Time To First Token(最初のトークンが生成されるまでの時間) TBT = Time Between Tokens(トークン間の生成間隔) TTFTは主にPrefill時間に、TBTは主にDecodeの反復時間に支配される。混在実行では、典型的に以下の 問題が起きる。 • Prefillは大きな行列積を連続で実行するため、SMを長時間占有する • Decodeは小さいバッチで頻繁にスケジュールされ、トークン単位の低レイテンシが求められる • Prefillが長時間GPUを握ると、進行中セッションのDecodeが待たされ、TTFTとTBTがともに悪化す る サービス設計では、この2つの指標を別々に最適化する必要がある。 48
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
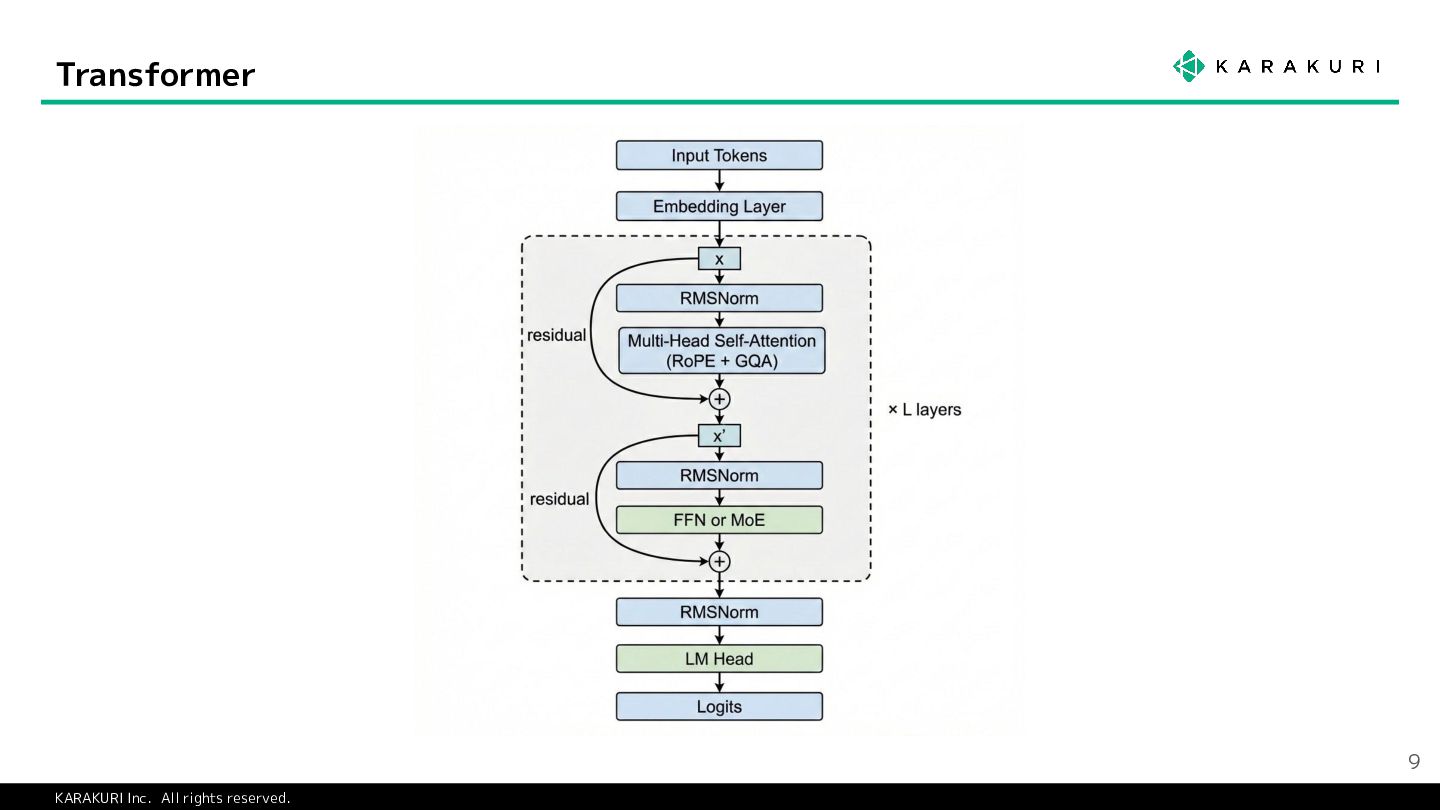{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
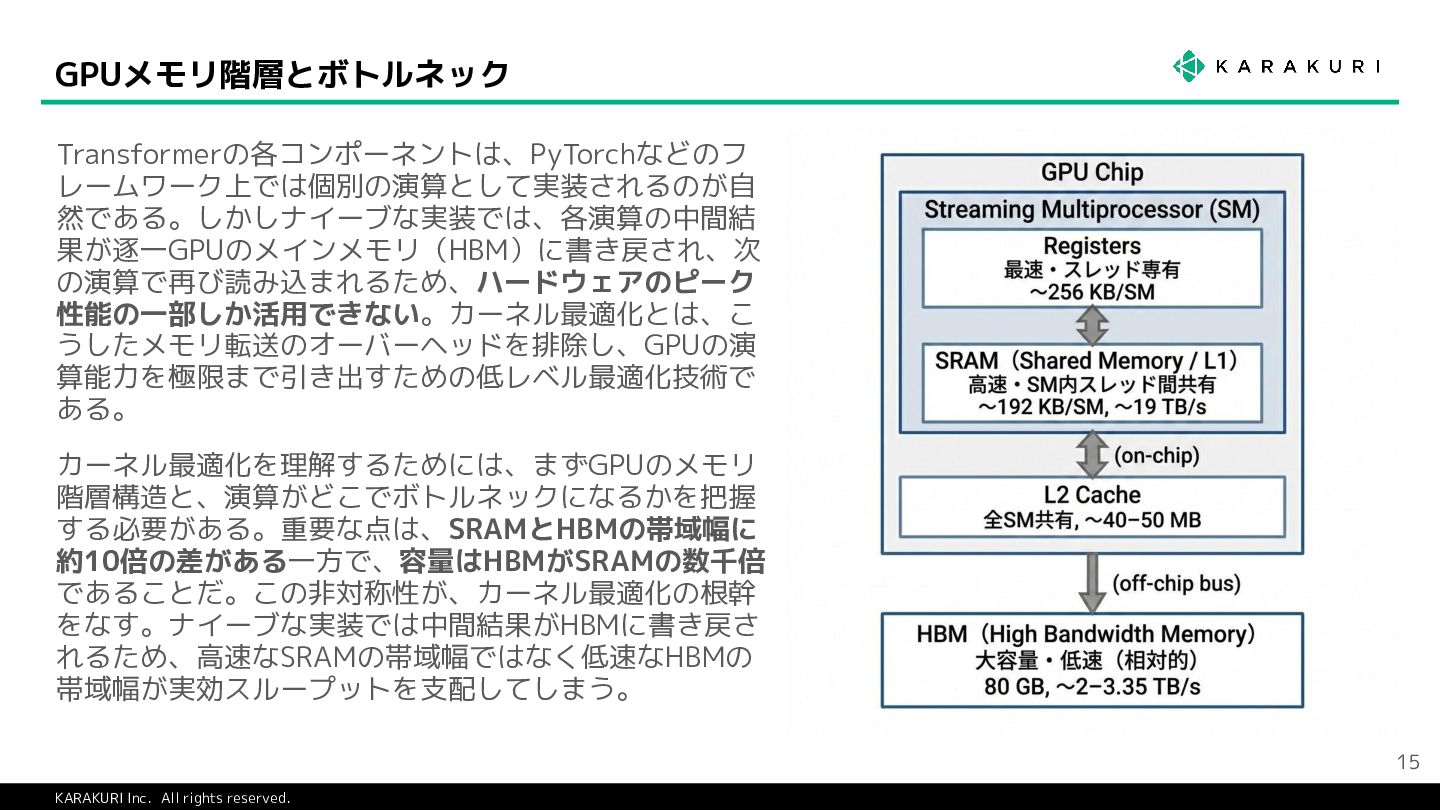{kind=link}
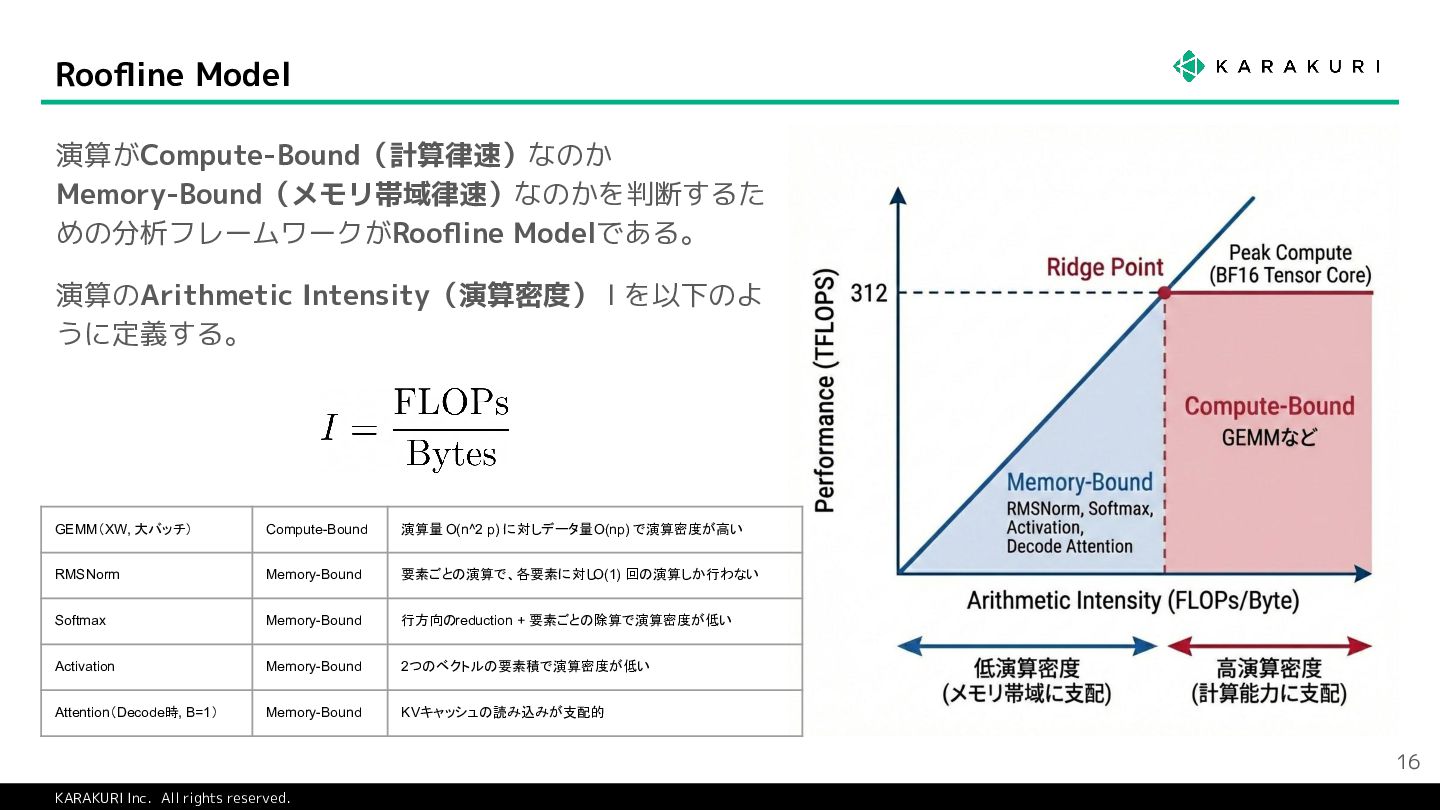{kind=link}
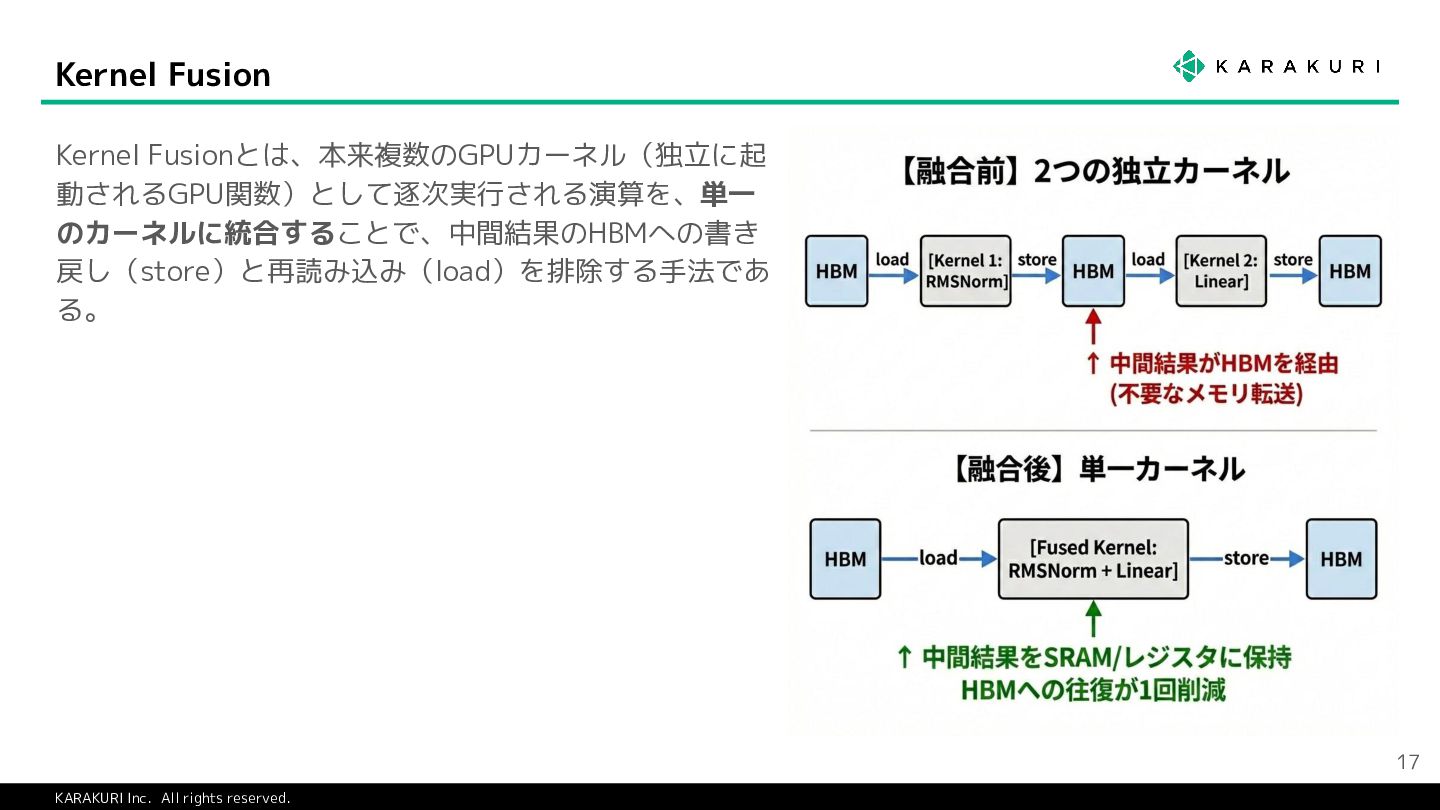{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
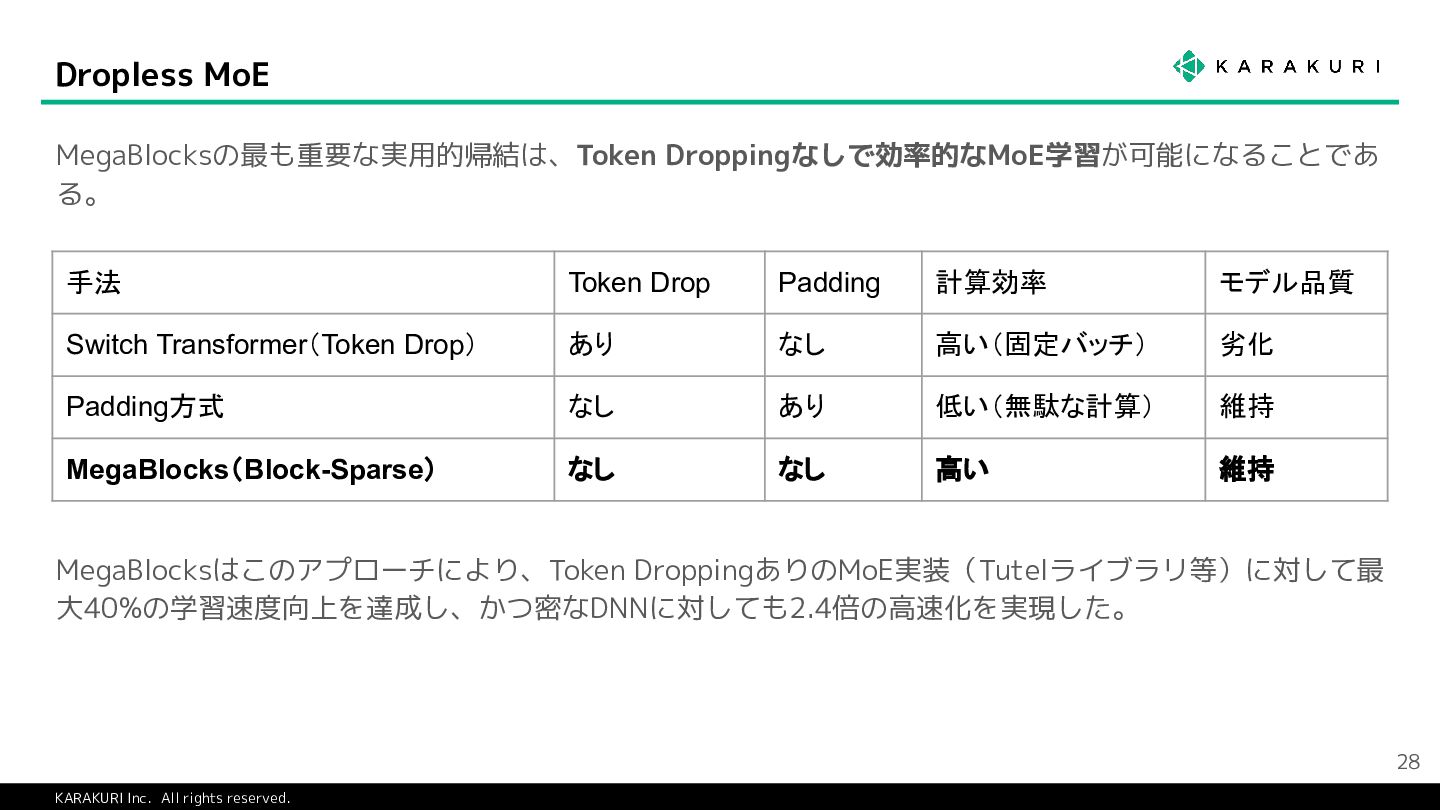{kind=link}
{kind=link}
{kind=link}
{kind=link}
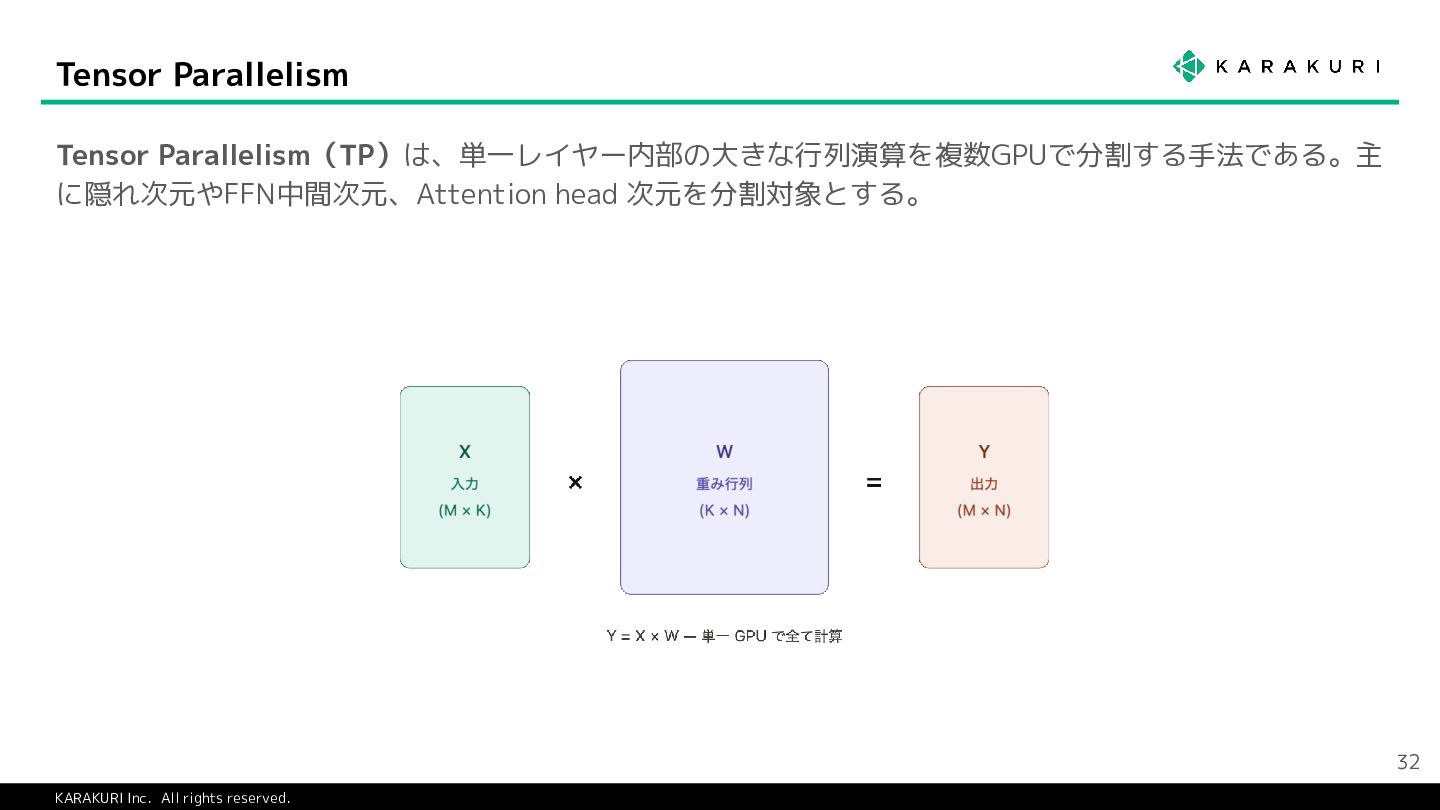{kind=link}
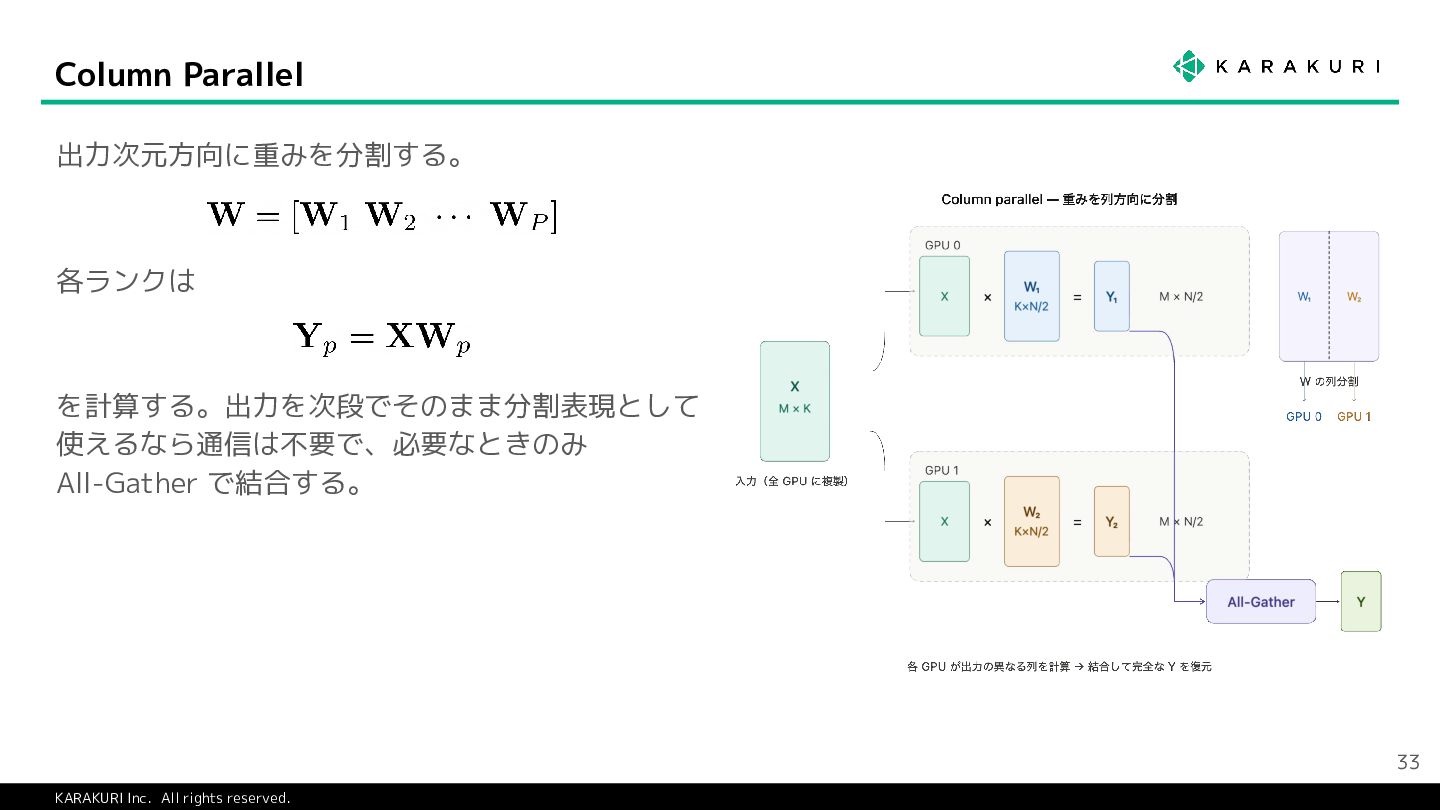{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
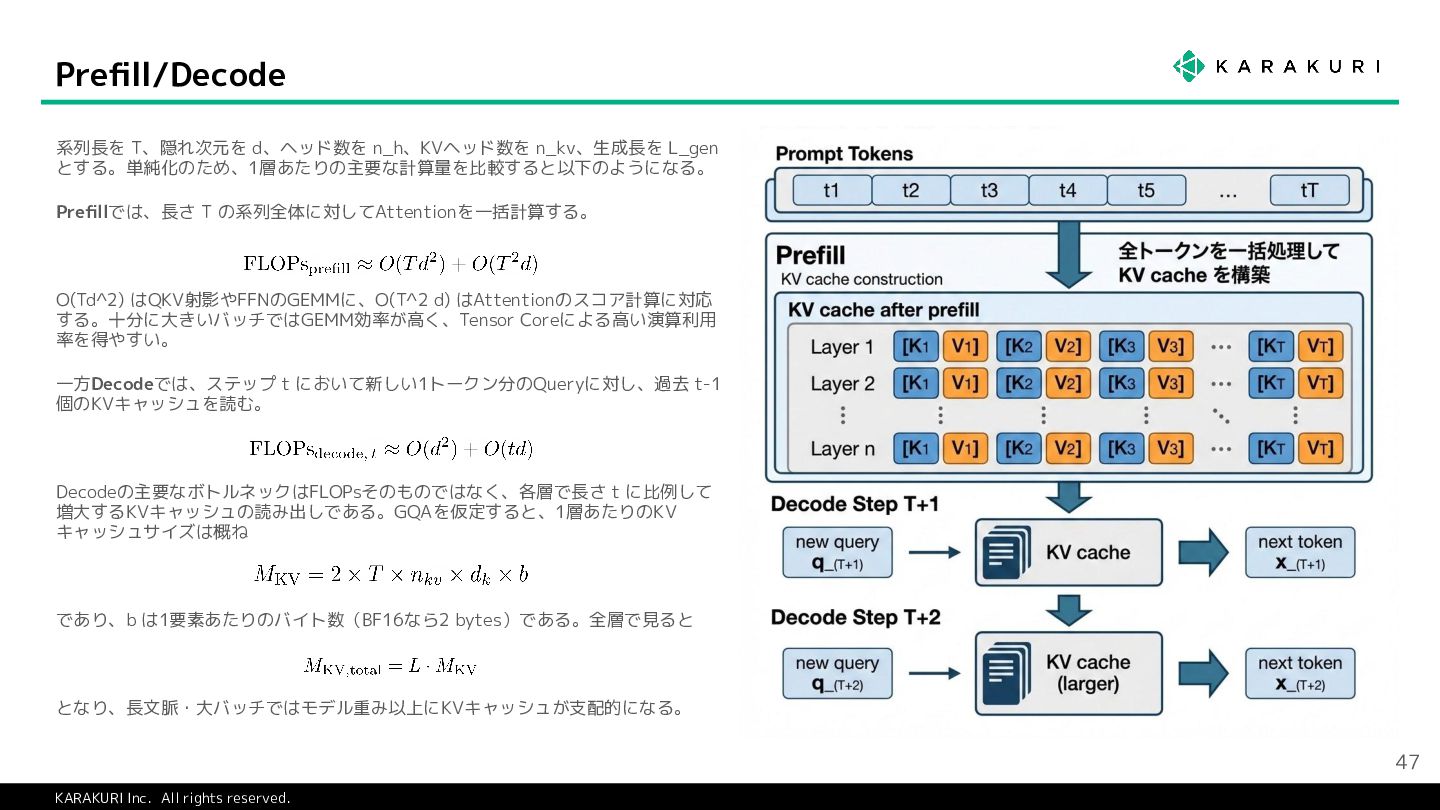{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
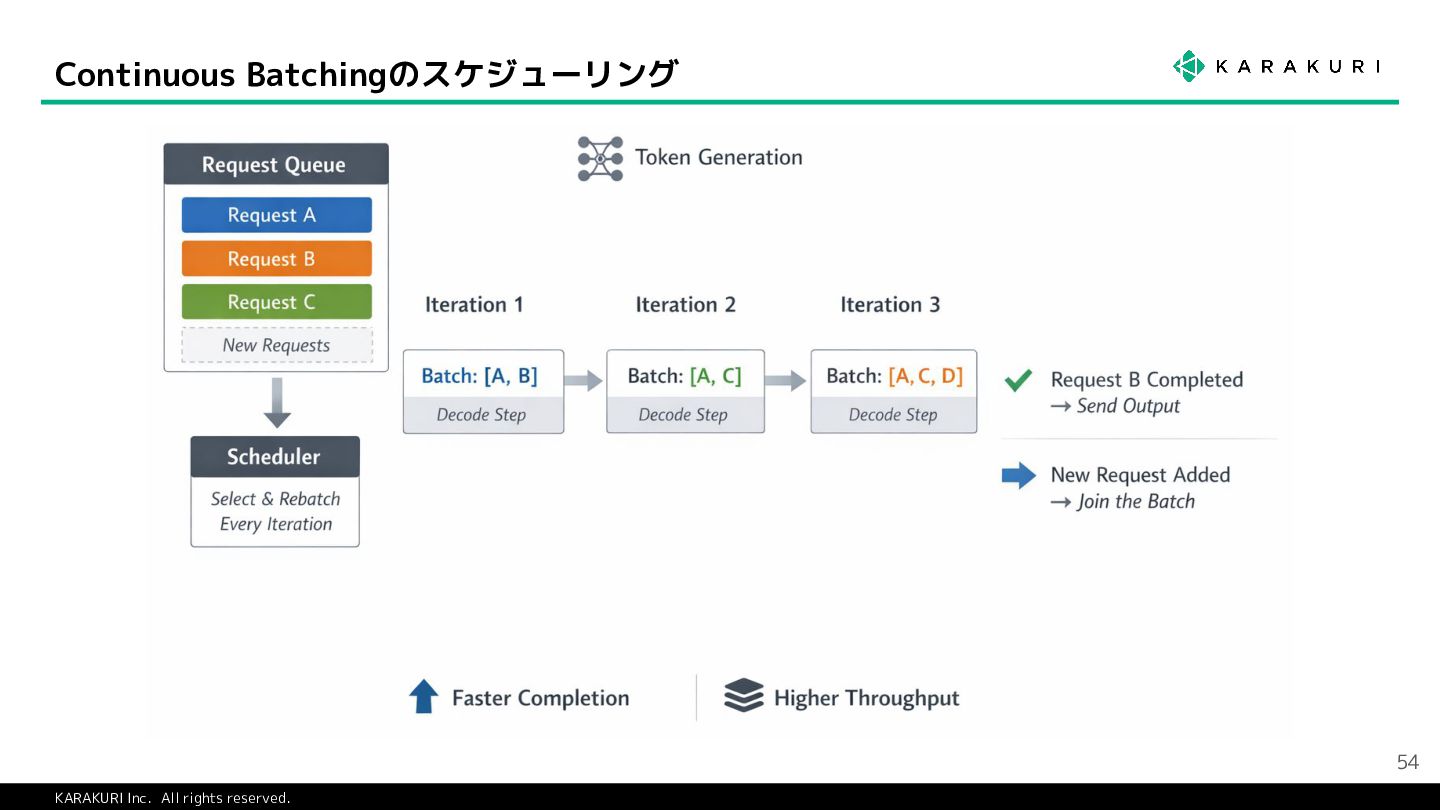{kind=link}
{kind=link}
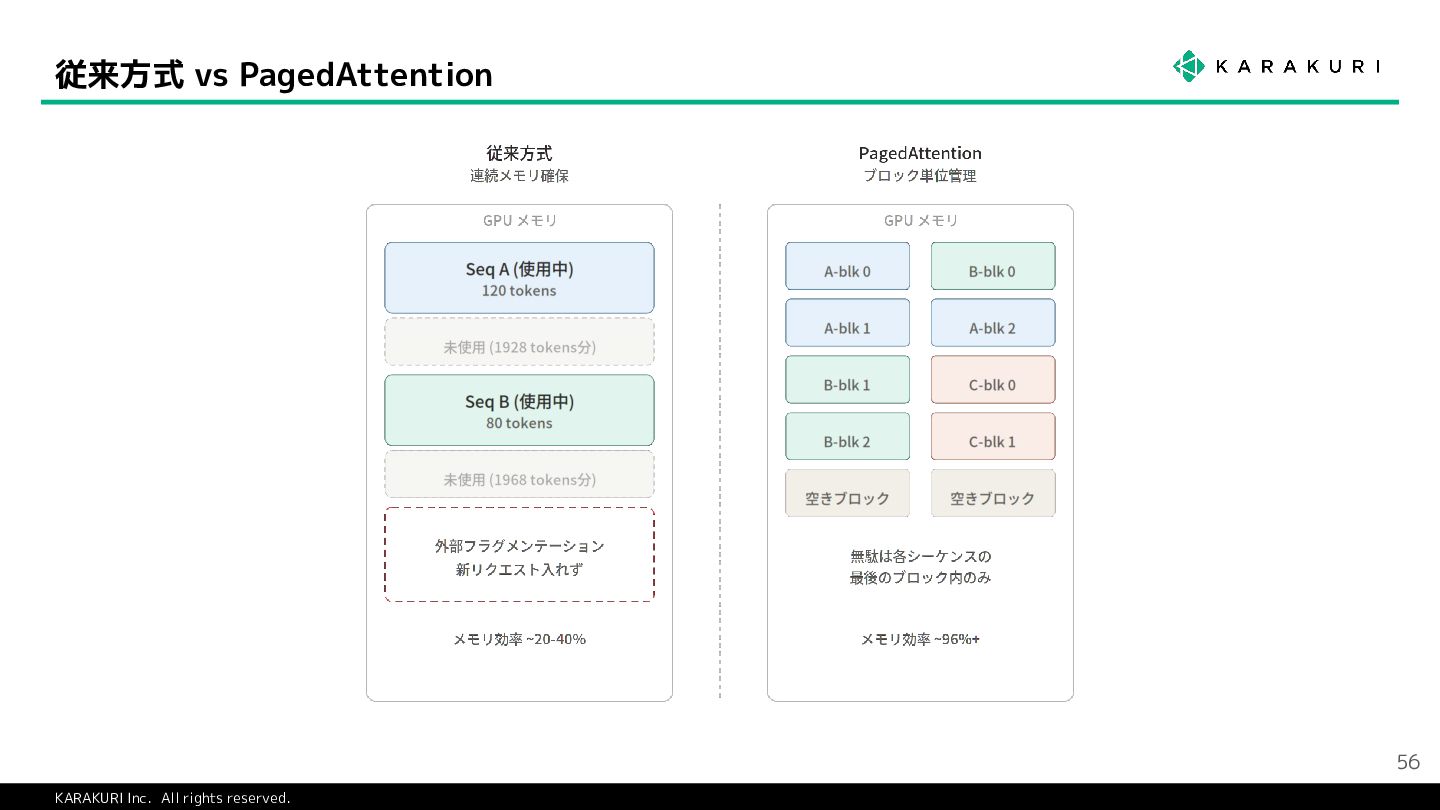{kind=link}
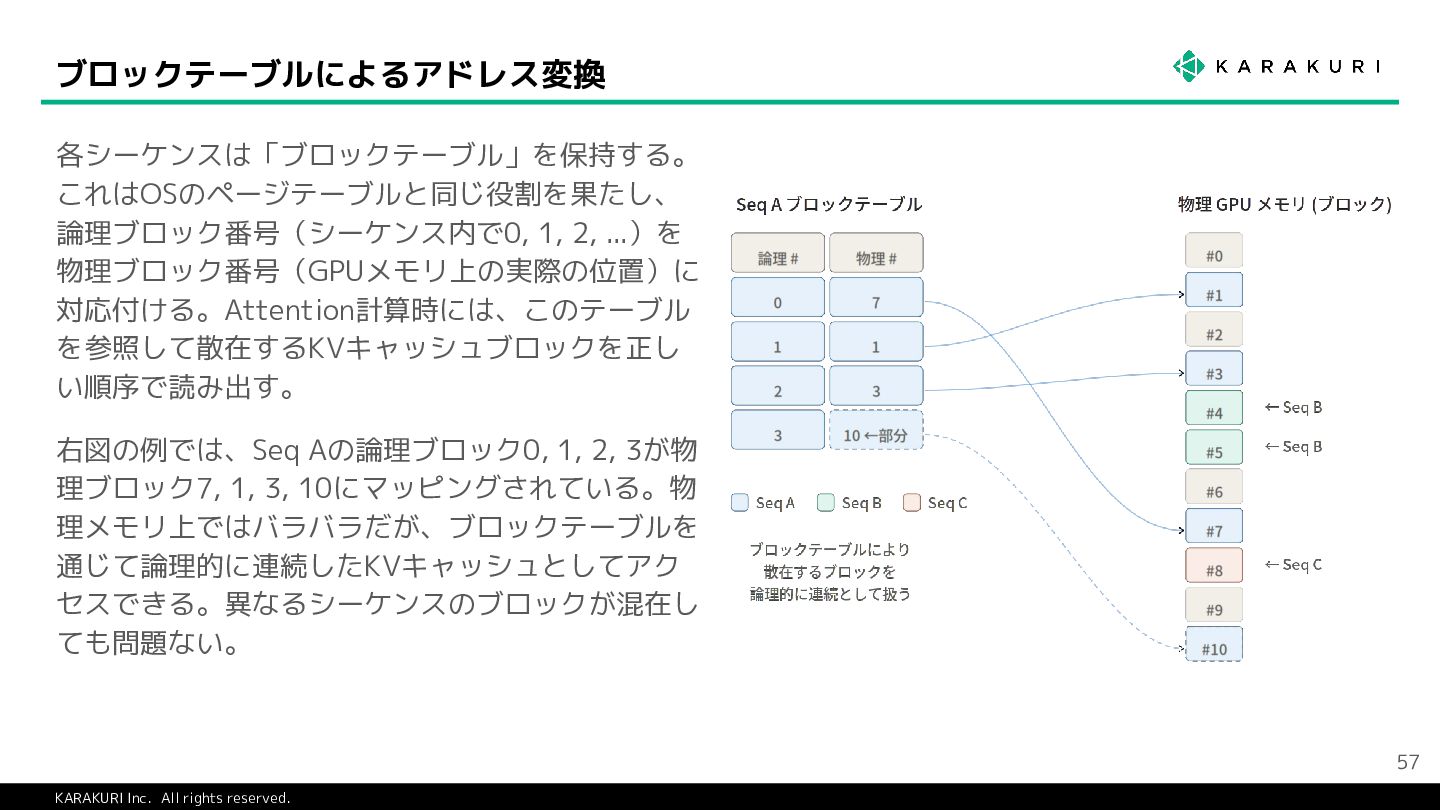{kind=link}
{kind=link}
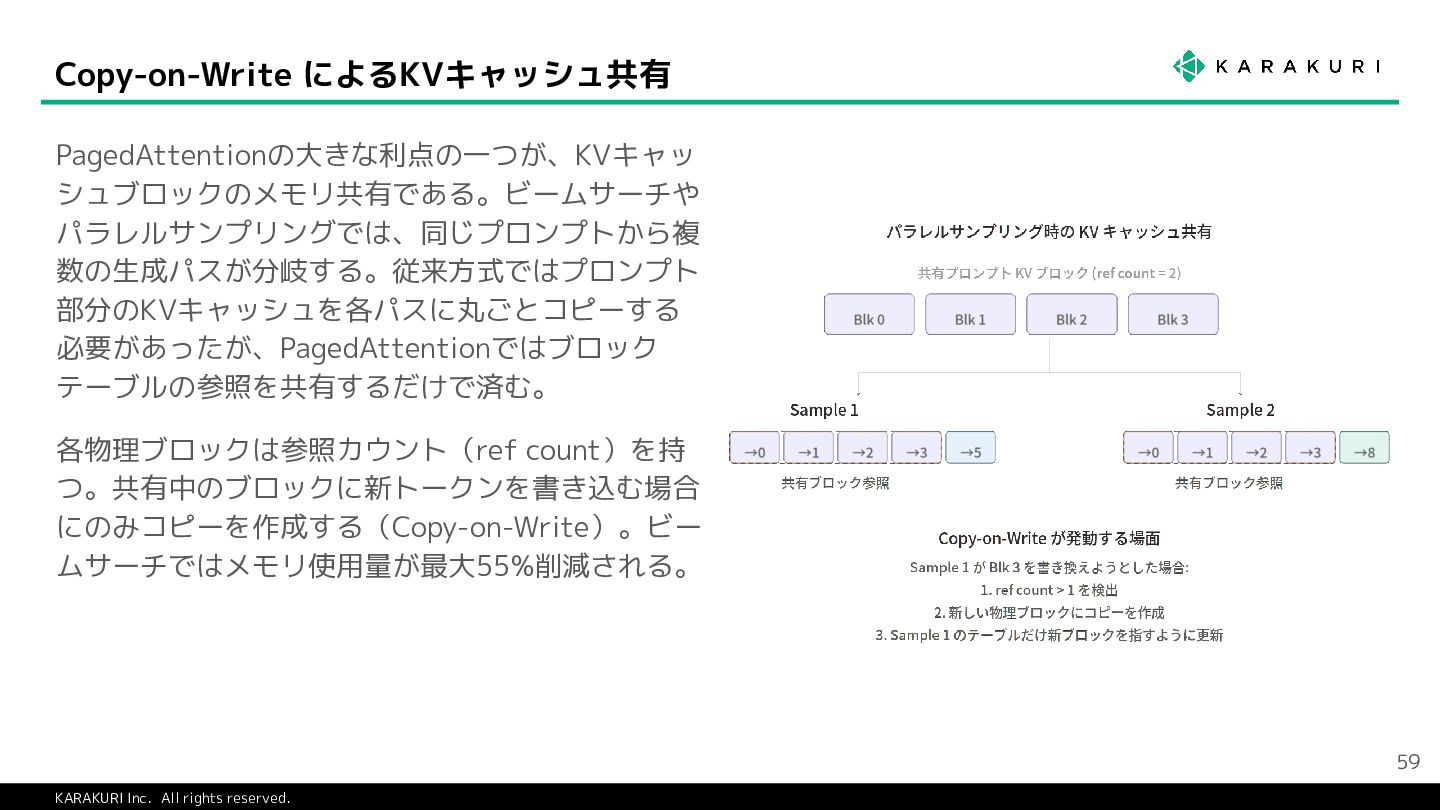{kind=link}
{kind=link}
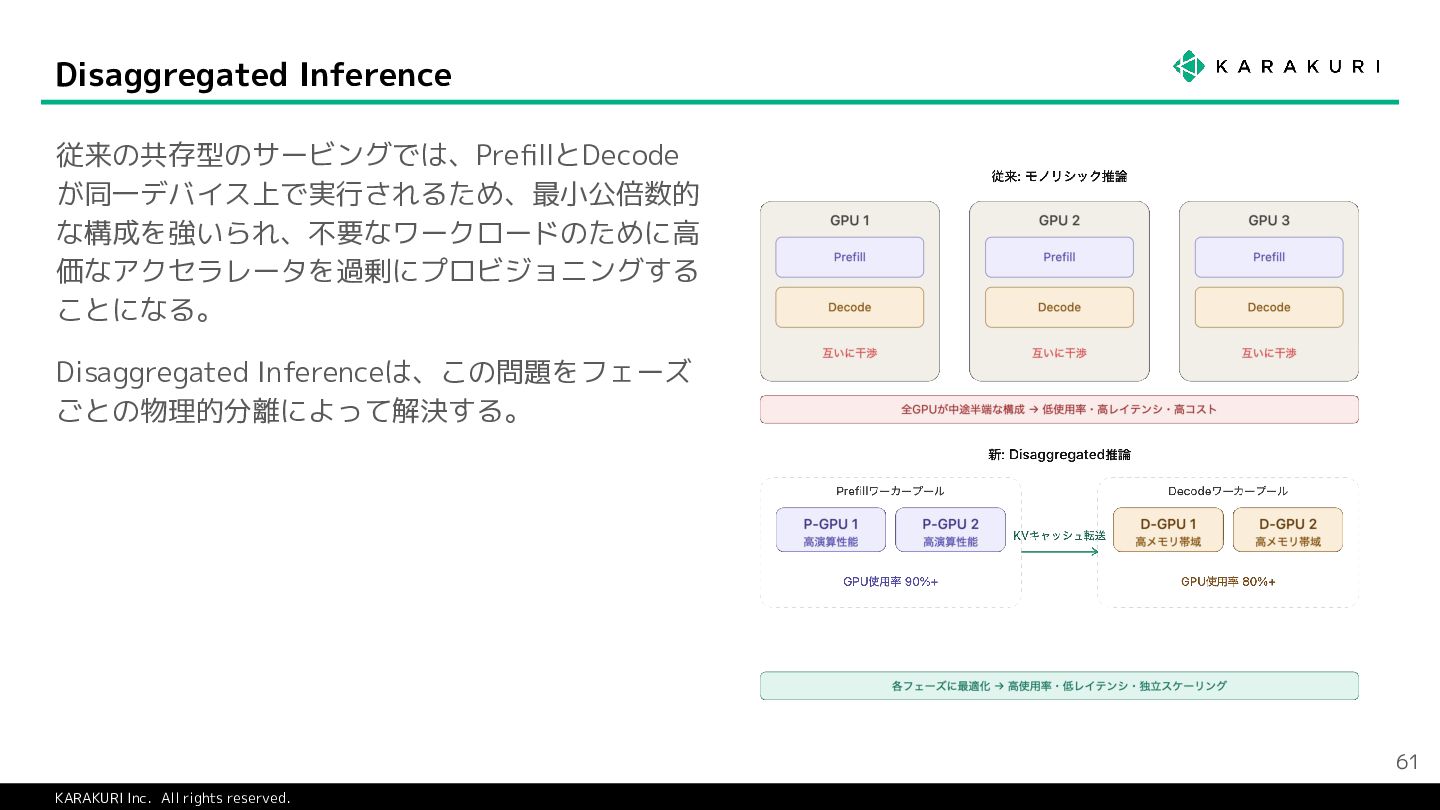{kind=link}
{kind=link}
{kind=link}
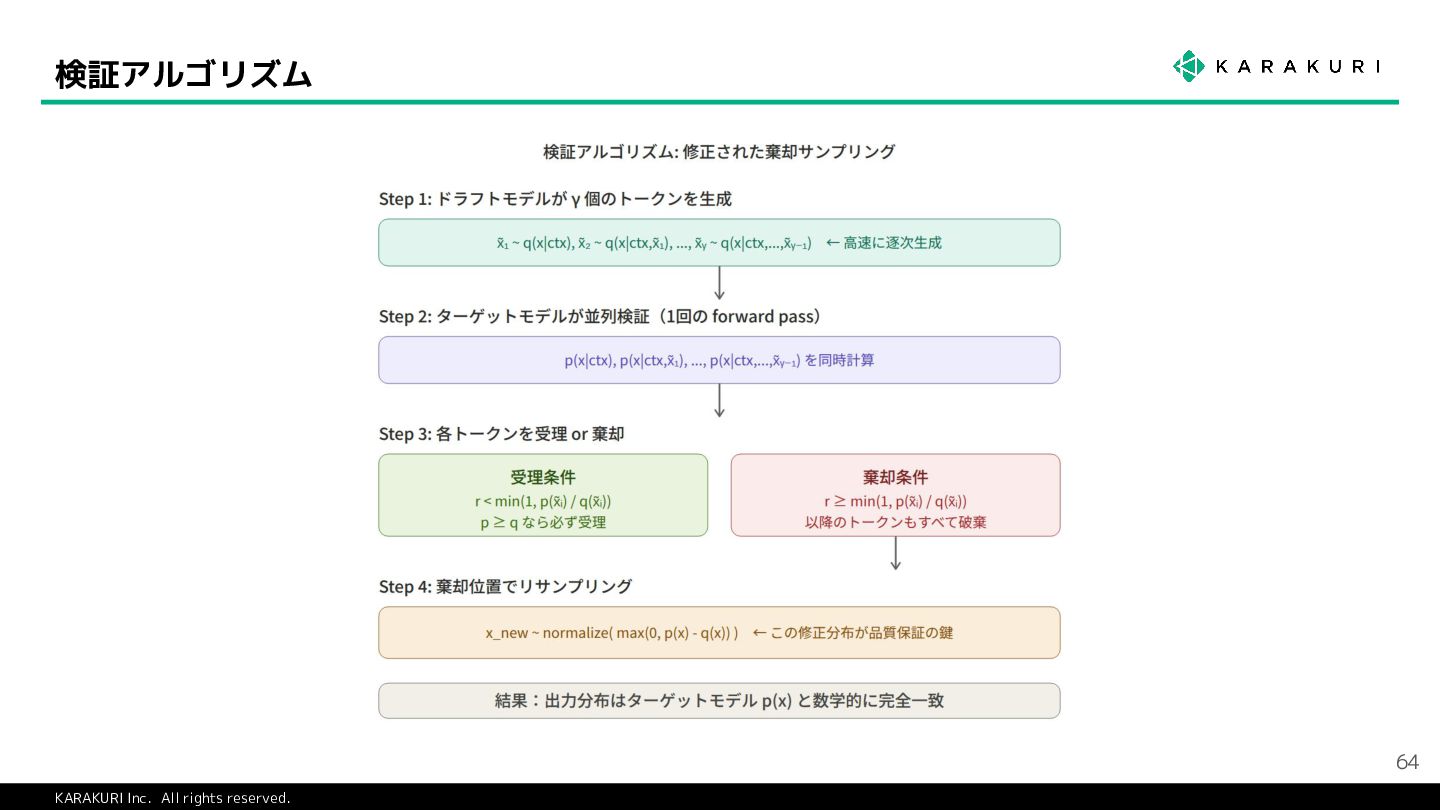{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
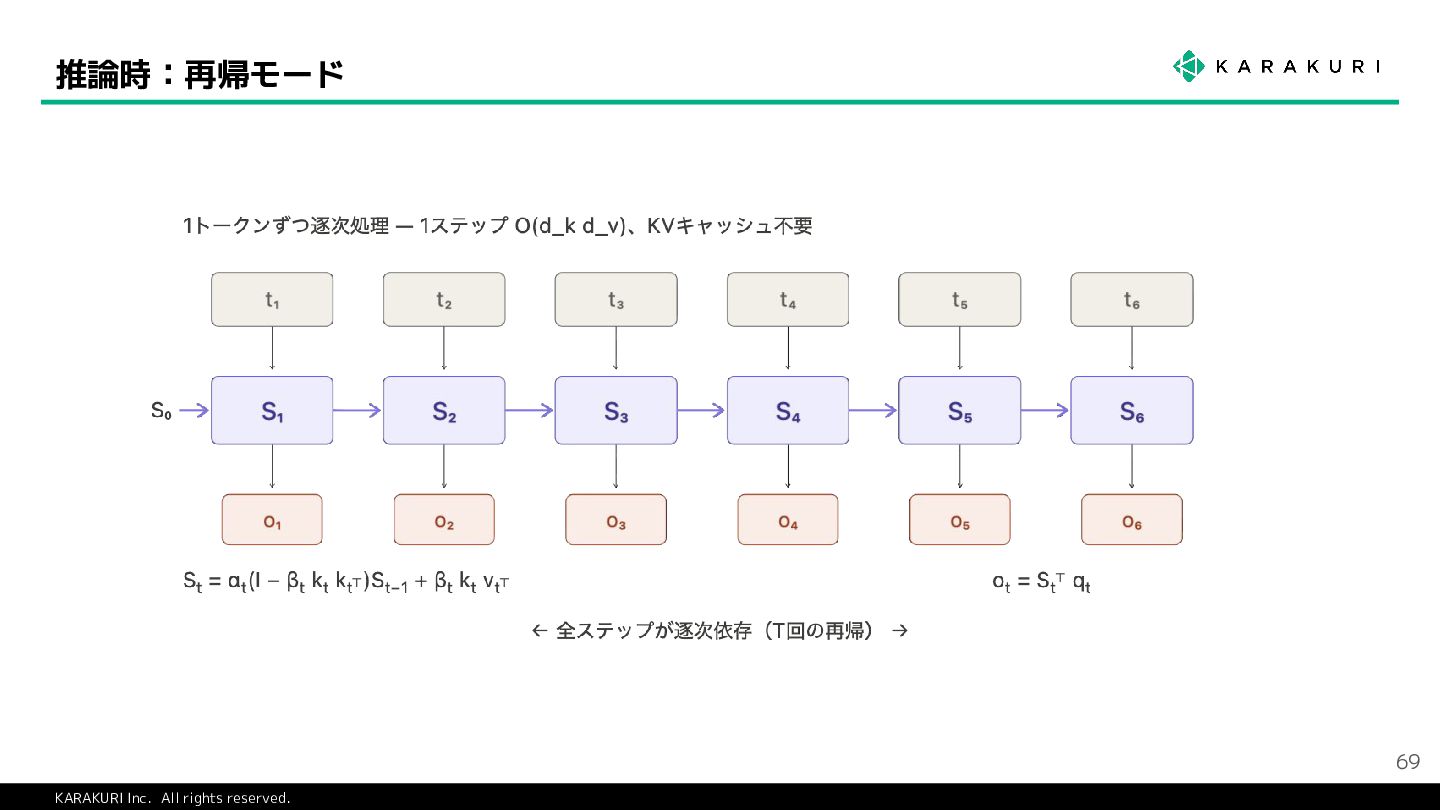{kind=link}
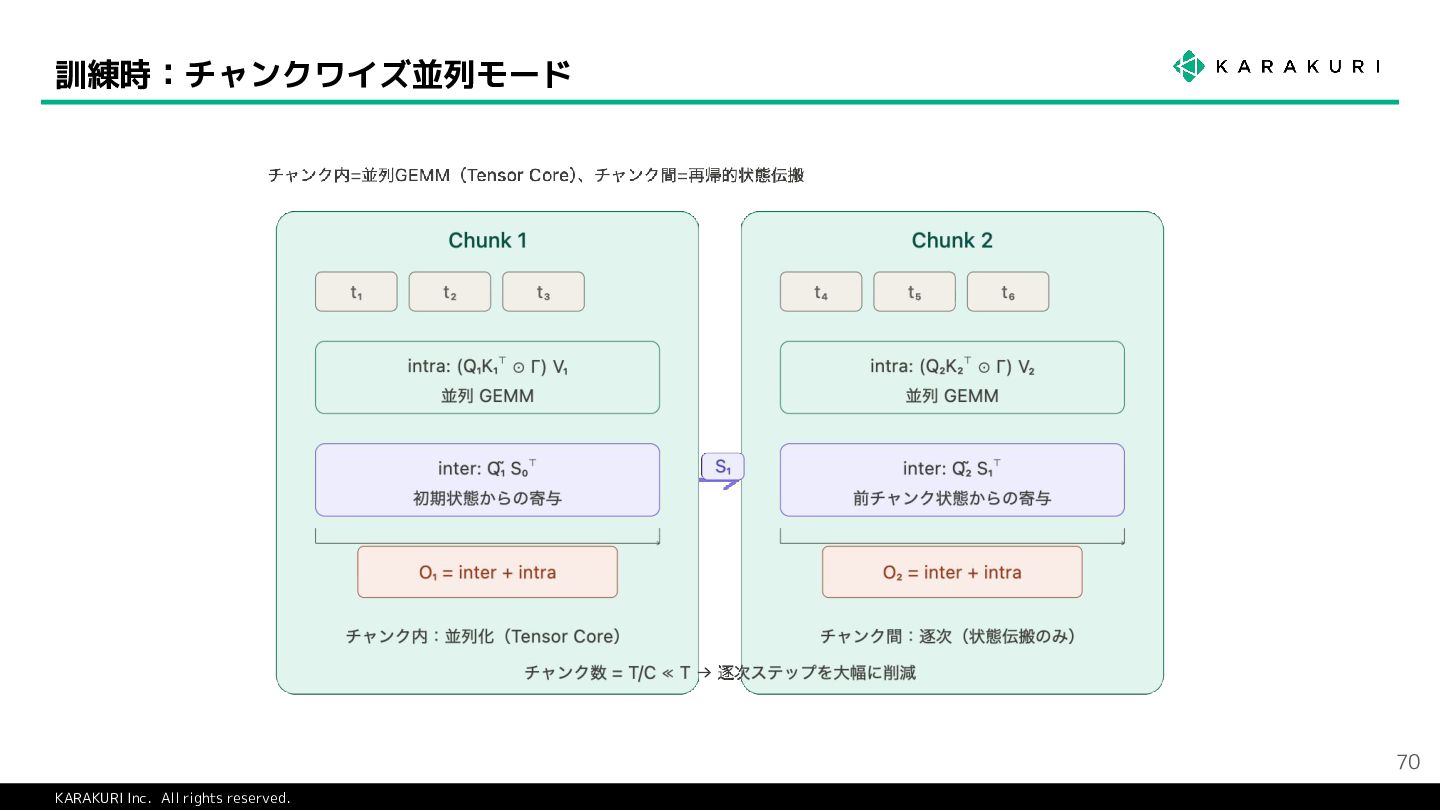{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}