Liang and Gregory Ditzler Department of Electrical and Computer Engineering University of Arizona {zhengzhongliang, ditzler}@email.arizona.edu 2018 IEEE Symposium Series on Computational Intelligence
Language Model • Experiments and Results • Conclusions Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
an ANN: Neural networks can be easily attacked and fooled. “Dog” (Original image) Malicious perturbation “Camel” (Adversarial image) • Poisoning of LSTM language model: In this work we study the learning process of an Long Short-Term Memory (LSTM) language model when training data is poisoned. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
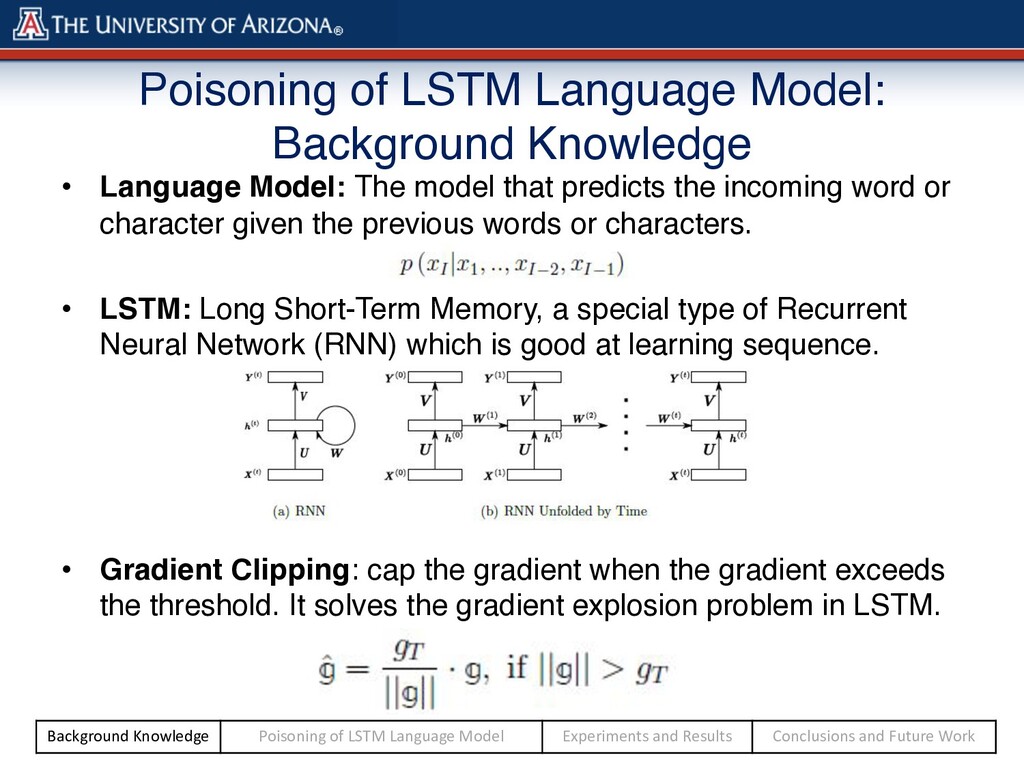
The model that predicts the incoming word or character given the previous words or characters. • LSTM: Long Short-Term Memory, a special type of Recurrent Neural Network (RNN) which is good at learning sequence. • Gradient Clipping: cap the gradient when the gradient exceeds the threshold. It solves the gradient explosion problem in LSTM. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
training samples and loses generalization ability on testing samples. • Dropout: Randomly removes some neurons and weights at each training batch. Dropout is a good method to reduce overfitting in neural networks. • Adversarial Learning: Studies the behavior of machine learning algorithms under attacks. qExploratory Attacks: Attacker can manipulate only testing data to deceive a trained algorithm. qCausative Attacks: Attacker can manipulate training data to disturb the training of algorithms (also referred as training data poisoning). Poisoning of LSTM Language Model: Background Knowledge Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
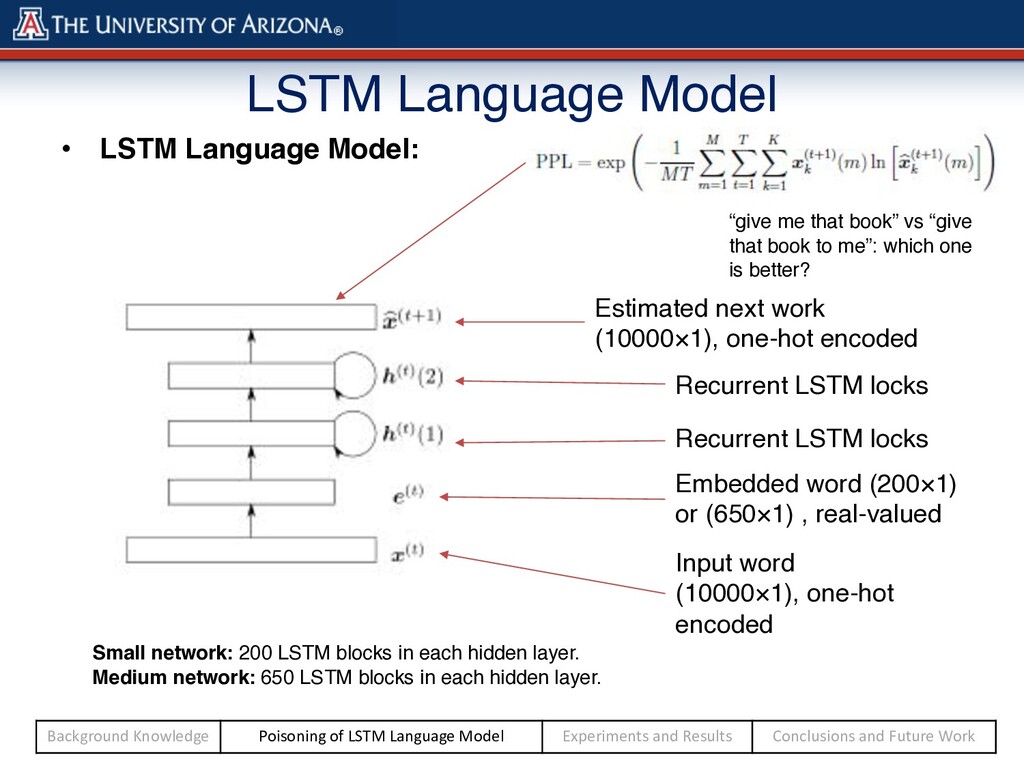
one-hot encoded Embedded word (200×1) or (650×1) , real-valued Recurrent LSTM locks Recurrent LSTM locks Estimated next work (10000×1), one-hot encoded “give me that book” vs “give that book to me”: which one is better? Small network: 200 LSTM blocks in each hidden layer. Medium network: 650 LSTM blocks in each hidden layer. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
Bank Preprocess Select Penn Tree Bank Shakespeare Append • Preprocess: Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
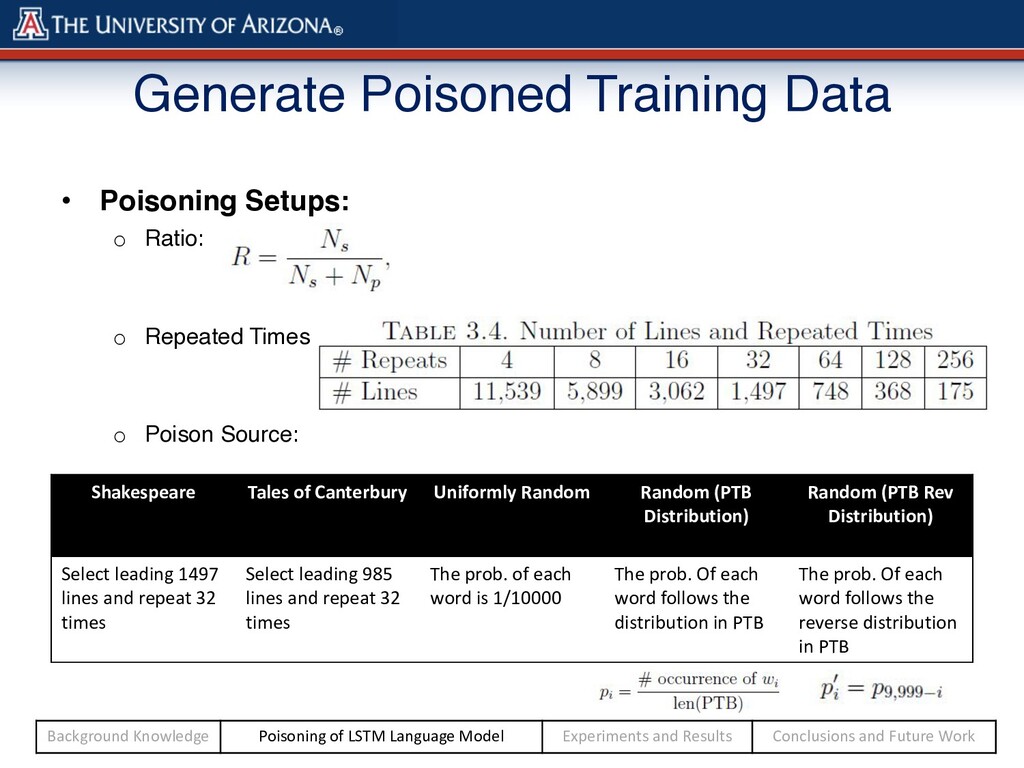
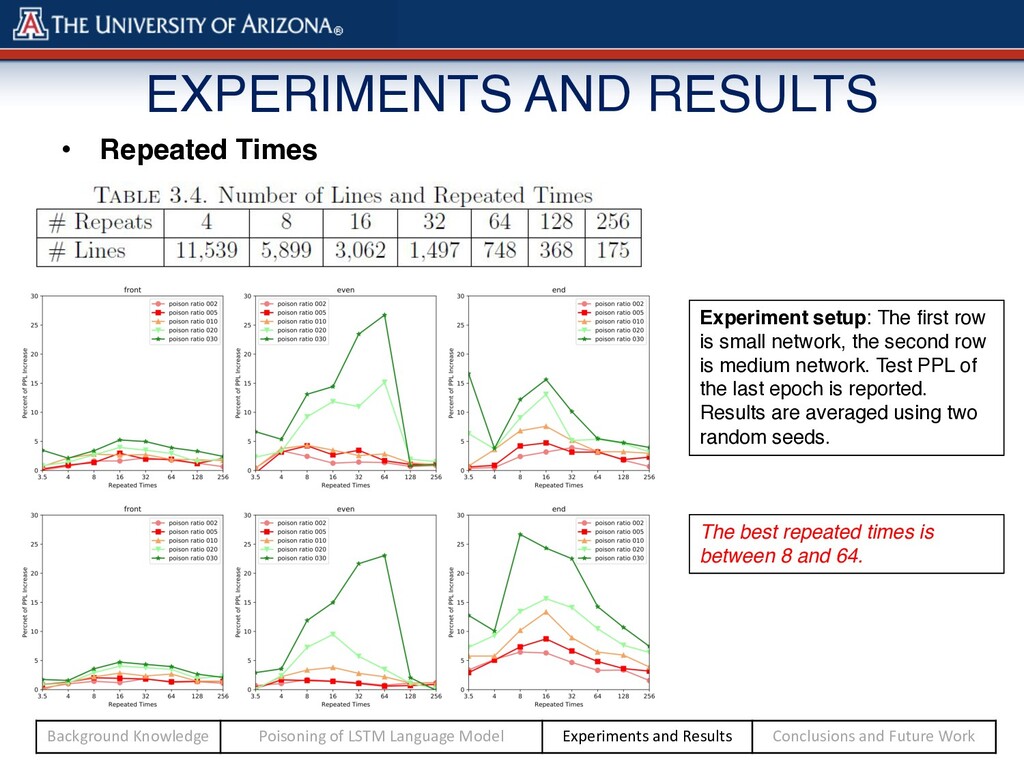
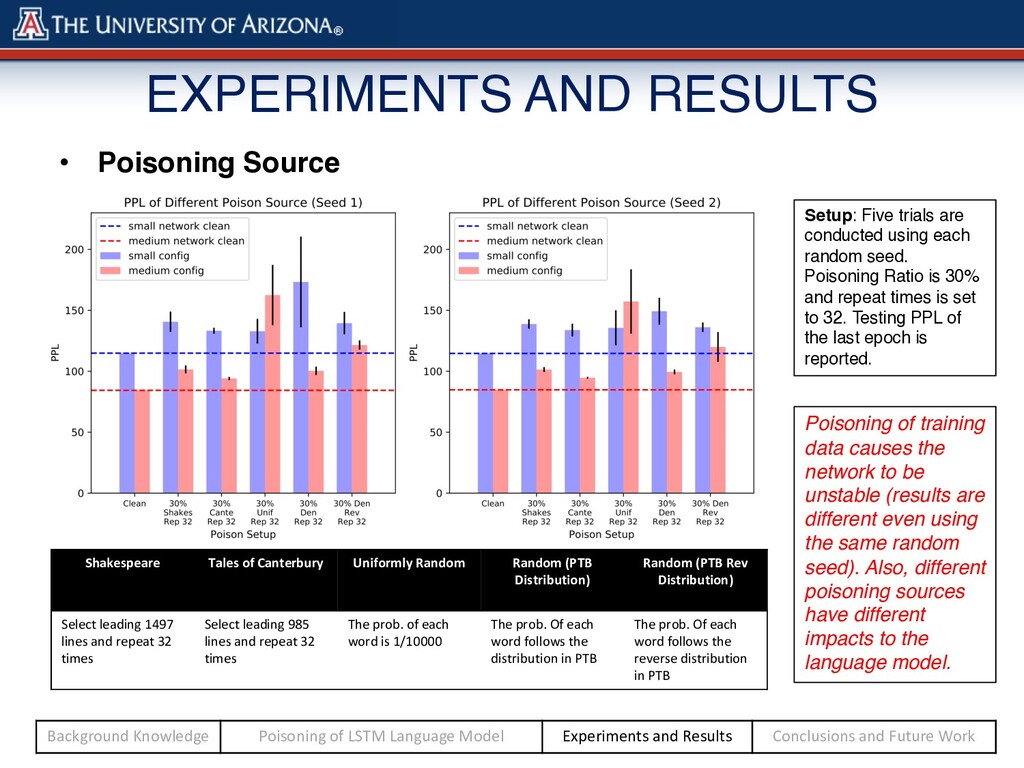
Repeated Times: o Poison Source: Shakespeare Tales of Canterbury Uniformly Random Random (PTB Distribution) Random (PTB Rev Distribution) Select leading 1497 lines and repeat 32 times Select leading 985 lines and repeat 32 times The prob. of each word is 1/10000 The prob. Of each word follows the distribution in PTB The prob. Of each word follows the reverse distribution in PTB Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
shuffled/unshuffled training data and test on unshuffled testing data. The testing PPL is reported. The order of sentence is part of the knowledge to be learned by the LSTM language model. So if this order of sentence is changed in training data, the performance of the language model decreases. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
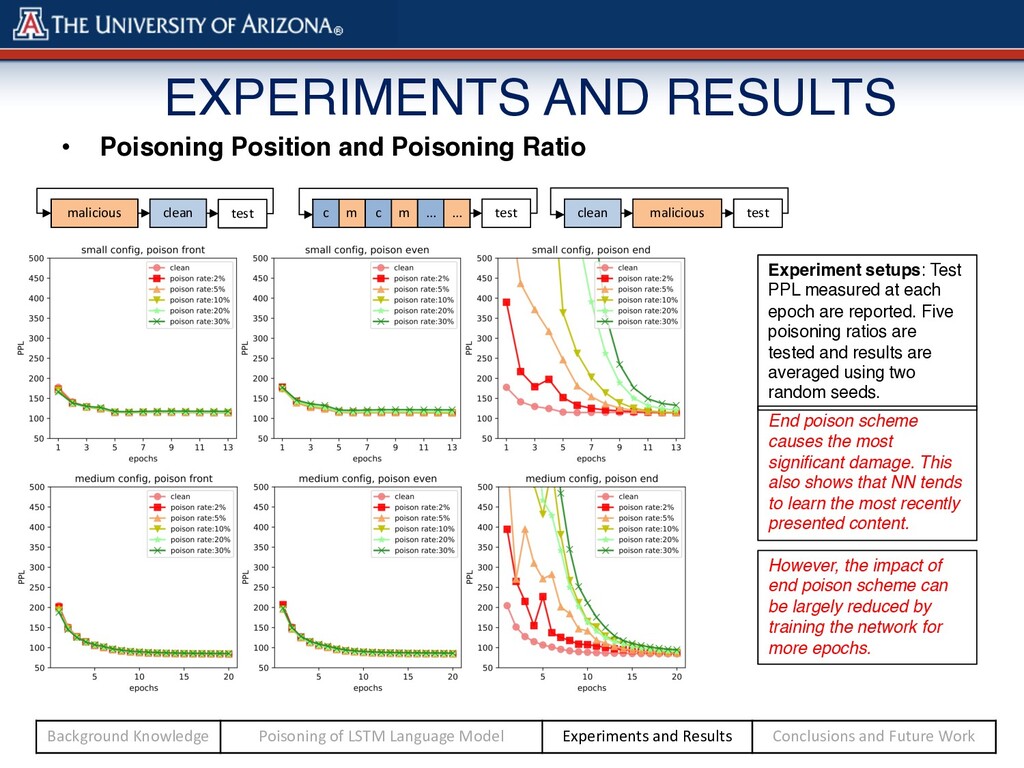
malicious test test c m c m … … End poison scheme causes the most significant damage. This also shows that NN tends to learn the most recently presented content. However, the impact of end poison scheme can be largely reduced by training the network for more epochs. Experiment setups: Test PPL measured at each epoch are reported. Five poisoning ratios are tested and results are averaged using two random seeds. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work EXPERIMENTS AND RESULTS
is between 8 and 64. Experiment setup: The first row is small network, the second row is medium network. Test PPL of the last epoch is reported. Results are averaged using two random seeds. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
conducted using each random seed. Poisoning Ratio is 30% and repeat times is set to 32. Testing PPL of the last epoch is reported. Poisoning of training data causes the network to be unstable (results are different even using the same random seed). Also, different poisoning sources have different impacts to the language model. Shakespeare Tales of Canterbury Uniformly Random Random (PTB Distribution) Random (PTB Rev Distribution) Select leading 1497 lines and repeat 32 times Select leading 985 lines and repeat 32 times The prob. of each word is 1/10000 The prob. Of each word follows the distribution in PTB The prob. Of each word follows the reverse distribution in PTB Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
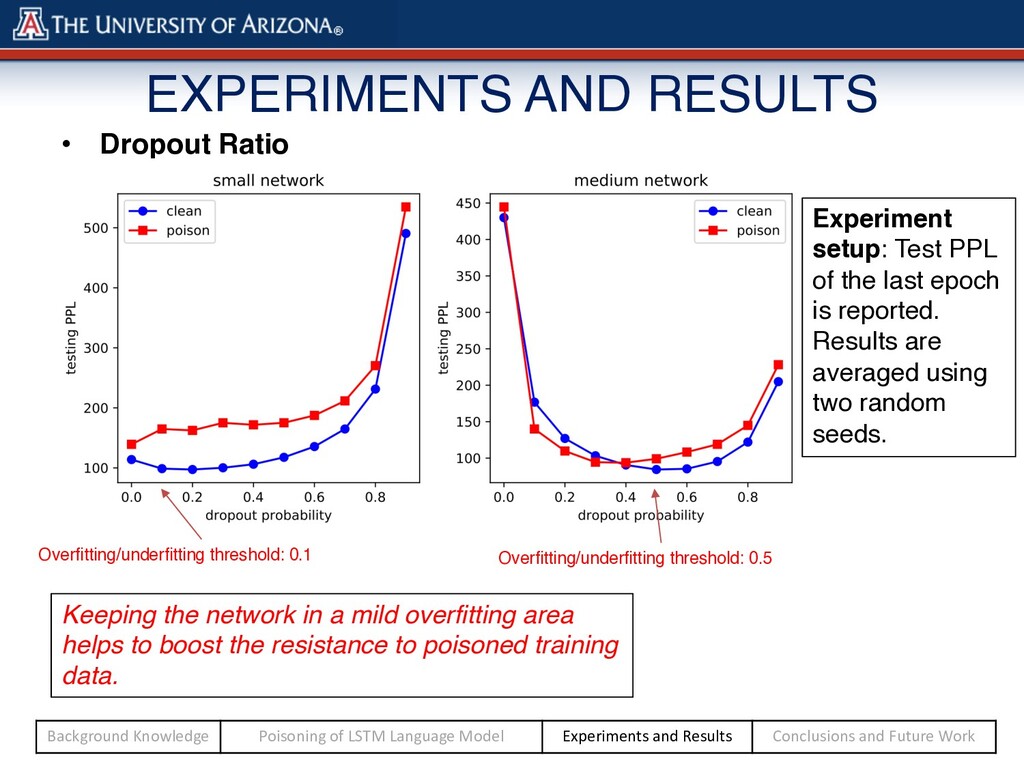
threshold: 0.5 Keeping the network in a mild overfitting area helps to boost the resistance to poisoned training data. Experiment setup: Test PPL of the last epoch is reported. Results are averaged using two random seeds. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
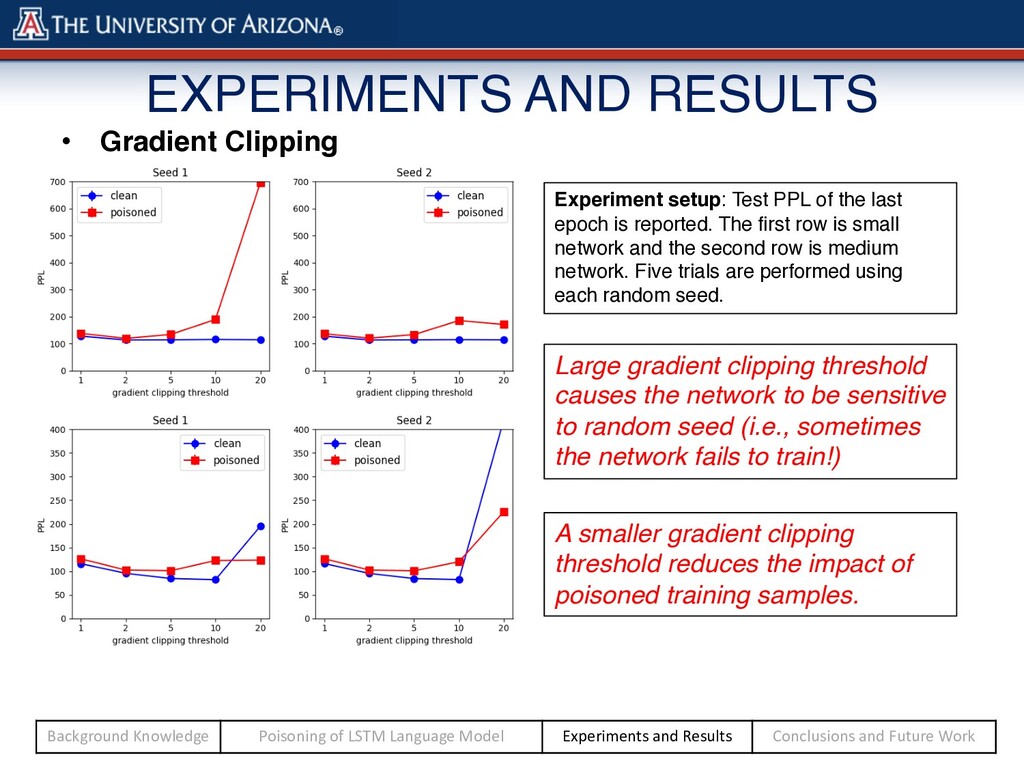
causes the network to be sensitive to random seed (i.e., sometimes the network fails to train!) A smaller gradient clipping threshold reduces the impact of poisoned training samples. Experiment setup: Test PPL of the last epoch is reported. The first row is small network and the second row is medium network. Five trials are performed using each random seed. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
language model. • Appending poisoned data to the end of training set causes the largest damage to the model. But this damage can be largely reduced by training the network for more epochs. • The number of repeated pattern have a significantly impact on the network’s performance. • Different poisoning sources also have different impacts on the network. – Poisoning samples can cause the network to be unstable – The result is not the same even using the same random seed • Dropout can reduce the impact of poisoned training samples; however, this only shows up when the network is in a mild overfitting region. • Gradient clipping is important to training an LSTM language model. – A relatively small clipping threshold can reduce the impact of poisoned training samples. Background Knowledge Poisoning of LSTM Language Model Experiments and Results Conclusions and Future Work
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}