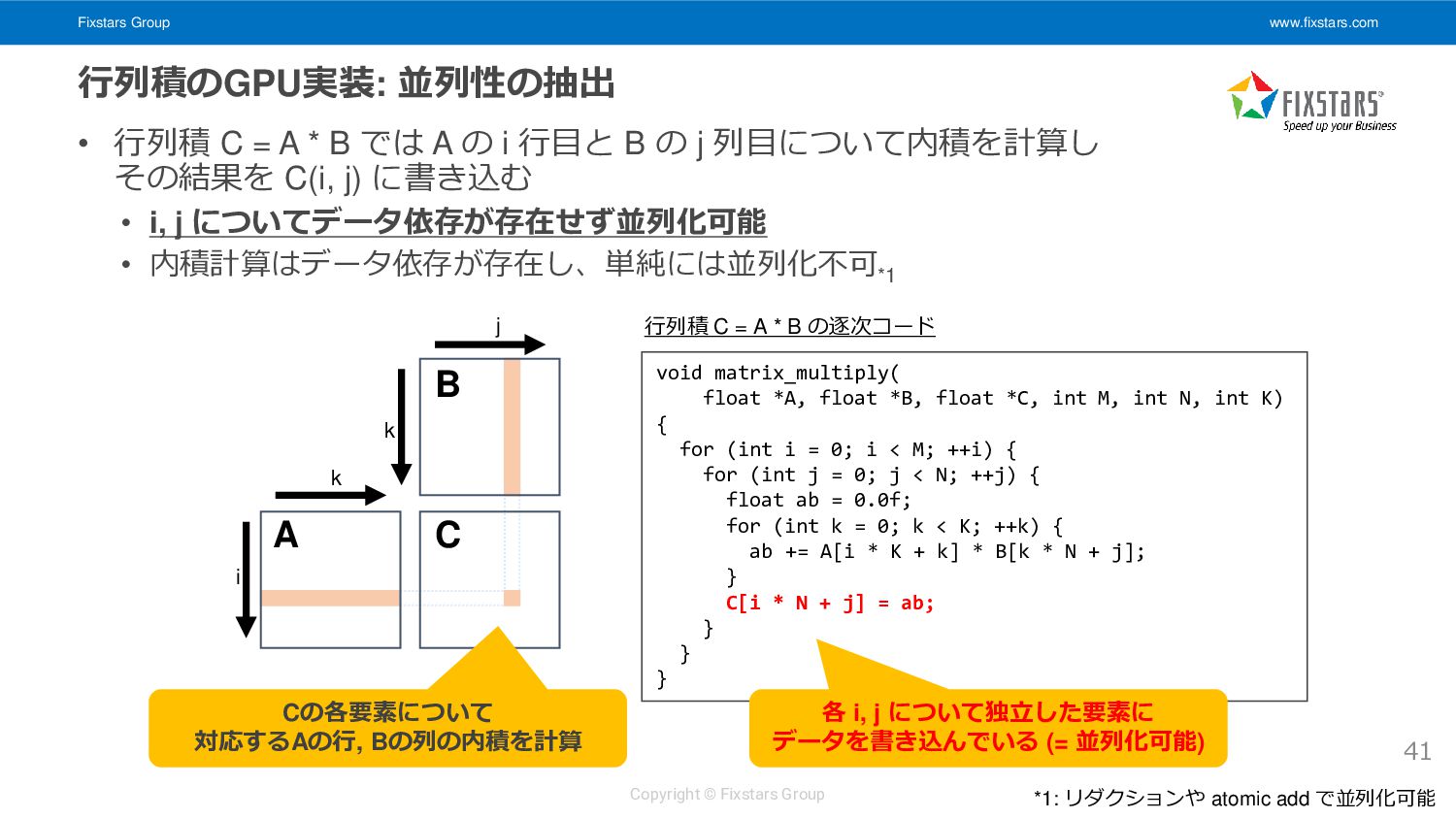
行列積 C = A * B では A の i 行目と B の j 列目について内積を計算し その結果を C(i, j) に書き込む • i, j についてデータ依存が存在せず並列化可能 • 内積計算はデータ依存が存在し、単純には並列化不可 *1 41 void matrix_multiply( float *A, float *B, float *C, int M, int N, int K) { for (int i = 0; i < M; ++i) { for (int j = 0; j < N; ++j) { float ab = 0.0f; for (int k = 0; k < K; ++k) { ab += A[i * K + k] * B[k * N + j]; } C[i * N + j] = ab; } } } 行列積 C = A * B の逐次コード j i k k C A B Cの各要素について 対応するAの行, Bの列の内積を計算 各 i, j について独立した要素に データを書き込んでいる (= 並列化可能) *1: リダクションや atomic add で並列化可能
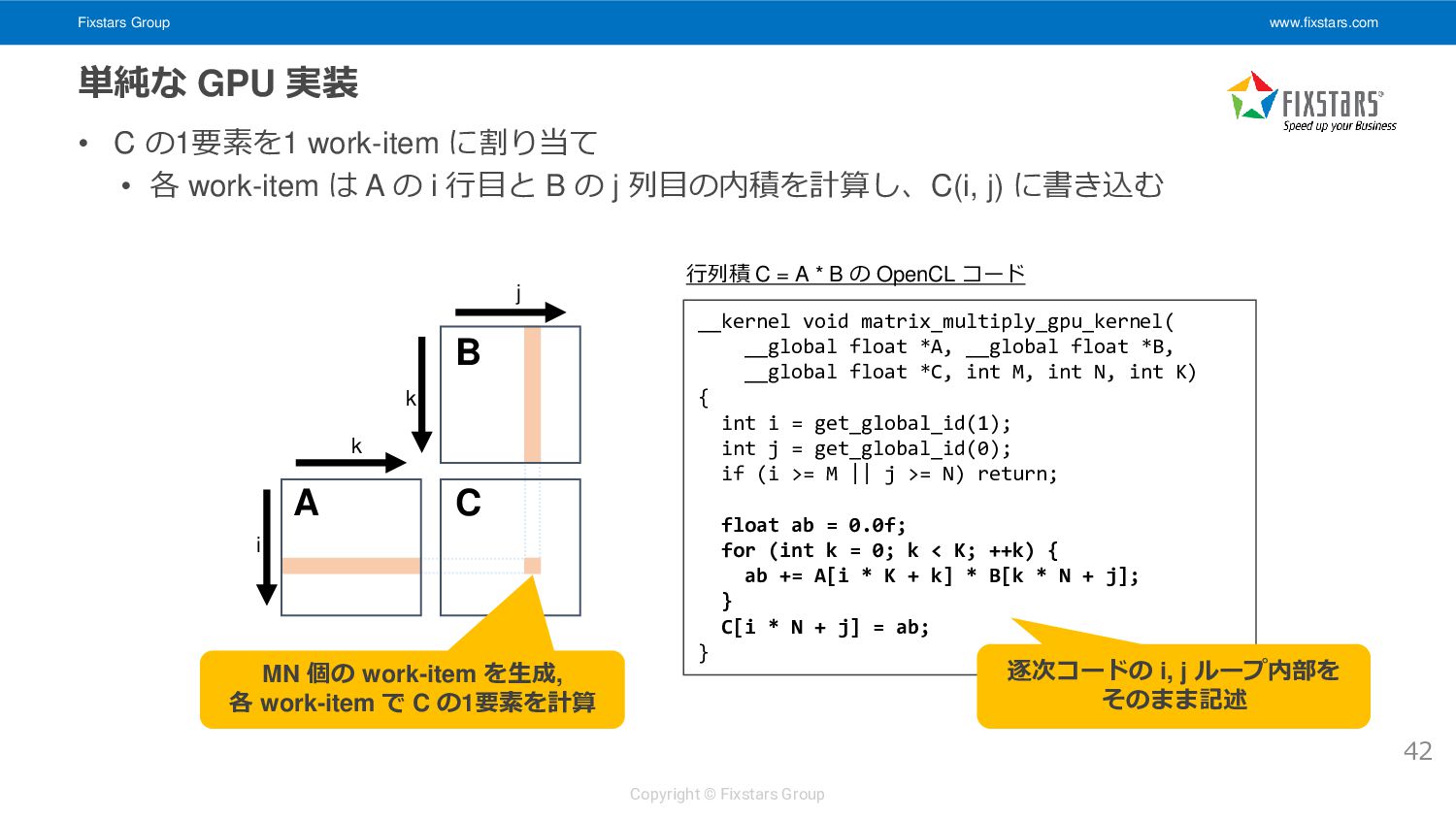
• C の1要素を1 work-item に割り当て • 各 work-item は A の i 行目と B の j 列目の内積を計算し、C(i, j) に書き込む 42 j i k k C A B __kernel void matrix_multiply_gpu_kernel( __global float *A, __global float *B, __global float *C, int M, int N, int K) { int i = get_global_id(1); int j = get_global_id(0); if (i >= M || j >= N) return; float ab = 0.0f; for (int k = 0; k < K; ++k) { ab += A[i * K + k] * B[k * N + j]; } C[i * N + j] = ab; } 行列積 C = A * B の OpenCL コード MN 個の work-item を生成, 各 work-item で C の1要素を計算 逐次コードの i, j ループ内部を そのまま記述
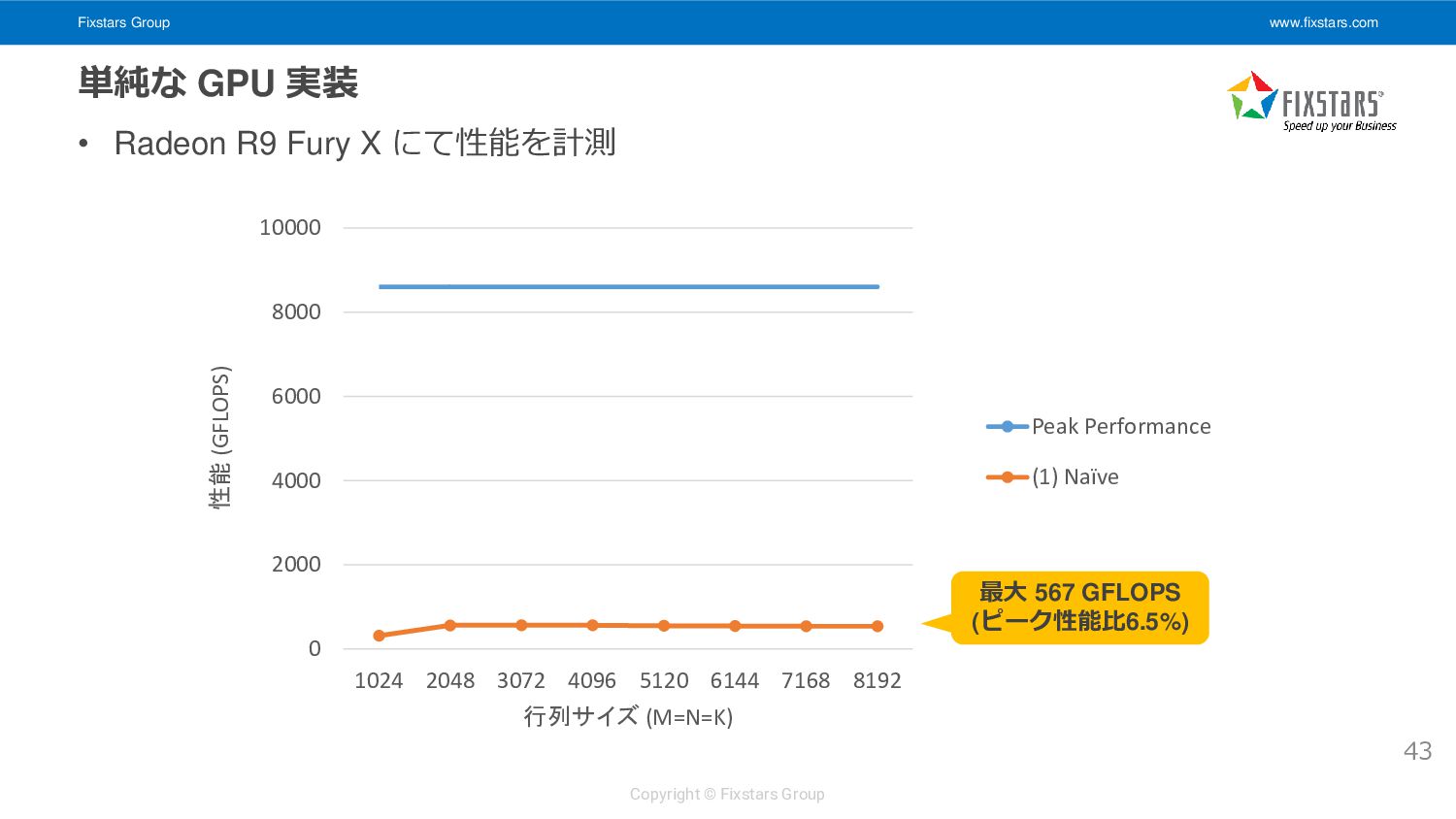
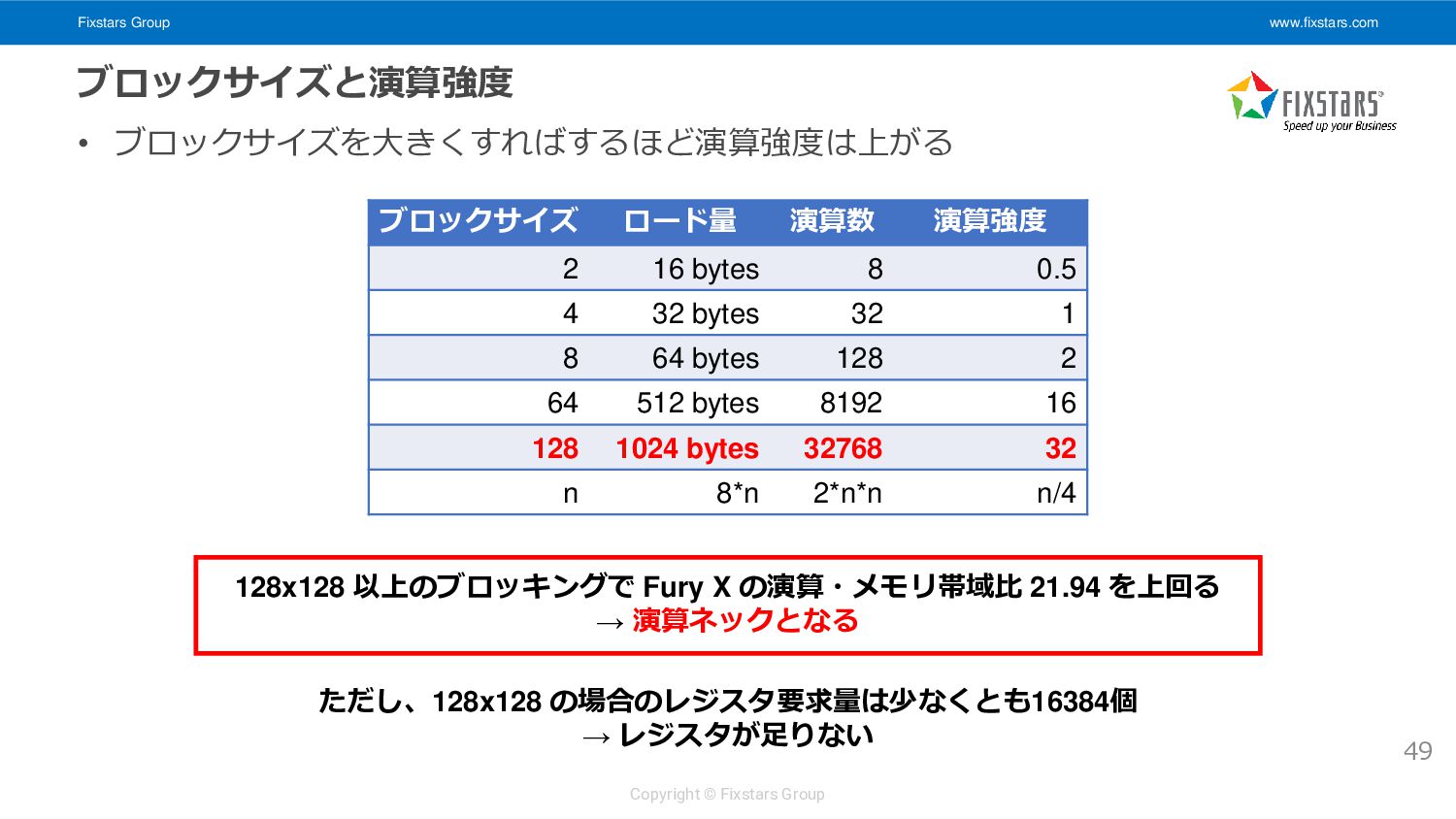
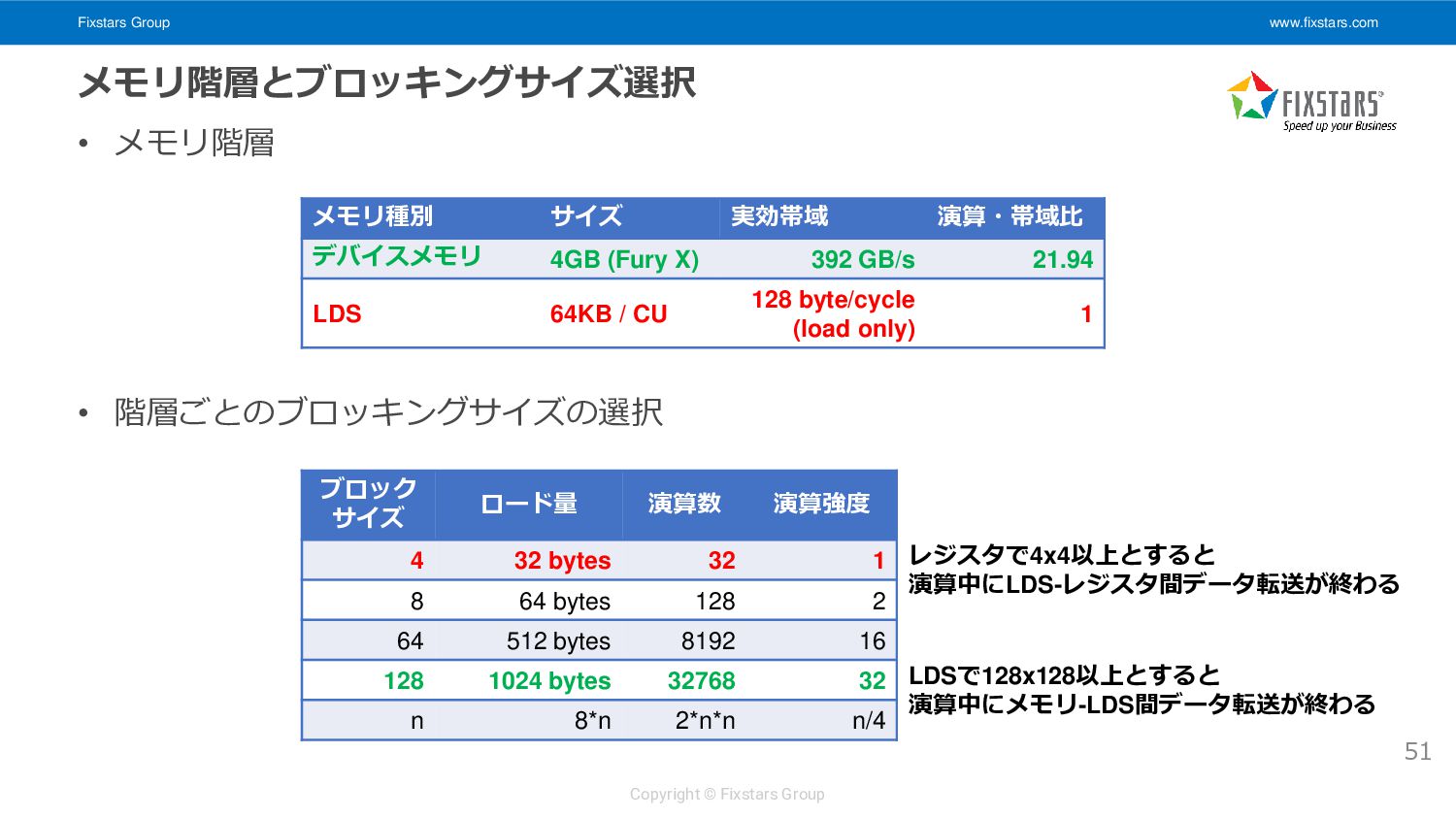
• 1 work-item あたりの演算数とメモリアクセス量を調べる 44 __kernel void matrix_multiply_gpu_kernel( __global float *A, __global float *B, __global float *C, int M, int N, int K) { int i = get_global_id(0); int j = get_global_id(1); if (i >= M || j >= N) return; float ab = 0.0f; for (int k = 0; k < K; ++k) { ab += A[i * K + k] * B[k * N + j]; } C[i * N + j] = ab; } ロード 2K回, 浮動小数点演算: 2K回 (積+和), ストア: 1回 演算強度: 2K (2K + 1) ∗ sizeof(float) ≈ 0.25
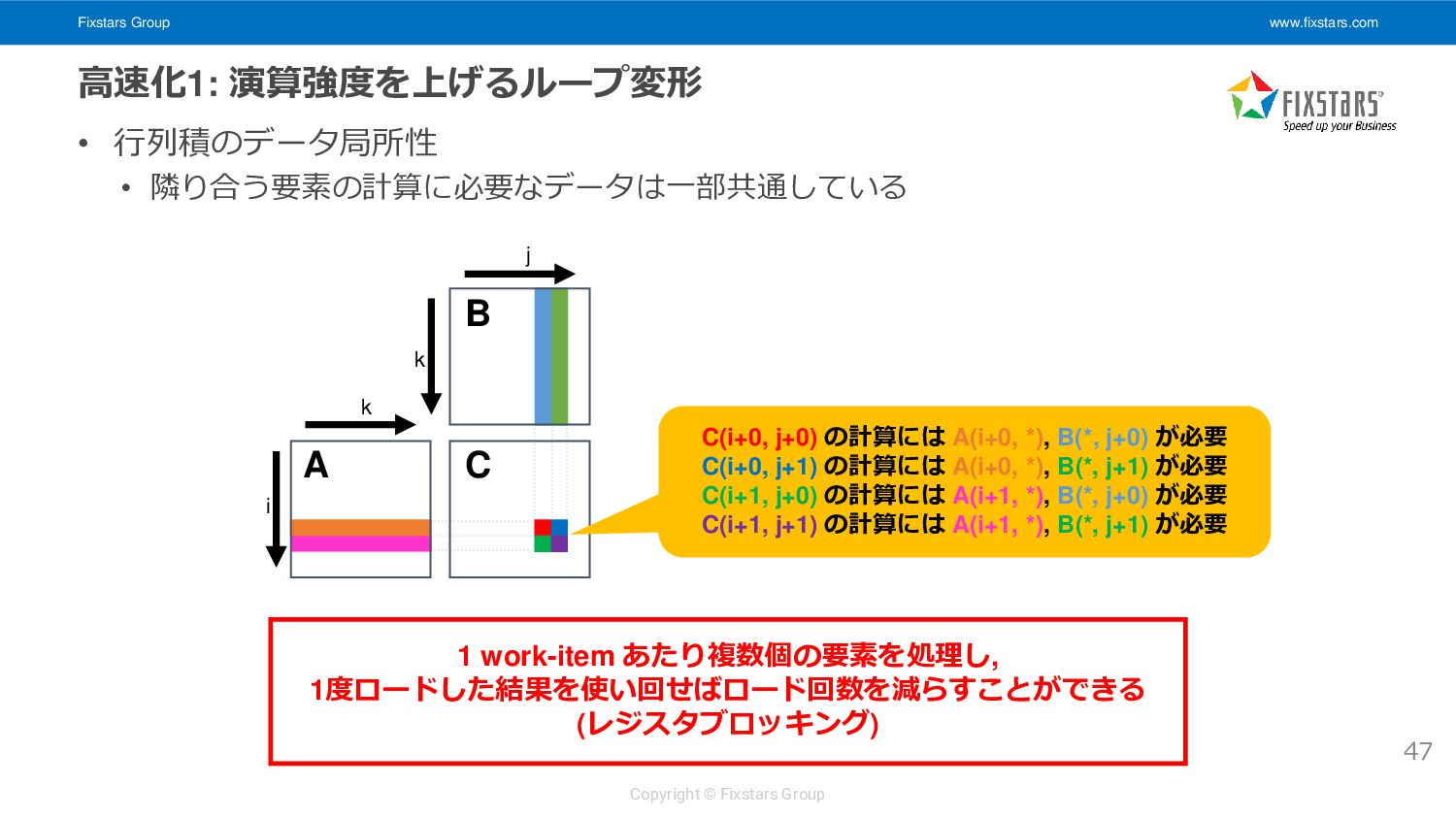
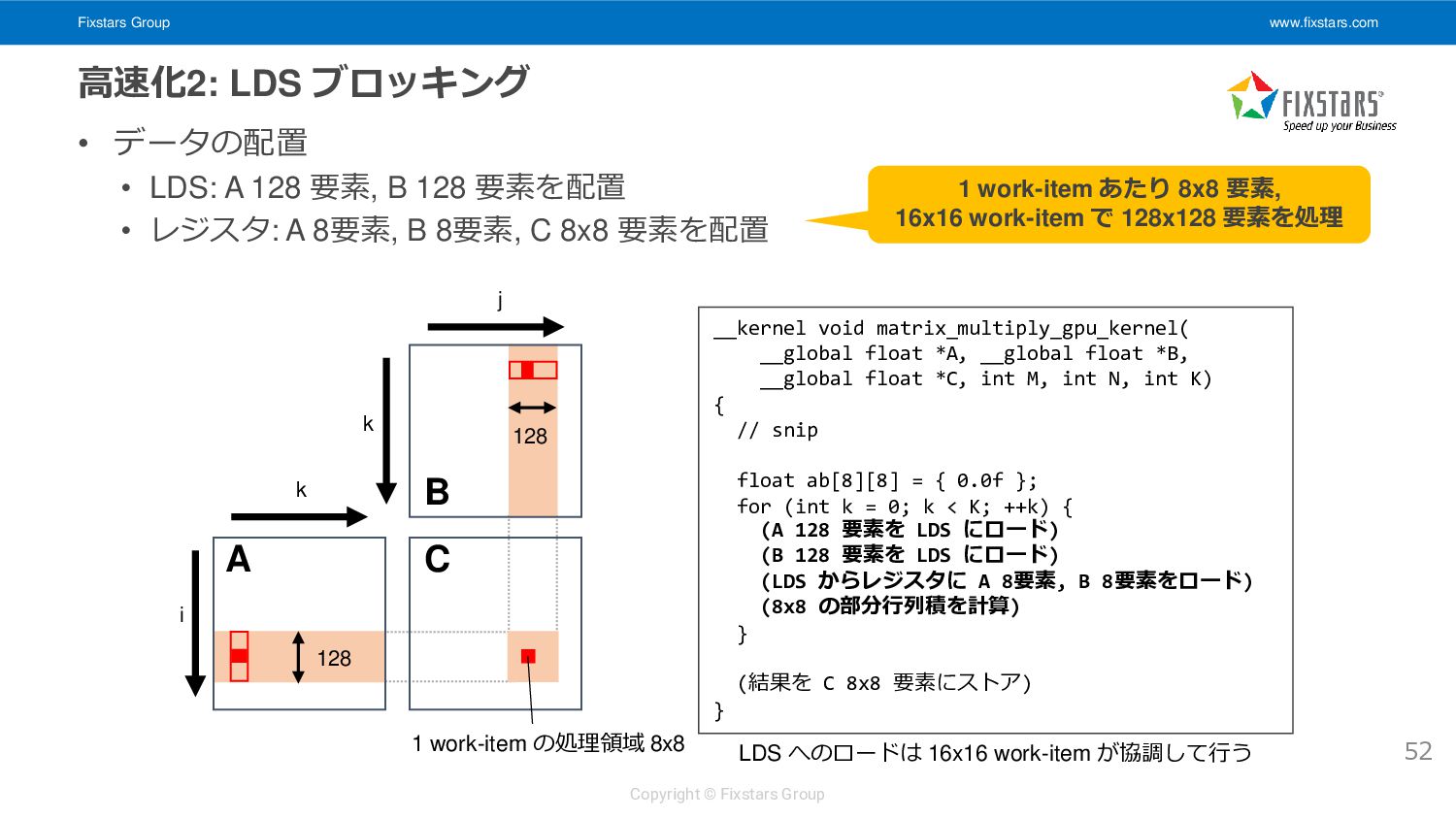
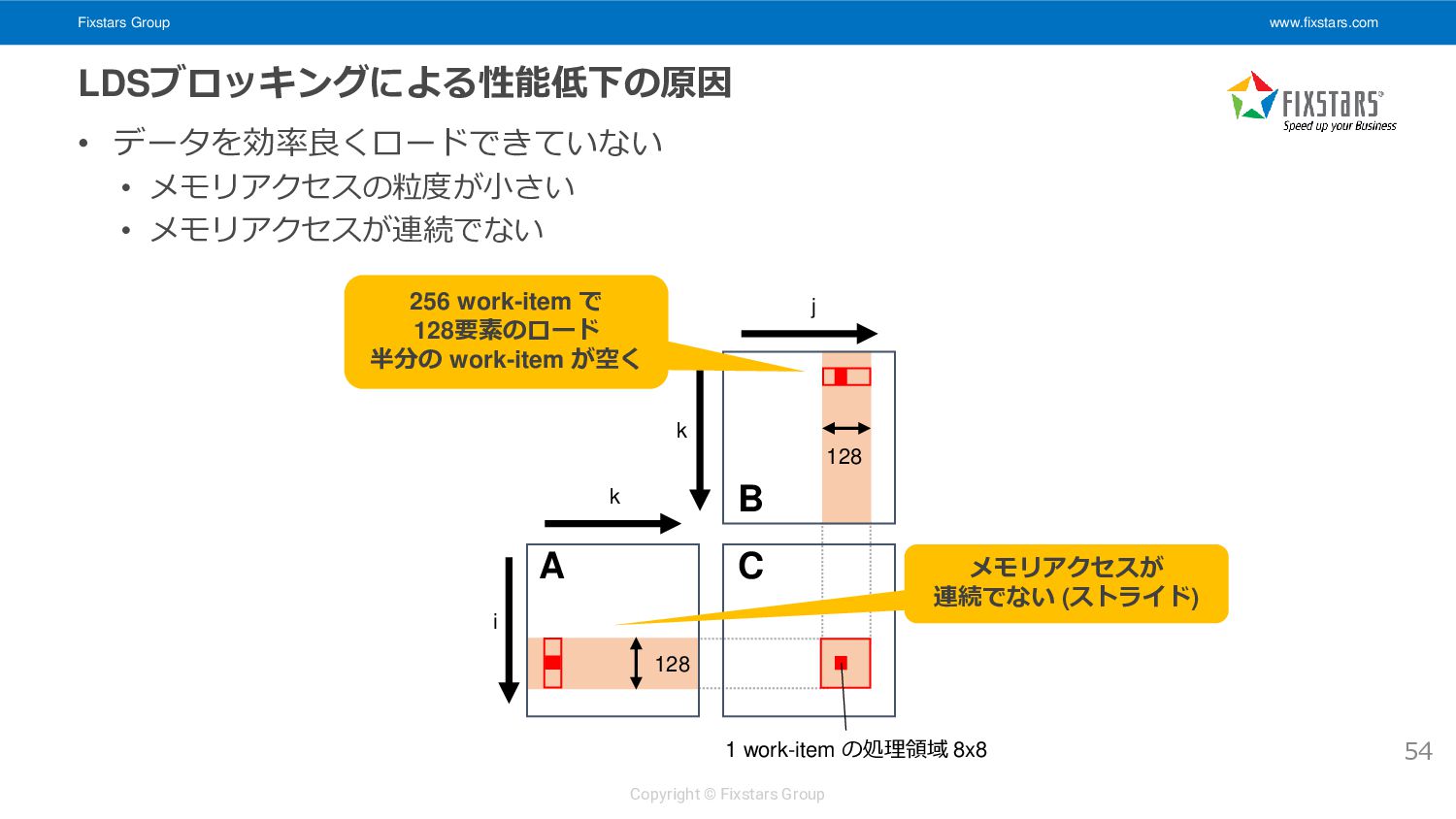
• データの配置 • LDS: A 128 要素, B 128 要素を配置 • レジスタ: A 8要素, B 8要素, C 8x8 要素を配置 52 i k k C A B 1 work-item の処理領域 8x8 j __kernel void matrix_multiply_gpu_kernel( __global float *A, __global float *B, __global float *C, int M, int N, int K) { // snip float ab[8][8] = { 0.0f }; for (int k = 0; k < K; ++k) { (A 128 要素を LDS にロード) (B 128 要素を LDS にロード) (LDS からレジスタに A 8要素, B 8要素をロード) (8x8 の部分行列積を計算) } (結果を C 8x8 要素にストア) } 128 128 1 work-item あたり 8x8 要素, 16x16 work-item で 128x128 要素を処理 LDS へのロードは 16x16 work-item が協調して行う
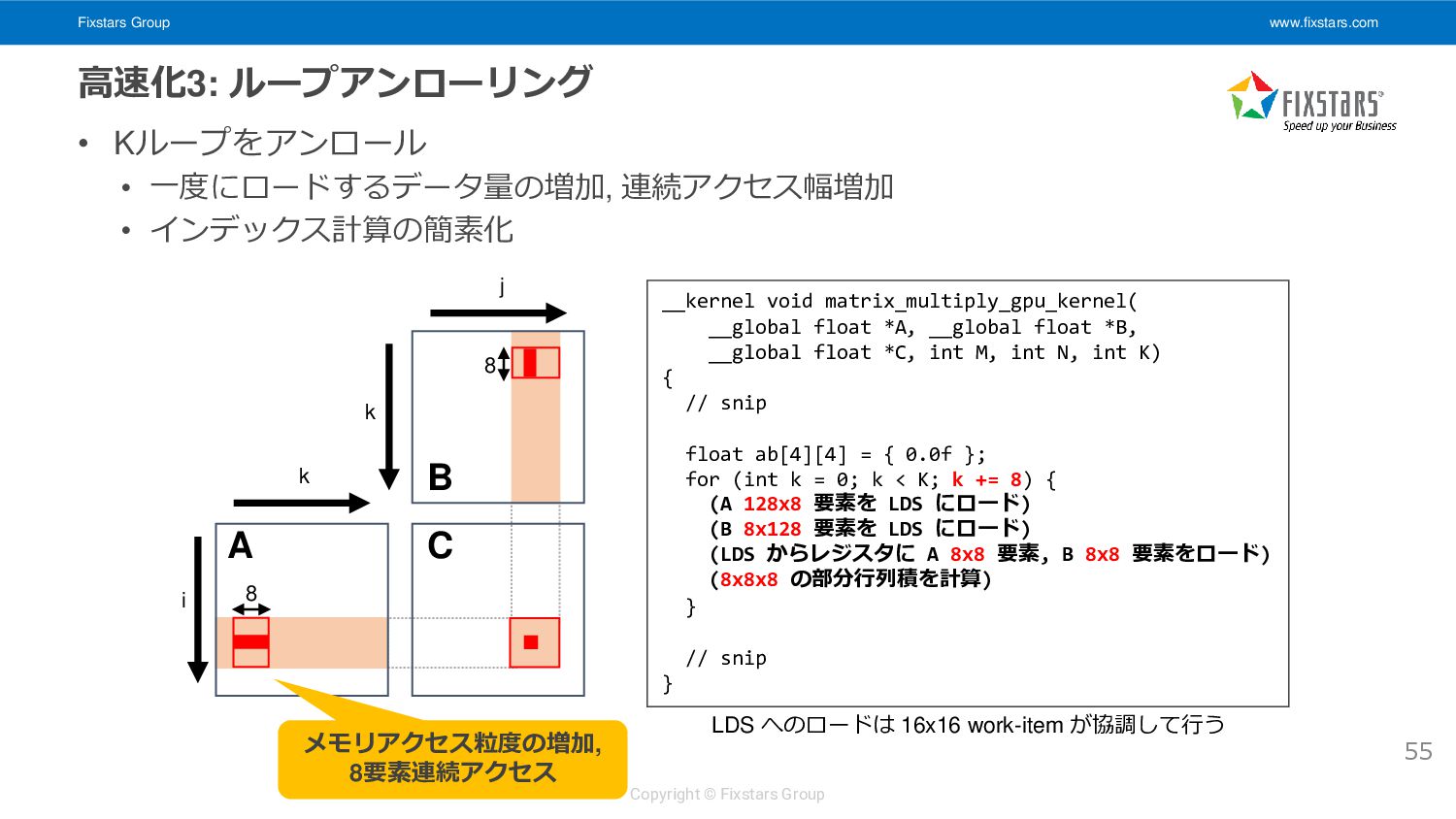
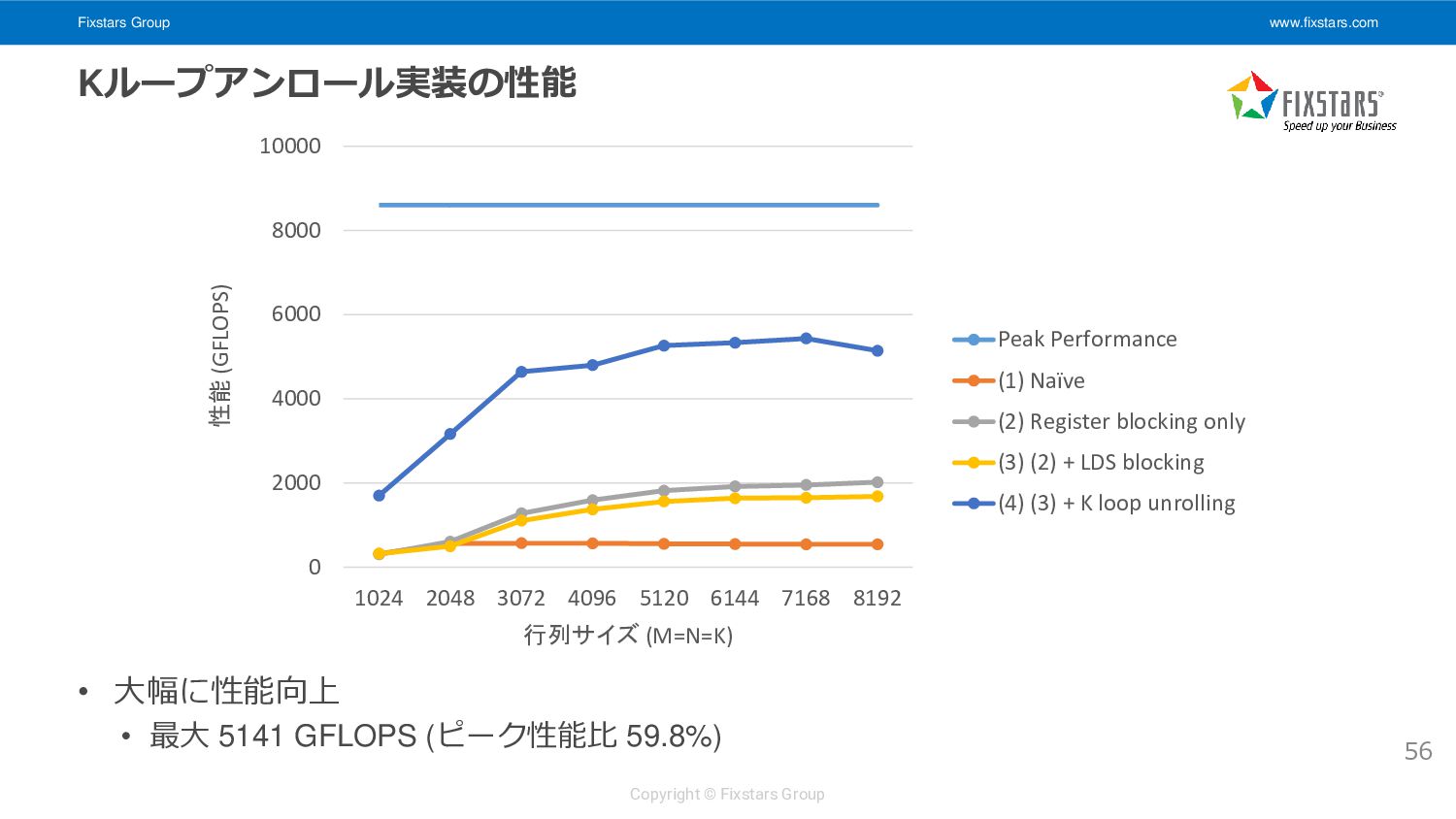
Kループをアンロール • 一度にロードするデータ量の増加, 連続アクセス幅増加 • インデックス計算の簡素化 55 i k k C A B j __kernel void matrix_multiply_gpu_kernel( __global float *A, __global float *B, __global float *C, int M, int N, int K) { // snip float ab[4][4] = { 0.0f }; for (int k = 0; k < K; k += 8) { (A 128x8 要素を LDS にロード) (B 8x128 要素を LDS にロード) (LDS からレジスタに A 8x8 要素, B 8x8 要素をロード) (8x8x8 の部分行列積を計算) } // snip } 8 8 LDS へのロードは 16x16 work-item が協調して行う メモリアクセス粒度の増加, 8要素連続アクセス
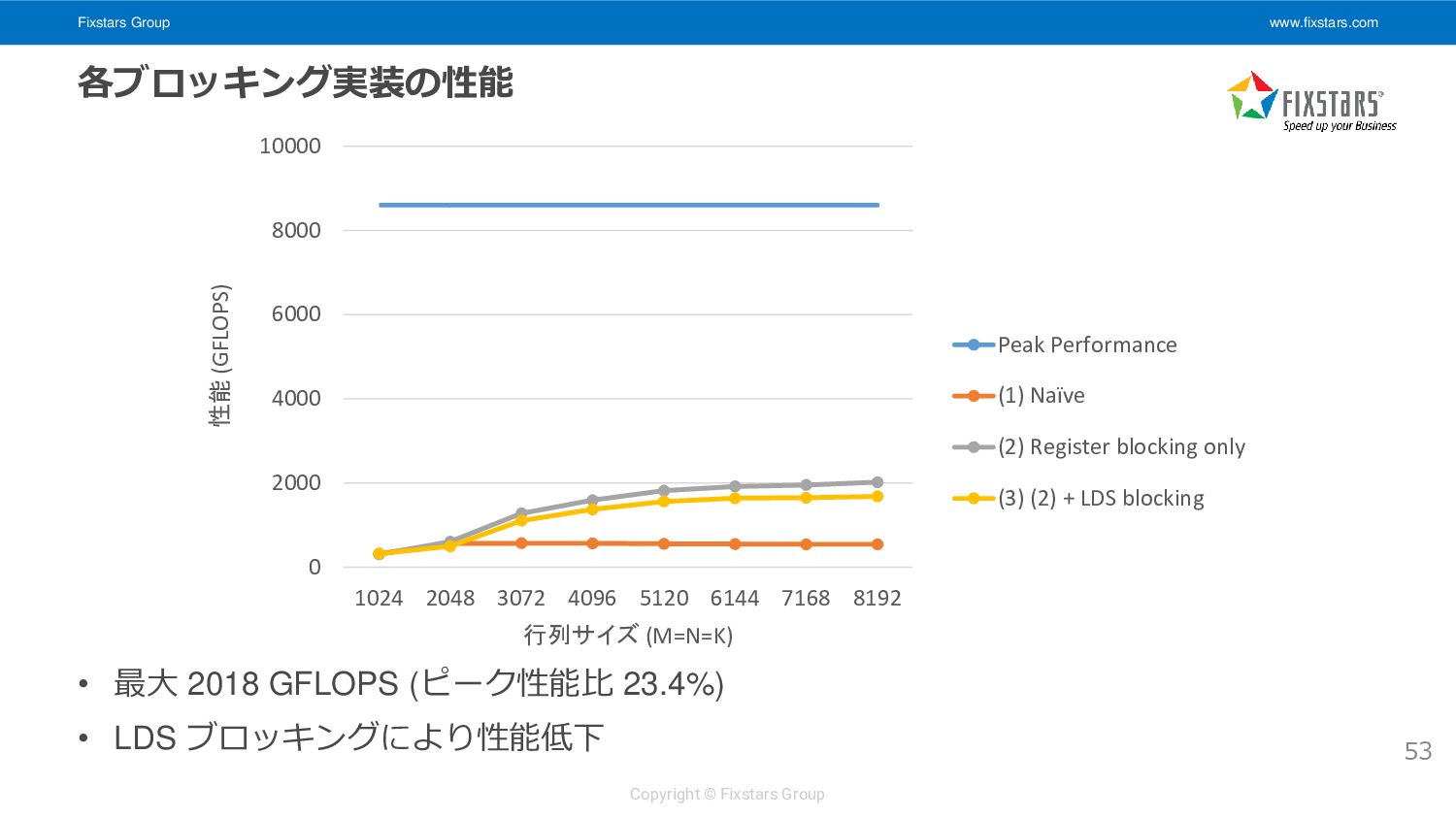
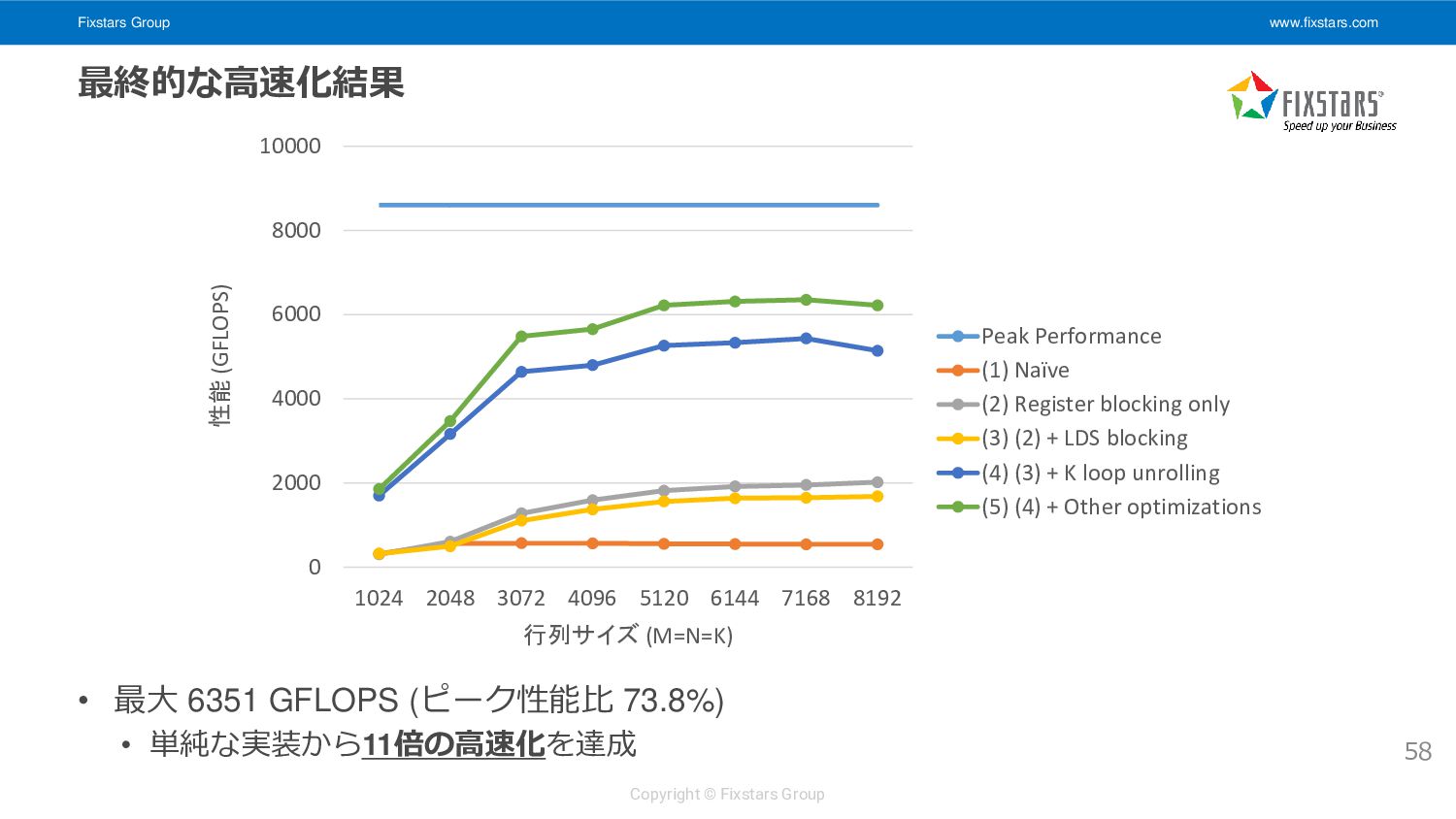
演算とデータ転送を同時に行う • LDS バッファを2つ用意し、片方のバッファを使って計算している間に もう片方のバッファにデータをロードする 57 __kernel void matrix_multiply_gpu_kernel( __global float *A, __global float *B, __global float *C, int M, int N, int K) { // snip int X = 0, Y = 1; (A, B 128x8 要素を LDS[X] にロード) float ab[4][4] = { 0.0f }; for (int k = 0; k < K; k += 8) { (次の A, B 128x8 要素をロード開始) (LDS[X] からレジスタに A 8要素, B 8要素をロード) (8x8x8 の部分行列積を計算) (A, B のロード完了を待ち、LDS[Y] にストア) X ^= 1, Y ^= 1; // バッファの入れ替え } // snip } k = i の計算中に k = i + 1 のロードを 先行して行う
Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) • White Paper | AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE • AMD Radeon™ HD 7970 with graphics core next (GCN) architecture. Hot Chips 24. https://ieeexplore.ieee.org/document/7476485 • AMD GRAPHIC CORE NEXT - AMD Developer Central http://developer.amd.com/wordpress/media/2013/06/2620_final.pdf • AMD GCN3 ISA Architecture Manual https://gpuopen.com/compute-product/amd-gcn3-isa-architecture-manual/ • AMDGPU Compute Application Binary Interface. https://github.com/ROCm-Developer-Tools/ROCm-ComputeABI- Doc/blob/master/AMDGPU-ABI.md • AMD Catalyst OpenCL 2.0 ABI description. https://github.com/CLRX/CLRX-mirror/wiki/AmdCl2Abi • Junjie Lai et al., “Performance Upper Bound Analysis and Optimization of SGEMM on Fermi and Kepler GPUs” • Scott Gray, “SGEMM · NervanaSystems/maxas Wiki · GitHub” https://github.com/NervanaSystems/maxas/wiki/SGEMM 61
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}