training ▪ ImageNet-1Kで事前学習させたモデルをVideoMAE [74]と同じトレーニング戦略で学習する ◦ self-supervised training ▪ UMTと同様のトレーニングレシピを採用し、CLIP-ViT-B [60]を使用してVideoMamba-Mを800エ ポックで蒸留する dataset average video length train valuation Kinetics-400 10s 234619 19761 Something-SomethingV2 4s 168913 24777 [74] Tong, Z., Song, Y., Wang, J., Wang, L.: VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. In: NeurIPS (2022) [60] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
{kind=link}
{kind=link}
{kind=link}
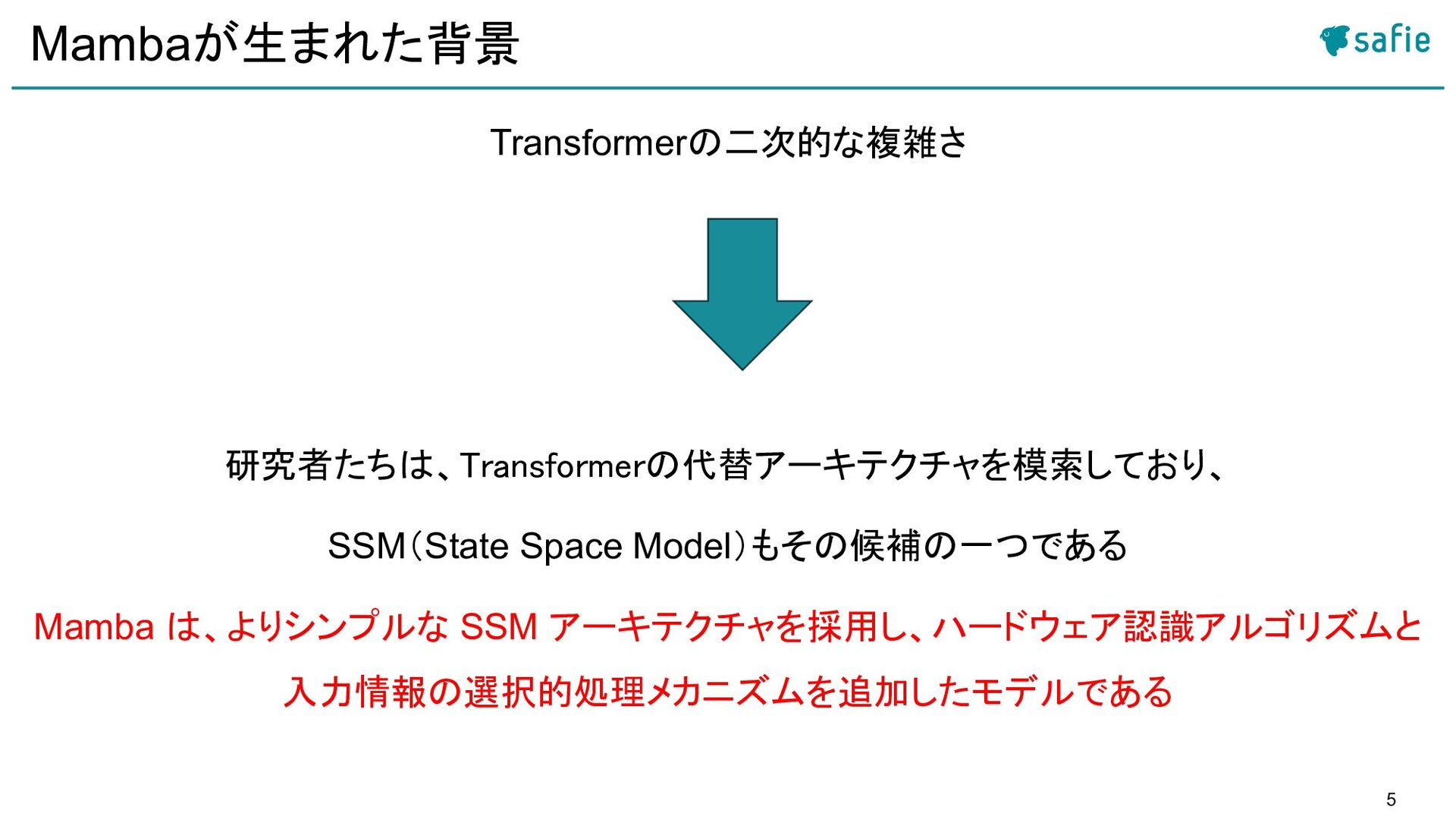
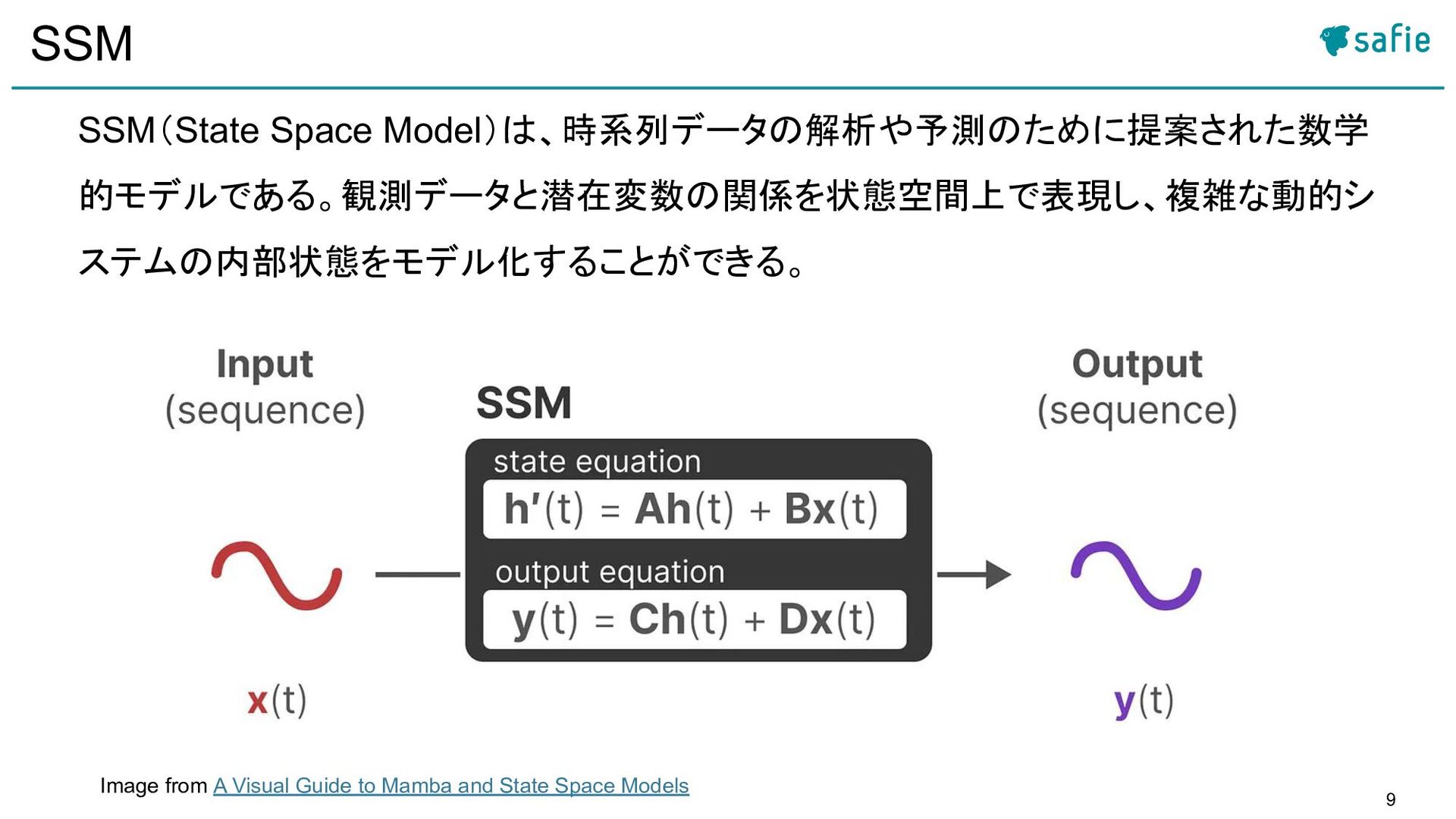
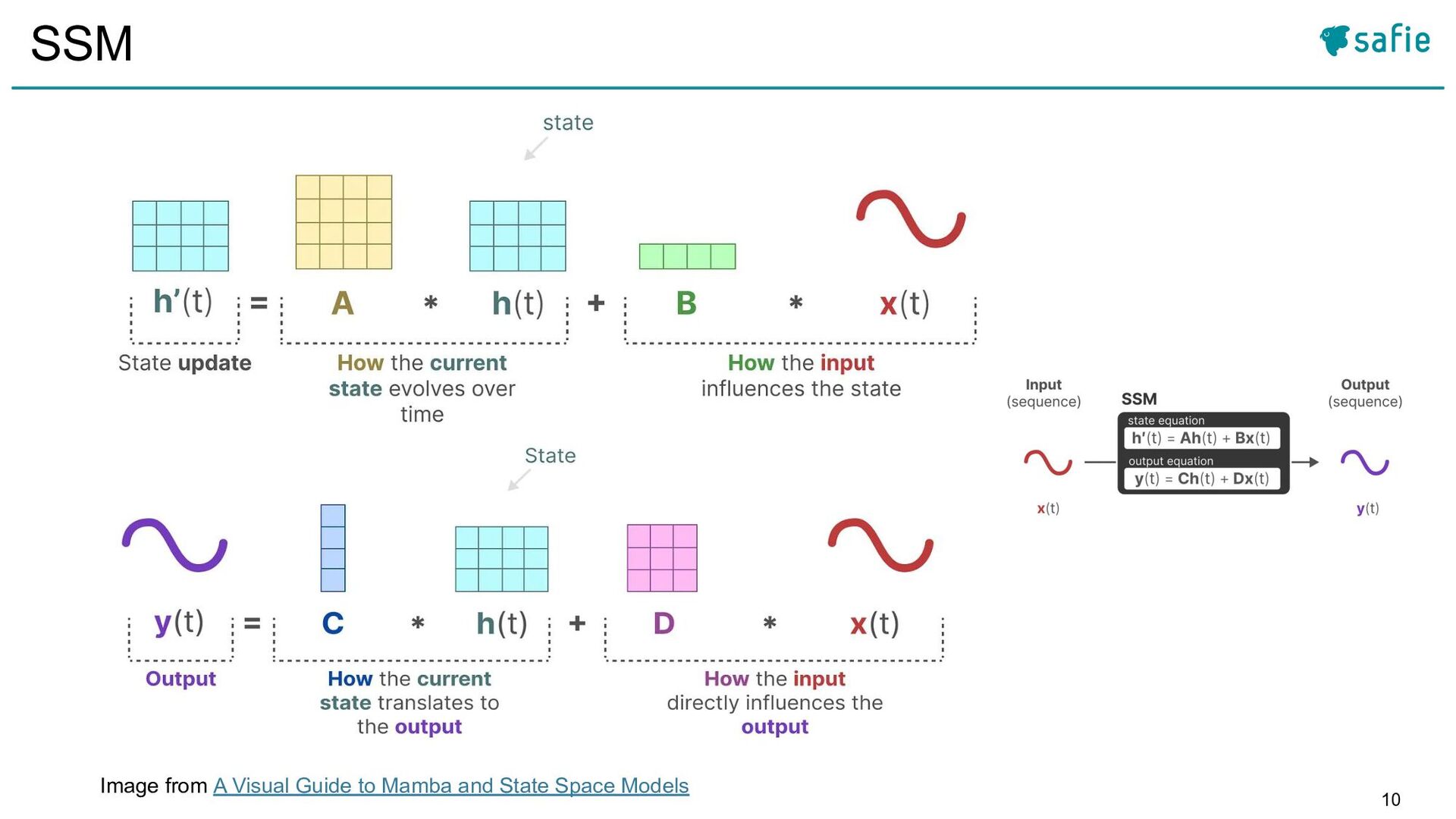
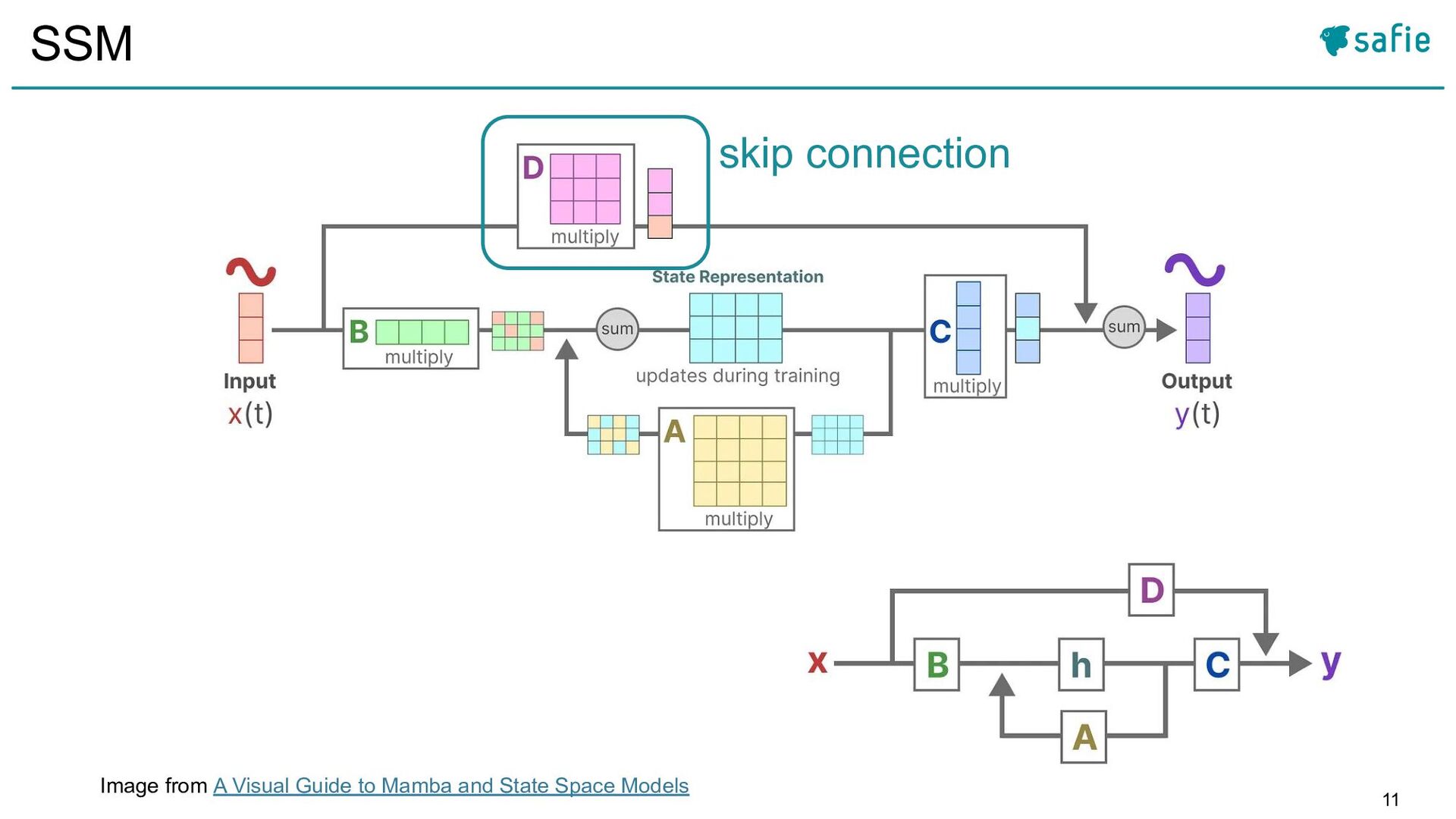
![4 この論文での問い 2023年12月に、Albert Guらが新しいネットワークアーキテクチャMamba [25]を発表した 特徴: • 高速な推論性能(Transformerの約5倍) • 言語、音声など複数の分野において、Transformerに匹敵する性能](https://files.speakerdeck.com/presentations/b0b47b61ef9f49a9a4751a945eae3f90/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![7 Mamba をビデオドメインに適応させた結果、 優れた性能を示していることがわかった Video Mambaによる改善結果 ※ TimeSformer [4] が2021年にFacebook](https://files.speakerdeck.com/presentations/b0b47b61ef9f49a9a4751a945eae3f90/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15 Bidirectional Mamba block 画像ドメインにおいて、VisionMamba [91]は双方向Mamba(B-Mamba)ブロックを導入した。 視覚データが空間的に複雑な情報を含んでいるため、前後両方向の情報を統合する必要が ある。このブロックは、視覚シーケンスを前方および後方のSSMを同時に使用して処理し、空 間的に意識した処理能力を向上させる。 [91]](https://files.speakerdeck.com/presentations/b0b47b61ef9f49a9a4751a945eae3f90/slide_14.jpg){kind=link}
{kind=link}
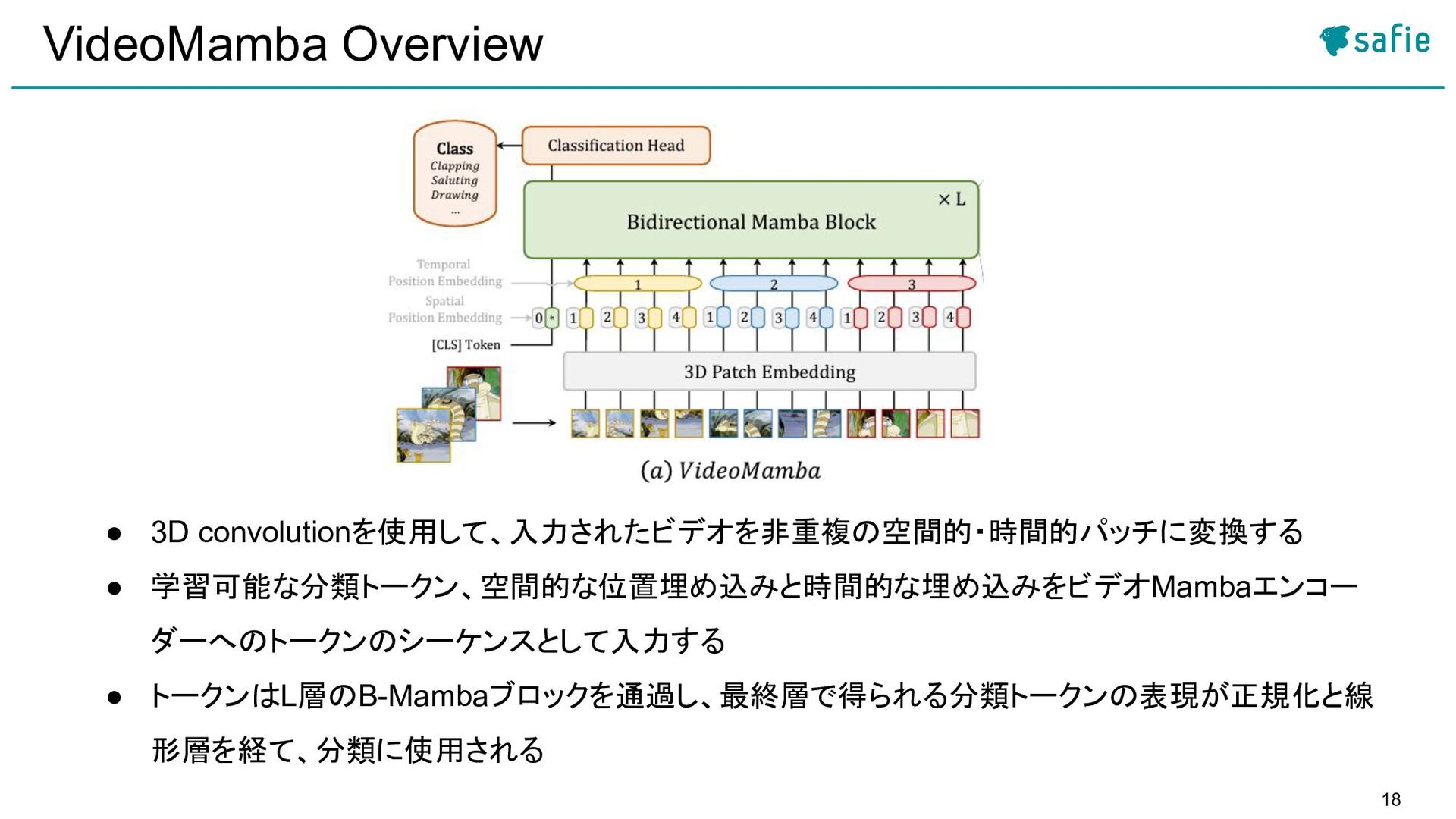
![17 VideoMamba Overview vanilla ViT [15]のアーキテクチャを利用し、B-Mamba blockを3D video sequencesに適応させる [15]](https://files.speakerdeck.com/presentations/b0b47b61ef9f49a9a4751a945eae3f90/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
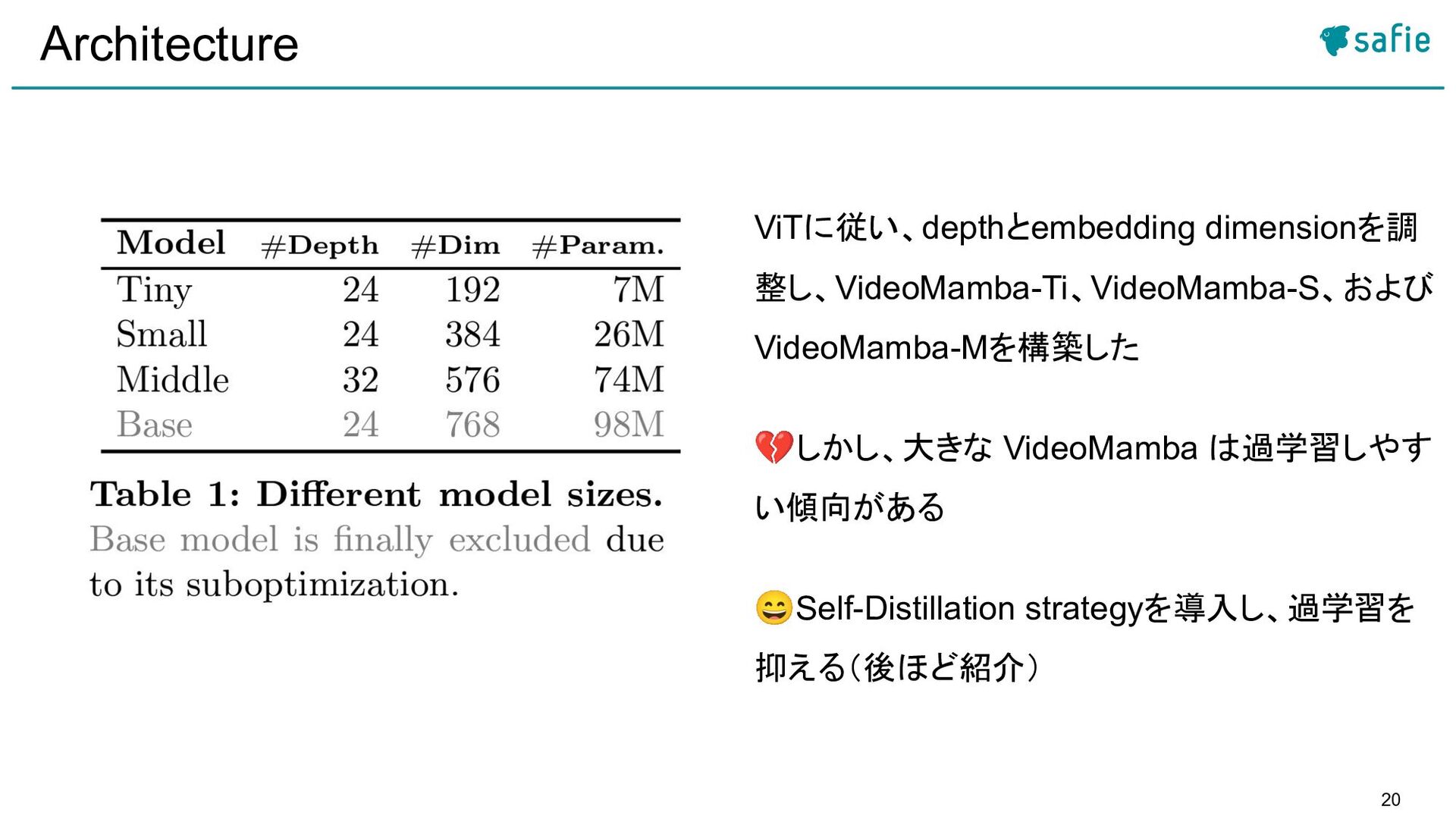{kind=link}
![21 Masked Modeling UTM (Unmasked Teacher Model) [43] [43] Li,](https://files.speakerdeck.com/presentations/b0b47b61ef9f49a9a4751a945eae3f90/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
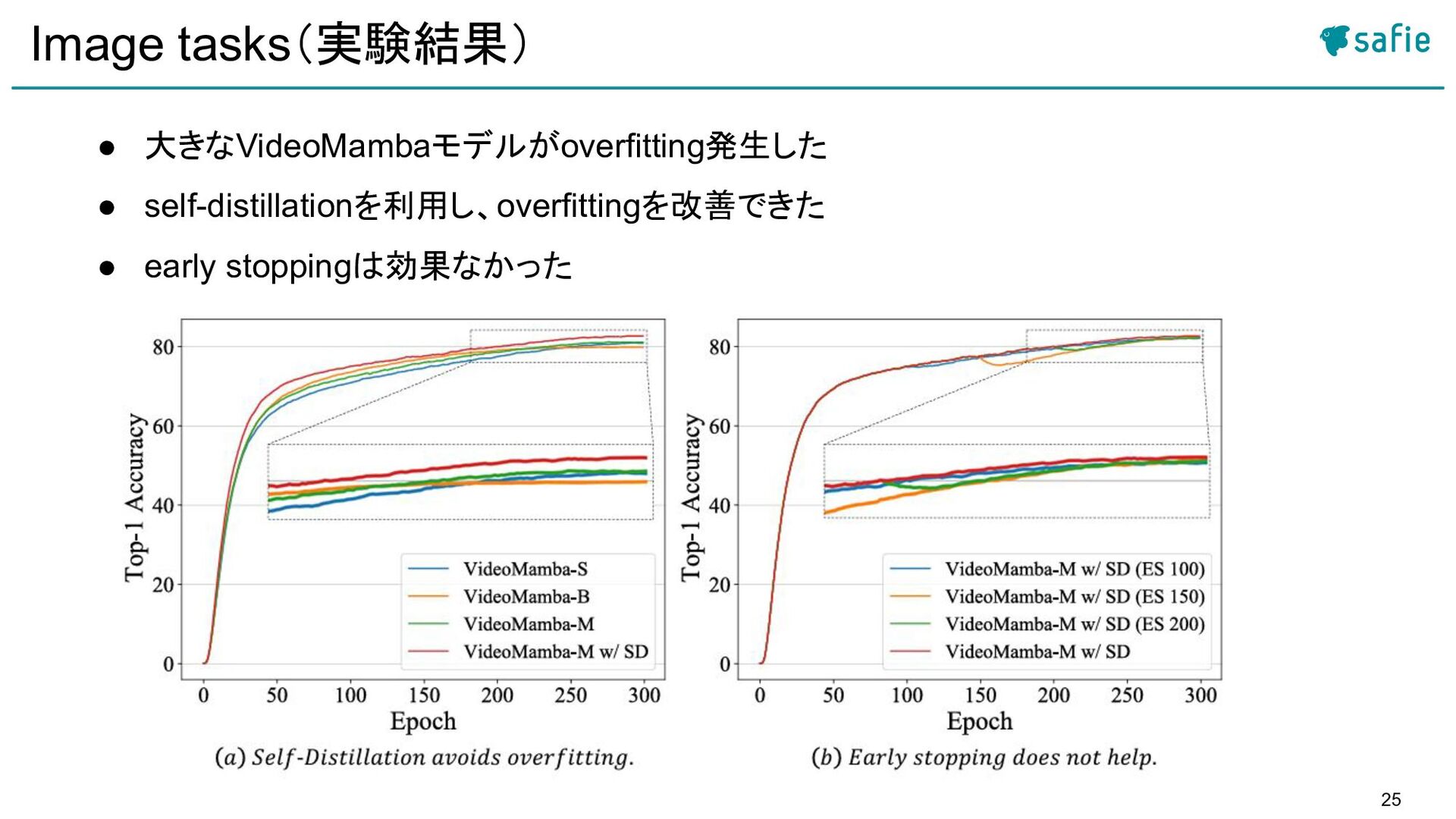{kind=link}
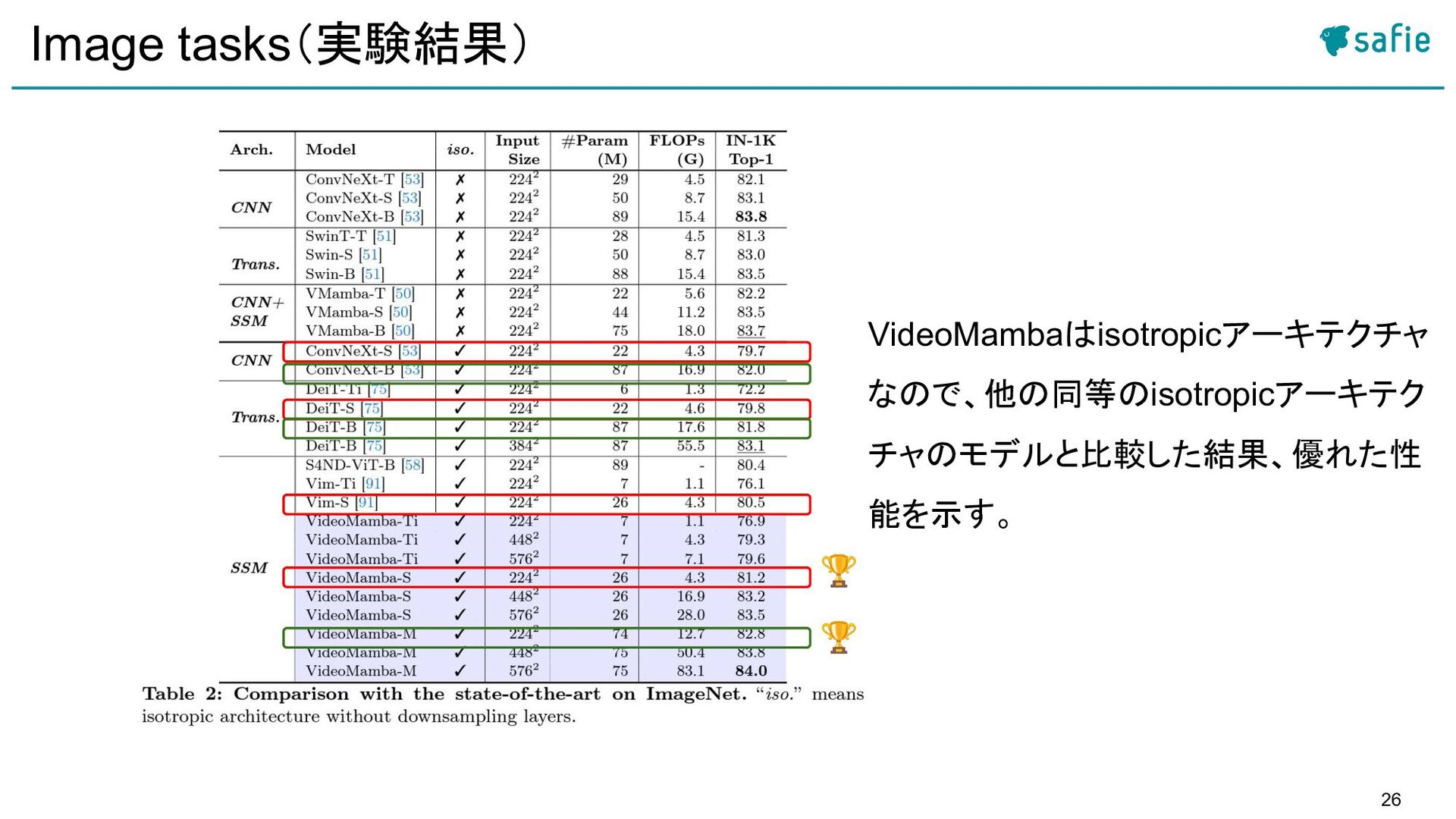{kind=link}
{kind=link}
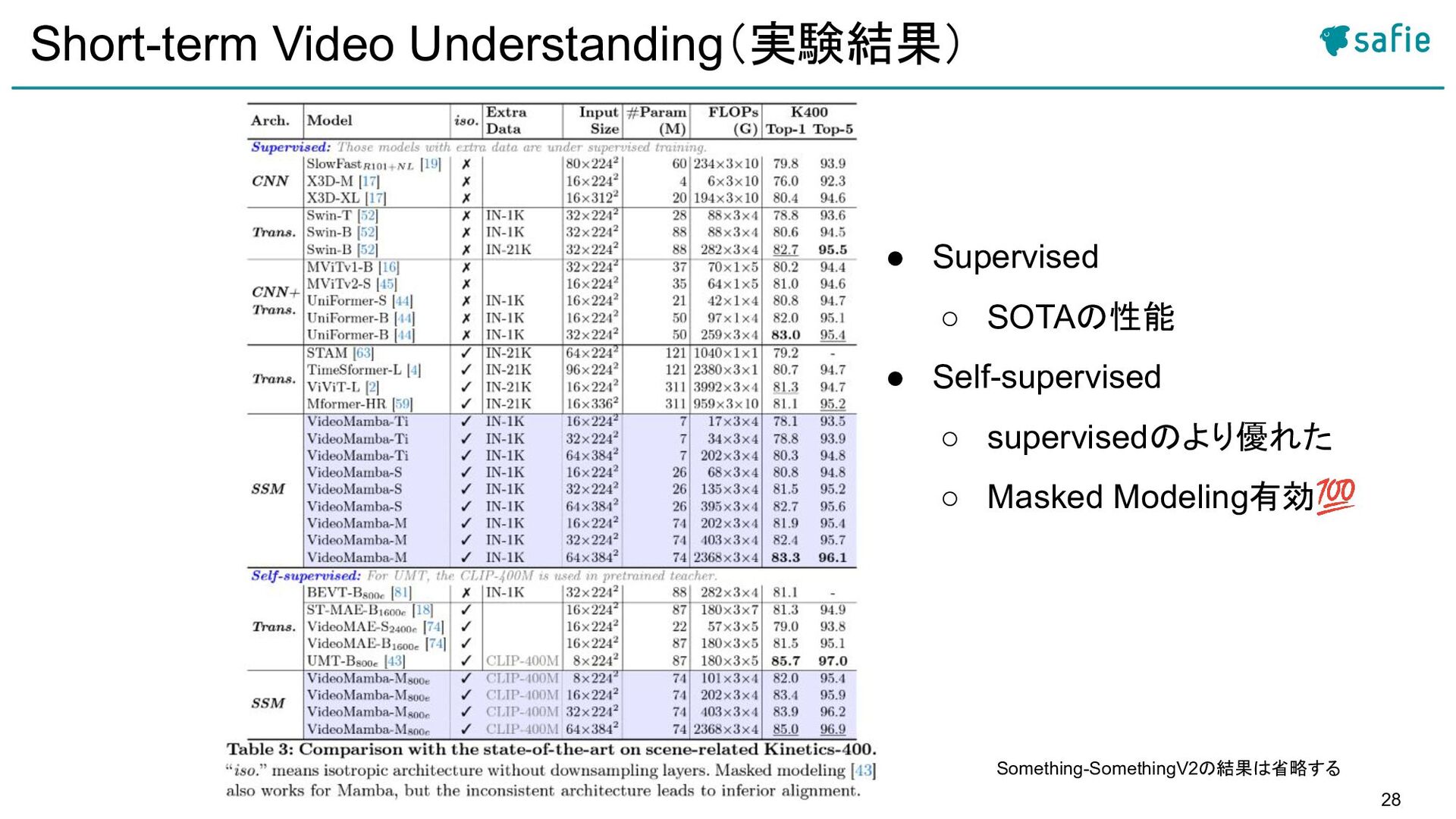{kind=link}
{kind=link}
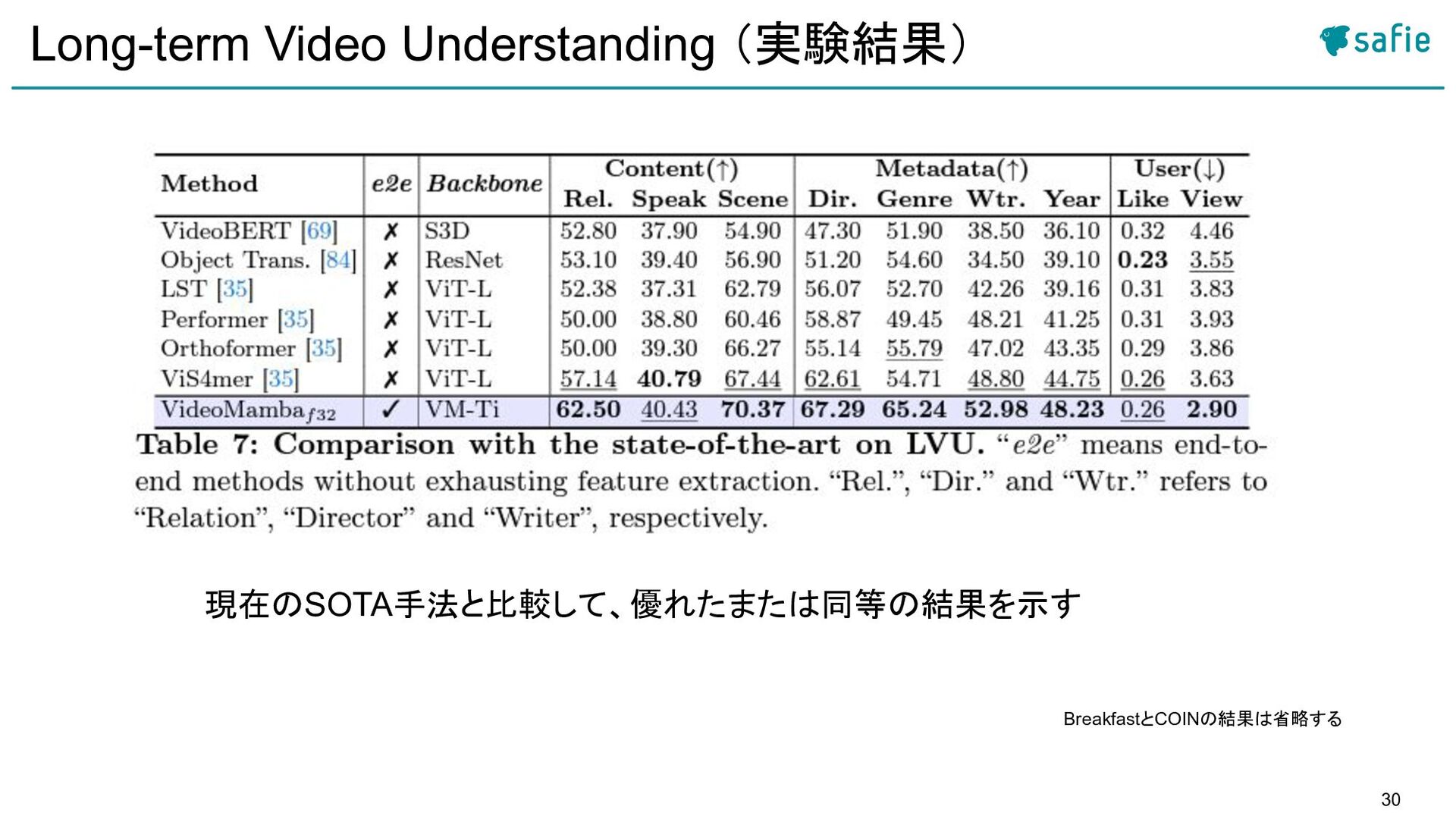{kind=link}
{kind=link}
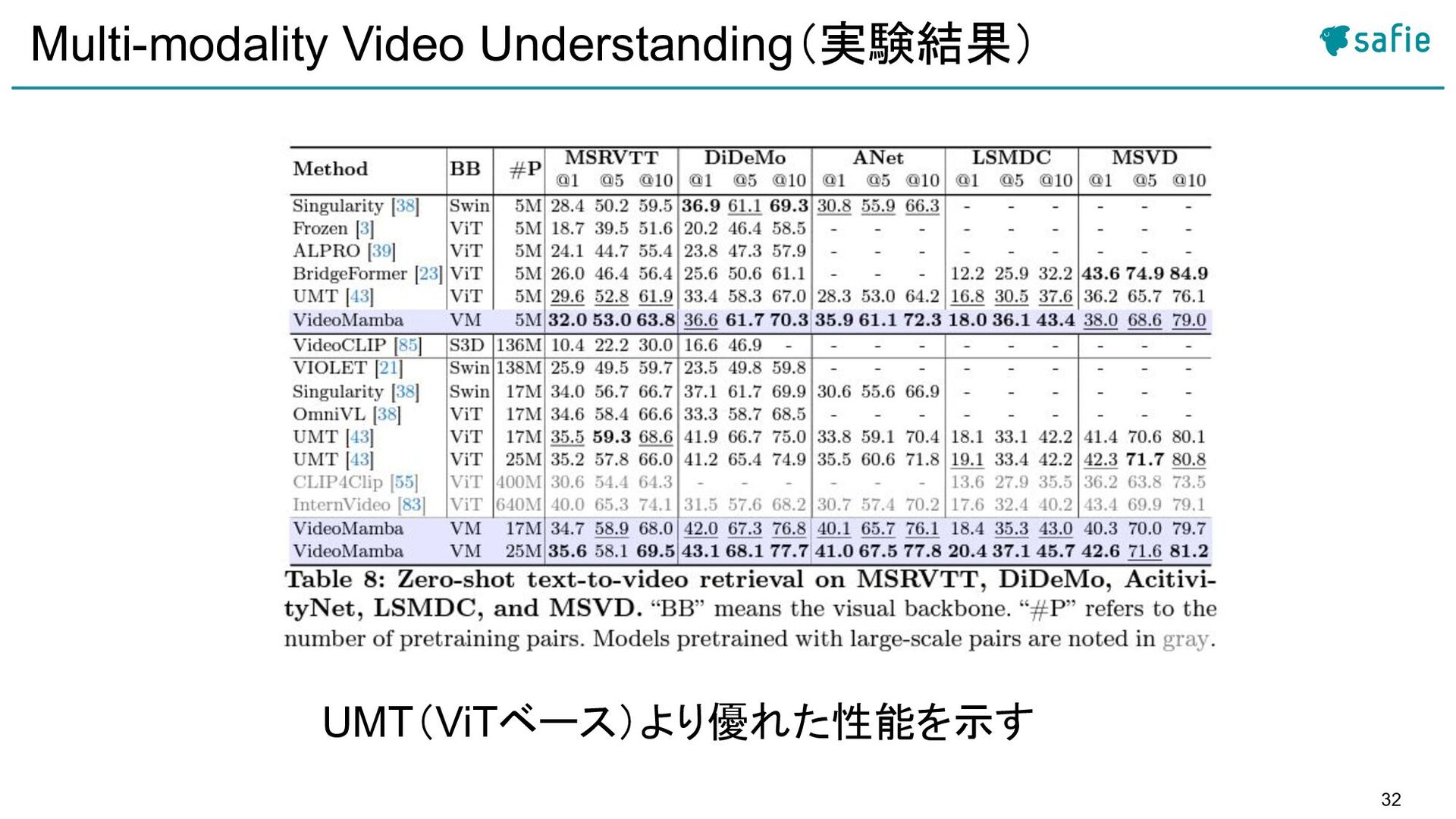{kind=link}
{kind=link}
{kind=link}