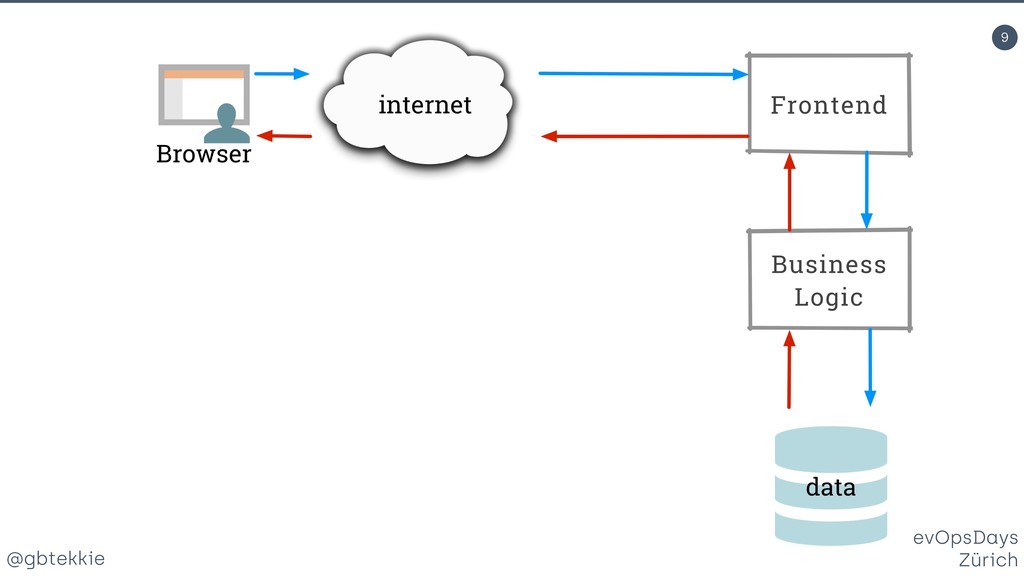
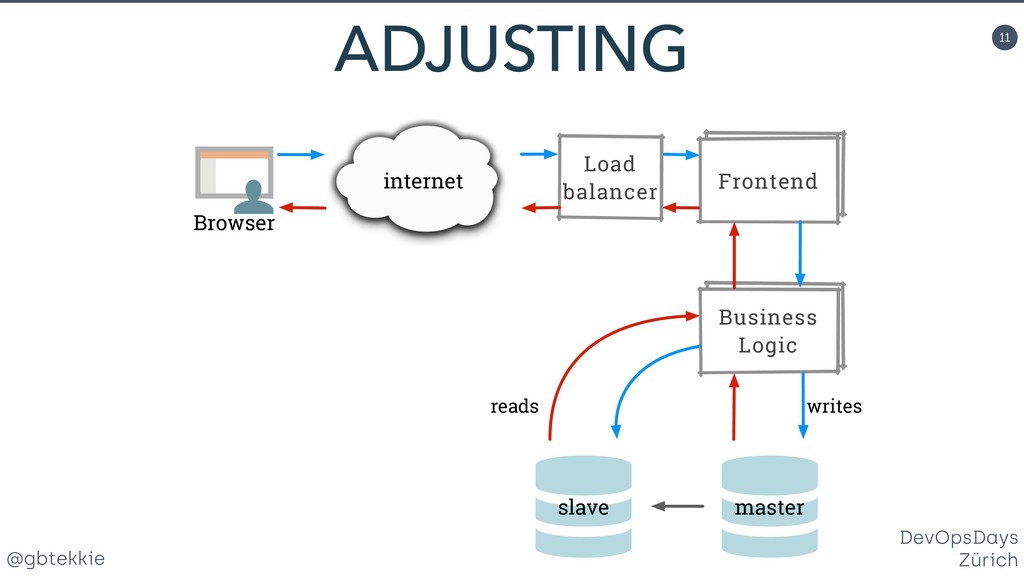
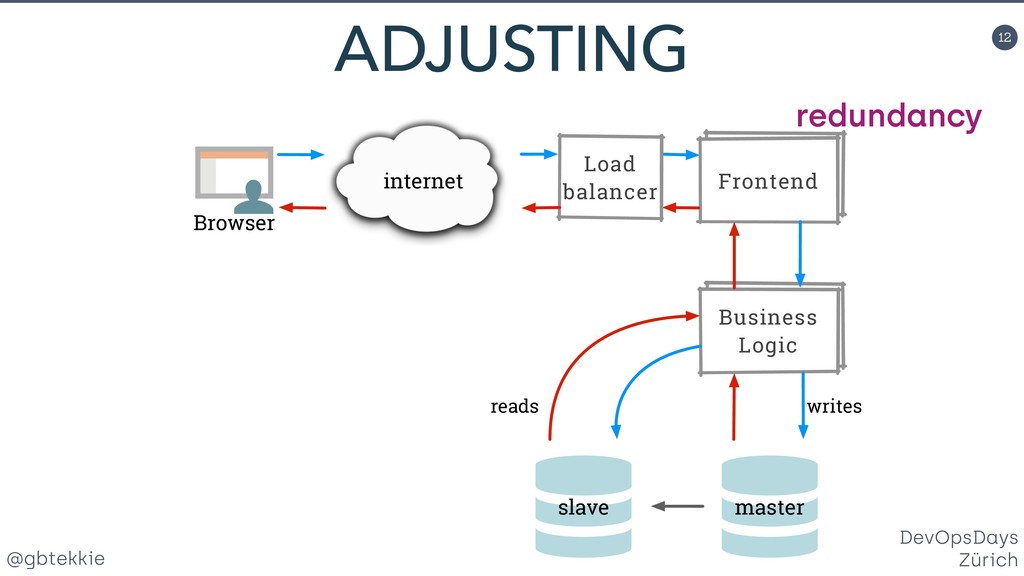
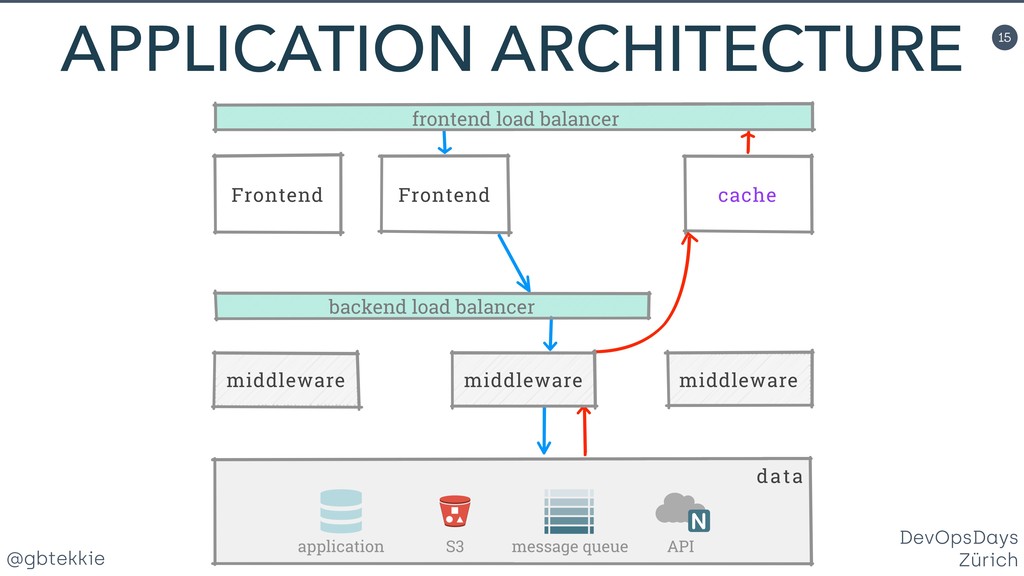
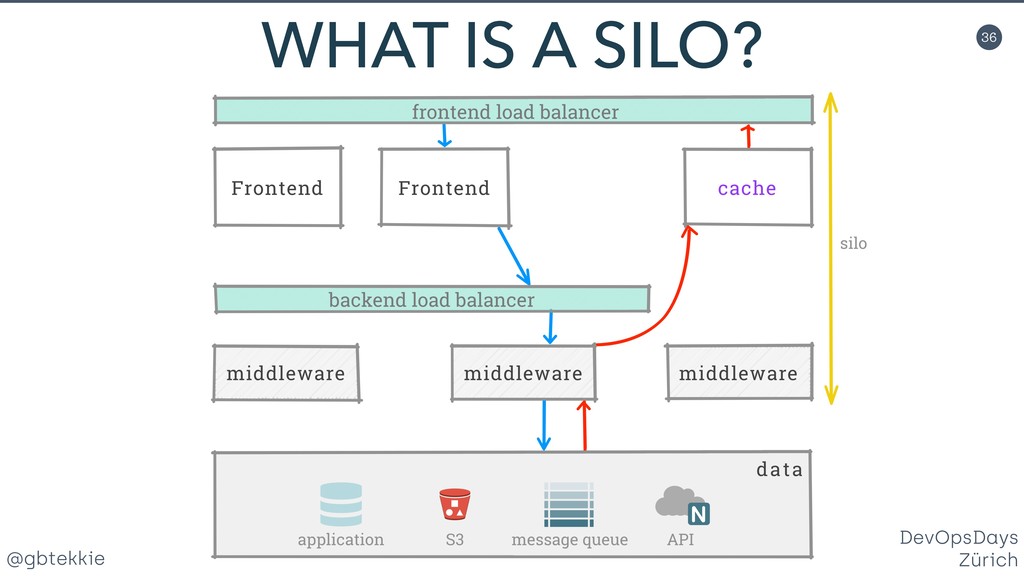
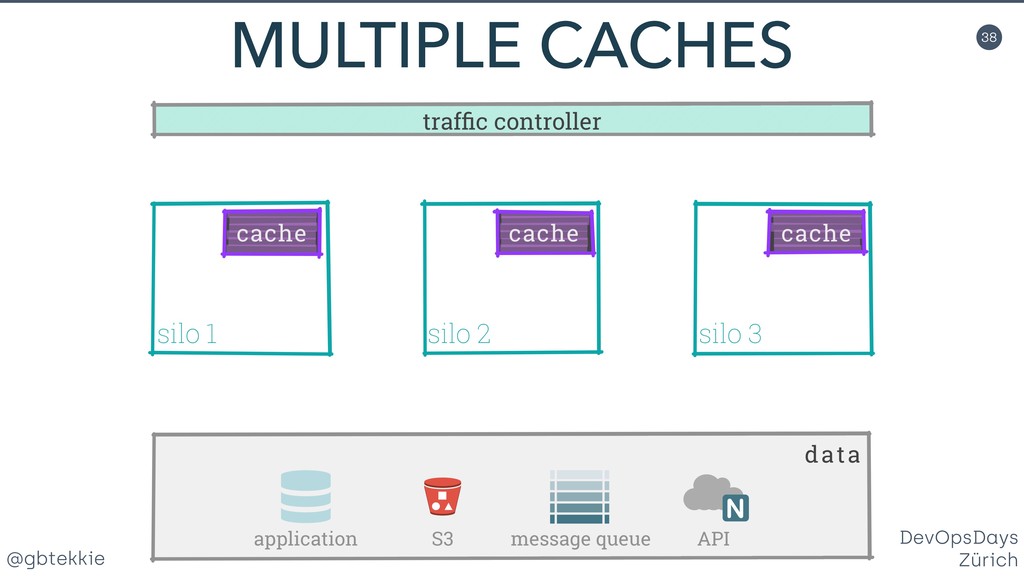
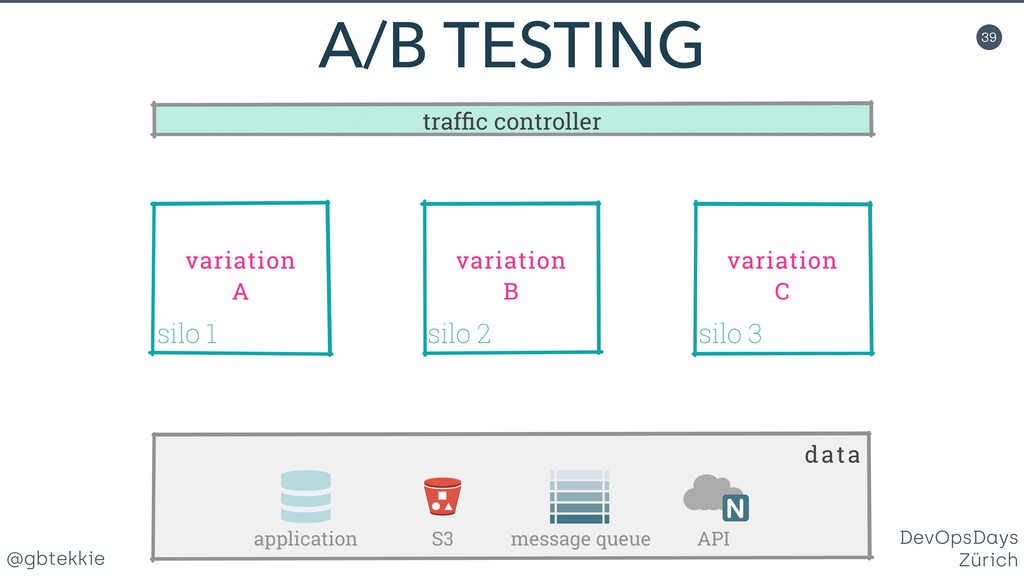
Data redundancy, computing clusters, load balancing, fail-over mechanisms, each of these individually addresses one potential issue, but none treats systems in your organisation holistically for maximising business revenue. You'll learn how to stop hating your existing infrastructure, prepare it for the leap to high availability using simple and intuitive changes that your DevOps team will love. Silos are a clever method of grouping servers in such a way that they can be scaled both horizontally and vertically, depending on the actual application needs. Most importantly, it frees you from over-optimizing the architecture upfront, by allowing fine adjustments easy to integrate in your Agile workflow. And they offer real A/B testing for your infrastructure and backend code. Then we'll look together at the awesome new things that you can do with your new silo superpowers. You'll be able to impress not only your fellow tekkies, but also marketing with helpful new tricks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
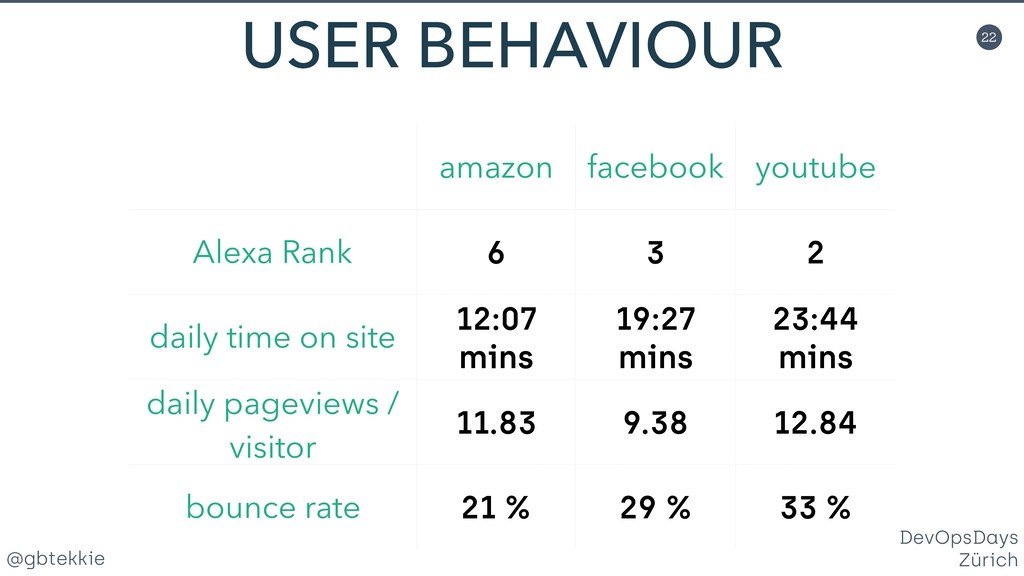{kind=link}
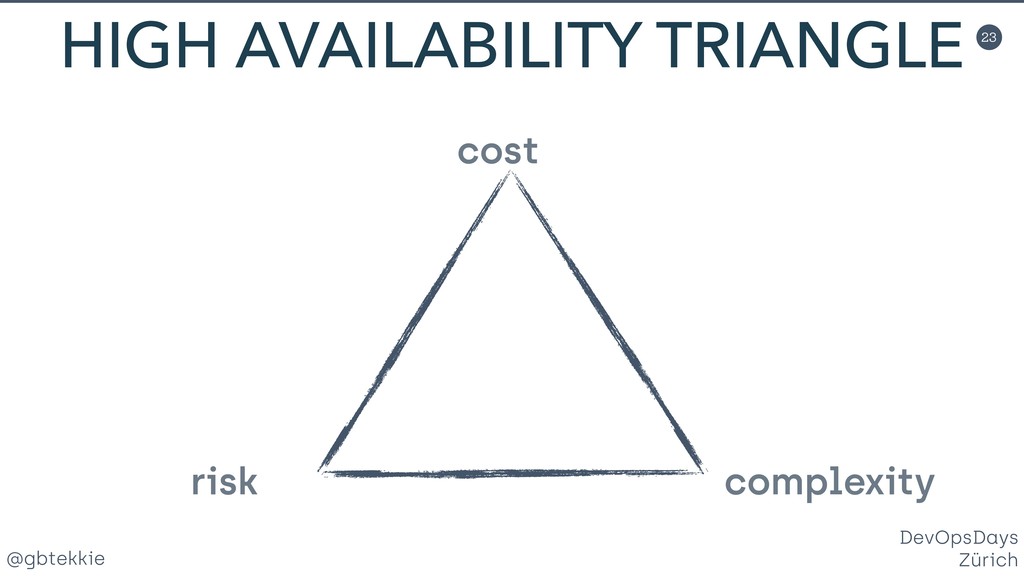{kind=link}
{kind=link}
{kind=link}
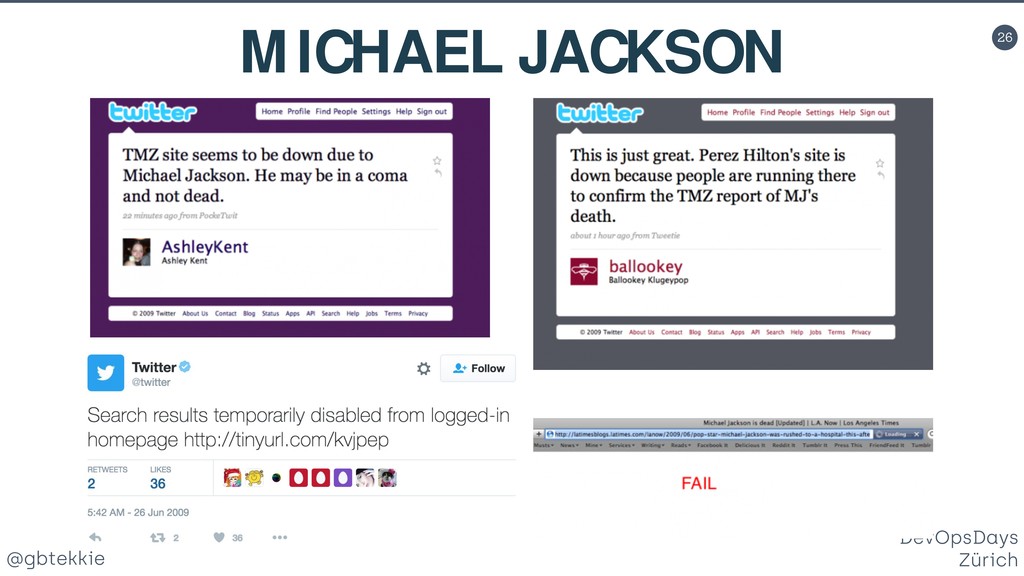{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}