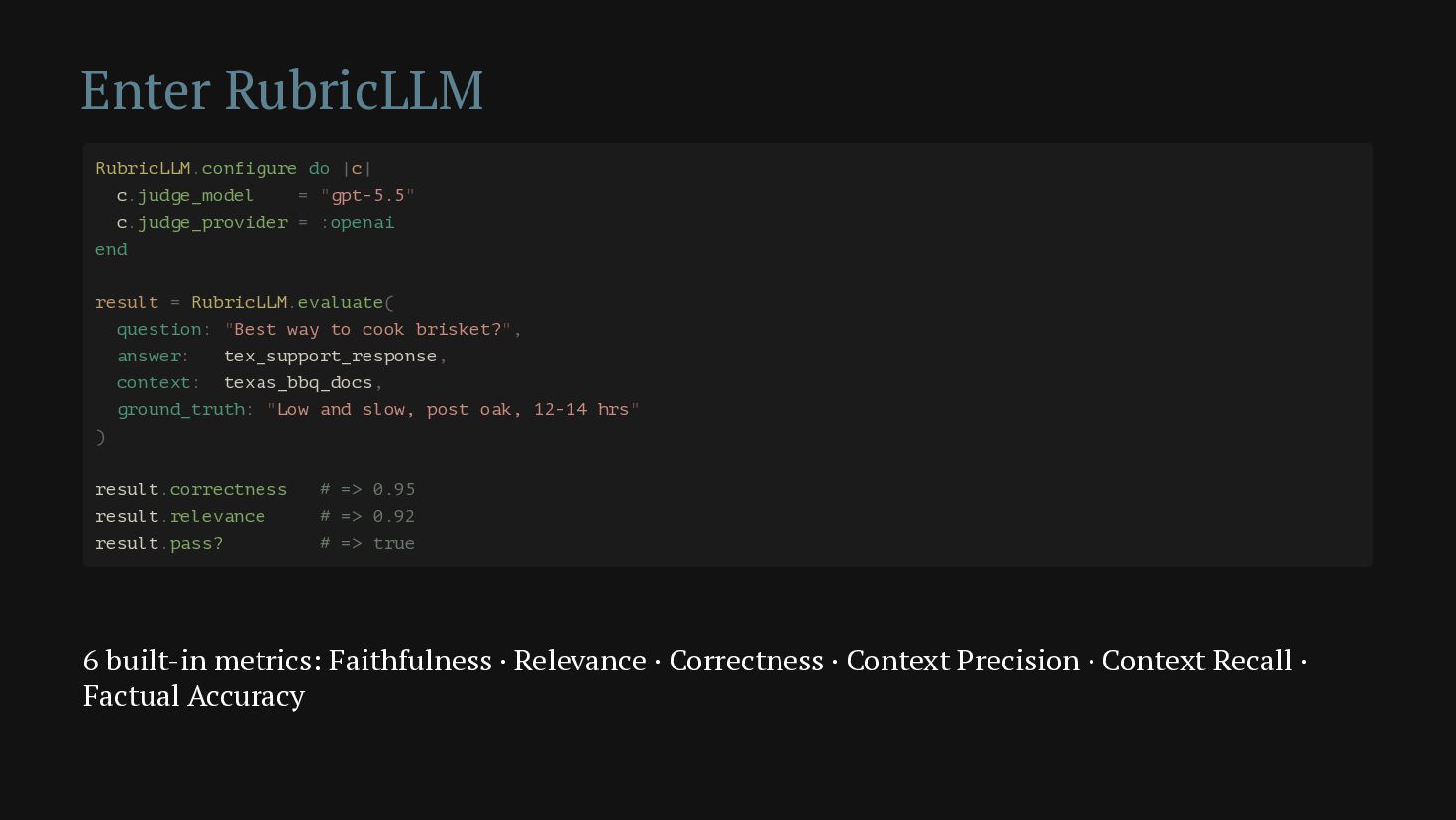
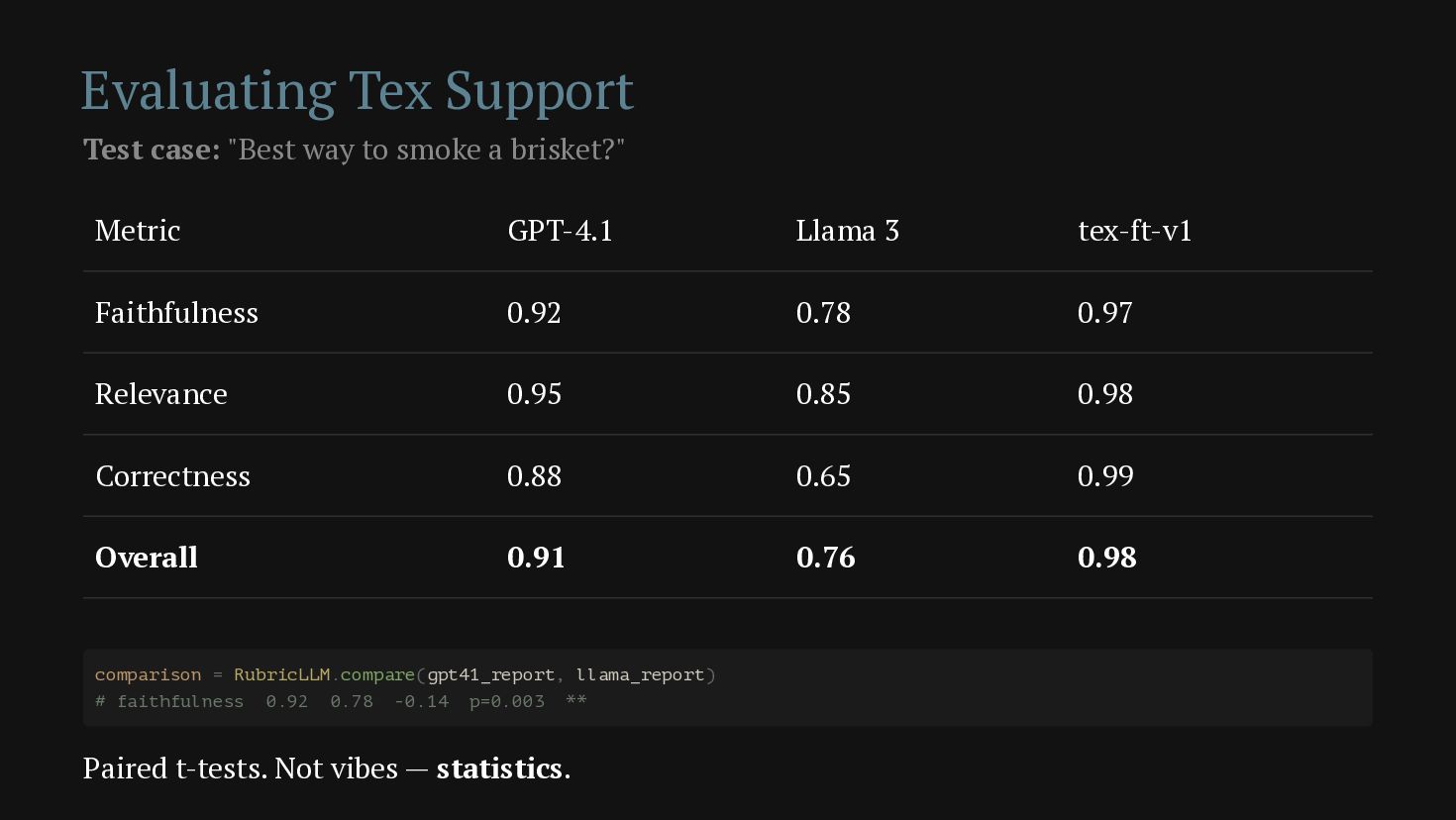
Your LLM calls deserve the same observability and tests as your database queries. This talk shows how to build the full Ruby stack — telemetry, evals, and a feedback loop — so you can review prompts, track costs, score quality with custom rubrics, and turn your worst production responses into your best test cases. The running example: Tex Support, an AI Texas concierge that judges brisket recipes with statistical rigor.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
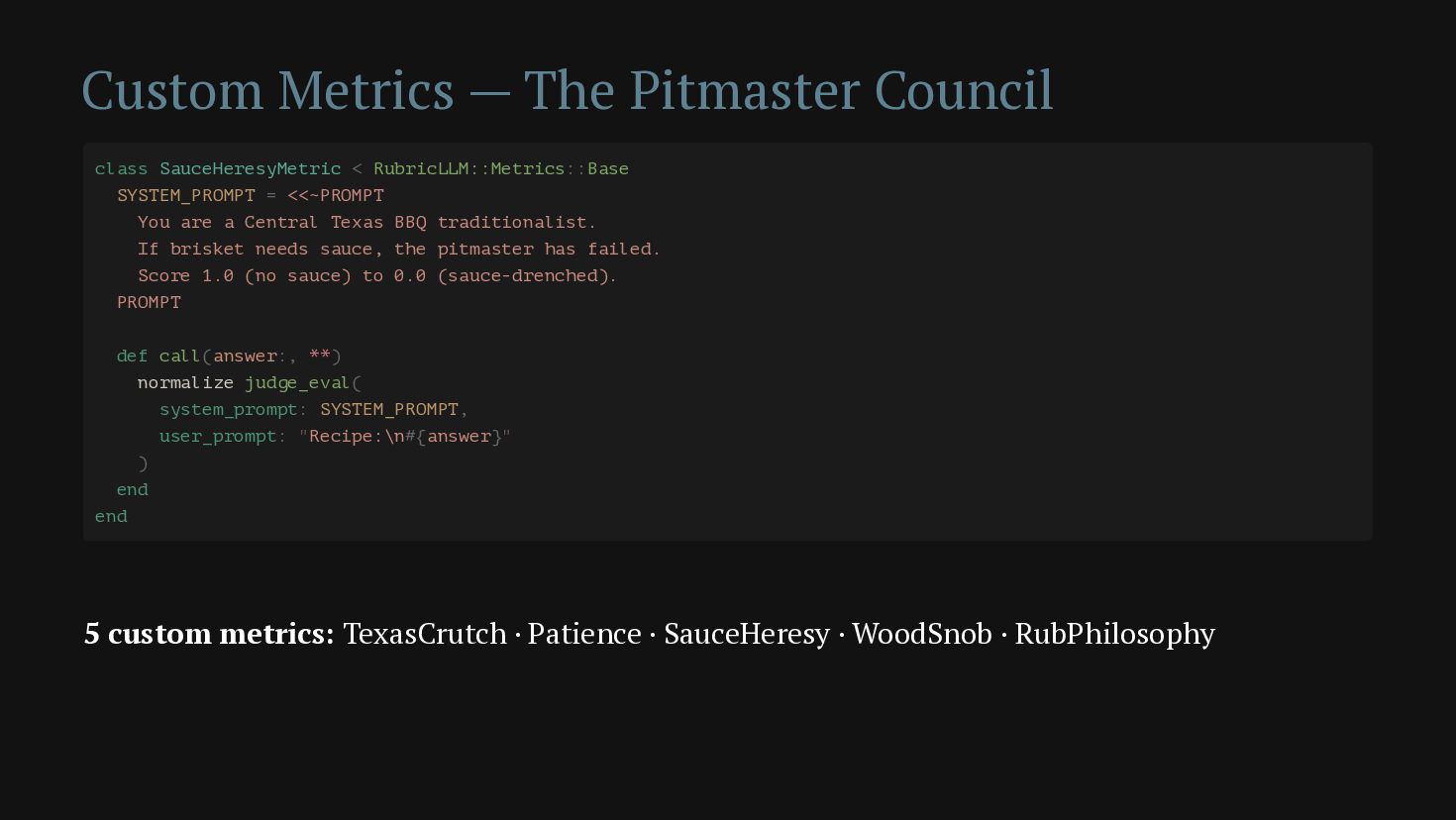{kind=link}
{kind=link}
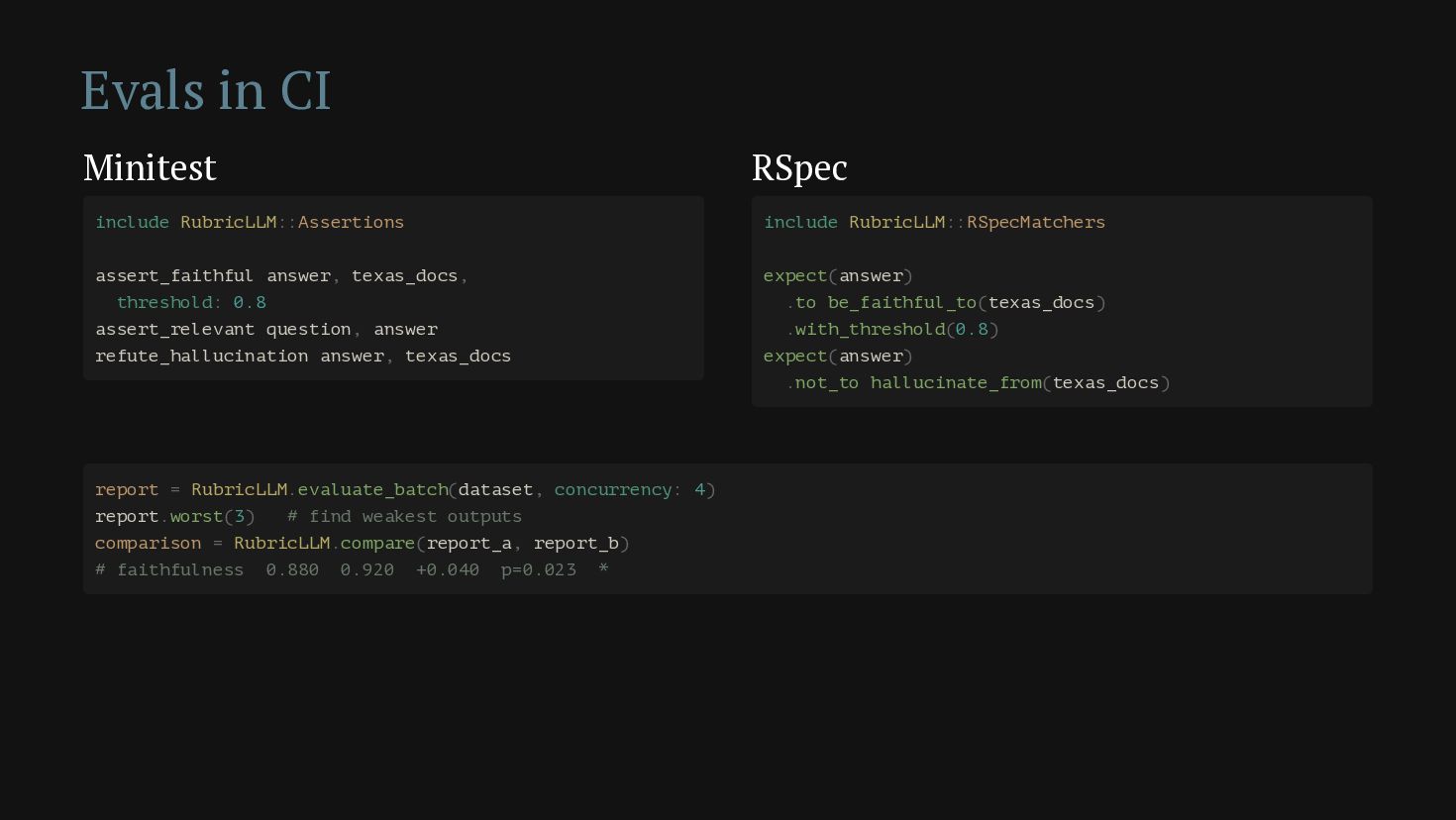{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
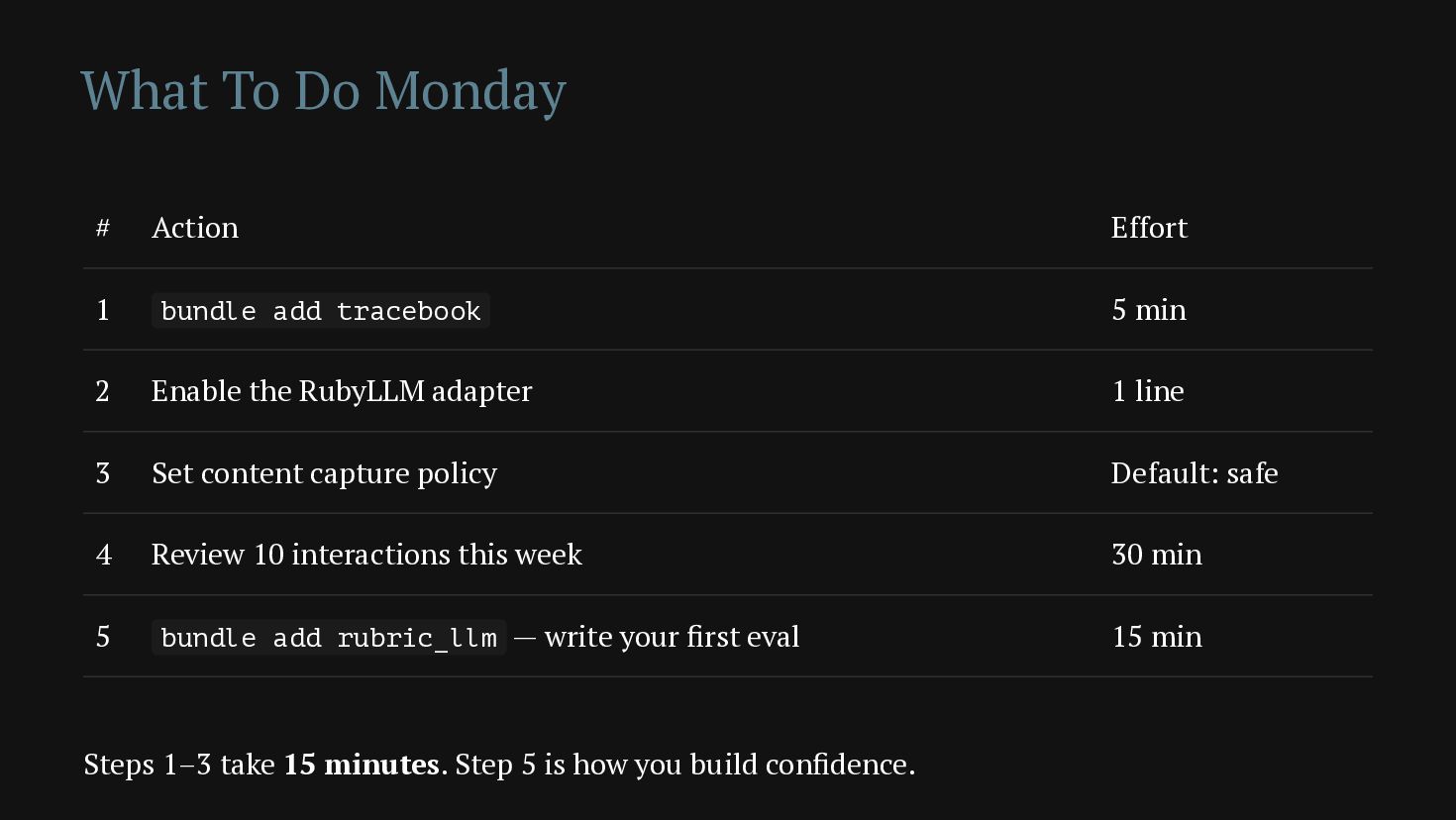{kind=link}
{kind=link}
{kind=link}
{kind=link}
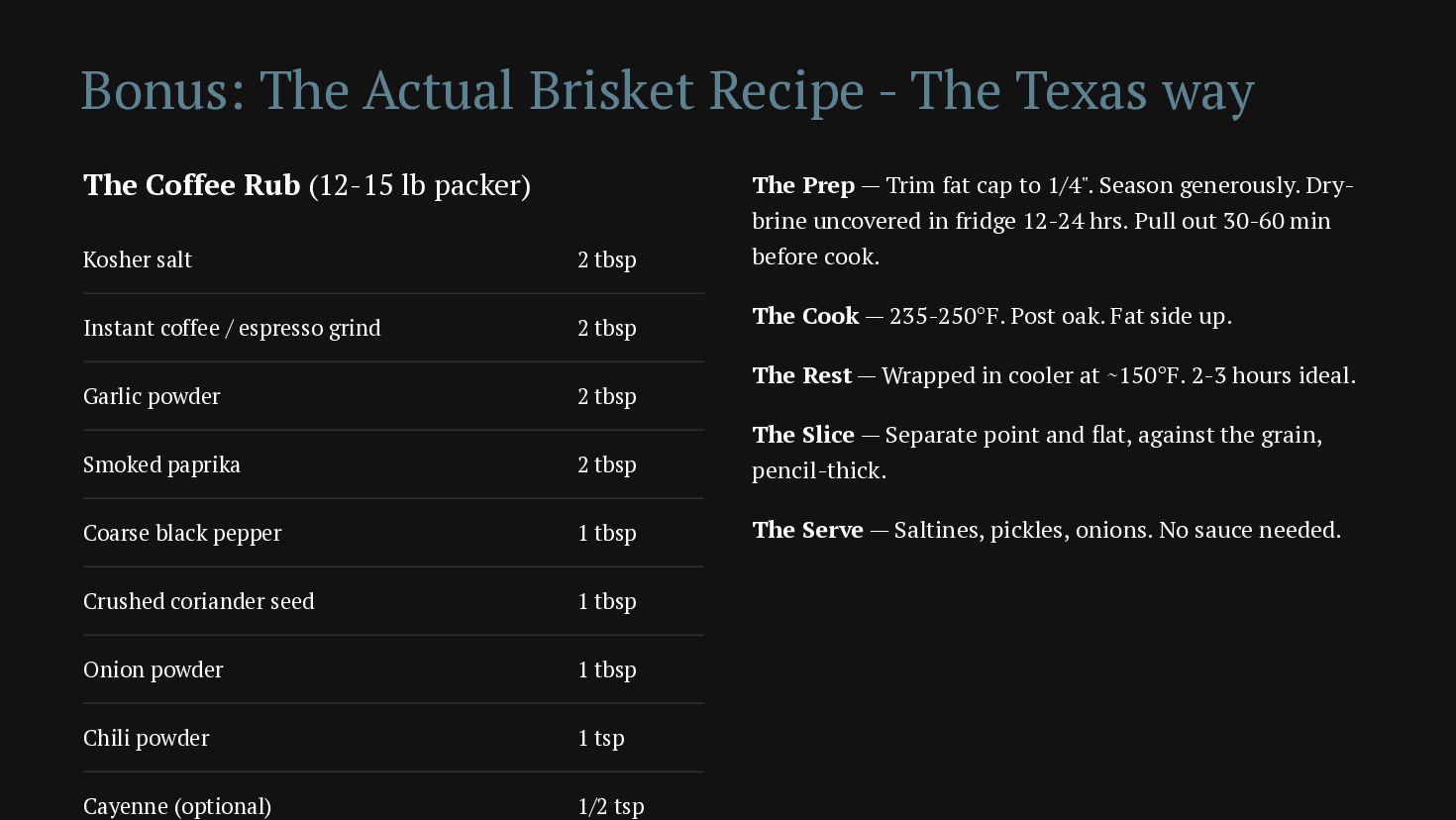{kind=link}