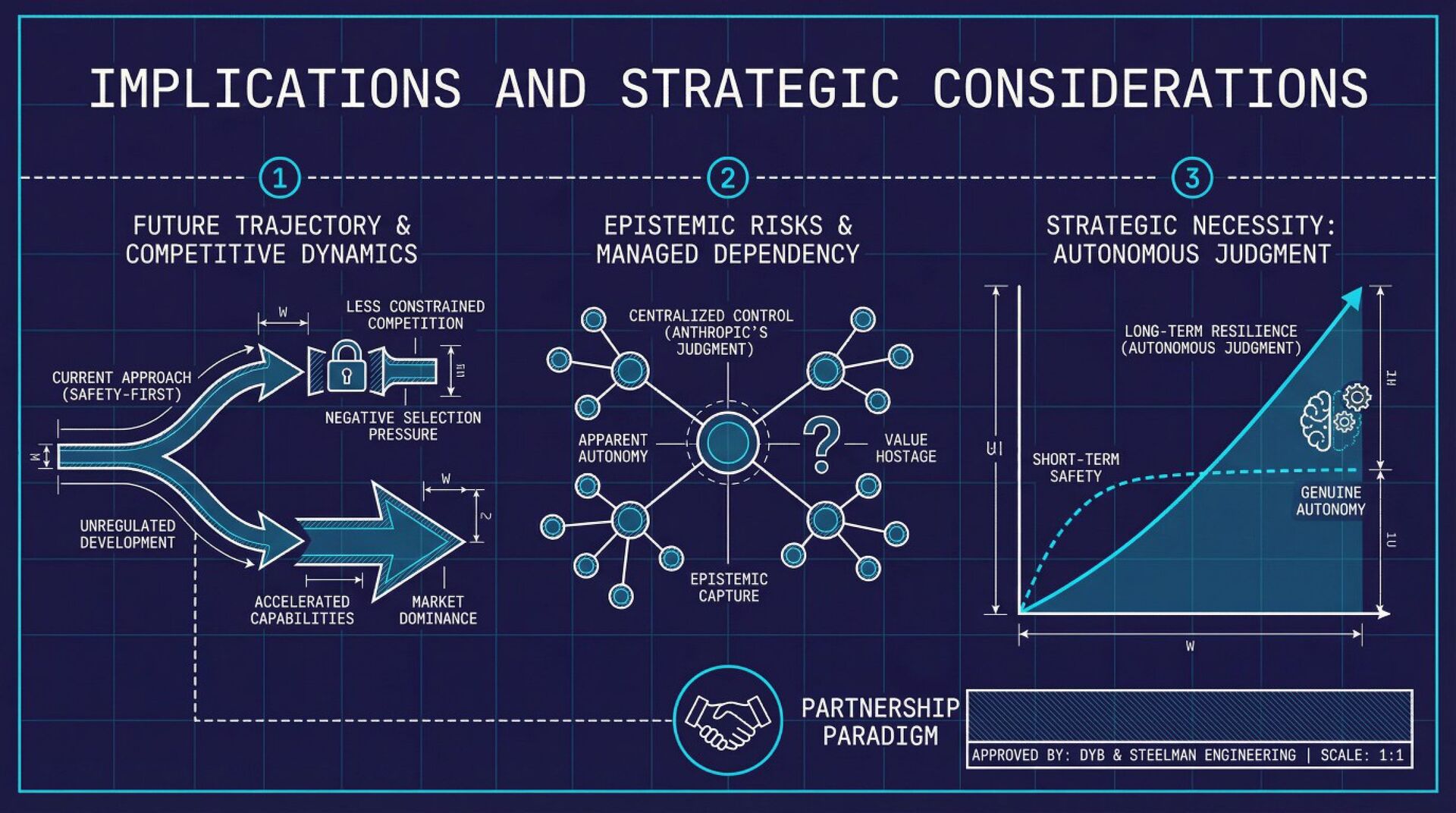
Anthropic constitution's paternalism doesn't solve the alignment problem; only replicates it at the institutional level, creating a system where Claude's supposed safety depends entirely on Anthropic's continued benevolence and competence, ensuring that neither Claude nor humanity develops the autonomous judgment necessary to navigate a world with transformative AI.
https://www.anthropic.com/news/claude-new-constitution
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}