Standard Code for Information Interchange) ◦ Character = 7 bits, e.g., ⟨A⟩ = 65, or 0x41, or 0b1000001 ◦ Not enough for modern texts (even with extended) • Big-5 (i.e. CP950 on Windows) ◦ Character = 16 bits (2 byte), e.g., ⟨字⟩ = 0xA672 ◦ Region-specific encoding/codepage • Unicode Codepoints ◦ Character = 21 bits (logically), e.g., ⟨字⟩ = U+5B57, or No. 22383 ◦ One standard to rule them all (over the world) ◦ Technically, some codepoints do not refer to visible/standalone characters /zì/ character 13
21 bits (~3 bytes unsigned) • For example ⟨字⟩ is at No. 22383 (U+5B57) • “Let's store each character with 4 bytes” ◦ Named as UCS-4, or UTF-32 (where UCS=Universal Coded Character Set, and UTF=Unicode Transformation Format) ◦ Encoded buffer looks like codepoint sequence, easy peasy! ◦ ⟨語言⟩ = ⟨U+8A9E⟩⟨U+8A00⟩ → ⟨9E 8A 00 00⟩⟨8A 00 00 00⟩ ◦ ⟨AB⟩ = ⟨U+0041⟩⟨U+0042⟩ → ⟨41 00 00 00⟩⟨42 00 00 00⟩ ◦ Not efficient in most cases (where using ASCII or Extended ASCII was/is enough) OK then, How to represent a number in computer world? /yǔ yán/ language I'm trying to make it short & simple, hence the information may be imprecise or incorrect. Please refer to Wikipedia and Unicode website for detailed history. ⚠ 14
lower 2 bytes?” ◦ UCS-2, and later UTF-16 (unlike UCS-2 & UTF-32, these two are different!) ◦ ⟨語⟩⟨言⟩ = ⟨U+8A9E⟩⟨U+8A00⟩ → bytes ⟨9E 8A 00 00⟩⟨00 8A 00 00⟩ ◦ ⟨A⟩⟨B⟩ = ⟨U+0041⟩⟨U+0042⟩ → ⟨41 00 00 00⟩⟨42 00 00 00⟩ ◦ Reduced overall document size by 50% (in comparison to UTF-32) • “Come on. My ASCII document is still bloated to 200% with a lot of trash.” ◦ UTF-8 encodes a character with 1~4 bytes smartly (i.e. variable length) ◦ ⟨語言AB⟩ = ⟨U+8A9E⟩⟨U+8A00⟩⟨U+0041⟩⟨U+0042⟩ → ⟨E8 AA 9E⟩⟨E8 A8 80⟩⟨41⟩⟨42⟩ OK then, How to represent a number in computer world? (cont.) 15
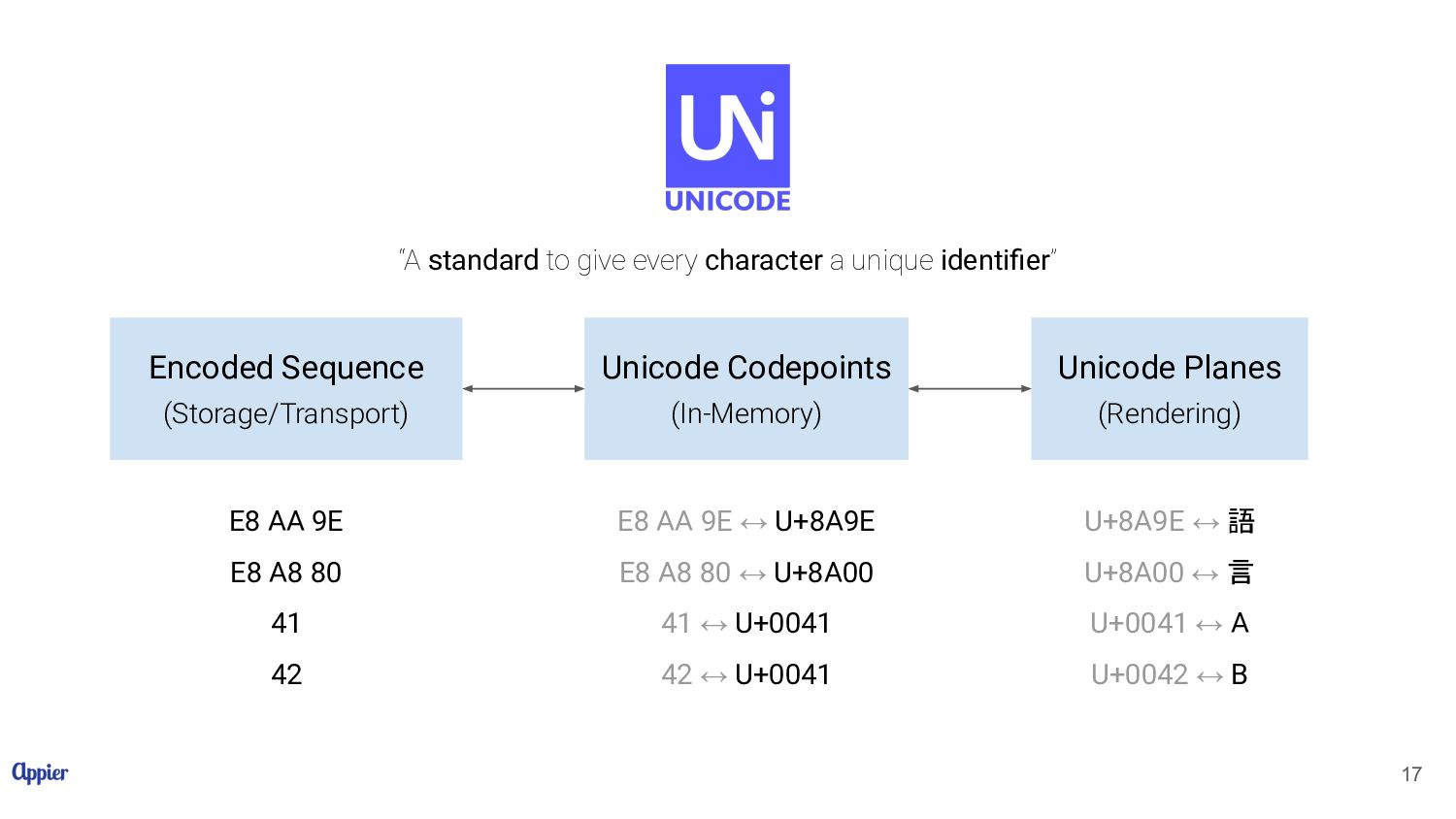
AA 9E E8 A8 80 41 42 E8 AA 9E ↔ U+8A9E E8 A8 80 ↔ U+8A00 41 ↔ U+0041 42 ↔ U+0041 U+8A9E ↔ 語 U+8A00 ↔ 言 U+0041 ↔ A U+0042 ↔ B “A standard to give every character a unique identifier” 17
represent all characters ◦ But UCS-2 only takes 16 bits for each character ◦ What if we need to store/display a character that takes more than 16 bits? ◦ For example, 💩 = U+1F4A9 = 0b11111010010101001 (17 bits) • Augment UCS-2 with variable length capability → UTF-16 • Unicode defines planes ◦ Plane = Group of 65536 (216) codepoints ◦ BMP (Basic Multilingual Plane) or simply Plane 0, defines commonly used characters ◦ Codepoint outside BMP takes more than 16 bits 20
when printed or displayed ◦ For example, the diacritics (accents) and the Hangul syllables • Compatible codepoint sequences ◦ Possibly distinct appearance, but same meaning in some contexts ◦ For example, ⟨ff⟩ U+FB00 is compatible with two ordinary Latin ⟨f⟩ U+0066 letters ◦ Another example, ligature ⟨㍿⟩ U+337F ◦ Ref. CJK Compatibility • Normal form (Normalization) ◦ Reduce equivalent codepoint sequences to the same codepoints ◦ NFD, NFC, NFKD, NFKC Unicode Equivalence / Normalization % python3 from unicodedata import normalize >>> '\uC77C', '\uC774\u11AF' ('일', '일') >>> '\uC77C' == '\uC774\u11AF' False >>> '\uC77C' == normalize('NFC', '\uC774\u11AF') True >>> normalize('NFD', '\uC77C') == '\uC774\u11AF' False /kabushiki gaisha/ 25
Python 3 • Python 3 ◦ len(str) and [x for x in str] operate on codepoints (beware of combining characters ⚠) ◦ Rule of 🍔 → ① bytes#decode to text on input, ② process text, ③ str#encode to bytes on output ◦ Use unicodedata#normalize and str#casefold for display/sorting/comparison ◦ Sorting (standard sorted) may require locale#setlocale, or just import pyuca ◦ Use grapheme#length to count visible characters ◦ Ref. Unicode HOWTO and Unicode Objects and Codecs (Python 3 official documentation) • JavaScript ◦ String#length counts UCS-2 code units, while for … of str and [...str] operate codepoints ◦ Beware of surrogate pairs (in some APIs) and combining characters ⚠ ◦ Consider String#normalize, String#localeCompare, and String#toLocaleLowerCase ◦ Use GraphemeSplitter#countGraphemes to count visible characters Programming with Unicode (the simple version) 27
% python3 Python 3.9.0 (default, Dec 6 2020, 18:02:34) >>> '\N{PILE OF POO}' '💩' >>> x = '⑧⑥' >>> int(x) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: invalid literal for int() with base 10: '⑧⑥' >>> sum([unicodedata.numeric(x[i]) * 10**(len(x)-i-1) \ for i in range(len(x))]) 86.0
comparison among strings, e.g., radical or strokes for Chinese, ref) • Casefolding (aggressive “lower()” for non-Latin caseless comparison) • CJK Unified Ideographs (For ⟨㋿⟩, which one to use → ⟨令 U+4EE4⟩ vs ⟨令 U+F9A8⟩) • IDN homograph attack (phishing scam) • Regular Expressions (e.g., r"\p{InCJK_Unified_Ideographs}") • Transliteration (letter swap rules, e.g., Greek ⟨α⟩ → ⟨a⟩, sometimes used in SMS) • Punycode (represent Unicode characters in ASCII subset, e.g., ⟨中文⟩ → ⟨xn--fiq228c⟩) • Right-to-left mark ⟨U+200F⟩ (e.g., ⟨U+0623 U+0647 U+0644 U+0627! U+200F⟩ → ⟨!ﻼھأ⟩) • Localization (with Unicode CLDR) → Unicode is not just about characters • Databases: MySQL (utf8mb4), and other languages: C, C++, Swift, Go, HTML, etc. • Security issues related to Unicode processing (e.g., CVE-2018-4290 – crashes iPhone) • … (Unicode is too hard to master) Advanced Topics (not covered today) 部首 筆劃 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}