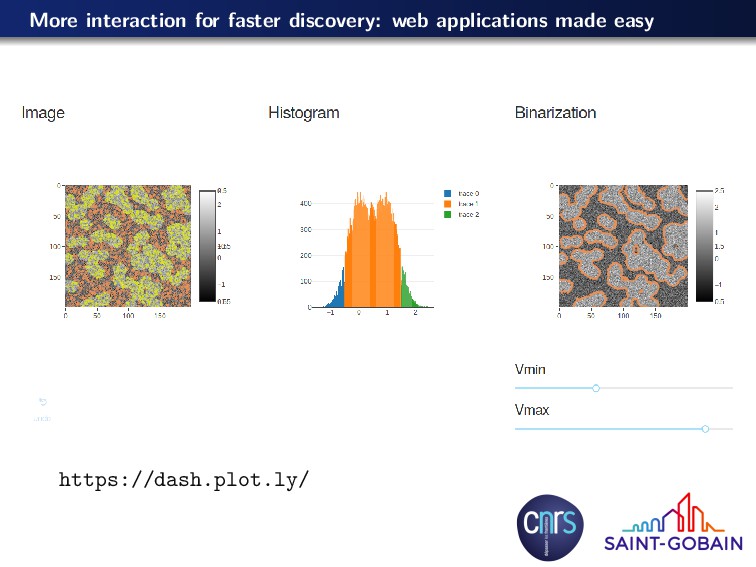
. callback ( dash . dependencies . Output ( ’ image−seg ’ , ’ f i g u r e ’ ) , [ dash . dependencies . Input ( ’ s l i d e r m i n ’ , ’ v a l u e ’ ) , dash . dependencies . Input ( ’ s l i d e r m a x ’ , ’ v a l u e ’ ) ] ) def update_figure ( v_min , v_max ) : mask = np . zeros ( img . shape , dtype=np . uint8 ) mask [ img < v_min ] = 1 mask [ img > v_max ] = 2 seg = segmentation . random_walker ( img , mask , mode=’← cg mg ’ ) r e t u r n { ’ data ’ : [ go . Heatmap ( z=img , colorscale=’ Greys ’ ) , go . Contour ( z=seg , ncontours=1, contours=d i c t ( start =1.5 , end =1.5 , coloring=’ l i n e s ’ ,) , line=d i c t ( width=3) ) ] }
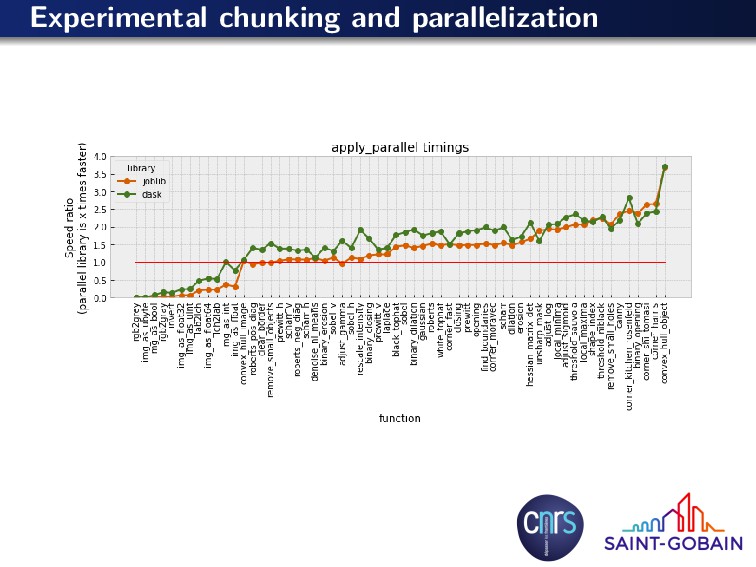
as np from sklearn . externals . joblib import Parallel , delayed def apply_parallel ( func , data , ∗args , chunk =100, overlap =10, n_jobs=4, ∗∗kwargs ) : ””” Apply a f u n c t i o n i n p a r a l l e l to o v e r l a p p i n g chunks of an a r r a y . j o b l i b i s used f o r p a r a l l e l p r o c e s s i n g . [ . . . ] Examples − − − − − − − − > > > from skimage import data , f i l t e r s > > > c o i n s = data . c o i n s () > > > r e s = a p p l y p a r a l l e l ( f i l t e r s . gaussian , coins , 2) ””” sh0 = data . shape [ 0 ] nb_chunks = sh0 // chunk end_chunk = sh0 % chunk arg_list = [ data [ max (0 , i∗chunk − overlap ) : min (( i+1)∗chunk + overlap , sh0 ) ] f o r i i n range (0 , nb_chunks ) ] i f end_chunk > 0 : arg_list . append ( data[−end_chunk − overlap : ] ) res_list = Parallel ( n_jobs=n_jobs ) ( delayed ( func ) ( sub_im , ∗args , ∗∗kwargs ) f o r sub_im i n arg_list ) output_dtype = res_list [ 0 ] . dtype out_data = np . empty ( data . shape , dtype=output_dtype ) f o r i i n range (1 , nb_chunks ) : out_data [ i∗chunk : ( i+1)∗chunk ] = res_list [ i ] [ overlap : overlap+chunk ] out_data [ : chunk ] = res_list [0][: − overlap ] i f end_chunk > 0 : out_data[−end_chunk : ] = res_list [ −1][ overlap : ] r e t u r n out_data
{kind=link}
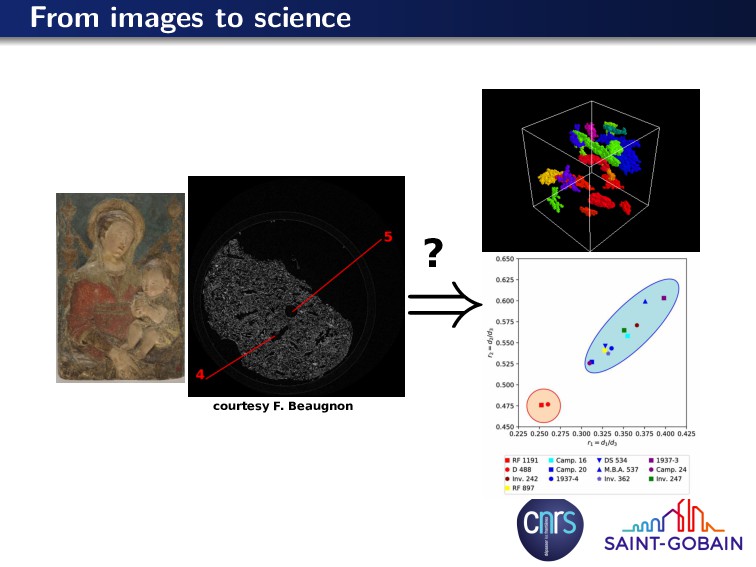{kind=link}
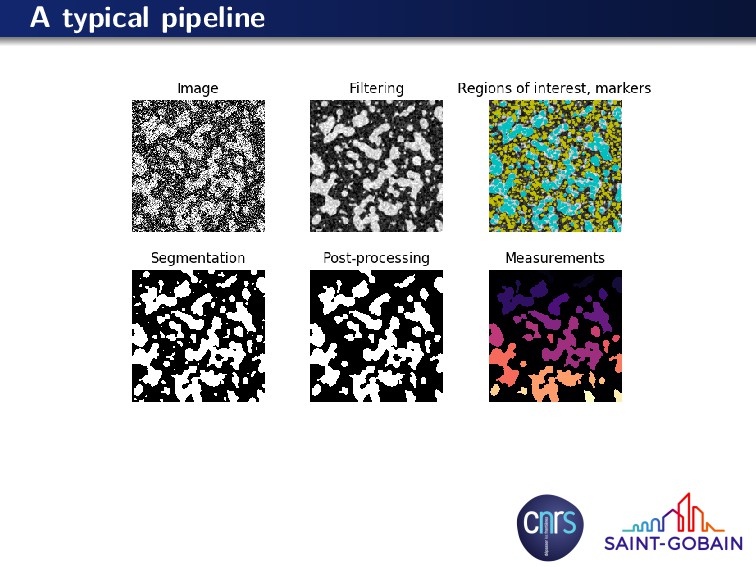{kind=link}
{kind=link}
{kind=link}
{kind=link}
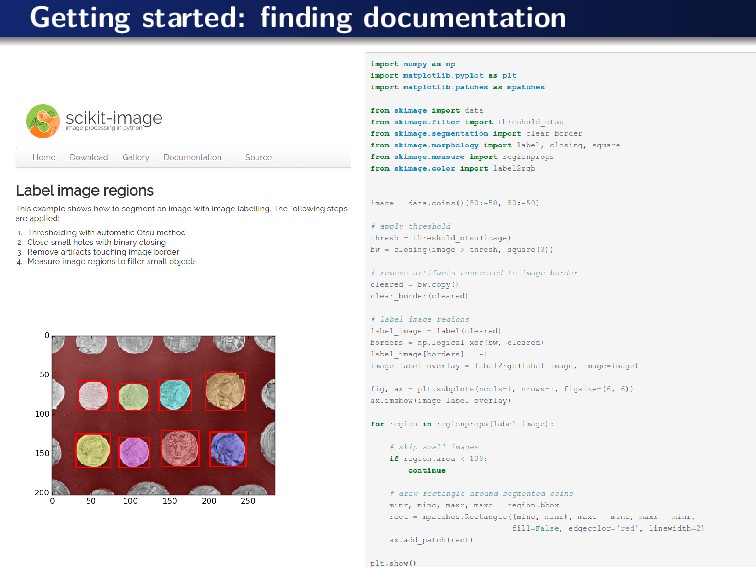{kind=link}
{kind=link}
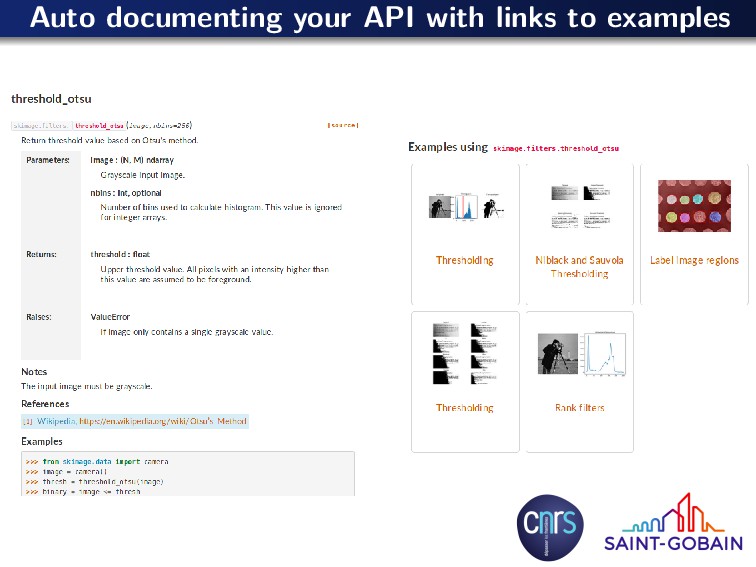{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
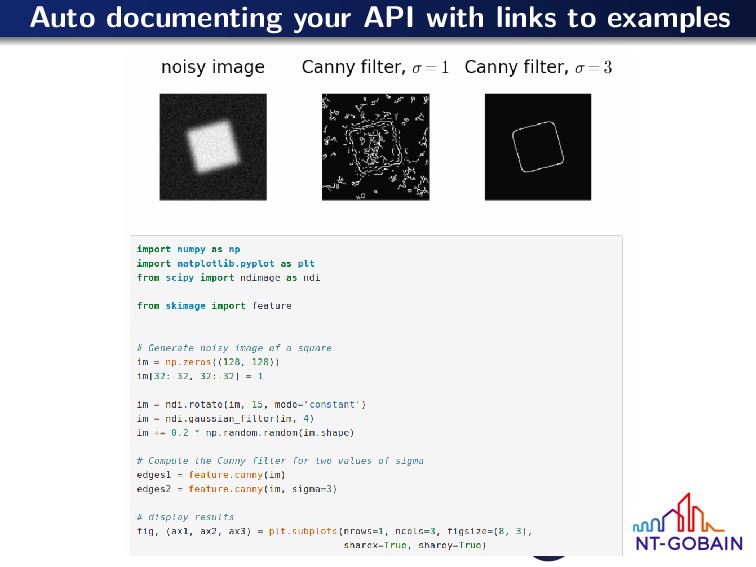
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}